diff --git a/sesh/go.mod b/sesh/go.mod
index 2b10b37..46ad3bf 100644
--- a/sesh/go.mod
+++ b/sesh/go.mod
@@ -2,11 +2,15 @@ module github.com/roodletoof/sesh
go 1.25.6
+require (
+ github.com/goccy/go-yaml v1.19.2
+ github.com/ktr0731/go-fuzzyfinder v0.9.0
+)
+
require (
github.com/gdamore/encoding v1.0.1 // indirect
github.com/gdamore/tcell/v2 v2.6.0 // indirect
github.com/ktr0731/go-ansisgr v0.1.0 // indirect
- github.com/ktr0731/go-fuzzyfinder v0.9.0 // indirect
github.com/lucasb-eyer/go-colorful v1.2.0 // indirect
github.com/mattn/go-runewidth v0.0.16 // indirect
github.com/nsf/termbox-go v1.1.1 // indirect
@@ -15,5 +19,4 @@ require (
golang.org/x/sys v0.32.0 // indirect
golang.org/x/term v0.31.0 // indirect
golang.org/x/text v0.24.0 // indirect
- gopkg.in/yaml.v3 v3.0.1 // indirect
)
diff --git a/sesh/go.sum b/sesh/go.sum
index f3caaf7..60b6f05 100644
--- a/sesh/go.sum
+++ b/sesh/go.sum
@@ -3,6 +3,12 @@ github.com/gdamore/encoding v1.0.1 h1:YzKZckdBL6jVt2Gc+5p82qhrGiqMdG/eNs6Wy0u3Uh
github.com/gdamore/encoding v1.0.1/go.mod h1:0Z0cMFinngz9kS1QfMjCP8TY7em3bZYeeklsSDPivEo=
github.com/gdamore/tcell/v2 v2.6.0 h1:OKbluoP9VYmJwZwq/iLb4BxwKcwGthaa1YNBJIyCySg=
github.com/gdamore/tcell/v2 v2.6.0/go.mod h1:be9omFATkdr0D9qewWW3d+MEvl5dha+Etb5y65J2H8Y=
+github.com/goccy/go-yaml v1.19.2 h1:PmFC1S6h8ljIz6gMRBopkjP1TVT7xuwrButHID66PoM=
+github.com/goccy/go-yaml v1.19.2/go.mod h1:XBurs7gK8ATbW4ZPGKgcbrY1Br56PdM69F7LkFRi1kA=
+github.com/google/go-cmp v0.7.0 h1:wk8382ETsv4JYUZwIsn6YpYiWiBsYLSJiTsyBybVuN8=
+github.com/google/go-cmp v0.7.0/go.mod h1:pXiqmnSA92OHEEa9HXL2W4E7lf9JzCmGVUdgjX3N/iU=
+github.com/google/gofuzz v1.2.0 h1:xRy4A+RhZaiKjJ1bPfwQ8sedCA+YS2YcCHW6ec7JMi0=
+github.com/google/gofuzz v1.2.0/go.mod h1:dBl0BpW6vV/+mYPU4Po3pmUjxk6FQPldtuIdl/M65Eg=
github.com/ktr0731/go-ansisgr v0.1.0 h1:fbuupput8739hQbEmZn1cEKjqQFwtCCZNznnF6ANo5w=
github.com/ktr0731/go-ansisgr v0.1.0/go.mod h1:G9lxwgBwH0iey0Dw5YQd7n6PmQTwTuTM/X5Sgm/UrzE=
github.com/ktr0731/go-fuzzyfinder v0.9.0 h1:JV8S118RABzRl3Lh/RsPhXReJWc2q0rbuipzXQH7L4c=
@@ -58,6 +64,3 @@ golang.org/x/tools v0.0.0-20191119224855-298f0cb1881e/go.mod h1:b+2E5dAYhXwXZwtn
golang.org/x/tools v0.1.12/go.mod h1:hNGJHUnrk76NpqgfD5Aqm5Crs+Hm0VOH/i9J2+nxYbc=
golang.org/x/tools v0.6.0/go.mod h1:Xwgl3UAJ/d3gWutnCtw505GrjyAbvKui8lOU390QaIU=
golang.org/x/xerrors v0.0.0-20190717185122-a985d3407aa7/go.mod h1:I/5z698sn9Ka8TeJc9MKroUUfqBBauWjQqLJ2OPfmY0=
-gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
-gopkg.in/yaml.v3 v3.0.1 h1:fxVm/GzAzEWqLHuvctI91KS9hhNmmWOoWu0XTYJS7CA=
-gopkg.in/yaml.v3 v3.0.1/go.mod h1:K4uyk7z7BCEPqu6E+C64Yfv1cQ7kz7rIZviUmN+EgEM=
diff --git a/sesh/main.go b/sesh/main.go
index 71de589..9e1bbff 100644
--- a/sesh/main.go
+++ b/sesh/main.go
@@ -1,6 +1,7 @@
package main
import (
+ "errors"
"fmt"
"os"
"os/exec"
@@ -9,14 +10,37 @@ import (
"strings"
"syscall"
+ "github.com/goccy/go-yaml"
"github.com/ktr0731/go-fuzzyfinder"
- "gopkg.in/yaml.v3"
)
+var _ yaml.InterfaceUnmarshaler = &Programs{}
+type Programs struct {
+ programs []string
+}
+
+// UnmarshalYAML implements [yaml.InterfaceUnmarshaler].
+func (p *Programs) UnmarshalYAML(f func(any) error) error {
+ var singleStr string
+ err1 := f(&singleStr)
+ if err1 == nil {
+ p.programs = []string{singleStr}
+ return nil
+ }
+ err2 := f(&p.programs)
+ if err2 != nil {
+ return errors.Join(
+ err1,
+ err2,
+ )
+ }
+ return nil
+}
+
type Window struct {
- Path string `yaml:"path"`
- Name string `yaml:"name"`
- Program string `yaml:"program"`
+ Path string `yaml:"path"`
+ Name string `yaml:"name"`
+ Programs Programs `yaml:"program"`
}
func (w Window) ExpandedPath() string {
@@ -30,7 +54,7 @@ func (w Window) ExpandedPath() string {
type Config map[string][]Window
const (
- tmux = "tmux"
+ tmux = "tmux"
mkdir = "mkdir"
)
@@ -74,7 +98,7 @@ func main() {
},
fuzzyfinder.WithPreviewWindow(
func(i, width, height int) string {
- width = width/2-4
+ width = width/2 - 4
if i < 0 {
return ""
}
@@ -90,8 +114,11 @@ func main() {
if window.Path != "" {
fmt.Fprintf(&builder, " path: %s\n", window.Path)
}
- if window.Program != "" {
- fmt.Fprintf(&builder, " prog: %s\n", window.Program)
+ if len(window.Programs.programs) != 0 {
+ fmt.Fprintf(&builder, " program:\n")
+ }
+ for _, prog := range window.Programs.programs {
+ fmt.Fprintf(&builder, " - %s\n", prog)
}
fmt.Fprint(&builder, "\n")
}
@@ -164,9 +191,9 @@ func NewWindowInSession(seshName string, window Window) {
if err != nil {
panic(err)
}
- if window.Program != "" {
+ for _, prog := range window.Programs.programs {
var carriageReturn = string([]byte{13})
- cmd = exec.Command(tmux, "send-keys", "-t", fmt.Sprintf("%s:$", seshName), window.Program, carriageReturn)
+ cmd = exec.Command(tmux, "send-keys", "-t", fmt.Sprintf("%s:$", seshName), prog, carriageReturn)
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Stdin = os.Stdin
diff --git a/sesh/vendor/github.com/goccy/go-yaml/.codecov.yml b/sesh/vendor/github.com/goccy/go-yaml/.codecov.yml
new file mode 100644
index 0000000..8364eea
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/.codecov.yml
@@ -0,0 +1,31 @@
+codecov:
+ require_ci_to_pass: yes
+
+coverage:
+ precision: 2
+ round: down
+ range: "70...100"
+
+ status:
+ project:
+ default:
+ target: 75%
+ threshold: 2%
+ patch: off
+ changes: no
+
+parsers:
+ gcov:
+ branch_detection:
+ conditional: yes
+ loop: yes
+ method: no
+ macro: no
+
+comment:
+ layout: "header,diff"
+ behavior: default
+ require_changes: no
+
+ignore:
+ - ast
diff --git a/sesh/vendor/github.com/goccy/go-yaml/.gitignore b/sesh/vendor/github.com/goccy/go-yaml/.gitignore
new file mode 100644
index 0000000..47952bd
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/.gitignore
@@ -0,0 +1,3 @@
+bin/
+.idea/
+cover.out
diff --git a/sesh/vendor/github.com/goccy/go-yaml/.golangci.yml b/sesh/vendor/github.com/goccy/go-yaml/.golangci.yml
new file mode 100644
index 0000000..05675c8
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/.golangci.yml
@@ -0,0 +1,65 @@
+version: "2"
+linters:
+ default: none
+ enable:
+ - errcheck
+ - govet
+ - ineffassign
+ - misspell
+ - perfsprint
+ - staticcheck
+ - unused
+ settings:
+ errcheck:
+ without_tests: true
+ govet:
+ disable:
+ - tests
+ misspell:
+ locale: US
+ perfsprint:
+ int-conversion: false
+ err-error: false
+ errorf: true
+ sprintf1: false
+ strconcat: false
+ staticcheck:
+ checks:
+ - -ST1000
+ - -ST1005
+ - all
+ exclusions:
+ generated: lax
+ presets:
+ - comments
+ - common-false-positives
+ - legacy
+ - std-error-handling
+ rules:
+ - linters:
+ - staticcheck
+ path: _test\.go
+ paths:
+ - third_party$
+ - builtin$
+ - examples$
+formatters:
+ enable:
+ - gci
+ - gofmt
+ settings:
+ gci:
+ sections:
+ - standard
+ - default
+ - prefix(github.com/goccy/go-yaml)
+ - blank
+ - dot
+ gofmt:
+ simplify: true
+ exclusions:
+ generated: lax
+ paths:
+ - third_party$
+ - builtin$
+ - examples$
diff --git a/sesh/vendor/github.com/goccy/go-yaml/CHANGELOG.md b/sesh/vendor/github.com/goccy/go-yaml/CHANGELOG.md
new file mode 100644
index 0000000..c8f820d
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/CHANGELOG.md
@@ -0,0 +1,186 @@
+# 1.11.2 - 2023-09-15
+
+### Fix bugs
+
+- Fix quoted comments ( #370 )
+- Fix handle of space at start or last ( #376 )
+- Fix sequence with comment ( #390 )
+
+# 1.11.1 - 2023-09-14
+
+### Fix bugs
+
+- Handle `\r` in a double-quoted string the same as `\n` ( #372 )
+- Replace loop with n.Values = append(n.Values, target.Values...) ( #380 )
+- Skip encoding an inline field if it is null ( #386 )
+- Fix comment parsing with null value ( #388 )
+
+# 1.11.0 - 2023-04-03
+
+### Features
+
+- Supports dynamically switch encode and decode processing for a given type
+
+# 1.10.1 - 2023-03-28
+
+### Features
+
+- Quote YAML 1.1 bools at encoding time for compatibility with other legacy parsers
+- Add support of 32-bit architecture
+
+### Fix bugs
+
+- Don't trim all space characters in block style sequence
+- Support strings starting with `@`
+
+# 1.10.0 - 2023-03-01
+
+### Fix bugs
+
+Reversible conversion of comments was not working in various cases, which has been corrected.
+**Breaking Change** exists in the comment map interface. However, if you are dealing with CommentMap directly, there is no problem.
+
+
+# 1.9.8 - 2022-12-19
+
+### Fix feature
+
+- Append new line at the end of file ( #329 )
+
+### Fix bugs
+
+- Fix custom marshaler ( #333, #334 )
+- Fix behavior when struct fields conflicted( #335 )
+- Fix position calculation for literal, folded and raw folded strings ( #330 )
+
+# 1.9.7 - 2022-12-03
+
+### Fix bugs
+
+- Fix handling of quoted map key ( #328 )
+- Fix resusing process of scanning context ( #322 )
+
+## v1.9.6 - 2022-10-26
+
+### New Features
+
+- Introduce MapKeyNode interface to limit node types for map key ( #312 )
+
+### Fix bugs
+
+- Quote strings with special characters in flow mode ( #270 )
+- typeError implements PrettyPrinter interface ( #280 )
+- Fix incorrect const type ( #284 )
+- Fix large literals type inference on 32 bits ( #293 )
+- Fix UTF-8 characters ( #294 )
+- Fix decoding of unknown aliases ( #317 )
+- Fix stream encoder for insert a separator between each encoded document ( #318 )
+
+### Update
+
+- Update golang.org/x/sys ( #289 )
+- Update Go version in CI ( #295 )
+- Add test cases for missing keys to struct literals ( #300 )
+
+## v1.9.5 - 2022-01-12
+
+### New Features
+
+* Add UseSingleQuote option ( #265 )
+
+### Fix bugs
+
+* Preserve defaults while decoding nested structs ( #260 )
+* Fix minor typo in decodeInit error ( #264 )
+* Handle empty sequence entries ( #275 )
+* Fix encoding of sequence with multiline string ( #276 )
+* Fix encoding of BytesMarshaler type ( #277 )
+* Fix indentState logic for multi-line value ( #278 )
+
+## v1.9.4 - 2021-10-12
+
+### Fix bugs
+
+* Keep prev/next reference between tokens containing comments when filtering comment tokens ( #257 )
+* Supports escaping reserved keywords in PathBuilder ( #258 )
+
+## v1.9.3 - 2021-09-07
+
+### New Features
+
+* Support encoding and decoding `time.Duration` fields ( #246 )
+* Allow reserved characters for key name in YAMLPath ( #251 )
+* Support getting YAMLPath from ast.Node ( #252 )
+* Support CommentToMap option ( #253 )
+
+### Fix bugs
+
+* Fix encoding nested sequences with `yaml.IndentSequence` ( #241 )
+* Fix error reporting on inline structs in strict mode ( #244, #245 )
+* Fix encoding of large floats ( #247 )
+
+### Improve workflow
+
+* Migrate CI from CircleCI to GitHub Action ( #249 )
+* Add workflow for ycat ( #250 )
+
+## v1.9.2 - 2021-07-26
+
+### Support WithComment option ( #238 )
+
+`yaml.WithComment` is a option for encoding with comment.
+The position where you want to add a comment is represented by YAMLPath, and it is the key of `yaml.CommentMap`.
+Also, you can select `Head` comment or `Line` comment as the comment type.
+
+## v1.9.1 - 2021-07-20
+
+### Fix DecodeFromNode ( #237 )
+
+- Fix YAML handling where anchor exists
+
+## v1.9.0 - 2021-07-19
+
+### New features
+
+- Support encoding of comment node ( #233 )
+- Support `yaml.NodeToValue(ast.Node, interface{}, ...DecodeOption) error` ( #236 )
+ - Can convert a AST node to a value directly
+
+### Fix decoder for comment
+
+- Fix parsing of literal with comment ( #234 )
+
+### Rename API ( #235 )
+
+- Rename `MarshalWithContext` to `MarshalContext`
+- Rename `UnmarshalWithContext` to `UnmarshalContext`
+
+## v1.8.10 - 2021-07-02
+
+### Fixed bugs
+
+- Fix searching anchor by alias name ( #212 )
+- Fixing Issue 186, scanner should account for newline characters when processing multi-line text. Without this source annotations line/column number (for this and all subsequent tokens) is inconsistent with plain text editors. e.g. https://github.com/goccy/go-yaml/issues/186. This addresses the issue specifically for single and double quote text only. ( #210 )
+- Add error for unterminated flow mapping node ( #213 )
+- Handle missing required field validation ( #221 )
+- Nicely format unexpected node type errors ( #229 )
+- Support to encode map which has defined type key ( #231 )
+
+### New features
+
+- Support sequence indentation by EncodeOption ( #232 )
+
+## v1.8.9 - 2021-03-01
+
+### Fixed bugs
+
+- Fix origin buffer for DocumentHeader and DocumentEnd and Directive
+- Fix origin buffer for anchor value
+- Fix syntax error about map value
+- Fix parsing MergeKey ('<<') characters
+- Fix encoding of float value
+- Fix incorrect column annotation when single or double quotes are used
+
+### New features
+
+- Support to encode/decode of ast.Node directly
diff --git a/sesh/vendor/github.com/goccy/go-yaml/LICENSE b/sesh/vendor/github.com/goccy/go-yaml/LICENSE
new file mode 100644
index 0000000..04485ce
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2019 Masaaki Goshima
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/sesh/vendor/github.com/goccy/go-yaml/Makefile b/sesh/vendor/github.com/goccy/go-yaml/Makefile
new file mode 100644
index 0000000..5993616
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/Makefile
@@ -0,0 +1,55 @@
+## Location to install dependencies to
+LOCALBIN ?= $(shell pwd)/bin
+TESTMOD := testdata/go_test.mod
+
+$(LOCALBIN):
+ mkdir -p $(LOCALBIN)
+
+.PHONY: test
+test:
+ go test -v -race ./...
+ go test -v -race ./testdata -modfile=$(TESTMOD)
+
+.PHONY: simple-test
+simple-test:
+ go test -v ./...
+ go test -v ./testdata -modfile=$(TESTMOD)
+
+.PHONY: fuzz
+fuzz:
+ go test -fuzz=Fuzz -fuzztime 60s
+
+.PHONY: cover
+cover:
+ go test -coverpkg=.,./ast,./lexer,./parser,./printer,./scanner,./token -coverprofile=cover.out -modfile=$(TESTMOD) ./... ./testdata
+
+.PHONY: cover-html
+cover-html: cover
+ go tool cover -html=cover.out
+
+.PHONY: ycat/build
+ycat/build: $(LOCALBIN)
+ cd ./cmd/ycat && go build -o $(LOCALBIN)/ycat .
+
+.PHONY: lint
+lint: golangci-lint ## Run golangci-lint
+ @$(GOLANGCI_LINT) run
+
+.PHONY: fmt
+fmt: golangci-lint ## Ensure consistent code style
+ @go mod tidy
+ @go fmt ./...
+ @$(GOLANGCI_LINT) run --fix
+
+## Tool Binaries
+GOLANGCI_LINT ?= $(LOCALBIN)/golangci-lint
+
+## Tool Versions
+GOLANGCI_VERSION := 2.1.2
+
+.PHONY: golangci-lint
+.PHONY: $(GOLANGCI_LINT)
+golangci-lint: $(GOLANGCI_LINT) ## Download golangci-lint locally if necessary.
+$(GOLANGCI_LINT): $(LOCALBIN)
+ @test -s $(LOCALBIN)/golangci-lint && $(LOCALBIN)/golangci-lint version --short | grep -q $(GOLANGCI_VERSION) || \
+ curl -sSfL https://raw.githubusercontent.com/golangci/golangci-lint/master/install.sh | sh -s -- -b $(LOCALBIN) v$(GOLANGCI_VERSION)
diff --git a/sesh/vendor/github.com/goccy/go-yaml/README.md b/sesh/vendor/github.com/goccy/go-yaml/README.md
new file mode 100644
index 0000000..d5ac5b7
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/README.md
@@ -0,0 +1,420 @@
+# YAML support for the Go language
+
+[](https://pkg.go.dev/github.com/goccy/go-yaml)
+
+[](https://codecov.io/gh/goccy/go-yaml)
+[](https://goreportcard.com/report/github.com/goccy/go-yaml)
+
+ +
+## This library has **NO** relation to the go-yaml/yaml library
+
+> [!IMPORTANT]
+> This library is developed from scratch to replace [`go-yaml/yaml`](https://github.com/go-yaml/yaml).
+> If you're looking for a better YAML library, this one should be helpful.
+
+# Why a new library?
+
+As of this writing, there already exists a de facto standard library for YAML processing for Go: [https://github.com/go-yaml/yaml](https://github.com/go-yaml/yaml). However, we believe that a new YAML library is necessary for the following reasons:
+
+- Not actively maintained
+- `go-yaml/yaml` has ported the libyaml written in C to Go, so the source code is not written in Go style
+- There is a lot of content that cannot be parsed
+- YAML is often used for configuration, and it is common to include validation along with it. However, the errors in `go-yaml/yaml` are not intuitive, and it is difficult to provide meaningful validation errors
+- When creating tools that use YAML, there are cases where reversible transformation of YAML is required. However, to perform reversible transformations of content that includes Comments or Anchors/Aliases, manipulating the AST is the only option
+- Non-intuitive [Marshaler](https://pkg.go.dev/gopkg.in/yaml.v3#Marshaler) / [Unmarshaler](https://pkg.go.dev/gopkg.in/yaml.v3#Unmarshaler)
+
+By the way, libraries such as [ghodss/yaml](https://github.com/ghodss/yaml) and [sigs.k8s.io/yaml](https://github.com/kubernetes-sigs/yaml) also depend on go-yaml/yaml, so if you are using these libraries, the same issues apply: they cannot parse things that go-yaml/yaml cannot parse, and they inherit many of the problems that go-yaml/yaml has.
+
+# Features
+
+- No dependencies
+- A better parser than `go-yaml/yaml`.
+ - [Support recursive processing](https://github.com/apple/device-management/blob/release/docs/schema.yaml)
+ - Higher coverage in the [YAML Test Suite](https://github.com/yaml/yaml-test-suite?tab=readme-ov-file)
+ - YAML Test Suite consists of 402 cases in total, of which `gopkg.in/yaml.v3` passes `295`. In addition to passing all those test cases, `goccy/go-yaml` successfully passes nearly 60 additional test cases ( 2024/12/15 )
+ - The test code is [here](https://github.com/goccy/go-yaml/blob/master/yaml_test_suite_test.go#L77)
+- Ease and sustainability of maintenance
+ - The main maintainer is [@goccy](https://github.com/goccy), but we are also building a system to develop as a team with trusted developers
+ - Since it is written from scratch, the code is easy to read for Gophers
+- An API structure that allows the use of not only `Encoder`/`Decoder` but also `Tokenizer` and `Parser` functionalities.
+ - [lexer.Tokenize](https://pkg.go.dev/github.com/goccy/go-yaml@v1.15.4/lexer#Tokenize)
+ - [parser.Parse](https://pkg.go.dev/github.com/goccy/go-yaml@v1.15.4/parser#Parse)
+- Filtering, replacing, and merging YAML content using YAML Path
+- Reversible transformation without using the AST for YAML that includes Anchors, Aliases, and Comments
+- Customize the Marshal/Unmarshal behavior for primitive types and third-party library types ([RegisterCustomMarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#RegisterCustomMarshaler), [RegisterCustomUnmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#RegisterCustomUnmarshaler))
+- Respects `encoding/json` behavior
+ - Accept the `json` tag. Note that not all options from the `json` tag will have significance when parsing YAML documents. If both tags exist, `yaml` tag will take precedence.
+ - [json.Marshaler](https://pkg.go.dev/encoding/json#Marshaler) style [marshaler](https://pkg.go.dev/github.com/goccy/go-yaml#BytesMarshaler)
+ - [json.Unmarshaler](https://pkg.go.dev/encoding/json#Unmarshaler) style [unmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#BytesUnmarshaler)
+ - Options for using `MarshalJSON` and `UnmarshalJSON` ([UseJSONMarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#UseJSONMarshaler), [UseJSONUnmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#UseJSONUnmarshaler))
+- Pretty format for error notifications
+- Smart validation processing combined with [go-playground/validator](https://github.com/go-playground/validator)
+ - [example test code is here](https://github.com/goccy/go-yaml/blob/45889c98b0a0967240eb595a1bd6896e2f575106/testdata/validate_test.go#L12)
+- Allow referencing elements declared in another file via anchors
+
+# Users
+
+The repositories that use goccy/go-yaml are listed here.
+
+- https://github.com/goccy/go-yaml/wiki/Users
+
+The source data is [here](https://github.com/goccy/go-yaml/network/dependents).
+It is already being used in many repositories. Now it's your turn 😄
+
+# Playground
+
+The Playground visualizes how go-yaml processes YAML text. Use it to assist with your debugging or issue reporting.
+
+https://goccy.github.io/go-yaml
+
+# Installation
+
+```sh
+go get github.com/goccy/go-yaml
+```
+
+# Synopsis
+
+## 1. Simple Encode/Decode
+
+Has an interface like `go-yaml/yaml` using `reflect`
+
+```go
+var v struct {
+ A int
+ B string
+}
+v.A = 1
+v.B = "hello"
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes)) // "a: 1\nb: hello\n"
+```
+
+```go
+ yml := `
+%YAML 1.2
+---
+a: 1
+b: c
+`
+var v struct {
+ A int
+ B string
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+To control marshal/unmarshal behavior, you can use the `yaml` tag.
+
+```go
+ yml := `---
+foo: 1
+bar: c
+`
+var v struct {
+ A int `yaml:"foo"`
+ B string `yaml:"bar"`
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+For convenience, we also accept the `json` tag. Note that not all options from
+the `json` tag will have significance when parsing YAML documents. If both
+tags exist, `yaml` tag will take precedence.
+
+```go
+ yml := `---
+foo: 1
+bar: c
+`
+var v struct {
+ A int `json:"foo"`
+ B string `json:"bar"`
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+For custom marshal/unmarshaling, implement either `Bytes` or `Interface` variant of marshaler/unmarshaler. The difference is that while `BytesMarshaler`/`BytesUnmarshaler` behaves like [`encoding/json`](https://pkg.go.dev/encoding/json) and `InterfaceMarshaler`/`InterfaceUnmarshaler` behaves like [`gopkg.in/yaml.v2`](https://pkg.go.dev/gopkg.in/yaml.v2).
+
+Semantically both are the same, but they differ in performance. Because indentation matters in YAML, you cannot simply accept a valid YAML fragment from a Marshaler, and expect it to work when it is attached to the parent container's serialized form. Therefore when we receive use the `BytesMarshaler`, which returns `[]byte`, we must decode it once to figure out how to make it work in the given context. If you use the `InterfaceMarshaler`, we can skip the decoding.
+
+If you are repeatedly marshaling complex objects, the latter is always better
+performance wise. But if you are, for example, just providing a choice between
+a config file format that is read only once, the former is probably easier to
+code.
+
+## 2. Reference elements declared in another file
+
+`testdata` directory contains `anchor.yml` file:
+
+```shell
+├── testdata
+ └── anchor.yml
+```
+
+And `anchor.yml` is defined as follows:
+
+```yaml
+a: &a
+ b: 1
+ c: hello
+```
+
+Then, if `yaml.ReferenceDirs("testdata")` option is passed to `yaml.Decoder`,
+ `Decoder` tries to find the anchor definition from YAML files the under `testdata` directory.
+
+```go
+buf := bytes.NewBufferString("a: *a\n")
+dec := yaml.NewDecoder(buf, yaml.ReferenceDirs("testdata"))
+var v struct {
+ A struct {
+ B int
+ C string
+ }
+}
+if err := dec.Decode(&v); err != nil {
+ //...
+}
+fmt.Printf("%+v\n", v) // {A:{B:1 C:hello}}
+```
+
+## 3. Encode with `Anchor` and `Alias`
+
+### 3.1. Explicitly declared `Anchor` name and `Alias` name
+
+If you want to use `anchor`, you can define it as a struct tag.
+If the value specified for an anchor is a pointer type and the same address as the pointer is found, the value is automatically set to alias.
+If an explicit alias name is specified, an error is raised if its value is different from the value specified in the anchor.
+
+```go
+type T struct {
+ A int
+ B string
+}
+var v struct {
+ C *T `yaml:"c,anchor=x"`
+ D *T `yaml:"d,alias=x"`
+}
+v.C = &T{A: 1, B: "hello"}
+v.D = v.C
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ panic(err)
+}
+fmt.Println(string(bytes))
+/*
+c: &x
+ a: 1
+ b: hello
+d: *x
+*/
+```
+
+### 3.2. Implicitly declared `Anchor` and `Alias` names
+
+If you do not explicitly declare the anchor name, the default behavior is to
+use the equivalent of `strings.ToLower($FieldName)` as the name of the anchor.
+If the value specified for an anchor is a pointer type and the same address as the pointer is found, the value is automatically set to alias.
+
+```go
+type T struct {
+ I int
+ S string
+}
+var v struct {
+ A *T `yaml:"a,anchor"`
+ B *T `yaml:"b,anchor"`
+ C *T `yaml:"c"`
+ D *T `yaml:"d"`
+}
+v.A = &T{I: 1, S: "hello"}
+v.B = &T{I: 2, S: "world"}
+v.C = v.A // C has same pointer address to A
+v.D = v.B // D has same pointer address to B
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes))
+/*
+a: &a
+ i: 1
+ s: hello
+b: &b
+ i: 2
+ s: world
+c: *a
+d: *b
+*/
+```
+
+### 3.3 MergeKey and Alias
+
+Merge key and alias ( `<<: *alias` ) can be used by embedding a structure with the `inline,alias` tag.
+
+```go
+type Person struct {
+ *Person `yaml:",omitempty,inline,alias"` // embed Person type for default value
+ Name string `yaml:",omitempty"`
+ Age int `yaml:",omitempty"`
+}
+defaultPerson := &Person{
+ Name: "John Smith",
+ Age: 20,
+}
+people := []*Person{
+ {
+ Person: defaultPerson, // assign default value
+ Name: "Ken", // override Name property
+ Age: 10, // override Age property
+ },
+ {
+ Person: defaultPerson, // assign default value only
+ },
+}
+var doc struct {
+ Default *Person `yaml:"default,anchor"`
+ People []*Person `yaml:"people"`
+}
+doc.Default = defaultPerson
+doc.People = people
+bytes, err := yaml.Marshal(doc)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes))
+/*
+default: &default
+ name: John Smith
+ age: 20
+people:
+- <<: *default
+ name: Ken
+ age: 10
+- <<: *default
+*/
+```
+
+## 4. Pretty Formatted Errors
+
+Error values produced during parsing have two extra features over regular
+error values.
+
+First, by default, they contain extra information on the location of the error
+from the source YAML document, to make it easier to find the error location.
+
+Second, the error messages can optionally be colorized.
+
+If you would like to control exactly how the output looks like, consider
+using `yaml.FormatError`, which accepts two boolean values to
+control turning these features on or off.
+
+
+
+## This library has **NO** relation to the go-yaml/yaml library
+
+> [!IMPORTANT]
+> This library is developed from scratch to replace [`go-yaml/yaml`](https://github.com/go-yaml/yaml).
+> If you're looking for a better YAML library, this one should be helpful.
+
+# Why a new library?
+
+As of this writing, there already exists a de facto standard library for YAML processing for Go: [https://github.com/go-yaml/yaml](https://github.com/go-yaml/yaml). However, we believe that a new YAML library is necessary for the following reasons:
+
+- Not actively maintained
+- `go-yaml/yaml` has ported the libyaml written in C to Go, so the source code is not written in Go style
+- There is a lot of content that cannot be parsed
+- YAML is often used for configuration, and it is common to include validation along with it. However, the errors in `go-yaml/yaml` are not intuitive, and it is difficult to provide meaningful validation errors
+- When creating tools that use YAML, there are cases where reversible transformation of YAML is required. However, to perform reversible transformations of content that includes Comments or Anchors/Aliases, manipulating the AST is the only option
+- Non-intuitive [Marshaler](https://pkg.go.dev/gopkg.in/yaml.v3#Marshaler) / [Unmarshaler](https://pkg.go.dev/gopkg.in/yaml.v3#Unmarshaler)
+
+By the way, libraries such as [ghodss/yaml](https://github.com/ghodss/yaml) and [sigs.k8s.io/yaml](https://github.com/kubernetes-sigs/yaml) also depend on go-yaml/yaml, so if you are using these libraries, the same issues apply: they cannot parse things that go-yaml/yaml cannot parse, and they inherit many of the problems that go-yaml/yaml has.
+
+# Features
+
+- No dependencies
+- A better parser than `go-yaml/yaml`.
+ - [Support recursive processing](https://github.com/apple/device-management/blob/release/docs/schema.yaml)
+ - Higher coverage in the [YAML Test Suite](https://github.com/yaml/yaml-test-suite?tab=readme-ov-file)
+ - YAML Test Suite consists of 402 cases in total, of which `gopkg.in/yaml.v3` passes `295`. In addition to passing all those test cases, `goccy/go-yaml` successfully passes nearly 60 additional test cases ( 2024/12/15 )
+ - The test code is [here](https://github.com/goccy/go-yaml/blob/master/yaml_test_suite_test.go#L77)
+- Ease and sustainability of maintenance
+ - The main maintainer is [@goccy](https://github.com/goccy), but we are also building a system to develop as a team with trusted developers
+ - Since it is written from scratch, the code is easy to read for Gophers
+- An API structure that allows the use of not only `Encoder`/`Decoder` but also `Tokenizer` and `Parser` functionalities.
+ - [lexer.Tokenize](https://pkg.go.dev/github.com/goccy/go-yaml@v1.15.4/lexer#Tokenize)
+ - [parser.Parse](https://pkg.go.dev/github.com/goccy/go-yaml@v1.15.4/parser#Parse)
+- Filtering, replacing, and merging YAML content using YAML Path
+- Reversible transformation without using the AST for YAML that includes Anchors, Aliases, and Comments
+- Customize the Marshal/Unmarshal behavior for primitive types and third-party library types ([RegisterCustomMarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#RegisterCustomMarshaler), [RegisterCustomUnmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#RegisterCustomUnmarshaler))
+- Respects `encoding/json` behavior
+ - Accept the `json` tag. Note that not all options from the `json` tag will have significance when parsing YAML documents. If both tags exist, `yaml` tag will take precedence.
+ - [json.Marshaler](https://pkg.go.dev/encoding/json#Marshaler) style [marshaler](https://pkg.go.dev/github.com/goccy/go-yaml#BytesMarshaler)
+ - [json.Unmarshaler](https://pkg.go.dev/encoding/json#Unmarshaler) style [unmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#BytesUnmarshaler)
+ - Options for using `MarshalJSON` and `UnmarshalJSON` ([UseJSONMarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#UseJSONMarshaler), [UseJSONUnmarshaler](https://pkg.go.dev/github.com/goccy/go-yaml#UseJSONUnmarshaler))
+- Pretty format for error notifications
+- Smart validation processing combined with [go-playground/validator](https://github.com/go-playground/validator)
+ - [example test code is here](https://github.com/goccy/go-yaml/blob/45889c98b0a0967240eb595a1bd6896e2f575106/testdata/validate_test.go#L12)
+- Allow referencing elements declared in another file via anchors
+
+# Users
+
+The repositories that use goccy/go-yaml are listed here.
+
+- https://github.com/goccy/go-yaml/wiki/Users
+
+The source data is [here](https://github.com/goccy/go-yaml/network/dependents).
+It is already being used in many repositories. Now it's your turn 😄
+
+# Playground
+
+The Playground visualizes how go-yaml processes YAML text. Use it to assist with your debugging or issue reporting.
+
+https://goccy.github.io/go-yaml
+
+# Installation
+
+```sh
+go get github.com/goccy/go-yaml
+```
+
+# Synopsis
+
+## 1. Simple Encode/Decode
+
+Has an interface like `go-yaml/yaml` using `reflect`
+
+```go
+var v struct {
+ A int
+ B string
+}
+v.A = 1
+v.B = "hello"
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes)) // "a: 1\nb: hello\n"
+```
+
+```go
+ yml := `
+%YAML 1.2
+---
+a: 1
+b: c
+`
+var v struct {
+ A int
+ B string
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+To control marshal/unmarshal behavior, you can use the `yaml` tag.
+
+```go
+ yml := `---
+foo: 1
+bar: c
+`
+var v struct {
+ A int `yaml:"foo"`
+ B string `yaml:"bar"`
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+For convenience, we also accept the `json` tag. Note that not all options from
+the `json` tag will have significance when parsing YAML documents. If both
+tags exist, `yaml` tag will take precedence.
+
+```go
+ yml := `---
+foo: 1
+bar: c
+`
+var v struct {
+ A int `json:"foo"`
+ B string `json:"bar"`
+}
+if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ //...
+}
+```
+
+For custom marshal/unmarshaling, implement either `Bytes` or `Interface` variant of marshaler/unmarshaler. The difference is that while `BytesMarshaler`/`BytesUnmarshaler` behaves like [`encoding/json`](https://pkg.go.dev/encoding/json) and `InterfaceMarshaler`/`InterfaceUnmarshaler` behaves like [`gopkg.in/yaml.v2`](https://pkg.go.dev/gopkg.in/yaml.v2).
+
+Semantically both are the same, but they differ in performance. Because indentation matters in YAML, you cannot simply accept a valid YAML fragment from a Marshaler, and expect it to work when it is attached to the parent container's serialized form. Therefore when we receive use the `BytesMarshaler`, which returns `[]byte`, we must decode it once to figure out how to make it work in the given context. If you use the `InterfaceMarshaler`, we can skip the decoding.
+
+If you are repeatedly marshaling complex objects, the latter is always better
+performance wise. But if you are, for example, just providing a choice between
+a config file format that is read only once, the former is probably easier to
+code.
+
+## 2. Reference elements declared in another file
+
+`testdata` directory contains `anchor.yml` file:
+
+```shell
+├── testdata
+ └── anchor.yml
+```
+
+And `anchor.yml` is defined as follows:
+
+```yaml
+a: &a
+ b: 1
+ c: hello
+```
+
+Then, if `yaml.ReferenceDirs("testdata")` option is passed to `yaml.Decoder`,
+ `Decoder` tries to find the anchor definition from YAML files the under `testdata` directory.
+
+```go
+buf := bytes.NewBufferString("a: *a\n")
+dec := yaml.NewDecoder(buf, yaml.ReferenceDirs("testdata"))
+var v struct {
+ A struct {
+ B int
+ C string
+ }
+}
+if err := dec.Decode(&v); err != nil {
+ //...
+}
+fmt.Printf("%+v\n", v) // {A:{B:1 C:hello}}
+```
+
+## 3. Encode with `Anchor` and `Alias`
+
+### 3.1. Explicitly declared `Anchor` name and `Alias` name
+
+If you want to use `anchor`, you can define it as a struct tag.
+If the value specified for an anchor is a pointer type and the same address as the pointer is found, the value is automatically set to alias.
+If an explicit alias name is specified, an error is raised if its value is different from the value specified in the anchor.
+
+```go
+type T struct {
+ A int
+ B string
+}
+var v struct {
+ C *T `yaml:"c,anchor=x"`
+ D *T `yaml:"d,alias=x"`
+}
+v.C = &T{A: 1, B: "hello"}
+v.D = v.C
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ panic(err)
+}
+fmt.Println(string(bytes))
+/*
+c: &x
+ a: 1
+ b: hello
+d: *x
+*/
+```
+
+### 3.2. Implicitly declared `Anchor` and `Alias` names
+
+If you do not explicitly declare the anchor name, the default behavior is to
+use the equivalent of `strings.ToLower($FieldName)` as the name of the anchor.
+If the value specified for an anchor is a pointer type and the same address as the pointer is found, the value is automatically set to alias.
+
+```go
+type T struct {
+ I int
+ S string
+}
+var v struct {
+ A *T `yaml:"a,anchor"`
+ B *T `yaml:"b,anchor"`
+ C *T `yaml:"c"`
+ D *T `yaml:"d"`
+}
+v.A = &T{I: 1, S: "hello"}
+v.B = &T{I: 2, S: "world"}
+v.C = v.A // C has same pointer address to A
+v.D = v.B // D has same pointer address to B
+bytes, err := yaml.Marshal(v)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes))
+/*
+a: &a
+ i: 1
+ s: hello
+b: &b
+ i: 2
+ s: world
+c: *a
+d: *b
+*/
+```
+
+### 3.3 MergeKey and Alias
+
+Merge key and alias ( `<<: *alias` ) can be used by embedding a structure with the `inline,alias` tag.
+
+```go
+type Person struct {
+ *Person `yaml:",omitempty,inline,alias"` // embed Person type for default value
+ Name string `yaml:",omitempty"`
+ Age int `yaml:",omitempty"`
+}
+defaultPerson := &Person{
+ Name: "John Smith",
+ Age: 20,
+}
+people := []*Person{
+ {
+ Person: defaultPerson, // assign default value
+ Name: "Ken", // override Name property
+ Age: 10, // override Age property
+ },
+ {
+ Person: defaultPerson, // assign default value only
+ },
+}
+var doc struct {
+ Default *Person `yaml:"default,anchor"`
+ People []*Person `yaml:"people"`
+}
+doc.Default = defaultPerson
+doc.People = people
+bytes, err := yaml.Marshal(doc)
+if err != nil {
+ //...
+}
+fmt.Println(string(bytes))
+/*
+default: &default
+ name: John Smith
+ age: 20
+people:
+- <<: *default
+ name: Ken
+ age: 10
+- <<: *default
+*/
+```
+
+## 4. Pretty Formatted Errors
+
+Error values produced during parsing have two extra features over regular
+error values.
+
+First, by default, they contain extra information on the location of the error
+from the source YAML document, to make it easier to find the error location.
+
+Second, the error messages can optionally be colorized.
+
+If you would like to control exactly how the output looks like, consider
+using `yaml.FormatError`, which accepts two boolean values to
+control turning these features on or off.
+
+ +
+## 5. Use YAMLPath
+
+```go
+yml := `
+store:
+ book:
+ - author: john
+ price: 10
+ - author: ken
+ price: 12
+ bicycle:
+ color: red
+ price: 19.95
+`
+path, err := yaml.PathString("$.store.book[*].author")
+if err != nil {
+ //...
+}
+var authors []string
+if err := path.Read(strings.NewReader(yml), &authors); err != nil {
+ //...
+}
+fmt.Println(authors)
+// [john ken]
+```
+
+### 5.1 Print customized error with YAML source code
+
+```go
+package main
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml"
+)
+
+func main() {
+ yml := `
+a: 1
+b: "hello"
+`
+ var v struct {
+ A int
+ B string
+ }
+ if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ panic(err)
+ }
+ if v.A != 2 {
+ // output error with YAML source
+ path, err := yaml.PathString("$.a")
+ if err != nil {
+ panic(err)
+ }
+ source, err := path.AnnotateSource([]byte(yml), true)
+ if err != nil {
+ panic(err)
+ }
+ fmt.Printf("a value expected 2 but actual %d:\n%s\n", v.A, string(source))
+ }
+}
+```
+
+output result is the following:
+
+
+
+## 5. Use YAMLPath
+
+```go
+yml := `
+store:
+ book:
+ - author: john
+ price: 10
+ - author: ken
+ price: 12
+ bicycle:
+ color: red
+ price: 19.95
+`
+path, err := yaml.PathString("$.store.book[*].author")
+if err != nil {
+ //...
+}
+var authors []string
+if err := path.Read(strings.NewReader(yml), &authors); err != nil {
+ //...
+}
+fmt.Println(authors)
+// [john ken]
+```
+
+### 5.1 Print customized error with YAML source code
+
+```go
+package main
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml"
+)
+
+func main() {
+ yml := `
+a: 1
+b: "hello"
+`
+ var v struct {
+ A int
+ B string
+ }
+ if err := yaml.Unmarshal([]byte(yml), &v); err != nil {
+ panic(err)
+ }
+ if v.A != 2 {
+ // output error with YAML source
+ path, err := yaml.PathString("$.a")
+ if err != nil {
+ panic(err)
+ }
+ source, err := path.AnnotateSource([]byte(yml), true)
+ if err != nil {
+ panic(err)
+ }
+ fmt.Printf("a value expected 2 but actual %d:\n%s\n", v.A, string(source))
+ }
+}
+```
+
+output result is the following:
+
+ +
+
+# Tools
+
+## ycat
+
+print yaml file with color
+
+
+
+
+# Tools
+
+## ycat
+
+print yaml file with color
+
+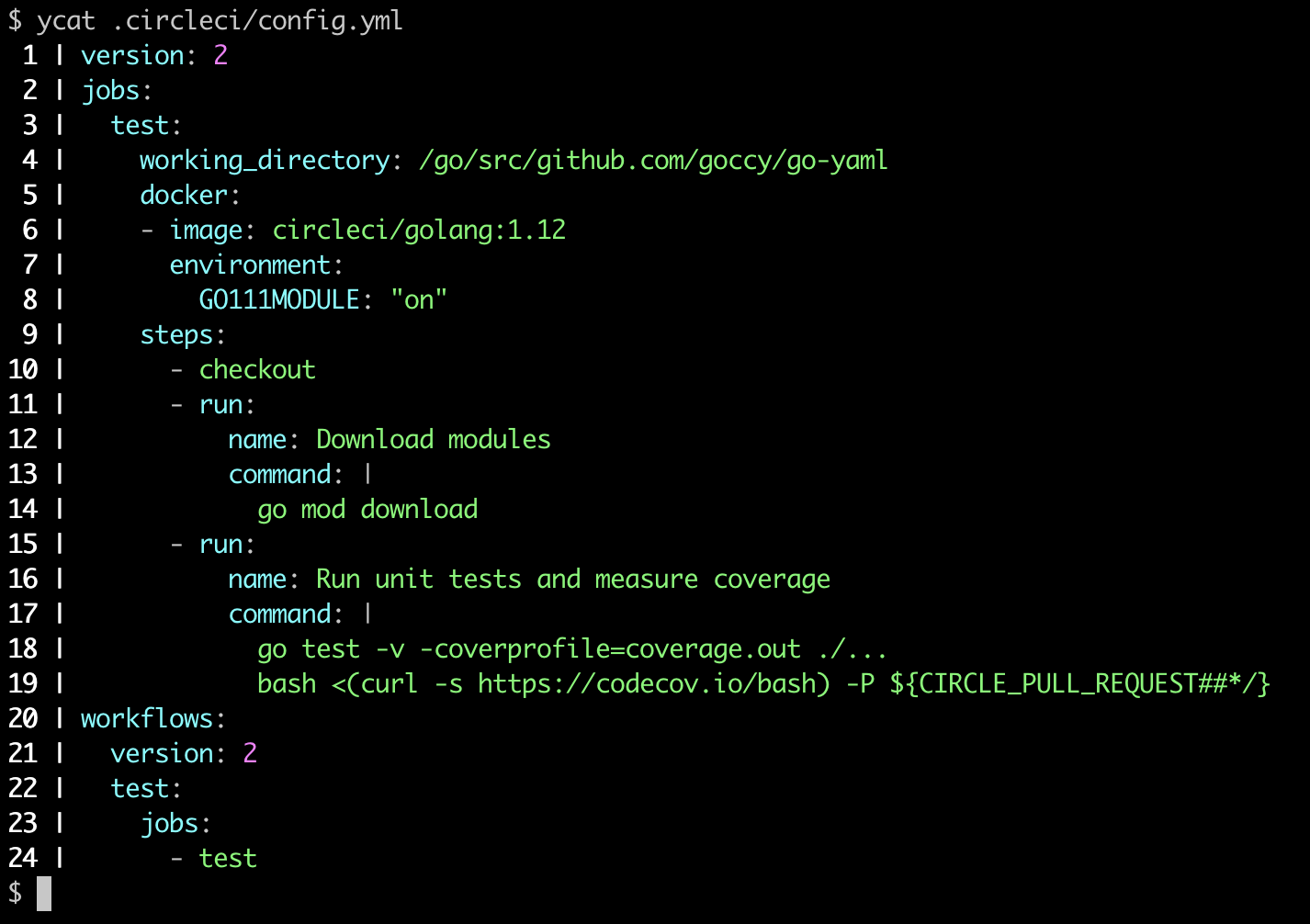 +
+### Installation
+
+```sh
+git clone https://github.com/goccy/go-yaml.git
+cd go-yaml/cmd/ycat && go install .
+```
+
+
+# For Developers
+
+> [!NOTE]
+> In this project, we manage such test code under the `testdata` directory to avoid adding dependencies on libraries that are only needed for testing to the top `go.mod` file. Therefore, if you want to add test cases that use 3rd party libraries, please add the test code to the `testdata` directory.
+
+# Looking for Sponsors
+
+I'm looking for sponsors this library. This library is being developed as a personal project in my spare time. If you want a quick response or problem resolution when using this library in your project, please register as a [sponsor](https://github.com/sponsors/goccy). I will cooperate as much as possible. Of course, this library is developed as an MIT license, so you can use it freely for free.
+
+# License
+
+MIT
diff --git a/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go b/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go
new file mode 100644
index 0000000..a8078a5
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go
@@ -0,0 +1,2381 @@
+package ast
+
+import (
+ "errors"
+ "fmt"
+ "io"
+ "math"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+var (
+ ErrInvalidTokenType = errors.New("invalid token type")
+ ErrInvalidAnchorName = errors.New("invalid anchor name")
+ ErrInvalidAliasName = errors.New("invalid alias name")
+)
+
+// NodeType type identifier of node
+type NodeType int
+
+const (
+ // UnknownNodeType type identifier for default
+ UnknownNodeType NodeType = iota
+ // DocumentType type identifier for document node
+ DocumentType
+ // NullType type identifier for null node
+ NullType
+ // BoolType type identifier for boolean node
+ BoolType
+ // IntegerType type identifier for integer node
+ IntegerType
+ // FloatType type identifier for float node
+ FloatType
+ // InfinityType type identifier for infinity node
+ InfinityType
+ // NanType type identifier for nan node
+ NanType
+ // StringType type identifier for string node
+ StringType
+ // MergeKeyType type identifier for merge key node
+ MergeKeyType
+ // LiteralType type identifier for literal node
+ LiteralType
+ // MappingType type identifier for mapping node
+ MappingType
+ // MappingKeyType type identifier for mapping key node
+ MappingKeyType
+ // MappingValueType type identifier for mapping value node
+ MappingValueType
+ // SequenceType type identifier for sequence node
+ SequenceType
+ // SequenceEntryType type identifier for sequence entry node
+ SequenceEntryType
+ // AnchorType type identifier for anchor node
+ AnchorType
+ // AliasType type identifier for alias node
+ AliasType
+ // DirectiveType type identifier for directive node
+ DirectiveType
+ // TagType type identifier for tag node
+ TagType
+ // CommentType type identifier for comment node
+ CommentType
+ // CommentGroupType type identifier for comment group node
+ CommentGroupType
+)
+
+// String node type identifier to text
+func (t NodeType) String() string {
+ switch t {
+ case UnknownNodeType:
+ return "UnknownNode"
+ case DocumentType:
+ return "Document"
+ case NullType:
+ return "Null"
+ case BoolType:
+ return "Bool"
+ case IntegerType:
+ return "Integer"
+ case FloatType:
+ return "Float"
+ case InfinityType:
+ return "Infinity"
+ case NanType:
+ return "Nan"
+ case StringType:
+ return "String"
+ case MergeKeyType:
+ return "MergeKey"
+ case LiteralType:
+ return "Literal"
+ case MappingType:
+ return "Mapping"
+ case MappingKeyType:
+ return "MappingKey"
+ case MappingValueType:
+ return "MappingValue"
+ case SequenceType:
+ return "Sequence"
+ case SequenceEntryType:
+ return "SequenceEntry"
+ case AnchorType:
+ return "Anchor"
+ case AliasType:
+ return "Alias"
+ case DirectiveType:
+ return "Directive"
+ case TagType:
+ return "Tag"
+ case CommentType:
+ return "Comment"
+ case CommentGroupType:
+ return "CommentGroup"
+ }
+ return ""
+}
+
+// String node type identifier to YAML Structure name
+// based on https://yaml.org/spec/1.2/spec.html
+func (t NodeType) YAMLName() string {
+ switch t {
+ case UnknownNodeType:
+ return "unknown"
+ case DocumentType:
+ return "document"
+ case NullType:
+ return "null"
+ case BoolType:
+ return "boolean"
+ case IntegerType:
+ return "int"
+ case FloatType:
+ return "float"
+ case InfinityType:
+ return "inf"
+ case NanType:
+ return "nan"
+ case StringType:
+ return "string"
+ case MergeKeyType:
+ return "merge key"
+ case LiteralType:
+ return "scalar"
+ case MappingType:
+ return "mapping"
+ case MappingKeyType:
+ return "key"
+ case MappingValueType:
+ return "value"
+ case SequenceType:
+ return "sequence"
+ case SequenceEntryType:
+ return "value"
+ case AnchorType:
+ return "anchor"
+ case AliasType:
+ return "alias"
+ case DirectiveType:
+ return "directive"
+ case TagType:
+ return "tag"
+ case CommentType:
+ return "comment"
+ case CommentGroupType:
+ return "comment"
+ }
+ return ""
+}
+
+// Node type of node
+type Node interface {
+ io.Reader
+ // String node to text
+ String() string
+ // GetToken returns token instance
+ GetToken() *token.Token
+ // Type returns type of node
+ Type() NodeType
+ // AddColumn add column number to child nodes recursively
+ AddColumn(int)
+ // SetComment set comment token to node
+ SetComment(*CommentGroupNode) error
+ // Comment returns comment token instance
+ GetComment() *CommentGroupNode
+ // GetPath returns YAMLPath for the current node
+ GetPath() string
+ // SetPath set YAMLPath for the current node
+ SetPath(string)
+ // MarshalYAML
+ MarshalYAML() ([]byte, error)
+ // already read length
+ readLen() int
+ // append read length
+ addReadLen(int)
+ // clean read length
+ clearLen()
+}
+
+// MapKeyNode type for map key node
+type MapKeyNode interface {
+ Node
+ IsMergeKey() bool
+ // String node to text without comment
+ stringWithoutComment() string
+}
+
+// ScalarNode type for scalar node
+type ScalarNode interface {
+ MapKeyNode
+ GetValue() interface{}
+}
+
+type BaseNode struct {
+ Path string
+ Comment *CommentGroupNode
+ read int
+}
+
+func addCommentString(base string, node *CommentGroupNode) string {
+ return fmt.Sprintf("%s %s", base, node.String())
+}
+
+func (n *BaseNode) readLen() int {
+ return n.read
+}
+
+func (n *BaseNode) clearLen() {
+ n.read = 0
+}
+
+func (n *BaseNode) addReadLen(len int) {
+ n.read += len
+}
+
+// GetPath returns YAMLPath for the current node.
+func (n *BaseNode) GetPath() string {
+ if n == nil {
+ return ""
+ }
+ return n.Path
+}
+
+// SetPath set YAMLPath for the current node.
+func (n *BaseNode) SetPath(path string) {
+ if n == nil {
+ return
+ }
+ n.Path = path
+}
+
+// GetComment returns comment token instance
+func (n *BaseNode) GetComment() *CommentGroupNode {
+ return n.Comment
+}
+
+// SetComment set comment token
+func (n *BaseNode) SetComment(node *CommentGroupNode) error {
+ n.Comment = node
+ return nil
+}
+
+func min(a, b int) int {
+ if a < b {
+ return a
+ }
+ return b
+}
+
+func readNode(p []byte, node Node) (int, error) {
+ s := node.String()
+ readLen := node.readLen()
+ remain := len(s) - readLen
+ if remain == 0 {
+ node.clearLen()
+ return 0, io.EOF
+ }
+ size := min(remain, len(p))
+ for idx, b := range []byte(s[readLen : readLen+size]) {
+ p[idx] = byte(b)
+ }
+ node.addReadLen(size)
+ return size, nil
+}
+
+func checkLineBreak(t *token.Token) bool {
+ if t.Prev != nil {
+ lbc := "\n"
+ prev := t.Prev
+ var adjustment int
+ // if the previous type is sequence entry use the previous type for that
+ if prev.Type == token.SequenceEntryType {
+ // as well as switching to previous type count any new lines in origin to account for:
+ // -
+ // b: c
+ adjustment = strings.Count(strings.TrimRight(t.Origin, lbc), lbc)
+ if prev.Prev != nil {
+ prev = prev.Prev
+ }
+ }
+ lineDiff := t.Position.Line - prev.Position.Line - 1
+ if lineDiff > 0 {
+ if prev.Type == token.StringType {
+ // Remove any line breaks included in multiline string
+ adjustment += strings.Count(strings.TrimRight(strings.TrimSpace(prev.Origin), lbc), lbc)
+ }
+ // Due to the way that comment parsing works its assumed that when a null value does not have new line in origin
+ // it was squashed therefore difference is ignored.
+ // foo:
+ // bar:
+ // # comment
+ // baz: 1
+ // becomes
+ // foo:
+ // bar: null # comment
+ //
+ // baz: 1
+ if prev.Type == token.NullType || prev.Type == token.ImplicitNullType {
+ return strings.Count(prev.Origin, lbc) > 0
+ }
+ if lineDiff-adjustment > 0 {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+// Null create node for null value
+func Null(tk *token.Token) *NullNode {
+ return &NullNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// Bool create node for boolean value
+func Bool(tk *token.Token) *BoolNode {
+ b, _ := strconv.ParseBool(tk.Value)
+ return &BoolNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: b,
+ }
+}
+
+// Integer create node for integer value
+func Integer(tk *token.Token) *IntegerNode {
+ var v any
+ if num := token.ToNumber(tk.Value); num != nil {
+ v = num.Value
+ }
+ return &IntegerNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: v,
+ }
+}
+
+// Float create node for float value
+func Float(tk *token.Token) *FloatNode {
+ var v float64
+ if num := token.ToNumber(tk.Value); num != nil && num.Type == token.NumberTypeFloat {
+ value, ok := num.Value.(float64)
+ if ok {
+ v = value
+ }
+ }
+ return &FloatNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: v,
+ }
+}
+
+// Infinity create node for .inf or -.inf value
+func Infinity(tk *token.Token) *InfinityNode {
+ node := &InfinityNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+ switch tk.Value {
+ case ".inf", ".Inf", ".INF":
+ node.Value = math.Inf(0)
+ case "-.inf", "-.Inf", "-.INF":
+ node.Value = math.Inf(-1)
+ }
+ return node
+}
+
+// Nan create node for .nan value
+func Nan(tk *token.Token) *NanNode {
+ return &NanNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// String create node for string value
+func String(tk *token.Token) *StringNode {
+ return &StringNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: tk.Value,
+ }
+}
+
+// Comment create node for comment
+func Comment(tk *token.Token) *CommentNode {
+ return &CommentNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+func CommentGroup(comments []*token.Token) *CommentGroupNode {
+ nodes := []*CommentNode{}
+ for _, comment := range comments {
+ nodes = append(nodes, Comment(comment))
+ }
+ return &CommentGroupNode{
+ BaseNode: &BaseNode{},
+ Comments: nodes,
+ }
+}
+
+// MergeKey create node for merge key ( << )
+func MergeKey(tk *token.Token) *MergeKeyNode {
+ return &MergeKeyNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// Mapping create node for map
+func Mapping(tk *token.Token, isFlowStyle bool, values ...*MappingValueNode) *MappingNode {
+ node := &MappingNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ IsFlowStyle: isFlowStyle,
+ Values: []*MappingValueNode{},
+ }
+ node.Values = append(node.Values, values...)
+ return node
+}
+
+// MappingValue create node for mapping value
+func MappingValue(tk *token.Token, key MapKeyNode, value Node) *MappingValueNode {
+ return &MappingValueNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ Key: key,
+ Value: value,
+ }
+}
+
+// MappingKey create node for map key ( '?' ).
+func MappingKey(tk *token.Token) *MappingKeyNode {
+ return &MappingKeyNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+// Sequence create node for sequence
+func Sequence(tk *token.Token, isFlowStyle bool) *SequenceNode {
+ return &SequenceNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ IsFlowStyle: isFlowStyle,
+ Values: []Node{},
+ }
+}
+
+func Anchor(tk *token.Token) *AnchorNode {
+ return &AnchorNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Alias(tk *token.Token) *AliasNode {
+ return &AliasNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Document(tk *token.Token, body Node) *DocumentNode {
+ return &DocumentNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ Body: body,
+ }
+}
+
+func Directive(tk *token.Token) *DirectiveNode {
+ return &DirectiveNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Literal(tk *token.Token) *LiteralNode {
+ return &LiteralNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Tag(tk *token.Token) *TagNode {
+ return &TagNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+// File contains all documents in YAML file
+type File struct {
+ Name string
+ Docs []*DocumentNode
+}
+
+// Read implements (io.Reader).Read
+func (f *File) Read(p []byte) (int, error) {
+ for _, doc := range f.Docs {
+ n, err := doc.Read(p)
+ if err == io.EOF {
+ continue
+ }
+ return n, nil
+ }
+ return 0, io.EOF
+}
+
+// String all documents to text
+func (f *File) String() string {
+ docs := []string{}
+ for _, doc := range f.Docs {
+ docs = append(docs, doc.String())
+ }
+ if len(docs) > 0 {
+ return strings.Join(docs, "\n") + "\n"
+ } else {
+ return ""
+ }
+}
+
+// DocumentNode type of Document
+type DocumentNode struct {
+ *BaseNode
+ Start *token.Token // position of DocumentHeader ( `---` )
+ End *token.Token // position of DocumentEnd ( `...` )
+ Body Node
+}
+
+// Read implements (io.Reader).Read
+func (d *DocumentNode) Read(p []byte) (int, error) {
+ return readNode(p, d)
+}
+
+// Type returns DocumentNodeType
+func (d *DocumentNode) Type() NodeType { return DocumentType }
+
+// GetToken returns token instance
+func (d *DocumentNode) GetToken() *token.Token {
+ return d.Body.GetToken()
+}
+
+// AddColumn add column number to child nodes recursively
+func (d *DocumentNode) AddColumn(col int) {
+ if d.Body != nil {
+ d.Body.AddColumn(col)
+ }
+}
+
+// String document to text
+func (d *DocumentNode) String() string {
+ doc := []string{}
+ if d.Start != nil {
+ doc = append(doc, d.Start.Value)
+ }
+ if d.Body != nil {
+ doc = append(doc, d.Body.String())
+ }
+ if d.End != nil {
+ doc = append(doc, d.End.Value)
+ }
+ return strings.Join(doc, "\n")
+}
+
+// MarshalYAML encodes to a YAML text
+func (d *DocumentNode) MarshalYAML() ([]byte, error) {
+ return []byte(d.String()), nil
+}
+
+// NullNode type of null node
+type NullNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *NullNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns NullType
+func (n *NullNode) Type() NodeType { return NullType }
+
+// GetToken returns token instance
+func (n *NullNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *NullNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns nil value
+func (n *NullNode) GetValue() interface{} {
+ return nil
+}
+
+// String returns `null` text
+func (n *NullNode) String() string {
+ if n.Token.Type == token.ImplicitNullType {
+ if n.Comment != nil {
+ return n.Comment.String()
+ }
+ return ""
+ }
+ if n.Comment != nil {
+ return addCommentString("null", n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *NullNode) stringWithoutComment() string {
+ return "null"
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *NullNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *NullNode) IsMergeKey() bool {
+ return false
+}
+
+// IntegerNode type of integer node
+type IntegerNode struct {
+ *BaseNode
+ Token *token.Token
+ Value interface{} // int64 or uint64 value
+}
+
+// Read implements (io.Reader).Read
+func (n *IntegerNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns IntegerType
+func (n *IntegerNode) Type() NodeType { return IntegerType }
+
+// GetToken returns token instance
+func (n *IntegerNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *IntegerNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns int64 value
+func (n *IntegerNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String int64 to text
+func (n *IntegerNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *IntegerNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *IntegerNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *IntegerNode) IsMergeKey() bool {
+ return false
+}
+
+// FloatNode type of float node
+type FloatNode struct {
+ *BaseNode
+ Token *token.Token
+ Precision int
+ Value float64
+}
+
+// Read implements (io.Reader).Read
+func (n *FloatNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns FloatType
+func (n *FloatNode) Type() NodeType { return FloatType }
+
+// GetToken returns token instance
+func (n *FloatNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *FloatNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns float64 value
+func (n *FloatNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String float64 to text
+func (n *FloatNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *FloatNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *FloatNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *FloatNode) IsMergeKey() bool {
+ return false
+}
+
+// StringNode type of string node
+type StringNode struct {
+ *BaseNode
+ Token *token.Token
+ Value string
+}
+
+// Read implements (io.Reader).Read
+func (n *StringNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns StringType
+func (n *StringNode) Type() NodeType { return StringType }
+
+// GetToken returns token instance
+func (n *StringNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *StringNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns string value
+func (n *StringNode) GetValue() interface{} {
+ return n.Value
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *StringNode) IsMergeKey() bool {
+ return false
+}
+
+// escapeSingleQuote escapes s to a single quoted scalar.
+// https://yaml.org/spec/1.2.2/#732-single-quoted-style
+func escapeSingleQuote(s string) string {
+ var sb strings.Builder
+ growLen := len(s) + // s includes also one ' from the doubled pair
+ 2 + // opening and closing '
+ strings.Count(s, "'") // ' added by ReplaceAll
+ sb.Grow(growLen)
+ sb.WriteString("'")
+ sb.WriteString(strings.ReplaceAll(s, "'", "''"))
+ sb.WriteString("'")
+ return sb.String()
+}
+
+// String string value to text with quote or literal header if required
+func (n *StringNode) String() string {
+ switch n.Token.Type {
+ case token.SingleQuoteType:
+ quoted := escapeSingleQuote(n.Value)
+ if n.Comment != nil {
+ return addCommentString(quoted, n.Comment)
+ }
+ return quoted
+ case token.DoubleQuoteType:
+ quoted := strconv.Quote(n.Value)
+ if n.Comment != nil {
+ return addCommentString(quoted, n.Comment)
+ }
+ return quoted
+ }
+
+ lbc := token.DetectLineBreakCharacter(n.Value)
+ if strings.Contains(n.Value, lbc) {
+ // This block assumes that the line breaks in this inside scalar content and the Outside scalar content are the same.
+ // It works mostly, but inconsistencies occur if line break characters are mixed.
+ header := token.LiteralBlockHeader(n.Value)
+ space := strings.Repeat(" ", n.Token.Position.Column-1)
+ indent := strings.Repeat(" ", n.Token.Position.IndentNum)
+ values := []string{}
+ for _, v := range strings.Split(n.Value, lbc) {
+ values = append(values, fmt.Sprintf("%s%s%s", space, indent, v))
+ }
+ block := strings.TrimSuffix(strings.TrimSuffix(strings.Join(values, lbc), fmt.Sprintf("%s%s%s", lbc, indent, space)), fmt.Sprintf("%s%s", indent, space))
+ return fmt.Sprintf("%s%s%s", header, lbc, block)
+ } else if len(n.Value) > 0 && (n.Value[0] == '{' || n.Value[0] == '[') {
+ return fmt.Sprintf(`'%s'`, n.Value)
+ }
+ if n.Comment != nil {
+ return addCommentString(n.Value, n.Comment)
+ }
+ return n.Value
+}
+
+func (n *StringNode) stringWithoutComment() string {
+ switch n.Token.Type {
+ case token.SingleQuoteType:
+ quoted := fmt.Sprintf(`'%s'`, n.Value)
+ return quoted
+ case token.DoubleQuoteType:
+ quoted := strconv.Quote(n.Value)
+ return quoted
+ }
+
+ lbc := token.DetectLineBreakCharacter(n.Value)
+ if strings.Contains(n.Value, lbc) {
+ // This block assumes that the line breaks in this inside scalar content and the Outside scalar content are the same.
+ // It works mostly, but inconsistencies occur if line break characters are mixed.
+ header := token.LiteralBlockHeader(n.Value)
+ space := strings.Repeat(" ", n.Token.Position.Column-1)
+ indent := strings.Repeat(" ", n.Token.Position.IndentNum)
+ values := []string{}
+ for _, v := range strings.Split(n.Value, lbc) {
+ values = append(values, fmt.Sprintf("%s%s%s", space, indent, v))
+ }
+ block := strings.TrimSuffix(strings.TrimSuffix(strings.Join(values, lbc), fmt.Sprintf("%s%s%s", lbc, indent, space)), fmt.Sprintf(" %s", space))
+ return fmt.Sprintf("%s%s%s", header, lbc, block)
+ } else if len(n.Value) > 0 && (n.Value[0] == '{' || n.Value[0] == '[') {
+ return fmt.Sprintf(`'%s'`, n.Value)
+ }
+ return n.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *StringNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// LiteralNode type of literal node
+type LiteralNode struct {
+ *BaseNode
+ Start *token.Token
+ Value *StringNode
+}
+
+// Read implements (io.Reader).Read
+func (n *LiteralNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns LiteralType
+func (n *LiteralNode) Type() NodeType { return LiteralType }
+
+// GetToken returns token instance
+func (n *LiteralNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *LiteralNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// GetValue returns string value
+func (n *LiteralNode) GetValue() interface{} {
+ return n.String()
+}
+
+// String literal to text
+func (n *LiteralNode) String() string {
+ origin := n.Value.GetToken().Origin
+ lit := strings.TrimRight(strings.TrimRight(origin, " "), "\n")
+ if n.Comment != nil {
+ return fmt.Sprintf("%s %s\n%s", n.Start.Value, n.Comment.String(), lit)
+ }
+ return fmt.Sprintf("%s\n%s", n.Start.Value, lit)
+}
+
+func (n *LiteralNode) stringWithoutComment() string {
+ return n.String()
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *LiteralNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *LiteralNode) IsMergeKey() bool {
+ return false
+}
+
+// MergeKeyNode type of merge key node
+type MergeKeyNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *MergeKeyNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MergeKeyType
+func (n *MergeKeyNode) Type() NodeType { return MergeKeyType }
+
+// GetToken returns token instance
+func (n *MergeKeyNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// GetValue returns '<<' value
+func (n *MergeKeyNode) GetValue() interface{} {
+ return n.Token.Value
+}
+
+// String returns '<<' value
+func (n *MergeKeyNode) String() string {
+ return n.stringWithoutComment()
+}
+
+func (n *MergeKeyNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MergeKeyNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MergeKeyNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *MergeKeyNode) IsMergeKey() bool {
+ return true
+}
+
+// BoolNode type of boolean node
+type BoolNode struct {
+ *BaseNode
+ Token *token.Token
+ Value bool
+}
+
+// Read implements (io.Reader).Read
+func (n *BoolNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns BoolType
+func (n *BoolNode) Type() NodeType { return BoolType }
+
+// GetToken returns token instance
+func (n *BoolNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *BoolNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns boolean value
+func (n *BoolNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String boolean to text
+func (n *BoolNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *BoolNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *BoolNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *BoolNode) IsMergeKey() bool {
+ return false
+}
+
+// InfinityNode type of infinity node
+type InfinityNode struct {
+ *BaseNode
+ Token *token.Token
+ Value float64
+}
+
+// Read implements (io.Reader).Read
+func (n *InfinityNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns InfinityType
+func (n *InfinityNode) Type() NodeType { return InfinityType }
+
+// GetToken returns token instance
+func (n *InfinityNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *InfinityNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns math.Inf(0) or math.Inf(-1)
+func (n *InfinityNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String infinity to text
+func (n *InfinityNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *InfinityNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *InfinityNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *InfinityNode) IsMergeKey() bool {
+ return false
+}
+
+// NanNode type of nan node
+type NanNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *NanNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns NanType
+func (n *NanNode) Type() NodeType { return NanType }
+
+// GetToken returns token instance
+func (n *NanNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *NanNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns math.NaN()
+func (n *NanNode) GetValue() interface{} {
+ return math.NaN()
+}
+
+// String returns .nan
+func (n *NanNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *NanNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *NanNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *NanNode) IsMergeKey() bool {
+ return false
+}
+
+// MapNode interface of MappingValueNode / MappingNode
+type MapNode interface {
+ MapRange() *MapNodeIter
+}
+
+// MapNodeIter is an iterator for ranging over a MapNode
+type MapNodeIter struct {
+ values []*MappingValueNode
+ idx int
+}
+
+const (
+ startRangeIndex = -1
+)
+
+// Next advances the map iterator and reports whether there is another entry.
+// It returns false when the iterator is exhausted.
+func (m *MapNodeIter) Next() bool {
+ m.idx++
+ next := m.idx < len(m.values)
+ return next
+}
+
+// Key returns the key of the iterator's current map node entry.
+func (m *MapNodeIter) Key() MapKeyNode {
+ return m.values[m.idx].Key
+}
+
+// Value returns the value of the iterator's current map node entry.
+func (m *MapNodeIter) Value() Node {
+ return m.values[m.idx].Value
+}
+
+// KeyValue returns the MappingValueNode of the iterator's current map node entry.
+func (m *MapNodeIter) KeyValue() *MappingValueNode {
+ return m.values[m.idx]
+}
+
+// MappingNode type of mapping node
+type MappingNode struct {
+ *BaseNode
+ Start *token.Token
+ End *token.Token
+ IsFlowStyle bool
+ Values []*MappingValueNode
+ FootComment *CommentGroupNode
+}
+
+func (n *MappingNode) startPos() *token.Position {
+ if len(n.Values) == 0 {
+ return n.Start.Position
+ }
+ return n.Values[0].Key.GetToken().Position
+}
+
+// Merge merge key/value of map.
+func (n *MappingNode) Merge(target *MappingNode) {
+ keyToMapValueMap := map[string]*MappingValueNode{}
+ for _, value := range n.Values {
+ key := value.Key.String()
+ keyToMapValueMap[key] = value
+ }
+ column := n.startPos().Column - target.startPos().Column
+ target.AddColumn(column)
+ for _, value := range target.Values {
+ mapValue, exists := keyToMapValueMap[value.Key.String()]
+ if exists {
+ mapValue.Value = value.Value
+ } else {
+ n.Values = append(n.Values, value)
+ }
+ }
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *MappingNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ for _, value := range n.Values {
+ value.SetIsFlowStyle(isFlow)
+ }
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingType
+func (n *MappingNode) Type() NodeType { return MappingType }
+
+// GetToken returns token instance
+func (n *MappingNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ n.End.AddColumn(col)
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+func (n *MappingNode) flowStyleString(commentMode bool) string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, strings.TrimLeft(value.String(), " "))
+ }
+ mapText := fmt.Sprintf("{%s}", strings.Join(values, ", "))
+ if commentMode && n.Comment != nil {
+ return addCommentString(mapText, n.Comment)
+ }
+ return mapText
+}
+
+func (n *MappingNode) blockStyleString(commentMode bool) string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, value.String())
+ }
+ mapText := strings.Join(values, "\n")
+ if commentMode && n.Comment != nil {
+ value := values[0]
+ var spaceNum int
+ for i := 0; i < len(value); i++ {
+ if value[i] != ' ' {
+ break
+ }
+ spaceNum++
+ }
+ comment := n.Comment.StringWithSpace(spaceNum)
+ return fmt.Sprintf("%s\n%s", comment, mapText)
+ }
+ return mapText
+}
+
+// String mapping values to text
+func (n *MappingNode) String() string {
+ if len(n.Values) == 0 {
+ if n.Comment != nil {
+ return addCommentString("{}", n.Comment)
+ }
+ return "{}"
+ }
+
+ commentMode := true
+ if n.IsFlowStyle || len(n.Values) == 0 {
+ return n.flowStyleString(commentMode)
+ }
+ return n.blockStyleString(commentMode)
+}
+
+// MapRange implements MapNode protocol
+func (n *MappingNode) MapRange() *MapNodeIter {
+ return &MapNodeIter{
+ idx: startRangeIndex,
+ values: n.Values,
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// MappingKeyNode type of tag node
+type MappingKeyNode struct {
+ *BaseNode
+ Start *token.Token
+ Value Node
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingKeyNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingKeyType
+func (n *MappingKeyNode) Type() NodeType { return MappingKeyType }
+
+// GetToken returns token instance
+func (n *MappingKeyNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingKeyNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String tag to text
+func (n *MappingKeyNode) String() string {
+ return n.stringWithoutComment()
+}
+
+func (n *MappingKeyNode) stringWithoutComment() string {
+ return fmt.Sprintf("%s %s", n.Start.Value, n.Value.String())
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingKeyNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *MappingKeyNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+// MappingValueNode type of mapping value
+type MappingValueNode struct {
+ *BaseNode
+ Start *token.Token // delimiter token ':'.
+ CollectEntry *token.Token // collect entry token ','.
+ Key MapKeyNode
+ Value Node
+ FootComment *CommentGroupNode
+ IsFlowStyle bool
+}
+
+// Replace replace value node.
+func (n *MappingValueNode) Replace(value Node) error {
+ column := n.Value.GetToken().Position.Column - value.GetToken().Position.Column
+ value.AddColumn(column)
+ n.Value = value
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingValueNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingValueType
+func (n *MappingValueNode) Type() NodeType { return MappingValueType }
+
+// GetToken returns token instance
+func (n *MappingValueNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingValueNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Key != nil {
+ n.Key.AddColumn(col)
+ }
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *MappingValueNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ switch value := n.Value.(type) {
+ case *MappingNode:
+ value.SetIsFlowStyle(isFlow)
+ case *MappingValueNode:
+ value.SetIsFlowStyle(isFlow)
+ case *SequenceNode:
+ value.SetIsFlowStyle(isFlow)
+ }
+}
+
+// String mapping value to text
+func (n *MappingValueNode) String() string {
+ var text string
+ if n.Comment != nil {
+ text = fmt.Sprintf(
+ "%s\n%s",
+ n.Comment.StringWithSpace(n.Key.GetToken().Position.Column-1),
+ n.toString(),
+ )
+ } else {
+ text = n.toString()
+ }
+ if n.FootComment != nil {
+ text += fmt.Sprintf("\n%s", n.FootComment.StringWithSpace(n.Key.GetToken().Position.Column-1))
+ }
+ return text
+}
+
+func (n *MappingValueNode) toString() string {
+ space := strings.Repeat(" ", n.Key.GetToken().Position.Column-1)
+ if checkLineBreak(n.Key.GetToken()) {
+ space = fmt.Sprintf("%s%s", "\n", space)
+ }
+ keyIndentLevel := n.Key.GetToken().Position.IndentLevel
+ valueIndentLevel := n.Value.GetToken().Position.IndentLevel
+ keyComment := n.Key.GetComment()
+ if _, ok := n.Value.(ScalarNode); ok {
+ value := n.Value.String()
+ if value == "" {
+ // implicit null value.
+ return fmt.Sprintf("%s%s:", space, n.Key.String())
+ }
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), value)
+ } else if keyIndentLevel < valueIndentLevel && !n.IsFlowStyle {
+ valueStr := n.Value.String()
+ // For flow-style values indented on the next line, we need to add the proper indentation
+ if m, ok := n.Value.(*MappingNode); ok && m.IsFlowStyle {
+ valueIndent := strings.Repeat(" ", n.Value.GetToken().Position.Column-1)
+ valueStr = valueIndent + valueStr
+ } else if s, ok := n.Value.(*SequenceNode); ok && s.IsFlowStyle {
+ valueIndent := strings.Repeat(" ", n.Value.GetToken().Position.Column-1)
+ valueStr = valueIndent + valueStr
+ }
+ if keyComment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s\n%s",
+ space,
+ n.Key.stringWithoutComment(),
+ keyComment.String(),
+ valueStr,
+ )
+ }
+ return fmt.Sprintf("%s%s:\n%s", space, n.Key.String(), valueStr)
+ } else if m, ok := n.Value.(*MappingNode); ok && (m.IsFlowStyle || len(m.Values) == 0) {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if s, ok := n.Value.(*SequenceNode); ok && (s.IsFlowStyle || len(s.Values) == 0) {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*AnchorNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*AliasNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*TagNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ }
+
+ if keyComment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s\n%s",
+ space,
+ n.Key.stringWithoutComment(),
+ keyComment.String(),
+ n.Value.String(),
+ )
+ }
+ if m, ok := n.Value.(*MappingNode); ok && m.Comment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s",
+ space,
+ n.Key.String(),
+ strings.TrimLeft(n.Value.String(), " "),
+ )
+ }
+ return fmt.Sprintf("%s%s:\n%s", space, n.Key.String(), n.Value.String())
+}
+
+// MapRange implements MapNode protocol
+func (n *MappingValueNode) MapRange() *MapNodeIter {
+ return &MapNodeIter{
+ idx: startRangeIndex,
+ values: []*MappingValueNode{n},
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingValueNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// ArrayNode interface of SequenceNode
+type ArrayNode interface {
+ ArrayRange() *ArrayNodeIter
+}
+
+// ArrayNodeIter is an iterator for ranging over a ArrayNode
+type ArrayNodeIter struct {
+ values []Node
+ idx int
+}
+
+// Next advances the array iterator and reports whether there is another entry.
+// It returns false when the iterator is exhausted.
+func (m *ArrayNodeIter) Next() bool {
+ m.idx++
+ next := m.idx < len(m.values)
+ return next
+}
+
+// Value returns the value of the iterator's current array entry.
+func (m *ArrayNodeIter) Value() Node {
+ return m.values[m.idx]
+}
+
+// Len returns length of array
+func (m *ArrayNodeIter) Len() int {
+ return len(m.values)
+}
+
+// SequenceNode type of sequence node
+type SequenceNode struct {
+ *BaseNode
+ Start *token.Token
+ End *token.Token
+ IsFlowStyle bool
+ Values []Node
+ ValueHeadComments []*CommentGroupNode
+ Entries []*SequenceEntryNode
+ FootComment *CommentGroupNode
+}
+
+// Replace replace value node.
+func (n *SequenceNode) Replace(idx int, value Node) error {
+ if len(n.Values) <= idx {
+ return fmt.Errorf(
+ "invalid index for sequence: sequence length is %d, but specified %d index",
+ len(n.Values), idx,
+ )
+ }
+ column := n.Values[idx].GetToken().Position.Column - value.GetToken().Position.Column
+ value.AddColumn(column)
+ n.Values[idx] = value
+ return nil
+}
+
+// Merge merge sequence value.
+func (n *SequenceNode) Merge(target *SequenceNode) {
+ column := n.Start.Position.Column - target.Start.Position.Column
+ target.AddColumn(column)
+ n.Values = append(n.Values, target.Values...)
+ if len(target.ValueHeadComments) == 0 {
+ n.ValueHeadComments = append(n.ValueHeadComments, make([]*CommentGroupNode, len(target.Values))...)
+ return
+ }
+ n.ValueHeadComments = append(n.ValueHeadComments, target.ValueHeadComments...)
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *SequenceNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ for _, value := range n.Values {
+ switch value := value.(type) {
+ case *MappingNode:
+ value.SetIsFlowStyle(isFlow)
+ case *MappingValueNode:
+ value.SetIsFlowStyle(isFlow)
+ case *SequenceNode:
+ value.SetIsFlowStyle(isFlow)
+ }
+ }
+}
+
+// Read implements (io.Reader).Read
+func (n *SequenceNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns SequenceType
+func (n *SequenceNode) Type() NodeType { return SequenceType }
+
+// GetToken returns token instance
+func (n *SequenceNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *SequenceNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ n.End.AddColumn(col)
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+func (n *SequenceNode) flowStyleString() string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, value.String())
+ }
+ seqText := fmt.Sprintf("[%s]", strings.Join(values, ", "))
+ if n.Comment != nil {
+ return addCommentString(seqText, n.Comment)
+ }
+ return seqText
+}
+
+func (n *SequenceNode) blockStyleString() string {
+ space := strings.Repeat(" ", n.Start.Position.Column-1)
+ values := []string{}
+ if n.Comment != nil {
+ values = append(values, n.Comment.StringWithSpace(n.Start.Position.Column-1))
+ }
+
+ for idx, value := range n.Values {
+ if value == nil {
+ continue
+ }
+ valueStr := value.String()
+ newLinePrefix := ""
+ if strings.HasPrefix(valueStr, "\n") {
+ valueStr = valueStr[1:]
+ newLinePrefix = "\n"
+ }
+ splittedValues := strings.Split(valueStr, "\n")
+ trimmedFirstValue := strings.TrimLeft(splittedValues[0], " ")
+ diffLength := len(splittedValues[0]) - len(trimmedFirstValue)
+ if len(splittedValues) > 1 && value.Type() == StringType || value.Type() == LiteralType {
+ // If multi-line string, the space characters for indent have already been added, so delete them.
+ prefix := space + " "
+ for i := 1; i < len(splittedValues); i++ {
+ splittedValues[i] = strings.TrimPrefix(splittedValues[i], prefix)
+ }
+ }
+ newValues := []string{trimmedFirstValue}
+ for i := 1; i < len(splittedValues); i++ {
+ if len(splittedValues[i]) <= diffLength {
+ // this line is \n or white space only
+ newValues = append(newValues, "")
+ continue
+ }
+ trimmed := splittedValues[i][diffLength:]
+ newValues = append(newValues, fmt.Sprintf("%s %s", space, trimmed))
+ }
+ newValue := strings.Join(newValues, "\n")
+ if len(n.ValueHeadComments) == len(n.Values) && n.ValueHeadComments[idx] != nil {
+ values = append(values, fmt.Sprintf("%s%s", newLinePrefix, n.ValueHeadComments[idx].StringWithSpace(n.Start.Position.Column-1)))
+ newLinePrefix = ""
+ }
+ values = append(values, fmt.Sprintf("%s%s- %s", newLinePrefix, space, newValue))
+ }
+ if n.FootComment != nil {
+ values = append(values, n.FootComment.StringWithSpace(n.Start.Position.Column-1))
+ }
+ return strings.Join(values, "\n")
+}
+
+// String sequence to text
+func (n *SequenceNode) String() string {
+ if n.IsFlowStyle || len(n.Values) == 0 {
+ return n.flowStyleString()
+ }
+ return n.blockStyleString()
+}
+
+// ArrayRange implements ArrayNode protocol
+func (n *SequenceNode) ArrayRange() *ArrayNodeIter {
+ return &ArrayNodeIter{
+ idx: startRangeIndex,
+ values: n.Values,
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *SequenceNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// SequenceEntryNode is the sequence entry.
+type SequenceEntryNode struct {
+ *BaseNode
+ HeadComment *CommentGroupNode // head comment.
+ LineComment *CommentGroupNode // line comment e.g.) - # comment.
+ Start *token.Token // entry token.
+ Value Node // value node.
+}
+
+// String node to text
+func (n *SequenceEntryNode) String() string {
+ return "" // TODO
+}
+
+// GetToken returns token instance
+func (n *SequenceEntryNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// Type returns type of node
+func (n *SequenceEntryNode) Type() NodeType {
+ return SequenceEntryType
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *SequenceEntryNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+}
+
+// SetComment set line comment.
+func (n *SequenceEntryNode) SetComment(cm *CommentGroupNode) error {
+ n.LineComment = cm
+ return nil
+}
+
+// Comment returns comment token instance
+func (n *SequenceEntryNode) GetComment() *CommentGroupNode {
+ return n.LineComment
+}
+
+// MarshalYAML
+func (n *SequenceEntryNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+func (n *SequenceEntryNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// SequenceEntry creates SequenceEntryNode instance.
+func SequenceEntry(start *token.Token, value Node, headComment *CommentGroupNode) *SequenceEntryNode {
+ return &SequenceEntryNode{
+ BaseNode: &BaseNode{},
+ HeadComment: headComment,
+ Start: start,
+ Value: value,
+ }
+}
+
+// SequenceMergeValue creates SequenceMergeValueNode instance.
+func SequenceMergeValue(values ...MapNode) *SequenceMergeValueNode {
+ return &SequenceMergeValueNode{
+ values: values,
+ }
+}
+
+// SequenceMergeValueNode is used to convert the Sequence node specified for the merge key into a MapNode format.
+type SequenceMergeValueNode struct {
+ values []MapNode
+}
+
+// MapRange returns MapNodeIter instance.
+func (n *SequenceMergeValueNode) MapRange() *MapNodeIter {
+ ret := &MapNodeIter{idx: startRangeIndex}
+ for _, value := range n.values {
+ iter := value.MapRange()
+ ret.values = append(ret.values, iter.values...)
+ }
+ return ret
+}
+
+// AnchorNode type of anchor node
+type AnchorNode struct {
+ *BaseNode
+ Start *token.Token
+ Name Node
+ Value Node
+}
+
+func (n *AnchorNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+func (n *AnchorNode) SetName(name string) error {
+ if n.Name == nil {
+ return ErrInvalidAnchorName
+ }
+ s, ok := n.Name.(*StringNode)
+ if !ok {
+ return ErrInvalidAnchorName
+ }
+ s.Value = name
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *AnchorNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns AnchorType
+func (n *AnchorNode) Type() NodeType { return AnchorType }
+
+// GetToken returns token instance
+func (n *AnchorNode) GetToken() *token.Token {
+ return n.Start
+}
+
+func (n *AnchorNode) GetValue() any {
+ return n.Value.GetToken().Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *AnchorNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Name != nil {
+ n.Name.AddColumn(col)
+ }
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String anchor to text
+func (n *AnchorNode) String() string {
+ anchor := "&" + n.Name.String()
+ value := n.Value.String()
+ if s, ok := n.Value.(*SequenceNode); ok && !s.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", anchor, value)
+ } else if m, ok := n.Value.(*MappingNode); ok && !m.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", anchor, value)
+ }
+ if value == "" {
+ // implicit null value.
+ return anchor
+ }
+ return fmt.Sprintf("%s %s", anchor, value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *AnchorNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *AnchorNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+// AliasNode type of alias node
+type AliasNode struct {
+ *BaseNode
+ Start *token.Token
+ Value Node
+}
+
+func (n *AliasNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+func (n *AliasNode) SetName(name string) error {
+ if n.Value == nil {
+ return ErrInvalidAliasName
+ }
+ s, ok := n.Value.(*StringNode)
+ if !ok {
+ return ErrInvalidAliasName
+ }
+ s.Value = name
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *AliasNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns AliasType
+func (n *AliasNode) Type() NodeType { return AliasType }
+
+// GetToken returns token instance
+func (n *AliasNode) GetToken() *token.Token {
+ return n.Start
+}
+
+func (n *AliasNode) GetValue() any {
+ return n.Value.GetToken().Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *AliasNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String alias to text
+func (n *AliasNode) String() string {
+ return fmt.Sprintf("*%s", n.Value.String())
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *AliasNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *AliasNode) IsMergeKey() bool {
+ return false
+}
+
+// DirectiveNode type of directive node
+type DirectiveNode struct {
+ *BaseNode
+ // Start is '%' token.
+ Start *token.Token
+ // Name is directive name e.g.) "YAML" or "TAG".
+ Name Node
+ // Values is directive values e.g.) "1.2" or "!!" and "tag:clarkevans.com,2002:app/".
+ Values []Node
+}
+
+// Read implements (io.Reader).Read
+func (n *DirectiveNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns DirectiveType
+func (n *DirectiveNode) Type() NodeType { return DirectiveType }
+
+// GetToken returns token instance
+func (n *DirectiveNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *DirectiveNode) AddColumn(col int) {
+ if n.Name != nil {
+ n.Name.AddColumn(col)
+ }
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+// String directive to text
+func (n *DirectiveNode) String() string {
+ values := make([]string, 0, len(n.Values))
+ for _, val := range n.Values {
+ values = append(values, val.String())
+ }
+ return strings.Join(append([]string{"%" + n.Name.String()}, values...), " ")
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *DirectiveNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// TagNode type of tag node
+type TagNode struct {
+ *BaseNode
+ Directive *DirectiveNode
+ Start *token.Token
+ Value Node
+}
+
+func (n *TagNode) GetValue() any {
+ scalar, ok := n.Value.(ScalarNode)
+ if !ok {
+ return nil
+ }
+ return scalar.GetValue()
+}
+
+func (n *TagNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+// Read implements (io.Reader).Read
+func (n *TagNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *TagNode) Type() NodeType { return TagType }
+
+// GetToken returns token instance
+func (n *TagNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *TagNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String tag to text
+func (n *TagNode) String() string {
+ value := n.Value.String()
+ if s, ok := n.Value.(*SequenceNode); ok && !s.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", n.Start.Value, value)
+ } else if m, ok := n.Value.(*MappingNode); ok && !m.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", n.Start.Value, value)
+ }
+
+ return fmt.Sprintf("%s %s", n.Start.Value, value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *TagNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *TagNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+func (n *TagNode) ArrayRange() *ArrayNodeIter {
+ arr, ok := n.Value.(ArrayNode)
+ if !ok {
+ return nil
+ }
+ return arr.ArrayRange()
+}
+
+// CommentNode type of comment node
+type CommentNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *CommentNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *CommentNode) Type() NodeType { return CommentType }
+
+// GetToken returns token instance
+func (n *CommentNode) GetToken() *token.Token { return n.Token }
+
+// AddColumn add column number to child nodes recursively
+func (n *CommentNode) AddColumn(col int) {
+ if n.Token == nil {
+ return
+ }
+ n.Token.AddColumn(col)
+}
+
+// String comment to text
+func (n *CommentNode) String() string {
+ return fmt.Sprintf("#%s", n.Token.Value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *CommentNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// CommentGroupNode type of comment node
+type CommentGroupNode struct {
+ *BaseNode
+ Comments []*CommentNode
+}
+
+// Read implements (io.Reader).Read
+func (n *CommentGroupNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *CommentGroupNode) Type() NodeType { return CommentType }
+
+// GetToken returns token instance
+func (n *CommentGroupNode) GetToken() *token.Token {
+ if len(n.Comments) > 0 {
+ return n.Comments[0].Token
+ }
+ return nil
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *CommentGroupNode) AddColumn(col int) {
+ for _, comment := range n.Comments {
+ comment.AddColumn(col)
+ }
+}
+
+// String comment to text
+func (n *CommentGroupNode) String() string {
+ values := []string{}
+ for _, comment := range n.Comments {
+ values = append(values, comment.String())
+ }
+ return strings.Join(values, "\n")
+}
+
+func (n *CommentGroupNode) StringWithSpace(col int) string {
+ values := []string{}
+ space := strings.Repeat(" ", col)
+ for _, comment := range n.Comments {
+ space := space
+ if checkLineBreak(comment.Token) {
+ space = fmt.Sprintf("%s%s", "\n", space)
+ }
+ values = append(values, space+comment.String())
+ }
+ return strings.Join(values, "\n")
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *CommentGroupNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// Visitor has Visit method that is invokded for each node encountered by Walk.
+// If the result visitor w is not nil, Walk visits each of the children of node with the visitor w,
+// followed by a call of w.Visit(nil).
+type Visitor interface {
+ Visit(Node) Visitor
+}
+
+// Walk traverses an AST in depth-first order: It starts by calling v.Visit(node); node must not be nil.
+// If the visitor w returned by v.Visit(node) is not nil,
+// Walk is invoked recursively with visitor w for each of the non-nil children of node,
+// followed by a call of w.Visit(nil).
+func Walk(v Visitor, node Node) {
+ if v = v.Visit(node); v == nil {
+ return
+ }
+
+ switch n := node.(type) {
+ case *CommentNode:
+ case *NullNode:
+ walkComment(v, n.BaseNode)
+ case *IntegerNode:
+ walkComment(v, n.BaseNode)
+ case *FloatNode:
+ walkComment(v, n.BaseNode)
+ case *StringNode:
+ walkComment(v, n.BaseNode)
+ case *MergeKeyNode:
+ walkComment(v, n.BaseNode)
+ case *BoolNode:
+ walkComment(v, n.BaseNode)
+ case *InfinityNode:
+ walkComment(v, n.BaseNode)
+ case *NanNode:
+ walkComment(v, n.BaseNode)
+ case *LiteralNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *DirectiveNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Name)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *TagNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *DocumentNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Body)
+ case *MappingNode:
+ walkComment(v, n.BaseNode)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *MappingKeyNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *MappingValueNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Key)
+ Walk(v, n.Value)
+ case *SequenceNode:
+ walkComment(v, n.BaseNode)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *AnchorNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Name)
+ Walk(v, n.Value)
+ case *AliasNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ }
+}
+
+func walkComment(v Visitor, base *BaseNode) {
+ if base == nil {
+ return
+ }
+ if base.Comment == nil {
+ return
+ }
+ Walk(v, base.Comment)
+}
+
+type filterWalker struct {
+ typ NodeType
+ results []Node
+}
+
+func (v *filterWalker) Visit(n Node) Visitor {
+ if v.typ == n.Type() {
+ v.results = append(v.results, n)
+ }
+ return v
+}
+
+type parentFinder struct {
+ target Node
+}
+
+func (f *parentFinder) walk(parent, node Node) Node {
+ if f.target == node {
+ return parent
+ }
+ switch n := node.(type) {
+ case *CommentNode:
+ return nil
+ case *NullNode:
+ return nil
+ case *IntegerNode:
+ return nil
+ case *FloatNode:
+ return nil
+ case *StringNode:
+ return nil
+ case *MergeKeyNode:
+ return nil
+ case *BoolNode:
+ return nil
+ case *InfinityNode:
+ return nil
+ case *NanNode:
+ return nil
+ case *LiteralNode:
+ return f.walk(node, n.Value)
+ case *DirectiveNode:
+ if found := f.walk(node, n.Name); found != nil {
+ return found
+ }
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *TagNode:
+ return f.walk(node, n.Value)
+ case *DocumentNode:
+ return f.walk(node, n.Body)
+ case *MappingNode:
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *MappingKeyNode:
+ return f.walk(node, n.Value)
+ case *MappingValueNode:
+ if found := f.walk(node, n.Key); found != nil {
+ return found
+ }
+ return f.walk(node, n.Value)
+ case *SequenceNode:
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *AnchorNode:
+ if found := f.walk(node, n.Name); found != nil {
+ return found
+ }
+ return f.walk(node, n.Value)
+ case *AliasNode:
+ return f.walk(node, n.Value)
+ }
+ return nil
+}
+
+// Parent get parent node from child node.
+func Parent(root, child Node) Node {
+ finder := &parentFinder{target: child}
+ return finder.walk(root, root)
+}
+
+// Filter returns a list of nodes that match the given type.
+func Filter(typ NodeType, node Node) []Node {
+ walker := &filterWalker{typ: typ}
+ Walk(walker, node)
+ return walker.results
+}
+
+// FilterFile returns a list of nodes that match the given type.
+func FilterFile(typ NodeType, file *File) []Node {
+ results := []Node{}
+ for _, doc := range file.Docs {
+ walker := &filterWalker{typ: typ}
+ Walk(walker, doc)
+ results = append(results, walker.results...)
+ }
+ return results
+}
+
+type ErrInvalidMergeType struct {
+ dst Node
+ src Node
+}
+
+func (e *ErrInvalidMergeType) Error() string {
+ return fmt.Sprintf("cannot merge %s into %s", e.src.Type(), e.dst.Type())
+}
+
+// Merge merge document, map, sequence node.
+func Merge(dst Node, src Node) error {
+ if doc, ok := src.(*DocumentNode); ok {
+ src = doc.Body
+ }
+ err := &ErrInvalidMergeType{dst: dst, src: src}
+ switch dst.Type() {
+ case DocumentType:
+ node, _ := dst.(*DocumentNode)
+ return Merge(node.Body, src)
+ case MappingType:
+ node, _ := dst.(*MappingNode)
+ target, ok := src.(*MappingNode)
+ if !ok {
+ return err
+ }
+ node.Merge(target)
+ return nil
+ case SequenceType:
+ node, _ := dst.(*SequenceNode)
+ target, ok := src.(*SequenceNode)
+ if !ok {
+ return err
+ }
+ node.Merge(target)
+ return nil
+ }
+ return err
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/context.go b/sesh/vendor/github.com/goccy/go-yaml/context.go
new file mode 100644
index 0000000..133f05e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/context.go
@@ -0,0 +1,37 @@
+package yaml
+
+import "context"
+
+type (
+ ctxMergeKey struct{}
+ ctxAnchorKey struct{}
+)
+
+func withMerge(ctx context.Context) context.Context {
+ return context.WithValue(ctx, ctxMergeKey{}, true)
+}
+
+func isMerge(ctx context.Context) bool {
+ v, ok := ctx.Value(ctxMergeKey{}).(bool)
+ if !ok {
+ return false
+ }
+ return v
+}
+
+func withAnchor(ctx context.Context, name string) context.Context {
+ anchorMap := getAnchorMap(ctx)
+ if anchorMap == nil {
+ anchorMap = make(map[string]struct{})
+ }
+ anchorMap[name] = struct{}{}
+ return context.WithValue(ctx, ctxAnchorKey{}, anchorMap)
+}
+
+func getAnchorMap(ctx context.Context) map[string]struct{} {
+ v, ok := ctx.Value(ctxAnchorKey{}).(map[string]struct{})
+ if !ok {
+ return nil
+ }
+ return v
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/decode.go b/sesh/vendor/github.com/goccy/go-yaml/decode.go
new file mode 100644
index 0000000..e9b3baa
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/decode.go
@@ -0,0 +1,2037 @@
+package yaml
+
+import (
+ "bytes"
+ "context"
+ "encoding"
+ "encoding/base64"
+ "fmt"
+ "io"
+ "maps"
+ "math"
+ "os"
+ "path/filepath"
+ "reflect"
+ "sort"
+ "strconv"
+ "strings"
+ "time"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/internal/format"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Decoder reads and decodes YAML values from an input stream.
+type Decoder struct {
+ reader io.Reader
+ referenceReaders []io.Reader
+ anchorNodeMap map[string]ast.Node
+ anchorValueMap map[string]reflect.Value
+ customUnmarshalerMap map[reflect.Type]func(context.Context, interface{}, []byte) error
+ commentMaps []CommentMap
+ toCommentMap CommentMap
+ opts []DecodeOption
+ referenceFiles []string
+ referenceDirs []string
+ isRecursiveDir bool
+ isResolvedReference bool
+ validator StructValidator
+ disallowUnknownField bool
+ allowedFieldPrefixes []string
+ allowDuplicateMapKey bool
+ useOrderedMap bool
+ useJSONUnmarshaler bool
+ parsedFile *ast.File
+ streamIndex int
+ decodeDepth int
+}
+
+// NewDecoder returns a new decoder that reads from r.
+func NewDecoder(r io.Reader, opts ...DecodeOption) *Decoder {
+ return &Decoder{
+ reader: r,
+ anchorNodeMap: map[string]ast.Node{},
+ anchorValueMap: map[string]reflect.Value{},
+ customUnmarshalerMap: map[reflect.Type]func(context.Context, interface{}, []byte) error{},
+ opts: opts,
+ referenceReaders: []io.Reader{},
+ referenceFiles: []string{},
+ referenceDirs: []string{},
+ isRecursiveDir: false,
+ isResolvedReference: false,
+ disallowUnknownField: false,
+ allowDuplicateMapKey: false,
+ useOrderedMap: false,
+ }
+}
+
+const maxDecodeDepth = 10000
+
+func (d *Decoder) stepIn() {
+ d.decodeDepth++
+}
+
+func (d *Decoder) stepOut() {
+ d.decodeDepth--
+}
+
+func (d *Decoder) isExceededMaxDepth() bool {
+ return d.decodeDepth > maxDecodeDepth
+}
+
+func (d *Decoder) castToFloat(v interface{}) interface{} {
+ switch vv := v.(type) {
+ case int:
+ return float64(vv)
+ case int8:
+ return float64(vv)
+ case int16:
+ return float64(vv)
+ case int32:
+ return float64(vv)
+ case int64:
+ return float64(vv)
+ case uint:
+ return float64(vv)
+ case uint8:
+ return float64(vv)
+ case uint16:
+ return float64(vv)
+ case uint32:
+ return float64(vv)
+ case uint64:
+ return float64(vv)
+ case float32:
+ return float64(vv)
+ case float64:
+ return vv
+ case string:
+ // if error occurred, return zero value
+ f, _ := strconv.ParseFloat(vv, 64)
+ return f
+ }
+ return 0
+}
+
+func (d *Decoder) mapKeyNodeToString(ctx context.Context, node ast.MapKeyNode) (string, error) {
+ key, err := d.nodeToValue(ctx, node)
+ if err != nil {
+ return "", err
+ }
+ if key == nil {
+ return "null", nil
+ }
+ if k, ok := key.(string); ok {
+ return k, nil
+ }
+ return fmt.Sprint(key), nil
+}
+
+func (d *Decoder) setToMapValue(ctx context.Context, node ast.Node, m map[string]interface{}) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return err
+ }
+ iter := value.MapRange()
+ for iter.Next() {
+ if err := d.setToMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return err
+ }
+ }
+ } else {
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return err
+ }
+ m[key] = v
+ }
+ case *ast.MappingNode:
+ for _, value := range n.Values {
+ if err := d.setToMapValue(ctx, value, m); err != nil {
+ return err
+ }
+ }
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+ d.anchorNodeMap[anchorName] = n.Value
+ }
+ return nil
+}
+
+func (d *Decoder) setToOrderedMapValue(ctx context.Context, node ast.Node, m *MapSlice) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return err
+ }
+ iter := value.MapRange()
+ for iter.Next() {
+ if err := d.setToOrderedMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return err
+ }
+ }
+ } else {
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return err
+ }
+ value, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return err
+ }
+ *m = append(*m, MapItem{Key: key, Value: value})
+ }
+ case *ast.MappingNode:
+ for _, value := range n.Values {
+ if err := d.setToOrderedMapValue(ctx, value, m); err != nil {
+ return err
+ }
+ }
+ }
+ return nil
+}
+
+func (d *Decoder) setPathToCommentMap(node ast.Node) {
+ if node == nil {
+ return
+ }
+ if d.toCommentMap == nil {
+ return
+ }
+ d.addHeadOrLineCommentToMap(node)
+ d.addFootCommentToMap(node)
+}
+
+func (d *Decoder) addHeadOrLineCommentToMap(node ast.Node) {
+ sequence, ok := node.(*ast.SequenceNode)
+ if ok {
+ d.addSequenceNodeCommentToMap(sequence)
+ return
+ }
+ commentGroup := node.GetComment()
+ if commentGroup == nil {
+ return
+ }
+ texts := []string{}
+ targetLine := node.GetToken().Position.Line
+ minCommentLine := math.MaxInt
+ for _, comment := range commentGroup.Comments {
+ if minCommentLine > comment.Token.Position.Line {
+ minCommentLine = comment.Token.Position.Line
+ }
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) == 0 {
+ return
+ }
+ commentPath := node.GetPath()
+ if minCommentLine < targetLine {
+ switch n := node.(type) {
+ case *ast.MappingNode:
+ if len(n.Values) != 0 {
+ commentPath = n.Values[0].Key.GetPath()
+ }
+ case *ast.MappingValueNode:
+ commentPath = n.Key.GetPath()
+ }
+ d.addCommentToMap(commentPath, HeadComment(texts...))
+ } else {
+ d.addCommentToMap(commentPath, LineComment(texts[0]))
+ }
+}
+
+func (d *Decoder) addSequenceNodeCommentToMap(node *ast.SequenceNode) {
+ if len(node.ValueHeadComments) != 0 {
+ for idx, headComment := range node.ValueHeadComments {
+ if headComment == nil {
+ continue
+ }
+ texts := make([]string, 0, len(headComment.Comments))
+ for _, comment := range headComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ d.addCommentToMap(node.Values[idx].GetPath(), HeadComment(texts...))
+ }
+ }
+ }
+ firstElemHeadComment := node.GetComment()
+ if firstElemHeadComment != nil {
+ texts := make([]string, 0, len(firstElemHeadComment.Comments))
+ for _, comment := range firstElemHeadComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ if len(node.Values) != 0 {
+ d.addCommentToMap(node.Values[0].GetPath(), HeadComment(texts...))
+ }
+ }
+ }
+}
+
+func (d *Decoder) addFootCommentToMap(node ast.Node) {
+ var (
+ footComment *ast.CommentGroupNode
+ footCommentPath = node.GetPath()
+ )
+ switch n := node.(type) {
+ case *ast.SequenceNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ case *ast.MappingNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ case *ast.MappingValueNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ }
+ if footComment == nil {
+ return
+ }
+ var texts []string
+ for _, comment := range footComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ d.addCommentToMap(footCommentPath, FootComment(texts...))
+ }
+}
+
+func (d *Decoder) addCommentToMap(path string, comment *Comment) {
+ for _, c := range d.toCommentMap[path] {
+ if c.Position == comment.Position {
+ // already added same comment
+ return
+ }
+ }
+ d.toCommentMap[path] = append(d.toCommentMap[path], comment)
+ sort.Slice(d.toCommentMap[path], func(i, j int) bool {
+ return d.toCommentMap[path][i].Position < d.toCommentMap[path][j].Position
+ })
+}
+
+func (d *Decoder) nodeToValue(ctx context.Context, node ast.Node) (any, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.NullNode:
+ return nil, nil
+ case *ast.StringNode:
+ return n.GetValue(), nil
+ case *ast.IntegerNode:
+ return n.GetValue(), nil
+ case *ast.FloatNode:
+ return n.GetValue(), nil
+ case *ast.BoolNode:
+ return n.GetValue(), nil
+ case *ast.InfinityNode:
+ return n.GetValue(), nil
+ case *ast.NanNode:
+ return n.GetValue(), nil
+ case *ast.TagNode:
+ if n.Directive != nil {
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ if v == nil {
+ return "", nil
+ }
+ return fmt.Sprint(v), nil
+ }
+ switch token.ReservedTagKeyword(n.Start.Value) {
+ case token.TimestampTag:
+ t, _ := d.castToTime(ctx, n.Value)
+ return t, nil
+ case token.IntegerTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ i, _ := strconv.Atoi(fmt.Sprint(v))
+ return i, nil
+ case token.FloatTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return d.castToFloat(v), nil
+ case token.NullTag:
+ return nil, nil
+ case token.BinaryTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ str, ok := v.(string)
+ if !ok {
+ return nil, errors.ErrSyntax(
+ fmt.Sprintf("cannot convert %q to string", fmt.Sprint(v)),
+ n.Value.GetToken(),
+ )
+ }
+ b, _ := base64.StdEncoding.DecodeString(str)
+ return b, nil
+ case token.BooleanTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ str := strings.ToLower(fmt.Sprint(v))
+ b, err := strconv.ParseBool(str)
+ if err == nil {
+ return b, nil
+ }
+ switch str {
+ case "yes":
+ return true, nil
+ case "no":
+ return false, nil
+ }
+ return nil, errors.ErrSyntax(fmt.Sprintf("cannot convert %q to boolean", fmt.Sprint(v)), n.Value.GetToken())
+ case token.StringTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ if v == nil {
+ return "", nil
+ }
+ return fmt.Sprint(v), nil
+ case token.MappingTag:
+ return d.nodeToValue(ctx, n.Value)
+ default:
+ return d.nodeToValue(ctx, n.Value)
+ }
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+
+ // To handle the case where alias is processed recursively, the result of alias can be set to nil in advance.
+ d.anchorNodeMap[anchorName] = nil
+ anchorValue, err := d.nodeToValue(withAnchor(ctx, anchorName), n.Value)
+ if err != nil {
+ delete(d.anchorNodeMap, anchorName)
+ return nil, err
+ }
+ d.anchorNodeMap[anchorName] = n.Value
+ d.anchorValueMap[anchorName] = reflect.ValueOf(anchorValue)
+ return anchorValue, nil
+ case *ast.AliasNode:
+ text := n.Value.String()
+ if _, exists := getAnchorMap(ctx)[text]; exists {
+ // self recursion.
+ return nil, nil
+ }
+ if v, exists := d.anchorValueMap[text]; exists {
+ if !v.IsValid() {
+ return nil, nil
+ }
+ return v.Interface(), nil
+ }
+ if node, exists := d.anchorNodeMap[text]; exists {
+ return d.nodeToValue(ctx, node)
+ }
+ return nil, errors.ErrSyntax(fmt.Sprintf("could not find alias %q", text), n.Value.GetToken())
+ case *ast.LiteralNode:
+ return n.Value.GetValue(), nil
+ case *ast.MappingKeyNode:
+ return d.nodeToValue(ctx, n.Value)
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return nil, err
+ }
+ iter := value.MapRange()
+ if d.useOrderedMap {
+ m := MapSlice{}
+ for iter.Next() {
+ if err := d.setToOrderedMapValue(ctx, iter.KeyValue(), &m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ m := make(map[string]any)
+ for iter.Next() {
+ if err := d.setToMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return nil, err
+ }
+ if d.useOrderedMap {
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return MapSlice{{Key: key, Value: v}}, nil
+ }
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return map[string]interface{}{key: v}, nil
+ case *ast.MappingNode:
+ if d.useOrderedMap {
+ m := make(MapSlice, 0, len(n.Values))
+ for _, value := range n.Values {
+ if err := d.setToOrderedMapValue(ctx, value, &m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ m := make(map[string]interface{}, len(n.Values))
+ for _, value := range n.Values {
+ if err := d.setToMapValue(ctx, value, m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ case *ast.SequenceNode:
+ v := make([]interface{}, 0, len(n.Values))
+ for _, value := range n.Values {
+ vv, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return nil, err
+ }
+ v = append(v, vv)
+ }
+ return v, nil
+ }
+ return nil, nil
+}
+
+func (d *Decoder) getMapNode(node ast.Node, isMerge bool) (ast.MapNode, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ switch n := node.(type) {
+ case ast.MapNode:
+ return n, nil
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+ d.anchorNodeMap[anchorName] = n.Value
+ return d.getMapNode(n.Value, isMerge)
+ case *ast.AliasNode:
+ aliasName := n.Value.GetToken().Value
+ node := d.anchorNodeMap[aliasName]
+ if node == nil {
+ return nil, fmt.Errorf("cannot find anchor by alias name %s", aliasName)
+ }
+ return d.getMapNode(node, isMerge)
+ case *ast.SequenceNode:
+ if !isMerge {
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.MappingType, node.GetToken())
+ }
+ var mapNodes []ast.MapNode
+ for _, value := range n.Values {
+ mapNode, err := d.getMapNode(value, false)
+ if err != nil {
+ return nil, err
+ }
+ mapNodes = append(mapNodes, mapNode)
+ }
+ return ast.SequenceMergeValue(mapNodes...), nil
+ }
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.MappingType, node.GetToken())
+}
+
+func (d *Decoder) getArrayNode(node ast.Node) (ast.ArrayNode, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ if _, ok := node.(*ast.NullNode); ok {
+ return nil, nil
+ }
+ if anchor, ok := node.(*ast.AnchorNode); ok {
+ arrayNode, ok := anchor.Value.(ast.ArrayNode)
+ if ok {
+ return arrayNode, nil
+ }
+
+ return nil, errors.ErrUnexpectedNodeType(anchor.Value.Type(), ast.SequenceType, node.GetToken())
+ }
+ if alias, ok := node.(*ast.AliasNode); ok {
+ aliasName := alias.Value.GetToken().Value
+ node := d.anchorNodeMap[aliasName]
+ if node == nil {
+ return nil, fmt.Errorf("cannot find anchor by alias name %s", aliasName)
+ }
+ arrayNode, ok := node.(ast.ArrayNode)
+ if ok {
+ return arrayNode, nil
+ }
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.SequenceType, node.GetToken())
+ }
+ arrayNode, ok := node.(ast.ArrayNode)
+ if !ok {
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.SequenceType, node.GetToken())
+ }
+ return arrayNode, nil
+}
+
+func (d *Decoder) convertValue(v reflect.Value, typ reflect.Type, src ast.Node) (reflect.Value, error) {
+ if typ.Kind() != reflect.String {
+ if !v.Type().ConvertibleTo(typ) {
+
+ // Special case for "strings -> floats" aka scientific notation
+ // If the destination type is a float and the source type is a string, check if we can
+ // use strconv.ParseFloat to convert the string to a float.
+ if (typ.Kind() == reflect.Float32 || typ.Kind() == reflect.Float64) &&
+ v.Type().Kind() == reflect.String {
+ if f, err := strconv.ParseFloat(v.String(), 64); err == nil {
+ if typ.Kind() == reflect.Float32 {
+ return reflect.ValueOf(float32(f)), nil
+ } else if typ.Kind() == reflect.Float64 {
+ return reflect.ValueOf(f), nil
+ }
+ // else, fall through to the error below
+ }
+ }
+ return reflect.Zero(typ), errors.ErrTypeMismatch(typ, v.Type(), src.GetToken())
+ }
+ return v.Convert(typ), nil
+ }
+ // cast value to string
+ var strVal string
+ switch v.Type().Kind() {
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ strVal = strconv.FormatInt(v.Int(), 10)
+ case reflect.Float32, reflect.Float64:
+ strVal = fmt.Sprint(v.Float())
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ strVal = strconv.FormatUint(v.Uint(), 10)
+ case reflect.Bool:
+ strVal = strconv.FormatBool(v.Bool())
+ default:
+ if !v.Type().ConvertibleTo(typ) {
+ return reflect.Zero(typ), errors.ErrTypeMismatch(typ, v.Type(), src.GetToken())
+ }
+ return v.Convert(typ), nil
+ }
+
+ val := reflect.ValueOf(strVal)
+ if val.Type() != typ {
+ // Handle named types, e.g., `type MyString string`
+ val = val.Convert(typ)
+ }
+ return val, nil
+}
+
+func (d *Decoder) deleteStructKeys(structType reflect.Type, unknownFields map[string]ast.Node) error {
+ if structType.Kind() == reflect.Ptr {
+ structType = structType.Elem()
+ }
+ structFieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return err
+ }
+
+ for j := 0; j < structType.NumField(); j++ {
+ field := structType.Field(j)
+ if isIgnoredStructField(field) {
+ continue
+ }
+
+ structField, exists := structFieldMap[field.Name]
+ if !exists {
+ continue
+ }
+
+ if structField.IsInline {
+ _ = d.deleteStructKeys(field.Type, unknownFields)
+ } else {
+ delete(unknownFields, structField.RenderName)
+ }
+ }
+ return nil
+}
+
+func (d *Decoder) unmarshalableDocument(node ast.Node) ([]byte, error) {
+ doc := format.FormatNodeWithResolvedAlias(node, d.anchorNodeMap)
+ return []byte(doc), nil
+}
+
+func (d *Decoder) unmarshalableText(node ast.Node) ([]byte, bool) {
+ doc := format.FormatNodeWithResolvedAlias(node, d.anchorNodeMap)
+ var v string
+ if err := Unmarshal([]byte(doc), &v); err != nil {
+ return nil, false
+ }
+ return []byte(v), true
+}
+
+type jsonUnmarshaler interface {
+ UnmarshalJSON([]byte) error
+}
+
+func (d *Decoder) existsTypeInCustomUnmarshalerMap(t reflect.Type) bool {
+ if _, exists := d.customUnmarshalerMap[t]; exists {
+ return true
+ }
+
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+ if _, exists := globalCustomUnmarshalerMap[t]; exists {
+ return true
+ }
+ return false
+}
+
+func (d *Decoder) unmarshalerFromCustomUnmarshalerMap(t reflect.Type) (func(context.Context, interface{}, []byte) error, bool) {
+ if unmarshaler, exists := d.customUnmarshalerMap[t]; exists {
+ return unmarshaler, exists
+ }
+
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+ if unmarshaler, exists := globalCustomUnmarshalerMap[t]; exists {
+ return unmarshaler, exists
+ }
+ return nil, false
+}
+
+func (d *Decoder) canDecodeByUnmarshaler(dst reflect.Value) bool {
+ ptrValue := dst.Addr()
+ if d.existsTypeInCustomUnmarshalerMap(ptrValue.Type()) {
+ return true
+ }
+ iface := ptrValue.Interface()
+ switch iface.(type) {
+ case BytesUnmarshalerContext,
+ BytesUnmarshaler,
+ InterfaceUnmarshalerContext,
+ InterfaceUnmarshaler,
+ NodeUnmarshaler,
+ NodeUnmarshalerContext,
+ *time.Time,
+ *time.Duration,
+ encoding.TextUnmarshaler:
+ return true
+ case jsonUnmarshaler:
+ return d.useJSONUnmarshaler
+ }
+ return false
+}
+
+func (d *Decoder) decodeByUnmarshaler(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ ptrValue := dst.Addr()
+ if unmarshaler, exists := d.unmarshalerFromCustomUnmarshalerMap(ptrValue.Type()); exists {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler(ctx, ptrValue.Interface(), b); err != nil {
+ return err
+ }
+ return nil
+ }
+ iface := ptrValue.Interface()
+
+ if unmarshaler, ok := iface.(BytesUnmarshalerContext); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler.UnmarshalYAML(ctx, b); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(BytesUnmarshaler); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler.UnmarshalYAML(b); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(InterfaceUnmarshalerContext); ok {
+ if err := unmarshaler.UnmarshalYAML(ctx, func(v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), src); err != nil {
+ return err
+ }
+ return nil
+ }); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(InterfaceUnmarshaler); ok {
+ if err := unmarshaler.UnmarshalYAML(func(v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), src); err != nil {
+ return err
+ }
+ return nil
+ }); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(NodeUnmarshaler); ok {
+ if err := unmarshaler.UnmarshalYAML(src); err != nil {
+ return err
+ }
+
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(NodeUnmarshalerContext); ok {
+ if err := unmarshaler.UnmarshalYAML(ctx, src); err != nil {
+ return err
+ }
+
+ return nil
+ }
+
+ if _, ok := iface.(*time.Time); ok {
+ return d.decodeTime(ctx, dst, src)
+ }
+
+ if _, ok := iface.(*time.Duration); ok {
+ return d.decodeDuration(ctx, dst, src)
+ }
+
+ if unmarshaler, isText := iface.(encoding.TextUnmarshaler); isText {
+ b, ok := d.unmarshalableText(src)
+ if ok {
+ if err := unmarshaler.UnmarshalText(b); err != nil {
+ return err
+ }
+ return nil
+ }
+ }
+
+ if d.useJSONUnmarshaler {
+ if unmarshaler, ok := iface.(jsonUnmarshaler); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ jsonBytes, err := YAMLToJSON(b)
+ if err != nil {
+ return err
+ }
+ jsonBytes = bytes.TrimRight(jsonBytes, "\n")
+ if err := unmarshaler.UnmarshalJSON(jsonBytes); err != nil {
+ return err
+ }
+ return nil
+ }
+ }
+
+ return errors.New("does not implemented Unmarshaler")
+}
+
+var (
+ astNodeType = reflect.TypeOf((*ast.Node)(nil)).Elem()
+)
+
+func (d *Decoder) decodeValue(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+ if !dst.IsValid() {
+ return nil
+ }
+
+ if src.Type() == ast.AnchorType {
+ anchor, _ := src.(*ast.AnchorNode)
+ anchorName := anchor.Name.GetToken().Value
+ if err := d.decodeValue(withAnchor(ctx, anchorName), dst, anchor.Value); err != nil {
+ return err
+ }
+ d.anchorValueMap[anchorName] = dst
+ return nil
+ }
+ if d.canDecodeByUnmarshaler(dst) {
+ if err := d.decodeByUnmarshaler(ctx, dst, src); err != nil {
+ return err
+ }
+ return nil
+ }
+ valueType := dst.Type()
+ switch valueType.Kind() {
+ case reflect.Ptr:
+ if dst.IsNil() {
+ return nil
+ }
+ if src.Type() == ast.NullType {
+ // set nil value to pointer
+ dst.Set(reflect.Zero(valueType))
+ return nil
+ }
+ v := d.createDecodableValue(dst.Type())
+ if err := d.decodeValue(ctx, v, src); err != nil {
+ return err
+ }
+ castedValue, err := d.castToAssignableValue(v, dst.Type(), src)
+ if err != nil {
+ return err
+ }
+ dst.Set(castedValue)
+ case reflect.Interface:
+ if dst.Type() == astNodeType {
+ dst.Set(reflect.ValueOf(src))
+ return nil
+ }
+ srcVal, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ v := reflect.ValueOf(srcVal)
+ if v.IsValid() {
+ dst.Set(v)
+ } else {
+ dst.Set(reflect.Zero(valueType))
+ }
+ case reflect.Map:
+ return d.decodeMap(ctx, dst, src)
+ case reflect.Array:
+ return d.decodeArray(ctx, dst, src)
+ case reflect.Slice:
+ if mapSlice, ok := dst.Addr().Interface().(*MapSlice); ok {
+ return d.decodeMapSlice(ctx, mapSlice, src)
+ }
+ return d.decodeSlice(ctx, dst, src)
+ case reflect.Struct:
+ if mapItem, ok := dst.Addr().Interface().(*MapItem); ok {
+ return d.decodeMapItem(ctx, mapItem, src)
+ }
+ return d.decodeStruct(ctx, dst, src)
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ switch vv := v.(type) {
+ case int64:
+ if !dst.OverflowInt(vv) {
+ dst.SetInt(vv)
+ return nil
+ }
+ case uint64:
+ if vv <= math.MaxInt64 && !dst.OverflowInt(int64(vv)) {
+ dst.SetInt(int64(vv))
+ return nil
+ }
+ case float64:
+ if vv <= math.MaxInt64 && !dst.OverflowInt(int64(vv)) {
+ dst.SetInt(int64(vv))
+ return nil
+ }
+ case string: // handle scientific notation
+ if i, err := strconv.ParseFloat(vv, 64); err == nil {
+ if 0 <= i && i <= math.MaxUint64 && !dst.OverflowInt(int64(i)) {
+ dst.SetInt(int64(i))
+ return nil
+ }
+ } else { // couldn't be parsed as float
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ default:
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ return errors.ErrOverflow(valueType, fmt.Sprint(v), src.GetToken())
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64:
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ switch vv := v.(type) {
+ case int64:
+ if 0 <= vv && !dst.OverflowUint(uint64(vv)) {
+ dst.SetUint(uint64(vv))
+ return nil
+ }
+ case uint64:
+ if !dst.OverflowUint(vv) {
+ dst.SetUint(vv)
+ return nil
+ }
+ case float64:
+ if 0 <= vv && vv <= math.MaxUint64 && !dst.OverflowUint(uint64(vv)) {
+ dst.SetUint(uint64(vv))
+ return nil
+ }
+ case string: // handle scientific notation
+ if i, err := strconv.ParseFloat(vv, 64); err == nil {
+ if 0 <= i && i <= math.MaxUint64 && !dst.OverflowUint(uint64(i)) {
+ dst.SetUint(uint64(i))
+ return nil
+ }
+ } else { // couldn't be parsed as float
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+
+ default:
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ return errors.ErrOverflow(valueType, fmt.Sprint(v), src.GetToken())
+ }
+ srcVal, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ v := reflect.ValueOf(srcVal)
+ if v.IsValid() {
+ convertedValue, err := d.convertValue(v, dst.Type(), src)
+ if err != nil {
+ return err
+ }
+ dst.Set(convertedValue)
+ }
+ return nil
+}
+
+func (d *Decoder) createDecodableValue(typ reflect.Type) reflect.Value {
+ for {
+ if typ.Kind() == reflect.Ptr {
+ typ = typ.Elem()
+ continue
+ }
+ break
+ }
+ return reflect.New(typ).Elem()
+}
+
+func (d *Decoder) castToAssignableValue(value reflect.Value, target reflect.Type, src ast.Node) (reflect.Value, error) {
+ if target.Kind() != reflect.Ptr {
+ if !value.Type().AssignableTo(target) {
+ return reflect.Value{}, errors.ErrTypeMismatch(target, value.Type(), src.GetToken())
+ }
+ return value, nil
+ }
+
+ const maxAddrCount = 5
+
+ for i := 0; i < maxAddrCount; i++ {
+ if value.Type().AssignableTo(target) {
+ break
+ }
+ if !value.CanAddr() {
+ break
+ }
+ value = value.Addr()
+ }
+ if !value.Type().AssignableTo(target) {
+ return reflect.Value{}, errors.ErrTypeMismatch(target, value.Type(), src.GetToken())
+ }
+ return value, nil
+}
+
+func (d *Decoder) createDecodedNewValue(
+ ctx context.Context, typ reflect.Type, defaultVal reflect.Value, node ast.Node,
+) (reflect.Value, error) {
+ if node.Type() == ast.AliasType {
+ aliasName := node.(*ast.AliasNode).Value.GetToken().Value
+ value := d.anchorValueMap[aliasName]
+ if value.IsValid() {
+ v, err := d.castToAssignableValue(value, typ, node)
+ if err == nil {
+ return v, nil
+ }
+ }
+ anchor, exists := d.anchorNodeMap[aliasName]
+ if exists {
+ node = anchor
+ }
+ }
+ var newValue reflect.Value
+ if node.Type() == ast.NullType {
+ newValue = reflect.New(typ).Elem()
+ } else {
+ newValue = d.createDecodableValue(typ)
+ }
+ for defaultVal.Kind() == reflect.Ptr {
+ defaultVal = defaultVal.Elem()
+ }
+ if defaultVal.IsValid() && defaultVal.Type().AssignableTo(newValue.Type()) {
+ newValue.Set(defaultVal)
+ }
+ if node.Type() != ast.NullType {
+ if err := d.decodeValue(ctx, newValue, node); err != nil {
+ return reflect.Value{}, err
+ }
+ }
+ return d.castToAssignableValue(newValue, typ, node)
+}
+
+func (d *Decoder) keyToNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool, getKeyOrValueNode func(*ast.MapNodeIter) ast.Node) (map[string]ast.Node, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(node, false)
+ if err != nil {
+ return nil, err
+ }
+ keyMap := map[string]struct{}{}
+ keyToNodeMap := map[string]ast.Node{}
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ keyNode := mapIter.Key()
+ if keyNode.IsMergeKey() {
+ if ignoreMergeKey {
+ continue
+ }
+ mergeMap, err := d.keyToNodeMap(ctx, mapIter.Value(), ignoreMergeKey, getKeyOrValueNode)
+ if err != nil {
+ return nil, err
+ }
+ for k, v := range mergeMap {
+ if err := d.validateDuplicateKey(keyMap, k, v); err != nil {
+ return nil, err
+ }
+ keyToNodeMap[k] = v
+ }
+ } else {
+ keyVal, err := d.nodeToValue(ctx, keyNode)
+ if err != nil {
+ return nil, err
+ }
+ key, ok := keyVal.(string)
+ if !ok {
+ return nil, err
+ }
+ if err := d.validateDuplicateKey(keyMap, key, keyNode); err != nil {
+ return nil, err
+ }
+ keyToNodeMap[key] = getKeyOrValueNode(mapIter)
+ }
+ }
+ return keyToNodeMap, nil
+}
+
+func (d *Decoder) keyToKeyNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool) (map[string]ast.Node, error) {
+ m, err := d.keyToNodeMap(ctx, node, ignoreMergeKey, func(nodeMap *ast.MapNodeIter) ast.Node { return nodeMap.Key() })
+ if err != nil {
+ return nil, err
+ }
+ return m, nil
+}
+
+func (d *Decoder) keyToValueNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool) (map[string]ast.Node, error) {
+ m, err := d.keyToNodeMap(ctx, node, ignoreMergeKey, func(nodeMap *ast.MapNodeIter) ast.Node { return nodeMap.Value() })
+ if err != nil {
+ return nil, err
+ }
+ return m, nil
+}
+
+func (d *Decoder) setDefaultValueIfConflicted(v reflect.Value, fieldMap StructFieldMap) error {
+ for v.Type().Kind() == reflect.Ptr {
+ v = v.Elem()
+ }
+ typ := v.Type()
+ if typ.Kind() != reflect.Struct {
+ return nil
+ }
+ embeddedStructFieldMap, err := structFieldMap(typ)
+ if err != nil {
+ return err
+ }
+ for i := 0; i < typ.NumField(); i++ {
+ field := typ.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ structField := embeddedStructFieldMap[field.Name]
+ if !fieldMap.isIncludedRenderName(structField.RenderName) {
+ continue
+ }
+ // if declared same key name, set default value
+ fieldValue := v.Field(i)
+ if fieldValue.CanSet() {
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ }
+ }
+ return nil
+}
+
+// This is a subset of the formats allowed by the regular expression
+// defined at http://yaml.org/type/timestamp.html.
+var allowedTimestampFormats = []string{
+ "2006-1-2T15:4:5.999999999Z07:00", // RCF3339Nano with short date fields.
+ "2006-1-2t15:4:5.999999999Z07:00", // RFC3339Nano with short date fields and lower-case "t".
+ "2006-1-2 15:4:5.999999999", // space separated with no time zone
+ "2006-1-2", // date only
+}
+
+func (d *Decoder) castToTime(ctx context.Context, src ast.Node) (time.Time, error) {
+ if src == nil {
+ return time.Time{}, nil
+ }
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return time.Time{}, err
+ }
+ if t, ok := v.(time.Time); ok {
+ return t, nil
+ }
+ s, ok := v.(string)
+ if !ok {
+ return time.Time{}, errors.ErrTypeMismatch(reflect.TypeOf(time.Time{}), reflect.TypeOf(v), src.GetToken())
+ }
+ for _, format := range allowedTimestampFormats {
+ t, err := time.Parse(format, s)
+ if err != nil {
+ // invalid format
+ continue
+ }
+ return t, nil
+ }
+ return time.Time{}, nil
+}
+
+func (d *Decoder) decodeTime(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ t, err := d.castToTime(ctx, src)
+ if err != nil {
+ return err
+ }
+ dst.Set(reflect.ValueOf(t))
+ return nil
+}
+
+func (d *Decoder) castToDuration(ctx context.Context, src ast.Node) (time.Duration, error) {
+ if src == nil {
+ return 0, nil
+ }
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return 0, err
+ }
+ if t, ok := v.(time.Duration); ok {
+ return t, nil
+ }
+ s, ok := v.(string)
+ if !ok {
+ return 0, errors.ErrTypeMismatch(reflect.TypeOf(time.Duration(0)), reflect.TypeOf(v), src.GetToken())
+ }
+ t, err := time.ParseDuration(s)
+ if err != nil {
+ return 0, err
+ }
+ return t, nil
+}
+
+func (d *Decoder) decodeDuration(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ t, err := d.castToDuration(ctx, src)
+ if err != nil {
+ return err
+ }
+ dst.Set(reflect.ValueOf(t))
+ return nil
+}
+
+// getMergeAliasName support single alias only
+func (d *Decoder) getMergeAliasName(src ast.Node) string {
+ mapNode, err := d.getMapNode(src, true)
+ if err != nil {
+ return ""
+ }
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() && value.Type() == ast.AliasType {
+ return value.(*ast.AliasNode).Value.GetToken().Value
+ }
+ }
+ return ""
+}
+
+func (d *Decoder) decodeStruct(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ if src == nil {
+ return nil
+ }
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ structType := dst.Type()
+ srcValue := reflect.ValueOf(src)
+ srcType := srcValue.Type()
+ if srcType.Kind() == reflect.Ptr {
+ srcType = srcType.Elem()
+ srcValue = srcValue.Elem()
+ }
+ if structType == srcType {
+ // dst value implements ast.Node
+ dst.Set(srcValue)
+ return nil
+ }
+ structFieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return err
+ }
+ ignoreMergeKey := structFieldMap.hasMergeProperty()
+ keyToNodeMap, err := d.keyToValueNodeMap(ctx, src, ignoreMergeKey)
+ if err != nil {
+ return err
+ }
+ var unknownFields map[string]ast.Node
+ if d.disallowUnknownField {
+ unknownFields, err = d.keyToKeyNodeMap(ctx, src, ignoreMergeKey)
+ if err != nil {
+ return err
+ }
+ }
+
+ aliasName := d.getMergeAliasName(src)
+ var foundErr error
+
+ for i := 0; i < structType.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ structField := structFieldMap[field.Name]
+ if structField.IsInline {
+ fieldValue := dst.FieldByName(field.Name)
+ if structField.IsAutoAlias {
+ if aliasName != "" {
+ newFieldValue := d.anchorValueMap[aliasName]
+ if newFieldValue.IsValid() {
+ value, err := d.castToAssignableValue(newFieldValue, fieldValue.Type(), d.anchorNodeMap[aliasName])
+ if err != nil {
+ return err
+ }
+ fieldValue.Set(value)
+ }
+ }
+ continue
+ }
+ if !fieldValue.CanSet() {
+ return fmt.Errorf("cannot set embedded type as unexported field %s.%s", field.PkgPath, field.Name)
+ }
+ if fieldValue.Type().Kind() == reflect.Ptr && src.Type() == ast.NullType {
+ // set nil value to pointer
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ continue
+ }
+ mapNode := ast.Mapping(nil, false)
+ for k, v := range keyToNodeMap {
+ key := &ast.StringNode{BaseNode: &ast.BaseNode{}, Value: k}
+ mapNode.Values = append(mapNode.Values, ast.MappingValue(nil, key, v))
+ }
+ newFieldValue, err := d.createDecodedNewValue(ctx, fieldValue.Type(), fieldValue, mapNode)
+ if d.disallowUnknownField {
+ if err := d.deleteStructKeys(fieldValue.Type(), unknownFields); err != nil {
+ return err
+ }
+ }
+
+ if err != nil {
+ if foundErr != nil {
+ continue
+ }
+ var te *errors.TypeError
+ if errors.As(err, &te) {
+ if te.StructFieldName != nil {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), *te.StructFieldName)
+ te.StructFieldName = &fieldName
+ } else {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), field.Name)
+ te.StructFieldName = &fieldName
+ }
+ foundErr = te
+ continue
+ } else {
+ foundErr = err
+ }
+ continue
+ }
+ _ = d.setDefaultValueIfConflicted(newFieldValue, structFieldMap)
+ fieldValue.Set(newFieldValue)
+ continue
+ }
+ v, exists := keyToNodeMap[structField.RenderName]
+ if !exists {
+ continue
+ }
+ delete(unknownFields, structField.RenderName)
+ fieldValue := dst.FieldByName(field.Name)
+ if fieldValue.Type().Kind() == reflect.Ptr && src.Type() == ast.NullType {
+ // set nil value to pointer
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ continue
+ }
+ newFieldValue, err := d.createDecodedNewValue(ctx, fieldValue.Type(), fieldValue, v)
+ if err != nil {
+ if foundErr != nil {
+ continue
+ }
+ var te *errors.TypeError
+ if errors.As(err, &te) {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), field.Name)
+ te.StructFieldName = &fieldName
+ foundErr = te
+ } else {
+ foundErr = err
+ }
+ continue
+ }
+ fieldValue.Set(newFieldValue)
+ }
+ if foundErr != nil {
+ return foundErr
+ }
+
+ // Ignore unknown fields when parsing an inline struct (recognized by a nil token).
+ // Unknown fields are expected (they could be fields from the parent struct).
+ if len(unknownFields) != 0 && d.disallowUnknownField && src.GetToken() != nil {
+ for key, node := range unknownFields {
+ var ok bool
+ for _, prefix := range d.allowedFieldPrefixes {
+ if strings.HasPrefix(key, prefix) {
+ ok = true
+ break
+ }
+ }
+ if !ok {
+ return errors.ErrUnknownField(fmt.Sprintf(`unknown field "%s"`, key), node.GetToken())
+ }
+ }
+ }
+
+ if d.validator != nil {
+ if err := d.validator.Struct(dst.Interface()); err != nil {
+ ev := reflect.ValueOf(err)
+ if ev.Type().Kind() == reflect.Slice {
+ for i := 0; i < ev.Len(); i++ {
+ fieldErr, ok := ev.Index(i).Interface().(FieldError)
+ if !ok {
+ continue
+ }
+ fieldName := fieldErr.StructField()
+ structField, exists := structFieldMap[fieldName]
+ if !exists {
+ continue
+ }
+ node, exists := keyToNodeMap[structField.RenderName]
+ if exists {
+ // TODO: to make FieldError message cutomizable
+ return errors.ErrSyntax(
+ fmt.Sprintf("%s", err),
+ d.getParentMapTokenIfExistsForValidationError(node.Type(), node.GetToken()),
+ )
+ } else if t := src.GetToken(); t != nil && t.Prev != nil && t.Prev.Prev != nil {
+ // A missing required field will not be in the keyToNodeMap
+ // the error needs to be associated with the parent of the source node
+ return errors.ErrSyntax(fmt.Sprintf("%s", err), t.Prev.Prev)
+ }
+ }
+ }
+ return err
+ }
+ }
+ return nil
+}
+
+// getParentMapTokenIfExists if the NodeType is a container type such as MappingType or SequenceType,
+// it is necessary to return the parent MapNode's colon token to represent the entire container.
+func (d *Decoder) getParentMapTokenIfExistsForValidationError(typ ast.NodeType, tk *token.Token) *token.Token {
+ if tk == nil {
+ return nil
+ }
+ if typ == ast.MappingType {
+ // map:
+ // key: value
+ // ^ current token ( colon )
+ if tk.Prev == nil {
+ return tk
+ }
+ key := tk.Prev
+ if key.Prev == nil {
+ return tk
+ }
+ return key.Prev
+ }
+ if typ == ast.SequenceType {
+ // map:
+ // - value
+ // ^ current token ( sequence entry )
+ if tk.Prev == nil {
+ return tk
+ }
+ return tk.Prev
+ }
+ return tk
+}
+
+func (d *Decoder) decodeArray(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ arrayNode, err := d.getArrayNode(src)
+ if err != nil {
+ return err
+ }
+ if arrayNode == nil {
+ return nil
+ }
+ iter := arrayNode.ArrayRange()
+ arrayValue := reflect.New(dst.Type()).Elem()
+ arrayType := dst.Type()
+ elemType := arrayType.Elem()
+ idx := 0
+
+ var foundErr error
+ for iter.Next() {
+ v := iter.Value()
+ if elemType.Kind() == reflect.Ptr && v.Type() == ast.NullType {
+ // set nil value to pointer
+ arrayValue.Index(idx).Set(reflect.Zero(elemType))
+ } else {
+ dstValue, err := d.createDecodedNewValue(ctx, elemType, reflect.Value{}, v)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ continue
+ }
+ arrayValue.Index(idx).Set(dstValue)
+ }
+ idx++
+ }
+ dst.Set(arrayValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) decodeSlice(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ arrayNode, err := d.getArrayNode(src)
+ if err != nil {
+ return err
+ }
+ if arrayNode == nil {
+ return nil
+ }
+ iter := arrayNode.ArrayRange()
+ sliceType := dst.Type()
+ sliceValue := reflect.MakeSlice(sliceType, 0, iter.Len())
+ elemType := sliceType.Elem()
+
+ var foundErr error
+ for iter.Next() {
+ v := iter.Value()
+ if elemType.Kind() == reflect.Ptr && v.Type() == ast.NullType {
+ // set nil value to pointer
+ sliceValue = reflect.Append(sliceValue, reflect.Zero(elemType))
+ continue
+ }
+ dstValue, err := d.createDecodedNewValue(ctx, elemType, reflect.Value{}, v)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ continue
+ }
+ sliceValue = reflect.Append(sliceValue, dstValue)
+ }
+ dst.Set(sliceValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) decodeMapItem(ctx context.Context, dst *MapItem, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapIter := mapNode.MapRange()
+ if !mapIter.Next() {
+ return nil
+ }
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ if err := d.decodeMapItem(withMerge(ctx), dst, value); err != nil {
+ return err
+ }
+ return nil
+ }
+ k, err := d.nodeToValue(ctx, key)
+ if err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return err
+ }
+ *dst = MapItem{Key: k, Value: v}
+ return nil
+}
+
+func (d *Decoder) validateDuplicateKey(keyMap map[string]struct{}, key interface{}, keyNode ast.Node) error {
+ k, ok := key.(string)
+ if !ok {
+ return nil
+ }
+ if !d.allowDuplicateMapKey {
+ if _, exists := keyMap[k]; exists {
+ return errors.ErrDuplicateKey(fmt.Sprintf(`duplicate key "%s"`, k), keyNode.GetToken())
+ }
+ }
+ keyMap[k] = struct{}{}
+ return nil
+}
+
+func (d *Decoder) decodeMapSlice(ctx context.Context, dst *MapSlice, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapSlice := MapSlice{}
+ mapIter := mapNode.MapRange()
+ keyMap := map[string]struct{}{}
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ var m MapSlice
+ if err := d.decodeMapSlice(withMerge(ctx), &m, value); err != nil {
+ return err
+ }
+ for _, v := range m {
+ if err := d.validateDuplicateKey(keyMap, v.Key, value); err != nil {
+ return err
+ }
+ mapSlice = append(mapSlice, v)
+ }
+ continue
+ }
+ k, err := d.nodeToValue(ctx, key)
+ if err != nil {
+ return err
+ }
+ if err := d.validateDuplicateKey(keyMap, k, key); err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return err
+ }
+ mapSlice = append(mapSlice, MapItem{Key: k, Value: v})
+ }
+ *dst = mapSlice
+ return nil
+}
+
+func (d *Decoder) decodeMap(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapType := dst.Type()
+ mapValue := reflect.MakeMap(mapType)
+ keyType := mapValue.Type().Key()
+ valueType := mapValue.Type().Elem()
+ mapIter := mapNode.MapRange()
+ keyMap := map[string]struct{}{}
+ var foundErr error
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ if err := d.decodeMap(withMerge(ctx), dst, value); err != nil {
+ return err
+ }
+ iter := dst.MapRange()
+ for iter.Next() {
+ if err := d.validateDuplicateKey(keyMap, iter.Key(), value); err != nil {
+ return err
+ }
+ mapValue.SetMapIndex(iter.Key(), iter.Value())
+ }
+ continue
+ }
+
+ k := d.createDecodableValue(keyType)
+ if d.canDecodeByUnmarshaler(k) {
+ if err := d.decodeByUnmarshaler(ctx, k, key); err != nil {
+ return err
+ }
+ } else {
+ keyVal, err := d.createDecodedNewValue(ctx, keyType, reflect.Value{}, key)
+ if err != nil {
+ return err
+ }
+ k = keyVal
+ }
+
+ if k.IsValid() {
+ if err := d.validateDuplicateKey(keyMap, k.Interface(), key); err != nil {
+ return err
+ }
+ }
+ if valueType.Kind() == reflect.Ptr && value.Type() == ast.NullType {
+ // set nil value to pointer
+ mapValue.SetMapIndex(k, reflect.Zero(valueType))
+ continue
+ }
+ dstValue, err := d.createDecodedNewValue(ctx, valueType, reflect.Value{}, value)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ }
+ if !k.IsValid() {
+ // expect nil key
+ mapValue.SetMapIndex(d.createDecodableValue(keyType), dstValue)
+ continue
+ }
+ if keyType.Kind() != k.Kind() {
+ return errors.ErrSyntax(
+ fmt.Sprintf("cannot convert %q type to %q type", k.Kind(), keyType.Kind()),
+ key.GetToken(),
+ )
+ }
+ mapValue.SetMapIndex(k, dstValue)
+ }
+ dst.Set(mapValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) fileToReader(file string) (io.Reader, error) {
+ reader, err := os.Open(file)
+ if err != nil {
+ return nil, err
+ }
+ return reader, nil
+}
+
+func (d *Decoder) isYAMLFile(file string) bool {
+ ext := filepath.Ext(file)
+ if ext == ".yml" {
+ return true
+ }
+ if ext == ".yaml" {
+ return true
+ }
+ return false
+}
+
+func (d *Decoder) readersUnderDir(dir string) ([]io.Reader, error) {
+ pattern := fmt.Sprintf("%s/*", dir)
+ matches, err := filepath.Glob(pattern)
+ if err != nil {
+ return nil, err
+ }
+ readers := []io.Reader{}
+ for _, match := range matches {
+ if !d.isYAMLFile(match) {
+ continue
+ }
+ reader, err := d.fileToReader(match)
+ if err != nil {
+ return nil, err
+ }
+ readers = append(readers, reader)
+ }
+ return readers, nil
+}
+
+func (d *Decoder) readersUnderDirRecursive(dir string) ([]io.Reader, error) {
+ readers := []io.Reader{}
+ if err := filepath.Walk(dir, func(path string, info os.FileInfo, _ error) error {
+ if !d.isYAMLFile(path) {
+ return nil
+ }
+ reader, readerErr := d.fileToReader(path)
+ if readerErr != nil {
+ return readerErr
+ }
+ readers = append(readers, reader)
+ return nil
+ }); err != nil {
+ return nil, err
+ }
+ return readers, nil
+}
+
+func (d *Decoder) resolveReference(ctx context.Context) error {
+ for _, opt := range d.opts {
+ if err := opt(d); err != nil {
+ return err
+ }
+ }
+ for _, file := range d.referenceFiles {
+ reader, err := d.fileToReader(file)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, reader)
+ }
+ for _, dir := range d.referenceDirs {
+ if !d.isRecursiveDir {
+ readers, err := d.readersUnderDir(dir)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ } else {
+ readers, err := d.readersUnderDirRecursive(dir)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ }
+ }
+ for _, reader := range d.referenceReaders {
+ bytes, err := io.ReadAll(reader)
+ if err != nil {
+ return err
+ }
+
+ // assign new anchor definition to anchorMap
+ if _, err := d.parse(ctx, bytes); err != nil {
+ return err
+ }
+ }
+ d.isResolvedReference = true
+ return nil
+}
+
+func (d *Decoder) parse(ctx context.Context, bytes []byte) (*ast.File, error) {
+ var parseMode parser.Mode
+ if d.toCommentMap != nil {
+ parseMode = parser.ParseComments
+ }
+ var opts []parser.Option
+ if d.allowDuplicateMapKey {
+ opts = append(opts, parser.AllowDuplicateMapKey())
+ }
+ f, err := parser.ParseBytes(bytes, parseMode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ normalizedFile := &ast.File{}
+ for _, doc := range f.Docs {
+ // try to decode ast.Node to value and map anchor value to anchorMap
+ v, err := d.nodeToValue(ctx, doc.Body)
+ if err != nil {
+ return nil, err
+ }
+ if v != nil || (doc.Body != nil && doc.Body.Type() == ast.NullType) {
+ normalizedFile.Docs = append(normalizedFile.Docs, doc)
+ cm := CommentMap{}
+ maps.Copy(cm, d.toCommentMap)
+ d.commentMaps = append(d.commentMaps, cm)
+ }
+ for k := range d.toCommentMap {
+ delete(d.toCommentMap, k)
+ }
+ }
+ return normalizedFile, nil
+}
+
+func (d *Decoder) isInitialized() bool {
+ return d.parsedFile != nil
+}
+
+func (d *Decoder) decodeInit(ctx context.Context) error {
+ if !d.isResolvedReference {
+ if err := d.resolveReference(ctx); err != nil {
+ return err
+ }
+ }
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, d.reader); err != nil {
+ return err
+ }
+ file, err := d.parse(ctx, buf.Bytes())
+ if err != nil {
+ return err
+ }
+ d.parsedFile = file
+ return nil
+}
+
+func (d *Decoder) decode(ctx context.Context, v reflect.Value) error {
+ d.decodeDepth = 0
+ d.anchorValueMap = make(map[string]reflect.Value)
+ if len(d.parsedFile.Docs) == 0 {
+ // empty document.
+ dst := v.Elem()
+ if dst.IsValid() {
+ dst.Set(reflect.Zero(dst.Type()))
+ }
+ }
+ if len(d.parsedFile.Docs) <= d.streamIndex {
+ return io.EOF
+ }
+ body := d.parsedFile.Docs[d.streamIndex].Body
+ if body == nil {
+ return nil
+ }
+ if len(d.commentMaps) > d.streamIndex {
+ maps.Copy(d.toCommentMap, d.commentMaps[d.streamIndex])
+ }
+ if err := d.decodeValue(ctx, v.Elem(), body); err != nil {
+ return err
+ }
+ d.streamIndex++
+ return nil
+}
+
+// Decode reads the next YAML-encoded value from its input
+// and stores it in the value pointed to by v.
+//
+// See the documentation for Unmarshal for details about the
+// conversion of YAML into a Go value.
+func (d *Decoder) Decode(v interface{}) error {
+ return d.DecodeContext(context.Background(), v)
+}
+
+// DecodeContext reads the next YAML-encoded value from its input
+// and stores it in the value pointed to by v with context.Context.
+func (d *Decoder) DecodeContext(ctx context.Context, v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if !rv.IsValid() || rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if d.isInitialized() {
+ if err := d.decode(ctx, rv); err != nil {
+ return err
+ }
+ return nil
+ }
+ if err := d.decodeInit(ctx); err != nil {
+ return err
+ }
+ if err := d.decode(ctx, rv); err != nil {
+ return err
+ }
+ return nil
+}
+
+// DecodeFromNode decodes node into the value pointed to by v.
+func (d *Decoder) DecodeFromNode(node ast.Node, v interface{}) error {
+ return d.DecodeFromNodeContext(context.Background(), node, v)
+}
+
+// DecodeFromNodeContext decodes node into the value pointed to by v with context.Context.
+func (d *Decoder) DecodeFromNodeContext(ctx context.Context, node ast.Node, v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if !d.isInitialized() {
+ if err := d.decodeInit(ctx); err != nil {
+ return err
+ }
+ }
+ // resolve references to the anchor on the same file
+ if _, err := d.nodeToValue(ctx, node); err != nil {
+ return err
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), node); err != nil {
+ return err
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/encode.go b/sesh/vendor/github.com/goccy/go-yaml/encode.go
new file mode 100644
index 0000000..e810608
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/encode.go
@@ -0,0 +1,1074 @@
+package yaml
+
+import (
+ "context"
+ "encoding"
+ "fmt"
+ "io"
+ "math"
+ "reflect"
+ "sort"
+ "strconv"
+ "strings"
+ "time"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/printer"
+ "github.com/goccy/go-yaml/token"
+)
+
+const (
+ // DefaultIndentSpaces default number of space for indent
+ DefaultIndentSpaces = 2
+)
+
+// Encoder writes YAML values to an output stream.
+type Encoder struct {
+ writer io.Writer
+ opts []EncodeOption
+ singleQuote bool
+ isFlowStyle bool
+ isJSONStyle bool
+ useJSONMarshaler bool
+ enableSmartAnchor bool
+ aliasRefToName map[uintptr]string
+ anchorRefToName map[uintptr]string
+ anchorNameMap map[string]struct{}
+ anchorCallback func(*ast.AnchorNode, interface{}) error
+ customMarshalerMap map[reflect.Type]func(context.Context, interface{}) ([]byte, error)
+ omitZero bool
+ omitEmpty bool
+ autoInt bool
+ useLiteralStyleIfMultiline bool
+ commentMap map[*Path][]*Comment
+ written bool
+
+ line int
+ column int
+ offset int
+ indentNum int
+ indentLevel int
+ indentSequence bool
+}
+
+// NewEncoder returns a new encoder that writes to w.
+// The Encoder should be closed after use to flush all data to w.
+func NewEncoder(w io.Writer, opts ...EncodeOption) *Encoder {
+ return &Encoder{
+ writer: w,
+ opts: opts,
+ customMarshalerMap: map[reflect.Type]func(context.Context, interface{}) ([]byte, error){},
+ line: 1,
+ column: 1,
+ offset: 0,
+ indentNum: DefaultIndentSpaces,
+ anchorRefToName: make(map[uintptr]string),
+ anchorNameMap: make(map[string]struct{}),
+ aliasRefToName: make(map[uintptr]string),
+ }
+}
+
+// Close closes the encoder by writing any remaining data.
+// It does not write a stream terminating string "...".
+func (e *Encoder) Close() error {
+ return nil
+}
+
+// Encode writes the YAML encoding of v to the stream.
+// If multiple items are encoded to the stream,
+// the second and subsequent document will be preceded with a "---" document separator,
+// but the first will not.
+//
+// See the documentation for Marshal for details about the conversion of Go values to YAML.
+func (e *Encoder) Encode(v interface{}) error {
+ return e.EncodeContext(context.Background(), v)
+}
+
+// EncodeContext writes the YAML encoding of v to the stream with context.Context.
+func (e *Encoder) EncodeContext(ctx context.Context, v interface{}) error {
+ node, err := e.EncodeToNodeContext(ctx, v)
+ if err != nil {
+ return err
+ }
+ if err := e.setCommentByCommentMap(node); err != nil {
+ return err
+ }
+ if !e.written {
+ e.written = true
+ } else {
+ // write document separator
+ _, _ = e.writer.Write([]byte("---\n"))
+ }
+ var p printer.Printer
+ _, _ = e.writer.Write(p.PrintNode(node))
+ return nil
+}
+
+// EncodeToNode convert v to ast.Node.
+func (e *Encoder) EncodeToNode(v interface{}) (ast.Node, error) {
+ return e.EncodeToNodeContext(context.Background(), v)
+}
+
+// EncodeToNodeContext convert v to ast.Node with context.Context.
+func (e *Encoder) EncodeToNodeContext(ctx context.Context, v interface{}) (ast.Node, error) {
+ for _, opt := range e.opts {
+ if err := opt(e); err != nil {
+ return nil, err
+ }
+ }
+ if e.enableSmartAnchor {
+ // during the first encoding, store all mappings between alias addresses and their names.
+ if _, err := e.encodeValue(ctx, reflect.ValueOf(v), 1); err != nil {
+ return nil, err
+ }
+ e.clearSmartAnchorRef()
+ }
+ node, err := e.encodeValue(ctx, reflect.ValueOf(v), 1)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func (e *Encoder) setCommentByCommentMap(node ast.Node) error {
+ if e.commentMap == nil {
+ return nil
+ }
+ for path, comments := range e.commentMap {
+ n, err := path.FilterNode(node)
+ if err != nil {
+ return err
+ }
+ if n == nil {
+ continue
+ }
+ for _, comment := range comments {
+ commentTokens := []*token.Token{}
+ for _, text := range comment.Texts {
+ commentTokens = append(commentTokens, token.New(text, text, nil))
+ }
+ commentGroup := ast.CommentGroup(commentTokens)
+ switch comment.Position {
+ case CommentHeadPosition:
+ if err := e.setHeadComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ case CommentLinePosition:
+ if err := e.setLineComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ case CommentFootPosition:
+ if err := e.setFootComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ default:
+ return ErrUnknownCommentPositionType
+ }
+ }
+ }
+ return nil
+}
+
+func (e *Encoder) setHeadComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedHeadPositionType(node)
+ }
+ switch p := parent.(type) {
+ case *ast.MappingValueNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.MappingNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.SequenceNode:
+ if len(p.ValueHeadComments) == 0 {
+ p.ValueHeadComments = make([]*ast.CommentGroupNode, len(p.Values))
+ }
+ var foundIdx int
+ for idx, v := range p.Values {
+ if v == filtered {
+ foundIdx = idx
+ break
+ }
+ }
+ p.ValueHeadComments[foundIdx] = comment
+ default:
+ return ErrUnsupportedHeadPositionType(node)
+ }
+ return nil
+}
+
+func (e *Encoder) setLineComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ switch filtered.(type) {
+ case *ast.MappingValueNode, *ast.SequenceNode:
+ // Line comment cannot be set for mapping value node.
+ // It should probably be set for the parent map node
+ if err := e.setLineCommentToParentMapNode(node, filtered, comment); err != nil {
+ return err
+ }
+ default:
+ if err := filtered.SetComment(comment); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+func (e *Encoder) setLineCommentToParentMapNode(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedLinePositionType(node)
+ }
+ switch p := parent.(type) {
+ case *ast.MappingValueNode:
+ if err := p.Key.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.MappingNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ default:
+ return ErrUnsupportedLinePositionType(parent)
+ }
+ return nil
+}
+
+func (e *Encoder) setFootComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedFootPositionType(node)
+ }
+ switch n := parent.(type) {
+ case *ast.MappingValueNode:
+ n.FootComment = comment
+ case *ast.MappingNode:
+ n.FootComment = comment
+ case *ast.SequenceNode:
+ n.FootComment = comment
+ default:
+ return ErrUnsupportedFootPositionType(n)
+ }
+ return nil
+}
+
+func (e *Encoder) encodeDocument(doc []byte) (ast.Node, error) {
+ f, err := parser.ParseBytes(doc, 0)
+ if err != nil {
+ return nil, err
+ }
+ for _, docNode := range f.Docs {
+ if docNode.Body != nil {
+ return docNode.Body, nil
+ }
+ }
+ return nil, nil
+}
+
+func (e *Encoder) isInvalidValue(v reflect.Value) bool {
+ if !v.IsValid() {
+ return true
+ }
+ kind := v.Type().Kind()
+ if kind == reflect.Ptr && v.IsNil() {
+ return true
+ }
+ if kind == reflect.Interface && v.IsNil() {
+ return true
+ }
+ return false
+}
+
+type jsonMarshaler interface {
+ MarshalJSON() ([]byte, error)
+}
+
+func (e *Encoder) existsTypeInCustomMarshalerMap(t reflect.Type) bool {
+ if _, exists := e.customMarshalerMap[t]; exists {
+ return true
+ }
+
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+ if _, exists := globalCustomMarshalerMap[t]; exists {
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) marshalerFromCustomMarshalerMap(t reflect.Type) (func(context.Context, interface{}) ([]byte, error), bool) {
+ if marshaler, exists := e.customMarshalerMap[t]; exists {
+ return marshaler, exists
+ }
+
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+ if marshaler, exists := globalCustomMarshalerMap[t]; exists {
+ return marshaler, exists
+ }
+ return nil, false
+}
+
+func (e *Encoder) canEncodeByMarshaler(v reflect.Value) bool {
+ if !v.CanInterface() {
+ return false
+ }
+ if e.existsTypeInCustomMarshalerMap(v.Type()) {
+ return true
+ }
+ iface := v.Interface()
+ switch iface.(type) {
+ case BytesMarshalerContext:
+ return true
+ case BytesMarshaler:
+ return true
+ case InterfaceMarshalerContext:
+ return true
+ case InterfaceMarshaler:
+ return true
+ case time.Time, *time.Time:
+ return true
+ case time.Duration:
+ return true
+ case encoding.TextMarshaler:
+ return true
+ case jsonMarshaler:
+ return e.useJSONMarshaler
+ }
+ return false
+}
+
+func (e *Encoder) encodeByMarshaler(ctx context.Context, v reflect.Value, column int) (ast.Node, error) {
+ iface := v.Interface()
+
+ if marshaler, exists := e.marshalerFromCustomMarshalerMap(v.Type()); exists {
+ doc, err := marshaler(ctx, iface)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(BytesMarshalerContext); ok {
+ doc, err := marshaler.MarshalYAML(ctx)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(BytesMarshaler); ok {
+ doc, err := marshaler.MarshalYAML()
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(InterfaceMarshalerContext); ok {
+ marshalV, err := marshaler.MarshalYAML(ctx)
+ if err != nil {
+ return nil, err
+ }
+ return e.encodeValue(ctx, reflect.ValueOf(marshalV), column)
+ }
+
+ if marshaler, ok := iface.(InterfaceMarshaler); ok {
+ marshalV, err := marshaler.MarshalYAML()
+ if err != nil {
+ return nil, err
+ }
+ return e.encodeValue(ctx, reflect.ValueOf(marshalV), column)
+ }
+
+ if t, ok := iface.(time.Time); ok {
+ return e.encodeTime(t, column), nil
+ }
+ // Handle *time.Time explicitly since it implements TextMarshaler and shouldn't be treated as plain text
+ if t, ok := iface.(*time.Time); ok && t != nil {
+ return e.encodeTime(*t, column), nil
+ }
+
+ if t, ok := iface.(time.Duration); ok {
+ return e.encodeDuration(t, column), nil
+ }
+
+ if marshaler, ok := iface.(encoding.TextMarshaler); ok {
+ text, err := marshaler.MarshalText()
+ if err != nil {
+ return nil, err
+ }
+ node := e.encodeString(string(text), column)
+ return node, nil
+ }
+
+ if e.useJSONMarshaler {
+ if marshaler, ok := iface.(jsonMarshaler); ok {
+ jsonBytes, err := marshaler.MarshalJSON()
+ if err != nil {
+ return nil, err
+ }
+ doc, err := JSONToYAML(jsonBytes)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+ }
+
+ return nil, errors.New("does not implemented Marshaler")
+}
+
+func (e *Encoder) encodeValue(ctx context.Context, v reflect.Value, column int) (ast.Node, error) {
+ if e.isInvalidValue(v) {
+ return e.encodeNil(), nil
+ }
+ if e.canEncodeByMarshaler(v) {
+ node, err := e.encodeByMarshaler(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+ switch v.Type().Kind() {
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return e.encodeInt(v.Int()), nil
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64:
+ return e.encodeUint(v.Uint()), nil
+ case reflect.Float32:
+ return e.encodeFloat(v.Float(), 32), nil
+ case reflect.Float64:
+ return e.encodeFloat(v.Float(), 64), nil
+ case reflect.Ptr:
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeValue(ctx, v.Elem(), column)
+ case reflect.Interface:
+ return e.encodeValue(ctx, v.Elem(), column)
+ case reflect.String:
+ return e.encodeString(v.String(), column), nil
+ case reflect.Bool:
+ return e.encodeBool(v.Bool()), nil
+ case reflect.Slice:
+ if mapSlice, ok := v.Interface().(MapSlice); ok {
+ return e.encodeMapSlice(ctx, mapSlice, column)
+ }
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeSlice(ctx, v)
+ case reflect.Array:
+ return e.encodeArray(ctx, v)
+ case reflect.Struct:
+ if v.CanInterface() {
+ if mapItem, ok := v.Interface().(MapItem); ok {
+ return e.encodeMapItem(ctx, mapItem, column)
+ }
+ if t, ok := v.Interface().(time.Time); ok {
+ return e.encodeTime(t, column), nil
+ }
+ }
+ return e.encodeStruct(ctx, v, column)
+ case reflect.Map:
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeMap(ctx, v, column)
+ default:
+ return nil, fmt.Errorf("unknown value type %s", v.Type().String())
+ }
+}
+
+func (e *Encoder) encodePtrAnchor(v reflect.Value, column int) ast.Node {
+ anchorName, exists := e.getAnchor(v.Pointer())
+ if !exists {
+ return nil
+ }
+ aliasName := anchorName
+ alias := ast.Alias(token.New("*", "*", e.pos(column)))
+ alias.Value = ast.String(token.New(aliasName, aliasName, e.pos(column)))
+ e.setSmartAlias(aliasName, v.Pointer())
+ return alias
+}
+
+func (e *Encoder) pos(column int) *token.Position {
+ return &token.Position{
+ Line: e.line,
+ Column: column,
+ Offset: e.offset,
+ IndentNum: e.indentNum,
+ IndentLevel: e.indentLevel,
+ }
+}
+
+func (e *Encoder) encodeNil() *ast.NullNode {
+ value := "null"
+ return ast.Null(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeInt(v int64) *ast.IntegerNode {
+ value := strconv.FormatInt(v, 10)
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeUint(v uint64) *ast.IntegerNode {
+ value := strconv.FormatUint(v, 10)
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeFloat(v float64, bitSize int) ast.Node {
+ if v == math.Inf(0) {
+ value := ".inf"
+ return ast.Infinity(token.New(value, value, e.pos(e.column)))
+ } else if v == math.Inf(-1) {
+ value := "-.inf"
+ return ast.Infinity(token.New(value, value, e.pos(e.column)))
+ } else if math.IsNaN(v) {
+ value := ".nan"
+ return ast.Nan(token.New(value, value, e.pos(e.column)))
+ }
+ value := strconv.FormatFloat(v, 'g', -1, bitSize)
+ if !strings.Contains(value, ".") && !strings.Contains(value, "e") {
+ if e.autoInt {
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+ }
+ // append x.0 suffix to keep float value context
+ value = fmt.Sprintf("%s.0", value)
+ }
+ return ast.Float(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) isNeedQuoted(v string) bool {
+ if e.isJSONStyle {
+ return true
+ }
+ if e.useLiteralStyleIfMultiline && strings.ContainsAny(v, "\n\r") {
+ return false
+ }
+ if e.isFlowStyle && strings.ContainsAny(v, `]},'"`) {
+ return true
+ }
+ if e.isFlowStyle {
+ for i := 0; i < len(v); i++ {
+ if v[i] != ':' {
+ continue
+ }
+ if i+1 < len(v) && v[i+1] == '/' {
+ continue
+ }
+ return true
+ }
+ }
+ if token.IsNeedQuoted(v) {
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) encodeString(v string, column int) *ast.StringNode {
+ if e.isNeedQuoted(v) {
+ if e.singleQuote {
+ v = quoteWith(v, '\'')
+ } else {
+ v = strconv.Quote(v)
+ }
+ }
+ return ast.String(token.New(v, v, e.pos(column)))
+}
+
+func (e *Encoder) encodeBool(v bool) *ast.BoolNode {
+ value := strconv.FormatBool(v)
+ return ast.Bool(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeSlice(ctx context.Context, value reflect.Value) (*ast.SequenceNode, error) {
+ if e.indentSequence {
+ e.column += e.indentNum
+ defer func() { e.column -= e.indentNum }()
+ }
+ column := e.column
+ sequence := ast.Sequence(token.New("-", "-", e.pos(column)), e.isFlowStyle)
+ for i := 0; i < value.Len(); i++ {
+ node, err := e.encodeValue(ctx, value.Index(i), column)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, node)
+ }
+ return sequence, nil
+}
+
+func (e *Encoder) encodeArray(ctx context.Context, value reflect.Value) (*ast.SequenceNode, error) {
+ if e.indentSequence {
+ e.column += e.indentNum
+ defer func() { e.column -= e.indentNum }()
+ }
+ column := e.column
+ sequence := ast.Sequence(token.New("-", "-", e.pos(column)), e.isFlowStyle)
+ for i := 0; i < value.Len(); i++ {
+ node, err := e.encodeValue(ctx, value.Index(i), column)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, node)
+ }
+ return sequence, nil
+}
+
+func (e *Encoder) encodeMapItem(ctx context.Context, item MapItem, column int) (*ast.MappingValueNode, error) {
+ k := reflect.ValueOf(item.Key)
+ v := reflect.ValueOf(item.Value)
+ value, err := e.encodeValue(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(value) {
+ value.AddColumn(e.indentNum)
+ }
+ if e.isTagAndMapNode(value) {
+ value.AddColumn(e.indentNum)
+ }
+ return ast.MappingValue(
+ token.New("", "", e.pos(column)),
+ e.encodeString(k.Interface().(string), column),
+ value,
+ ), nil
+}
+
+func (e *Encoder) encodeMapSlice(ctx context.Context, value MapSlice, column int) (*ast.MappingNode, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ for _, item := range value {
+ encoded, err := e.encodeMapItem(ctx, item, column)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, encoded)
+ }
+ return node, nil
+}
+
+func (e *Encoder) isMapNode(node ast.Node) bool {
+ _, ok := node.(ast.MapNode)
+ return ok
+}
+
+func (e *Encoder) isTagAndMapNode(node ast.Node) bool {
+ tn, ok := node.(*ast.TagNode)
+ return ok && e.isMapNode(tn.Value)
+}
+
+func (e *Encoder) encodeMap(ctx context.Context, value reflect.Value, column int) (ast.Node, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ keys := make([]interface{}, len(value.MapKeys()))
+ for i, k := range value.MapKeys() {
+ keys[i] = k.Interface()
+ }
+ sort.Slice(keys, func(i, j int) bool {
+ return fmt.Sprint(keys[i]) < fmt.Sprint(keys[j])
+ })
+ for _, key := range keys {
+ k := reflect.ValueOf(key)
+ v := value.MapIndex(k)
+ encoded, err := e.encodeValue(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ if e.isTagAndMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ keyText := fmt.Sprint(key)
+ vRef := e.toPointer(v)
+
+ // during the second encoding, an anchor is assigned if it is found to be used by an alias.
+ if aliasName, exists := e.getSmartAlias(vRef); exists {
+ anchorName := aliasName
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = encoded
+ encoded = anchorNode
+ }
+
+ kn, err := e.encodeValue(ctx, reflect.ValueOf(key), column)
+ keyNode, ok := kn.(ast.MapKeyNode)
+ if !ok || err != nil {
+ keyNode = e.encodeString(fmt.Sprint(key), column)
+ }
+ node.Values = append(node.Values, ast.MappingValue(
+ nil,
+ keyNode,
+ encoded,
+ ))
+ e.setSmartAnchor(vRef, keyText)
+ }
+ return node, nil
+}
+
+// IsZeroer is used to check whether an object is zero to determine
+// whether it should be omitted when marshaling with the omitempty flag.
+// One notable implementation is time.Time.
+type IsZeroer interface {
+ IsZero() bool
+}
+
+func (e *Encoder) isOmittedByOmitZero(v reflect.Value) bool {
+ kind := v.Kind()
+ if z, ok := v.Interface().(IsZeroer); ok {
+ if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
+ return true
+ }
+ return z.IsZero()
+ }
+ switch kind {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr, reflect.Slice, reflect.Map:
+ return v.IsNil()
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Struct:
+ vt := v.Type()
+ for i := v.NumField() - 1; i >= 0; i-- {
+ if vt.Field(i).PkgPath != "" {
+ continue // private field
+ }
+ if !e.isOmittedByOmitZero(v.Field(i)) {
+ return false
+ }
+ }
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) isOmittedByOmitEmptyOption(v reflect.Value) bool {
+ switch v.Kind() {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr:
+ return v.IsNil()
+ case reflect.Slice, reflect.Map:
+ return v.Len() == 0
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ }
+ return false
+}
+
+// The current implementation of the omitempty tag combines the functionality of encoding/json's omitempty and omitzero tags.
+// This stems from a historical decision to respect the implementation of gopkg.in/yaml.v2, but it has caused confusion,
+// so we are working to integrate it into the functionality of encoding/json. (However, this will take some time.)
+// In the current implementation, in addition to the exclusion conditions of omitempty,
+// if a type implements IsZero, that implementation will be used.
+// Furthermore, for non-pointer structs, if all fields are eligible for exclusion,
+// the struct itself will also be excluded. These behaviors are originally the functionality of omitzero.
+func (e *Encoder) isOmittedByOmitEmptyTag(v reflect.Value) bool {
+ kind := v.Kind()
+ if z, ok := v.Interface().(IsZeroer); ok {
+ if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
+ return true
+ }
+ return z.IsZero()
+ }
+ switch kind {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr:
+ return v.IsNil()
+ case reflect.Slice, reflect.Map:
+ return v.Len() == 0
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Struct:
+ vt := v.Type()
+ for i := v.NumField() - 1; i >= 0; i-- {
+ if vt.Field(i).PkgPath != "" {
+ continue // private field
+ }
+ if !e.isOmittedByOmitEmptyTag(v.Field(i)) {
+ return false
+ }
+ }
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) encodeTime(v time.Time, column int) *ast.StringNode {
+ value := v.Format(time.RFC3339Nano)
+ if e.isJSONStyle {
+ value = strconv.Quote(value)
+ }
+ return ast.String(token.New(value, value, e.pos(column)))
+}
+
+func (e *Encoder) encodeDuration(v time.Duration, column int) *ast.StringNode {
+ value := v.String()
+ if e.isJSONStyle {
+ value = strconv.Quote(value)
+ }
+ return ast.String(token.New(value, value, e.pos(column)))
+}
+
+func (e *Encoder) encodeAnchor(anchorName string, value ast.Node, fieldValue reflect.Value, column int) (*ast.AnchorNode, error) {
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = value
+ if e.anchorCallback != nil {
+ if err := e.anchorCallback(anchorNode, fieldValue.Interface()); err != nil {
+ return nil, err
+ }
+ if snode, ok := anchorNode.Name.(*ast.StringNode); ok {
+ anchorName = snode.Value
+ }
+ }
+ if fieldValue.Kind() == reflect.Ptr {
+ e.setAnchor(fieldValue.Pointer(), anchorName)
+ }
+ return anchorNode, nil
+}
+
+func (e *Encoder) encodeStruct(ctx context.Context, value reflect.Value, column int) (ast.Node, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ structType := value.Type()
+ fieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return nil, err
+ }
+ hasInlineAnchorField := false
+ var inlineAnchorValue reflect.Value
+ for i := 0; i < value.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ fieldValue := value.FieldByName(field.Name)
+ sf := fieldMap[field.Name]
+ if (e.omitZero || sf.IsOmitZero) && e.isOmittedByOmitZero(fieldValue) {
+ // omit encoding by omitzero tag or OmitZero option.
+ continue
+ }
+ if e.omitEmpty && e.isOmittedByOmitEmptyOption(fieldValue) {
+ // omit encoding by OmitEmpty option.
+ continue
+ }
+ if sf.IsOmitEmpty && e.isOmittedByOmitEmptyTag(fieldValue) {
+ // omit encoding by omitempty tag.
+ continue
+ }
+ ve := e
+ if !e.isFlowStyle && sf.IsFlow {
+ ve = &Encoder{}
+ *ve = *e
+ ve.isFlowStyle = true
+ }
+ encoded, err := ve.encodeValue(ctx, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ var key ast.MapKeyNode = e.encodeString(sf.RenderName, column)
+ switch {
+ case encoded.Type() == ast.AliasType:
+ if aliasName := sf.AliasName; aliasName != "" {
+ alias, ok := encoded.(*ast.AliasNode)
+ if !ok {
+ return nil, errors.ErrUnexpectedNodeType(encoded.Type(), ast.AliasType, encoded.GetToken())
+ }
+ got := alias.Value.String()
+ if aliasName != got {
+ return nil, fmt.Errorf("expected alias name is %q but got %q", aliasName, got)
+ }
+ }
+ if sf.IsInline {
+ // if both used alias and inline, output `<<: *alias`
+ key = ast.MergeKey(token.New("<<", "<<", e.pos(column)))
+ }
+ case sf.AnchorName != "":
+ anchorNode, err := e.encodeAnchor(sf.AnchorName, encoded, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ encoded = anchorNode
+ case sf.IsInline:
+ isAutoAnchor := sf.IsAutoAnchor
+ if !hasInlineAnchorField {
+ hasInlineAnchorField = isAutoAnchor
+ }
+ if isAutoAnchor {
+ inlineAnchorValue = fieldValue
+ }
+ mapNode, ok := encoded.(ast.MapNode)
+ if !ok {
+ // if an inline field is null, skip encoding it
+ if _, ok := encoded.(*ast.NullNode); ok {
+ continue
+ }
+ return nil, errors.New("inline value is must be map or struct type")
+ }
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ mapKey := mapIter.Key()
+ mapValue := mapIter.Value()
+ keyName := mapKey.GetToken().Value
+ if fieldMap.isIncludedRenderName(keyName) {
+ // if declared the same key name, skip encoding this field
+ continue
+ }
+ mapKey.AddColumn(-e.indentNum)
+ mapValue.AddColumn(-e.indentNum)
+ node.Values = append(node.Values, ast.MappingValue(nil, mapKey, mapValue))
+ }
+ continue
+ case sf.IsAutoAnchor:
+ anchorNode, err := e.encodeAnchor(sf.RenderName, encoded, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ encoded = anchorNode
+ }
+ node.Values = append(node.Values, ast.MappingValue(nil, key, encoded))
+ }
+ if hasInlineAnchorField {
+ node.AddColumn(e.indentNum)
+ anchorName := "anchor"
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = node
+ if e.anchorCallback != nil {
+ if err := e.anchorCallback(anchorNode, value.Addr().Interface()); err != nil {
+ return nil, err
+ }
+ if snode, ok := anchorNode.Name.(*ast.StringNode); ok {
+ anchorName = snode.Value
+ }
+ }
+ if inlineAnchorValue.Kind() == reflect.Ptr {
+ e.setAnchor(inlineAnchorValue.Pointer(), anchorName)
+ }
+ return anchorNode, nil
+ }
+ return node, nil
+}
+
+func (e *Encoder) toPointer(v reflect.Value) uintptr {
+ if e.isInvalidValue(v) {
+ return 0
+ }
+
+ switch v.Type().Kind() {
+ case reflect.Ptr:
+ return v.Pointer()
+ case reflect.Interface:
+ return e.toPointer(v.Elem())
+ case reflect.Slice:
+ return v.Pointer()
+ case reflect.Map:
+ return v.Pointer()
+ }
+ return 0
+}
+
+func (e *Encoder) clearSmartAnchorRef() {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.anchorRefToName = make(map[uintptr]string)
+ e.anchorNameMap = make(map[string]struct{})
+}
+
+func (e *Encoder) setSmartAnchor(ptr uintptr, name string) {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.setAnchor(ptr, e.generateAnchorName(name))
+}
+
+func (e *Encoder) setAnchor(ptr uintptr, name string) {
+ if ptr == 0 {
+ return
+ }
+ if name == "" {
+ return
+ }
+ e.anchorRefToName[ptr] = name
+ e.anchorNameMap[name] = struct{}{}
+}
+
+func (e *Encoder) generateAnchorName(base string) string {
+ if _, exists := e.anchorNameMap[base]; !exists {
+ return base
+ }
+ for i := 1; i < 100; i++ {
+ name := base + strconv.Itoa(i)
+ if _, exists := e.anchorNameMap[name]; exists {
+ continue
+ }
+ return name
+ }
+ return ""
+}
+
+func (e *Encoder) getAnchor(ref uintptr) (string, bool) {
+ anchorName, exists := e.anchorRefToName[ref]
+ return anchorName, exists
+}
+
+func (e *Encoder) setSmartAlias(name string, ref uintptr) {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.aliasRefToName[ref] = name
+}
+
+func (e *Encoder) getSmartAlias(ref uintptr) (string, bool) {
+ if !e.enableSmartAnchor {
+ return "", false
+ }
+ aliasName, exists := e.aliasRefToName[ref]
+ return aliasName, exists
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/error.go b/sesh/vendor/github.com/goccy/go-yaml/error.go
new file mode 100644
index 0000000..52d3e7e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/error.go
@@ -0,0 +1,77 @@
+package yaml
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+)
+
+var (
+ ErrInvalidQuery = errors.New("invalid query")
+ ErrInvalidPath = errors.New("invalid path instance")
+ ErrInvalidPathString = errors.New("invalid path string")
+ ErrNotFoundNode = errors.New("node not found")
+ ErrUnknownCommentPositionType = errors.New("unknown comment position type")
+ ErrInvalidCommentMapValue = errors.New("invalid comment map value. it must be not nil value")
+ ErrDecodeRequiredPointerType = errors.New("required pointer type value")
+ ErrExceededMaxDepth = errors.New("exceeded max depth")
+ FormatErrorWithToken = errors.FormatError
+)
+
+type (
+ SyntaxError = errors.SyntaxError
+ TypeError = errors.TypeError
+ OverflowError = errors.OverflowError
+ DuplicateKeyError = errors.DuplicateKeyError
+ UnknownFieldError = errors.UnknownFieldError
+ UnexpectedNodeTypeError = errors.UnexpectedNodeTypeError
+ Error = errors.Error
+)
+
+func ErrUnsupportedHeadPositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment head position for %s", node.Type())
+}
+
+func ErrUnsupportedLinePositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment line position for %s", node.Type())
+}
+
+func ErrUnsupportedFootPositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment foot position for %s", node.Type())
+}
+
+// IsInvalidQueryError whether err is ErrInvalidQuery or not.
+func IsInvalidQueryError(err error) bool {
+ return errors.Is(err, ErrInvalidQuery)
+}
+
+// IsInvalidPathError whether err is ErrInvalidPath or not.
+func IsInvalidPathError(err error) bool {
+ return errors.Is(err, ErrInvalidPath)
+}
+
+// IsInvalidPathStringError whether err is ErrInvalidPathString or not.
+func IsInvalidPathStringError(err error) bool {
+ return errors.Is(err, ErrInvalidPathString)
+}
+
+// IsNotFoundNodeError whether err is ErrNotFoundNode or not.
+func IsNotFoundNodeError(err error) bool {
+ return errors.Is(err, ErrNotFoundNode)
+}
+
+// IsInvalidTokenTypeError whether err is ast.ErrInvalidTokenType or not.
+func IsInvalidTokenTypeError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidTokenType)
+}
+
+// IsInvalidAnchorNameError whether err is ast.ErrInvalidAnchorName or not.
+func IsInvalidAnchorNameError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidAnchorName)
+}
+
+// IsInvalidAliasNameError whether err is ast.ErrInvalidAliasName or not.
+func IsInvalidAliasNameError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidAliasName)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go b/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go
new file mode 100644
index 0000000..b08a3fc
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go
@@ -0,0 +1,246 @@
+package errors
+
+import (
+ "errors"
+ "fmt"
+ "reflect"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/printer"
+ "github.com/goccy/go-yaml/token"
+)
+
+var (
+ As = errors.As
+ Is = errors.Is
+ New = errors.New
+)
+
+const (
+ defaultFormatColor = false
+ defaultIncludeSource = true
+)
+
+type Error interface {
+ error
+ GetToken() *token.Token
+ GetMessage() string
+ FormatError(bool, bool) string
+}
+
+var (
+ _ Error = new(SyntaxError)
+ _ Error = new(TypeError)
+ _ Error = new(OverflowError)
+ _ Error = new(DuplicateKeyError)
+ _ Error = new(UnknownFieldError)
+ _ Error = new(UnexpectedNodeTypeError)
+)
+
+type SyntaxError struct {
+ Message string
+ Token *token.Token
+}
+
+type TypeError struct {
+ DstType reflect.Type
+ SrcType reflect.Type
+ StructFieldName *string
+ Token *token.Token
+}
+
+type OverflowError struct {
+ DstType reflect.Type
+ SrcNum string
+ Token *token.Token
+}
+
+type DuplicateKeyError struct {
+ Message string
+ Token *token.Token
+}
+
+type UnknownFieldError struct {
+ Message string
+ Token *token.Token
+}
+
+type UnexpectedNodeTypeError struct {
+ Actual ast.NodeType
+ Expected ast.NodeType
+ Token *token.Token
+}
+
+// ErrSyntax create syntax error instance with message and token
+func ErrSyntax(msg string, tk *token.Token) *SyntaxError {
+ return &SyntaxError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+// ErrOverflow creates an overflow error instance with message and a token.
+func ErrOverflow(dstType reflect.Type, num string, tk *token.Token) *OverflowError {
+ return &OverflowError{
+ DstType: dstType,
+ SrcNum: num,
+ Token: tk,
+ }
+}
+
+// ErrTypeMismatch cerates an type mismatch error instance with token.
+func ErrTypeMismatch(dstType, srcType reflect.Type, token *token.Token) *TypeError {
+ return &TypeError{
+ DstType: dstType,
+ SrcType: srcType,
+ Token: token,
+ }
+}
+
+// ErrDuplicateKey creates an duplicate key error instance with token.
+func ErrDuplicateKey(msg string, tk *token.Token) *DuplicateKeyError {
+ return &DuplicateKeyError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+// ErrUnknownField creates an unknown field error instance with token.
+func ErrUnknownField(msg string, tk *token.Token) *UnknownFieldError {
+ return &UnknownFieldError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+func ErrUnexpectedNodeType(actual, expected ast.NodeType, tk *token.Token) *UnexpectedNodeTypeError {
+ return &UnexpectedNodeTypeError{
+ Actual: actual,
+ Expected: expected,
+ Token: tk,
+ }
+}
+
+func (e *SyntaxError) GetMessage() string {
+ return e.Message
+}
+
+func (e *SyntaxError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *SyntaxError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *SyntaxError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *OverflowError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *OverflowError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *OverflowError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *OverflowError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *OverflowError) msg() string {
+ return fmt.Sprintf("cannot unmarshal %s into Go value of type %s ( overflow )", e.SrcNum, e.DstType)
+}
+
+func (e *TypeError) msg() string {
+ if e.StructFieldName != nil {
+ return fmt.Sprintf("cannot unmarshal %s into Go struct field %s of type %s", e.SrcType, *e.StructFieldName, e.DstType)
+ }
+ return fmt.Sprintf("cannot unmarshal %s into Go value of type %s", e.SrcType, e.DstType)
+}
+
+func (e *TypeError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *TypeError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *TypeError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *TypeError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *DuplicateKeyError) GetMessage() string {
+ return e.Message
+}
+
+func (e *DuplicateKeyError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *DuplicateKeyError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *DuplicateKeyError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *UnknownFieldError) GetMessage() string {
+ return e.Message
+}
+
+func (e *UnknownFieldError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *UnknownFieldError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *UnknownFieldError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *UnexpectedNodeTypeError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *UnexpectedNodeTypeError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *UnexpectedNodeTypeError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *UnexpectedNodeTypeError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *UnexpectedNodeTypeError) msg() string {
+ return fmt.Sprintf("%s was used where %s is expected", e.Actual.YAMLName(), e.Expected.YAMLName())
+}
+
+func FormatError(errMsg string, token *token.Token, colored, inclSource bool) string {
+ var pp printer.Printer
+ if token == nil {
+ return pp.PrintErrorMessage(errMsg, colored)
+ }
+ pos := fmt.Sprintf("[%d:%d] ", token.Position.Line, token.Position.Column)
+ msg := pp.PrintErrorMessage(fmt.Sprintf("%s%s", pos, errMsg), colored)
+ if inclSource {
+ msg += "\n" + pp.PrintErrorToken(token, colored)
+ }
+ return msg
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go b/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go
new file mode 100644
index 0000000..461dc36
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go
@@ -0,0 +1,541 @@
+package format
+
+import (
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/token"
+)
+
+func FormatNodeWithResolvedAlias(n ast.Node, anchorNodeMap map[string]ast.Node) string {
+ tk := getFirstToken(n)
+ if tk == nil {
+ return ""
+ }
+ formatter := newFormatter(tk, hasComment(n))
+ formatter.anchorNodeMap = anchorNodeMap
+ return formatter.format(n)
+}
+
+func FormatNode(n ast.Node) string {
+ tk := getFirstToken(n)
+ if tk == nil {
+ return ""
+ }
+ return newFormatter(tk, hasComment(n)).format(n)
+}
+
+func FormatFile(file *ast.File) string {
+ if len(file.Docs) == 0 {
+ return ""
+ }
+ tk := getFirstToken(file.Docs[0])
+ if tk == nil {
+ return ""
+ }
+ return newFormatter(tk, hasCommentFile(file)).formatFile(file)
+}
+
+func hasCommentFile(f *ast.File) bool {
+ for _, doc := range f.Docs {
+ if hasComment(doc.Body) {
+ return true
+ }
+ }
+ return false
+}
+
+func hasComment(n ast.Node) bool {
+ if n == nil {
+ return false
+ }
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ return hasComment(nn.Body)
+ case *ast.NullNode:
+ return nn.Comment != nil
+ case *ast.BoolNode:
+ return nn.Comment != nil
+ case *ast.IntegerNode:
+ return nn.Comment != nil
+ case *ast.FloatNode:
+ return nn.Comment != nil
+ case *ast.StringNode:
+ return nn.Comment != nil
+ case *ast.InfinityNode:
+ return nn.Comment != nil
+ case *ast.NanNode:
+ return nn.Comment != nil
+ case *ast.LiteralNode:
+ return nn.Comment != nil
+ case *ast.DirectiveNode:
+ if nn.Comment != nil {
+ return true
+ }
+ for _, value := range nn.Values {
+ if hasComment(value) {
+ return true
+ }
+ }
+ case *ast.TagNode:
+ if nn.Comment != nil {
+ return true
+ }
+ return hasComment(nn.Value)
+ case *ast.MappingNode:
+ if nn.Comment != nil || nn.FootComment != nil {
+ return true
+ }
+ for _, value := range nn.Values {
+ if value.Comment != nil || value.FootComment != nil {
+ return true
+ }
+ if hasComment(value.Key) {
+ return true
+ }
+ if hasComment(value.Value) {
+ return true
+ }
+ }
+ case *ast.MappingKeyNode:
+ return nn.Comment != nil
+ case *ast.MergeKeyNode:
+ return nn.Comment != nil
+ case *ast.SequenceNode:
+ if nn.Comment != nil || nn.FootComment != nil {
+ return true
+ }
+ for _, entry := range nn.Entries {
+ if entry.Comment != nil || entry.HeadComment != nil || entry.LineComment != nil {
+ return true
+ }
+ if hasComment(entry.Value) {
+ return true
+ }
+ }
+ case *ast.AnchorNode:
+ if nn.Comment != nil {
+ return true
+ }
+ if hasComment(nn.Name) || hasComment(nn.Value) {
+ return true
+ }
+ case *ast.AliasNode:
+ if nn.Comment != nil {
+ return true
+ }
+ if hasComment(nn.Value) {
+ return true
+ }
+ }
+ return false
+}
+
+func getFirstToken(n ast.Node) *token.Token {
+ if n == nil {
+ return nil
+ }
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ if nn.Start != nil {
+ return nn.Start
+ }
+ return getFirstToken(nn.Body)
+ case *ast.NullNode:
+ return nn.Token
+ case *ast.BoolNode:
+ return nn.Token
+ case *ast.IntegerNode:
+ return nn.Token
+ case *ast.FloatNode:
+ return nn.Token
+ case *ast.StringNode:
+ return nn.Token
+ case *ast.InfinityNode:
+ return nn.Token
+ case *ast.NanNode:
+ return nn.Token
+ case *ast.LiteralNode:
+ return nn.Start
+ case *ast.DirectiveNode:
+ return nn.Start
+ case *ast.TagNode:
+ return nn.Start
+ case *ast.MappingNode:
+ if nn.IsFlowStyle {
+ return nn.Start
+ }
+ if len(nn.Values) == 0 {
+ return nn.Start
+ }
+ return getFirstToken(nn.Values[0].Key)
+ case *ast.MappingKeyNode:
+ return nn.Start
+ case *ast.MergeKeyNode:
+ return nn.Token
+ case *ast.SequenceNode:
+ return nn.Start
+ case *ast.AnchorNode:
+ return nn.Start
+ case *ast.AliasNode:
+ return nn.Start
+ }
+ return nil
+}
+
+type Formatter struct {
+ existsComment bool
+ tokenToOriginMap map[*token.Token]string
+ anchorNodeMap map[string]ast.Node
+}
+
+func newFormatter(tk *token.Token, existsComment bool) *Formatter {
+ tokenToOriginMap := make(map[*token.Token]string)
+ for tk.Prev != nil {
+ tk = tk.Prev
+ }
+ tokenToOriginMap[tk] = tk.Origin
+
+ var origin string
+ for tk.Next != nil {
+ tk = tk.Next
+ if tk.Type == token.CommentType {
+ origin += strings.Repeat("\n", strings.Count(normalizeNewLineChars(tk.Origin), "\n"))
+ continue
+ }
+ origin += tk.Origin
+ tokenToOriginMap[tk] = origin
+ origin = ""
+ }
+ return &Formatter{
+ existsComment: existsComment,
+ tokenToOriginMap: tokenToOriginMap,
+ }
+}
+
+func getIndentNumByFirstLineToken(tk *token.Token) int {
+ defaultIndent := tk.Position.Column - 1
+
+ // key: value
+ // ^
+ // next
+ if tk.Type == token.SequenceEntryType {
+ // If the current token is the sequence entry.
+ // the indent is calculated from the column value of the current token.
+ return defaultIndent
+ }
+
+ // key: value
+ // ^
+ // next
+ if tk.Next != nil && tk.Next.Type == token.MappingValueType {
+ // If the current token is the key in the mapping-value,
+ // the indent is calculated from the column value of the current token.
+ return defaultIndent
+ }
+
+ if tk.Prev == nil {
+ return defaultIndent
+ }
+ prev := tk.Prev
+
+ // key: value
+ // ^
+ // prev
+ if prev.Type == token.MappingValueType {
+ // If the current token is the value in the mapping-value,
+ // the indent is calculated from the column value of the key two steps back.
+ if prev.Prev == nil {
+ return defaultIndent
+ }
+ return prev.Prev.Position.Column - 1
+ }
+
+ // - value
+ // ^
+ // prev
+ if prev.Type == token.SequenceEntryType {
+ // If the value is not a mapping-value and the previous token was a sequence entry,
+ // the indent is calculated using the column value of the sequence entry token.
+ return prev.Position.Column - 1
+ }
+
+ return defaultIndent
+}
+
+func (f *Formatter) format(n ast.Node) string {
+ return f.trimSpacePrefix(
+ f.trimIndentSpace(
+ getIndentNumByFirstLineToken(getFirstToken(n)),
+ f.trimNewLineCharPrefix(f.formatNode(n)),
+ ),
+ )
+}
+
+func (f *Formatter) formatFile(file *ast.File) string {
+ if len(file.Docs) == 0 {
+ return ""
+ }
+ var ret string
+ for _, doc := range file.Docs {
+ ret += f.formatDocument(doc)
+ }
+ return ret
+}
+
+func (f *Formatter) origin(tk *token.Token) string {
+ if tk == nil {
+ return ""
+ }
+ if f.existsComment {
+ return tk.Origin
+ }
+ return f.tokenToOriginMap[tk]
+}
+
+func (f *Formatter) formatDocument(n *ast.DocumentNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Body) + f.origin(n.End)
+}
+
+func (f *Formatter) formatNull(n *ast.NullNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatString(n *ast.StringNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatInteger(n *ast.IntegerNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatFloat(n *ast.FloatNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatBool(n *ast.BoolNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatInfinity(n *ast.InfinityNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatNan(n *ast.NanNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatLiteral(n *ast.LiteralNode) string {
+ return f.origin(n.Start) + f.formatCommentGroup(n.Comment) + f.origin(n.Value.Token)
+}
+
+func (f *Formatter) formatMergeKey(n *ast.MergeKeyNode) string {
+ return f.origin(n.Token)
+}
+
+func (f *Formatter) formatMappingValue(n *ast.MappingValueNode) string {
+ return f.formatCommentGroup(n.Comment) +
+ f.origin(n.Key.GetToken()) + ":" + f.formatCommentGroup(n.Key.GetComment()) + f.formatNode(n.Value) +
+ f.formatCommentGroup(n.FootComment)
+}
+
+func (f *Formatter) formatDirective(n *ast.DirectiveNode) string {
+ ret := f.origin(n.Start) + f.formatNode(n.Name)
+ for _, val := range n.Values {
+ ret += f.formatNode(val)
+ }
+ return ret
+}
+
+func (f *Formatter) formatMapping(n *ast.MappingNode) string {
+ var ret string
+ if n.IsFlowStyle {
+ ret = f.origin(n.Start)
+ } else {
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ for _, value := range n.Values {
+ if value.CollectEntry != nil {
+ ret += f.origin(value.CollectEntry)
+ }
+ ret += f.formatMappingValue(value)
+ }
+ if n.IsFlowStyle {
+ ret += f.origin(n.End)
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ return ret
+}
+
+func (f *Formatter) formatTag(n *ast.TagNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatMappingKey(n *ast.MappingKeyNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatSequence(n *ast.SequenceNode) string {
+ var ret string
+ if n.IsFlowStyle {
+ ret = f.origin(n.Start)
+ } else {
+ // add head comment.
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ for _, entry := range n.Entries {
+ ret += f.formatNode(entry)
+ }
+ if n.IsFlowStyle {
+ ret += f.origin(n.End)
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ ret += f.formatCommentGroup(n.FootComment)
+ return ret
+}
+
+func (f *Formatter) formatSequenceEntry(n *ast.SequenceEntryNode) string {
+ return f.formatCommentGroup(n.HeadComment) + f.origin(n.Start) + f.formatCommentGroup(n.LineComment) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatAnchor(n *ast.AnchorNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Name) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatAlias(n *ast.AliasNode) string {
+ if f.anchorNodeMap != nil {
+ anchorName := n.Value.GetToken().Value
+ node := f.anchorNodeMap[anchorName]
+ if node != nil {
+ formatted := f.formatNode(node)
+ // If formatted text contains newline characters, indentation needs to be considered.
+ if strings.Contains(formatted, "\n") {
+ // If the first character is not a newline, the first line should be output without indentation.
+ isIgnoredFirstLine := !strings.HasPrefix(formatted, "\n")
+ formatted = f.addIndentSpace(n.GetToken().Position.IndentNum, formatted, isIgnoredFirstLine)
+ }
+ return formatted
+ }
+ }
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatNode(n ast.Node) string {
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ return f.formatDocument(nn)
+ case *ast.NullNode:
+ return f.formatNull(nn)
+ case *ast.BoolNode:
+ return f.formatBool(nn)
+ case *ast.IntegerNode:
+ return f.formatInteger(nn)
+ case *ast.FloatNode:
+ return f.formatFloat(nn)
+ case *ast.StringNode:
+ return f.formatString(nn)
+ case *ast.InfinityNode:
+ return f.formatInfinity(nn)
+ case *ast.NanNode:
+ return f.formatNan(nn)
+ case *ast.LiteralNode:
+ return f.formatLiteral(nn)
+ case *ast.DirectiveNode:
+ return f.formatDirective(nn)
+ case *ast.TagNode:
+ return f.formatTag(nn)
+ case *ast.MappingNode:
+ return f.formatMapping(nn)
+ case *ast.MappingKeyNode:
+ return f.formatMappingKey(nn)
+ case *ast.MappingValueNode:
+ return f.formatMappingValue(nn)
+ case *ast.MergeKeyNode:
+ return f.formatMergeKey(nn)
+ case *ast.SequenceNode:
+ return f.formatSequence(nn)
+ case *ast.SequenceEntryNode:
+ return f.formatSequenceEntry(nn)
+ case *ast.AnchorNode:
+ return f.formatAnchor(nn)
+ case *ast.AliasNode:
+ return f.formatAlias(nn)
+ }
+ return ""
+}
+
+func (f *Formatter) formatCommentGroup(g *ast.CommentGroupNode) string {
+ if g == nil {
+ return ""
+ }
+ var ret string
+ for _, cm := range g.Comments {
+ ret += f.formatComment(cm)
+ }
+ return ret
+}
+
+func (f *Formatter) formatComment(n *ast.CommentNode) string {
+ if n == nil {
+ return ""
+ }
+ return n.Token.Origin
+}
+
+// nolint: unused
+func (f *Formatter) formatIndent(col int) string {
+ if col <= 1 {
+ return ""
+ }
+ return strings.Repeat(" ", col-1)
+}
+
+func (f *Formatter) trimNewLineCharPrefix(v string) string {
+ return strings.TrimLeftFunc(v, func(r rune) bool {
+ return r == '\n' || r == '\r'
+ })
+}
+
+func (f *Formatter) trimSpacePrefix(v string) string {
+ return strings.TrimLeftFunc(v, func(r rune) bool {
+ return r == ' '
+ })
+}
+
+func (f *Formatter) trimIndentSpace(trimIndentNum int, v string) string {
+ if trimIndentNum == 0 {
+ return v
+ }
+ lines := strings.Split(normalizeNewLineChars(v), "\n")
+ out := make([]string, 0, len(lines))
+ for _, line := range lines {
+ var cnt int
+ out = append(out, strings.TrimLeftFunc(line, func(r rune) bool {
+ cnt++
+ return r == ' ' && cnt <= trimIndentNum
+ }))
+ }
+ return strings.Join(out, "\n")
+}
+
+func (f *Formatter) addIndentSpace(indentNum int, v string, isIgnoredFirstLine bool) string {
+ if indentNum == 0 {
+ return v
+ }
+ indent := strings.Repeat(" ", indentNum)
+ lines := strings.Split(normalizeNewLineChars(v), "\n")
+ out := make([]string, 0, len(lines))
+ for idx, line := range lines {
+ if line == "" || (isIgnoredFirstLine && idx == 0) {
+ out = append(out, line)
+ continue
+ }
+ out = append(out, indent+line)
+ }
+ return strings.Join(out, "\n")
+}
+
+// normalizeNewLineChars normalize CRLF and CR to LF.
+func normalizeNewLineChars(v string) string {
+ return strings.ReplaceAll(strings.ReplaceAll(v, "\r\n", "\n"), "\r", "\n")
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go b/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go
new file mode 100644
index 0000000..3207f4f
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go
@@ -0,0 +1,23 @@
+package lexer
+
+import (
+ "io"
+
+ "github.com/goccy/go-yaml/scanner"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Tokenize split to token instances from string
+func Tokenize(src string) token.Tokens {
+ var s scanner.Scanner
+ s.Init(src)
+ var tokens token.Tokens
+ for {
+ subTokens, err := s.Scan()
+ if err == io.EOF {
+ break
+ }
+ tokens.Add(subTokens...)
+ }
+ return tokens
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/option.go b/sesh/vendor/github.com/goccy/go-yaml/option.go
new file mode 100644
index 0000000..12b8f27
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/option.go
@@ -0,0 +1,352 @@
+package yaml
+
+import (
+ "context"
+ "io"
+ "reflect"
+
+ "github.com/goccy/go-yaml/ast"
+)
+
+// DecodeOption functional option type for Decoder
+type DecodeOption func(d *Decoder) error
+
+// ReferenceReaders pass to Decoder that reference to anchor defined by passed readers
+func ReferenceReaders(readers ...io.Reader) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ return nil
+ }
+}
+
+// ReferenceFiles pass to Decoder that reference to anchor defined by passed files
+func ReferenceFiles(files ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceFiles = files
+ return nil
+ }
+}
+
+// ReferenceDirs pass to Decoder that reference to anchor defined by files under the passed dirs
+func ReferenceDirs(dirs ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceDirs = dirs
+ return nil
+ }
+}
+
+// RecursiveDir search yaml file recursively from passed dirs by ReferenceDirs option
+func RecursiveDir(isRecursive bool) DecodeOption {
+ return func(d *Decoder) error {
+ d.isRecursiveDir = isRecursive
+ return nil
+ }
+}
+
+// Validator set StructValidator instance to Decoder
+func Validator(v StructValidator) DecodeOption {
+ return func(d *Decoder) error {
+ d.validator = v
+ return nil
+ }
+}
+
+// Strict enable DisallowUnknownField
+func Strict() DecodeOption {
+ return func(d *Decoder) error {
+ d.disallowUnknownField = true
+ return nil
+ }
+}
+
+// DisallowUnknownField causes the Decoder to return an error when the destination
+// is a struct and the input contains object keys which do not match any
+// non-ignored, exported fields in the destination.
+func DisallowUnknownField() DecodeOption {
+ return func(d *Decoder) error {
+ d.disallowUnknownField = true
+ return nil
+ }
+}
+
+// AllowFieldPrefixes, when paired with [DisallowUnknownField], allows fields
+// with the specified prefixes to bypass the unknown field check.
+func AllowFieldPrefixes(prefixes ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.allowedFieldPrefixes = append(d.allowedFieldPrefixes, prefixes...)
+ return nil
+ }
+}
+
+// AllowDuplicateMapKey ignore syntax error when mapping keys that are duplicates.
+func AllowDuplicateMapKey() DecodeOption {
+ return func(d *Decoder) error {
+ d.allowDuplicateMapKey = true
+ return nil
+ }
+}
+
+// UseOrderedMap can be interpreted as a map,
+// and uses MapSlice ( ordered map ) aggressively if there is no type specification
+func UseOrderedMap() DecodeOption {
+ return func(d *Decoder) error {
+ d.useOrderedMap = true
+ return nil
+ }
+}
+
+// UseJSONUnmarshaler if neither `BytesUnmarshaler` nor `InterfaceUnmarshaler` is implemented
+// and `UnmashalJSON([]byte)error` is implemented, convert the argument from `YAML` to `JSON` and then call it.
+func UseJSONUnmarshaler() DecodeOption {
+ return func(d *Decoder) error {
+ d.useJSONUnmarshaler = true
+ return nil
+ }
+}
+
+// CustomUnmarshaler overrides any decoding process for the type specified in generics.
+//
+// NOTE: If RegisterCustomUnmarshaler and CustomUnmarshaler of DecodeOption are specified for the same type,
+// the CustomUnmarshaler specified in DecodeOption takes precedence.
+func CustomUnmarshaler[T any](unmarshaler func(*T, []byte) error) DecodeOption {
+ return func(d *Decoder) error {
+ var typ *T
+ d.customUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(v.(*T), b)
+ }
+ return nil
+ }
+}
+
+// CustomUnmarshalerContext overrides any decoding process for the type specified in generics.
+// Similar to CustomUnmarshaler, but allows passing a context to the unmarshaler function.
+func CustomUnmarshalerContext[T any](unmarshaler func(context.Context, *T, []byte) error) DecodeOption {
+ return func(d *Decoder) error {
+ var typ *T
+ d.customUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(ctx, v.(*T), b)
+ }
+ return nil
+ }
+}
+
+// EncodeOption functional option type for Encoder
+type EncodeOption func(e *Encoder) error
+
+// Indent change indent number
+func Indent(spaces int) EncodeOption {
+ return func(e *Encoder) error {
+ e.indentNum = spaces
+ return nil
+ }
+}
+
+// IndentSequence causes sequence values to be indented the same value as Indent
+func IndentSequence(indent bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.indentSequence = indent
+ return nil
+ }
+}
+
+// UseSingleQuote determines if single or double quotes should be preferred for strings.
+func UseSingleQuote(sq bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.singleQuote = sq
+ return nil
+ }
+}
+
+// Flow encoding by flow style
+func Flow(isFlowStyle bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.isFlowStyle = isFlowStyle
+ return nil
+ }
+}
+
+// WithSmartAnchor when multiple map values share the same pointer,
+// an anchor is automatically assigned to the first occurrence, and aliases are used for subsequent elements.
+// The map key name is used as the anchor name by default.
+// If key names conflict, a suffix is automatically added to avoid collisions.
+// This is an experimental feature and cannot be used simultaneously with anchor tags.
+func WithSmartAnchor() EncodeOption {
+ return func(e *Encoder) error {
+ e.enableSmartAnchor = true
+ return nil
+ }
+}
+
+// UseLiteralStyleIfMultiline causes encoding multiline strings with a literal syntax,
+// no matter what characters they include
+func UseLiteralStyleIfMultiline(useLiteralStyleIfMultiline bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.useLiteralStyleIfMultiline = useLiteralStyleIfMultiline
+ return nil
+ }
+}
+
+// JSON encode in JSON format
+func JSON() EncodeOption {
+ return func(e *Encoder) error {
+ e.isJSONStyle = true
+ e.isFlowStyle = true
+ return nil
+ }
+}
+
+// MarshalAnchor call back if encoder find an anchor during encoding
+func MarshalAnchor(callback func(*ast.AnchorNode, interface{}) error) EncodeOption {
+ return func(e *Encoder) error {
+ e.anchorCallback = callback
+ return nil
+ }
+}
+
+// UseJSONMarshaler if neither `BytesMarshaler` nor `InterfaceMarshaler`
+// nor `encoding.TextMarshaler` is implemented and `MarshalJSON()([]byte, error)` is implemented,
+// call `MarshalJSON` to convert the returned `JSON` to `YAML` for processing.
+func UseJSONMarshaler() EncodeOption {
+ return func(e *Encoder) error {
+ e.useJSONMarshaler = true
+ return nil
+ }
+}
+
+// CustomMarshaler overrides any encoding process for the type specified in generics.
+//
+// NOTE: If type T implements MarshalYAML for pointer receiver, the type specified in CustomMarshaler must be *T.
+// If RegisterCustomMarshaler and CustomMarshaler of EncodeOption are specified for the same type,
+// the CustomMarshaler specified in EncodeOption takes precedence.
+func CustomMarshaler[T any](marshaler func(T) ([]byte, error)) EncodeOption {
+ return func(e *Encoder) error {
+ var typ T
+ e.customMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(v.(T))
+ }
+ return nil
+ }
+}
+
+// CustomMarshalerContext overrides any encoding process for the type specified in generics.
+// Similar to CustomMarshaler, but allows passing a context to the marshaler function.
+func CustomMarshalerContext[T any](marshaler func(context.Context, T) ([]byte, error)) EncodeOption {
+ return func(e *Encoder) error {
+ var typ T
+ e.customMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(ctx, v.(T))
+ }
+ return nil
+ }
+}
+
+// AutoInt automatically converts floating-point numbers to integers when the fractional part is zero.
+// For example, a value of 1.0 will be encoded as 1.
+func AutoInt() EncodeOption {
+ return func(e *Encoder) error {
+ e.autoInt = true
+ return nil
+ }
+}
+
+// OmitEmpty behaves in the same way as the interpretation of the omitempty tag in the encoding/json library.
+// set on all the fields.
+// In the current implementation, the omitempty tag is not implemented in the same way as encoding/json,
+// so please specify this option if you expect the same behavior.
+func OmitEmpty() EncodeOption {
+ return func(e *Encoder) error {
+ e.omitEmpty = true
+ return nil
+ }
+}
+
+// OmitZero forces the encoder to assume an `omitzero` struct tag is
+// set on all the fields. See `Marshal` commentary for the `omitzero` tag logic.
+func OmitZero() EncodeOption {
+ return func(e *Encoder) error {
+ e.omitZero = true
+ return nil
+ }
+}
+
+// CommentPosition type of the position for comment.
+type CommentPosition int
+
+const (
+ CommentHeadPosition CommentPosition = CommentPosition(iota)
+ CommentLinePosition
+ CommentFootPosition
+)
+
+func (p CommentPosition) String() string {
+ switch p {
+ case CommentHeadPosition:
+ return "Head"
+ case CommentLinePosition:
+ return "Line"
+ case CommentFootPosition:
+ return "Foot"
+ default:
+ return ""
+ }
+}
+
+// LineComment create a one-line comment for CommentMap.
+func LineComment(text string) *Comment {
+ return &Comment{
+ Texts: []string{text},
+ Position: CommentLinePosition,
+ }
+}
+
+// HeadComment create a multiline comment for CommentMap.
+func HeadComment(texts ...string) *Comment {
+ return &Comment{
+ Texts: texts,
+ Position: CommentHeadPosition,
+ }
+}
+
+// FootComment create a multiline comment for CommentMap.
+func FootComment(texts ...string) *Comment {
+ return &Comment{
+ Texts: texts,
+ Position: CommentFootPosition,
+ }
+}
+
+// Comment raw data for comment.
+type Comment struct {
+ Texts []string
+ Position CommentPosition
+}
+
+// CommentMap map of the position of the comment and the comment information.
+type CommentMap map[string][]*Comment
+
+// WithComment add a comment using the location and text information given in the CommentMap.
+func WithComment(cm CommentMap) EncodeOption {
+ return func(e *Encoder) error {
+ commentMap := map[*Path][]*Comment{}
+ for k, v := range cm {
+ path, err := PathString(k)
+ if err != nil {
+ return err
+ }
+ commentMap[path] = v
+ }
+ e.commentMap = commentMap
+ return nil
+ }
+}
+
+// CommentToMap apply the position and content of comments in a YAML document to a CommentMap.
+func CommentToMap(cm CommentMap) DecodeOption {
+ return func(d *Decoder) error {
+ if cm == nil {
+ return ErrInvalidCommentMapValue
+ }
+ d.toCommentMap = cm
+ return nil
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/color.go b/sesh/vendor/github.com/goccy/go-yaml/parser/color.go
new file mode 100644
index 0000000..aeee0dc
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/color.go
@@ -0,0 +1,28 @@
+package parser
+
+import "fmt"
+
+const (
+ colorFgHiBlack int = iota + 90
+ colorFgHiRed
+ colorFgHiGreen
+ colorFgHiYellow
+ colorFgHiBlue
+ colorFgHiMagenta
+ colorFgHiCyan
+)
+
+var colorTable = []int{
+ colorFgHiRed,
+ colorFgHiGreen,
+ colorFgHiYellow,
+ colorFgHiBlue,
+ colorFgHiMagenta,
+ colorFgHiCyan,
+}
+
+func colorize(idx int, content string) string {
+ colorIdx := idx % len(colorTable)
+ color := colorTable[colorIdx]
+ return fmt.Sprintf("\x1b[1;%dm", color) + content + "\x1b[22;0m"
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/context.go b/sesh/vendor/github.com/goccy/go-yaml/parser/context.go
new file mode 100644
index 0000000..1584b3e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/context.go
@@ -0,0 +1,187 @@
+package parser
+
+import (
+ "fmt"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// context context at parsing
+type context struct {
+ tokenRef *tokenRef
+ path string
+ isFlow bool
+}
+
+type tokenRef struct {
+ tokens []*Token
+ size int
+ idx int
+}
+
+var pathSpecialChars = []string{
+ "$", "*", ".", "[", "]",
+}
+
+func containsPathSpecialChar(path string) bool {
+ for _, char := range pathSpecialChars {
+ if strings.Contains(path, char) {
+ return true
+ }
+ }
+ return false
+}
+
+func normalizePath(path string) string {
+ if containsPathSpecialChar(path) {
+ return fmt.Sprintf("'%s'", path)
+ }
+ return path
+}
+
+func (c *context) currentToken() *Token {
+ if c.tokenRef.idx >= c.tokenRef.size {
+ return nil
+ }
+ return c.tokenRef.tokens[c.tokenRef.idx]
+}
+
+func (c *context) isComment() bool {
+ return c.currentToken().Type() == token.CommentType
+}
+
+func (c *context) nextToken() *Token {
+ if c.tokenRef.idx+1 >= c.tokenRef.size {
+ return nil
+ }
+ return c.tokenRef.tokens[c.tokenRef.idx+1]
+}
+
+func (c *context) nextNotCommentToken() *Token {
+ for i := c.tokenRef.idx + 1; i < c.tokenRef.size; i++ {
+ tk := c.tokenRef.tokens[i]
+ if tk.Type() == token.CommentType {
+ continue
+ }
+ return tk
+ }
+ return nil
+}
+
+func (c *context) isTokenNotFound() bool {
+ return c.currentToken() == nil
+}
+
+func (c *context) withGroup(g *TokenGroup) *context {
+ ctx := *c
+ ctx.tokenRef = &tokenRef{
+ tokens: g.Tokens,
+ size: len(g.Tokens),
+ }
+ return &ctx
+}
+
+func (c *context) withChild(path string) *context {
+ ctx := *c
+ ctx.path = c.path + "." + normalizePath(path)
+ return &ctx
+}
+
+func (c *context) withIndex(idx uint) *context {
+ ctx := *c
+ ctx.path = c.path + "[" + fmt.Sprint(idx) + "]"
+ return &ctx
+}
+
+func (c *context) withFlow(isFlow bool) *context {
+ ctx := *c
+ ctx.isFlow = isFlow
+ return &ctx
+}
+
+func newContext() *context {
+ return &context{
+ path: "$",
+ }
+}
+
+func (c *context) goNext() {
+ ref := c.tokenRef
+ if ref.size <= ref.idx+1 {
+ ref.idx = ref.size
+ } else {
+ ref.idx++
+ }
+}
+
+func (c *context) next() bool {
+ return c.tokenRef.idx < c.tokenRef.size
+}
+
+func (c *context) insertNullToken(tk *Token) *Token {
+ nullToken := c.createImplicitNullToken(tk)
+ c.insertToken(nullToken)
+ c.goNext()
+
+ return nullToken
+}
+
+func (c *context) addNullValueToken(tk *Token) *Token {
+ nullToken := c.createImplicitNullToken(tk)
+ rawTk := nullToken.RawToken()
+
+ // add space for map or sequence value.
+ rawTk.Position.Column++
+
+ c.addToken(nullToken)
+ c.goNext()
+
+ return nullToken
+}
+
+func (c *context) createImplicitNullToken(base *Token) *Token {
+ pos := *(base.RawToken().Position)
+ pos.Column++
+ tk := token.New("null", " null", &pos)
+ tk.Type = token.ImplicitNullType
+ return &Token{Token: tk}
+}
+
+func (c *context) insertToken(tk *Token) {
+ ref := c.tokenRef
+ idx := ref.idx
+ if ref.size < idx {
+ return
+ }
+ if ref.size == idx {
+ curToken := ref.tokens[ref.size-1]
+ tk.RawToken().Next = curToken.RawToken()
+ curToken.RawToken().Prev = tk.RawToken()
+
+ ref.tokens = append(ref.tokens, tk)
+ ref.size = len(ref.tokens)
+ return
+ }
+
+ curToken := ref.tokens[idx]
+ tk.RawToken().Next = curToken.RawToken()
+ curToken.RawToken().Prev = tk.RawToken()
+
+ ref.tokens = append(ref.tokens[:idx+1], ref.tokens[idx:]...)
+ ref.tokens[idx] = tk
+ ref.size = len(ref.tokens)
+}
+
+func (c *context) addToken(tk *Token) {
+ ref := c.tokenRef
+ lastTk := ref.tokens[ref.size-1]
+ if lastTk.Group != nil {
+ lastTk = lastTk.Group.Last()
+ }
+ lastTk.RawToken().Next = tk.RawToken()
+ tk.RawToken().Prev = lastTk.RawToken()
+
+ ref.tokens = append(ref.tokens, tk)
+ ref.size = len(ref.tokens)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/node.go b/sesh/vendor/github.com/goccy/go-yaml/parser/node.go
new file mode 100644
index 0000000..8d35554
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/node.go
@@ -0,0 +1,257 @@
+package parser
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/token"
+)
+
+func newMappingNode(ctx *context, tk *Token, isFlow bool, values ...*ast.MappingValueNode) (*ast.MappingNode, error) {
+ node := ast.Mapping(tk.RawToken(), isFlow, values...)
+ node.SetPath(ctx.path)
+ return node, nil
+}
+
+func newMappingValueNode(ctx *context, colonTk, entryTk *Token, key ast.MapKeyNode, value ast.Node) (*ast.MappingValueNode, error) {
+ node := ast.MappingValue(colonTk.RawToken(), key, value)
+ node.SetPath(ctx.path)
+ node.CollectEntry = entryTk.RawToken()
+ if key.GetToken().Position.Line == value.GetToken().Position.Line {
+ // originally key was commented, but now that null value has been added, value must be commented.
+ if err := setLineComment(ctx, value, colonTk); err != nil {
+ return nil, err
+ }
+ // set line comment by colonTk or entryTk.
+ if err := setLineComment(ctx, value, entryTk); err != nil {
+ return nil, err
+ }
+ } else {
+ if err := setLineComment(ctx, key, colonTk); err != nil {
+ return nil, err
+ }
+ // set line comment by colonTk or entryTk.
+ if err := setLineComment(ctx, key, entryTk); err != nil {
+ return nil, err
+ }
+ }
+ return node, nil
+}
+
+func newMappingKeyNode(ctx *context, tk *Token) (*ast.MappingKeyNode, error) {
+ node := ast.MappingKey(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newAnchorNode(ctx *context, tk *Token) (*ast.AnchorNode, error) {
+ node := ast.Anchor(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newAliasNode(ctx *context, tk *Token) (*ast.AliasNode, error) {
+ node := ast.Alias(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newDirectiveNode(ctx *context, tk *Token) (*ast.DirectiveNode, error) {
+ node := ast.Directive(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newMergeKeyNode(ctx *context, tk *Token) (*ast.MergeKeyNode, error) {
+ node := ast.MergeKey(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newNullNode(ctx *context, tk *Token) (*ast.NullNode, error) {
+ node := ast.Null(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newBoolNode(ctx *context, tk *Token) (*ast.BoolNode, error) {
+ node := ast.Bool(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newIntegerNode(ctx *context, tk *Token) (*ast.IntegerNode, error) {
+ node := ast.Integer(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newFloatNode(ctx *context, tk *Token) (*ast.FloatNode, error) {
+ node := ast.Float(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newInfinityNode(ctx *context, tk *Token) (*ast.InfinityNode, error) {
+ node := ast.Infinity(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newNanNode(ctx *context, tk *Token) (*ast.NanNode, error) {
+ node := ast.Nan(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newStringNode(ctx *context, tk *Token) (*ast.StringNode, error) {
+ node := ast.String(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newLiteralNode(ctx *context, tk *Token) (*ast.LiteralNode, error) {
+ node := ast.Literal(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newTagNode(ctx *context, tk *Token) (*ast.TagNode, error) {
+ node := ast.Tag(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newSequenceNode(ctx *context, tk *Token, isFlow bool) (*ast.SequenceNode, error) {
+ node := ast.Sequence(tk.RawToken(), isFlow)
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newTagDefaultScalarValueNode(ctx *context, tag *token.Token) (ast.ScalarNode, error) {
+ pos := *(tag.Position)
+ pos.Column++
+
+ var (
+ tk *Token
+ node ast.ScalarNode
+ )
+ switch token.ReservedTagKeyword(tag.Value) {
+ case token.IntegerTag:
+ tk = &Token{Token: token.New("0", "0", &pos)}
+ n, err := newIntegerNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.FloatTag:
+ tk = &Token{Token: token.New("0", "0", &pos)}
+ n, err := newFloatNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.StringTag, token.BinaryTag, token.TimestampTag:
+ tk = &Token{Token: token.New("", "", &pos)}
+ n, err := newStringNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.BooleanTag:
+ tk = &Token{Token: token.New("false", "false", &pos)}
+ n, err := newBoolNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.NullTag:
+ tk = &Token{Token: token.New("null", "null", &pos)}
+ n, err := newNullNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ default:
+ return nil, errors.ErrSyntax(fmt.Sprintf("cannot assign default value for %q tag", tag.Value), tag)
+ }
+ ctx.insertToken(tk)
+ ctx.goNext()
+ return node, nil
+}
+
+func setLineComment(ctx *context, node ast.Node, tk *Token) error {
+ if tk == nil || tk.LineComment == nil {
+ return nil
+ }
+ comment := ast.CommentGroup([]*token.Token{tk.LineComment})
+ comment.SetPath(ctx.path)
+ if err := node.SetComment(comment); err != nil {
+ return err
+ }
+ return nil
+}
+
+func setHeadComment(cm *ast.CommentGroupNode, value ast.Node) error {
+ if cm == nil {
+ return nil
+ }
+ switch n := value.(type) {
+ case *ast.MappingNode:
+ if len(n.Values) != 0 && value.GetComment() == nil {
+ cm.SetPath(n.Values[0].GetPath())
+ return n.Values[0].SetComment(cm)
+ }
+ case *ast.MappingValueNode:
+ cm.SetPath(n.GetPath())
+ return n.SetComment(cm)
+ }
+ cm.SetPath(value.GetPath())
+ return value.SetComment(cm)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/option.go b/sesh/vendor/github.com/goccy/go-yaml/parser/option.go
new file mode 100644
index 0000000..3121a64
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/option.go
@@ -0,0 +1,12 @@
+package parser
+
+// Option represents parser's option.
+type Option func(p *parser)
+
+// AllowDuplicateMapKey allow the use of keys with the same name in the same map,
+// but by default, this is not permitted.
+func AllowDuplicateMapKey() Option {
+ return func(p *parser) {
+ p.allowDuplicateMapKey = true
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go b/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go
new file mode 100644
index 0000000..f5bfd1a
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go
@@ -0,0 +1,1330 @@
+package parser
+
+import (
+ "fmt"
+ "os"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/lexer"
+ "github.com/goccy/go-yaml/token"
+)
+
+type Mode uint
+
+const (
+ ParseComments Mode = 1 << iota // parse comments and add them to AST
+)
+
+// ParseBytes parse from byte slice, and returns ast.File
+func ParseBytes(bytes []byte, mode Mode, opts ...Option) (*ast.File, error) {
+ tokens := lexer.Tokenize(string(bytes))
+ f, err := Parse(tokens, mode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return f, nil
+}
+
+// Parse parse from token instances, and returns ast.File
+func Parse(tokens token.Tokens, mode Mode, opts ...Option) (*ast.File, error) {
+ if tk := tokens.InvalidToken(); tk != nil {
+ return nil, errors.ErrSyntax(tk.Error, tk)
+ }
+ p, err := newParser(tokens, mode, opts)
+ if err != nil {
+ return nil, err
+ }
+ f, err := p.parse(newContext())
+ if err != nil {
+ return nil, err
+ }
+ return f, nil
+}
+
+// Parse parse from filename, and returns ast.File
+func ParseFile(filename string, mode Mode, opts ...Option) (*ast.File, error) {
+ file, err := os.ReadFile(filename)
+ if err != nil {
+ return nil, err
+ }
+ f, err := ParseBytes(file, mode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ f.Name = filename
+ return f, nil
+}
+
+type YAMLVersion string
+
+const (
+ YAML10 YAMLVersion = "1.0"
+ YAML11 YAMLVersion = "1.1"
+ YAML12 YAMLVersion = "1.2"
+ YAML13 YAMLVersion = "1.3"
+)
+
+var yamlVersionMap = map[string]YAMLVersion{
+ "1.0": YAML10,
+ "1.1": YAML11,
+ "1.2": YAML12,
+ "1.3": YAML13,
+}
+
+type parser struct {
+ tokens []*Token
+ pathMap map[string]ast.Node
+ yamlVersion YAMLVersion
+ allowDuplicateMapKey bool
+ secondaryTagDirective *ast.DirectiveNode
+}
+
+func newParser(tokens token.Tokens, mode Mode, opts []Option) (*parser, error) {
+ filteredTokens := []*token.Token{}
+ if mode&ParseComments != 0 {
+ filteredTokens = tokens
+ } else {
+ for _, tk := range tokens {
+ if tk.Type == token.CommentType {
+ continue
+ }
+ // keep prev/next reference between tokens containing comments
+ // https://github.com/goccy/go-yaml/issues/254
+ filteredTokens = append(filteredTokens, tk)
+ }
+ }
+ tks, err := CreateGroupedTokens(token.Tokens(filteredTokens))
+ if err != nil {
+ return nil, err
+ }
+ p := &parser{
+ tokens: tks,
+ pathMap: make(map[string]ast.Node),
+ }
+ for _, opt := range opts {
+ opt(p)
+ }
+ return p, nil
+}
+
+func (p *parser) parse(ctx *context) (*ast.File, error) {
+ file := &ast.File{Docs: []*ast.DocumentNode{}}
+ for _, token := range p.tokens {
+ doc, err := p.parseDocument(ctx, token.Group)
+ if err != nil {
+ return nil, err
+ }
+ file.Docs = append(file.Docs, doc)
+ }
+ return file, nil
+}
+
+func (p *parser) parseDocument(ctx *context, docGroup *TokenGroup) (*ast.DocumentNode, error) {
+ if len(docGroup.Tokens) == 0 {
+ return ast.Document(docGroup.RawToken(), nil), nil
+ }
+
+ p.pathMap = make(map[string]ast.Node)
+
+ var (
+ tokens = docGroup.Tokens
+ start *token.Token
+ end *token.Token
+ )
+ if docGroup.First().Type() == token.DocumentHeaderType {
+ start = docGroup.First().RawToken()
+ tokens = tokens[1:]
+ }
+ if docGroup.Last().Type() == token.DocumentEndType {
+ end = docGroup.Last().RawToken()
+ tokens = tokens[:len(tokens)-1]
+ defer func() {
+ // clear yaml version value if DocumentEnd token (...) is specified.
+ p.yamlVersion = ""
+ }()
+ }
+
+ if len(tokens) == 0 {
+ return ast.Document(docGroup.RawToken(), nil), nil
+ }
+
+ body, err := p.parseDocumentBody(ctx.withGroup(&TokenGroup{
+ Type: TokenGroupDocumentBody,
+ Tokens: tokens,
+ }))
+ if err != nil {
+ return nil, err
+ }
+ node := ast.Document(start, body)
+ node.End = end
+ return node, nil
+}
+
+func (p *parser) parseDocumentBody(ctx *context) (ast.Node, error) {
+ node, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if ctx.next() {
+ return nil, errors.ErrSyntax("value is not allowed in this context", ctx.currentToken().RawToken())
+ }
+ return node, nil
+}
+
+func (p *parser) parseToken(ctx *context, tk *Token) (ast.Node, error) {
+ switch tk.GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return p.parseMap(ctx)
+ case TokenGroupDirective:
+ node, err := p.parseDirective(ctx.withGroup(tk.Group), tk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupDirectiveName:
+ node, err := p.parseDirectiveName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupAnchor:
+ node, err := p.parseAnchor(ctx.withGroup(tk.Group), tk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupAnchorName:
+ anchor, err := p.parseAnchorName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", tk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+ case TokenGroupAlias:
+ node, err := p.parseAlias(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupLiteral, TokenGroupFolded:
+ node, err := p.parseLiteral(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupScalarTag:
+ node, err := p.parseTag(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ }
+ switch tk.Type() {
+ case token.CommentType:
+ return p.parseComment(ctx)
+ case token.TagType:
+ return p.parseTag(ctx)
+ case token.MappingStartType:
+ return p.parseFlowMap(ctx.withFlow(true))
+ case token.SequenceStartType:
+ return p.parseFlowSequence(ctx.withFlow(true))
+ case token.SequenceEntryType:
+ return p.parseSequence(ctx)
+ case token.SequenceEndType:
+ // SequenceEndType is always validated in parseFlowSequence.
+ // Therefore, if this is found in other cases, it is treated as a syntax error.
+ return nil, errors.ErrSyntax("could not find '[' character corresponding to ']'", tk.RawToken())
+ case token.MappingEndType:
+ // MappingEndType is always validated in parseFlowMap.
+ // Therefore, if this is found in other cases, it is treated as a syntax error.
+ return nil, errors.ErrSyntax("could not find '{' character corresponding to '}'", tk.RawToken())
+ case token.MappingValueType:
+ return nil, errors.ErrSyntax("found an invalid key for this map", tk.RawToken())
+ }
+ node, err := p.parseScalarValue(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+}
+
+func (p *parser) parseScalarValue(ctx *context, tk *Token) (ast.ScalarNode, error) {
+ if tk.Group != nil {
+ switch tk.GroupType() {
+ case TokenGroupAnchor:
+ return p.parseAnchor(ctx.withGroup(tk.Group), tk.Group)
+ case TokenGroupAnchorName:
+ anchor, err := p.parseAnchorName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", tk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+ case TokenGroupAlias:
+ return p.parseAlias(ctx.withGroup(tk.Group))
+ case TokenGroupLiteral, TokenGroupFolded:
+ return p.parseLiteral(ctx.withGroup(tk.Group))
+ case TokenGroupScalarTag:
+ return p.parseTag(ctx.withGroup(tk.Group))
+ default:
+ return nil, errors.ErrSyntax("unexpected scalar value", tk.RawToken())
+ }
+ }
+ switch tk.Type() {
+ case token.MergeKeyType:
+ return newMergeKeyNode(ctx, tk)
+ case token.NullType, token.ImplicitNullType:
+ return newNullNode(ctx, tk)
+ case token.BoolType:
+ return newBoolNode(ctx, tk)
+ case token.IntegerType, token.BinaryIntegerType, token.OctetIntegerType, token.HexIntegerType:
+ return newIntegerNode(ctx, tk)
+ case token.FloatType:
+ return newFloatNode(ctx, tk)
+ case token.InfinityType:
+ return newInfinityNode(ctx, tk)
+ case token.NanType:
+ return newNanNode(ctx, tk)
+ case token.StringType, token.SingleQuoteType, token.DoubleQuoteType:
+ return newStringNode(ctx, tk)
+ case token.TagType:
+ // this case applies when it is a scalar tag and its value does not exist.
+ // Examples of cases where the value does not exist include cases like `key: !!str,` or `!!str : value`.
+ return p.parseScalarTag(ctx)
+ }
+ return nil, errors.ErrSyntax("unexpected scalar value type", tk.RawToken())
+}
+
+func (p *parser) parseFlowMap(ctx *context) (*ast.MappingNode, error) {
+ node, err := newMappingNode(ctx, ctx.currentToken(), true)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip MappingStart token
+
+ isFirst := true
+ for ctx.next() {
+ tk := ctx.currentToken()
+ if tk.Type() == token.MappingEndType {
+ node.End = tk.RawToken()
+ break
+ }
+
+ var entryTk *Token
+ if tk.Type() == token.CollectEntryType {
+ entryTk = tk
+ ctx.goNext()
+ } else if !isFirst {
+ return nil, errors.ErrSyntax("',' or '}' must be specified", tk.RawToken())
+ }
+
+ if tk := ctx.currentToken(); tk.Type() == token.MappingEndType {
+ // this case is here: "{ elem, }".
+ // In this case, ignore the last element and break mapping parsing.
+ node.End = tk.RawToken()
+ break
+ }
+
+ mapKeyTk := ctx.currentToken()
+ switch mapKeyTk.GroupType() {
+ case TokenGroupMapKeyValue:
+ value, err := p.parseMapKeyValue(ctx.withGroup(mapKeyTk.Group), mapKeyTk.Group, entryTk)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, value)
+ ctx.goNext()
+ case TokenGroupMapKey:
+ key, err := p.parseMapKey(ctx.withGroup(mapKeyTk.Group), mapKeyTk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx := ctx.withChild(p.mapKeyText(key))
+ colonTk := mapKeyTk.Group.Last()
+ if p.isFlowMapDelim(ctx.nextToken()) {
+ value, err := newNullNode(ctx, ctx.insertNullToken(colonTk))
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, colonTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ ctx.goNext()
+ } else {
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find map value", colonTk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, colonTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ }
+ default:
+ if !p.isFlowMapDelim(ctx.nextToken()) {
+ errTk := mapKeyTk
+ if errTk == nil {
+ errTk = tk
+ }
+ return nil, errors.ErrSyntax("could not find flow map content", errTk.RawToken())
+ }
+ key, err := p.parseScalarValue(ctx, mapKeyTk)
+ if err != nil {
+ return nil, err
+ }
+ value, err := newNullNode(ctx, ctx.insertNullToken(mapKeyTk))
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, mapKeyTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ ctx.goNext()
+ }
+ isFirst = false
+ }
+ if node.End == nil {
+ return nil, errors.ErrSyntax("could not find flow mapping end token '}'", node.Start)
+ }
+
+ // set line comment if exists. e.g.) } # comment
+ if err := setLineComment(ctx, node, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip mapping end token.
+ return node, nil
+}
+
+func (p *parser) isFlowMapDelim(tk *Token) bool {
+ return tk.Type() == token.MappingEndType || tk.Type() == token.CollectEntryType
+}
+
+func (p *parser) parseMap(ctx *context) (*ast.MappingNode, error) {
+ keyTk := ctx.currentToken()
+ if keyTk.Group == nil {
+ return nil, errors.ErrSyntax("unexpected map key", keyTk.RawToken())
+ }
+ var keyValueNode *ast.MappingValueNode
+ if keyTk.GroupType() == TokenGroupMapKeyValue {
+ node, err := p.parseMapKeyValue(ctx.withGroup(keyTk.Group), keyTk.Group, nil)
+ if err != nil {
+ return nil, err
+ }
+ keyValueNode = node
+ ctx.goNext()
+ if err := p.validateMapKeyValueNextToken(ctx, keyTk, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ } else {
+ key, err := p.parseMapKey(ctx.withGroup(keyTk.Group), keyTk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+
+ valueTk := ctx.currentToken()
+ if keyTk.Line() == valueTk.Line() && valueTk.Type() == token.SequenceEntryType {
+ return nil, errors.ErrSyntax("block sequence entries are not allowed in this context", valueTk.RawToken())
+ }
+ ctx := ctx.withChild(p.mapKeyText(key))
+ value, err := p.parseMapValue(ctx, key, keyTk.Group.Last())
+ if err != nil {
+ return nil, err
+ }
+ node, err := newMappingValueNode(ctx, keyTk.Group.Last(), nil, key, value)
+ if err != nil {
+ return nil, err
+ }
+ keyValueNode = node
+ }
+ mapNode, err := newMappingNode(ctx, &Token{Token: keyValueNode.GetToken()}, false, keyValueNode)
+ if err != nil {
+ return nil, err
+ }
+ var tk *Token
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ } else {
+ tk = ctx.currentToken()
+ }
+ for tk.Column() == keyTk.Column() {
+ typ := tk.Type()
+ if ctx.isFlow && typ == token.SequenceEndType {
+ // [
+ // key: value
+ // ] <=
+ break
+ }
+ if !p.isMapToken(tk) {
+ return nil, errors.ErrSyntax("non-map value is specified", tk.RawToken())
+ }
+ cm := p.parseHeadComment(ctx)
+ if typ == token.MappingEndType {
+ // a: {
+ // b: c
+ // } <=
+ ctx.goNext()
+ break
+ }
+ node, err := p.parseMap(ctx)
+ if err != nil {
+ return nil, err
+ }
+ if len(node.Values) != 0 {
+ if err := setHeadComment(cm, node.Values[0]); err != nil {
+ return nil, err
+ }
+ }
+ mapNode.Values = append(mapNode.Values, node.Values...)
+ if node.FootComment != nil {
+ mapNode.Values[len(mapNode.Values)-1].FootComment = node.FootComment
+ }
+ tk = ctx.currentToken()
+ }
+ if ctx.isComment() {
+ if keyTk.Column() <= ctx.currentToken().Column() {
+ // If the comment is in the same or deeper column as the last element column in map value,
+ // treat it as a footer comment for the last element.
+ if len(mapNode.Values) == 1 {
+ mapNode.Values[0].FootComment = p.parseFootComment(ctx, keyTk.Column())
+ mapNode.Values[0].FootComment.SetPath(mapNode.Values[0].Key.GetPath())
+ } else {
+ mapNode.FootComment = p.parseFootComment(ctx, keyTk.Column())
+ mapNode.FootComment.SetPath(mapNode.GetPath())
+ }
+ }
+ }
+ return mapNode, nil
+}
+
+func (p *parser) validateMapKeyValueNextToken(ctx *context, keyTk, tk *Token) error {
+ if tk == nil {
+ return nil
+ }
+ if tk.Column() <= keyTk.Column() {
+ return nil
+ }
+ if ctx.isComment() {
+ return nil
+ }
+ if ctx.isFlow && (tk.Type() == token.CollectEntryType || tk.Type() == token.SequenceEndType) {
+ return nil
+ }
+ // a: b
+ // c <= this token is invalid.
+ return errors.ErrSyntax("value is not allowed in this context. map key-value is pre-defined", tk.RawToken())
+}
+
+func (p *parser) isMapToken(tk *Token) bool {
+ if tk.Group == nil {
+ return tk.Type() == token.MappingStartType || tk.Type() == token.MappingEndType
+ }
+ g := tk.Group
+ return g.Type == TokenGroupMapKey || g.Type == TokenGroupMapKeyValue
+}
+
+func (p *parser) parseMapKeyValue(ctx *context, g *TokenGroup, entryTk *Token) (*ast.MappingValueNode, error) {
+ if g.Type != TokenGroupMapKeyValue {
+ return nil, errors.ErrSyntax("unexpected map key-value pair", g.RawToken())
+ }
+ if g.First().Group == nil {
+ return nil, errors.ErrSyntax("unexpected map key", g.RawToken())
+ }
+ keyGroup := g.First().Group
+ key, err := p.parseMapKey(ctx.withGroup(keyGroup), keyGroup)
+ if err != nil {
+ return nil, err
+ }
+
+ c := ctx.withChild(p.mapKeyText(key))
+ value, err := p.parseToken(c, g.Last())
+ if err != nil {
+ return nil, err
+ }
+ return newMappingValueNode(c, keyGroup.Last(), entryTk, key, value)
+}
+
+func (p *parser) parseMapKey(ctx *context, g *TokenGroup) (ast.MapKeyNode, error) {
+ if g.Type != TokenGroupMapKey {
+ return nil, errors.ErrSyntax("unexpected map key", g.RawToken())
+ }
+ if g.First().Type() == token.MappingKeyType {
+ mapKeyTk := g.First()
+ if mapKeyTk.Group != nil {
+ ctx = ctx.withGroup(mapKeyTk.Group)
+ }
+ key, err := newMappingKeyNode(ctx, mapKeyTk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip mapping key token
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find value for mapping key", mapKeyTk.RawToken())
+ }
+
+ scalar, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ key.Value = scalar
+ keyText := p.mapKeyText(scalar)
+ keyPath := ctx.withChild(keyText).path
+ key.SetPath(keyPath)
+ if err := p.validateMapKey(ctx, key.GetToken(), keyPath, g.Last()); err != nil {
+ return nil, err
+ }
+ p.pathMap[keyPath] = key
+ return key, nil
+ }
+ if g.Last().Type() != token.MappingValueType {
+ return nil, errors.ErrSyntax("expected map key-value delimiter ':'", g.Last().RawToken())
+ }
+
+ scalar, err := p.parseScalarValue(ctx, g.First())
+ if err != nil {
+ return nil, err
+ }
+ key, ok := scalar.(ast.MapKeyNode)
+ if !ok {
+ return nil, errors.ErrSyntax("cannot take map-key node", scalar.GetToken())
+ }
+ keyText := p.mapKeyText(key)
+ keyPath := ctx.withChild(keyText).path
+ key.SetPath(keyPath)
+ if err := p.validateMapKey(ctx, key.GetToken(), keyPath, g.Last()); err != nil {
+ return nil, err
+ }
+ p.pathMap[keyPath] = key
+ return key, nil
+}
+
+func (p *parser) validateMapKey(ctx *context, tk *token.Token, keyPath string, colonTk *Token) error {
+ if !p.allowDuplicateMapKey {
+ if n, exists := p.pathMap[keyPath]; exists {
+ pos := n.GetToken().Position
+ return errors.ErrSyntax(
+ fmt.Sprintf("mapping key %q already defined at [%d:%d]", tk.Value, pos.Line, pos.Column),
+ tk,
+ )
+ }
+ }
+ origin := p.removeLeftWhiteSpace(tk.Origin)
+ if ctx.isFlow {
+ if tk.Type == token.StringType {
+ origin = p.removeRightWhiteSpace(origin)
+ if tk.Position.Line+p.newLineCharacterNum(origin) != colonTk.Line() {
+ return errors.ErrSyntax("map key definition includes an implicit line break", tk)
+ }
+ }
+ return nil
+ }
+ if tk.Type != token.StringType && tk.Type != token.SingleQuoteType && tk.Type != token.DoubleQuoteType {
+ return nil
+ }
+ if p.existsNewLineCharacter(origin) {
+ return errors.ErrSyntax("unexpected key name", tk)
+ }
+ return nil
+}
+
+func (p *parser) removeLeftWhiteSpace(src string) string {
+ // CR or LF or CRLF
+ return strings.TrimLeftFunc(src, func(r rune) bool {
+ return r == ' ' || r == '\r' || r == '\n'
+ })
+}
+
+func (p *parser) removeRightWhiteSpace(src string) string {
+ // CR or LF or CRLF
+ return strings.TrimRightFunc(src, func(r rune) bool {
+ return r == ' ' || r == '\r' || r == '\n'
+ })
+}
+
+func (p *parser) existsNewLineCharacter(src string) bool {
+ return p.newLineCharacterNum(src) > 0
+}
+
+func (p *parser) newLineCharacterNum(src string) int {
+ var num int
+ for i := 0; i < len(src); i++ {
+ switch src[i] {
+ case '\r':
+ if len(src) > i+1 && src[i+1] == '\n' {
+ i++
+ }
+ num++
+ case '\n':
+ num++
+ }
+ }
+ return num
+}
+
+func (p *parser) mapKeyText(n ast.Node) string {
+ if n == nil {
+ return ""
+ }
+ switch nn := n.(type) {
+ case *ast.MappingKeyNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.TagNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.AnchorNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.AliasNode:
+ return ""
+ }
+ return n.GetToken().Value
+}
+
+func (p *parser) parseMapValue(ctx *context, key ast.MapKeyNode, colonTk *Token) (ast.Node, error) {
+ tk := ctx.currentToken()
+ if tk == nil {
+ return newNullNode(ctx, ctx.addNullValueToken(colonTk))
+ }
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ }
+ keyCol := key.GetToken().Position.Column
+ keyLine := key.GetToken().Position.Line
+
+ if tk.Column() != keyCol && tk.Line() == keyLine && (tk.GroupType() == TokenGroupMapKey || tk.GroupType() == TokenGroupMapKeyValue) {
+ // a: b:
+ // ^
+ //
+ // a: b: c
+ // ^
+ return nil, errors.ErrSyntax("mapping value is not allowed in this context", tk.RawToken())
+ }
+
+ if tk.Column() == keyCol && p.isMapToken(tk) {
+ // in this case,
+ // ----
+ // key:
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(colonTk))
+ }
+
+ if tk.Line() == keyLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() == keyCol && p.isMapToken(ctx.nextToken()) {
+ // in this case,
+ // ----
+ // key: &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ if tk.Column() <= keyCol && tk.GroupType() == TokenGroupAnchorName {
+ // key:
+ // &anchor
+ return nil, errors.ErrSyntax("anchor is not allowed in this context", tk.RawToken())
+ }
+ if tk.Column() <= keyCol && tk.Type() == token.TagType {
+ // key:
+ // !!tag
+ return nil, errors.ErrSyntax("tag is not allowed in this context", tk.RawToken())
+ }
+
+ if tk.Column() < keyCol {
+ // in this case,
+ // ----
+ // key:
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(colonTk))
+ }
+
+ if tk.Line() == keyLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() < keyCol {
+ // in this case,
+ // ----
+ // key: &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := p.validateAnchorValueInMapOrSeq(value, keyCol); err != nil {
+ return nil, err
+ }
+ return value, nil
+}
+
+func (p *parser) validateAnchorValueInMapOrSeq(value ast.Node, col int) error {
+ anchor, ok := value.(*ast.AnchorNode)
+ if !ok {
+ return nil
+ }
+ tag, ok := anchor.Value.(*ast.TagNode)
+ if !ok {
+ return nil
+ }
+ anchorTk := anchor.GetToken()
+ tagTk := tag.GetToken()
+
+ if anchorTk.Position.Line == tagTk.Position.Line {
+ // key:
+ // &anchor !!tag
+ //
+ // - &anchor !!tag
+ return nil
+ }
+
+ if tagTk.Position.Column <= col {
+ // key: &anchor
+ // !!tag
+ //
+ // - &anchor
+ // !!tag
+ return errors.ErrSyntax("tag is not allowed in this context", tagTk)
+ }
+ return nil
+}
+
+func (p *parser) parseAnchor(ctx *context, g *TokenGroup) (*ast.AnchorNode, error) {
+ anchorNameGroup := g.First().Group
+ anchor, err := p.parseAnchorName(ctx.withGroup(anchorNameGroup))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", anchor.GetToken())
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+}
+
+func (p *parser) parseAnchorName(ctx *context) (*ast.AnchorNode, error) {
+ anchor, err := newAnchorNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", anchor.GetToken())
+ }
+
+ anchorName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if anchorName == nil {
+ return nil, errors.ErrSyntax("unexpected anchor. anchor name is not scalar value", ctx.currentToken().RawToken())
+ }
+ anchor.Name = anchorName
+ return anchor, nil
+}
+
+func (p *parser) parseAlias(ctx *context) (*ast.AliasNode, error) {
+ alias, err := newAliasNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find alias value", alias.GetToken())
+ }
+
+ aliasName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if aliasName == nil {
+ return nil, errors.ErrSyntax("unexpected alias. alias name is not scalar value", ctx.currentToken().RawToken())
+ }
+ alias.Value = aliasName
+ return alias, nil
+}
+
+func (p *parser) parseLiteral(ctx *context) (*ast.LiteralNode, error) {
+ node, err := newLiteralNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip literal/folded token
+
+ tk := ctx.currentToken()
+ if tk == nil {
+ value, err := newStringNode(ctx, &Token{Token: token.New("", "", node.Start.Position)})
+ if err != nil {
+ return nil, err
+ }
+ node.Value = value
+ return node, nil
+ }
+ value, err := p.parseToken(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ str, ok := value.(*ast.StringNode)
+ if !ok {
+ return nil, errors.ErrSyntax("unexpected token. required string token", value.GetToken())
+ }
+ node.Value = str
+ return node, nil
+}
+
+func (p *parser) parseScalarTag(ctx *context) (*ast.TagNode, error) {
+ tag, err := p.parseTag(ctx)
+ if err != nil {
+ return nil, err
+ }
+ if tag.Value == nil {
+ return nil, errors.ErrSyntax("specified not scalar tag", tag.GetToken())
+ }
+ if _, ok := tag.Value.(ast.ScalarNode); !ok {
+ return nil, errors.ErrSyntax("specified not scalar tag", tag.GetToken())
+ }
+ return tag, nil
+}
+
+func (p *parser) parseTag(ctx *context) (*ast.TagNode, error) {
+ tagTk := ctx.currentToken()
+ tagRawTk := tagTk.RawToken()
+ node, err := newTagNode(ctx, tagTk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+
+ comment := p.parseHeadComment(ctx)
+
+ var tagValue ast.Node
+ if p.secondaryTagDirective != nil {
+ value, err := newStringNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ tagValue = value
+ node.Directive = p.secondaryTagDirective
+ } else {
+ value, err := p.parseTagValue(ctx, tagRawTk, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ tagValue = value
+ }
+ if err := setHeadComment(comment, tagValue); err != nil {
+ return nil, err
+ }
+ node.Value = tagValue
+ return node, nil
+}
+
+func (p *parser) parseTagValue(ctx *context, tagRawTk *token.Token, tk *Token) (ast.Node, error) {
+ if tk == nil {
+ return newNullNode(ctx, ctx.createImplicitNullToken(&Token{Token: tagRawTk}))
+ }
+ switch token.ReservedTagKeyword(tagRawTk.Value) {
+ case token.MappingTag, token.SetTag:
+ if !p.isMapToken(tk) {
+ return nil, errors.ErrSyntax("could not find map", tk.RawToken())
+ }
+ if tk.Type() == token.MappingStartType {
+ return p.parseFlowMap(ctx.withFlow(true))
+ }
+ return p.parseMap(ctx)
+ case token.IntegerTag, token.FloatTag, token.StringTag, token.BinaryTag, token.TimestampTag, token.BooleanTag, token.NullTag:
+ if tk.GroupType() == TokenGroupLiteral || tk.GroupType() == TokenGroupFolded {
+ return p.parseLiteral(ctx.withGroup(tk.Group))
+ } else if tk.Type() == token.CollectEntryType || tk.Type() == token.MappingValueType {
+ return newTagDefaultScalarValueNode(ctx, tagRawTk)
+ }
+ scalar, err := p.parseScalarValue(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return scalar, nil
+ case token.SequenceTag, token.OrderedMapTag:
+ if tk.Type() == token.SequenceStartType {
+ return p.parseFlowSequence(ctx.withFlow(true))
+ }
+ return p.parseSequence(ctx)
+ }
+ return p.parseToken(ctx, tk)
+}
+
+func (p *parser) parseFlowSequence(ctx *context) (*ast.SequenceNode, error) {
+ node, err := newSequenceNode(ctx, ctx.currentToken(), true)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip SequenceStart token
+
+ isFirst := true
+ for ctx.next() {
+ tk := ctx.currentToken()
+ if tk.Type() == token.SequenceEndType {
+ node.End = tk.RawToken()
+ break
+ }
+
+ var entryTk *Token
+ if tk.Type() == token.CollectEntryType {
+ if isFirst {
+ return nil, errors.ErrSyntax("expected sequence element, but found ','", tk.RawToken())
+ }
+ entryTk = tk
+ ctx.goNext()
+ } else if !isFirst {
+ return nil, errors.ErrSyntax("',' or ']' must be specified", tk.RawToken())
+ }
+
+ if tk := ctx.currentToken(); tk.Type() == token.SequenceEndType {
+ // this case is here: "[ elem, ]".
+ // In this case, ignore the last element and break sequence parsing.
+ node.End = tk.RawToken()
+ break
+ }
+
+ if ctx.isTokenNotFound() {
+ break
+ }
+
+ ctx := ctx.withIndex(uint(len(node.Values)))
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, value)
+ seqEntry := ast.SequenceEntry(entryTk.RawToken(), value, nil)
+ if err := setLineComment(ctx, seqEntry, entryTk); err != nil {
+ return nil, err
+ }
+ seqEntry.SetPath(ctx.path)
+ node.Entries = append(node.Entries, seqEntry)
+
+ isFirst = false
+ }
+ if node.End == nil {
+ return nil, errors.ErrSyntax("sequence end token ']' not found", node.Start)
+ }
+
+ // set line comment if exists. e.g.) ] # comment
+ if err := setLineComment(ctx, node, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip sequence end token.
+ return node, nil
+}
+
+func (p *parser) parseSequence(ctx *context) (*ast.SequenceNode, error) {
+ seqTk := ctx.currentToken()
+ seqNode, err := newSequenceNode(ctx, seqTk, false)
+ if err != nil {
+ return nil, err
+ }
+
+ tk := seqTk
+ for tk.Type() == token.SequenceEntryType && tk.Column() == seqTk.Column() {
+ seqTk := tk
+ headComment := p.parseHeadComment(ctx)
+ ctx.goNext() // skip sequence entry token
+
+ ctx := ctx.withIndex(uint(len(seqNode.Values)))
+ value, err := p.parseSequenceValue(ctx, seqTk)
+ if err != nil {
+ return nil, err
+ }
+ seqEntry := ast.SequenceEntry(seqTk.RawToken(), value, headComment)
+ if err := setLineComment(ctx, seqEntry, seqTk); err != nil {
+ return nil, err
+ }
+ seqEntry.SetPath(ctx.path)
+ seqNode.ValueHeadComments = append(seqNode.ValueHeadComments, headComment)
+ seqNode.Values = append(seqNode.Values, value)
+ seqNode.Entries = append(seqNode.Entries, seqEntry)
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ } else {
+ tk = ctx.currentToken()
+ }
+ }
+ if ctx.isComment() {
+ if seqTk.Column() <= ctx.currentToken().Column() {
+ // If the comment is in the same or deeper column as the last element column in sequence value,
+ // treat it as a footer comment for the last element.
+ seqNode.FootComment = p.parseFootComment(ctx, seqTk.Column())
+ if len(seqNode.Values) != 0 {
+ seqNode.FootComment.SetPath(seqNode.Values[len(seqNode.Values)-1].GetPath())
+ }
+ }
+ }
+ return seqNode, nil
+}
+
+func (p *parser) parseSequenceValue(ctx *context, seqTk *Token) (ast.Node, error) {
+ tk := ctx.currentToken()
+ if tk == nil {
+ return newNullNode(ctx, ctx.addNullValueToken(seqTk))
+ }
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ }
+ seqCol := seqTk.Column()
+ seqLine := seqTk.Line()
+
+ if tk.Column() == seqCol && tk.Type() == token.SequenceEntryType {
+ // in this case,
+ // ----
+ // -
+ // -
+ return newNullNode(ctx, ctx.insertNullToken(seqTk))
+ }
+
+ if tk.Line() == seqLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() == seqCol && ctx.nextToken().Type() == token.SequenceEntryType {
+ // in this case,
+ // ----
+ // - &anchor
+ // -
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ if tk.Column() <= seqCol && tk.GroupType() == TokenGroupAnchorName {
+ // -
+ // &anchor
+ return nil, errors.ErrSyntax("anchor is not allowed in this sequence context", tk.RawToken())
+ }
+ if tk.Column() <= seqCol && tk.Type() == token.TagType {
+ // -
+ // !!tag
+ return nil, errors.ErrSyntax("tag is not allowed in this sequence context", tk.RawToken())
+ }
+
+ if tk.Column() < seqCol {
+ // in this case,
+ // ----
+ // -
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(seqTk))
+ }
+
+ if tk.Line() == seqLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() < seqCol {
+ // in this case,
+ // ----
+ // - &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := p.validateAnchorValueInMapOrSeq(value, seqCol); err != nil {
+ return nil, err
+ }
+ return value, nil
+}
+
+func (p *parser) parseDirective(ctx *context, g *TokenGroup) (*ast.DirectiveNode, error) {
+ directiveNameGroup := g.First().Group
+ directive, err := p.parseDirectiveName(ctx.withGroup(directiveNameGroup))
+ if err != nil {
+ return nil, err
+ }
+
+ switch directive.Name.String() {
+ case "YAML":
+ if len(g.Tokens) != 2 {
+ return nil, errors.ErrSyntax("unexpected format YAML directive", g.First().RawToken())
+ }
+ valueTk := g.Tokens[1]
+ valueRawTk := valueTk.RawToken()
+ value := valueRawTk.Value
+ ver, exists := yamlVersionMap[value]
+ if !exists {
+ return nil, errors.ErrSyntax(fmt.Sprintf("unknown YAML version %q", value), valueRawTk)
+ }
+ if p.yamlVersion != "" {
+ return nil, errors.ErrSyntax("YAML version has already been specified", valueRawTk)
+ }
+ p.yamlVersion = ver
+ versionNode, err := newStringNode(ctx, valueTk)
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, versionNode)
+ case "TAG":
+ if len(g.Tokens) != 3 {
+ return nil, errors.ErrSyntax("unexpected format TAG directive", g.First().RawToken())
+ }
+ tagKey, err := newStringNode(ctx, g.Tokens[1])
+ if err != nil {
+ return nil, err
+ }
+ if tagKey.Value == "!!" {
+ p.secondaryTagDirective = directive
+ }
+ tagValue, err := newStringNode(ctx, g.Tokens[2])
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, tagKey, tagValue)
+ default:
+ if len(g.Tokens) > 1 {
+ for _, tk := range g.Tokens[1:] {
+ value, err := newStringNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, value)
+ }
+ }
+ }
+ return directive, nil
+}
+
+func (p *parser) parseDirectiveName(ctx *context) (*ast.DirectiveNode, error) {
+ directive, err := newDirectiveNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find directive value", directive.GetToken())
+ }
+
+ directiveName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if directiveName == nil {
+ return nil, errors.ErrSyntax("unexpected directive. directive name is not scalar value", ctx.currentToken().RawToken())
+ }
+ directive.Name = directiveName
+ return directive, nil
+}
+
+func (p *parser) parseComment(ctx *context) (ast.Node, error) {
+ cm := p.parseHeadComment(ctx)
+ if ctx.isTokenNotFound() {
+ return cm, nil
+ }
+ node, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := setHeadComment(cm, node); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func (p *parser) parseHeadComment(ctx *context) *ast.CommentGroupNode {
+ tks := []*token.Token{}
+ for ctx.isComment() {
+ tks = append(tks, ctx.currentToken().RawToken())
+ ctx.goNext()
+ }
+ if len(tks) == 0 {
+ return nil
+ }
+ return ast.CommentGroup(tks)
+}
+
+func (p *parser) parseFootComment(ctx *context, col int) *ast.CommentGroupNode {
+ tks := []*token.Token{}
+ for ctx.isComment() && col <= ctx.currentToken().Column() {
+ tks = append(tks, ctx.currentToken().RawToken())
+ ctx.goNext()
+ }
+ if len(tks) == 0 {
+ return nil
+ }
+ return ast.CommentGroup(tks)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/token.go b/sesh/vendor/github.com/goccy/go-yaml/parser/token.go
new file mode 100644
index 0000000..b07c018
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/token.go
@@ -0,0 +1,746 @@
+package parser
+
+import (
+ "fmt"
+ "os"
+ "strings"
+
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/token"
+)
+
+type TokenGroupType int
+
+const (
+ TokenGroupNone TokenGroupType = iota
+ TokenGroupDirective
+ TokenGroupDirectiveName
+ TokenGroupDocument
+ TokenGroupDocumentBody
+ TokenGroupAnchor
+ TokenGroupAnchorName
+ TokenGroupAlias
+ TokenGroupLiteral
+ TokenGroupFolded
+ TokenGroupScalarTag
+ TokenGroupMapKey
+ TokenGroupMapKeyValue
+)
+
+func (t TokenGroupType) String() string {
+ switch t {
+ case TokenGroupNone:
+ return "none"
+ case TokenGroupDirective:
+ return "directive"
+ case TokenGroupDirectiveName:
+ return "directive_name"
+ case TokenGroupDocument:
+ return "document"
+ case TokenGroupDocumentBody:
+ return "document_body"
+ case TokenGroupAnchor:
+ return "anchor"
+ case TokenGroupAnchorName:
+ return "anchor_name"
+ case TokenGroupAlias:
+ return "alias"
+ case TokenGroupLiteral:
+ return "literal"
+ case TokenGroupFolded:
+ return "folded"
+ case TokenGroupScalarTag:
+ return "scalar_tag"
+ case TokenGroupMapKey:
+ return "map_key"
+ case TokenGroupMapKeyValue:
+ return "map_key_value"
+ }
+ return "none"
+}
+
+type Token struct {
+ Token *token.Token
+ Group *TokenGroup
+ LineComment *token.Token
+}
+
+func (t *Token) RawToken() *token.Token {
+ if t == nil {
+ return nil
+ }
+ if t.Token != nil {
+ return t.Token
+ }
+ return t.Group.RawToken()
+}
+
+func (t *Token) Type() token.Type {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Type
+ }
+ return t.Group.TokenType()
+}
+
+func (t *Token) GroupType() TokenGroupType {
+ if t == nil {
+ return TokenGroupNone
+ }
+ if t.Token != nil {
+ return TokenGroupNone
+ }
+ return t.Group.Type
+}
+
+func (t *Token) Line() int {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Position.Line
+ }
+ return t.Group.Line()
+}
+
+func (t *Token) Column() int {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Position.Column
+ }
+ return t.Group.Column()
+}
+
+func (t *Token) SetGroupType(typ TokenGroupType) {
+ if t.Group == nil {
+ return
+ }
+ t.Group.Type = typ
+}
+
+func (t *Token) Dump() {
+ ctx := new(groupTokenRenderContext)
+ if t.Token != nil {
+ fmt.Fprint(os.Stdout, t.Token.Value)
+ return
+ }
+ t.Group.dump(ctx)
+ fmt.Fprintf(os.Stdout, "\n")
+}
+
+func (t *Token) dump(ctx *groupTokenRenderContext) {
+ if t.Token != nil {
+ fmt.Fprint(os.Stdout, t.Token.Value)
+ return
+ }
+ t.Group.dump(ctx)
+}
+
+type groupTokenRenderContext struct {
+ num int
+}
+
+type TokenGroup struct {
+ Type TokenGroupType
+ Tokens []*Token
+}
+
+func (g *TokenGroup) First() *Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[0]
+}
+
+func (g *TokenGroup) Last() *Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[len(g.Tokens)-1]
+}
+
+func (g *TokenGroup) dump(ctx *groupTokenRenderContext) {
+ num := ctx.num
+ fmt.Fprint(os.Stdout, colorize(num, "("))
+ ctx.num++
+ for _, tk := range g.Tokens {
+ tk.dump(ctx)
+ }
+ fmt.Fprint(os.Stdout, colorize(num, ")"))
+}
+
+func (g *TokenGroup) RawToken() *token.Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[0].RawToken()
+}
+
+func (g *TokenGroup) Line() int {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Line()
+}
+
+func (g *TokenGroup) Column() int {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Column()
+}
+
+func (g *TokenGroup) TokenType() token.Type {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Type()
+}
+
+func CreateGroupedTokens(tokens token.Tokens) ([]*Token, error) {
+ var err error
+ tks := newTokens(tokens)
+ tks = createLineCommentTokenGroups(tks)
+ tks, err = createLiteralAndFoldedTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createAnchorAndAliasTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createScalarTagTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createAnchorWithScalarTagTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createMapKeyTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks = createMapKeyValueTokenGroups(tks)
+ tks, err = createDirectiveTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createDocumentTokens(tks)
+ if err != nil {
+ return nil, err
+ }
+ return tks, nil
+}
+
+func newTokens(tks token.Tokens) []*Token {
+ ret := make([]*Token, 0, len(tks))
+ for _, tk := range tks {
+ ret = append(ret, &Token{Token: tk})
+ }
+ return ret
+}
+
+func createLineCommentTokenGroups(tokens []*Token) []*Token {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.CommentType:
+ if i > 0 && tokens[i-1].Line() == tk.Line() {
+ tokens[i-1].LineComment = tk.RawToken()
+ } else {
+ ret = append(ret, tk)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret
+}
+
+func createLiteralAndFoldedTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.LiteralType:
+ tks := []*Token{tk}
+ if i+1 < len(tokens) {
+ tks = append(tks, tokens[i+1])
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupLiteral,
+ Tokens: tks,
+ },
+ })
+ i++
+ case token.FoldedType:
+ tks := []*Token{tk}
+ if i+1 < len(tokens) {
+ tks = append(tks, tokens[i+1])
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupFolded,
+ Tokens: tks,
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createAnchorAndAliasTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.AnchorType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor name", tk.RawToken())
+ }
+ if i+2 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor value", tk.RawToken())
+ }
+ anchorName := &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchorName,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ }
+ valueTk := tokens[i+2]
+ if tk.Line() == valueTk.Line() && valueTk.Type() == token.SequenceEntryType {
+ return nil, errors.ErrSyntax("sequence entries are not allowed after anchor on the same line", valueTk.RawToken())
+ }
+ if tk.Line() == valueTk.Line() && isScalarType(valueTk) {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{anchorName, valueTk},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, anchorName)
+ }
+ i++
+ case token.AliasType:
+ if i+1 == len(tokens) {
+ return nil, errors.ErrSyntax("undefined alias name", tk.RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAlias,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createScalarTagTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ if tk.Type() != token.TagType {
+ ret = append(ret, tk)
+ continue
+ }
+ tag := tk.RawToken()
+ if strings.HasPrefix(tag.Value, "!!") {
+ // secondary tag.
+ switch token.ReservedTagKeyword(tag.Value) {
+ case token.IntegerTag, token.FloatTag, token.StringTag, token.BinaryTag, token.TimestampTag, token.BooleanTag, token.NullTag:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if isScalarType(tokens[i+1]) {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ }
+ case token.MergeTag:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].Type() != token.MergeKeyType {
+ return nil, errors.ErrSyntax("could not find merge key", tokens[i+1].RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ } else {
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if isFlowType(tokens[i+1]) {
+ ret = append(ret, tk)
+ continue
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ }
+ }
+ return ret, nil
+}
+
+func createAnchorWithScalarTagTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.GroupType() {
+ case TokenGroupAnchorName:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor value", tk.RawToken())
+ }
+ valueTk := tokens[i+1]
+ if tk.Line() == valueTk.Line() && valueTk.GroupType() == TokenGroupScalarTag {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyTokenGroups(tokens []*Token) ([]*Token, error) {
+ tks, err := createMapKeyByMappingKey(tokens)
+ if err != nil {
+ return nil, err
+ }
+ return createMapKeyByMappingValue(tks)
+}
+
+func createMapKeyByMappingKey(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.MappingKeyType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined map key", tk.RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupMapKey,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyByMappingValue(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.MappingValueType:
+ if i == 0 {
+ return nil, errors.ErrSyntax("unexpected key name", tk.RawToken())
+ }
+ mapKeyTk := tokens[i-1]
+ if isNotMapKeyType(mapKeyTk) {
+ return nil, errors.ErrSyntax("found an invalid key for this map", tokens[i].RawToken())
+ }
+ newTk := &Token{Token: mapKeyTk.Token, Group: mapKeyTk.Group}
+ mapKeyTk.Token = nil
+ mapKeyTk.Group = &TokenGroup{
+ Type: TokenGroupMapKey,
+ Tokens: []*Token{newTk, tk},
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyValueTokenGroups(tokens []*Token) []*Token {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.GroupType() {
+ case TokenGroupMapKey:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ valueTk := tokens[i+1]
+ if tk.Line() != valueTk.Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if valueTk.GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if valueTk.Type() == token.TagType && valueTk.GroupType() != TokenGroupScalarTag {
+ ret = append(ret, tk)
+ continue
+ }
+
+ if isScalarType(valueTk) || valueTk.Type() == token.TagType {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupMapKeyValue,
+ Tokens: []*Token{tk, valueTk},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ continue
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret
+}
+
+func createDirectiveTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.DirectiveType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined directive value", tk.RawToken())
+ }
+ directiveName := &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDirectiveName,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ }
+ i++
+ var valueTks []*Token
+ for j := i + 1; j < len(tokens); j++ {
+ if tokens[j].Line() != tk.Line() {
+ break
+ }
+ valueTks = append(valueTks, tokens[j])
+ i++
+ }
+ if i+1 >= len(tokens) || tokens[i+1].Type() != token.DocumentHeaderType {
+ return nil, errors.ErrSyntax("unexpected directive value. document not started", tk.RawToken())
+ }
+ if len(valueTks) != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDirective,
+ Tokens: append([]*Token{directiveName}, valueTks...),
+ },
+ })
+ } else {
+ ret = append(ret, directiveName)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createDocumentTokens(tokens []*Token) ([]*Token, error) {
+ var ret []*Token
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.DocumentHeaderType:
+ if i != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{Tokens: tokens[:i]},
+ })
+ }
+ if i+1 == len(tokens) {
+ // if current token is last token, add DocumentHeader only tokens to ret.
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ }
+ if tokens[i+1].Type() == token.DocumentHeaderType {
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ }
+ if tokens[i].Line() == tokens[i+1].Line() {
+ switch tokens[i+1].GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return nil, errors.ErrSyntax("value cannot be placed after document separator", tokens[i+1].RawToken())
+ }
+ switch tokens[i+1].Type() {
+ case token.SequenceEntryType:
+ return nil, errors.ErrSyntax("value cannot be placed after document separator", tokens[i+1].RawToken())
+ }
+ }
+ tks, err := createDocumentTokens(tokens[i+1:])
+ if err != nil {
+ return nil, err
+ }
+ if len(tks) != 0 {
+ tks[0].SetGroupType(TokenGroupDocument)
+ tks[0].Group.Tokens = append([]*Token{tk}, tks[0].Group.Tokens...)
+ return append(ret, tks...), nil
+ }
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ case token.DocumentEndType:
+ if i != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: tokens[0 : i+1],
+ },
+ })
+ }
+ if i+1 == len(tokens) {
+ return ret, nil
+ }
+ if isScalarType(tokens[i+1]) {
+ return nil, errors.ErrSyntax("unexpected end content", tokens[i+1].RawToken())
+ }
+
+ tks, err := createDocumentTokens(tokens[i+1:])
+ if err != nil {
+ return nil, err
+ }
+ return append(ret, tks...), nil
+ }
+ }
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: tokens,
+ },
+ }), nil
+}
+
+func isScalarType(tk *Token) bool {
+ switch tk.GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return false
+ }
+ typ := tk.Type()
+ return typ == token.AnchorType ||
+ typ == token.AliasType ||
+ typ == token.LiteralType ||
+ typ == token.FoldedType ||
+ typ == token.NullType ||
+ typ == token.ImplicitNullType ||
+ typ == token.BoolType ||
+ typ == token.IntegerType ||
+ typ == token.BinaryIntegerType ||
+ typ == token.OctetIntegerType ||
+ typ == token.HexIntegerType ||
+ typ == token.FloatType ||
+ typ == token.InfinityType ||
+ typ == token.NanType ||
+ typ == token.StringType ||
+ typ == token.SingleQuoteType ||
+ typ == token.DoubleQuoteType
+}
+
+func isNotMapKeyType(tk *Token) bool {
+ typ := tk.Type()
+ return typ == token.DirectiveType ||
+ typ == token.DocumentHeaderType ||
+ typ == token.DocumentEndType ||
+ typ == token.CollectEntryType ||
+ typ == token.MappingStartType ||
+ typ == token.MappingValueType ||
+ typ == token.MappingEndType ||
+ typ == token.SequenceStartType ||
+ typ == token.SequenceEntryType ||
+ typ == token.SequenceEndType
+}
+
+func isFlowType(tk *Token) bool {
+ typ := tk.Type()
+ return typ == token.MappingStartType ||
+ typ == token.MappingEndType ||
+ typ == token.SequenceStartType ||
+ typ == token.SequenceEntryType
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/path.go b/sesh/vendor/github.com/goccy/go-yaml/path.go
new file mode 100644
index 0000000..568c4b4
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/path.go
@@ -0,0 +1,835 @@
+package yaml
+
+import (
+ "bytes"
+ "fmt"
+ "io"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/printer"
+)
+
+// PathString create Path from string
+//
+// YAMLPath rule
+// $ : the root object/element
+// . : child operator
+// .. : recursive descent
+// [num] : object/element of array by number
+// [*] : all objects/elements for array.
+//
+// If you want to use reserved characters such as `.` and `*` as a key name,
+// enclose them in single quotation as follows ( $.foo.'bar.baz-*'.hoge ).
+// If you want to use a single quote with reserved characters, escape it with `\` ( $.foo.'bar.baz\'s value'.hoge ).
+func PathString(s string) (*Path, error) {
+ buf := []rune(s)
+ length := len(buf)
+ cursor := 0
+ builder := &PathBuilder{}
+ for cursor < length {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ builder = builder.Root()
+ cursor++
+ case '.':
+ b, buf, c, err := parsePathDot(builder, buf, cursor)
+ if err != nil {
+ return nil, err
+ }
+ length = len(buf)
+ builder = b
+ cursor = c
+ case '[':
+ b, buf, c, err := parsePathIndex(builder, buf, cursor)
+ if err != nil {
+ return nil, err
+ }
+ length = len(buf)
+ builder = b
+ cursor = c
+ default:
+ return nil, fmt.Errorf("invalid path at %d: %w", cursor, ErrInvalidPathString)
+ }
+ }
+ return builder.Build(), nil
+}
+
+func parsePathRecursive(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ length := len(buf)
+ cursor += 2 // skip .. characters
+ start := cursor
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '..' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '..' character: %w", ErrInvalidPathString)
+ case '.', '[':
+ goto end
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '..' character: %w", ErrInvalidPathString)
+ }
+ }
+end:
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("not found recursive selector: %w", ErrInvalidPathString)
+ }
+ return b.Recursive(string(buf[start:cursor])), buf, cursor, nil
+}
+
+func parsePathDot(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+ length := len(buf)
+ if cursor+1 < length && buf[cursor+1] == '.' {
+ b, buf, c, err := parsePathRecursive(b, buf, cursor)
+ if err != nil {
+ return nil, nil, 0, err
+ }
+ return b, buf, c, nil
+ }
+ cursor++ // skip . character
+ start := cursor
+
+ // if started single quote, looking for end single quote char
+ if cursor < length && buf[cursor] == '\'' {
+ return parseQuotedKey(b, buf, cursor)
+ }
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '.' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '.' character: %w", ErrInvalidPathString)
+ case '.', '[':
+ goto end
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '.' character: %w", ErrInvalidPathString)
+ }
+ }
+end:
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("could not find by empty key: %w", ErrInvalidPathString)
+ }
+ return b.child(string(buf[start:cursor])), buf, cursor, nil
+}
+
+func parseQuotedKey(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+
+ cursor++ // skip single quote
+ start := cursor
+ length := len(buf)
+ var foundEndDelim bool
+ for ; cursor < length; cursor++ {
+ switch buf[cursor] {
+ case '\\':
+ buf = append(append([]rune{}, buf[:cursor]...), buf[cursor+1:]...)
+ length = len(buf)
+ case '\'':
+ foundEndDelim = true
+ goto end
+ }
+ }
+end:
+ if !foundEndDelim {
+ return nil, nil, 0, fmt.Errorf("could not find end delimiter for key: %w", ErrInvalidPathString)
+ }
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("could not find by empty key: %w", ErrInvalidPathString)
+ }
+ selector := buf[start:cursor]
+ cursor++
+ if cursor < length {
+ switch buf[cursor] {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '.' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '.' character: %w", ErrInvalidPathString)
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '.' character: %w", ErrInvalidPathString)
+ }
+ }
+ return b.child(string(selector)), buf, cursor, nil
+}
+
+func parsePathIndex(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+
+ length := len(buf)
+ cursor++ // skip '[' character
+ if length <= cursor {
+ return nil, nil, 0, fmt.Errorf("unexpected end of YAML Path: %w", ErrInvalidPathString)
+ }
+ c := buf[cursor]
+ switch c {
+ case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '*':
+ start := cursor
+ cursor++
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
+ continue
+ }
+ break
+ }
+ if buf[cursor] != ']' {
+ return nil, nil, 0, fmt.Errorf("invalid character %s at %d: %w", string(buf[cursor]), cursor, ErrInvalidPathString)
+ }
+ numOrAll := string(buf[start:cursor])
+ if numOrAll == "*" {
+ return b.IndexAll(), buf, cursor + 1, nil
+ }
+ num, err := strconv.ParseInt(numOrAll, 10, 64)
+ if err != nil {
+ return nil, nil, 0, err
+ }
+ return b.Index(uint(num)), buf, cursor + 1, nil
+ }
+ return nil, nil, 0, fmt.Errorf("invalid character %q at %d: %w", c, cursor, ErrInvalidPathString)
+}
+
+// Path represent YAMLPath ( like a JSONPath ).
+type Path struct {
+ node pathNode
+}
+
+// String path to text.
+func (p *Path) String() string {
+ return p.node.String()
+}
+
+// Read decode from r and set extracted value by YAMLPath to v.
+func (p *Path) Read(r io.Reader, v interface{}) error {
+ node, err := p.ReadNode(r)
+ if err != nil {
+ return err
+ }
+ if err := Unmarshal([]byte(node.String()), v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReadNode create AST from r and extract node by YAMLPath.
+func (p *Path) ReadNode(r io.Reader) (ast.Node, error) {
+ if p.node == nil {
+ return nil, ErrInvalidPath
+ }
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, r); err != nil {
+ return nil, err
+ }
+ f, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return nil, err
+ }
+ node, err := p.FilterFile(f)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+// Filter filter from target by YAMLPath and set it to v.
+func (p *Path) Filter(target, v interface{}) error {
+ b, err := Marshal(target)
+ if err != nil {
+ return err
+ }
+ if err := p.Read(bytes.NewBuffer(b), v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// FilterFile filter from ast.File by YAMLPath.
+func (p *Path) FilterFile(f *ast.File) (ast.Node, error) {
+ for _, doc := range f.Docs {
+ // For simplicity, directives cannot be the target of operations
+ if doc.Body != nil && doc.Body.Type() == ast.DirectiveType {
+ continue
+ }
+ node, err := p.FilterNode(doc.Body)
+ if err != nil {
+ return nil, err
+ }
+ if node != nil {
+ return node, nil
+ }
+ }
+ return nil, fmt.Errorf("failed to find path ( %s ): %w", p.node, ErrNotFoundNode)
+}
+
+// FilterNode filter from node by YAMLPath.
+func (p *Path) FilterNode(node ast.Node) (ast.Node, error) {
+ if node == nil {
+ return nil, nil
+ }
+ n, err := p.node.filter(node)
+ if err != nil {
+ return nil, err
+ }
+ return n, nil
+}
+
+// MergeFromReader merge YAML text into ast.File.
+func (p *Path) MergeFromReader(dst *ast.File, src io.Reader) error {
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, src); err != nil {
+ return err
+ }
+ file, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return err
+ }
+ if err := p.MergeFromFile(dst, file); err != nil {
+ return err
+ }
+ return nil
+}
+
+// MergeFromFile merge ast.File into ast.File.
+func (p *Path) MergeFromFile(dst *ast.File, src *ast.File) error {
+ base, err := p.FilterFile(dst)
+ if err != nil {
+ return err
+ }
+ for _, doc := range src.Docs {
+ if err := ast.Merge(base, doc); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// MergeFromNode merge ast.Node into ast.File.
+func (p *Path) MergeFromNode(dst *ast.File, src ast.Node) error {
+ base, err := p.FilterFile(dst)
+ if err != nil {
+ return err
+ }
+ if err := ast.Merge(base, src); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReplaceWithReader replace ast.File with io.Reader.
+func (p *Path) ReplaceWithReader(dst *ast.File, src io.Reader) error {
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, src); err != nil {
+ return err
+ }
+ file, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return err
+ }
+ if err := p.ReplaceWithFile(dst, file); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReplaceWithFile replace ast.File with ast.File.
+func (p *Path) ReplaceWithFile(dst *ast.File, src *ast.File) error {
+ for _, doc := range src.Docs {
+ if err := p.ReplaceWithNode(dst, doc); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// ReplaceNode replace ast.File with ast.Node.
+func (p *Path) ReplaceWithNode(dst *ast.File, node ast.Node) error {
+ for _, doc := range dst.Docs {
+ // For simplicity, directives cannot be the target of operations
+ if doc.Body != nil && doc.Body.Type() == ast.DirectiveType {
+ continue
+ }
+ if node.Type() == ast.DocumentType {
+ node = node.(*ast.DocumentNode).Body
+ }
+ if err := p.node.replace(doc.Body, node); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// AnnotateSource add annotation to passed source ( see section 5.1 in README.md ).
+func (p *Path) AnnotateSource(source []byte, colored bool) ([]byte, error) {
+ file, err := parser.ParseBytes(source, 0)
+ if err != nil {
+ return nil, err
+ }
+ node, err := p.FilterFile(file)
+ if err != nil {
+ return nil, err
+ }
+ var pp printer.Printer
+ return []byte(pp.PrintErrorToken(node.GetToken(), colored)), nil
+}
+
+// PathBuilder represent builder for YAMLPath.
+type PathBuilder struct {
+ root *rootNode
+ node pathNode
+}
+
+// Root add '$' to current path.
+func (b *PathBuilder) Root() *PathBuilder {
+ root := newRootNode()
+ return &PathBuilder{root: root, node: root}
+}
+
+// IndexAll add '[*]' to current path.
+func (b *PathBuilder) IndexAll() *PathBuilder {
+ b.node = b.node.chain(newIndexAllNode())
+ return b
+}
+
+// Recursive add '..selector' to current path.
+func (b *PathBuilder) Recursive(selector string) *PathBuilder {
+ b.node = b.node.chain(newRecursiveNode(selector))
+ return b
+}
+
+func (b *PathBuilder) containsReservedPathCharacters(path string) bool {
+ if strings.Contains(path, ".") {
+ return true
+ }
+ if strings.Contains(path, "*") {
+ return true
+ }
+ return false
+}
+
+func (b *PathBuilder) enclosedSingleQuote(name string) bool {
+ return strings.HasPrefix(name, "'") && strings.HasSuffix(name, "'")
+}
+
+func (b *PathBuilder) normalizeSelectorName(name string) string {
+ if b.enclosedSingleQuote(name) {
+ // already escaped name
+ return name
+ }
+ if b.containsReservedPathCharacters(name) {
+ escapedName := strings.ReplaceAll(name, `'`, `\'`)
+ return "'" + escapedName + "'"
+ }
+ return name
+}
+
+func (b *PathBuilder) child(name string) *PathBuilder {
+ b.node = b.node.chain(newSelectorNode(name))
+ return b
+}
+
+// Child add '.name' to current path.
+func (b *PathBuilder) Child(name string) *PathBuilder {
+ return b.child(b.normalizeSelectorName(name))
+}
+
+// Index add '[idx]' to current path.
+func (b *PathBuilder) Index(idx uint) *PathBuilder {
+ b.node = b.node.chain(newIndexNode(idx))
+ return b
+}
+
+// Build build YAMLPath.
+func (b *PathBuilder) Build() *Path {
+ return &Path{node: b.root}
+}
+
+type pathNode interface {
+ fmt.Stringer
+ chain(pathNode) pathNode
+ filter(ast.Node) (ast.Node, error)
+ replace(ast.Node, ast.Node) error
+}
+
+type basePathNode struct {
+ child pathNode
+}
+
+func (n *basePathNode) chain(node pathNode) pathNode {
+ n.child = node
+ return node
+}
+
+type rootNode struct {
+ *basePathNode
+}
+
+func newRootNode() *rootNode {
+ return &rootNode{basePathNode: &basePathNode{}}
+}
+
+func (n *rootNode) String() string {
+ s := "$"
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *rootNode) filter(node ast.Node) (ast.Node, error) {
+ if n.child == nil {
+ return node, nil
+ }
+ filtered, err := n.child.filter(node)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+}
+
+func (n *rootNode) replace(node ast.Node, target ast.Node) error {
+ if n.child == nil {
+ return nil
+ }
+ if err := n.child.replace(node, target); err != nil {
+ return err
+ }
+ return nil
+}
+
+type selectorNode struct {
+ *basePathNode
+ selector string
+}
+
+func newSelectorNode(selector string) *selectorNode {
+ return &selectorNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *selectorNode) filter(node ast.Node) (ast.Node, error) {
+ selector := n.selector
+ if len(selector) > 1 && selector[0] == '\'' && selector[len(selector)-1] == '\'' {
+ selector = selector[1 : len(selector)-1]
+ }
+ switch node.Type() {
+ case ast.MappingType:
+ for _, value := range node.(*ast.MappingNode).Values {
+ key := value.Key.GetToken().Value
+ if len(key) > 0 {
+ switch key[0] {
+ case '"':
+ var err error
+ key, err = strconv.Unquote(key)
+ if err != nil {
+ return nil, err
+ }
+ case '\'':
+ if len(key) > 1 && key[len(key)-1] == '\'' {
+ key = key[1 : len(key)-1]
+ }
+ }
+ }
+ if key == selector {
+ if n.child == nil {
+ return value.Value, nil
+ }
+ filtered, err := n.child.filter(value.Value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+ }
+ }
+ case ast.MappingValueType:
+ value, _ := node.(*ast.MappingValueNode)
+ key := value.Key.GetToken().Value
+ if key == selector {
+ if n.child == nil {
+ return value.Value, nil
+ }
+ filtered, err := n.child.filter(value.Value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+ }
+ default:
+ return nil, fmt.Errorf("expected node type is map or map value. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ return nil, nil
+}
+
+func (n *selectorNode) replaceMapValue(value *ast.MappingValueNode, target ast.Node) error {
+ key := value.Key.GetToken().Value
+ if key != n.selector {
+ return nil
+ }
+ if n.child == nil {
+ if err := value.Replace(target); err != nil {
+ return err
+ }
+ } else {
+ if err := n.child.replace(value.Value, target); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+func (n *selectorNode) replace(node ast.Node, target ast.Node) error {
+ switch node.Type() {
+ case ast.MappingType:
+ for _, value := range node.(*ast.MappingNode).Values {
+ if err := n.replaceMapValue(value, target); err != nil {
+ return err
+ }
+ }
+ case ast.MappingValueType:
+ value, _ := node.(*ast.MappingValueNode)
+ if err := n.replaceMapValue(value, target); err != nil {
+ return err
+ }
+ default:
+ return fmt.Errorf("expected node type is map or map value. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ return nil
+}
+
+func (n *selectorNode) String() string {
+ var builder PathBuilder
+ selector := builder.normalizeSelectorName(n.selector)
+ s := fmt.Sprintf(".%s", selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+type indexNode struct {
+ *basePathNode
+ selector uint
+}
+
+func newIndexNode(selector uint) *indexNode {
+ return &indexNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *indexNode) filter(node ast.Node) (ast.Node, error) {
+ if node.Type() != ast.SequenceType {
+ return nil, fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.selector >= uint(len(sequence.Values)) {
+ return nil, fmt.Errorf("expected index is %d. but got sequences has %d items: %w", n.selector, len(sequence.Values), ErrInvalidQuery)
+ }
+ value := sequence.Values[n.selector]
+ if n.child == nil {
+ return value, nil
+ }
+ filtered, err := n.child.filter(value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+}
+
+func (n *indexNode) replace(node ast.Node, target ast.Node) error {
+ if node.Type() != ast.SequenceType {
+ return fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.selector >= uint(len(sequence.Values)) {
+ return fmt.Errorf("expected index is %d. but got sequences has %d items: %w", n.selector, len(sequence.Values), ErrInvalidQuery)
+ }
+ if n.child == nil {
+ if err := sequence.Replace(int(n.selector), target); err != nil {
+ return err
+ }
+ return nil
+ }
+ if err := n.child.replace(sequence.Values[n.selector], target); err != nil {
+ return err
+ }
+ return nil
+}
+
+func (n *indexNode) String() string {
+ s := fmt.Sprintf("[%d]", n.selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+type indexAllNode struct {
+ *basePathNode
+}
+
+func newIndexAllNode() *indexAllNode {
+ return &indexAllNode{
+ basePathNode: &basePathNode{},
+ }
+}
+
+func (n *indexAllNode) String() string {
+ s := "[*]"
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *indexAllNode) filter(node ast.Node) (ast.Node, error) {
+ if node.Type() != ast.SequenceType {
+ return nil, fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.child == nil {
+ return sequence, nil
+ }
+ out := *sequence
+ out.Values = []ast.Node{}
+ for _, value := range sequence.Values {
+ filtered, err := n.child.filter(value)
+ if err != nil {
+ return nil, err
+ }
+ out.Values = append(out.Values, filtered)
+ }
+ return &out, nil
+}
+
+func (n *indexAllNode) replace(node ast.Node, target ast.Node) error {
+ if node.Type() != ast.SequenceType {
+ return fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.child == nil {
+ for idx := range sequence.Values {
+ if err := sequence.Replace(idx, target); err != nil {
+ return err
+ }
+ }
+ return nil
+ }
+ for _, value := range sequence.Values {
+ if err := n.child.replace(value, target); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+type recursiveNode struct {
+ *basePathNode
+ selector string
+}
+
+func newRecursiveNode(selector string) *recursiveNode {
+ return &recursiveNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *recursiveNode) String() string {
+ s := fmt.Sprintf("..%s", n.selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *recursiveNode) filterNode(node ast.Node) (*ast.SequenceNode, error) {
+ sequence := &ast.SequenceNode{BaseNode: &ast.BaseNode{}}
+ switch typedNode := node.(type) {
+ case *ast.MappingNode:
+ for _, value := range typedNode.Values {
+ seq, err := n.filterNode(value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ }
+ case *ast.MappingValueNode:
+ key := typedNode.Key.GetToken().Value
+ if n.selector == key {
+ sequence.Values = append(sequence.Values, typedNode.Value)
+ }
+ seq, err := n.filterNode(typedNode.Value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ case *ast.SequenceNode:
+ for _, value := range typedNode.Values {
+ seq, err := n.filterNode(value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ }
+ }
+ return sequence, nil
+}
+
+func (n *recursiveNode) filter(node ast.Node) (ast.Node, error) {
+ sequence, err := n.filterNode(node)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Start = node.GetToken()
+ return sequence, nil
+}
+
+func (n *recursiveNode) replaceNode(node ast.Node, target ast.Node) error {
+ switch typedNode := node.(type) {
+ case *ast.MappingNode:
+ for _, value := range typedNode.Values {
+ if err := n.replaceNode(value, target); err != nil {
+ return err
+ }
+ }
+ case *ast.MappingValueNode:
+ key := typedNode.Key.GetToken().Value
+ if n.selector == key {
+ if err := typedNode.Replace(target); err != nil {
+ return err
+ }
+ }
+ if err := n.replaceNode(typedNode.Value, target); err != nil {
+ return err
+ }
+ case *ast.SequenceNode:
+ for _, value := range typedNode.Values {
+ if err := n.replaceNode(value, target); err != nil {
+ return err
+ }
+ }
+ }
+ return nil
+}
+
+func (n *recursiveNode) replace(node ast.Node, target ast.Node) error {
+ if err := n.replaceNode(node, target); err != nil {
+ return err
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/printer/color.go b/sesh/vendor/github.com/goccy/go-yaml/printer/color.go
new file mode 100644
index 0000000..79d7d7c
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/printer/color.go
@@ -0,0 +1,83 @@
+// This source inspired by https://github.com/fatih/color.
+package printer
+
+import (
+ "fmt"
+ "strings"
+)
+
+type ColorAttribute int
+
+const (
+ ColorReset ColorAttribute = iota
+ ColorBold
+ ColorFaint
+ ColorItalic
+ ColorUnderline
+ ColorBlinkSlow
+ ColorBlinkRapid
+ ColorReverseVideo
+ ColorConcealed
+ ColorCrossedOut
+)
+
+const (
+ ColorFgHiBlack ColorAttribute = iota + 90
+ ColorFgHiRed
+ ColorFgHiGreen
+ ColorFgHiYellow
+ ColorFgHiBlue
+ ColorFgHiMagenta
+ ColorFgHiCyan
+ ColorFgHiWhite
+)
+
+const (
+ ColorResetBold ColorAttribute = iota + 22
+ ColorResetItalic
+ ColorResetUnderline
+ ColorResetBlinking
+
+ ColorResetReversed
+ ColorResetConcealed
+ ColorResetCrossedOut
+)
+
+const escape = "\x1b"
+
+var colorResetMap = map[ColorAttribute]ColorAttribute{
+ ColorBold: ColorResetBold,
+ ColorFaint: ColorResetBold,
+ ColorItalic: ColorResetItalic,
+ ColorUnderline: ColorResetUnderline,
+ ColorBlinkSlow: ColorResetBlinking,
+ ColorBlinkRapid: ColorResetBlinking,
+ ColorReverseVideo: ColorResetReversed,
+ ColorConcealed: ColorResetConcealed,
+ ColorCrossedOut: ColorResetCrossedOut,
+}
+
+func format(attrs ...ColorAttribute) string {
+ format := make([]string, 0, len(attrs))
+ for _, attr := range attrs {
+ format = append(format, fmt.Sprint(attr))
+ }
+ return fmt.Sprintf("%s[%sm", escape, strings.Join(format, ";"))
+}
+
+func unformat(attrs ...ColorAttribute) string {
+ format := make([]string, len(attrs))
+ for _, attr := range attrs {
+ v := fmt.Sprint(ColorReset)
+ reset, exists := colorResetMap[attr]
+ if exists {
+ v = fmt.Sprint(reset)
+ }
+ format = append(format, v)
+ }
+ return fmt.Sprintf("%s[%sm", escape, strings.Join(format, ";"))
+}
+
+func colorize(msg string, attrs ...ColorAttribute) string {
+ return format(attrs...) + msg + unformat(attrs...)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go b/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go
new file mode 100644
index 0000000..9346983
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go
@@ -0,0 +1,353 @@
+package printer
+
+import (
+ "fmt"
+ "math"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Property additional property set for each the token
+type Property struct {
+ Prefix string
+ Suffix string
+}
+
+// PrintFunc returns property instance
+type PrintFunc func() *Property
+
+// Printer create text from token collection or ast
+type Printer struct {
+ LineNumber bool
+ LineNumberFormat func(num int) string
+ MapKey PrintFunc
+ Anchor PrintFunc
+ Alias PrintFunc
+ Bool PrintFunc
+ String PrintFunc
+ Number PrintFunc
+ Comment PrintFunc
+}
+
+func defaultLineNumberFormat(num int) string {
+ return fmt.Sprintf("%2d | ", num)
+}
+
+func (p *Printer) property(tk *token.Token) *Property {
+ prop := &Property{}
+ switch tk.PreviousType() {
+ case token.AnchorType:
+ if p.Anchor != nil {
+ return p.Anchor()
+ }
+ return prop
+ case token.AliasType:
+ if p.Alias != nil {
+ return p.Alias()
+ }
+ return prop
+ }
+ switch tk.NextType() {
+ case token.MappingValueType:
+ if p.MapKey != nil {
+ return p.MapKey()
+ }
+ return prop
+ }
+ switch tk.Type {
+ case token.BoolType:
+ if p.Bool != nil {
+ return p.Bool()
+ }
+ return prop
+ case token.AnchorType:
+ if p.Anchor != nil {
+ return p.Anchor()
+ }
+ return prop
+ case token.AliasType:
+ if p.Anchor != nil {
+ return p.Alias()
+ }
+ return prop
+ case token.StringType, token.SingleQuoteType, token.DoubleQuoteType:
+ if p.String != nil {
+ return p.String()
+ }
+ return prop
+ case token.IntegerType, token.FloatType:
+ if p.Number != nil {
+ return p.Number()
+ }
+ return prop
+ case token.CommentType:
+ if p.Comment != nil {
+ return p.Comment()
+ }
+ return prop
+ default:
+ }
+ return prop
+}
+
+// PrintTokens create text from token collection
+func (p *Printer) PrintTokens(tokens token.Tokens) string {
+ if len(tokens) == 0 {
+ return ""
+ }
+ if p.LineNumber {
+ if p.LineNumberFormat == nil {
+ p.LineNumberFormat = defaultLineNumberFormat
+ }
+ }
+ texts := []string{}
+ lineNumber := tokens[0].Position.Line
+ for _, tk := range tokens {
+ lines := strings.Split(tk.Origin, "\n")
+ prop := p.property(tk)
+ header := ""
+ if p.LineNumber {
+ header = p.LineNumberFormat(lineNumber)
+ }
+ if len(lines) == 1 {
+ line := prop.Prefix + lines[0] + prop.Suffix
+ if len(texts) == 0 {
+ texts = append(texts, header+line)
+ lineNumber++
+ } else {
+ text := texts[len(texts)-1]
+ texts[len(texts)-1] = text + line
+ }
+ } else {
+ for idx, src := range lines {
+ if p.LineNumber {
+ header = p.LineNumberFormat(lineNumber)
+ }
+ line := prop.Prefix + src + prop.Suffix
+ if idx == 0 {
+ if len(texts) == 0 {
+ texts = append(texts, header+line)
+ lineNumber++
+ } else {
+ text := texts[len(texts)-1]
+ texts[len(texts)-1] = text + line
+ }
+ } else {
+ texts = append(texts, fmt.Sprintf("%s%s", header, line))
+ lineNumber++
+ }
+ }
+ }
+ }
+ return strings.Join(texts, "\n")
+}
+
+// PrintNode create text from ast.Node
+func (p *Printer) PrintNode(node ast.Node) []byte {
+ return []byte(fmt.Sprintf("%+v\n", node))
+}
+
+func (p *Printer) setDefaultColorSet() {
+ p.Bool = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiMagenta),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Number = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiMagenta),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.MapKey = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiCyan),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Anchor = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiYellow),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Alias = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiYellow),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.String = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiGreen),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Comment = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiBlack),
+ Suffix: format(ColorReset),
+ }
+ }
+}
+
+func (p *Printer) PrintErrorMessage(msg string, isColored bool) string {
+ if isColored {
+ return fmt.Sprintf("%s%s%s",
+ format(ColorFgHiRed),
+ msg,
+ format(ColorReset),
+ )
+ }
+ return msg
+}
+
+func (p *Printer) removeLeftSideNewLineChar(src string) string {
+ return strings.TrimLeft(strings.TrimLeft(strings.TrimLeft(src, "\r"), "\n"), "\r\n")
+}
+
+func (p *Printer) removeRightSideNewLineChar(src string) string {
+ return strings.TrimRight(strings.TrimRight(strings.TrimRight(src, "\r"), "\n"), "\r\n")
+}
+
+func (p *Printer) removeRightSideWhiteSpaceChar(src string) string {
+ return p.removeRightSideNewLineChar(strings.TrimRight(src, " "))
+}
+
+func (p *Printer) newLineCount(s string) int {
+ src := []rune(s)
+ size := len(src)
+ cnt := 0
+ for i := 0; i < size; i++ {
+ c := src[i]
+ switch c {
+ case '\r':
+ if i+1 < size && src[i+1] == '\n' {
+ i++
+ }
+ cnt++
+ case '\n':
+ cnt++
+ }
+ }
+ return cnt
+}
+
+func (p *Printer) isNewLineLastChar(s string) bool {
+ for i := len(s) - 1; i > 0; i-- {
+ c := s[i]
+ switch c {
+ case ' ':
+ continue
+ case '\n', '\r':
+ return true
+ }
+ break
+ }
+ return false
+}
+
+func (p *Printer) printBeforeTokens(tk *token.Token, minLine, extLine int) token.Tokens {
+ for tk.Prev != nil {
+ if tk.Prev.Position.Line < minLine {
+ break
+ }
+ tk = tk.Prev
+ }
+ minTk := tk.Clone()
+ if minTk.Prev != nil {
+ // add white spaces to minTk by prev token
+ prev := minTk.Prev
+ whiteSpaceLen := len(prev.Origin) - len(strings.TrimRight(prev.Origin, " "))
+ minTk.Origin = strings.Repeat(" ", whiteSpaceLen) + minTk.Origin
+ }
+ minTk.Origin = p.removeLeftSideNewLineChar(minTk.Origin)
+ tokens := token.Tokens{minTk}
+ tk = minTk.Next
+ for tk != nil && tk.Position.Line <= extLine {
+ clonedTk := tk.Clone()
+ tokens.Add(clonedTk)
+ tk = clonedTk.Next
+ }
+ lastTk := tokens[len(tokens)-1]
+ trimmedOrigin := p.removeRightSideWhiteSpaceChar(lastTk.Origin)
+ suffix := lastTk.Origin[len(trimmedOrigin):]
+ lastTk.Origin = trimmedOrigin
+
+ if lastTk.Next != nil && len(suffix) > 1 {
+ next := lastTk.Next.Clone()
+ // add suffix to header of next token
+ if suffix[0] == '\n' || suffix[0] == '\r' {
+ suffix = suffix[1:]
+ }
+ next.Origin = suffix + next.Origin
+ lastTk.Next = next
+ }
+ return tokens
+}
+
+func (p *Printer) printAfterTokens(tk *token.Token, maxLine int) token.Tokens {
+ tokens := token.Tokens{}
+ if tk == nil {
+ return tokens
+ }
+ if tk.Position.Line > maxLine {
+ return tokens
+ }
+ minTk := tk.Clone()
+ minTk.Origin = p.removeLeftSideNewLineChar(minTk.Origin)
+ tokens.Add(minTk)
+ tk = minTk.Next
+ for tk != nil && tk.Position.Line <= maxLine {
+ clonedTk := tk.Clone()
+ tokens.Add(clonedTk)
+ tk = clonedTk.Next
+ }
+ return tokens
+}
+
+func (p *Printer) setupErrorTokenFormat(annotateLine int, isColored bool) {
+ prefix := func(annotateLine, num int) string {
+ if annotateLine == num {
+ return fmt.Sprintf("> %2d | ", num)
+ }
+ return fmt.Sprintf(" %2d | ", num)
+ }
+ p.LineNumber = true
+ p.LineNumberFormat = func(num int) string {
+ if isColored {
+ return colorize(prefix(annotateLine, num), ColorBold, ColorFgHiWhite)
+ }
+ return prefix(annotateLine, num)
+ }
+ if isColored {
+ p.setDefaultColorSet()
+ }
+}
+
+func (p *Printer) PrintErrorToken(tk *token.Token, isColored bool) string {
+ errToken := tk
+ curLine := tk.Position.Line
+ curExtLine := curLine + p.newLineCount(p.removeLeftSideNewLineChar(tk.Origin))
+ if p.isNewLineLastChar(tk.Origin) {
+ // if last character ( exclude white space ) is new line character, ignore it.
+ curExtLine--
+ }
+
+ minLine := int(math.Max(float64(curLine-3), 1))
+ maxLine := curExtLine + 3
+ p.setupErrorTokenFormat(curLine, isColored)
+
+ beforeTokens := p.printBeforeTokens(tk, minLine, curExtLine)
+ lastTk := beforeTokens[len(beforeTokens)-1]
+ afterTokens := p.printAfterTokens(lastTk.Next, maxLine)
+
+ beforeSource := p.PrintTokens(beforeTokens)
+ prefixSpaceNum := len(fmt.Sprintf(" %2d | ", curLine))
+ annotateLine := strings.Repeat(" ", prefixSpaceNum+errToken.Position.Column-1) + "^"
+ afterSource := p.PrintTokens(afterTokens)
+ return fmt.Sprintf("%s\n%s\n%s", beforeSource, annotateLine, afterSource)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go
new file mode 100644
index 0000000..4f3250b
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go
@@ -0,0 +1,452 @@
+package scanner
+
+import (
+ "errors"
+ "strconv"
+ "strings"
+ "sync"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// Context context at scanning
+type Context struct {
+ idx int
+ size int
+ notSpaceCharPos int
+ notSpaceOrgCharPos int
+ src []rune
+ buf []rune
+ obuf []rune
+ tokens token.Tokens
+ mstate *MultiLineState
+}
+
+type MultiLineState struct {
+ opt string
+ firstLineIndentColumn int
+ prevLineIndentColumn int
+ lineIndentColumn int
+ lastNotSpaceOnlyLineIndentColumn int
+ spaceOnlyIndentColumn int
+ foldedNewLine bool
+ isRawFolded bool
+ isLiteral bool
+ isFolded bool
+}
+
+var (
+ ctxPool = sync.Pool{
+ New: func() interface{} {
+ return createContext()
+ },
+ }
+)
+
+func createContext() *Context {
+ return &Context{
+ idx: 0,
+ tokens: token.Tokens{},
+ }
+}
+
+func newContext(src []rune) *Context {
+ ctx, _ := ctxPool.Get().(*Context)
+ ctx.reset(src)
+ return ctx
+}
+
+func (c *Context) release() {
+ ctxPool.Put(c)
+}
+
+func (c *Context) clear() {
+ c.resetBuffer()
+ c.mstate = nil
+}
+
+func (c *Context) reset(src []rune) {
+ c.idx = 0
+ c.size = len(src)
+ c.src = src
+ c.tokens = c.tokens[:0]
+ c.resetBuffer()
+ c.mstate = nil
+}
+
+func (c *Context) resetBuffer() {
+ c.buf = c.buf[:0]
+ c.obuf = c.obuf[:0]
+ c.notSpaceCharPos = 0
+ c.notSpaceOrgCharPos = 0
+}
+
+func (c *Context) breakMultiLine() {
+ c.mstate = nil
+}
+
+func (c *Context) getMultiLineState() *MultiLineState {
+ return c.mstate
+}
+
+func (c *Context) setLiteral(lastDelimColumn int, opt string) {
+ mstate := &MultiLineState{
+ isLiteral: true,
+ opt: opt,
+ }
+ indent := firstLineIndentColumnByOpt(opt)
+ if indent > 0 {
+ mstate.firstLineIndentColumn = lastDelimColumn + indent
+ }
+ c.mstate = mstate
+}
+
+func (c *Context) setFolded(lastDelimColumn int, opt string) {
+ mstate := &MultiLineState{
+ isFolded: true,
+ opt: opt,
+ }
+ indent := firstLineIndentColumnByOpt(opt)
+ if indent > 0 {
+ mstate.firstLineIndentColumn = lastDelimColumn + indent
+ }
+ c.mstate = mstate
+}
+
+func (c *Context) setRawFolded(column int) {
+ mstate := &MultiLineState{
+ isRawFolded: true,
+ }
+ mstate.updateIndentColumn(column)
+ c.mstate = mstate
+}
+
+func firstLineIndentColumnByOpt(opt string) int {
+ opt = strings.TrimPrefix(opt, "-")
+ opt = strings.TrimPrefix(opt, "+")
+ opt = strings.TrimSuffix(opt, "-")
+ opt = strings.TrimSuffix(opt, "+")
+ i, _ := strconv.ParseInt(opt, 10, 64)
+ return int(i)
+}
+
+func (s *MultiLineState) lastDelimColumn() int {
+ if s.firstLineIndentColumn == 0 {
+ return 0
+ }
+ return s.firstLineIndentColumn - 1
+}
+
+func (s *MultiLineState) updateIndentColumn(column int) {
+ if s.firstLineIndentColumn == 0 {
+ s.firstLineIndentColumn = column
+ }
+ if s.lineIndentColumn == 0 {
+ s.lineIndentColumn = column
+ }
+}
+
+func (s *MultiLineState) updateSpaceOnlyIndentColumn(column int) {
+ if s.firstLineIndentColumn != 0 {
+ return
+ }
+ s.spaceOnlyIndentColumn = column
+}
+
+func (s *MultiLineState) validateIndentAfterSpaceOnly(column int) error {
+ if s.firstLineIndentColumn != 0 {
+ return nil
+ }
+ if s.spaceOnlyIndentColumn > column {
+ return errors.New("invalid number of indent is specified after space only")
+ }
+ return nil
+}
+
+func (s *MultiLineState) validateIndentColumn() error {
+ if firstLineIndentColumnByOpt(s.opt) == 0 {
+ return nil
+ }
+ if s.firstLineIndentColumn > s.lineIndentColumn {
+ return errors.New("invalid number of indent is specified in the multi-line header")
+ }
+ return nil
+}
+
+func (s *MultiLineState) updateNewLineState() {
+ s.prevLineIndentColumn = s.lineIndentColumn
+ if s.lineIndentColumn != 0 {
+ s.lastNotSpaceOnlyLineIndentColumn = s.lineIndentColumn
+ }
+ s.foldedNewLine = true
+ s.lineIndentColumn = 0
+}
+
+func (s *MultiLineState) isIndentColumn(column int) bool {
+ if s.firstLineIndentColumn == 0 {
+ return column == 1
+ }
+ return s.firstLineIndentColumn > column
+}
+
+func (s *MultiLineState) addIndent(ctx *Context, column int) {
+ if s.firstLineIndentColumn == 0 {
+ return
+ }
+
+ // If the first line of the document has already been evaluated, the number is treated as the threshold, since the `firstLineIndentColumn` is a positive number.
+ if column < s.firstLineIndentColumn {
+ return
+ }
+
+ // `c.foldedNewLine` is a variable that is set to true for every newline.
+ if !s.isLiteral && s.foldedNewLine {
+ s.foldedNewLine = false
+ }
+ // Since addBuf ignore space character, add to the buffer directly.
+ ctx.buf = append(ctx.buf, ' ')
+ ctx.notSpaceCharPos = len(ctx.buf)
+}
+
+// updateNewLineInFolded if Folded or RawFolded context and the content on the current line starts at the same column as the previous line,
+// treat the new-line-char as a space.
+func (s *MultiLineState) updateNewLineInFolded(ctx *Context, column int) {
+ if s.isLiteral {
+ return
+ }
+
+ // Folded or RawFolded.
+
+ if !s.foldedNewLine {
+ return
+ }
+ var (
+ lastChar rune
+ prevLastChar rune
+ )
+ if len(ctx.buf) != 0 {
+ lastChar = ctx.buf[len(ctx.buf)-1]
+ }
+ if len(ctx.buf) > 1 {
+ prevLastChar = ctx.buf[len(ctx.buf)-2]
+ }
+ if s.lineIndentColumn == s.prevLineIndentColumn {
+ // ---
+ // >
+ // a
+ // b
+ if lastChar == '\n' {
+ ctx.buf[len(ctx.buf)-1] = ' '
+ }
+ } else if s.prevLineIndentColumn == 0 && s.lastNotSpaceOnlyLineIndentColumn == column {
+ // if previous line is indent-space and new-line-char only, prevLineIndentColumn is zero.
+ // In this case, last new-line-char is removed.
+ // ---
+ // >
+ // a
+ //
+ // b
+ if lastChar == '\n' && prevLastChar == '\n' {
+ ctx.buf = ctx.buf[:len(ctx.buf)-1]
+ ctx.notSpaceCharPos = len(ctx.buf)
+ }
+ }
+ s.foldedNewLine = false
+}
+
+func (s *MultiLineState) hasTrimAllEndNewlineOpt() bool {
+ return strings.HasPrefix(s.opt, "-") || strings.HasSuffix(s.opt, "-") || s.isRawFolded
+}
+
+func (s *MultiLineState) hasKeepAllEndNewlineOpt() bool {
+ return strings.HasPrefix(s.opt, "+") || strings.HasSuffix(s.opt, "+")
+}
+
+func (c *Context) addToken(tk *token.Token) {
+ if tk == nil {
+ return
+ }
+ c.tokens = append(c.tokens, tk)
+}
+
+func (c *Context) addBuf(r rune) {
+ if len(c.buf) == 0 && (r == ' ' || r == '\t') {
+ return
+ }
+ c.buf = append(c.buf, r)
+ if r != ' ' && r != '\t' {
+ c.notSpaceCharPos = len(c.buf)
+ }
+}
+
+func (c *Context) addBufWithTab(r rune) {
+ if len(c.buf) == 0 && r == ' ' {
+ return
+ }
+ c.buf = append(c.buf, r)
+ if r != ' ' {
+ c.notSpaceCharPos = len(c.buf)
+ }
+}
+
+func (c *Context) addOriginBuf(r rune) {
+ c.obuf = append(c.obuf, r)
+ if r != ' ' && r != '\t' {
+ c.notSpaceOrgCharPos = len(c.obuf)
+ }
+}
+
+func (c *Context) removeRightSpaceFromBuf() {
+ trimmedBuf := c.obuf[:c.notSpaceOrgCharPos]
+ buflen := len(trimmedBuf)
+ diff := len(c.obuf) - buflen
+ if diff > 0 {
+ c.obuf = c.obuf[:buflen]
+ c.buf = c.bufferedSrc()
+ }
+}
+
+func (c *Context) isEOS() bool {
+ return len(c.src)-1 <= c.idx
+}
+
+func (c *Context) isNextEOS() bool {
+ return len(c.src) <= c.idx+1
+}
+
+func (c *Context) next() bool {
+ return c.idx < c.size
+}
+
+func (c *Context) source(s, e int) string {
+ return string(c.src[s:e])
+}
+
+func (c *Context) previousChar() rune {
+ if c.idx > 0 {
+ return c.src[c.idx-1]
+ }
+ return rune(0)
+}
+
+func (c *Context) currentChar() rune {
+ if c.size > c.idx {
+ return c.src[c.idx]
+ }
+ return rune(0)
+}
+
+func (c *Context) nextChar() rune {
+ if c.size > c.idx+1 {
+ return c.src[c.idx+1]
+ }
+ return rune(0)
+}
+
+func (c *Context) repeatNum(r rune) int {
+ cnt := 0
+ for i := c.idx; i < c.size; i++ {
+ if c.src[i] == r {
+ cnt++
+ } else {
+ break
+ }
+ }
+ return cnt
+}
+
+func (c *Context) progress(num int) {
+ c.idx += num
+}
+
+func (c *Context) existsBuffer() bool {
+ return len(c.bufferedSrc()) != 0
+}
+
+func (c *Context) isMultiLine() bool {
+ return c.mstate != nil
+}
+
+func (c *Context) bufferedSrc() []rune {
+ src := c.buf[:c.notSpaceCharPos]
+ if c.isMultiLine() {
+ mstate := c.getMultiLineState()
+ // remove end '\n' character and trailing empty lines.
+ // https://yaml.org/spec/1.2.2/#8112-block-chomping-indicator
+ if mstate.hasTrimAllEndNewlineOpt() {
+ // If the '-' flag is specified, all trailing newline characters will be removed.
+ src = []rune(strings.TrimRight(string(src), "\n"))
+ } else if !mstate.hasKeepAllEndNewlineOpt() {
+ // Normally, all but one of the trailing newline characters are removed.
+ var newLineCharCount int
+ for i := len(src) - 1; i >= 0; i-- {
+ if src[i] == '\n' {
+ newLineCharCount++
+ continue
+ }
+ break
+ }
+ removedNewLineCharCount := newLineCharCount - 1
+ for removedNewLineCharCount > 0 {
+ src = []rune(strings.TrimSuffix(string(src), "\n"))
+ removedNewLineCharCount--
+ }
+ }
+
+ // If the text ends with a space character, remove all of them.
+ if mstate.hasTrimAllEndNewlineOpt() {
+ src = []rune(strings.TrimRight(string(src), " "))
+ }
+ if string(src) == "\n" {
+ // If the content consists only of a newline,
+ // it can be considered as the document ending without any specified value,
+ // so it is treated as an empty string.
+ src = []rune{}
+ }
+ if mstate.hasKeepAllEndNewlineOpt() && len(src) == 0 {
+ src = []rune{'\n'}
+ }
+ }
+ return src
+}
+
+func (c *Context) bufferedToken(pos *token.Position) *token.Token {
+ if c.idx == 0 {
+ return nil
+ }
+ source := c.bufferedSrc()
+ if len(source) == 0 {
+ c.buf = c.buf[:0] // clear value's buffer only.
+ return nil
+ }
+ var tk *token.Token
+ if c.isMultiLine() {
+ tk = token.String(string(source), string(c.obuf), pos)
+ } else {
+ tk = token.New(string(source), string(c.obuf), pos)
+ }
+ c.setTokenTypeByPrevTag(tk)
+ c.resetBuffer()
+ return tk
+}
+
+func (c *Context) setTokenTypeByPrevTag(tk *token.Token) {
+ lastTk := c.lastToken()
+ if lastTk == nil {
+ return
+ }
+ if lastTk.Type != token.TagType {
+ return
+ }
+ tag := token.ReservedTagKeyword(lastTk.Value)
+ if _, exists := token.ReservedTagKeywordMap[tag]; !exists {
+ tk.Type = token.StringType
+ }
+}
+
+func (c *Context) lastToken() *token.Token {
+ if len(c.tokens) != 0 {
+ return c.tokens[len(c.tokens)-1]
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go
new file mode 100644
index 0000000..3f5419a
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go
@@ -0,0 +1,17 @@
+package scanner
+
+import "github.com/goccy/go-yaml/token"
+
+type InvalidTokenError struct {
+ Token *token.Token
+}
+
+func (e *InvalidTokenError) Error() string {
+ return e.Token.Error
+}
+
+func ErrInvalidToken(tk *token.Token) *InvalidTokenError {
+ return &InvalidTokenError{
+ Token: tk,
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go
new file mode 100644
index 0000000..799f469
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go
@@ -0,0 +1,1536 @@
+package scanner
+
+import (
+ "errors"
+ "fmt"
+ "io"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// IndentState state for indent
+type IndentState int
+
+const (
+ // IndentStateEqual equals previous indent
+ IndentStateEqual IndentState = iota
+ // IndentStateUp more indent than previous
+ IndentStateUp
+ // IndentStateDown less indent than previous
+ IndentStateDown
+ // IndentStateKeep uses not indent token
+ IndentStateKeep
+)
+
+// Scanner holds the scanner's internal state while processing a given text.
+// It can be allocated as part of another data structure but must be initialized via Init before use.
+type Scanner struct {
+ source []rune
+ sourcePos int
+ sourceSize int
+ // line number. This number starts from 1.
+ line int
+ // column number. This number starts from 1.
+ column int
+ // offset represents the offset from the beginning of the source.
+ offset int
+ // lastDelimColumn is the last column needed to compare indent is retained.
+ lastDelimColumn int
+ // indentNum indicates the number of spaces used for indentation.
+ indentNum int
+ // prevLineIndentNum indicates the number of spaces used for indentation at previous line.
+ prevLineIndentNum int
+ // indentLevel indicates the level of indent depth. This value does not match the column value.
+ indentLevel int
+ isFirstCharAtLine bool
+ isAnchor bool
+ isAlias bool
+ isDirective bool
+ startedFlowSequenceNum int
+ startedFlowMapNum int
+ indentState IndentState
+ savedPos *token.Position
+}
+
+func (s *Scanner) pos() *token.Position {
+ return &token.Position{
+ Line: s.line,
+ Column: s.column,
+ Offset: s.offset,
+ IndentNum: s.indentNum,
+ IndentLevel: s.indentLevel,
+ }
+}
+
+func (s *Scanner) bufferedToken(ctx *Context) *token.Token {
+ if s.savedPos != nil {
+ tk := ctx.bufferedToken(s.savedPos)
+ s.savedPos = nil
+ return tk
+ }
+ line := s.line
+ column := s.column - len(ctx.buf)
+ level := s.indentLevel
+ if ctx.isMultiLine() {
+ line -= s.newLineCount(ctx.buf)
+ column = strings.Index(string(ctx.obuf), string(ctx.buf)) + 1
+ // Since we are in a literal, folded or raw folded
+ // we can use the indent level from the last token.
+ last := ctx.lastToken()
+ if last != nil { // The last token should never be nil here.
+ level = last.Position.IndentLevel + 1
+ }
+ }
+ return ctx.bufferedToken(&token.Position{
+ Line: line,
+ Column: column,
+ Offset: s.offset - len(ctx.buf),
+ IndentNum: s.indentNum,
+ IndentLevel: level,
+ })
+}
+
+func (s *Scanner) progressColumn(ctx *Context, num int) {
+ s.column += num
+ s.offset += num
+ s.progress(ctx, num)
+}
+
+func (s *Scanner) progressOnly(ctx *Context, num int) {
+ s.offset += num
+ s.progress(ctx, num)
+}
+
+func (s *Scanner) progressLine(ctx *Context) {
+ s.prevLineIndentNum = s.indentNum
+ s.column = 1
+ s.line++
+ s.offset++
+ s.indentNum = 0
+ s.isFirstCharAtLine = true
+ s.isAnchor = false
+ s.isAlias = false
+ s.isDirective = false
+ s.progress(ctx, 1)
+}
+
+func (s *Scanner) progress(ctx *Context, num int) {
+ ctx.progress(num)
+ s.sourcePos += num
+}
+
+func (s *Scanner) isNewLineChar(c rune) bool {
+ if c == '\n' {
+ return true
+ }
+ if c == '\r' {
+ return true
+ }
+ return false
+}
+
+func (s *Scanner) newLineCount(src []rune) int {
+ size := len(src)
+ cnt := 0
+ for i := 0; i < size; i++ {
+ c := src[i]
+ switch c {
+ case '\r':
+ if i+1 < size && src[i+1] == '\n' {
+ i++
+ }
+ cnt++
+ case '\n':
+ cnt++
+ }
+ }
+ return cnt
+}
+
+func (s *Scanner) updateIndentLevel() {
+ if s.prevLineIndentNum < s.indentNum {
+ s.indentLevel++
+ } else if s.prevLineIndentNum > s.indentNum {
+ if s.indentLevel > 0 {
+ s.indentLevel--
+ }
+ }
+}
+
+func (s *Scanner) updateIndentState(ctx *Context) {
+ if s.lastDelimColumn == 0 {
+ return
+ }
+
+ if s.lastDelimColumn < s.column {
+ s.indentState = IndentStateUp
+ } else {
+ // If lastDelimColumn and s.column are the same,
+ // treat as Down state since it is the same column as delimiter.
+ s.indentState = IndentStateDown
+ }
+}
+
+func (s *Scanner) updateIndent(ctx *Context, c rune) {
+ if s.isFirstCharAtLine && s.isNewLineChar(c) {
+ return
+ }
+ if s.isFirstCharAtLine && c == ' ' {
+ s.indentNum++
+ return
+ }
+ if s.isFirstCharAtLine && c == '\t' {
+ // found tab indent.
+ // In this case, scanTab returns error.
+ return
+ }
+ if !s.isFirstCharAtLine {
+ s.indentState = IndentStateKeep
+ return
+ }
+ s.updateIndentLevel()
+ s.updateIndentState(ctx)
+ s.isFirstCharAtLine = false
+}
+
+func (s *Scanner) isChangedToIndentStateDown() bool {
+ return s.indentState == IndentStateDown
+}
+
+func (s *Scanner) isChangedToIndentStateUp() bool {
+ return s.indentState == IndentStateUp
+}
+
+func (s *Scanner) addBufferedTokenIfExists(ctx *Context) {
+ ctx.addToken(s.bufferedToken(ctx))
+}
+
+func (s *Scanner) breakMultiLine(ctx *Context) {
+ ctx.breakMultiLine()
+}
+
+func (s *Scanner) scanSingleQuote(ctx *Context) (*token.Token, error) {
+ ctx.addOriginBuf('\'')
+ srcpos := s.pos()
+ startIndex := ctx.idx + 1
+ src := ctx.src
+ size := len(src)
+ value := []rune{}
+ isFirstLineChar := false
+ isNewLine := false
+
+ for idx := startIndex; idx < size; idx++ {
+ if !isNewLine {
+ s.progressColumn(ctx, 1)
+ } else {
+ isNewLine = false
+ }
+ c := src[idx]
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ notSpaceIdx := -1
+ for i := len(value) - 1; i >= 0; i-- {
+ if value[i] == ' ' {
+ continue
+ }
+ notSpaceIdx = i
+ break
+ }
+ if len(value) > notSpaceIdx {
+ value = value[:notSpaceIdx+1]
+ }
+ if isFirstLineChar {
+ value = append(value, '\n')
+ } else {
+ value = append(value, ' ')
+ }
+ isFirstLineChar = true
+ isNewLine = true
+ s.progressLine(ctx)
+ if idx+1 < size {
+ if err := s.validateDocumentSeparatorMarker(ctx, src[idx+1:]); err != nil {
+ return nil, err
+ }
+ }
+ continue
+ } else if isFirstLineChar && c == ' ' {
+ continue
+ } else if isFirstLineChar && c == '\t' {
+ if s.lastDelimColumn >= s.column {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "tab character cannot be used for indentation in single-quoted text",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ continue
+ } else if c != '\'' {
+ value = append(value, c)
+ isFirstLineChar = false
+ continue
+ } else if idx+1 < len(ctx.src) && ctx.src[idx+1] == '\'' {
+ // '' handle as ' character
+ value = append(value, c)
+ ctx.addOriginBuf(c)
+ idx++
+ s.progressColumn(ctx, 1)
+ continue
+ }
+ s.progressColumn(ctx, 1)
+ return token.SingleQuote(string(value), string(ctx.obuf), srcpos), nil
+ }
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "could not find end character of single-quoted text",
+ string(ctx.obuf), srcpos,
+ ),
+ )
+}
+
+func hexToInt(b rune) int {
+ if b >= 'A' && b <= 'F' {
+ return int(b) - 'A' + 10
+ }
+ if b >= 'a' && b <= 'f' {
+ return int(b) - 'a' + 10
+ }
+ return int(b) - '0'
+}
+
+func hexRunesToInt(b []rune) int {
+ sum := 0
+ for i := 0; i < len(b); i++ {
+ sum += hexToInt(b[i]) << (uint(len(b)-i-1) * 4)
+ }
+ return sum
+}
+
+func (s *Scanner) scanDoubleQuote(ctx *Context) (*token.Token, error) {
+ ctx.addOriginBuf('"')
+ srcpos := s.pos()
+ startIndex := ctx.idx + 1
+ src := ctx.src
+ size := len(src)
+ value := []rune{}
+ isFirstLineChar := false
+ isNewLine := false
+
+ for idx := startIndex; idx < size; idx++ {
+ if !isNewLine {
+ s.progressColumn(ctx, 1)
+ } else {
+ isNewLine = false
+ }
+ c := src[idx]
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ notSpaceIdx := -1
+ for i := len(value) - 1; i >= 0; i-- {
+ if value[i] == ' ' {
+ continue
+ }
+ notSpaceIdx = i
+ break
+ }
+ if len(value) > notSpaceIdx {
+ value = value[:notSpaceIdx+1]
+ }
+ if isFirstLineChar {
+ value = append(value, '\n')
+ } else {
+ value = append(value, ' ')
+ }
+ isFirstLineChar = true
+ isNewLine = true
+ s.progressLine(ctx)
+ if idx+1 < size {
+ if err := s.validateDocumentSeparatorMarker(ctx, src[idx+1:]); err != nil {
+ return nil, err
+ }
+ }
+ continue
+ } else if isFirstLineChar && c == ' ' {
+ continue
+ } else if isFirstLineChar && c == '\t' {
+ if s.lastDelimColumn >= s.column {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "tab character cannot be used for indentation in double-quoted text",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ continue
+ } else if c == '\\' {
+ isFirstLineChar = false
+ if idx+1 >= size {
+ value = append(value, c)
+ continue
+ }
+ nextChar := src[idx+1]
+ progress := 0
+ switch nextChar {
+ case '0':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x00)
+ case 'a':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x07)
+ case 'b':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x08)
+ case 't':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x09)
+ case 'n':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0A)
+ case 'v':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0B)
+ case 'f':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0C)
+ case 'r':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0D)
+ case 'e':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x1B)
+ case ' ':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x20)
+ case '"':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x22)
+ case '/':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2F)
+ case '\\':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x5C)
+ case 'N':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x85)
+ case '_':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0xA0)
+ case 'L':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2028)
+ case 'P':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2029)
+ case 'x':
+ if idx+3 >= size {
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, nextChar)
+ } else {
+ progress = 3
+ codeNum := hexRunesToInt(src[idx+2 : idx+progress+1])
+ value = append(value, rune(codeNum))
+ }
+ case 'u':
+ // \u0000 style must have 5 characters at least.
+ if idx+5 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-16 character",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ progress = 5
+ codeNum := hexRunesToInt(src[idx+2 : idx+6])
+
+ // handle surrogate pairs.
+ if codeNum >= 0xD800 && codeNum <= 0xDBFF {
+ high := codeNum
+
+ // \u0000\u0000 style must have 11 characters at least.
+ if idx+11 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-16 surrogate pair",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+
+ if src[idx+6] != '\\' || src[idx+7] != 'u' {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "found unexpected character after high surrogate for UTF-16 surrogate pair",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+
+ low := hexRunesToInt(src[idx+8 : idx+12])
+ if low < 0xDC00 || low > 0xDFFF {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "found unexpected low surrogate after high surrogate",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ codeNum = ((high - 0xD800) * 0x400) + (low - 0xDC00) + 0x10000
+ progress += 6
+ }
+ value = append(value, rune(codeNum))
+ case 'U':
+ // \U00000000 style must have 9 characters at least.
+ if idx+9 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-32 character",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ progress = 9
+ codeNum := hexRunesToInt(src[idx+2 : idx+10])
+ value = append(value, rune(codeNum))
+ case '\n':
+ isFirstLineChar = true
+ isNewLine = true
+ ctx.addOriginBuf(nextChar)
+ s.progressColumn(ctx, 1)
+ s.progressLine(ctx)
+ idx++
+ continue
+ case '\r':
+ isFirstLineChar = true
+ isNewLine = true
+ ctx.addOriginBuf(nextChar)
+ s.progressLine(ctx)
+ progress = 1
+ // Skip \n after \r in CRLF sequences
+ if idx+2 < size && src[idx+2] == '\n' {
+ ctx.addOriginBuf('\n')
+ progress = 2
+ }
+ case '\t':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, nextChar)
+ default:
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ fmt.Sprintf("found unknown escape character %q", nextChar),
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ idx += progress
+ s.progressColumn(ctx, progress)
+ continue
+ } else if c == '\t' {
+ var (
+ foundNotSpaceChar bool
+ progress int
+ )
+ for i := idx + 1; i < size; i++ {
+ if src[i] == ' ' || src[i] == '\t' {
+ progress++
+ continue
+ }
+ if s.isNewLineChar(src[i]) {
+ break
+ }
+ foundNotSpaceChar = true
+ }
+ if foundNotSpaceChar {
+ value = append(value, c)
+ if src[idx+1] != '"' {
+ s.progressColumn(ctx, 1)
+ }
+ } else {
+ idx += progress
+ s.progressColumn(ctx, progress)
+ }
+ continue
+ } else if c != '"' {
+ value = append(value, c)
+ isFirstLineChar = false
+ continue
+ }
+ s.progressColumn(ctx, 1)
+ return token.DoubleQuote(string(value), string(ctx.obuf), srcpos), nil
+ }
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "could not find end character of double-quoted text",
+ string(ctx.obuf), srcpos,
+ ),
+ )
+}
+
+func (s *Scanner) validateDocumentSeparatorMarker(ctx *Context, src []rune) error {
+ if s.foundDocumentSeparatorMarker(src) {
+ return ErrInvalidToken(
+ token.Invalid("found unexpected document separator", string(ctx.obuf), s.pos()),
+ )
+ }
+ return nil
+}
+
+func (s *Scanner) foundDocumentSeparatorMarker(src []rune) bool {
+ if len(src) < 3 {
+ return false
+ }
+ var marker string
+ if len(src) == 3 {
+ marker = string(src)
+ } else {
+ marker = strings.TrimRightFunc(string(src[:4]), func(r rune) bool {
+ return r == ' ' || r == '\t' || r == '\n' || r == '\r'
+ })
+ }
+ return marker == "---" || marker == "..."
+}
+
+func (s *Scanner) scanQuote(ctx *Context, ch rune) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+ if ch == '\'' {
+ tk, err := s.scanSingleQuote(ctx)
+ if err != nil {
+ return false, err
+ }
+ ctx.addToken(tk)
+ } else {
+ tk, err := s.scanDoubleQuote(ctx)
+ if err != nil {
+ return false, err
+ }
+ ctx.addToken(tk)
+ }
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanWhiteSpace(ctx *Context) bool {
+ if ctx.isMultiLine() {
+ return false
+ }
+ if !s.isAnchor && !s.isDirective && !s.isAlias && !s.isFirstCharAtLine {
+ return false
+ }
+
+ if s.isFirstCharAtLine {
+ s.progressColumn(ctx, 1)
+ ctx.addOriginBuf(' ')
+ return true
+ }
+ if s.isDirective {
+ s.addBufferedTokenIfExists(ctx)
+ s.progressColumn(ctx, 1)
+ ctx.addOriginBuf(' ')
+ return true
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ s.isAnchor = false
+ s.isAlias = false
+ return true
+}
+
+func (s *Scanner) isMergeKey(ctx *Context) bool {
+ if ctx.repeatNum('<') != 2 {
+ return false
+ }
+ src := ctx.src
+ size := len(src)
+ for idx := ctx.idx + 2; idx < size; idx++ {
+ c := src[idx]
+ if c == ' ' {
+ continue
+ }
+ if c != ':' {
+ return false
+ }
+ if idx+1 < size {
+ nc := src[idx+1]
+ if nc == ' ' || s.isNewLineChar(nc) {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+func (s *Scanner) scanTag(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() || s.isDirective {
+ return false, nil
+ }
+
+ ctx.addOriginBuf('!')
+ s.progress(ctx, 1) // skip '!' character
+
+ var progress int
+ for idx, c := range ctx.src[ctx.idx:] {
+ progress = idx + 1
+ switch c {
+ case ' ':
+ ctx.addOriginBuf(c)
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value)))
+ ctx.clear()
+ return true, nil
+ case ',':
+ if s.startedFlowSequenceNum > 0 || s.startedFlowMapNum > 0 {
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value))-1) // progress column before collect-entry for scanning it at scanFlowEntry function.
+ ctx.clear()
+ return true, nil
+ } else {
+ ctx.addOriginBuf(c)
+ }
+ case '\n', '\r':
+ ctx.addOriginBuf(c)
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value))-1) // progress column before new-line-char for scanning new-line-char at scanNewLine function.
+ ctx.clear()
+ return true, nil
+ case '{', '}':
+ ctx.addOriginBuf(c)
+ s.progressColumn(ctx, progress)
+ invalidTk := token.Invalid(fmt.Sprintf("found invalid tag character %q", c), string(ctx.obuf), s.pos())
+ return false, ErrInvalidToken(invalidTk)
+ default:
+ ctx.addOriginBuf(c)
+ }
+ }
+ s.progressColumn(ctx, progress)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanComment(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ c := ctx.previousChar()
+ if c != ' ' && c != '\t' && !s.isNewLineChar(c) {
+ return false
+ }
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('#')
+ s.progress(ctx, 1) // skip '#' character
+
+ for idx, c := range ctx.src[ctx.idx:] {
+ ctx.addOriginBuf(c)
+ if !s.isNewLineChar(c) {
+ continue
+ }
+ if ctx.previousChar() == '\\' {
+ continue
+ }
+ value := ctx.source(ctx.idx, ctx.idx+idx)
+ progress := len([]rune(value))
+ ctx.addToken(token.Comment(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, progress)
+ s.progressLine(ctx)
+ ctx.clear()
+ return true
+ }
+ // document ends with comment.
+ value := string(ctx.src[ctx.idx:])
+ ctx.addToken(token.Comment(value, string(ctx.obuf), s.pos()))
+ progress := len([]rune(value))
+ s.progressColumn(ctx, progress)
+ s.progressLine(ctx)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMultiLine(ctx *Context, c rune) error {
+ state := ctx.getMultiLineState()
+ ctx.addOriginBuf(c)
+ // normalize CR and CRLF to LF
+ if c == '\r' {
+ if ctx.nextChar() == '\n' {
+ ctx.addOriginBuf('\n')
+ s.progress(ctx, 1)
+ s.offset++
+ }
+ c = '\n'
+ }
+ if ctx.isEOS() {
+ if s.isFirstCharAtLine && c == ' ' {
+ state.addIndent(ctx, s.column)
+ } else {
+ ctx.addBuf(c)
+ }
+ state.updateIndentColumn(s.column)
+ if err := state.validateIndentColumn(); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ value := ctx.bufferedSrc()
+ ctx.addToken(token.String(string(value), string(ctx.obuf), s.pos()))
+ ctx.clear()
+ s.progressColumn(ctx, 1)
+ } else if s.isNewLineChar(c) {
+ ctx.addBuf(c)
+ state.updateSpaceOnlyIndentColumn(s.column - 1)
+ state.updateNewLineState()
+ s.progressLine(ctx)
+ if ctx.next() {
+ if s.foundDocumentSeparatorMarker(ctx.src[ctx.idx:]) {
+ value := ctx.bufferedSrc()
+ ctx.addToken(token.String(string(value), string(ctx.obuf), s.pos()))
+ ctx.clear()
+ s.breakMultiLine(ctx)
+ }
+ }
+ } else if s.isFirstCharAtLine && c == ' ' {
+ state.addIndent(ctx, s.column)
+ s.progressColumn(ctx, 1)
+ } else if s.isFirstCharAtLine && c == '\t' && state.isIndentColumn(s.column) {
+ err := ErrInvalidToken(
+ token.Invalid(
+ "found a tab character where an indentation space is expected",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ return err
+ } else if c == '\t' && !state.isIndentColumn(s.column) {
+ ctx.addBufWithTab(c)
+ s.progressColumn(ctx, 1)
+ } else {
+ if err := state.validateIndentAfterSpaceOnly(s.column); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ state.updateIndentColumn(s.column)
+ if err := state.validateIndentColumn(); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ if col := state.lastDelimColumn(); col > 0 {
+ s.lastDelimColumn = col
+ }
+ state.updateNewLineInFolded(ctx, s.column)
+ ctx.addBufWithTab(c)
+ s.progressColumn(ctx, 1)
+ }
+ return nil
+}
+
+func (s *Scanner) scanNewLine(ctx *Context, c rune) {
+ if len(ctx.buf) > 0 && s.savedPos == nil {
+ bufLen := len(ctx.bufferedSrc())
+ s.savedPos = s.pos()
+ s.savedPos.Column -= bufLen
+ s.savedPos.Offset -= bufLen
+ }
+
+ // if the following case, origin buffer has unnecessary two spaces.
+ // So, `removeRightSpaceFromOriginBuf` remove them, also fix column number too.
+ // ---
+ // a:[space][space]
+ // b: c
+ ctx.removeRightSpaceFromBuf()
+
+ // There is no problem that we ignore CR which followed by LF and normalize it to LF, because of following YAML1.2 spec.
+ // > Line breaks inside scalar content must be normalized by the YAML processor. Each such line break must be parsed into a single line feed character.
+ // > Outside scalar content, YAML allows any line break to be used to terminate lines.
+ // > -- https://yaml.org/spec/1.2/spec.html
+ if c == '\r' && ctx.nextChar() == '\n' {
+ ctx.addOriginBuf('\r')
+ s.progress(ctx, 1)
+ s.offset++
+ c = '\n'
+ }
+
+ if ctx.isEOS() {
+ s.addBufferedTokenIfExists(ctx)
+ } else if s.isAnchor || s.isAlias || s.isDirective {
+ s.addBufferedTokenIfExists(ctx)
+ }
+ if ctx.existsBuffer() && s.isFirstCharAtLine {
+ if ctx.buf[len(ctx.buf)-1] == ' ' {
+ ctx.buf[len(ctx.buf)-1] = '\n'
+ } else {
+ ctx.buf = append(ctx.buf, '\n')
+ }
+ } else {
+ ctx.addBuf(' ')
+ }
+ ctx.addOriginBuf(c)
+ s.progressLine(ctx)
+}
+
+func (s *Scanner) isFlowMode() bool {
+ if s.startedFlowSequenceNum > 0 {
+ return true
+ }
+ if s.startedFlowMapNum > 0 {
+ return true
+ }
+ return false
+}
+
+func (s *Scanner) scanFlowMapStart(ctx *Context) bool {
+ if ctx.existsBuffer() && !s.isFlowMode() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('{')
+ ctx.addToken(token.MappingStart(string(ctx.obuf), s.pos()))
+ s.startedFlowMapNum++
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowMapEnd(ctx *Context) bool {
+ if s.startedFlowMapNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('}')
+ ctx.addToken(token.MappingEnd(string(ctx.obuf), s.pos()))
+ s.startedFlowMapNum--
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowArrayStart(ctx *Context) bool {
+ if ctx.existsBuffer() && !s.isFlowMode() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('[')
+ ctx.addToken(token.SequenceStart(string(ctx.obuf), s.pos()))
+ s.startedFlowSequenceNum++
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowArrayEnd(ctx *Context) bool {
+ if ctx.existsBuffer() && s.startedFlowSequenceNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf(']')
+ ctx.addToken(token.SequenceEnd(string(ctx.obuf), s.pos()))
+ s.startedFlowSequenceNum--
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowEntry(ctx *Context, c rune) bool {
+ if s.startedFlowSequenceNum <= 0 && s.startedFlowMapNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf(c)
+ ctx.addToken(token.CollectEntry(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMapDelim(ctx *Context) (bool, error) {
+ nc := ctx.nextChar()
+ if s.isDirective || s.isAnchor || s.isAlias {
+ return false, nil
+ }
+ if s.startedFlowMapNum <= 0 && nc != ' ' && nc != '\t' && !s.isNewLineChar(nc) && !ctx.isNextEOS() {
+ return false, nil
+ }
+ if s.startedFlowMapNum > 0 && nc == '/' {
+ // like http://
+ return false, nil
+ }
+ if s.startedFlowMapNum > 0 {
+ tk := ctx.lastToken()
+ if tk != nil && tk.Type == token.MappingValueType {
+ return false, nil
+ }
+ }
+
+ if strings.HasPrefix(strings.TrimPrefix(string(ctx.obuf), " "), "\t") && !strings.HasPrefix(string(ctx.buf), "\t") {
+ invalidTk := token.Invalid("tab character cannot use as a map key directly", string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return false, ErrInvalidToken(invalidTk)
+ }
+
+ // mapping value
+ tk := s.bufferedToken(ctx)
+ if tk != nil {
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ } else if tk := ctx.lastToken(); tk != nil {
+ // If the map key is quote, the buffer does not exist because it has already been cut into tokens.
+ // Therefore, we need to check the last token.
+ if tk.Indicator == token.QuotedScalarIndicator {
+ s.lastDelimColumn = tk.Position.Column
+ }
+ }
+ ctx.addToken(token.MappingValue(s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanDocumentStart(ctx *Context) bool {
+ if s.indentNum != 0 {
+ return false
+ }
+ if s.column != 1 {
+ return false
+ }
+ if ctx.repeatNum('-') != 3 {
+ return false
+ }
+ if ctx.size > ctx.idx+3 {
+ c := ctx.src[ctx.idx+3]
+ if c != ' ' && c != '\t' && c != '\n' && c != '\r' {
+ return false
+ }
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addToken(token.DocumentHeader(string(ctx.obuf)+"---", s.pos()))
+ s.progressColumn(ctx, 3)
+ ctx.clear()
+ s.clearState()
+ return true
+}
+
+func (s *Scanner) scanDocumentEnd(ctx *Context) bool {
+ if s.indentNum != 0 {
+ return false
+ }
+ if s.column != 1 {
+ return false
+ }
+ if ctx.repeatNum('.') != 3 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addToken(token.DocumentEnd(string(ctx.obuf)+"...", s.pos()))
+ s.progressColumn(ctx, 3)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMergeKey(ctx *Context) bool {
+ if !s.isMergeKey(ctx) {
+ return false
+ }
+
+ s.lastDelimColumn = s.column
+ ctx.addToken(token.MergeKey(string(ctx.obuf)+"<<", s.pos()))
+ s.progressColumn(ctx, 2)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanRawFoldedChar(ctx *Context) bool {
+ if !ctx.existsBuffer() {
+ return false
+ }
+ if !s.isChangedToIndentStateUp() {
+ return false
+ }
+
+ ctx.setRawFolded(s.column)
+ ctx.addBuf('-')
+ ctx.addOriginBuf('-')
+ s.progressColumn(ctx, 1)
+ return true
+}
+
+func (s *Scanner) scanSequence(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+
+ nc := ctx.nextChar()
+ if nc != 0 && nc != ' ' && nc != '\t' && !s.isNewLineChar(nc) {
+ return false, nil
+ }
+
+ if strings.HasPrefix(strings.TrimPrefix(string(ctx.obuf), " "), "\t") {
+ invalidTk := token.Invalid("tab character cannot use as a sequence delimiter", string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return false, ErrInvalidToken(invalidTk)
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('-')
+ tk := token.SequenceEntry(string(ctx.obuf), s.pos())
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanMultiLineHeader(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+
+ if err := s.scanMultiLineHeaderOption(ctx); err != nil {
+ return false, err
+ }
+ s.progressLine(ctx)
+ return true, nil
+}
+
+func (s *Scanner) validateMultiLineHeaderOption(opt string) error {
+ if len(opt) == 0 {
+ return nil
+ }
+ orgOpt := opt
+ opt = strings.TrimPrefix(opt, "-")
+ opt = strings.TrimPrefix(opt, "+")
+ opt = strings.TrimSuffix(opt, "-")
+ opt = strings.TrimSuffix(opt, "+")
+ if len(opt) == 0 {
+ return nil
+ }
+ if opt == "0" {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ i, err := strconv.ParseInt(opt, 10, 64)
+ if err != nil {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ if i > 9 {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ return nil
+}
+
+func (s *Scanner) scanMultiLineHeaderOption(ctx *Context) error {
+ header := ctx.currentChar()
+ ctx.addOriginBuf(header)
+ s.progress(ctx, 1) // skip '|' or '>' character
+
+ var progress int
+ var crlf bool
+ for idx, c := range ctx.src[ctx.idx:] {
+ progress = idx
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ nextIdx := ctx.idx + idx + 1
+ if c == '\r' && nextIdx < len(ctx.src) && ctx.src[nextIdx] == '\n' {
+ crlf = true
+ continue // process \n in the next iteration
+ }
+ break
+ }
+ }
+ endPos := ctx.idx + progress
+ if crlf {
+ // Exclude \r
+ endPos = endPos - 1
+ }
+ value := strings.TrimRight(ctx.source(ctx.idx, endPos), " ")
+ commentValueIndex := strings.Index(value, "#")
+ opt := value
+ if commentValueIndex > 0 {
+ opt = value[:commentValueIndex]
+ }
+ opt = strings.TrimRightFunc(opt, func(r rune) bool {
+ return r == ' ' || r == '\t'
+ })
+ if len(opt) != 0 {
+ if err := s.validateMultiLineHeaderOption(opt); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, progress)
+ return ErrInvalidToken(invalidTk)
+ }
+ }
+ if s.column == 1 {
+ s.lastDelimColumn = 1
+ }
+
+ commentIndex := strings.Index(string(ctx.obuf), "#")
+ headerBuf := string(ctx.obuf)
+ if commentIndex > 0 {
+ headerBuf = headerBuf[:commentIndex]
+ }
+ switch header {
+ case '|':
+ ctx.addToken(token.Literal("|"+opt, headerBuf, s.pos()))
+ ctx.setLiteral(s.lastDelimColumn, opt)
+ case '>':
+ ctx.addToken(token.Folded(">"+opt, headerBuf, s.pos()))
+ ctx.setFolded(s.lastDelimColumn, opt)
+ }
+ if commentIndex > 0 {
+ comment := value[commentValueIndex+1:]
+ s.offset += len(headerBuf)
+ s.column += len(headerBuf)
+ ctx.addToken(token.Comment(comment, string(ctx.obuf[len(headerBuf):]), s.pos()))
+ }
+ s.indentState = IndentStateKeep
+ ctx.resetBuffer()
+ s.progressColumn(ctx, progress)
+ return nil
+}
+
+func (s *Scanner) scanMapKey(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ nc := ctx.nextChar()
+ if nc != ' ' && nc != '\t' {
+ return false
+ }
+
+ tk := token.MappingKey(s.pos())
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanDirective(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+ if s.indentNum != 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('%')
+ ctx.addToken(token.Directive(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ s.isDirective = true
+ return true
+}
+
+func (s *Scanner) scanAnchor(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('&')
+ ctx.addToken(token.Anchor(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ s.isAnchor = true
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanAlias(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('*')
+ ctx.addToken(token.Alias(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ s.isAlias = true
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanReservedChar(ctx *Context, c rune) error {
+ if ctx.existsBuffer() {
+ return nil
+ }
+
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ err := ErrInvalidToken(
+ token.Invalid(
+ fmt.Sprintf("%q is a reserved character", c),
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return err
+}
+
+func (s *Scanner) scanTab(ctx *Context, c rune) error {
+ if s.startedFlowSequenceNum > 0 || s.startedFlowMapNum > 0 {
+ // tabs character is allowed in flow mode.
+ return nil
+ }
+
+ if !s.isFirstCharAtLine {
+ return nil
+ }
+
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ err := ErrInvalidToken(
+ token.Invalid("found character '\t' that cannot start any token",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return err
+}
+
+func (s *Scanner) scan(ctx *Context) error {
+ for ctx.next() {
+ c := ctx.currentChar()
+ // First, change the IndentState.
+ // If the target character is the first character in a line, IndentState is Up/Down/Equal state.
+ // The second and subsequent letters are Keep.
+ s.updateIndent(ctx, c)
+
+ // If IndentState is down, tokens are split, so the buffer accumulated until that point needs to be cutted as a token.
+ if s.isChangedToIndentStateDown() {
+ s.addBufferedTokenIfExists(ctx)
+ }
+ if ctx.isMultiLine() {
+ if s.isChangedToIndentStateDown() {
+ if tk := ctx.lastToken(); tk != nil {
+ // If literal/folded content is empty, no string token is added.
+ // Therefore, add an empty string token.
+ // But if literal/folded token column is 1, it is invalid at down state.
+ if tk.Position.Column == 1 {
+ return ErrInvalidToken(
+ token.Invalid(
+ "could not find multi-line content",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ if tk.Type != token.StringType {
+ ctx.addToken(token.String("", "", s.pos()))
+ }
+ }
+ s.breakMultiLine(ctx)
+ } else {
+ if err := s.scanMultiLine(ctx, c); err != nil {
+ return err
+ }
+ continue
+ }
+ }
+ switch c {
+ case '{':
+ if s.scanFlowMapStart(ctx) {
+ continue
+ }
+ case '}':
+ if s.scanFlowMapEnd(ctx) {
+ continue
+ }
+ case '.':
+ if s.scanDocumentEnd(ctx) {
+ continue
+ }
+ case '<':
+ if s.scanMergeKey(ctx) {
+ continue
+ }
+ case '-':
+ if s.scanDocumentStart(ctx) {
+ continue
+ }
+ if s.scanRawFoldedChar(ctx) {
+ continue
+ }
+ scanned, err := s.scanSequence(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '[':
+ if s.scanFlowArrayStart(ctx) {
+ continue
+ }
+ case ']':
+ if s.scanFlowArrayEnd(ctx) {
+ continue
+ }
+ case ',':
+ if s.scanFlowEntry(ctx, c) {
+ continue
+ }
+ case ':':
+ scanned, err := s.scanMapDelim(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '|', '>':
+ scanned, err := s.scanMultiLineHeader(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '!':
+ scanned, err := s.scanTag(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '%':
+ if s.scanDirective(ctx) {
+ continue
+ }
+ case '?':
+ if s.scanMapKey(ctx) {
+ continue
+ }
+ case '&':
+ if s.scanAnchor(ctx) {
+ continue
+ }
+ case '*':
+ if s.scanAlias(ctx) {
+ continue
+ }
+ case '#':
+ if s.scanComment(ctx) {
+ continue
+ }
+ case '\'', '"':
+ scanned, err := s.scanQuote(ctx, c)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '\r', '\n':
+ s.scanNewLine(ctx, c)
+ continue
+ case ' ':
+ if s.scanWhiteSpace(ctx) {
+ continue
+ }
+ case '@', '`':
+ if err := s.scanReservedChar(ctx, c); err != nil {
+ return err
+ }
+ case '\t':
+ if ctx.existsBuffer() && s.lastDelimColumn == 0 {
+ // tab indent for plain text (yaml-test-suite's spec-example-7-12-plain-lines).
+ s.indentNum++
+ ctx.addOriginBuf(c)
+ s.progressOnly(ctx, 1)
+ continue
+ }
+ if s.lastDelimColumn < s.column {
+ s.indentNum++
+ ctx.addOriginBuf(c)
+ s.progressOnly(ctx, 1)
+ continue
+ }
+ if err := s.scanTab(ctx, c); err != nil {
+ return err
+ }
+ }
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ s.progressColumn(ctx, 1)
+ }
+ s.addBufferedTokenIfExists(ctx)
+ return nil
+}
+
+// Init prepares the scanner s to tokenize the text src by setting the scanner at the beginning of src.
+func (s *Scanner) Init(text string) {
+ src := []rune(text)
+ s.source = src
+ s.sourcePos = 0
+ s.sourceSize = len(src)
+ s.line = 1
+ s.column = 1
+ s.offset = 1
+ s.isFirstCharAtLine = true
+ s.clearState()
+}
+
+func (s *Scanner) clearState() {
+ s.prevLineIndentNum = 0
+ s.lastDelimColumn = 0
+ s.indentLevel = 0
+ s.indentNum = 0
+}
+
+// Scan scans the next token and returns the token collection. The source end is indicated by io.EOF.
+func (s *Scanner) Scan() (token.Tokens, error) {
+ if s.sourcePos >= s.sourceSize {
+ return nil, io.EOF
+ }
+ ctx := newContext(s.source[s.sourcePos:])
+ defer ctx.release()
+
+ var tokens token.Tokens
+ err := s.scan(ctx)
+ tokens = append(tokens, ctx.tokens...)
+
+ if err != nil {
+ var invalidTokenErr *InvalidTokenError
+ if errors.As(err, &invalidTokenErr) {
+ tokens = append(tokens, invalidTokenErr.Token)
+ }
+ return tokens, err
+ }
+ return tokens, nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go b/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go
new file mode 100644
index 0000000..120448d
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go
@@ -0,0 +1,113 @@
+// Copied and trimmed down from https://github.com/golang/go/blob/e3769299cd3484e018e0e2a6e1b95c2b18ce4f41/src/strconv/quote.go
+// We want to use the standard library's private "quoteWith" function rather than write our own so that we get robust unicode support.
+// Every private function called by quoteWith was copied.
+// There are 2 modifications to simplify the code:
+// 1. The unicode.IsPrint function was substituted for the custom implementation of IsPrint
+// 2. All code paths reachable only when ASCIIonly or grphicOnly are set to true were removed.
+
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+package yaml
+
+import (
+ "unicode"
+ "unicode/utf8"
+)
+
+const (
+ lowerhex = "0123456789abcdef"
+)
+
+func quoteWith(s string, quote byte) string {
+ return string(appendQuotedWith(make([]byte, 0, 3*len(s)/2), s, quote))
+}
+
+func appendQuotedWith(buf []byte, s string, quote byte) []byte {
+ // Often called with big strings, so preallocate. If there's quoting,
+ // this is conservative but still helps a lot.
+ if cap(buf)-len(buf) < len(s) {
+ nBuf := make([]byte, len(buf), len(buf)+1+len(s)+1)
+ copy(nBuf, buf)
+ buf = nBuf
+ }
+ buf = append(buf, quote)
+ for width := 0; len(s) > 0; s = s[width:] {
+ r := rune(s[0])
+ width = 1
+ if r >= utf8.RuneSelf {
+ r, width = utf8.DecodeRuneInString(s)
+ }
+ if width == 1 && r == utf8.RuneError {
+ buf = append(buf, `\x`...)
+ buf = append(buf, lowerhex[s[0]>>4])
+ buf = append(buf, lowerhex[s[0]&0xF])
+ continue
+ }
+ buf = appendEscapedRune(buf, r, quote)
+ }
+ buf = append(buf, quote)
+ return buf
+}
+
+func appendEscapedRune(buf []byte, r rune, quote byte) []byte {
+ var runeTmp [utf8.UTFMax]byte
+ // goccy/go-yaml patch on top of the standard library's appendEscapedRune function.
+ //
+ // We use this to implement the YAML single-quoted string, where the only escape sequence is '', which represents a single quote.
+ // The below snippet from the standard library is for escaping e.g. \ with \\, which is not what we want for the single-quoted string.
+ //
+ // if r == rune(quote) || r == '\\' { // always backslashed
+ // buf = append(buf, '\\')
+ // buf = append(buf, byte(r))
+ // return buf
+ // }
+ if r == rune(quote) {
+ buf = append(buf, byte(r))
+ buf = append(buf, byte(r))
+ return buf
+ }
+ if unicode.IsPrint(r) {
+ n := utf8.EncodeRune(runeTmp[:], r)
+ buf = append(buf, runeTmp[:n]...)
+ return buf
+ }
+ switch r {
+ case '\a':
+ buf = append(buf, `\a`...)
+ case '\b':
+ buf = append(buf, `\b`...)
+ case '\f':
+ buf = append(buf, `\f`...)
+ case '\n':
+ buf = append(buf, `\n`...)
+ case '\r':
+ buf = append(buf, `\r`...)
+ case '\t':
+ buf = append(buf, `\t`...)
+ case '\v':
+ buf = append(buf, `\v`...)
+ default:
+ switch {
+ case r < ' ':
+ buf = append(buf, `\x`...)
+ buf = append(buf, lowerhex[byte(r)>>4])
+ buf = append(buf, lowerhex[byte(r)&0xF])
+ case r > utf8.MaxRune:
+ r = 0xFFFD
+ fallthrough
+ case r < 0x10000:
+ buf = append(buf, `\u`...)
+ for s := 12; s >= 0; s -= 4 {
+ buf = append(buf, lowerhex[r>>uint(s)&0xF])
+ }
+ default:
+ buf = append(buf, `\U`...)
+ for s := 28; s >= 0; s -= 4 {
+ buf = append(buf, lowerhex[r>>uint(s)&0xF])
+ }
+ }
+ }
+ return buf
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/struct.go b/sesh/vendor/github.com/goccy/go-yaml/struct.go
new file mode 100644
index 0000000..ece77f5
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/struct.go
@@ -0,0 +1,128 @@
+package yaml
+
+import (
+ "fmt"
+ "reflect"
+ "strings"
+)
+
+const (
+ // StructTagName tag keyword for Marshal/Unmarshal
+ StructTagName = "yaml"
+)
+
+// StructField information for each the field in structure
+type StructField struct {
+ FieldName string
+ RenderName string
+ AnchorName string
+ AliasName string
+ IsAutoAnchor bool
+ IsAutoAlias bool
+ IsOmitEmpty bool
+ IsOmitZero bool
+ IsFlow bool
+ IsInline bool
+}
+
+func getTag(field reflect.StructField) string {
+ // If struct tag `yaml` exist, use that. If no `yaml`
+ // exists, but `json` does, use that and try the best to
+ // adhere to its rules
+ tag := field.Tag.Get(StructTagName)
+ if tag == "" {
+ tag = field.Tag.Get(`json`)
+ }
+ return tag
+}
+
+func structField(field reflect.StructField) *StructField {
+ tag := getTag(field)
+ fieldName := strings.ToLower(field.Name)
+ options := strings.Split(tag, ",")
+ if len(options) > 0 {
+ if options[0] != "" {
+ fieldName = options[0]
+ }
+ }
+ sf := &StructField{
+ FieldName: field.Name,
+ RenderName: fieldName,
+ }
+ if len(options) > 1 {
+ for _, opt := range options[1:] {
+ switch {
+ case opt == "omitempty":
+ sf.IsOmitEmpty = true
+ case opt == "omitzero":
+ sf.IsOmitZero = true
+ case opt == "flow":
+ sf.IsFlow = true
+ case opt == "inline":
+ sf.IsInline = true
+ case strings.HasPrefix(opt, "anchor"):
+ anchor := strings.Split(opt, "=")
+ if len(anchor) > 1 {
+ sf.AnchorName = anchor[1]
+ } else {
+ sf.IsAutoAnchor = true
+ }
+ case strings.HasPrefix(opt, "alias"):
+ alias := strings.Split(opt, "=")
+ if len(alias) > 1 {
+ sf.AliasName = alias[1]
+ } else {
+ sf.IsAutoAlias = true
+ }
+ default:
+ }
+ }
+ }
+ return sf
+}
+
+func isIgnoredStructField(field reflect.StructField) bool {
+ if field.PkgPath != "" && !field.Anonymous {
+ // private field
+ return true
+ }
+ return getTag(field) == "-"
+}
+
+type StructFieldMap map[string]*StructField
+
+func (m StructFieldMap) isIncludedRenderName(name string) bool {
+ for _, v := range m {
+ if !v.IsInline && v.RenderName == name {
+ return true
+ }
+ }
+ return false
+}
+
+func (m StructFieldMap) hasMergeProperty() bool {
+ for _, v := range m {
+ if v.IsOmitEmpty && v.IsInline && v.IsAutoAlias {
+ return true
+ }
+ }
+ return false
+}
+
+func structFieldMap(structType reflect.Type) (StructFieldMap, error) {
+ fieldMap := StructFieldMap{}
+ renderNameMap := map[string]struct{}{}
+ for i := 0; i < structType.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ sf := structField(field)
+ if _, exists := renderNameMap[sf.RenderName]; exists {
+ return nil, fmt.Errorf("duplicated struct field name %s", sf.RenderName)
+ }
+ fieldMap[sf.FieldName] = sf
+ renderNameMap[sf.RenderName] = struct{}{}
+ }
+ return fieldMap, nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/token/token.go b/sesh/vendor/github.com/goccy/go-yaml/token/token.go
new file mode 100644
index 0000000..e887356
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/token/token.go
@@ -0,0 +1,1177 @@
+package token
+
+import (
+ "errors"
+ "fmt"
+ "strconv"
+ "strings"
+ "time"
+)
+
+// Character type for character
+type Character byte
+
+const (
+ // SequenceEntryCharacter character for sequence entry
+ SequenceEntryCharacter Character = '-'
+ // MappingKeyCharacter character for mapping key
+ MappingKeyCharacter Character = '?'
+ // MappingValueCharacter character for mapping value
+ MappingValueCharacter Character = ':'
+ // CollectEntryCharacter character for collect entry
+ CollectEntryCharacter Character = ','
+ // SequenceStartCharacter character for sequence start
+ SequenceStartCharacter Character = '['
+ // SequenceEndCharacter character for sequence end
+ SequenceEndCharacter Character = ']'
+ // MappingStartCharacter character for mapping start
+ MappingStartCharacter Character = '{'
+ // MappingEndCharacter character for mapping end
+ MappingEndCharacter Character = '}'
+ // CommentCharacter character for comment
+ CommentCharacter Character = '#'
+ // AnchorCharacter character for anchor
+ AnchorCharacter Character = '&'
+ // AliasCharacter character for alias
+ AliasCharacter Character = '*'
+ // TagCharacter character for tag
+ TagCharacter Character = '!'
+ // LiteralCharacter character for literal
+ LiteralCharacter Character = '|'
+ // FoldedCharacter character for folded
+ FoldedCharacter Character = '>'
+ // SingleQuoteCharacter character for single quote
+ SingleQuoteCharacter Character = '\''
+ // DoubleQuoteCharacter character for double quote
+ DoubleQuoteCharacter Character = '"'
+ // DirectiveCharacter character for directive
+ DirectiveCharacter Character = '%'
+ // SpaceCharacter character for space
+ SpaceCharacter Character = ' '
+ // LineBreakCharacter character for line break
+ LineBreakCharacter Character = '\n'
+)
+
+// Type type identifier for token
+type Type int
+
+const (
+ // UnknownType reserve for invalid type
+ UnknownType Type = iota
+ // DocumentHeaderType type for DocumentHeader token
+ DocumentHeaderType
+ // DocumentEndType type for DocumentEnd token
+ DocumentEndType
+ // SequenceEntryType type for SequenceEntry token
+ SequenceEntryType
+ // MappingKeyType type for MappingKey token
+ MappingKeyType
+ // MappingValueType type for MappingValue token
+ MappingValueType
+ // MergeKeyType type for MergeKey token
+ MergeKeyType
+ // CollectEntryType type for CollectEntry token
+ CollectEntryType
+ // SequenceStartType type for SequenceStart token
+ SequenceStartType
+ // SequenceEndType type for SequenceEnd token
+ SequenceEndType
+ // MappingStartType type for MappingStart token
+ MappingStartType
+ // MappingEndType type for MappingEnd token
+ MappingEndType
+ // CommentType type for Comment token
+ CommentType
+ // AnchorType type for Anchor token
+ AnchorType
+ // AliasType type for Alias token
+ AliasType
+ // TagType type for Tag token
+ TagType
+ // LiteralType type for Literal token
+ LiteralType
+ // FoldedType type for Folded token
+ FoldedType
+ // SingleQuoteType type for SingleQuote token
+ SingleQuoteType
+ // DoubleQuoteType type for DoubleQuote token
+ DoubleQuoteType
+ // DirectiveType type for Directive token
+ DirectiveType
+ // SpaceType type for Space token
+ SpaceType
+ // NullType type for Null token
+ NullType
+ // ImplicitNullType type for implicit Null token.
+ // This is used when explicit keywords such as null or ~ are not specified.
+ // It is distinguished during encoding and output as an empty string.
+ ImplicitNullType
+ // InfinityType type for Infinity token
+ InfinityType
+ // NanType type for Nan token
+ NanType
+ // IntegerType type for Integer token
+ IntegerType
+ // BinaryIntegerType type for BinaryInteger token
+ BinaryIntegerType
+ // OctetIntegerType type for OctetInteger token
+ OctetIntegerType
+ // HexIntegerType type for HexInteger token
+ HexIntegerType
+ // FloatType type for Float token
+ FloatType
+ // StringType type for String token
+ StringType
+ // BoolType type for Bool token
+ BoolType
+ // InvalidType type for invalid token
+ InvalidType
+)
+
+// String type identifier to text
+func (t Type) String() string {
+ switch t {
+ case UnknownType:
+ return "Unknown"
+ case DocumentHeaderType:
+ return "DocumentHeader"
+ case DocumentEndType:
+ return "DocumentEnd"
+ case SequenceEntryType:
+ return "SequenceEntry"
+ case MappingKeyType:
+ return "MappingKey"
+ case MappingValueType:
+ return "MappingValue"
+ case MergeKeyType:
+ return "MergeKey"
+ case CollectEntryType:
+ return "CollectEntry"
+ case SequenceStartType:
+ return "SequenceStart"
+ case SequenceEndType:
+ return "SequenceEnd"
+ case MappingStartType:
+ return "MappingStart"
+ case MappingEndType:
+ return "MappingEnd"
+ case CommentType:
+ return "Comment"
+ case AnchorType:
+ return "Anchor"
+ case AliasType:
+ return "Alias"
+ case TagType:
+ return "Tag"
+ case LiteralType:
+ return "Literal"
+ case FoldedType:
+ return "Folded"
+ case SingleQuoteType:
+ return "SingleQuote"
+ case DoubleQuoteType:
+ return "DoubleQuote"
+ case DirectiveType:
+ return "Directive"
+ case SpaceType:
+ return "Space"
+ case StringType:
+ return "String"
+ case BoolType:
+ return "Bool"
+ case IntegerType:
+ return "Integer"
+ case BinaryIntegerType:
+ return "BinaryInteger"
+ case OctetIntegerType:
+ return "OctetInteger"
+ case HexIntegerType:
+ return "HexInteger"
+ case FloatType:
+ return "Float"
+ case NullType:
+ return "Null"
+ case ImplicitNullType:
+ return "ImplicitNull"
+ case InfinityType:
+ return "Infinity"
+ case NanType:
+ return "Nan"
+ case InvalidType:
+ return "Invalid"
+ }
+ return ""
+}
+
+// CharacterType type for character category
+type CharacterType int
+
+const (
+ // CharacterTypeIndicator type of indicator character
+ CharacterTypeIndicator CharacterType = iota
+ // CharacterTypeWhiteSpace type of white space character
+ CharacterTypeWhiteSpace
+ // CharacterTypeMiscellaneous type of miscellaneous character
+ CharacterTypeMiscellaneous
+ // CharacterTypeEscaped type of escaped character
+ CharacterTypeEscaped
+ // CharacterTypeInvalid type for a invalid token.
+ CharacterTypeInvalid
+)
+
+// String character type identifier to text
+func (c CharacterType) String() string {
+ switch c {
+ case CharacterTypeIndicator:
+ return "Indicator"
+ case CharacterTypeWhiteSpace:
+ return "WhiteSpace"
+ case CharacterTypeMiscellaneous:
+ return "Miscellaneous"
+ case CharacterTypeEscaped:
+ return "Escaped"
+ }
+ return ""
+}
+
+// Indicator type for indicator
+type Indicator int
+
+const (
+ // NotIndicator not indicator
+ NotIndicator Indicator = iota
+ // BlockStructureIndicator indicator for block structure ( '-', '?', ':' )
+ BlockStructureIndicator
+ // FlowCollectionIndicator indicator for flow collection ( '[', ']', '{', '}', ',' )
+ FlowCollectionIndicator
+ // CommentIndicator indicator for comment ( '#' )
+ CommentIndicator
+ // NodePropertyIndicator indicator for node property ( '!', '&', '*' )
+ NodePropertyIndicator
+ // BlockScalarIndicator indicator for block scalar ( '|', '>' )
+ BlockScalarIndicator
+ // QuotedScalarIndicator indicator for quoted scalar ( ''', '"' )
+ QuotedScalarIndicator
+ // DirectiveIndicator indicator for directive ( '%' )
+ DirectiveIndicator
+ // InvalidUseOfReservedIndicator indicator for invalid use of reserved keyword ( '@', '`' )
+ InvalidUseOfReservedIndicator
+)
+
+// String indicator to text
+func (i Indicator) String() string {
+ switch i {
+ case NotIndicator:
+ return "NotIndicator"
+ case BlockStructureIndicator:
+ return "BlockStructure"
+ case FlowCollectionIndicator:
+ return "FlowCollection"
+ case CommentIndicator:
+ return "Comment"
+ case NodePropertyIndicator:
+ return "NodeProperty"
+ case BlockScalarIndicator:
+ return "BlockScalar"
+ case QuotedScalarIndicator:
+ return "QuotedScalar"
+ case DirectiveIndicator:
+ return "Directive"
+ case InvalidUseOfReservedIndicator:
+ return "InvalidUseOfReserved"
+ }
+ return ""
+}
+
+var (
+ reservedNullKeywords = []string{
+ "null",
+ "Null",
+ "NULL",
+ "~",
+ }
+ reservedBoolKeywords = []string{
+ "true",
+ "True",
+ "TRUE",
+ "false",
+ "False",
+ "FALSE",
+ }
+ // For compatibility with other YAML 1.1 parsers
+ // Note that we use these solely for encoding the bool value with quotes.
+ // go-yaml should not treat these as reserved keywords at parsing time.
+ // as go-yaml is supposed to be compliant only with YAML 1.2.
+ reservedLegacyBoolKeywords = []string{
+ "y",
+ "Y",
+ "yes",
+ "Yes",
+ "YES",
+ "n",
+ "N",
+ "no",
+ "No",
+ "NO",
+ "on",
+ "On",
+ "ON",
+ "off",
+ "Off",
+ "OFF",
+ }
+ reservedInfKeywords = []string{
+ ".inf",
+ ".Inf",
+ ".INF",
+ "-.inf",
+ "-.Inf",
+ "-.INF",
+ }
+ reservedNanKeywords = []string{
+ ".nan",
+ ".NaN",
+ ".NAN",
+ }
+ reservedKeywordMap = map[string]func(string, string, *Position) *Token{}
+ // reservedEncKeywordMap contains is the keyword map used at encoding time.
+ // This is supposed to be a superset of reservedKeywordMap,
+ // and used to quote legacy keywords present in YAML 1.1 or lesser for compatibility reasons,
+ // even though this library is supposed to be YAML 1.2-compliant.
+ reservedEncKeywordMap = map[string]func(string, string, *Position) *Token{}
+)
+
+func reservedKeywordToken(typ Type, value, org string, pos *Position) *Token {
+ return &Token{
+ Type: typ,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+func init() {
+ for _, keyword := range reservedNullKeywords {
+ f := func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(NullType, value, org, pos)
+ }
+
+ reservedKeywordMap[keyword] = f
+ reservedEncKeywordMap[keyword] = f
+ }
+ for _, keyword := range reservedBoolKeywords {
+ f := func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(BoolType, value, org, pos)
+ }
+ reservedKeywordMap[keyword] = f
+ reservedEncKeywordMap[keyword] = f
+ }
+ for _, keyword := range reservedLegacyBoolKeywords {
+ reservedEncKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(BoolType, value, org, pos)
+ }
+ }
+ for _, keyword := range reservedInfKeywords {
+ reservedKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(InfinityType, value, org, pos)
+ }
+ }
+ for _, keyword := range reservedNanKeywords {
+ reservedKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(NanType, value, org, pos)
+ }
+ }
+}
+
+// ReservedTagKeyword type of reserved tag keyword
+type ReservedTagKeyword string
+
+const (
+ // IntegerTag `!!int` tag
+ IntegerTag ReservedTagKeyword = "!!int"
+ // FloatTag `!!float` tag
+ FloatTag ReservedTagKeyword = "!!float"
+ // NullTag `!!null` tag
+ NullTag ReservedTagKeyword = "!!null"
+ // SequenceTag `!!seq` tag
+ SequenceTag ReservedTagKeyword = "!!seq"
+ // MappingTag `!!map` tag
+ MappingTag ReservedTagKeyword = "!!map"
+ // StringTag `!!str` tag
+ StringTag ReservedTagKeyword = "!!str"
+ // BinaryTag `!!binary` tag
+ BinaryTag ReservedTagKeyword = "!!binary"
+ // OrderedMapTag `!!omap` tag
+ OrderedMapTag ReservedTagKeyword = "!!omap"
+ // SetTag `!!set` tag
+ SetTag ReservedTagKeyword = "!!set"
+ // TimestampTag `!!timestamp` tag
+ TimestampTag ReservedTagKeyword = "!!timestamp"
+ // BooleanTag `!!bool` tag
+ BooleanTag ReservedTagKeyword = "!!bool"
+ // MergeTag `!!merge` tag
+ MergeTag ReservedTagKeyword = "!!merge"
+)
+
+var (
+ // ReservedTagKeywordMap map for reserved tag keywords
+ ReservedTagKeywordMap = map[ReservedTagKeyword]func(string, string, *Position) *Token{
+ IntegerTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ FloatTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ NullTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ SequenceTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ MappingTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ StringTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ BinaryTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ OrderedMapTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ SetTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ TimestampTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ BooleanTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ MergeTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ }
+)
+
+type NumberType string
+
+const (
+ NumberTypeDecimal NumberType = "decimal"
+ NumberTypeBinary NumberType = "binary"
+ NumberTypeOctet NumberType = "octet"
+ NumberTypeHex NumberType = "hex"
+ NumberTypeFloat NumberType = "float"
+)
+
+type NumberValue struct {
+ Type NumberType
+ Value any
+ Text string
+}
+
+func ToNumber(value string) *NumberValue {
+ num, err := toNumber(value)
+ if err != nil {
+ return nil
+ }
+ return num
+}
+
+func isNumber(value string) bool {
+ num, err := toNumber(value)
+ if err != nil {
+ var numErr *strconv.NumError
+ if errors.As(err, &numErr) && errors.Is(numErr.Err, strconv.ErrRange) {
+ return true
+ }
+ return false
+ }
+ return num != nil
+}
+
+func toNumber(value string) (*NumberValue, error) {
+ if len(value) == 0 {
+ return nil, nil
+ }
+ if strings.HasPrefix(value, "_") {
+ return nil, nil
+ }
+ dotCount := strings.Count(value, ".")
+ if dotCount > 1 {
+ return nil, nil
+ }
+
+ isNegative := strings.HasPrefix(value, "-")
+ normalized := strings.ReplaceAll(strings.TrimPrefix(strings.TrimPrefix(value, "+"), "-"), "_", "")
+
+ var (
+ typ NumberType
+ base int
+ )
+ switch {
+ case strings.HasPrefix(normalized, "0x"):
+ normalized = strings.TrimPrefix(normalized, "0x")
+ base = 16
+ typ = NumberTypeHex
+ case strings.HasPrefix(normalized, "0o"):
+ normalized = strings.TrimPrefix(normalized, "0o")
+ base = 8
+ typ = NumberTypeOctet
+ case strings.HasPrefix(normalized, "0b"):
+ normalized = strings.TrimPrefix(normalized, "0b")
+ base = 2
+ typ = NumberTypeBinary
+ case strings.HasPrefix(normalized, "0") && len(normalized) > 1 && dotCount == 0:
+ base = 8
+ typ = NumberTypeOctet
+ case dotCount == 1:
+ typ = NumberTypeFloat
+ default:
+ typ = NumberTypeDecimal
+ base = 10
+ }
+
+ text := normalized
+ if isNegative {
+ text = "-" + text
+ }
+
+ var v any
+ if typ == NumberTypeFloat {
+ f, err := strconv.ParseFloat(text, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = f
+ } else if isNegative {
+ i, err := strconv.ParseInt(text, base, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = i
+ } else {
+ u, err := strconv.ParseUint(text, base, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = u
+ }
+
+ return &NumberValue{
+ Type: typ,
+ Value: v,
+ Text: text,
+ }, nil
+}
+
+// This is a subset of the formats permitted by the regular expression
+// defined at http://yaml.org/type/timestamp.html. Note that time.Parse
+// cannot handle: "2001-12-14 21:59:43.10 -5" from the examples.
+var timestampFormats = []string{
+ time.RFC3339Nano,
+ "2006-01-02t15:04:05.999999999Z07:00", // RFC3339Nano with lower-case "t".
+ time.DateTime,
+ time.DateOnly,
+
+ // Not in examples, but to preserve backward compatibility by quoting time values.
+ "15:4",
+}
+
+func isTimestamp(value string) bool {
+ for _, format := range timestampFormats {
+ if _, err := time.Parse(format, value); err == nil {
+ return true
+ }
+ }
+ return false
+}
+
+// IsNeedQuoted checks whether the value needs quote for passed string or not
+func IsNeedQuoted(value string) bool {
+ if value == "" {
+ return true
+ }
+ if _, exists := reservedEncKeywordMap[value]; exists {
+ return true
+ }
+ if isNumber(value) {
+ return true
+ }
+ if value == "-" {
+ return true
+ }
+ first := value[0]
+ switch first {
+ case '*', '&', '[', '{', '}', ']', ',', '!', '|', '>', '%', '\'', '"', '@', ' ', '`':
+ return true
+ }
+ last := value[len(value)-1]
+ switch last {
+ case ':', ' ':
+ return true
+ }
+ if isTimestamp(value) {
+ return true
+ }
+ for i, c := range value {
+ switch c {
+ case '#', '\\':
+ return true
+ case ':', '-':
+ if i+1 < len(value) && value[i+1] == ' ' {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+// LiteralBlockHeader detect literal block scalar header
+func LiteralBlockHeader(value string) string {
+ lbc := DetectLineBreakCharacter(value)
+
+ switch {
+ case !strings.Contains(value, lbc):
+ return ""
+ case strings.HasSuffix(value, fmt.Sprintf("%s%s", lbc, lbc)):
+ return "|+"
+ case strings.HasSuffix(value, lbc):
+ return "|"
+ default:
+ return "|-"
+ }
+}
+
+// New create reserved keyword token or number token and other string token.
+func New(value string, org string, pos *Position) *Token {
+ fn := reservedKeywordMap[value]
+ if fn != nil {
+ return fn(value, org, pos)
+ }
+ if num := ToNumber(value); num != nil {
+ tk := &Token{
+ Type: IntegerType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ switch num.Type {
+ case NumberTypeFloat:
+ tk.Type = FloatType
+ case NumberTypeBinary:
+ tk.Type = BinaryIntegerType
+ case NumberTypeOctet:
+ tk.Type = OctetIntegerType
+ case NumberTypeHex:
+ tk.Type = HexIntegerType
+ }
+ return tk
+ }
+ return String(value, org, pos)
+}
+
+// Position type for position in YAML document
+type Position struct {
+ Line int
+ Column int
+ Offset int
+ IndentNum int
+ IndentLevel int
+}
+
+// String position to text
+func (p *Position) String() string {
+ return fmt.Sprintf("[level:%d,line:%d,column:%d,offset:%d]", p.IndentLevel, p.Line, p.Column, p.Offset)
+}
+
+// Token type for token
+type Token struct {
+ // Type is a token type.
+ Type Type
+ // CharacterType is a character type.
+ CharacterType CharacterType
+ // Indicator is a indicator type.
+ Indicator Indicator
+ // Value is a string extracted with only meaningful characters, with spaces and such removed.
+ Value string
+ // Origin is a string that stores the original text as-is.
+ Origin string
+ // Error keeps error message for InvalidToken.
+ Error string
+ // Position is a token position.
+ Position *Position
+ // Next is a next token reference.
+ Next *Token
+ // Prev is a previous token reference.
+ Prev *Token
+}
+
+// PreviousType previous token type
+func (t *Token) PreviousType() Type {
+ if t.Prev != nil {
+ return t.Prev.Type
+ }
+ return UnknownType
+}
+
+// NextType next token type
+func (t *Token) NextType() Type {
+ if t.Next != nil {
+ return t.Next.Type
+ }
+ return UnknownType
+}
+
+// AddColumn append column number to current position of column
+func (t *Token) AddColumn(col int) {
+ if t == nil {
+ return
+ }
+ t.Position.Column += col
+}
+
+// Clone copy token ( preserve Prev/Next reference )
+func (t *Token) Clone() *Token {
+ if t == nil {
+ return nil
+ }
+ copied := *t
+ if t.Position != nil {
+ pos := *(t.Position)
+ copied.Position = &pos
+ }
+ return &copied
+}
+
+// Dump outputs token information to stdout for debugging.
+func (t *Token) Dump() {
+ fmt.Printf(
+ "[TYPE]:%q [CHARTYPE]:%q [INDICATOR]:%q [VALUE]:%q [ORG]:%q [POS(line:column:level:offset)]: %d:%d:%d:%d\n",
+ t.Type, t.CharacterType, t.Indicator, t.Value, t.Origin, t.Position.Line, t.Position.Column, t.Position.IndentLevel, t.Position.Offset,
+ )
+}
+
+// Tokens type of token collection
+type Tokens []*Token
+
+func (t Tokens) InvalidToken() *Token {
+ for _, tt := range t {
+ if tt.Type == InvalidType {
+ return tt
+ }
+ }
+ return nil
+}
+
+func (t *Tokens) add(tk *Token) {
+ tokens := *t
+ if len(tokens) == 0 {
+ tokens = append(tokens, tk)
+ } else {
+ last := tokens[len(tokens)-1]
+ last.Next = tk
+ tk.Prev = last
+ tokens = append(tokens, tk)
+ }
+ *t = tokens
+}
+
+// Add append new some tokens
+func (t *Tokens) Add(tks ...*Token) {
+ for _, tk := range tks {
+ t.add(tk)
+ }
+}
+
+// Dump dump all token structures for debugging
+func (t Tokens) Dump() {
+ for _, tk := range t {
+ fmt.Print("- ")
+ tk.Dump()
+ }
+}
+
+// String create token for String
+func String(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: StringType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceEntry create token for SequenceEntry
+func SequenceEntry(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceEntryType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(SequenceEntryCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingKey create token for MappingKey
+func MappingKey(pos *Position) *Token {
+ return &Token{
+ Type: MappingKeyType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(MappingKeyCharacter),
+ Origin: string(MappingKeyCharacter),
+ Position: pos,
+ }
+}
+
+// MappingValue create token for MappingValue
+func MappingValue(pos *Position) *Token {
+ return &Token{
+ Type: MappingValueType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(MappingValueCharacter),
+ Origin: string(MappingValueCharacter),
+ Position: pos,
+ }
+}
+
+// CollectEntry create token for CollectEntry
+func CollectEntry(org string, pos *Position) *Token {
+ return &Token{
+ Type: CollectEntryType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(CollectEntryCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceStart create token for SequenceStart
+func SequenceStart(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceStartType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(SequenceStartCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceEnd create token for SequenceEnd
+func SequenceEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceEndType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(SequenceEndCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingStart create token for MappingStart
+func MappingStart(org string, pos *Position) *Token {
+ return &Token{
+ Type: MappingStartType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(MappingStartCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingEnd create token for MappingEnd
+func MappingEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: MappingEndType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(MappingEndCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Comment create token for Comment
+func Comment(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: CommentType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: CommentIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Anchor create token for Anchor
+func Anchor(org string, pos *Position) *Token {
+ return &Token{
+ Type: AnchorType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: string(AnchorCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Alias create token for Alias
+func Alias(org string, pos *Position) *Token {
+ return &Token{
+ Type: AliasType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: string(AliasCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Tag create token for Tag
+func Tag(value string, org string, pos *Position) *Token {
+ fn := ReservedTagKeywordMap[ReservedTagKeyword(value)]
+ if fn != nil {
+ return fn(value, org, pos)
+ }
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Literal create token for Literal
+func Literal(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: LiteralType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Folded create token for Folded
+func Folded(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: FoldedType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SingleQuote create token for SingleQuote
+func SingleQuote(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: SingleQuoteType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: QuotedScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DoubleQuote create token for DoubleQuote
+func DoubleQuote(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: DoubleQuoteType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: QuotedScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Directive create token for Directive
+func Directive(org string, pos *Position) *Token {
+ return &Token{
+ Type: DirectiveType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: DirectiveIndicator,
+ Value: string(DirectiveCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Space create token for Space
+func Space(pos *Position) *Token {
+ return &Token{
+ Type: SpaceType,
+ CharacterType: CharacterTypeWhiteSpace,
+ Indicator: NotIndicator,
+ Value: string(SpaceCharacter),
+ Origin: string(SpaceCharacter),
+ Position: pos,
+ }
+}
+
+// MergeKey create token for MergeKey
+func MergeKey(org string, pos *Position) *Token {
+ return &Token{
+ Type: MergeKeyType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "<<",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DocumentHeader create token for DocumentHeader
+func DocumentHeader(org string, pos *Position) *Token {
+ return &Token{
+ Type: DocumentHeaderType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "---",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DocumentEnd create token for DocumentEnd
+func DocumentEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: DocumentEndType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "...",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+func Invalid(err string, org string, pos *Position) *Token {
+ return &Token{
+ Type: InvalidType,
+ CharacterType: CharacterTypeInvalid,
+ Indicator: NotIndicator,
+ Value: org,
+ Origin: org,
+ Error: err,
+ Position: pos,
+ }
+}
+
+// DetectLineBreakCharacter detect line break character in only one inside scalar content scope.
+func DetectLineBreakCharacter(src string) string {
+ nc := strings.Count(src, "\n")
+ rc := strings.Count(src, "\r")
+ rnc := strings.Count(src, "\r\n")
+ switch {
+ case nc == rnc && rc == rnc:
+ return "\r\n"
+ case rc > nc:
+ return "\r"
+ default:
+ return "\n"
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/validate.go b/sesh/vendor/github.com/goccy/go-yaml/validate.go
new file mode 100644
index 0000000..20a2d6d
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/validate.go
@@ -0,0 +1,13 @@
+package yaml
+
+// StructValidator need to implement Struct method only
+// ( see https://pkg.go.dev/github.com/go-playground/validator/v10#Validate.Struct )
+type StructValidator interface {
+ Struct(interface{}) error
+}
+
+// FieldError need to implement StructField method only
+// ( see https://pkg.go.dev/github.com/go-playground/validator/v10#FieldError )
+type FieldError interface {
+ StructField() string
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/yaml.go b/sesh/vendor/github.com/goccy/go-yaml/yaml.go
new file mode 100644
index 0000000..e1b5fbd
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/yaml.go
@@ -0,0 +1,357 @@
+package yaml
+
+import (
+ "bytes"
+ "context"
+ "io"
+ "reflect"
+ "sync"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+)
+
+// BytesMarshaler interface may be implemented by types to customize their
+// behavior when being marshaled into a YAML document. The returned value
+// is marshaled in place of the original value implementing Marshaler.
+//
+// If an error is returned by MarshalYAML, the marshaling procedure stops
+// and returns with the provided error.
+type BytesMarshaler interface {
+ MarshalYAML() ([]byte, error)
+}
+
+// BytesMarshalerContext interface use BytesMarshaler with context.Context.
+type BytesMarshalerContext interface {
+ MarshalYAML(context.Context) ([]byte, error)
+}
+
+// InterfaceMarshaler interface has MarshalYAML compatible with github.com/go-yaml/yaml package.
+type InterfaceMarshaler interface {
+ MarshalYAML() (interface{}, error)
+}
+
+// InterfaceMarshalerContext interface use InterfaceMarshaler with context.Context.
+type InterfaceMarshalerContext interface {
+ MarshalYAML(context.Context) (interface{}, error)
+}
+
+// BytesUnmarshaler interface may be implemented by types to customize their
+// behavior when being unmarshaled from a YAML document.
+type BytesUnmarshaler interface {
+ UnmarshalYAML([]byte) error
+}
+
+// BytesUnmarshalerContext interface use BytesUnmarshaler with context.Context.
+type BytesUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, []byte) error
+}
+
+// InterfaceUnmarshaler interface has UnmarshalYAML compatible with github.com/go-yaml/yaml package.
+type InterfaceUnmarshaler interface {
+ UnmarshalYAML(func(interface{}) error) error
+}
+
+// InterfaceUnmarshalerContext interface use InterfaceUnmarshaler with context.Context.
+type InterfaceUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, func(interface{}) error) error
+}
+
+// NodeUnmarshaler interface is similar to BytesUnmarshaler but provide related AST node instead of raw YAML source.
+type NodeUnmarshaler interface {
+ UnmarshalYAML(ast.Node) error
+}
+
+// NodeUnmarshalerContext interface is similar to BytesUnmarshaler but provide related AST node instead of raw YAML source.
+type NodeUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, ast.Node) error
+}
+
+// MapItem is an item in a MapSlice.
+type MapItem struct {
+ Key, Value interface{}
+}
+
+// MapSlice encodes and decodes as a YAML map.
+// The order of keys is preserved when encoding and decoding.
+type MapSlice []MapItem
+
+// ToMap convert to map[interface{}]interface{}.
+func (s MapSlice) ToMap() map[interface{}]interface{} {
+ v := map[interface{}]interface{}{}
+ for _, item := range s {
+ v[item.Key] = item.Value
+ }
+ return v
+}
+
+// Marshal serializes the value provided into a YAML document. The structure
+// of the generated document will reflect the structure of the value itself.
+// Maps and pointers (to struct, string, int, etc) are accepted as the in value.
+//
+// Struct fields are only marshaled if they are exported (have an upper case
+// first letter), and are marshaled using the field name lowercased as the
+// default key. Custom keys may be defined via the "yaml" name in the field
+// tag: the content preceding the first comma is used as the key, and the
+// following comma-separated options are used to tweak the marshaling process.
+// Conflicting names result in a runtime error.
+//
+// The field tag format accepted is:
+//
+// `(...) yaml:"[][,[,]]" (...)`
+//
+// The following flags are currently supported:
+//
+// omitempty Only include the field if it's not set to the zero
+// value for the type or to empty slices or maps.
+// Zero valued structs will be omitted if all their public
+// fields are zero, unless they implement an IsZero
+// method (see the IsZeroer interface type), in which
+// case the field will be included if that method returns true.
+// Note that this definition is slightly different from the Go's
+// encoding/json 'omitempty' definition. It combines some elements
+// of 'omitempty' and 'omitzero'. See https://github.com/goccy/go-yaml/issues/695.
+//
+// omitzero The omitzero tag behaves in the same way as the interpretation of the omitzero tag in the encoding/json library.
+// 1) If the field type has an "IsZero() bool" method, that will be used to determine whether the value is zero.
+// 2) Otherwise, the value is zero if it is the zero value for its type.
+//
+// flow Marshal using a flow style (useful for structs,
+// sequences and maps).
+//
+// inline Inline the field, which must be a struct or a map,
+// causing all of its fields or keys to be processed as if
+// they were part of the outer struct. For maps, keys must
+// not conflict with the yaml keys of other struct fields.
+//
+// anchor Marshal with anchor. If want to define anchor name explicitly, use anchor=name style.
+// Otherwise, if used 'anchor' name only, used the field name lowercased as the anchor name
+//
+// alias Marshal with alias. If want to define alias name explicitly, use alias=name style.
+// Otherwise, If omitted alias name and the field type is pointer type,
+// assigned anchor name automatically from same pointer address.
+//
+// In addition, if the key is "-", the field is ignored.
+//
+// For example:
+//
+// type T struct {
+// F int `yaml:"a,omitempty"`
+// B int
+// }
+// yaml.Marshal(&T{B: 2}) // Returns "b: 2\n"
+// yaml.Marshal(&T{F: 1}) // Returns "a: 1\nb: 0\n"
+func Marshal(v interface{}) ([]byte, error) {
+ return MarshalWithOptions(v)
+}
+
+// MarshalWithOptions serializes the value provided into a YAML document with EncodeOptions.
+func MarshalWithOptions(v interface{}, opts ...EncodeOption) ([]byte, error) {
+ return MarshalContext(context.Background(), v, opts...)
+}
+
+// MarshalContext serializes the value provided into a YAML document with context.Context and EncodeOptions.
+func MarshalContext(ctx context.Context, v interface{}, opts ...EncodeOption) ([]byte, error) {
+ var buf bytes.Buffer
+ if err := NewEncoder(&buf, opts...).EncodeContext(ctx, v); err != nil {
+ return nil, err
+ }
+ return buf.Bytes(), nil
+}
+
+// ValueToNode convert from value to ast.Node.
+func ValueToNode(v interface{}, opts ...EncodeOption) (ast.Node, error) {
+ var buf bytes.Buffer
+ node, err := NewEncoder(&buf, opts...).EncodeToNode(v)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+// Unmarshal decodes the first document found within the in byte slice
+// and assigns decoded values into the out value.
+//
+// Struct fields are only unmarshalled if they are exported (have an
+// upper case first letter), and are unmarshalled using the field name
+// lowercased as the default key. Custom keys may be defined via the
+// "yaml" name in the field tag: the content preceding the first comma
+// is used as the key, and the following comma-separated options are
+// used to tweak the marshaling process (see Marshal).
+// Conflicting names result in a runtime error.
+//
+// For example:
+//
+// type T struct {
+// F int `yaml:"a,omitempty"`
+// B int
+// }
+// var t T
+// yaml.Unmarshal([]byte("a: 1\nb: 2"), &t)
+//
+// See the documentation of Marshal for the format of tags and a list of
+// supported tag options.
+func Unmarshal(data []byte, v interface{}) error {
+ return UnmarshalWithOptions(data, v)
+}
+
+// UnmarshalWithOptions decodes with DecodeOptions the first document found within the in byte slice
+// and assigns decoded values into the out value.
+func UnmarshalWithOptions(data []byte, v interface{}, opts ...DecodeOption) error {
+ return UnmarshalContext(context.Background(), data, v, opts...)
+}
+
+// UnmarshalContext decodes with context.Context and DecodeOptions.
+func UnmarshalContext(ctx context.Context, data []byte, v interface{}, opts ...DecodeOption) error {
+ dec := NewDecoder(bytes.NewBuffer(data), opts...)
+ if err := dec.DecodeContext(ctx, v); err != nil {
+ if err == io.EOF {
+ return nil
+ }
+ return err
+ }
+ return nil
+}
+
+// NodeToValue converts node to the value pointed to by v.
+func NodeToValue(node ast.Node, v interface{}, opts ...DecodeOption) error {
+ var buf bytes.Buffer
+ if err := NewDecoder(&buf, opts...).DecodeFromNode(node, v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// FormatError is a utility function that takes advantage of the metadata
+// stored in the errors returned by this package's parser.
+//
+// If the second argument `colored` is true, the error message is colorized.
+// If the third argument `inclSource` is true, the error message will
+// contain snippets of the YAML source that was used.
+func FormatError(e error, colored, inclSource bool) string {
+ var yamlErr Error
+ if errors.As(e, &yamlErr) {
+ return yamlErr.FormatError(colored, inclSource)
+ }
+
+ return e.Error()
+}
+
+// YAMLToJSON convert YAML bytes to JSON.
+func YAMLToJSON(bytes []byte) ([]byte, error) {
+ var v interface{}
+ if err := UnmarshalWithOptions(bytes, &v, UseOrderedMap()); err != nil {
+ return nil, err
+ }
+ out, err := MarshalWithOptions(v, JSON())
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+// JSONToYAML convert JSON bytes to YAML.
+func JSONToYAML(bytes []byte) ([]byte, error) {
+ var v interface{}
+ if err := UnmarshalWithOptions(bytes, &v, UseOrderedMap()); err != nil {
+ return nil, err
+ }
+ out, err := Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+var (
+ globalCustomMarshalerMu sync.Mutex
+ globalCustomUnmarshalerMu sync.Mutex
+ globalCustomMarshalerMap = map[reflect.Type]func(context.Context, interface{}) ([]byte, error){}
+ globalCustomUnmarshalerMap = map[reflect.Type]func(context.Context, interface{}, []byte) error{}
+)
+
+// RegisterCustomMarshaler overrides any encoding process for the type specified in generics.
+// If you want to switch the behavior for each encoder, use `CustomMarshaler` defined as EncodeOption.
+//
+// NOTE: If type T implements MarshalYAML for pointer receiver, the type specified in RegisterCustomMarshaler must be *T.
+// If RegisterCustomMarshaler and CustomMarshaler of EncodeOption are specified for the same type,
+// the CustomMarshaler specified in EncodeOption takes precedence.
+func RegisterCustomMarshaler[T any](marshaler func(T) ([]byte, error)) {
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+
+ var typ T
+ globalCustomMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(v.(T))
+ }
+}
+
+// RegisterCustomMarshalerContext overrides any encoding process for the type specified in generics.
+// Similar to RegisterCustomMarshalerContext, but allows passing a context to the unmarshaler function.
+func RegisterCustomMarshalerContext[T any](marshaler func(context.Context, T) ([]byte, error)) {
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+
+ var typ T
+ globalCustomMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(ctx, v.(T))
+ }
+}
+
+// RegisterCustomUnmarshaler overrides any decoding process for the type specified in generics.
+// If you want to switch the behavior for each decoder, use `CustomUnmarshaler` defined as DecodeOption.
+//
+// NOTE: If RegisterCustomUnmarshaler and CustomUnmarshaler of DecodeOption are specified for the same type,
+// the CustomUnmarshaler specified in DecodeOption takes precedence.
+func RegisterCustomUnmarshaler[T any](unmarshaler func(*T, []byte) error) {
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+
+ var typ *T
+ globalCustomUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(v.(*T), b)
+ }
+}
+
+// RegisterCustomUnmarshalerContext overrides any decoding process for the type specified in generics.
+// Similar to RegisterCustomUnmarshalerContext, but allows passing a context to the unmarshaler function.
+func RegisterCustomUnmarshalerContext[T any](unmarshaler func(context.Context, *T, []byte) error) {
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+
+ var typ *T
+ globalCustomUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(ctx, v.(*T), b)
+ }
+}
+
+// RawMessage is a raw encoded YAML value. It implements [BytesMarshaler] and
+// [BytesUnmarshaler] and can be used to delay YAML decoding or precompute a YAML
+// encoding.
+// It also implements [json.Marshaler] and [json.Unmarshaler].
+//
+// This is similar to [json.RawMessage] in the stdlib.
+type RawMessage []byte
+
+func (m RawMessage) MarshalYAML() ([]byte, error) {
+ if m == nil {
+ return []byte("null"), nil
+ }
+ return m, nil
+}
+
+func (m *RawMessage) UnmarshalYAML(dt []byte) error {
+ if m == nil {
+ return errors.New("yaml.RawMessage: UnmarshalYAML on nil pointer")
+ }
+ *m = append((*m)[0:0], dt...)
+ return nil
+}
+
+func (m *RawMessage) UnmarshalJSON(b []byte) error {
+ return m.UnmarshalYAML(b)
+}
+
+func (m RawMessage) MarshalJSON() ([]byte, error) {
+ return YAMLToJSON(m)
+}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/LICENSE b/sesh/vendor/gopkg.in/yaml.v3/LICENSE
deleted file mode 100644
index 2683e4b..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/LICENSE
+++ /dev/null
@@ -1,50 +0,0 @@
-
-This project is covered by two different licenses: MIT and Apache.
-
-#### MIT License ####
-
-The following files were ported to Go from C files of libyaml, and thus
-are still covered by their original MIT license, with the additional
-copyright staring in 2011 when the project was ported over:
-
- apic.go emitterc.go parserc.go readerc.go scannerc.go
- writerc.go yamlh.go yamlprivateh.go
-
-Copyright (c) 2006-2010 Kirill Simonov
-Copyright (c) 2006-2011 Kirill Simonov
-
-Permission is hereby granted, free of charge, to any person obtaining a copy of
-this software and associated documentation files (the "Software"), to deal in
-the Software without restriction, including without limitation the rights to
-use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-of the Software, and to permit persons to whom the Software is furnished to do
-so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all
-copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
-
-### Apache License ###
-
-All the remaining project files are covered by the Apache license:
-
-Copyright (c) 2011-2019 Canonical Ltd
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
diff --git a/sesh/vendor/gopkg.in/yaml.v3/NOTICE b/sesh/vendor/gopkg.in/yaml.v3/NOTICE
deleted file mode 100644
index 866d74a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/NOTICE
+++ /dev/null
@@ -1,13 +0,0 @@
-Copyright 2011-2016 Canonical Ltd.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
diff --git a/sesh/vendor/gopkg.in/yaml.v3/README.md b/sesh/vendor/gopkg.in/yaml.v3/README.md
deleted file mode 100644
index 08eb1ba..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/README.md
+++ /dev/null
@@ -1,150 +0,0 @@
-# YAML support for the Go language
-
-Introduction
-------------
-
-The yaml package enables Go programs to comfortably encode and decode YAML
-values. It was developed within [Canonical](https://www.canonical.com) as
-part of the [juju](https://juju.ubuntu.com) project, and is based on a
-pure Go port of the well-known [libyaml](http://pyyaml.org/wiki/LibYAML)
-C library to parse and generate YAML data quickly and reliably.
-
-Compatibility
--------------
-
-The yaml package supports most of YAML 1.2, but preserves some behavior
-from 1.1 for backwards compatibility.
-
-Specifically, as of v3 of the yaml package:
-
- - YAML 1.1 bools (_yes/no, on/off_) are supported as long as they are being
- decoded into a typed bool value. Otherwise they behave as a string. Booleans
- in YAML 1.2 are _true/false_ only.
- - Octals encode and decode as _0777_ per YAML 1.1, rather than _0o777_
- as specified in YAML 1.2, because most parsers still use the old format.
- Octals in the _0o777_ format are supported though, so new files work.
- - Does not support base-60 floats. These are gone from YAML 1.2, and were
- actually never supported by this package as it's clearly a poor choice.
-
-and offers backwards
-compatibility with YAML 1.1 in some cases.
-1.2, including support for
-anchors, tags, map merging, etc. Multi-document unmarshalling is not yet
-implemented, and base-60 floats from YAML 1.1 are purposefully not
-supported since they're a poor design and are gone in YAML 1.2.
-
-Installation and usage
-----------------------
-
-The import path for the package is *gopkg.in/yaml.v3*.
-
-To install it, run:
-
- go get gopkg.in/yaml.v3
-
-API documentation
------------------
-
-If opened in a browser, the import path itself leads to the API documentation:
-
- - [https://gopkg.in/yaml.v3](https://gopkg.in/yaml.v3)
-
-API stability
--------------
-
-The package API for yaml v3 will remain stable as described in [gopkg.in](https://gopkg.in).
-
-
-License
--------
-
-The yaml package is licensed under the MIT and Apache License 2.0 licenses.
-Please see the LICENSE file for details.
-
-
-Example
--------
-
-```Go
-package main
-
-import (
- "fmt"
- "log"
-
- "gopkg.in/yaml.v3"
-)
-
-var data = `
-a: Easy!
-b:
- c: 2
- d: [3, 4]
-`
-
-// Note: struct fields must be public in order for unmarshal to
-// correctly populate the data.
-type T struct {
- A string
- B struct {
- RenamedC int `yaml:"c"`
- D []int `yaml:",flow"`
- }
-}
-
-func main() {
- t := T{}
-
- err := yaml.Unmarshal([]byte(data), &t)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- t:\n%v\n\n", t)
-
- d, err := yaml.Marshal(&t)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- t dump:\n%s\n\n", string(d))
-
- m := make(map[interface{}]interface{})
-
- err = yaml.Unmarshal([]byte(data), &m)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- m:\n%v\n\n", m)
-
- d, err = yaml.Marshal(&m)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- m dump:\n%s\n\n", string(d))
-}
-```
-
-This example will generate the following output:
-
-```
---- t:
-{Easy! {2 [3 4]}}
-
---- t dump:
-a: Easy!
-b:
- c: 2
- d: [3, 4]
-
-
---- m:
-map[a:Easy! b:map[c:2 d:[3 4]]]
-
---- m dump:
-a: Easy!
-b:
- c: 2
- d:
- - 3
- - 4
-```
-
diff --git a/sesh/vendor/gopkg.in/yaml.v3/apic.go b/sesh/vendor/gopkg.in/yaml.v3/apic.go
deleted file mode 100644
index ae7d049..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/apic.go
+++ /dev/null
@@ -1,747 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "io"
-)
-
-func yaml_insert_token(parser *yaml_parser_t, pos int, token *yaml_token_t) {
- //fmt.Println("yaml_insert_token", "pos:", pos, "typ:", token.typ, "head:", parser.tokens_head, "len:", len(parser.tokens))
-
- // Check if we can move the queue at the beginning of the buffer.
- if parser.tokens_head > 0 && len(parser.tokens) == cap(parser.tokens) {
- if parser.tokens_head != len(parser.tokens) {
- copy(parser.tokens, parser.tokens[parser.tokens_head:])
- }
- parser.tokens = parser.tokens[:len(parser.tokens)-parser.tokens_head]
- parser.tokens_head = 0
- }
- parser.tokens = append(parser.tokens, *token)
- if pos < 0 {
- return
- }
- copy(parser.tokens[parser.tokens_head+pos+1:], parser.tokens[parser.tokens_head+pos:])
- parser.tokens[parser.tokens_head+pos] = *token
-}
-
-// Create a new parser object.
-func yaml_parser_initialize(parser *yaml_parser_t) bool {
- *parser = yaml_parser_t{
- raw_buffer: make([]byte, 0, input_raw_buffer_size),
- buffer: make([]byte, 0, input_buffer_size),
- }
- return true
-}
-
-// Destroy a parser object.
-func yaml_parser_delete(parser *yaml_parser_t) {
- *parser = yaml_parser_t{}
-}
-
-// String read handler.
-func yaml_string_read_handler(parser *yaml_parser_t, buffer []byte) (n int, err error) {
- if parser.input_pos == len(parser.input) {
- return 0, io.EOF
- }
- n = copy(buffer, parser.input[parser.input_pos:])
- parser.input_pos += n
- return n, nil
-}
-
-// Reader read handler.
-func yaml_reader_read_handler(parser *yaml_parser_t, buffer []byte) (n int, err error) {
- return parser.input_reader.Read(buffer)
-}
-
-// Set a string input.
-func yaml_parser_set_input_string(parser *yaml_parser_t, input []byte) {
- if parser.read_handler != nil {
- panic("must set the input source only once")
- }
- parser.read_handler = yaml_string_read_handler
- parser.input = input
- parser.input_pos = 0
-}
-
-// Set a file input.
-func yaml_parser_set_input_reader(parser *yaml_parser_t, r io.Reader) {
- if parser.read_handler != nil {
- panic("must set the input source only once")
- }
- parser.read_handler = yaml_reader_read_handler
- parser.input_reader = r
-}
-
-// Set the source encoding.
-func yaml_parser_set_encoding(parser *yaml_parser_t, encoding yaml_encoding_t) {
- if parser.encoding != yaml_ANY_ENCODING {
- panic("must set the encoding only once")
- }
- parser.encoding = encoding
-}
-
-// Create a new emitter object.
-func yaml_emitter_initialize(emitter *yaml_emitter_t) {
- *emitter = yaml_emitter_t{
- buffer: make([]byte, output_buffer_size),
- raw_buffer: make([]byte, 0, output_raw_buffer_size),
- states: make([]yaml_emitter_state_t, 0, initial_stack_size),
- events: make([]yaml_event_t, 0, initial_queue_size),
- best_width: -1,
- }
-}
-
-// Destroy an emitter object.
-func yaml_emitter_delete(emitter *yaml_emitter_t) {
- *emitter = yaml_emitter_t{}
-}
-
-// String write handler.
-func yaml_string_write_handler(emitter *yaml_emitter_t, buffer []byte) error {
- *emitter.output_buffer = append(*emitter.output_buffer, buffer...)
- return nil
-}
-
-// yaml_writer_write_handler uses emitter.output_writer to write the
-// emitted text.
-func yaml_writer_write_handler(emitter *yaml_emitter_t, buffer []byte) error {
- _, err := emitter.output_writer.Write(buffer)
- return err
-}
-
-// Set a string output.
-func yaml_emitter_set_output_string(emitter *yaml_emitter_t, output_buffer *[]byte) {
- if emitter.write_handler != nil {
- panic("must set the output target only once")
- }
- emitter.write_handler = yaml_string_write_handler
- emitter.output_buffer = output_buffer
-}
-
-// Set a file output.
-func yaml_emitter_set_output_writer(emitter *yaml_emitter_t, w io.Writer) {
- if emitter.write_handler != nil {
- panic("must set the output target only once")
- }
- emitter.write_handler = yaml_writer_write_handler
- emitter.output_writer = w
-}
-
-// Set the output encoding.
-func yaml_emitter_set_encoding(emitter *yaml_emitter_t, encoding yaml_encoding_t) {
- if emitter.encoding != yaml_ANY_ENCODING {
- panic("must set the output encoding only once")
- }
- emitter.encoding = encoding
-}
-
-// Set the canonical output style.
-func yaml_emitter_set_canonical(emitter *yaml_emitter_t, canonical bool) {
- emitter.canonical = canonical
-}
-
-// Set the indentation increment.
-func yaml_emitter_set_indent(emitter *yaml_emitter_t, indent int) {
- if indent < 2 || indent > 9 {
- indent = 2
- }
- emitter.best_indent = indent
-}
-
-// Set the preferred line width.
-func yaml_emitter_set_width(emitter *yaml_emitter_t, width int) {
- if width < 0 {
- width = -1
- }
- emitter.best_width = width
-}
-
-// Set if unescaped non-ASCII characters are allowed.
-func yaml_emitter_set_unicode(emitter *yaml_emitter_t, unicode bool) {
- emitter.unicode = unicode
-}
-
-// Set the preferred line break character.
-func yaml_emitter_set_break(emitter *yaml_emitter_t, line_break yaml_break_t) {
- emitter.line_break = line_break
-}
-
-///*
-// * Destroy a token object.
-// */
-//
-//YAML_DECLARE(void)
-//yaml_token_delete(yaml_token_t *token)
-//{
-// assert(token); // Non-NULL token object expected.
-//
-// switch (token.type)
-// {
-// case YAML_TAG_DIRECTIVE_TOKEN:
-// yaml_free(token.data.tag_directive.handle);
-// yaml_free(token.data.tag_directive.prefix);
-// break;
-//
-// case YAML_ALIAS_TOKEN:
-// yaml_free(token.data.alias.value);
-// break;
-//
-// case YAML_ANCHOR_TOKEN:
-// yaml_free(token.data.anchor.value);
-// break;
-//
-// case YAML_TAG_TOKEN:
-// yaml_free(token.data.tag.handle);
-// yaml_free(token.data.tag.suffix);
-// break;
-//
-// case YAML_SCALAR_TOKEN:
-// yaml_free(token.data.scalar.value);
-// break;
-//
-// default:
-// break;
-// }
-//
-// memset(token, 0, sizeof(yaml_token_t));
-//}
-//
-///*
-// * Check if a string is a valid UTF-8 sequence.
-// *
-// * Check 'reader.c' for more details on UTF-8 encoding.
-// */
-//
-//static int
-//yaml_check_utf8(yaml_char_t *start, size_t length)
-//{
-// yaml_char_t *end = start+length;
-// yaml_char_t *pointer = start;
-//
-// while (pointer < end) {
-// unsigned char octet;
-// unsigned int width;
-// unsigned int value;
-// size_t k;
-//
-// octet = pointer[0];
-// width = (octet & 0x80) == 0x00 ? 1 :
-// (octet & 0xE0) == 0xC0 ? 2 :
-// (octet & 0xF0) == 0xE0 ? 3 :
-// (octet & 0xF8) == 0xF0 ? 4 : 0;
-// value = (octet & 0x80) == 0x00 ? octet & 0x7F :
-// (octet & 0xE0) == 0xC0 ? octet & 0x1F :
-// (octet & 0xF0) == 0xE0 ? octet & 0x0F :
-// (octet & 0xF8) == 0xF0 ? octet & 0x07 : 0;
-// if (!width) return 0;
-// if (pointer+width > end) return 0;
-// for (k = 1; k < width; k ++) {
-// octet = pointer[k];
-// if ((octet & 0xC0) != 0x80) return 0;
-// value = (value << 6) + (octet & 0x3F);
-// }
-// if (!((width == 1) ||
-// (width == 2 && value >= 0x80) ||
-// (width == 3 && value >= 0x800) ||
-// (width == 4 && value >= 0x10000))) return 0;
-//
-// pointer += width;
-// }
-//
-// return 1;
-//}
-//
-
-// Create STREAM-START.
-func yaml_stream_start_event_initialize(event *yaml_event_t, encoding yaml_encoding_t) {
- *event = yaml_event_t{
- typ: yaml_STREAM_START_EVENT,
- encoding: encoding,
- }
-}
-
-// Create STREAM-END.
-func yaml_stream_end_event_initialize(event *yaml_event_t) {
- *event = yaml_event_t{
- typ: yaml_STREAM_END_EVENT,
- }
-}
-
-// Create DOCUMENT-START.
-func yaml_document_start_event_initialize(
- event *yaml_event_t,
- version_directive *yaml_version_directive_t,
- tag_directives []yaml_tag_directive_t,
- implicit bool,
-) {
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- version_directive: version_directive,
- tag_directives: tag_directives,
- implicit: implicit,
- }
-}
-
-// Create DOCUMENT-END.
-func yaml_document_end_event_initialize(event *yaml_event_t, implicit bool) {
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_END_EVENT,
- implicit: implicit,
- }
-}
-
-// Create ALIAS.
-func yaml_alias_event_initialize(event *yaml_event_t, anchor []byte) bool {
- *event = yaml_event_t{
- typ: yaml_ALIAS_EVENT,
- anchor: anchor,
- }
- return true
-}
-
-// Create SCALAR.
-func yaml_scalar_event_initialize(event *yaml_event_t, anchor, tag, value []byte, plain_implicit, quoted_implicit bool, style yaml_scalar_style_t) bool {
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- anchor: anchor,
- tag: tag,
- value: value,
- implicit: plain_implicit,
- quoted_implicit: quoted_implicit,
- style: yaml_style_t(style),
- }
- return true
-}
-
-// Create SEQUENCE-START.
-func yaml_sequence_start_event_initialize(event *yaml_event_t, anchor, tag []byte, implicit bool, style yaml_sequence_style_t) bool {
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(style),
- }
- return true
-}
-
-// Create SEQUENCE-END.
-func yaml_sequence_end_event_initialize(event *yaml_event_t) bool {
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- }
- return true
-}
-
-// Create MAPPING-START.
-func yaml_mapping_start_event_initialize(event *yaml_event_t, anchor, tag []byte, implicit bool, style yaml_mapping_style_t) {
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(style),
- }
-}
-
-// Create MAPPING-END.
-func yaml_mapping_end_event_initialize(event *yaml_event_t) {
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- }
-}
-
-// Destroy an event object.
-func yaml_event_delete(event *yaml_event_t) {
- *event = yaml_event_t{}
-}
-
-///*
-// * Create a document object.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_initialize(document *yaml_document_t,
-// version_directive *yaml_version_directive_t,
-// tag_directives_start *yaml_tag_directive_t,
-// tag_directives_end *yaml_tag_directive_t,
-// start_implicit int, end_implicit int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// struct {
-// start *yaml_node_t
-// end *yaml_node_t
-// top *yaml_node_t
-// } nodes = { NULL, NULL, NULL }
-// version_directive_copy *yaml_version_directive_t = NULL
-// struct {
-// start *yaml_tag_directive_t
-// end *yaml_tag_directive_t
-// top *yaml_tag_directive_t
-// } tag_directives_copy = { NULL, NULL, NULL }
-// value yaml_tag_directive_t = { NULL, NULL }
-// mark yaml_mark_t = { 0, 0, 0 }
-//
-// assert(document) // Non-NULL document object is expected.
-// assert((tag_directives_start && tag_directives_end) ||
-// (tag_directives_start == tag_directives_end))
-// // Valid tag directives are expected.
-//
-// if (!STACK_INIT(&context, nodes, INITIAL_STACK_SIZE)) goto error
-//
-// if (version_directive) {
-// version_directive_copy = yaml_malloc(sizeof(yaml_version_directive_t))
-// if (!version_directive_copy) goto error
-// version_directive_copy.major = version_directive.major
-// version_directive_copy.minor = version_directive.minor
-// }
-//
-// if (tag_directives_start != tag_directives_end) {
-// tag_directive *yaml_tag_directive_t
-// if (!STACK_INIT(&context, tag_directives_copy, INITIAL_STACK_SIZE))
-// goto error
-// for (tag_directive = tag_directives_start
-// tag_directive != tag_directives_end; tag_directive ++) {
-// assert(tag_directive.handle)
-// assert(tag_directive.prefix)
-// if (!yaml_check_utf8(tag_directive.handle,
-// strlen((char *)tag_directive.handle)))
-// goto error
-// if (!yaml_check_utf8(tag_directive.prefix,
-// strlen((char *)tag_directive.prefix)))
-// goto error
-// value.handle = yaml_strdup(tag_directive.handle)
-// value.prefix = yaml_strdup(tag_directive.prefix)
-// if (!value.handle || !value.prefix) goto error
-// if (!PUSH(&context, tag_directives_copy, value))
-// goto error
-// value.handle = NULL
-// value.prefix = NULL
-// }
-// }
-//
-// DOCUMENT_INIT(*document, nodes.start, nodes.end, version_directive_copy,
-// tag_directives_copy.start, tag_directives_copy.top,
-// start_implicit, end_implicit, mark, mark)
-//
-// return 1
-//
-//error:
-// STACK_DEL(&context, nodes)
-// yaml_free(version_directive_copy)
-// while (!STACK_EMPTY(&context, tag_directives_copy)) {
-// value yaml_tag_directive_t = POP(&context, tag_directives_copy)
-// yaml_free(value.handle)
-// yaml_free(value.prefix)
-// }
-// STACK_DEL(&context, tag_directives_copy)
-// yaml_free(value.handle)
-// yaml_free(value.prefix)
-//
-// return 0
-//}
-//
-///*
-// * Destroy a document object.
-// */
-//
-//YAML_DECLARE(void)
-//yaml_document_delete(document *yaml_document_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// tag_directive *yaml_tag_directive_t
-//
-// context.error = YAML_NO_ERROR // Eliminate a compiler warning.
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// while (!STACK_EMPTY(&context, document.nodes)) {
-// node yaml_node_t = POP(&context, document.nodes)
-// yaml_free(node.tag)
-// switch (node.type) {
-// case YAML_SCALAR_NODE:
-// yaml_free(node.data.scalar.value)
-// break
-// case YAML_SEQUENCE_NODE:
-// STACK_DEL(&context, node.data.sequence.items)
-// break
-// case YAML_MAPPING_NODE:
-// STACK_DEL(&context, node.data.mapping.pairs)
-// break
-// default:
-// assert(0) // Should not happen.
-// }
-// }
-// STACK_DEL(&context, document.nodes)
-//
-// yaml_free(document.version_directive)
-// for (tag_directive = document.tag_directives.start
-// tag_directive != document.tag_directives.end
-// tag_directive++) {
-// yaml_free(tag_directive.handle)
-// yaml_free(tag_directive.prefix)
-// }
-// yaml_free(document.tag_directives.start)
-//
-// memset(document, 0, sizeof(yaml_document_t))
-//}
-//
-///**
-// * Get a document node.
-// */
-//
-//YAML_DECLARE(yaml_node_t *)
-//yaml_document_get_node(document *yaml_document_t, index int)
-//{
-// assert(document) // Non-NULL document object is expected.
-//
-// if (index > 0 && document.nodes.start + index <= document.nodes.top) {
-// return document.nodes.start + index - 1
-// }
-// return NULL
-//}
-//
-///**
-// * Get the root object.
-// */
-//
-//YAML_DECLARE(yaml_node_t *)
-//yaml_document_get_root_node(document *yaml_document_t)
-//{
-// assert(document) // Non-NULL document object is expected.
-//
-// if (document.nodes.top != document.nodes.start) {
-// return document.nodes.start
-// }
-// return NULL
-//}
-//
-///*
-// * Add a scalar node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_scalar(document *yaml_document_t,
-// tag *yaml_char_t, value *yaml_char_t, length int,
-// style yaml_scalar_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// value_copy *yaml_char_t = NULL
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-// assert(value) // Non-NULL value is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_SCALAR_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (length < 0) {
-// length = strlen((char *)value)
-// }
-//
-// if (!yaml_check_utf8(value, length)) goto error
-// value_copy = yaml_malloc(length+1)
-// if (!value_copy) goto error
-// memcpy(value_copy, value, length)
-// value_copy[length] = '\0'
-//
-// SCALAR_NODE_INIT(node, tag_copy, value_copy, length, style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// yaml_free(tag_copy)
-// yaml_free(value_copy)
-//
-// return 0
-//}
-//
-///*
-// * Add a sequence node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_sequence(document *yaml_document_t,
-// tag *yaml_char_t, style yaml_sequence_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// struct {
-// start *yaml_node_item_t
-// end *yaml_node_item_t
-// top *yaml_node_item_t
-// } items = { NULL, NULL, NULL }
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_SEQUENCE_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (!STACK_INIT(&context, items, INITIAL_STACK_SIZE)) goto error
-//
-// SEQUENCE_NODE_INIT(node, tag_copy, items.start, items.end,
-// style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// STACK_DEL(&context, items)
-// yaml_free(tag_copy)
-//
-// return 0
-//}
-//
-///*
-// * Add a mapping node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_mapping(document *yaml_document_t,
-// tag *yaml_char_t, style yaml_mapping_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// struct {
-// start *yaml_node_pair_t
-// end *yaml_node_pair_t
-// top *yaml_node_pair_t
-// } pairs = { NULL, NULL, NULL }
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_MAPPING_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (!STACK_INIT(&context, pairs, INITIAL_STACK_SIZE)) goto error
-//
-// MAPPING_NODE_INIT(node, tag_copy, pairs.start, pairs.end,
-// style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// STACK_DEL(&context, pairs)
-// yaml_free(tag_copy)
-//
-// return 0
-//}
-//
-///*
-// * Append an item to a sequence node.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_append_sequence_item(document *yaml_document_t,
-// sequence int, item int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-//
-// assert(document) // Non-NULL document is required.
-// assert(sequence > 0
-// && document.nodes.start + sequence <= document.nodes.top)
-// // Valid sequence id is required.
-// assert(document.nodes.start[sequence-1].type == YAML_SEQUENCE_NODE)
-// // A sequence node is required.
-// assert(item > 0 && document.nodes.start + item <= document.nodes.top)
-// // Valid item id is required.
-//
-// if (!PUSH(&context,
-// document.nodes.start[sequence-1].data.sequence.items, item))
-// return 0
-//
-// return 1
-//}
-//
-///*
-// * Append a pair of a key and a value to a mapping node.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_append_mapping_pair(document *yaml_document_t,
-// mapping int, key int, value int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-//
-// pair yaml_node_pair_t
-//
-// assert(document) // Non-NULL document is required.
-// assert(mapping > 0
-// && document.nodes.start + mapping <= document.nodes.top)
-// // Valid mapping id is required.
-// assert(document.nodes.start[mapping-1].type == YAML_MAPPING_NODE)
-// // A mapping node is required.
-// assert(key > 0 && document.nodes.start + key <= document.nodes.top)
-// // Valid key id is required.
-// assert(value > 0 && document.nodes.start + value <= document.nodes.top)
-// // Valid value id is required.
-//
-// pair.key = key
-// pair.value = value
-//
-// if (!PUSH(&context,
-// document.nodes.start[mapping-1].data.mapping.pairs, pair))
-// return 0
-//
-// return 1
-//}
-//
-//
diff --git a/sesh/vendor/gopkg.in/yaml.v3/decode.go b/sesh/vendor/gopkg.in/yaml.v3/decode.go
deleted file mode 100644
index 0173b69..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/decode.go
+++ /dev/null
@@ -1,1000 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding"
- "encoding/base64"
- "fmt"
- "io"
- "math"
- "reflect"
- "strconv"
- "time"
-)
-
-// ----------------------------------------------------------------------------
-// Parser, produces a node tree out of a libyaml event stream.
-
-type parser struct {
- parser yaml_parser_t
- event yaml_event_t
- doc *Node
- anchors map[string]*Node
- doneInit bool
- textless bool
-}
-
-func newParser(b []byte) *parser {
- p := parser{}
- if !yaml_parser_initialize(&p.parser) {
- panic("failed to initialize YAML emitter")
- }
- if len(b) == 0 {
- b = []byte{'\n'}
- }
- yaml_parser_set_input_string(&p.parser, b)
- return &p
-}
-
-func newParserFromReader(r io.Reader) *parser {
- p := parser{}
- if !yaml_parser_initialize(&p.parser) {
- panic("failed to initialize YAML emitter")
- }
- yaml_parser_set_input_reader(&p.parser, r)
- return &p
-}
-
-func (p *parser) init() {
- if p.doneInit {
- return
- }
- p.anchors = make(map[string]*Node)
- p.expect(yaml_STREAM_START_EVENT)
- p.doneInit = true
-}
-
-func (p *parser) destroy() {
- if p.event.typ != yaml_NO_EVENT {
- yaml_event_delete(&p.event)
- }
- yaml_parser_delete(&p.parser)
-}
-
-// expect consumes an event from the event stream and
-// checks that it's of the expected type.
-func (p *parser) expect(e yaml_event_type_t) {
- if p.event.typ == yaml_NO_EVENT {
- if !yaml_parser_parse(&p.parser, &p.event) {
- p.fail()
- }
- }
- if p.event.typ == yaml_STREAM_END_EVENT {
- failf("attempted to go past the end of stream; corrupted value?")
- }
- if p.event.typ != e {
- p.parser.problem = fmt.Sprintf("expected %s event but got %s", e, p.event.typ)
- p.fail()
- }
- yaml_event_delete(&p.event)
- p.event.typ = yaml_NO_EVENT
-}
-
-// peek peeks at the next event in the event stream,
-// puts the results into p.event and returns the event type.
-func (p *parser) peek() yaml_event_type_t {
- if p.event.typ != yaml_NO_EVENT {
- return p.event.typ
- }
- // It's curious choice from the underlying API to generally return a
- // positive result on success, but on this case return true in an error
- // scenario. This was the source of bugs in the past (issue #666).
- if !yaml_parser_parse(&p.parser, &p.event) || p.parser.error != yaml_NO_ERROR {
- p.fail()
- }
- return p.event.typ
-}
-
-func (p *parser) fail() {
- var where string
- var line int
- if p.parser.context_mark.line != 0 {
- line = p.parser.context_mark.line
- // Scanner errors don't iterate line before returning error
- if p.parser.error == yaml_SCANNER_ERROR {
- line++
- }
- } else if p.parser.problem_mark.line != 0 {
- line = p.parser.problem_mark.line
- // Scanner errors don't iterate line before returning error
- if p.parser.error == yaml_SCANNER_ERROR {
- line++
- }
- }
- if line != 0 {
- where = "line " + strconv.Itoa(line) + ": "
- }
- var msg string
- if len(p.parser.problem) > 0 {
- msg = p.parser.problem
- } else {
- msg = "unknown problem parsing YAML content"
- }
- failf("%s%s", where, msg)
-}
-
-func (p *parser) anchor(n *Node, anchor []byte) {
- if anchor != nil {
- n.Anchor = string(anchor)
- p.anchors[n.Anchor] = n
- }
-}
-
-func (p *parser) parse() *Node {
- p.init()
- switch p.peek() {
- case yaml_SCALAR_EVENT:
- return p.scalar()
- case yaml_ALIAS_EVENT:
- return p.alias()
- case yaml_MAPPING_START_EVENT:
- return p.mapping()
- case yaml_SEQUENCE_START_EVENT:
- return p.sequence()
- case yaml_DOCUMENT_START_EVENT:
- return p.document()
- case yaml_STREAM_END_EVENT:
- // Happens when attempting to decode an empty buffer.
- return nil
- case yaml_TAIL_COMMENT_EVENT:
- panic("internal error: unexpected tail comment event (please report)")
- default:
- panic("internal error: attempted to parse unknown event (please report): " + p.event.typ.String())
- }
-}
-
-func (p *parser) node(kind Kind, defaultTag, tag, value string) *Node {
- var style Style
- if tag != "" && tag != "!" {
- tag = shortTag(tag)
- style = TaggedStyle
- } else if defaultTag != "" {
- tag = defaultTag
- } else if kind == ScalarNode {
- tag, _ = resolve("", value)
- }
- n := &Node{
- Kind: kind,
- Tag: tag,
- Value: value,
- Style: style,
- }
- if !p.textless {
- n.Line = p.event.start_mark.line + 1
- n.Column = p.event.start_mark.column + 1
- n.HeadComment = string(p.event.head_comment)
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- }
- return n
-}
-
-func (p *parser) parseChild(parent *Node) *Node {
- child := p.parse()
- parent.Content = append(parent.Content, child)
- return child
-}
-
-func (p *parser) document() *Node {
- n := p.node(DocumentNode, "", "", "")
- p.doc = n
- p.expect(yaml_DOCUMENT_START_EVENT)
- p.parseChild(n)
- if p.peek() == yaml_DOCUMENT_END_EVENT {
- n.FootComment = string(p.event.foot_comment)
- }
- p.expect(yaml_DOCUMENT_END_EVENT)
- return n
-}
-
-func (p *parser) alias() *Node {
- n := p.node(AliasNode, "", "", string(p.event.anchor))
- n.Alias = p.anchors[n.Value]
- if n.Alias == nil {
- failf("unknown anchor '%s' referenced", n.Value)
- }
- p.expect(yaml_ALIAS_EVENT)
- return n
-}
-
-func (p *parser) scalar() *Node {
- var parsedStyle = p.event.scalar_style()
- var nodeStyle Style
- switch {
- case parsedStyle&yaml_DOUBLE_QUOTED_SCALAR_STYLE != 0:
- nodeStyle = DoubleQuotedStyle
- case parsedStyle&yaml_SINGLE_QUOTED_SCALAR_STYLE != 0:
- nodeStyle = SingleQuotedStyle
- case parsedStyle&yaml_LITERAL_SCALAR_STYLE != 0:
- nodeStyle = LiteralStyle
- case parsedStyle&yaml_FOLDED_SCALAR_STYLE != 0:
- nodeStyle = FoldedStyle
- }
- var nodeValue = string(p.event.value)
- var nodeTag = string(p.event.tag)
- var defaultTag string
- if nodeStyle == 0 {
- if nodeValue == "<<" {
- defaultTag = mergeTag
- }
- } else {
- defaultTag = strTag
- }
- n := p.node(ScalarNode, defaultTag, nodeTag, nodeValue)
- n.Style |= nodeStyle
- p.anchor(n, p.event.anchor)
- p.expect(yaml_SCALAR_EVENT)
- return n
-}
-
-func (p *parser) sequence() *Node {
- n := p.node(SequenceNode, seqTag, string(p.event.tag), "")
- if p.event.sequence_style()&yaml_FLOW_SEQUENCE_STYLE != 0 {
- n.Style |= FlowStyle
- }
- p.anchor(n, p.event.anchor)
- p.expect(yaml_SEQUENCE_START_EVENT)
- for p.peek() != yaml_SEQUENCE_END_EVENT {
- p.parseChild(n)
- }
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- p.expect(yaml_SEQUENCE_END_EVENT)
- return n
-}
-
-func (p *parser) mapping() *Node {
- n := p.node(MappingNode, mapTag, string(p.event.tag), "")
- block := true
- if p.event.mapping_style()&yaml_FLOW_MAPPING_STYLE != 0 {
- block = false
- n.Style |= FlowStyle
- }
- p.anchor(n, p.event.anchor)
- p.expect(yaml_MAPPING_START_EVENT)
- for p.peek() != yaml_MAPPING_END_EVENT {
- k := p.parseChild(n)
- if block && k.FootComment != "" {
- // Must be a foot comment for the prior value when being dedented.
- if len(n.Content) > 2 {
- n.Content[len(n.Content)-3].FootComment = k.FootComment
- k.FootComment = ""
- }
- }
- v := p.parseChild(n)
- if k.FootComment == "" && v.FootComment != "" {
- k.FootComment = v.FootComment
- v.FootComment = ""
- }
- if p.peek() == yaml_TAIL_COMMENT_EVENT {
- if k.FootComment == "" {
- k.FootComment = string(p.event.foot_comment)
- }
- p.expect(yaml_TAIL_COMMENT_EVENT)
- }
- }
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- if n.Style&FlowStyle == 0 && n.FootComment != "" && len(n.Content) > 1 {
- n.Content[len(n.Content)-2].FootComment = n.FootComment
- n.FootComment = ""
- }
- p.expect(yaml_MAPPING_END_EVENT)
- return n
-}
-
-// ----------------------------------------------------------------------------
-// Decoder, unmarshals a node into a provided value.
-
-type decoder struct {
- doc *Node
- aliases map[*Node]bool
- terrors []string
-
- stringMapType reflect.Type
- generalMapType reflect.Type
-
- knownFields bool
- uniqueKeys bool
- decodeCount int
- aliasCount int
- aliasDepth int
-
- mergedFields map[interface{}]bool
-}
-
-var (
- nodeType = reflect.TypeOf(Node{})
- durationType = reflect.TypeOf(time.Duration(0))
- stringMapType = reflect.TypeOf(map[string]interface{}{})
- generalMapType = reflect.TypeOf(map[interface{}]interface{}{})
- ifaceType = generalMapType.Elem()
- timeType = reflect.TypeOf(time.Time{})
- ptrTimeType = reflect.TypeOf(&time.Time{})
-)
-
-func newDecoder() *decoder {
- d := &decoder{
- stringMapType: stringMapType,
- generalMapType: generalMapType,
- uniqueKeys: true,
- }
- d.aliases = make(map[*Node]bool)
- return d
-}
-
-func (d *decoder) terror(n *Node, tag string, out reflect.Value) {
- if n.Tag != "" {
- tag = n.Tag
- }
- value := n.Value
- if tag != seqTag && tag != mapTag {
- if len(value) > 10 {
- value = " `" + value[:7] + "...`"
- } else {
- value = " `" + value + "`"
- }
- }
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: cannot unmarshal %s%s into %s", n.Line, shortTag(tag), value, out.Type()))
-}
-
-func (d *decoder) callUnmarshaler(n *Node, u Unmarshaler) (good bool) {
- err := u.UnmarshalYAML(n)
- if e, ok := err.(*TypeError); ok {
- d.terrors = append(d.terrors, e.Errors...)
- return false
- }
- if err != nil {
- fail(err)
- }
- return true
-}
-
-func (d *decoder) callObsoleteUnmarshaler(n *Node, u obsoleteUnmarshaler) (good bool) {
- terrlen := len(d.terrors)
- err := u.UnmarshalYAML(func(v interface{}) (err error) {
- defer handleErr(&err)
- d.unmarshal(n, reflect.ValueOf(v))
- if len(d.terrors) > terrlen {
- issues := d.terrors[terrlen:]
- d.terrors = d.terrors[:terrlen]
- return &TypeError{issues}
- }
- return nil
- })
- if e, ok := err.(*TypeError); ok {
- d.terrors = append(d.terrors, e.Errors...)
- return false
- }
- if err != nil {
- fail(err)
- }
- return true
-}
-
-// d.prepare initializes and dereferences pointers and calls UnmarshalYAML
-// if a value is found to implement it.
-// It returns the initialized and dereferenced out value, whether
-// unmarshalling was already done by UnmarshalYAML, and if so whether
-// its types unmarshalled appropriately.
-//
-// If n holds a null value, prepare returns before doing anything.
-func (d *decoder) prepare(n *Node, out reflect.Value) (newout reflect.Value, unmarshaled, good bool) {
- if n.ShortTag() == nullTag {
- return out, false, false
- }
- again := true
- for again {
- again = false
- if out.Kind() == reflect.Ptr {
- if out.IsNil() {
- out.Set(reflect.New(out.Type().Elem()))
- }
- out = out.Elem()
- again = true
- }
- if out.CanAddr() {
- outi := out.Addr().Interface()
- if u, ok := outi.(Unmarshaler); ok {
- good = d.callUnmarshaler(n, u)
- return out, true, good
- }
- if u, ok := outi.(obsoleteUnmarshaler); ok {
- good = d.callObsoleteUnmarshaler(n, u)
- return out, true, good
- }
- }
- }
- return out, false, false
-}
-
-func (d *decoder) fieldByIndex(n *Node, v reflect.Value, index []int) (field reflect.Value) {
- if n.ShortTag() == nullTag {
- return reflect.Value{}
- }
- for _, num := range index {
- for {
- if v.Kind() == reflect.Ptr {
- if v.IsNil() {
- v.Set(reflect.New(v.Type().Elem()))
- }
- v = v.Elem()
- continue
- }
- break
- }
- v = v.Field(num)
- }
- return v
-}
-
-const (
- // 400,000 decode operations is ~500kb of dense object declarations, or
- // ~5kb of dense object declarations with 10000% alias expansion
- alias_ratio_range_low = 400000
-
- // 4,000,000 decode operations is ~5MB of dense object declarations, or
- // ~4.5MB of dense object declarations with 10% alias expansion
- alias_ratio_range_high = 4000000
-
- // alias_ratio_range is the range over which we scale allowed alias ratios
- alias_ratio_range = float64(alias_ratio_range_high - alias_ratio_range_low)
-)
-
-func allowedAliasRatio(decodeCount int) float64 {
- switch {
- case decodeCount <= alias_ratio_range_low:
- // allow 99% to come from alias expansion for small-to-medium documents
- return 0.99
- case decodeCount >= alias_ratio_range_high:
- // allow 10% to come from alias expansion for very large documents
- return 0.10
- default:
- // scale smoothly from 99% down to 10% over the range.
- // this maps to 396,000 - 400,000 allowed alias-driven decodes over the range.
- // 400,000 decode operations is ~100MB of allocations in worst-case scenarios (single-item maps).
- return 0.99 - 0.89*(float64(decodeCount-alias_ratio_range_low)/alias_ratio_range)
- }
-}
-
-func (d *decoder) unmarshal(n *Node, out reflect.Value) (good bool) {
- d.decodeCount++
- if d.aliasDepth > 0 {
- d.aliasCount++
- }
- if d.aliasCount > 100 && d.decodeCount > 1000 && float64(d.aliasCount)/float64(d.decodeCount) > allowedAliasRatio(d.decodeCount) {
- failf("document contains excessive aliasing")
- }
- if out.Type() == nodeType {
- out.Set(reflect.ValueOf(n).Elem())
- return true
- }
- switch n.Kind {
- case DocumentNode:
- return d.document(n, out)
- case AliasNode:
- return d.alias(n, out)
- }
- out, unmarshaled, good := d.prepare(n, out)
- if unmarshaled {
- return good
- }
- switch n.Kind {
- case ScalarNode:
- good = d.scalar(n, out)
- case MappingNode:
- good = d.mapping(n, out)
- case SequenceNode:
- good = d.sequence(n, out)
- case 0:
- if n.IsZero() {
- return d.null(out)
- }
- fallthrough
- default:
- failf("cannot decode node with unknown kind %d", n.Kind)
- }
- return good
-}
-
-func (d *decoder) document(n *Node, out reflect.Value) (good bool) {
- if len(n.Content) == 1 {
- d.doc = n
- d.unmarshal(n.Content[0], out)
- return true
- }
- return false
-}
-
-func (d *decoder) alias(n *Node, out reflect.Value) (good bool) {
- if d.aliases[n] {
- // TODO this could actually be allowed in some circumstances.
- failf("anchor '%s' value contains itself", n.Value)
- }
- d.aliases[n] = true
- d.aliasDepth++
- good = d.unmarshal(n.Alias, out)
- d.aliasDepth--
- delete(d.aliases, n)
- return good
-}
-
-var zeroValue reflect.Value
-
-func resetMap(out reflect.Value) {
- for _, k := range out.MapKeys() {
- out.SetMapIndex(k, zeroValue)
- }
-}
-
-func (d *decoder) null(out reflect.Value) bool {
- if out.CanAddr() {
- switch out.Kind() {
- case reflect.Interface, reflect.Ptr, reflect.Map, reflect.Slice:
- out.Set(reflect.Zero(out.Type()))
- return true
- }
- }
- return false
-}
-
-func (d *decoder) scalar(n *Node, out reflect.Value) bool {
- var tag string
- var resolved interface{}
- if n.indicatedString() {
- tag = strTag
- resolved = n.Value
- } else {
- tag, resolved = resolve(n.Tag, n.Value)
- if tag == binaryTag {
- data, err := base64.StdEncoding.DecodeString(resolved.(string))
- if err != nil {
- failf("!!binary value contains invalid base64 data")
- }
- resolved = string(data)
- }
- }
- if resolved == nil {
- return d.null(out)
- }
- if resolvedv := reflect.ValueOf(resolved); out.Type() == resolvedv.Type() {
- // We've resolved to exactly the type we want, so use that.
- out.Set(resolvedv)
- return true
- }
- // Perhaps we can use the value as a TextUnmarshaler to
- // set its value.
- if out.CanAddr() {
- u, ok := out.Addr().Interface().(encoding.TextUnmarshaler)
- if ok {
- var text []byte
- if tag == binaryTag {
- text = []byte(resolved.(string))
- } else {
- // We let any value be unmarshaled into TextUnmarshaler.
- // That might be more lax than we'd like, but the
- // TextUnmarshaler itself should bowl out any dubious values.
- text = []byte(n.Value)
- }
- err := u.UnmarshalText(text)
- if err != nil {
- fail(err)
- }
- return true
- }
- }
- switch out.Kind() {
- case reflect.String:
- if tag == binaryTag {
- out.SetString(resolved.(string))
- return true
- }
- out.SetString(n.Value)
- return true
- case reflect.Interface:
- out.Set(reflect.ValueOf(resolved))
- return true
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- // This used to work in v2, but it's very unfriendly.
- isDuration := out.Type() == durationType
-
- switch resolved := resolved.(type) {
- case int:
- if !isDuration && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case int64:
- if !isDuration && !out.OverflowInt(resolved) {
- out.SetInt(resolved)
- return true
- }
- case uint64:
- if !isDuration && resolved <= math.MaxInt64 && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case float64:
- if !isDuration && resolved <= math.MaxInt64 && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case string:
- if out.Type() == durationType {
- d, err := time.ParseDuration(resolved)
- if err == nil {
- out.SetInt(int64(d))
- return true
- }
- }
- }
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- switch resolved := resolved.(type) {
- case int:
- if resolved >= 0 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case int64:
- if resolved >= 0 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case uint64:
- if !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case float64:
- if resolved <= math.MaxUint64 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- }
- case reflect.Bool:
- switch resolved := resolved.(type) {
- case bool:
- out.SetBool(resolved)
- return true
- case string:
- // This offers some compatibility with the 1.1 spec (https://yaml.org/type/bool.html).
- // It only works if explicitly attempting to unmarshal into a typed bool value.
- switch resolved {
- case "y", "Y", "yes", "Yes", "YES", "on", "On", "ON":
- out.SetBool(true)
- return true
- case "n", "N", "no", "No", "NO", "off", "Off", "OFF":
- out.SetBool(false)
- return true
- }
- }
- case reflect.Float32, reflect.Float64:
- switch resolved := resolved.(type) {
- case int:
- out.SetFloat(float64(resolved))
- return true
- case int64:
- out.SetFloat(float64(resolved))
- return true
- case uint64:
- out.SetFloat(float64(resolved))
- return true
- case float64:
- out.SetFloat(resolved)
- return true
- }
- case reflect.Struct:
- if resolvedv := reflect.ValueOf(resolved); out.Type() == resolvedv.Type() {
- out.Set(resolvedv)
- return true
- }
- case reflect.Ptr:
- panic("yaml internal error: please report the issue")
- }
- d.terror(n, tag, out)
- return false
-}
-
-func settableValueOf(i interface{}) reflect.Value {
- v := reflect.ValueOf(i)
- sv := reflect.New(v.Type()).Elem()
- sv.Set(v)
- return sv
-}
-
-func (d *decoder) sequence(n *Node, out reflect.Value) (good bool) {
- l := len(n.Content)
-
- var iface reflect.Value
- switch out.Kind() {
- case reflect.Slice:
- out.Set(reflect.MakeSlice(out.Type(), l, l))
- case reflect.Array:
- if l != out.Len() {
- failf("invalid array: want %d elements but got %d", out.Len(), l)
- }
- case reflect.Interface:
- // No type hints. Will have to use a generic sequence.
- iface = out
- out = settableValueOf(make([]interface{}, l))
- default:
- d.terror(n, seqTag, out)
- return false
- }
- et := out.Type().Elem()
-
- j := 0
- for i := 0; i < l; i++ {
- e := reflect.New(et).Elem()
- if ok := d.unmarshal(n.Content[i], e); ok {
- out.Index(j).Set(e)
- j++
- }
- }
- if out.Kind() != reflect.Array {
- out.Set(out.Slice(0, j))
- }
- if iface.IsValid() {
- iface.Set(out)
- }
- return true
-}
-
-func (d *decoder) mapping(n *Node, out reflect.Value) (good bool) {
- l := len(n.Content)
- if d.uniqueKeys {
- nerrs := len(d.terrors)
- for i := 0; i < l; i += 2 {
- ni := n.Content[i]
- for j := i + 2; j < l; j += 2 {
- nj := n.Content[j]
- if ni.Kind == nj.Kind && ni.Value == nj.Value {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: mapping key %#v already defined at line %d", nj.Line, nj.Value, ni.Line))
- }
- }
- }
- if len(d.terrors) > nerrs {
- return false
- }
- }
- switch out.Kind() {
- case reflect.Struct:
- return d.mappingStruct(n, out)
- case reflect.Map:
- // okay
- case reflect.Interface:
- iface := out
- if isStringMap(n) {
- out = reflect.MakeMap(d.stringMapType)
- } else {
- out = reflect.MakeMap(d.generalMapType)
- }
- iface.Set(out)
- default:
- d.terror(n, mapTag, out)
- return false
- }
-
- outt := out.Type()
- kt := outt.Key()
- et := outt.Elem()
-
- stringMapType := d.stringMapType
- generalMapType := d.generalMapType
- if outt.Elem() == ifaceType {
- if outt.Key().Kind() == reflect.String {
- d.stringMapType = outt
- } else if outt.Key() == ifaceType {
- d.generalMapType = outt
- }
- }
-
- mergedFields := d.mergedFields
- d.mergedFields = nil
-
- var mergeNode *Node
-
- mapIsNew := false
- if out.IsNil() {
- out.Set(reflect.MakeMap(outt))
- mapIsNew = true
- }
- for i := 0; i < l; i += 2 {
- if isMerge(n.Content[i]) {
- mergeNode = n.Content[i+1]
- continue
- }
- k := reflect.New(kt).Elem()
- if d.unmarshal(n.Content[i], k) {
- if mergedFields != nil {
- ki := k.Interface()
- if mergedFields[ki] {
- continue
- }
- mergedFields[ki] = true
- }
- kkind := k.Kind()
- if kkind == reflect.Interface {
- kkind = k.Elem().Kind()
- }
- if kkind == reflect.Map || kkind == reflect.Slice {
- failf("invalid map key: %#v", k.Interface())
- }
- e := reflect.New(et).Elem()
- if d.unmarshal(n.Content[i+1], e) || n.Content[i+1].ShortTag() == nullTag && (mapIsNew || !out.MapIndex(k).IsValid()) {
- out.SetMapIndex(k, e)
- }
- }
- }
-
- d.mergedFields = mergedFields
- if mergeNode != nil {
- d.merge(n, mergeNode, out)
- }
-
- d.stringMapType = stringMapType
- d.generalMapType = generalMapType
- return true
-}
-
-func isStringMap(n *Node) bool {
- if n.Kind != MappingNode {
- return false
- }
- l := len(n.Content)
- for i := 0; i < l; i += 2 {
- shortTag := n.Content[i].ShortTag()
- if shortTag != strTag && shortTag != mergeTag {
- return false
- }
- }
- return true
-}
-
-func (d *decoder) mappingStruct(n *Node, out reflect.Value) (good bool) {
- sinfo, err := getStructInfo(out.Type())
- if err != nil {
- panic(err)
- }
-
- var inlineMap reflect.Value
- var elemType reflect.Type
- if sinfo.InlineMap != -1 {
- inlineMap = out.Field(sinfo.InlineMap)
- elemType = inlineMap.Type().Elem()
- }
-
- for _, index := range sinfo.InlineUnmarshalers {
- field := d.fieldByIndex(n, out, index)
- d.prepare(n, field)
- }
-
- mergedFields := d.mergedFields
- d.mergedFields = nil
- var mergeNode *Node
- var doneFields []bool
- if d.uniqueKeys {
- doneFields = make([]bool, len(sinfo.FieldsList))
- }
- name := settableValueOf("")
- l := len(n.Content)
- for i := 0; i < l; i += 2 {
- ni := n.Content[i]
- if isMerge(ni) {
- mergeNode = n.Content[i+1]
- continue
- }
- if !d.unmarshal(ni, name) {
- continue
- }
- sname := name.String()
- if mergedFields != nil {
- if mergedFields[sname] {
- continue
- }
- mergedFields[sname] = true
- }
- if info, ok := sinfo.FieldsMap[sname]; ok {
- if d.uniqueKeys {
- if doneFields[info.Id] {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: field %s already set in type %s", ni.Line, name.String(), out.Type()))
- continue
- }
- doneFields[info.Id] = true
- }
- var field reflect.Value
- if info.Inline == nil {
- field = out.Field(info.Num)
- } else {
- field = d.fieldByIndex(n, out, info.Inline)
- }
- d.unmarshal(n.Content[i+1], field)
- } else if sinfo.InlineMap != -1 {
- if inlineMap.IsNil() {
- inlineMap.Set(reflect.MakeMap(inlineMap.Type()))
- }
- value := reflect.New(elemType).Elem()
- d.unmarshal(n.Content[i+1], value)
- inlineMap.SetMapIndex(name, value)
- } else if d.knownFields {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: field %s not found in type %s", ni.Line, name.String(), out.Type()))
- }
- }
-
- d.mergedFields = mergedFields
- if mergeNode != nil {
- d.merge(n, mergeNode, out)
- }
- return true
-}
-
-func failWantMap() {
- failf("map merge requires map or sequence of maps as the value")
-}
-
-func (d *decoder) merge(parent *Node, merge *Node, out reflect.Value) {
- mergedFields := d.mergedFields
- if mergedFields == nil {
- d.mergedFields = make(map[interface{}]bool)
- for i := 0; i < len(parent.Content); i += 2 {
- k := reflect.New(ifaceType).Elem()
- if d.unmarshal(parent.Content[i], k) {
- d.mergedFields[k.Interface()] = true
- }
- }
- }
-
- switch merge.Kind {
- case MappingNode:
- d.unmarshal(merge, out)
- case AliasNode:
- if merge.Alias != nil && merge.Alias.Kind != MappingNode {
- failWantMap()
- }
- d.unmarshal(merge, out)
- case SequenceNode:
- for i := 0; i < len(merge.Content); i++ {
- ni := merge.Content[i]
- if ni.Kind == AliasNode {
- if ni.Alias != nil && ni.Alias.Kind != MappingNode {
- failWantMap()
- }
- } else if ni.Kind != MappingNode {
- failWantMap()
- }
- d.unmarshal(ni, out)
- }
- default:
- failWantMap()
- }
-
- d.mergedFields = mergedFields
-}
-
-func isMerge(n *Node) bool {
- return n.Kind == ScalarNode && n.Value == "<<" && (n.Tag == "" || n.Tag == "!" || shortTag(n.Tag) == mergeTag)
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/emitterc.go b/sesh/vendor/gopkg.in/yaml.v3/emitterc.go
deleted file mode 100644
index 0f47c9c..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/emitterc.go
+++ /dev/null
@@ -1,2020 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
- "fmt"
-)
-
-// Flush the buffer if needed.
-func flush(emitter *yaml_emitter_t) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) {
- return yaml_emitter_flush(emitter)
- }
- return true
-}
-
-// Put a character to the output buffer.
-func put(emitter *yaml_emitter_t, value byte) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.buffer[emitter.buffer_pos] = value
- emitter.buffer_pos++
- emitter.column++
- return true
-}
-
-// Put a line break to the output buffer.
-func put_break(emitter *yaml_emitter_t) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- switch emitter.line_break {
- case yaml_CR_BREAK:
- emitter.buffer[emitter.buffer_pos] = '\r'
- emitter.buffer_pos += 1
- case yaml_LN_BREAK:
- emitter.buffer[emitter.buffer_pos] = '\n'
- emitter.buffer_pos += 1
- case yaml_CRLN_BREAK:
- emitter.buffer[emitter.buffer_pos+0] = '\r'
- emitter.buffer[emitter.buffer_pos+1] = '\n'
- emitter.buffer_pos += 2
- default:
- panic("unknown line break setting")
- }
- if emitter.column == 0 {
- emitter.space_above = true
- }
- emitter.column = 0
- emitter.line++
- // [Go] Do this here and below and drop from everywhere else (see commented lines).
- emitter.indention = true
- return true
-}
-
-// Copy a character from a string into buffer.
-func write(emitter *yaml_emitter_t, s []byte, i *int) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- p := emitter.buffer_pos
- w := width(s[*i])
- switch w {
- case 4:
- emitter.buffer[p+3] = s[*i+3]
- fallthrough
- case 3:
- emitter.buffer[p+2] = s[*i+2]
- fallthrough
- case 2:
- emitter.buffer[p+1] = s[*i+1]
- fallthrough
- case 1:
- emitter.buffer[p+0] = s[*i+0]
- default:
- panic("unknown character width")
- }
- emitter.column++
- emitter.buffer_pos += w
- *i += w
- return true
-}
-
-// Write a whole string into buffer.
-func write_all(emitter *yaml_emitter_t, s []byte) bool {
- for i := 0; i < len(s); {
- if !write(emitter, s, &i) {
- return false
- }
- }
- return true
-}
-
-// Copy a line break character from a string into buffer.
-func write_break(emitter *yaml_emitter_t, s []byte, i *int) bool {
- if s[*i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- *i++
- } else {
- if !write(emitter, s, i) {
- return false
- }
- if emitter.column == 0 {
- emitter.space_above = true
- }
- emitter.column = 0
- emitter.line++
- // [Go] Do this here and above and drop from everywhere else (see commented lines).
- emitter.indention = true
- }
- return true
-}
-
-// Set an emitter error and return false.
-func yaml_emitter_set_emitter_error(emitter *yaml_emitter_t, problem string) bool {
- emitter.error = yaml_EMITTER_ERROR
- emitter.problem = problem
- return false
-}
-
-// Emit an event.
-func yaml_emitter_emit(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- emitter.events = append(emitter.events, *event)
- for !yaml_emitter_need_more_events(emitter) {
- event := &emitter.events[emitter.events_head]
- if !yaml_emitter_analyze_event(emitter, event) {
- return false
- }
- if !yaml_emitter_state_machine(emitter, event) {
- return false
- }
- yaml_event_delete(event)
- emitter.events_head++
- }
- return true
-}
-
-// Check if we need to accumulate more events before emitting.
-//
-// We accumulate extra
-// - 1 event for DOCUMENT-START
-// - 2 events for SEQUENCE-START
-// - 3 events for MAPPING-START
-//
-func yaml_emitter_need_more_events(emitter *yaml_emitter_t) bool {
- if emitter.events_head == len(emitter.events) {
- return true
- }
- var accumulate int
- switch emitter.events[emitter.events_head].typ {
- case yaml_DOCUMENT_START_EVENT:
- accumulate = 1
- break
- case yaml_SEQUENCE_START_EVENT:
- accumulate = 2
- break
- case yaml_MAPPING_START_EVENT:
- accumulate = 3
- break
- default:
- return false
- }
- if len(emitter.events)-emitter.events_head > accumulate {
- return false
- }
- var level int
- for i := emitter.events_head; i < len(emitter.events); i++ {
- switch emitter.events[i].typ {
- case yaml_STREAM_START_EVENT, yaml_DOCUMENT_START_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT:
- level++
- case yaml_STREAM_END_EVENT, yaml_DOCUMENT_END_EVENT, yaml_SEQUENCE_END_EVENT, yaml_MAPPING_END_EVENT:
- level--
- }
- if level == 0 {
- return false
- }
- }
- return true
-}
-
-// Append a directive to the directives stack.
-func yaml_emitter_append_tag_directive(emitter *yaml_emitter_t, value *yaml_tag_directive_t, allow_duplicates bool) bool {
- for i := 0; i < len(emitter.tag_directives); i++ {
- if bytes.Equal(value.handle, emitter.tag_directives[i].handle) {
- if allow_duplicates {
- return true
- }
- return yaml_emitter_set_emitter_error(emitter, "duplicate %TAG directive")
- }
- }
-
- // [Go] Do we actually need to copy this given garbage collection
- // and the lack of deallocating destructors?
- tag_copy := yaml_tag_directive_t{
- handle: make([]byte, len(value.handle)),
- prefix: make([]byte, len(value.prefix)),
- }
- copy(tag_copy.handle, value.handle)
- copy(tag_copy.prefix, value.prefix)
- emitter.tag_directives = append(emitter.tag_directives, tag_copy)
- return true
-}
-
-// Increase the indentation level.
-func yaml_emitter_increase_indent(emitter *yaml_emitter_t, flow, indentless bool) bool {
- emitter.indents = append(emitter.indents, emitter.indent)
- if emitter.indent < 0 {
- if flow {
- emitter.indent = emitter.best_indent
- } else {
- emitter.indent = 0
- }
- } else if !indentless {
- // [Go] This was changed so that indentations are more regular.
- if emitter.states[len(emitter.states)-1] == yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE {
- // The first indent inside a sequence will just skip the "- " indicator.
- emitter.indent += 2
- } else {
- // Everything else aligns to the chosen indentation.
- emitter.indent = emitter.best_indent*((emitter.indent+emitter.best_indent)/emitter.best_indent)
- }
- }
- return true
-}
-
-// State dispatcher.
-func yaml_emitter_state_machine(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- switch emitter.state {
- default:
- case yaml_EMIT_STREAM_START_STATE:
- return yaml_emitter_emit_stream_start(emitter, event)
-
- case yaml_EMIT_FIRST_DOCUMENT_START_STATE:
- return yaml_emitter_emit_document_start(emitter, event, true)
-
- case yaml_EMIT_DOCUMENT_START_STATE:
- return yaml_emitter_emit_document_start(emitter, event, false)
-
- case yaml_EMIT_DOCUMENT_CONTENT_STATE:
- return yaml_emitter_emit_document_content(emitter, event)
-
- case yaml_EMIT_DOCUMENT_END_STATE:
- return yaml_emitter_emit_document_end(emitter, event)
-
- case yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, true, false)
-
- case yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, false, true)
-
- case yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, false, false)
-
- case yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, true, false)
-
- case yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, false, true)
-
- case yaml_EMIT_FLOW_MAPPING_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, false, false)
-
- case yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE:
- return yaml_emitter_emit_flow_mapping_value(emitter, event, true)
-
- case yaml_EMIT_FLOW_MAPPING_VALUE_STATE:
- return yaml_emitter_emit_flow_mapping_value(emitter, event, false)
-
- case yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE:
- return yaml_emitter_emit_block_sequence_item(emitter, event, true)
-
- case yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE:
- return yaml_emitter_emit_block_sequence_item(emitter, event, false)
-
- case yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE:
- return yaml_emitter_emit_block_mapping_key(emitter, event, true)
-
- case yaml_EMIT_BLOCK_MAPPING_KEY_STATE:
- return yaml_emitter_emit_block_mapping_key(emitter, event, false)
-
- case yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE:
- return yaml_emitter_emit_block_mapping_value(emitter, event, true)
-
- case yaml_EMIT_BLOCK_MAPPING_VALUE_STATE:
- return yaml_emitter_emit_block_mapping_value(emitter, event, false)
-
- case yaml_EMIT_END_STATE:
- return yaml_emitter_set_emitter_error(emitter, "expected nothing after STREAM-END")
- }
- panic("invalid emitter state")
-}
-
-// Expect STREAM-START.
-func yaml_emitter_emit_stream_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if event.typ != yaml_STREAM_START_EVENT {
- return yaml_emitter_set_emitter_error(emitter, "expected STREAM-START")
- }
- if emitter.encoding == yaml_ANY_ENCODING {
- emitter.encoding = event.encoding
- if emitter.encoding == yaml_ANY_ENCODING {
- emitter.encoding = yaml_UTF8_ENCODING
- }
- }
- if emitter.best_indent < 2 || emitter.best_indent > 9 {
- emitter.best_indent = 2
- }
- if emitter.best_width >= 0 && emitter.best_width <= emitter.best_indent*2 {
- emitter.best_width = 80
- }
- if emitter.best_width < 0 {
- emitter.best_width = 1<<31 - 1
- }
- if emitter.line_break == yaml_ANY_BREAK {
- emitter.line_break = yaml_LN_BREAK
- }
-
- emitter.indent = -1
- emitter.line = 0
- emitter.column = 0
- emitter.whitespace = true
- emitter.indention = true
- emitter.space_above = true
- emitter.foot_indent = -1
-
- if emitter.encoding != yaml_UTF8_ENCODING {
- if !yaml_emitter_write_bom(emitter) {
- return false
- }
- }
- emitter.state = yaml_EMIT_FIRST_DOCUMENT_START_STATE
- return true
-}
-
-// Expect DOCUMENT-START or STREAM-END.
-func yaml_emitter_emit_document_start(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
-
- if event.typ == yaml_DOCUMENT_START_EVENT {
-
- if event.version_directive != nil {
- if !yaml_emitter_analyze_version_directive(emitter, event.version_directive) {
- return false
- }
- }
-
- for i := 0; i < len(event.tag_directives); i++ {
- tag_directive := &event.tag_directives[i]
- if !yaml_emitter_analyze_tag_directive(emitter, tag_directive) {
- return false
- }
- if !yaml_emitter_append_tag_directive(emitter, tag_directive, false) {
- return false
- }
- }
-
- for i := 0; i < len(default_tag_directives); i++ {
- tag_directive := &default_tag_directives[i]
- if !yaml_emitter_append_tag_directive(emitter, tag_directive, true) {
- return false
- }
- }
-
- implicit := event.implicit
- if !first || emitter.canonical {
- implicit = false
- }
-
- if emitter.open_ended && (event.version_directive != nil || len(event.tag_directives) > 0) {
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if event.version_directive != nil {
- implicit = false
- if !yaml_emitter_write_indicator(emitter, []byte("%YAML"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte("1.1"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if len(event.tag_directives) > 0 {
- implicit = false
- for i := 0; i < len(event.tag_directives); i++ {
- tag_directive := &event.tag_directives[i]
- if !yaml_emitter_write_indicator(emitter, []byte("%TAG"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_tag_handle(emitter, tag_directive.handle) {
- return false
- }
- if !yaml_emitter_write_tag_content(emitter, tag_directive.prefix, true) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- }
-
- if yaml_emitter_check_empty_document(emitter) {
- implicit = false
- }
- if !implicit {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte("---"), true, false, false) {
- return false
- }
- if emitter.canonical || true {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- }
-
- if len(emitter.head_comment) > 0 {
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !put_break(emitter) {
- return false
- }
- }
-
- emitter.state = yaml_EMIT_DOCUMENT_CONTENT_STATE
- return true
- }
-
- if event.typ == yaml_STREAM_END_EVENT {
- if emitter.open_ended {
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.state = yaml_EMIT_END_STATE
- return true
- }
-
- return yaml_emitter_set_emitter_error(emitter, "expected DOCUMENT-START or STREAM-END")
-}
-
-// Expect the root node.
-func yaml_emitter_emit_document_content(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- emitter.states = append(emitter.states, yaml_EMIT_DOCUMENT_END_STATE)
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !yaml_emitter_emit_node(emitter, event, true, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect DOCUMENT-END.
-func yaml_emitter_emit_document_end(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if event.typ != yaml_DOCUMENT_END_EVENT {
- return yaml_emitter_set_emitter_error(emitter, "expected DOCUMENT-END")
- }
- // [Go] Force document foot separation.
- emitter.foot_indent = 0
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.foot_indent = -1
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !event.implicit {
- // [Go] Allocate the slice elsewhere.
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.state = yaml_EMIT_DOCUMENT_START_STATE
- emitter.tag_directives = emitter.tag_directives[:0]
- return true
-}
-
-// Expect a flow item node.
-func yaml_emitter_emit_flow_sequence_item(emitter *yaml_emitter_t, event *yaml_event_t, first, trail bool) bool {
- if first {
- if !yaml_emitter_write_indicator(emitter, []byte{'['}, true, true, false) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- emitter.flow_level++
- }
-
- if event.typ == yaml_SEQUENCE_END_EVENT {
- if emitter.canonical && !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- emitter.flow_level--
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- if emitter.column == 0 || emitter.canonical && !first {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{']'}, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
-
- return true
- }
-
- if !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if emitter.column == 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE)
- } else {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE)
- }
- if !yaml_emitter_emit_node(emitter, event, false, true, false, false) {
- return false
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a flow key node.
-func yaml_emitter_emit_flow_mapping_key(emitter *yaml_emitter_t, event *yaml_event_t, first, trail bool) bool {
- if first {
- if !yaml_emitter_write_indicator(emitter, []byte{'{'}, true, true, false) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- emitter.flow_level++
- }
-
- if event.typ == yaml_MAPPING_END_EVENT {
- if (emitter.canonical || len(emitter.head_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0) && !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- emitter.flow_level--
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- if emitter.canonical && !first {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'}'}, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
-
- if !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
-
- if emitter.column == 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if !emitter.canonical && yaml_emitter_check_simple_key(emitter) {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, true)
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'?'}, true, false, false) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, false)
-}
-
-// Expect a flow value node.
-func yaml_emitter_emit_flow_mapping_value(emitter *yaml_emitter_t, event *yaml_event_t, simple bool) bool {
- if simple {
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, false, false, false) {
- return false
- }
- } else {
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, true, false, false) {
- return false
- }
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE)
- } else {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_KEY_STATE)
- }
- if !yaml_emitter_emit_node(emitter, event, false, false, true, false) {
- return false
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a block item node.
-func yaml_emitter_emit_block_sequence_item(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
- if first {
- if !yaml_emitter_increase_indent(emitter, false, false) {
- return false
- }
- }
- if event.typ == yaml_SEQUENCE_END_EVENT {
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'-'}, true, false, true) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE)
- if !yaml_emitter_emit_node(emitter, event, false, true, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a block key node.
-func yaml_emitter_emit_block_mapping_key(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
- if first {
- if !yaml_emitter_increase_indent(emitter, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if event.typ == yaml_MAPPING_END_EVENT {
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if len(emitter.line_comment) > 0 {
- // [Go] A line comment was provided for the key. That's unusual as the
- // scanner associates line comments with the value. Either way,
- // save the line comment and render it appropriately later.
- emitter.key_line_comment = emitter.line_comment
- emitter.line_comment = nil
- }
- if yaml_emitter_check_simple_key(emitter) {
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, true)
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'?'}, true, false, true) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, false)
-}
-
-// Expect a block value node.
-func yaml_emitter_emit_block_mapping_value(emitter *yaml_emitter_t, event *yaml_event_t, simple bool) bool {
- if simple {
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, false, false, false) {
- return false
- }
- } else {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, true, false, true) {
- return false
- }
- }
- if len(emitter.key_line_comment) > 0 {
- // [Go] Line comments are generally associated with the value, but when there's
- // no value on the same line as a mapping key they end up attached to the
- // key itself.
- if event.typ == yaml_SCALAR_EVENT {
- if len(emitter.line_comment) == 0 {
- // A scalar is coming and it has no line comments by itself yet,
- // so just let it handle the line comment as usual. If it has a
- // line comment, we can't have both so the one from the key is lost.
- emitter.line_comment = emitter.key_line_comment
- emitter.key_line_comment = nil
- }
- } else if event.sequence_style() != yaml_FLOW_SEQUENCE_STYLE && (event.typ == yaml_MAPPING_START_EVENT || event.typ == yaml_SEQUENCE_START_EVENT) {
- // An indented block follows, so write the comment right now.
- emitter.line_comment, emitter.key_line_comment = emitter.key_line_comment, emitter.line_comment
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- emitter.line_comment, emitter.key_line_comment = emitter.key_line_comment, emitter.line_comment
- }
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_KEY_STATE)
- if !yaml_emitter_emit_node(emitter, event, false, false, true, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-func yaml_emitter_silent_nil_event(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- return event.typ == yaml_SCALAR_EVENT && event.implicit && !emitter.canonical && len(emitter.scalar_data.value) == 0
-}
-
-// Expect a node.
-func yaml_emitter_emit_node(emitter *yaml_emitter_t, event *yaml_event_t,
- root bool, sequence bool, mapping bool, simple_key bool) bool {
-
- emitter.root_context = root
- emitter.sequence_context = sequence
- emitter.mapping_context = mapping
- emitter.simple_key_context = simple_key
-
- switch event.typ {
- case yaml_ALIAS_EVENT:
- return yaml_emitter_emit_alias(emitter, event)
- case yaml_SCALAR_EVENT:
- return yaml_emitter_emit_scalar(emitter, event)
- case yaml_SEQUENCE_START_EVENT:
- return yaml_emitter_emit_sequence_start(emitter, event)
- case yaml_MAPPING_START_EVENT:
- return yaml_emitter_emit_mapping_start(emitter, event)
- default:
- return yaml_emitter_set_emitter_error(emitter,
- fmt.Sprintf("expected SCALAR, SEQUENCE-START, MAPPING-START, or ALIAS, but got %v", event.typ))
- }
-}
-
-// Expect ALIAS.
-func yaml_emitter_emit_alias(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
-}
-
-// Expect SCALAR.
-func yaml_emitter_emit_scalar(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_select_scalar_style(emitter, event) {
- return false
- }
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- if !yaml_emitter_process_scalar(emitter) {
- return false
- }
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
-}
-
-// Expect SEQUENCE-START.
-func yaml_emitter_emit_sequence_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if emitter.flow_level > 0 || emitter.canonical || event.sequence_style() == yaml_FLOW_SEQUENCE_STYLE ||
- yaml_emitter_check_empty_sequence(emitter) {
- emitter.state = yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE
- } else {
- emitter.state = yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE
- }
- return true
-}
-
-// Expect MAPPING-START.
-func yaml_emitter_emit_mapping_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if emitter.flow_level > 0 || emitter.canonical || event.mapping_style() == yaml_FLOW_MAPPING_STYLE ||
- yaml_emitter_check_empty_mapping(emitter) {
- emitter.state = yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE
- } else {
- emitter.state = yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE
- }
- return true
-}
-
-// Check if the document content is an empty scalar.
-func yaml_emitter_check_empty_document(emitter *yaml_emitter_t) bool {
- return false // [Go] Huh?
-}
-
-// Check if the next events represent an empty sequence.
-func yaml_emitter_check_empty_sequence(emitter *yaml_emitter_t) bool {
- if len(emitter.events)-emitter.events_head < 2 {
- return false
- }
- return emitter.events[emitter.events_head].typ == yaml_SEQUENCE_START_EVENT &&
- emitter.events[emitter.events_head+1].typ == yaml_SEQUENCE_END_EVENT
-}
-
-// Check if the next events represent an empty mapping.
-func yaml_emitter_check_empty_mapping(emitter *yaml_emitter_t) bool {
- if len(emitter.events)-emitter.events_head < 2 {
- return false
- }
- return emitter.events[emitter.events_head].typ == yaml_MAPPING_START_EVENT &&
- emitter.events[emitter.events_head+1].typ == yaml_MAPPING_END_EVENT
-}
-
-// Check if the next node can be expressed as a simple key.
-func yaml_emitter_check_simple_key(emitter *yaml_emitter_t) bool {
- length := 0
- switch emitter.events[emitter.events_head].typ {
- case yaml_ALIAS_EVENT:
- length += len(emitter.anchor_data.anchor)
- case yaml_SCALAR_EVENT:
- if emitter.scalar_data.multiline {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix) +
- len(emitter.scalar_data.value)
- case yaml_SEQUENCE_START_EVENT:
- if !yaml_emitter_check_empty_sequence(emitter) {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix)
- case yaml_MAPPING_START_EVENT:
- if !yaml_emitter_check_empty_mapping(emitter) {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix)
- default:
- return false
- }
- return length <= 128
-}
-
-// Determine an acceptable scalar style.
-func yaml_emitter_select_scalar_style(emitter *yaml_emitter_t, event *yaml_event_t) bool {
-
- no_tag := len(emitter.tag_data.handle) == 0 && len(emitter.tag_data.suffix) == 0
- if no_tag && !event.implicit && !event.quoted_implicit {
- return yaml_emitter_set_emitter_error(emitter, "neither tag nor implicit flags are specified")
- }
-
- style := event.scalar_style()
- if style == yaml_ANY_SCALAR_STYLE {
- style = yaml_PLAIN_SCALAR_STYLE
- }
- if emitter.canonical {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- if emitter.simple_key_context && emitter.scalar_data.multiline {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
-
- if style == yaml_PLAIN_SCALAR_STYLE {
- if emitter.flow_level > 0 && !emitter.scalar_data.flow_plain_allowed ||
- emitter.flow_level == 0 && !emitter.scalar_data.block_plain_allowed {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- if len(emitter.scalar_data.value) == 0 && (emitter.flow_level > 0 || emitter.simple_key_context) {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- if no_tag && !event.implicit {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- }
- if style == yaml_SINGLE_QUOTED_SCALAR_STYLE {
- if !emitter.scalar_data.single_quoted_allowed {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- }
- if style == yaml_LITERAL_SCALAR_STYLE || style == yaml_FOLDED_SCALAR_STYLE {
- if !emitter.scalar_data.block_allowed || emitter.flow_level > 0 || emitter.simple_key_context {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- }
-
- if no_tag && !event.quoted_implicit && style != yaml_PLAIN_SCALAR_STYLE {
- emitter.tag_data.handle = []byte{'!'}
- }
- emitter.scalar_data.style = style
- return true
-}
-
-// Write an anchor.
-func yaml_emitter_process_anchor(emitter *yaml_emitter_t) bool {
- if emitter.anchor_data.anchor == nil {
- return true
- }
- c := []byte{'&'}
- if emitter.anchor_data.alias {
- c[0] = '*'
- }
- if !yaml_emitter_write_indicator(emitter, c, true, false, false) {
- return false
- }
- return yaml_emitter_write_anchor(emitter, emitter.anchor_data.anchor)
-}
-
-// Write a tag.
-func yaml_emitter_process_tag(emitter *yaml_emitter_t) bool {
- if len(emitter.tag_data.handle) == 0 && len(emitter.tag_data.suffix) == 0 {
- return true
- }
- if len(emitter.tag_data.handle) > 0 {
- if !yaml_emitter_write_tag_handle(emitter, emitter.tag_data.handle) {
- return false
- }
- if len(emitter.tag_data.suffix) > 0 {
- if !yaml_emitter_write_tag_content(emitter, emitter.tag_data.suffix, false) {
- return false
- }
- }
- } else {
- // [Go] Allocate these slices elsewhere.
- if !yaml_emitter_write_indicator(emitter, []byte("!<"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_tag_content(emitter, emitter.tag_data.suffix, false) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'>'}, false, false, false) {
- return false
- }
- }
- return true
-}
-
-// Write a scalar.
-func yaml_emitter_process_scalar(emitter *yaml_emitter_t) bool {
- switch emitter.scalar_data.style {
- case yaml_PLAIN_SCALAR_STYLE:
- return yaml_emitter_write_plain_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_SINGLE_QUOTED_SCALAR_STYLE:
- return yaml_emitter_write_single_quoted_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_DOUBLE_QUOTED_SCALAR_STYLE:
- return yaml_emitter_write_double_quoted_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_LITERAL_SCALAR_STYLE:
- return yaml_emitter_write_literal_scalar(emitter, emitter.scalar_data.value)
-
- case yaml_FOLDED_SCALAR_STYLE:
- return yaml_emitter_write_folded_scalar(emitter, emitter.scalar_data.value)
- }
- panic("unknown scalar style")
-}
-
-// Write a head comment.
-func yaml_emitter_process_head_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.tail_comment) {
- return false
- }
- emitter.tail_comment = emitter.tail_comment[:0]
- emitter.foot_indent = emitter.indent
- if emitter.foot_indent < 0 {
- emitter.foot_indent = 0
- }
- }
-
- if len(emitter.head_comment) == 0 {
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.head_comment) {
- return false
- }
- emitter.head_comment = emitter.head_comment[:0]
- return true
-}
-
-// Write an line comment.
-func yaml_emitter_process_line_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.line_comment) == 0 {
- return true
- }
- if !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !yaml_emitter_write_comment(emitter, emitter.line_comment) {
- return false
- }
- emitter.line_comment = emitter.line_comment[:0]
- return true
-}
-
-// Write a foot comment.
-func yaml_emitter_process_foot_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.foot_comment) == 0 {
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.foot_comment) {
- return false
- }
- emitter.foot_comment = emitter.foot_comment[:0]
- emitter.foot_indent = emitter.indent
- if emitter.foot_indent < 0 {
- emitter.foot_indent = 0
- }
- return true
-}
-
-// Check if a %YAML directive is valid.
-func yaml_emitter_analyze_version_directive(emitter *yaml_emitter_t, version_directive *yaml_version_directive_t) bool {
- if version_directive.major != 1 || version_directive.minor != 1 {
- return yaml_emitter_set_emitter_error(emitter, "incompatible %YAML directive")
- }
- return true
-}
-
-// Check if a %TAG directive is valid.
-func yaml_emitter_analyze_tag_directive(emitter *yaml_emitter_t, tag_directive *yaml_tag_directive_t) bool {
- handle := tag_directive.handle
- prefix := tag_directive.prefix
- if len(handle) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must not be empty")
- }
- if handle[0] != '!' {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must start with '!'")
- }
- if handle[len(handle)-1] != '!' {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must end with '!'")
- }
- for i := 1; i < len(handle)-1; i += width(handle[i]) {
- if !is_alpha(handle, i) {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must contain alphanumerical characters only")
- }
- }
- if len(prefix) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag prefix must not be empty")
- }
- return true
-}
-
-// Check if an anchor is valid.
-func yaml_emitter_analyze_anchor(emitter *yaml_emitter_t, anchor []byte, alias bool) bool {
- if len(anchor) == 0 {
- problem := "anchor value must not be empty"
- if alias {
- problem = "alias value must not be empty"
- }
- return yaml_emitter_set_emitter_error(emitter, problem)
- }
- for i := 0; i < len(anchor); i += width(anchor[i]) {
- if !is_alpha(anchor, i) {
- problem := "anchor value must contain alphanumerical characters only"
- if alias {
- problem = "alias value must contain alphanumerical characters only"
- }
- return yaml_emitter_set_emitter_error(emitter, problem)
- }
- }
- emitter.anchor_data.anchor = anchor
- emitter.anchor_data.alias = alias
- return true
-}
-
-// Check if a tag is valid.
-func yaml_emitter_analyze_tag(emitter *yaml_emitter_t, tag []byte) bool {
- if len(tag) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag value must not be empty")
- }
- for i := 0; i < len(emitter.tag_directives); i++ {
- tag_directive := &emitter.tag_directives[i]
- if bytes.HasPrefix(tag, tag_directive.prefix) {
- emitter.tag_data.handle = tag_directive.handle
- emitter.tag_data.suffix = tag[len(tag_directive.prefix):]
- return true
- }
- }
- emitter.tag_data.suffix = tag
- return true
-}
-
-// Check if a scalar is valid.
-func yaml_emitter_analyze_scalar(emitter *yaml_emitter_t, value []byte) bool {
- var (
- block_indicators = false
- flow_indicators = false
- line_breaks = false
- special_characters = false
- tab_characters = false
-
- leading_space = false
- leading_break = false
- trailing_space = false
- trailing_break = false
- break_space = false
- space_break = false
-
- preceded_by_whitespace = false
- followed_by_whitespace = false
- previous_space = false
- previous_break = false
- )
-
- emitter.scalar_data.value = value
-
- if len(value) == 0 {
- emitter.scalar_data.multiline = false
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = true
- emitter.scalar_data.single_quoted_allowed = true
- emitter.scalar_data.block_allowed = false
- return true
- }
-
- if len(value) >= 3 && ((value[0] == '-' && value[1] == '-' && value[2] == '-') || (value[0] == '.' && value[1] == '.' && value[2] == '.')) {
- block_indicators = true
- flow_indicators = true
- }
-
- preceded_by_whitespace = true
- for i, w := 0, 0; i < len(value); i += w {
- w = width(value[i])
- followed_by_whitespace = i+w >= len(value) || is_blank(value, i+w)
-
- if i == 0 {
- switch value[i] {
- case '#', ',', '[', ']', '{', '}', '&', '*', '!', '|', '>', '\'', '"', '%', '@', '`':
- flow_indicators = true
- block_indicators = true
- case '?', ':':
- flow_indicators = true
- if followed_by_whitespace {
- block_indicators = true
- }
- case '-':
- if followed_by_whitespace {
- flow_indicators = true
- block_indicators = true
- }
- }
- } else {
- switch value[i] {
- case ',', '?', '[', ']', '{', '}':
- flow_indicators = true
- case ':':
- flow_indicators = true
- if followed_by_whitespace {
- block_indicators = true
- }
- case '#':
- if preceded_by_whitespace {
- flow_indicators = true
- block_indicators = true
- }
- }
- }
-
- if value[i] == '\t' {
- tab_characters = true
- } else if !is_printable(value, i) || !is_ascii(value, i) && !emitter.unicode {
- special_characters = true
- }
- if is_space(value, i) {
- if i == 0 {
- leading_space = true
- }
- if i+width(value[i]) == len(value) {
- trailing_space = true
- }
- if previous_break {
- break_space = true
- }
- previous_space = true
- previous_break = false
- } else if is_break(value, i) {
- line_breaks = true
- if i == 0 {
- leading_break = true
- }
- if i+width(value[i]) == len(value) {
- trailing_break = true
- }
- if previous_space {
- space_break = true
- }
- previous_space = false
- previous_break = true
- } else {
- previous_space = false
- previous_break = false
- }
-
- // [Go]: Why 'z'? Couldn't be the end of the string as that's the loop condition.
- preceded_by_whitespace = is_blankz(value, i)
- }
-
- emitter.scalar_data.multiline = line_breaks
- emitter.scalar_data.flow_plain_allowed = true
- emitter.scalar_data.block_plain_allowed = true
- emitter.scalar_data.single_quoted_allowed = true
- emitter.scalar_data.block_allowed = true
-
- if leading_space || leading_break || trailing_space || trailing_break {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- }
- if trailing_space {
- emitter.scalar_data.block_allowed = false
- }
- if break_space {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- emitter.scalar_data.single_quoted_allowed = false
- }
- if space_break || tab_characters || special_characters {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- emitter.scalar_data.single_quoted_allowed = false
- }
- if space_break || special_characters {
- emitter.scalar_data.block_allowed = false
- }
- if line_breaks {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- }
- if flow_indicators {
- emitter.scalar_data.flow_plain_allowed = false
- }
- if block_indicators {
- emitter.scalar_data.block_plain_allowed = false
- }
- return true
-}
-
-// Check if the event data is valid.
-func yaml_emitter_analyze_event(emitter *yaml_emitter_t, event *yaml_event_t) bool {
-
- emitter.anchor_data.anchor = nil
- emitter.tag_data.handle = nil
- emitter.tag_data.suffix = nil
- emitter.scalar_data.value = nil
-
- if len(event.head_comment) > 0 {
- emitter.head_comment = event.head_comment
- }
- if len(event.line_comment) > 0 {
- emitter.line_comment = event.line_comment
- }
- if len(event.foot_comment) > 0 {
- emitter.foot_comment = event.foot_comment
- }
- if len(event.tail_comment) > 0 {
- emitter.tail_comment = event.tail_comment
- }
-
- switch event.typ {
- case yaml_ALIAS_EVENT:
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, true) {
- return false
- }
-
- case yaml_SCALAR_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || (!event.implicit && !event.quoted_implicit)) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
- if !yaml_emitter_analyze_scalar(emitter, event.value) {
- return false
- }
-
- case yaml_SEQUENCE_START_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || !event.implicit) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
-
- case yaml_MAPPING_START_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || !event.implicit) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
- }
- return true
-}
-
-// Write the BOM character.
-func yaml_emitter_write_bom(emitter *yaml_emitter_t) bool {
- if !flush(emitter) {
- return false
- }
- pos := emitter.buffer_pos
- emitter.buffer[pos+0] = '\xEF'
- emitter.buffer[pos+1] = '\xBB'
- emitter.buffer[pos+2] = '\xBF'
- emitter.buffer_pos += 3
- return true
-}
-
-func yaml_emitter_write_indent(emitter *yaml_emitter_t) bool {
- indent := emitter.indent
- if indent < 0 {
- indent = 0
- }
- if !emitter.indention || emitter.column > indent || (emitter.column == indent && !emitter.whitespace) {
- if !put_break(emitter) {
- return false
- }
- }
- if emitter.foot_indent == indent {
- if !put_break(emitter) {
- return false
- }
- }
- for emitter.column < indent {
- if !put(emitter, ' ') {
- return false
- }
- }
- emitter.whitespace = true
- //emitter.indention = true
- emitter.space_above = false
- emitter.foot_indent = -1
- return true
-}
-
-func yaml_emitter_write_indicator(emitter *yaml_emitter_t, indicator []byte, need_whitespace, is_whitespace, is_indention bool) bool {
- if need_whitespace && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !write_all(emitter, indicator) {
- return false
- }
- emitter.whitespace = is_whitespace
- emitter.indention = (emitter.indention && is_indention)
- emitter.open_ended = false
- return true
-}
-
-func yaml_emitter_write_anchor(emitter *yaml_emitter_t, value []byte) bool {
- if !write_all(emitter, value) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_tag_handle(emitter *yaml_emitter_t, value []byte) bool {
- if !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !write_all(emitter, value) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_tag_content(emitter *yaml_emitter_t, value []byte, need_whitespace bool) bool {
- if need_whitespace && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- for i := 0; i < len(value); {
- var must_write bool
- switch value[i] {
- case ';', '/', '?', ':', '@', '&', '=', '+', '$', ',', '_', '.', '~', '*', '\'', '(', ')', '[', ']':
- must_write = true
- default:
- must_write = is_alpha(value, i)
- }
- if must_write {
- if !write(emitter, value, &i) {
- return false
- }
- } else {
- w := width(value[i])
- for k := 0; k < w; k++ {
- octet := value[i]
- i++
- if !put(emitter, '%') {
- return false
- }
-
- c := octet >> 4
- if c < 10 {
- c += '0'
- } else {
- c += 'A' - 10
- }
- if !put(emitter, c) {
- return false
- }
-
- c = octet & 0x0f
- if c < 10 {
- c += '0'
- } else {
- c += 'A' - 10
- }
- if !put(emitter, c) {
- return false
- }
- }
- }
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_plain_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
- if len(value) > 0 && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
-
- spaces := false
- breaks := false
- for i := 0; i < len(value); {
- if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && !is_space(value, i+1) {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- spaces = true
- } else if is_break(value, i) {
- if !breaks && value[i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- spaces = false
- breaks = false
- }
- }
-
- if len(value) > 0 {
- emitter.whitespace = false
- }
- emitter.indention = false
- if emitter.root_context {
- emitter.open_ended = true
- }
-
- return true
-}
-
-func yaml_emitter_write_single_quoted_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
-
- if !yaml_emitter_write_indicator(emitter, []byte{'\''}, true, false, false) {
- return false
- }
-
- spaces := false
- breaks := false
- for i := 0; i < len(value); {
- if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && i > 0 && i < len(value)-1 && !is_space(value, i+1) {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- spaces = true
- } else if is_break(value, i) {
- if !breaks && value[i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if value[i] == '\'' {
- if !put(emitter, '\'') {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- spaces = false
- breaks = false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'\''}, false, false, false) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_double_quoted_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
- spaces := false
- if !yaml_emitter_write_indicator(emitter, []byte{'"'}, true, false, false) {
- return false
- }
-
- for i := 0; i < len(value); {
- if !is_printable(value, i) || (!emitter.unicode && !is_ascii(value, i)) ||
- is_bom(value, i) || is_break(value, i) ||
- value[i] == '"' || value[i] == '\\' {
-
- octet := value[i]
-
- var w int
- var v rune
- switch {
- case octet&0x80 == 0x00:
- w, v = 1, rune(octet&0x7F)
- case octet&0xE0 == 0xC0:
- w, v = 2, rune(octet&0x1F)
- case octet&0xF0 == 0xE0:
- w, v = 3, rune(octet&0x0F)
- case octet&0xF8 == 0xF0:
- w, v = 4, rune(octet&0x07)
- }
- for k := 1; k < w; k++ {
- octet = value[i+k]
- v = (v << 6) + (rune(octet) & 0x3F)
- }
- i += w
-
- if !put(emitter, '\\') {
- return false
- }
-
- var ok bool
- switch v {
- case 0x00:
- ok = put(emitter, '0')
- case 0x07:
- ok = put(emitter, 'a')
- case 0x08:
- ok = put(emitter, 'b')
- case 0x09:
- ok = put(emitter, 't')
- case 0x0A:
- ok = put(emitter, 'n')
- case 0x0b:
- ok = put(emitter, 'v')
- case 0x0c:
- ok = put(emitter, 'f')
- case 0x0d:
- ok = put(emitter, 'r')
- case 0x1b:
- ok = put(emitter, 'e')
- case 0x22:
- ok = put(emitter, '"')
- case 0x5c:
- ok = put(emitter, '\\')
- case 0x85:
- ok = put(emitter, 'N')
- case 0xA0:
- ok = put(emitter, '_')
- case 0x2028:
- ok = put(emitter, 'L')
- case 0x2029:
- ok = put(emitter, 'P')
- default:
- if v <= 0xFF {
- ok = put(emitter, 'x')
- w = 2
- } else if v <= 0xFFFF {
- ok = put(emitter, 'u')
- w = 4
- } else {
- ok = put(emitter, 'U')
- w = 8
- }
- for k := (w - 1) * 4; ok && k >= 0; k -= 4 {
- digit := byte((v >> uint(k)) & 0x0F)
- if digit < 10 {
- ok = put(emitter, digit+'0')
- } else {
- ok = put(emitter, digit+'A'-10)
- }
- }
- }
- if !ok {
- return false
- }
- spaces = false
- } else if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && i > 0 && i < len(value)-1 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if is_space(value, i+1) {
- if !put(emitter, '\\') {
- return false
- }
- }
- i += width(value[i])
- } else if !write(emitter, value, &i) {
- return false
- }
- spaces = true
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- spaces = false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'"'}, false, false, false) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_block_scalar_hints(emitter *yaml_emitter_t, value []byte) bool {
- if is_space(value, 0) || is_break(value, 0) {
- indent_hint := []byte{'0' + byte(emitter.best_indent)}
- if !yaml_emitter_write_indicator(emitter, indent_hint, false, false, false) {
- return false
- }
- }
-
- emitter.open_ended = false
-
- var chomp_hint [1]byte
- if len(value) == 0 {
- chomp_hint[0] = '-'
- } else {
- i := len(value) - 1
- for value[i]&0xC0 == 0x80 {
- i--
- }
- if !is_break(value, i) {
- chomp_hint[0] = '-'
- } else if i == 0 {
- chomp_hint[0] = '+'
- emitter.open_ended = true
- } else {
- i--
- for value[i]&0xC0 == 0x80 {
- i--
- }
- if is_break(value, i) {
- chomp_hint[0] = '+'
- emitter.open_ended = true
- }
- }
- }
- if chomp_hint[0] != 0 {
- if !yaml_emitter_write_indicator(emitter, chomp_hint[:], false, false, false) {
- return false
- }
- }
- return true
-}
-
-func yaml_emitter_write_literal_scalar(emitter *yaml_emitter_t, value []byte) bool {
- if !yaml_emitter_write_indicator(emitter, []byte{'|'}, true, false, false) {
- return false
- }
- if !yaml_emitter_write_block_scalar_hints(emitter, value) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- //emitter.indention = true
- emitter.whitespace = true
- breaks := true
- for i := 0; i < len(value); {
- if is_break(value, i) {
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- breaks = false
- }
- }
-
- return true
-}
-
-func yaml_emitter_write_folded_scalar(emitter *yaml_emitter_t, value []byte) bool {
- if !yaml_emitter_write_indicator(emitter, []byte{'>'}, true, false, false) {
- return false
- }
- if !yaml_emitter_write_block_scalar_hints(emitter, value) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
-
- //emitter.indention = true
- emitter.whitespace = true
-
- breaks := true
- leading_spaces := true
- for i := 0; i < len(value); {
- if is_break(value, i) {
- if !breaks && !leading_spaces && value[i] == '\n' {
- k := 0
- for is_break(value, k) {
- k += width(value[k])
- }
- if !is_blankz(value, k) {
- if !put_break(emitter) {
- return false
- }
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- leading_spaces = is_blank(value, i)
- }
- if !breaks && is_space(value, i) && !is_space(value, i+1) && emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- emitter.indention = false
- breaks = false
- }
- }
- return true
-}
-
-func yaml_emitter_write_comment(emitter *yaml_emitter_t, comment []byte) bool {
- breaks := false
- pound := false
- for i := 0; i < len(comment); {
- if is_break(comment, i) {
- if !write_break(emitter, comment, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- pound = false
- } else {
- if breaks && !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !pound {
- if comment[i] != '#' && (!put(emitter, '#') || !put(emitter, ' ')) {
- return false
- }
- pound = true
- }
- if !write(emitter, comment, &i) {
- return false
- }
- emitter.indention = false
- breaks = false
- }
- }
- if !breaks && !put_break(emitter) {
- return false
- }
-
- emitter.whitespace = true
- //emitter.indention = true
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/encode.go b/sesh/vendor/gopkg.in/yaml.v3/encode.go
deleted file mode 100644
index de9e72a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/encode.go
+++ /dev/null
@@ -1,577 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding"
- "fmt"
- "io"
- "reflect"
- "regexp"
- "sort"
- "strconv"
- "strings"
- "time"
- "unicode/utf8"
-)
-
-type encoder struct {
- emitter yaml_emitter_t
- event yaml_event_t
- out []byte
- flow bool
- indent int
- doneInit bool
-}
-
-func newEncoder() *encoder {
- e := &encoder{}
- yaml_emitter_initialize(&e.emitter)
- yaml_emitter_set_output_string(&e.emitter, &e.out)
- yaml_emitter_set_unicode(&e.emitter, true)
- return e
-}
-
-func newEncoderWithWriter(w io.Writer) *encoder {
- e := &encoder{}
- yaml_emitter_initialize(&e.emitter)
- yaml_emitter_set_output_writer(&e.emitter, w)
- yaml_emitter_set_unicode(&e.emitter, true)
- return e
-}
-
-func (e *encoder) init() {
- if e.doneInit {
- return
- }
- if e.indent == 0 {
- e.indent = 4
- }
- e.emitter.best_indent = e.indent
- yaml_stream_start_event_initialize(&e.event, yaml_UTF8_ENCODING)
- e.emit()
- e.doneInit = true
-}
-
-func (e *encoder) finish() {
- e.emitter.open_ended = false
- yaml_stream_end_event_initialize(&e.event)
- e.emit()
-}
-
-func (e *encoder) destroy() {
- yaml_emitter_delete(&e.emitter)
-}
-
-func (e *encoder) emit() {
- // This will internally delete the e.event value.
- e.must(yaml_emitter_emit(&e.emitter, &e.event))
-}
-
-func (e *encoder) must(ok bool) {
- if !ok {
- msg := e.emitter.problem
- if msg == "" {
- msg = "unknown problem generating YAML content"
- }
- failf("%s", msg)
- }
-}
-
-func (e *encoder) marshalDoc(tag string, in reflect.Value) {
- e.init()
- var node *Node
- if in.IsValid() {
- node, _ = in.Interface().(*Node)
- }
- if node != nil && node.Kind == DocumentNode {
- e.nodev(in)
- } else {
- yaml_document_start_event_initialize(&e.event, nil, nil, true)
- e.emit()
- e.marshal(tag, in)
- yaml_document_end_event_initialize(&e.event, true)
- e.emit()
- }
-}
-
-func (e *encoder) marshal(tag string, in reflect.Value) {
- tag = shortTag(tag)
- if !in.IsValid() || in.Kind() == reflect.Ptr && in.IsNil() {
- e.nilv()
- return
- }
- iface := in.Interface()
- switch value := iface.(type) {
- case *Node:
- e.nodev(in)
- return
- case Node:
- if !in.CanAddr() {
- var n = reflect.New(in.Type()).Elem()
- n.Set(in)
- in = n
- }
- e.nodev(in.Addr())
- return
- case time.Time:
- e.timev(tag, in)
- return
- case *time.Time:
- e.timev(tag, in.Elem())
- return
- case time.Duration:
- e.stringv(tag, reflect.ValueOf(value.String()))
- return
- case Marshaler:
- v, err := value.MarshalYAML()
- if err != nil {
- fail(err)
- }
- if v == nil {
- e.nilv()
- return
- }
- e.marshal(tag, reflect.ValueOf(v))
- return
- case encoding.TextMarshaler:
- text, err := value.MarshalText()
- if err != nil {
- fail(err)
- }
- in = reflect.ValueOf(string(text))
- case nil:
- e.nilv()
- return
- }
- switch in.Kind() {
- case reflect.Interface:
- e.marshal(tag, in.Elem())
- case reflect.Map:
- e.mapv(tag, in)
- case reflect.Ptr:
- e.marshal(tag, in.Elem())
- case reflect.Struct:
- e.structv(tag, in)
- case reflect.Slice, reflect.Array:
- e.slicev(tag, in)
- case reflect.String:
- e.stringv(tag, in)
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- e.intv(tag, in)
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- e.uintv(tag, in)
- case reflect.Float32, reflect.Float64:
- e.floatv(tag, in)
- case reflect.Bool:
- e.boolv(tag, in)
- default:
- panic("cannot marshal type: " + in.Type().String())
- }
-}
-
-func (e *encoder) mapv(tag string, in reflect.Value) {
- e.mappingv(tag, func() {
- keys := keyList(in.MapKeys())
- sort.Sort(keys)
- for _, k := range keys {
- e.marshal("", k)
- e.marshal("", in.MapIndex(k))
- }
- })
-}
-
-func (e *encoder) fieldByIndex(v reflect.Value, index []int) (field reflect.Value) {
- for _, num := range index {
- for {
- if v.Kind() == reflect.Ptr {
- if v.IsNil() {
- return reflect.Value{}
- }
- v = v.Elem()
- continue
- }
- break
- }
- v = v.Field(num)
- }
- return v
-}
-
-func (e *encoder) structv(tag string, in reflect.Value) {
- sinfo, err := getStructInfo(in.Type())
- if err != nil {
- panic(err)
- }
- e.mappingv(tag, func() {
- for _, info := range sinfo.FieldsList {
- var value reflect.Value
- if info.Inline == nil {
- value = in.Field(info.Num)
- } else {
- value = e.fieldByIndex(in, info.Inline)
- if !value.IsValid() {
- continue
- }
- }
- if info.OmitEmpty && isZero(value) {
- continue
- }
- e.marshal("", reflect.ValueOf(info.Key))
- e.flow = info.Flow
- e.marshal("", value)
- }
- if sinfo.InlineMap >= 0 {
- m := in.Field(sinfo.InlineMap)
- if m.Len() > 0 {
- e.flow = false
- keys := keyList(m.MapKeys())
- sort.Sort(keys)
- for _, k := range keys {
- if _, found := sinfo.FieldsMap[k.String()]; found {
- panic(fmt.Sprintf("cannot have key %q in inlined map: conflicts with struct field", k.String()))
- }
- e.marshal("", k)
- e.flow = false
- e.marshal("", m.MapIndex(k))
- }
- }
- }
- })
-}
-
-func (e *encoder) mappingv(tag string, f func()) {
- implicit := tag == ""
- style := yaml_BLOCK_MAPPING_STYLE
- if e.flow {
- e.flow = false
- style = yaml_FLOW_MAPPING_STYLE
- }
- yaml_mapping_start_event_initialize(&e.event, nil, []byte(tag), implicit, style)
- e.emit()
- f()
- yaml_mapping_end_event_initialize(&e.event)
- e.emit()
-}
-
-func (e *encoder) slicev(tag string, in reflect.Value) {
- implicit := tag == ""
- style := yaml_BLOCK_SEQUENCE_STYLE
- if e.flow {
- e.flow = false
- style = yaml_FLOW_SEQUENCE_STYLE
- }
- e.must(yaml_sequence_start_event_initialize(&e.event, nil, []byte(tag), implicit, style))
- e.emit()
- n := in.Len()
- for i := 0; i < n; i++ {
- e.marshal("", in.Index(i))
- }
- e.must(yaml_sequence_end_event_initialize(&e.event))
- e.emit()
-}
-
-// isBase60 returns whether s is in base 60 notation as defined in YAML 1.1.
-//
-// The base 60 float notation in YAML 1.1 is a terrible idea and is unsupported
-// in YAML 1.2 and by this package, but these should be marshalled quoted for
-// the time being for compatibility with other parsers.
-func isBase60Float(s string) (result bool) {
- // Fast path.
- if s == "" {
- return false
- }
- c := s[0]
- if !(c == '+' || c == '-' || c >= '0' && c <= '9') || strings.IndexByte(s, ':') < 0 {
- return false
- }
- // Do the full match.
- return base60float.MatchString(s)
-}
-
-// From http://yaml.org/type/float.html, except the regular expression there
-// is bogus. In practice parsers do not enforce the "\.[0-9_]*" suffix.
-var base60float = regexp.MustCompile(`^[-+]?[0-9][0-9_]*(?::[0-5]?[0-9])+(?:\.[0-9_]*)?$`)
-
-// isOldBool returns whether s is bool notation as defined in YAML 1.1.
-//
-// We continue to force strings that YAML 1.1 would interpret as booleans to be
-// rendered as quotes strings so that the marshalled output valid for YAML 1.1
-// parsing.
-func isOldBool(s string) (result bool) {
- switch s {
- case "y", "Y", "yes", "Yes", "YES", "on", "On", "ON",
- "n", "N", "no", "No", "NO", "off", "Off", "OFF":
- return true
- default:
- return false
- }
-}
-
-func (e *encoder) stringv(tag string, in reflect.Value) {
- var style yaml_scalar_style_t
- s := in.String()
- canUsePlain := true
- switch {
- case !utf8.ValidString(s):
- if tag == binaryTag {
- failf("explicitly tagged !!binary data must be base64-encoded")
- }
- if tag != "" {
- failf("cannot marshal invalid UTF-8 data as %s", shortTag(tag))
- }
- // It can't be encoded directly as YAML so use a binary tag
- // and encode it as base64.
- tag = binaryTag
- s = encodeBase64(s)
- case tag == "":
- // Check to see if it would resolve to a specific
- // tag when encoded unquoted. If it doesn't,
- // there's no need to quote it.
- rtag, _ := resolve("", s)
- canUsePlain = rtag == strTag && !(isBase60Float(s) || isOldBool(s))
- }
- // Note: it's possible for user code to emit invalid YAML
- // if they explicitly specify a tag and a string containing
- // text that's incompatible with that tag.
- switch {
- case strings.Contains(s, "\n"):
- if e.flow {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- } else {
- style = yaml_LITERAL_SCALAR_STYLE
- }
- case canUsePlain:
- style = yaml_PLAIN_SCALAR_STYLE
- default:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- e.emitScalar(s, "", tag, style, nil, nil, nil, nil)
-}
-
-func (e *encoder) boolv(tag string, in reflect.Value) {
- var s string
- if in.Bool() {
- s = "true"
- } else {
- s = "false"
- }
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) intv(tag string, in reflect.Value) {
- s := strconv.FormatInt(in.Int(), 10)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) uintv(tag string, in reflect.Value) {
- s := strconv.FormatUint(in.Uint(), 10)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) timev(tag string, in reflect.Value) {
- t := in.Interface().(time.Time)
- s := t.Format(time.RFC3339Nano)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) floatv(tag string, in reflect.Value) {
- // Issue #352: When formatting, use the precision of the underlying value
- precision := 64
- if in.Kind() == reflect.Float32 {
- precision = 32
- }
-
- s := strconv.FormatFloat(in.Float(), 'g', -1, precision)
- switch s {
- case "+Inf":
- s = ".inf"
- case "-Inf":
- s = "-.inf"
- case "NaN":
- s = ".nan"
- }
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) nilv() {
- e.emitScalar("null", "", "", yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) emitScalar(value, anchor, tag string, style yaml_scalar_style_t, head, line, foot, tail []byte) {
- // TODO Kill this function. Replace all initialize calls by their underlining Go literals.
- implicit := tag == ""
- if !implicit {
- tag = longTag(tag)
- }
- e.must(yaml_scalar_event_initialize(&e.event, []byte(anchor), []byte(tag), []byte(value), implicit, implicit, style))
- e.event.head_comment = head
- e.event.line_comment = line
- e.event.foot_comment = foot
- e.event.tail_comment = tail
- e.emit()
-}
-
-func (e *encoder) nodev(in reflect.Value) {
- e.node(in.Interface().(*Node), "")
-}
-
-func (e *encoder) node(node *Node, tail string) {
- // Zero nodes behave as nil.
- if node.Kind == 0 && node.IsZero() {
- e.nilv()
- return
- }
-
- // If the tag was not explicitly requested, and dropping it won't change the
- // implicit tag of the value, don't include it in the presentation.
- var tag = node.Tag
- var stag = shortTag(tag)
- var forceQuoting bool
- if tag != "" && node.Style&TaggedStyle == 0 {
- if node.Kind == ScalarNode {
- if stag == strTag && node.Style&(SingleQuotedStyle|DoubleQuotedStyle|LiteralStyle|FoldedStyle) != 0 {
- tag = ""
- } else {
- rtag, _ := resolve("", node.Value)
- if rtag == stag {
- tag = ""
- } else if stag == strTag {
- tag = ""
- forceQuoting = true
- }
- }
- } else {
- var rtag string
- switch node.Kind {
- case MappingNode:
- rtag = mapTag
- case SequenceNode:
- rtag = seqTag
- }
- if rtag == stag {
- tag = ""
- }
- }
- }
-
- switch node.Kind {
- case DocumentNode:
- yaml_document_start_event_initialize(&e.event, nil, nil, true)
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
- for _, node := range node.Content {
- e.node(node, "")
- }
- yaml_document_end_event_initialize(&e.event, true)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case SequenceNode:
- style := yaml_BLOCK_SEQUENCE_STYLE
- if node.Style&FlowStyle != 0 {
- style = yaml_FLOW_SEQUENCE_STYLE
- }
- e.must(yaml_sequence_start_event_initialize(&e.event, []byte(node.Anchor), []byte(longTag(tag)), tag == "", style))
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
- for _, node := range node.Content {
- e.node(node, "")
- }
- e.must(yaml_sequence_end_event_initialize(&e.event))
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case MappingNode:
- style := yaml_BLOCK_MAPPING_STYLE
- if node.Style&FlowStyle != 0 {
- style = yaml_FLOW_MAPPING_STYLE
- }
- yaml_mapping_start_event_initialize(&e.event, []byte(node.Anchor), []byte(longTag(tag)), tag == "", style)
- e.event.tail_comment = []byte(tail)
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
-
- // The tail logic below moves the foot comment of prior keys to the following key,
- // since the value for each key may be a nested structure and the foot needs to be
- // processed only the entirety of the value is streamed. The last tail is processed
- // with the mapping end event.
- var tail string
- for i := 0; i+1 < len(node.Content); i += 2 {
- k := node.Content[i]
- foot := k.FootComment
- if foot != "" {
- kopy := *k
- kopy.FootComment = ""
- k = &kopy
- }
- e.node(k, tail)
- tail = foot
-
- v := node.Content[i+1]
- e.node(v, "")
- }
-
- yaml_mapping_end_event_initialize(&e.event)
- e.event.tail_comment = []byte(tail)
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case AliasNode:
- yaml_alias_event_initialize(&e.event, []byte(node.Value))
- e.event.head_comment = []byte(node.HeadComment)
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case ScalarNode:
- value := node.Value
- if !utf8.ValidString(value) {
- if stag == binaryTag {
- failf("explicitly tagged !!binary data must be base64-encoded")
- }
- if stag != "" {
- failf("cannot marshal invalid UTF-8 data as %s", stag)
- }
- // It can't be encoded directly as YAML so use a binary tag
- // and encode it as base64.
- tag = binaryTag
- value = encodeBase64(value)
- }
-
- style := yaml_PLAIN_SCALAR_STYLE
- switch {
- case node.Style&DoubleQuotedStyle != 0:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- case node.Style&SingleQuotedStyle != 0:
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- case node.Style&LiteralStyle != 0:
- style = yaml_LITERAL_SCALAR_STYLE
- case node.Style&FoldedStyle != 0:
- style = yaml_FOLDED_SCALAR_STYLE
- case strings.Contains(value, "\n"):
- style = yaml_LITERAL_SCALAR_STYLE
- case forceQuoting:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
-
- e.emitScalar(value, node.Anchor, tag, style, []byte(node.HeadComment), []byte(node.LineComment), []byte(node.FootComment), []byte(tail))
- default:
- failf("cannot encode node with unknown kind %d", node.Kind)
- }
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/parserc.go b/sesh/vendor/gopkg.in/yaml.v3/parserc.go
deleted file mode 100644
index 268558a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/parserc.go
+++ /dev/null
@@ -1,1258 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
-)
-
-// The parser implements the following grammar:
-//
-// stream ::= STREAM-START implicit_document? explicit_document* STREAM-END
-// implicit_document ::= block_node DOCUMENT-END*
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// block_node_or_indentless_sequence ::=
-// ALIAS
-// | properties (block_content | indentless_block_sequence)?
-// | block_content
-// | indentless_block_sequence
-// block_node ::= ALIAS
-// | properties block_content?
-// | block_content
-// flow_node ::= ALIAS
-// | properties flow_content?
-// | flow_content
-// properties ::= TAG ANCHOR? | ANCHOR TAG?
-// block_content ::= block_collection | flow_collection | SCALAR
-// flow_content ::= flow_collection | SCALAR
-// block_collection ::= block_sequence | block_mapping
-// flow_collection ::= flow_sequence | flow_mapping
-// block_sequence ::= BLOCK-SEQUENCE-START (BLOCK-ENTRY block_node?)* BLOCK-END
-// indentless_sequence ::= (BLOCK-ENTRY block_node?)+
-// block_mapping ::= BLOCK-MAPPING_START
-// ((KEY block_node_or_indentless_sequence?)?
-// (VALUE block_node_or_indentless_sequence?)?)*
-// BLOCK-END
-// flow_sequence ::= FLOW-SEQUENCE-START
-// (flow_sequence_entry FLOW-ENTRY)*
-// flow_sequence_entry?
-// FLOW-SEQUENCE-END
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// flow_mapping ::= FLOW-MAPPING-START
-// (flow_mapping_entry FLOW-ENTRY)*
-// flow_mapping_entry?
-// FLOW-MAPPING-END
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-
-// Peek the next token in the token queue.
-func peek_token(parser *yaml_parser_t) *yaml_token_t {
- if parser.token_available || yaml_parser_fetch_more_tokens(parser) {
- token := &parser.tokens[parser.tokens_head]
- yaml_parser_unfold_comments(parser, token)
- return token
- }
- return nil
-}
-
-// yaml_parser_unfold_comments walks through the comments queue and joins all
-// comments behind the position of the provided token into the respective
-// top-level comment slices in the parser.
-func yaml_parser_unfold_comments(parser *yaml_parser_t, token *yaml_token_t) {
- for parser.comments_head < len(parser.comments) && token.start_mark.index >= parser.comments[parser.comments_head].token_mark.index {
- comment := &parser.comments[parser.comments_head]
- if len(comment.head) > 0 {
- if token.typ == yaml_BLOCK_END_TOKEN {
- // No heads on ends, so keep comment.head for a follow up token.
- break
- }
- if len(parser.head_comment) > 0 {
- parser.head_comment = append(parser.head_comment, '\n')
- }
- parser.head_comment = append(parser.head_comment, comment.head...)
- }
- if len(comment.foot) > 0 {
- if len(parser.foot_comment) > 0 {
- parser.foot_comment = append(parser.foot_comment, '\n')
- }
- parser.foot_comment = append(parser.foot_comment, comment.foot...)
- }
- if len(comment.line) > 0 {
- if len(parser.line_comment) > 0 {
- parser.line_comment = append(parser.line_comment, '\n')
- }
- parser.line_comment = append(parser.line_comment, comment.line...)
- }
- *comment = yaml_comment_t{}
- parser.comments_head++
- }
-}
-
-// Remove the next token from the queue (must be called after peek_token).
-func skip_token(parser *yaml_parser_t) {
- parser.token_available = false
- parser.tokens_parsed++
- parser.stream_end_produced = parser.tokens[parser.tokens_head].typ == yaml_STREAM_END_TOKEN
- parser.tokens_head++
-}
-
-// Get the next event.
-func yaml_parser_parse(parser *yaml_parser_t, event *yaml_event_t) bool {
- // Erase the event object.
- *event = yaml_event_t{}
-
- // No events after the end of the stream or error.
- if parser.stream_end_produced || parser.error != yaml_NO_ERROR || parser.state == yaml_PARSE_END_STATE {
- return true
- }
-
- // Generate the next event.
- return yaml_parser_state_machine(parser, event)
-}
-
-// Set parser error.
-func yaml_parser_set_parser_error(parser *yaml_parser_t, problem string, problem_mark yaml_mark_t) bool {
- parser.error = yaml_PARSER_ERROR
- parser.problem = problem
- parser.problem_mark = problem_mark
- return false
-}
-
-func yaml_parser_set_parser_error_context(parser *yaml_parser_t, context string, context_mark yaml_mark_t, problem string, problem_mark yaml_mark_t) bool {
- parser.error = yaml_PARSER_ERROR
- parser.context = context
- parser.context_mark = context_mark
- parser.problem = problem
- parser.problem_mark = problem_mark
- return false
-}
-
-// State dispatcher.
-func yaml_parser_state_machine(parser *yaml_parser_t, event *yaml_event_t) bool {
- //trace("yaml_parser_state_machine", "state:", parser.state.String())
-
- switch parser.state {
- case yaml_PARSE_STREAM_START_STATE:
- return yaml_parser_parse_stream_start(parser, event)
-
- case yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE:
- return yaml_parser_parse_document_start(parser, event, true)
-
- case yaml_PARSE_DOCUMENT_START_STATE:
- return yaml_parser_parse_document_start(parser, event, false)
-
- case yaml_PARSE_DOCUMENT_CONTENT_STATE:
- return yaml_parser_parse_document_content(parser, event)
-
- case yaml_PARSE_DOCUMENT_END_STATE:
- return yaml_parser_parse_document_end(parser, event)
-
- case yaml_PARSE_BLOCK_NODE_STATE:
- return yaml_parser_parse_node(parser, event, true, false)
-
- case yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE:
- return yaml_parser_parse_node(parser, event, true, true)
-
- case yaml_PARSE_FLOW_NODE_STATE:
- return yaml_parser_parse_node(parser, event, false, false)
-
- case yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE:
- return yaml_parser_parse_block_sequence_entry(parser, event, true)
-
- case yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_block_sequence_entry(parser, event, false)
-
- case yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_indentless_sequence_entry(parser, event)
-
- case yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE:
- return yaml_parser_parse_block_mapping_key(parser, event, true)
-
- case yaml_PARSE_BLOCK_MAPPING_KEY_STATE:
- return yaml_parser_parse_block_mapping_key(parser, event, false)
-
- case yaml_PARSE_BLOCK_MAPPING_VALUE_STATE:
- return yaml_parser_parse_block_mapping_value(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE:
- return yaml_parser_parse_flow_sequence_entry(parser, event, true)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_flow_sequence_entry(parser, event, false)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_key(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_value(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_end(parser, event)
-
- case yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE:
- return yaml_parser_parse_flow_mapping_key(parser, event, true)
-
- case yaml_PARSE_FLOW_MAPPING_KEY_STATE:
- return yaml_parser_parse_flow_mapping_key(parser, event, false)
-
- case yaml_PARSE_FLOW_MAPPING_VALUE_STATE:
- return yaml_parser_parse_flow_mapping_value(parser, event, false)
-
- case yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE:
- return yaml_parser_parse_flow_mapping_value(parser, event, true)
-
- default:
- panic("invalid parser state")
- }
-}
-
-// Parse the production:
-// stream ::= STREAM-START implicit_document? explicit_document* STREAM-END
-// ************
-func yaml_parser_parse_stream_start(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_STREAM_START_TOKEN {
- return yaml_parser_set_parser_error(parser, "did not find expected ", token.start_mark)
- }
- parser.state = yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE
- *event = yaml_event_t{
- typ: yaml_STREAM_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- encoding: token.encoding,
- }
- skip_token(parser)
- return true
-}
-
-// Parse the productions:
-// implicit_document ::= block_node DOCUMENT-END*
-// *
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// *************************
-func yaml_parser_parse_document_start(parser *yaml_parser_t, event *yaml_event_t, implicit bool) bool {
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- // Parse extra document end indicators.
- if !implicit {
- for token.typ == yaml_DOCUMENT_END_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- }
-
- if implicit && token.typ != yaml_VERSION_DIRECTIVE_TOKEN &&
- token.typ != yaml_TAG_DIRECTIVE_TOKEN &&
- token.typ != yaml_DOCUMENT_START_TOKEN &&
- token.typ != yaml_STREAM_END_TOKEN {
- // Parse an implicit document.
- if !yaml_parser_process_directives(parser, nil, nil) {
- return false
- }
- parser.states = append(parser.states, yaml_PARSE_DOCUMENT_END_STATE)
- parser.state = yaml_PARSE_BLOCK_NODE_STATE
-
- var head_comment []byte
- if len(parser.head_comment) > 0 {
- // [Go] Scan the header comment backwards, and if an empty line is found, break
- // the header so the part before the last empty line goes into the
- // document header, while the bottom of it goes into a follow up event.
- for i := len(parser.head_comment) - 1; i > 0; i-- {
- if parser.head_comment[i] == '\n' {
- if i == len(parser.head_comment)-1 {
- head_comment = parser.head_comment[:i]
- parser.head_comment = parser.head_comment[i+1:]
- break
- } else if parser.head_comment[i-1] == '\n' {
- head_comment = parser.head_comment[:i-1]
- parser.head_comment = parser.head_comment[i+1:]
- break
- }
- }
- }
- }
-
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
-
- head_comment: head_comment,
- }
-
- } else if token.typ != yaml_STREAM_END_TOKEN {
- // Parse an explicit document.
- var version_directive *yaml_version_directive_t
- var tag_directives []yaml_tag_directive_t
- start_mark := token.start_mark
- if !yaml_parser_process_directives(parser, &version_directive, &tag_directives) {
- return false
- }
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_DOCUMENT_START_TOKEN {
- yaml_parser_set_parser_error(parser,
- "did not find expected ", token.start_mark)
- return false
- }
- parser.states = append(parser.states, yaml_PARSE_DOCUMENT_END_STATE)
- parser.state = yaml_PARSE_DOCUMENT_CONTENT_STATE
- end_mark := token.end_mark
-
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- version_directive: version_directive,
- tag_directives: tag_directives,
- implicit: false,
- }
- skip_token(parser)
-
- } else {
- // Parse the stream end.
- parser.state = yaml_PARSE_END_STATE
- *event = yaml_event_t{
- typ: yaml_STREAM_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- skip_token(parser)
- }
-
- return true
-}
-
-// Parse the productions:
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// ***********
-//
-func yaml_parser_parse_document_content(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_VERSION_DIRECTIVE_TOKEN ||
- token.typ == yaml_TAG_DIRECTIVE_TOKEN ||
- token.typ == yaml_DOCUMENT_START_TOKEN ||
- token.typ == yaml_DOCUMENT_END_TOKEN ||
- token.typ == yaml_STREAM_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- return yaml_parser_process_empty_scalar(parser, event,
- token.start_mark)
- }
- return yaml_parser_parse_node(parser, event, true, false)
-}
-
-// Parse the productions:
-// implicit_document ::= block_node DOCUMENT-END*
-// *************
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-//
-func yaml_parser_parse_document_end(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- start_mark := token.start_mark
- end_mark := token.start_mark
-
- implicit := true
- if token.typ == yaml_DOCUMENT_END_TOKEN {
- end_mark = token.end_mark
- skip_token(parser)
- implicit = false
- }
-
- parser.tag_directives = parser.tag_directives[:0]
-
- parser.state = yaml_PARSE_DOCUMENT_START_STATE
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_END_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- implicit: implicit,
- }
- yaml_parser_set_event_comments(parser, event)
- if len(event.head_comment) > 0 && len(event.foot_comment) == 0 {
- event.foot_comment = event.head_comment
- event.head_comment = nil
- }
- return true
-}
-
-func yaml_parser_set_event_comments(parser *yaml_parser_t, event *yaml_event_t) {
- event.head_comment = parser.head_comment
- event.line_comment = parser.line_comment
- event.foot_comment = parser.foot_comment
- parser.head_comment = nil
- parser.line_comment = nil
- parser.foot_comment = nil
- parser.tail_comment = nil
- parser.stem_comment = nil
-}
-
-// Parse the productions:
-// block_node_or_indentless_sequence ::=
-// ALIAS
-// *****
-// | properties (block_content | indentless_block_sequence)?
-// ********** *
-// | block_content | indentless_block_sequence
-// *
-// block_node ::= ALIAS
-// *****
-// | properties block_content?
-// ********** *
-// | block_content
-// *
-// flow_node ::= ALIAS
-// *****
-// | properties flow_content?
-// ********** *
-// | flow_content
-// *
-// properties ::= TAG ANCHOR? | ANCHOR TAG?
-// *************************
-// block_content ::= block_collection | flow_collection | SCALAR
-// ******
-// flow_content ::= flow_collection | SCALAR
-// ******
-func yaml_parser_parse_node(parser *yaml_parser_t, event *yaml_event_t, block, indentless_sequence bool) bool {
- //defer trace("yaml_parser_parse_node", "block:", block, "indentless_sequence:", indentless_sequence)()
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_ALIAS_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- *event = yaml_event_t{
- typ: yaml_ALIAS_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- anchor: token.value,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
-
- start_mark := token.start_mark
- end_mark := token.start_mark
-
- var tag_token bool
- var tag_handle, tag_suffix, anchor []byte
- var tag_mark yaml_mark_t
- if token.typ == yaml_ANCHOR_TOKEN {
- anchor = token.value
- start_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_TAG_TOKEN {
- tag_token = true
- tag_handle = token.value
- tag_suffix = token.suffix
- tag_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- } else if token.typ == yaml_TAG_TOKEN {
- tag_token = true
- tag_handle = token.value
- tag_suffix = token.suffix
- start_mark = token.start_mark
- tag_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_ANCHOR_TOKEN {
- anchor = token.value
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- }
-
- var tag []byte
- if tag_token {
- if len(tag_handle) == 0 {
- tag = tag_suffix
- tag_suffix = nil
- } else {
- for i := range parser.tag_directives {
- if bytes.Equal(parser.tag_directives[i].handle, tag_handle) {
- tag = append([]byte(nil), parser.tag_directives[i].prefix...)
- tag = append(tag, tag_suffix...)
- break
- }
- }
- if len(tag) == 0 {
- yaml_parser_set_parser_error_context(parser,
- "while parsing a node", start_mark,
- "found undefined tag handle", tag_mark)
- return false
- }
- }
- }
-
- implicit := len(tag) == 0
- if indentless_sequence && token.typ == yaml_BLOCK_ENTRY_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_SEQUENCE_STYLE),
- }
- return true
- }
- if token.typ == yaml_SCALAR_TOKEN {
- var plain_implicit, quoted_implicit bool
- end_mark = token.end_mark
- if (len(tag) == 0 && token.style == yaml_PLAIN_SCALAR_STYLE) || (len(tag) == 1 && tag[0] == '!') {
- plain_implicit = true
- } else if len(tag) == 0 {
- quoted_implicit = true
- }
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- value: token.value,
- implicit: plain_implicit,
- quoted_implicit: quoted_implicit,
- style: yaml_style_t(token.style),
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
- if token.typ == yaml_FLOW_SEQUENCE_START_TOKEN {
- // [Go] Some of the events below can be merged as they differ only on style.
- end_mark = token.end_mark
- parser.state = yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_FLOW_SEQUENCE_STYLE),
- }
- yaml_parser_set_event_comments(parser, event)
- return true
- }
- if token.typ == yaml_FLOW_MAPPING_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_FLOW_MAPPING_STYLE),
- }
- yaml_parser_set_event_comments(parser, event)
- return true
- }
- if block && token.typ == yaml_BLOCK_SEQUENCE_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_SEQUENCE_STYLE),
- }
- if parser.stem_comment != nil {
- event.head_comment = parser.stem_comment
- parser.stem_comment = nil
- }
- return true
- }
- if block && token.typ == yaml_BLOCK_MAPPING_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_MAPPING_STYLE),
- }
- if parser.stem_comment != nil {
- event.head_comment = parser.stem_comment
- parser.stem_comment = nil
- }
- return true
- }
- if len(anchor) > 0 || len(tag) > 0 {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- quoted_implicit: false,
- style: yaml_style_t(yaml_PLAIN_SCALAR_STYLE),
- }
- return true
- }
-
- context := "while parsing a flow node"
- if block {
- context = "while parsing a block node"
- }
- yaml_parser_set_parser_error_context(parser, context, start_mark,
- "did not find expected node content", token.start_mark)
- return false
-}
-
-// Parse the productions:
-// block_sequence ::= BLOCK-SEQUENCE-START (BLOCK-ENTRY block_node?)* BLOCK-END
-// ******************** *********** * *********
-//
-func yaml_parser_parse_block_sequence_entry(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_BLOCK_ENTRY_TOKEN {
- mark := token.end_mark
- prior_head_len := len(parser.head_comment)
- skip_token(parser)
- yaml_parser_split_stem_comment(parser, prior_head_len)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_BLOCK_ENTRY_TOKEN && token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, true, false)
- } else {
- parser.state = yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- }
- if token.typ == yaml_BLOCK_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
-
- skip_token(parser)
- return true
- }
-
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a block collection", context_mark,
- "did not find expected '-' indicator", token.start_mark)
-}
-
-// Parse the productions:
-// indentless_sequence ::= (BLOCK-ENTRY block_node?)+
-// *********** *
-func yaml_parser_parse_indentless_sequence_entry(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_BLOCK_ENTRY_TOKEN {
- mark := token.end_mark
- prior_head_len := len(parser.head_comment)
- skip_token(parser)
- yaml_parser_split_stem_comment(parser, prior_head_len)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_BLOCK_ENTRY_TOKEN &&
- token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, true, false)
- }
- parser.state = yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.start_mark, // [Go] Shouldn't this be token.end_mark?
- }
- return true
-}
-
-// Split stem comment from head comment.
-//
-// When a sequence or map is found under a sequence entry, the former head comment
-// is assigned to the underlying sequence or map as a whole, not the individual
-// sequence or map entry as would be expected otherwise. To handle this case the
-// previous head comment is moved aside as the stem comment.
-func yaml_parser_split_stem_comment(parser *yaml_parser_t, stem_len int) {
- if stem_len == 0 {
- return
- }
-
- token := peek_token(parser)
- if token == nil || token.typ != yaml_BLOCK_SEQUENCE_START_TOKEN && token.typ != yaml_BLOCK_MAPPING_START_TOKEN {
- return
- }
-
- parser.stem_comment = parser.head_comment[:stem_len]
- if len(parser.head_comment) == stem_len {
- parser.head_comment = nil
- } else {
- // Copy suffix to prevent very strange bugs if someone ever appends
- // further bytes to the prefix in the stem_comment slice above.
- parser.head_comment = append([]byte(nil), parser.head_comment[stem_len+1:]...)
- }
-}
-
-// Parse the productions:
-// block_mapping ::= BLOCK-MAPPING_START
-// *******************
-// ((KEY block_node_or_indentless_sequence?)?
-// *** *
-// (VALUE block_node_or_indentless_sequence?)?)*
-//
-// BLOCK-END
-// *********
-//
-func yaml_parser_parse_block_mapping_key(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- // [Go] A tail comment was left from the prior mapping value processed. Emit an event
- // as it needs to be processed with that value and not the following key.
- if len(parser.tail_comment) > 0 {
- *event = yaml_event_t{
- typ: yaml_TAIL_COMMENT_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- foot_comment: parser.tail_comment,
- }
- parser.tail_comment = nil
- return true
- }
-
- if token.typ == yaml_KEY_TOKEN {
- mark := token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, true, true)
- } else {
- parser.state = yaml_PARSE_BLOCK_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- } else if token.typ == yaml_BLOCK_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
-
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a block mapping", context_mark,
- "did not find expected key", token.start_mark)
-}
-
-// Parse the productions:
-// block_mapping ::= BLOCK-MAPPING_START
-//
-// ((KEY block_node_or_indentless_sequence?)?
-//
-// (VALUE block_node_or_indentless_sequence?)?)*
-// ***** *
-// BLOCK-END
-//
-//
-func yaml_parser_parse_block_mapping_value(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_VALUE_TOKEN {
- mark := token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_MAPPING_KEY_STATE)
- return yaml_parser_parse_node(parser, event, true, true)
- }
- parser.state = yaml_PARSE_BLOCK_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- parser.state = yaml_PARSE_BLOCK_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Parse the productions:
-// flow_sequence ::= FLOW-SEQUENCE-START
-// *******************
-// (flow_sequence_entry FLOW-ENTRY)*
-// * **********
-// flow_sequence_entry?
-// *
-// FLOW-SEQUENCE-END
-// *****************
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *
-//
-func yaml_parser_parse_flow_sequence_entry(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- if !first {
- if token.typ == yaml_FLOW_ENTRY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- } else {
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a flow sequence", context_mark,
- "did not find expected ',' or ']'", token.start_mark)
- }
- }
-
- if token.typ == yaml_KEY_TOKEN {
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- implicit: true,
- style: yaml_style_t(yaml_FLOW_MAPPING_STYLE),
- }
- skip_token(parser)
- return true
- } else if token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
-
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
-
- skip_token(parser)
- return true
-}
-
-//
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *** *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_key(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_FLOW_ENTRY_TOKEN &&
- token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- mark := token.end_mark
- skip_token(parser)
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
-}
-
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// ***** *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_value(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_VALUE_TOKEN {
- skip_token(parser)
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_ENTRY_TOKEN && token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_end(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.start_mark, // [Go] Shouldn't this be end_mark?
- }
- return true
-}
-
-// Parse the productions:
-// flow_mapping ::= FLOW-MAPPING-START
-// ******************
-// (flow_mapping_entry FLOW-ENTRY)*
-// * **********
-// flow_mapping_entry?
-// ******************
-// FLOW-MAPPING-END
-// ****************
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// * *** *
-//
-func yaml_parser_parse_flow_mapping_key(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- if !first {
- if token.typ == yaml_FLOW_ENTRY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- } else {
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a flow mapping", context_mark,
- "did not find expected ',' or '}'", token.start_mark)
- }
- }
-
- if token.typ == yaml_KEY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_FLOW_ENTRY_TOKEN &&
- token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- } else {
- parser.state = yaml_PARSE_FLOW_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
- }
- } else if token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
-
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
-}
-
-// Parse the productions:
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// * ***** *
-//
-func yaml_parser_parse_flow_mapping_value(parser *yaml_parser_t, event *yaml_event_t, empty bool) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if empty {
- parser.state = yaml_PARSE_FLOW_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
- }
- if token.typ == yaml_VALUE_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_ENTRY_TOKEN && token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_KEY_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
- parser.state = yaml_PARSE_FLOW_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Generate an empty scalar event.
-func yaml_parser_process_empty_scalar(parser *yaml_parser_t, event *yaml_event_t, mark yaml_mark_t) bool {
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: mark,
- end_mark: mark,
- value: nil, // Empty
- implicit: true,
- style: yaml_style_t(yaml_PLAIN_SCALAR_STYLE),
- }
- return true
-}
-
-var default_tag_directives = []yaml_tag_directive_t{
- {[]byte("!"), []byte("!")},
- {[]byte("!!"), []byte("tag:yaml.org,2002:")},
-}
-
-// Parse directives.
-func yaml_parser_process_directives(parser *yaml_parser_t,
- version_directive_ref **yaml_version_directive_t,
- tag_directives_ref *[]yaml_tag_directive_t) bool {
-
- var version_directive *yaml_version_directive_t
- var tag_directives []yaml_tag_directive_t
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- for token.typ == yaml_VERSION_DIRECTIVE_TOKEN || token.typ == yaml_TAG_DIRECTIVE_TOKEN {
- if token.typ == yaml_VERSION_DIRECTIVE_TOKEN {
- if version_directive != nil {
- yaml_parser_set_parser_error(parser,
- "found duplicate %YAML directive", token.start_mark)
- return false
- }
- if token.major != 1 || token.minor != 1 {
- yaml_parser_set_parser_error(parser,
- "found incompatible YAML document", token.start_mark)
- return false
- }
- version_directive = &yaml_version_directive_t{
- major: token.major,
- minor: token.minor,
- }
- } else if token.typ == yaml_TAG_DIRECTIVE_TOKEN {
- value := yaml_tag_directive_t{
- handle: token.value,
- prefix: token.prefix,
- }
- if !yaml_parser_append_tag_directive(parser, value, false, token.start_mark) {
- return false
- }
- tag_directives = append(tag_directives, value)
- }
-
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
-
- for i := range default_tag_directives {
- if !yaml_parser_append_tag_directive(parser, default_tag_directives[i], true, token.start_mark) {
- return false
- }
- }
-
- if version_directive_ref != nil {
- *version_directive_ref = version_directive
- }
- if tag_directives_ref != nil {
- *tag_directives_ref = tag_directives
- }
- return true
-}
-
-// Append a tag directive to the directives stack.
-func yaml_parser_append_tag_directive(parser *yaml_parser_t, value yaml_tag_directive_t, allow_duplicates bool, mark yaml_mark_t) bool {
- for i := range parser.tag_directives {
- if bytes.Equal(value.handle, parser.tag_directives[i].handle) {
- if allow_duplicates {
- return true
- }
- return yaml_parser_set_parser_error(parser, "found duplicate %TAG directive", mark)
- }
- }
-
- // [Go] I suspect the copy is unnecessary. This was likely done
- // because there was no way to track ownership of the data.
- value_copy := yaml_tag_directive_t{
- handle: make([]byte, len(value.handle)),
- prefix: make([]byte, len(value.prefix)),
- }
- copy(value_copy.handle, value.handle)
- copy(value_copy.prefix, value.prefix)
- parser.tag_directives = append(parser.tag_directives, value_copy)
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/readerc.go b/sesh/vendor/gopkg.in/yaml.v3/readerc.go
deleted file mode 100644
index b7de0a8..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/readerc.go
+++ /dev/null
@@ -1,434 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "io"
-)
-
-// Set the reader error and return 0.
-func yaml_parser_set_reader_error(parser *yaml_parser_t, problem string, offset int, value int) bool {
- parser.error = yaml_READER_ERROR
- parser.problem = problem
- parser.problem_offset = offset
- parser.problem_value = value
- return false
-}
-
-// Byte order marks.
-const (
- bom_UTF8 = "\xef\xbb\xbf"
- bom_UTF16LE = "\xff\xfe"
- bom_UTF16BE = "\xfe\xff"
-)
-
-// Determine the input stream encoding by checking the BOM symbol. If no BOM is
-// found, the UTF-8 encoding is assumed. Return 1 on success, 0 on failure.
-func yaml_parser_determine_encoding(parser *yaml_parser_t) bool {
- // Ensure that we had enough bytes in the raw buffer.
- for !parser.eof && len(parser.raw_buffer)-parser.raw_buffer_pos < 3 {
- if !yaml_parser_update_raw_buffer(parser) {
- return false
- }
- }
-
- // Determine the encoding.
- buf := parser.raw_buffer
- pos := parser.raw_buffer_pos
- avail := len(buf) - pos
- if avail >= 2 && buf[pos] == bom_UTF16LE[0] && buf[pos+1] == bom_UTF16LE[1] {
- parser.encoding = yaml_UTF16LE_ENCODING
- parser.raw_buffer_pos += 2
- parser.offset += 2
- } else if avail >= 2 && buf[pos] == bom_UTF16BE[0] && buf[pos+1] == bom_UTF16BE[1] {
- parser.encoding = yaml_UTF16BE_ENCODING
- parser.raw_buffer_pos += 2
- parser.offset += 2
- } else if avail >= 3 && buf[pos] == bom_UTF8[0] && buf[pos+1] == bom_UTF8[1] && buf[pos+2] == bom_UTF8[2] {
- parser.encoding = yaml_UTF8_ENCODING
- parser.raw_buffer_pos += 3
- parser.offset += 3
- } else {
- parser.encoding = yaml_UTF8_ENCODING
- }
- return true
-}
-
-// Update the raw buffer.
-func yaml_parser_update_raw_buffer(parser *yaml_parser_t) bool {
- size_read := 0
-
- // Return if the raw buffer is full.
- if parser.raw_buffer_pos == 0 && len(parser.raw_buffer) == cap(parser.raw_buffer) {
- return true
- }
-
- // Return on EOF.
- if parser.eof {
- return true
- }
-
- // Move the remaining bytes in the raw buffer to the beginning.
- if parser.raw_buffer_pos > 0 && parser.raw_buffer_pos < len(parser.raw_buffer) {
- copy(parser.raw_buffer, parser.raw_buffer[parser.raw_buffer_pos:])
- }
- parser.raw_buffer = parser.raw_buffer[:len(parser.raw_buffer)-parser.raw_buffer_pos]
- parser.raw_buffer_pos = 0
-
- // Call the read handler to fill the buffer.
- size_read, err := parser.read_handler(parser, parser.raw_buffer[len(parser.raw_buffer):cap(parser.raw_buffer)])
- parser.raw_buffer = parser.raw_buffer[:len(parser.raw_buffer)+size_read]
- if err == io.EOF {
- parser.eof = true
- } else if err != nil {
- return yaml_parser_set_reader_error(parser, "input error: "+err.Error(), parser.offset, -1)
- }
- return true
-}
-
-// Ensure that the buffer contains at least `length` characters.
-// Return true on success, false on failure.
-//
-// The length is supposed to be significantly less that the buffer size.
-func yaml_parser_update_buffer(parser *yaml_parser_t, length int) bool {
- if parser.read_handler == nil {
- panic("read handler must be set")
- }
-
- // [Go] This function was changed to guarantee the requested length size at EOF.
- // The fact we need to do this is pretty awful, but the description above implies
- // for that to be the case, and there are tests
-
- // If the EOF flag is set and the raw buffer is empty, do nothing.
- if parser.eof && parser.raw_buffer_pos == len(parser.raw_buffer) {
- // [Go] ACTUALLY! Read the documentation of this function above.
- // This is just broken. To return true, we need to have the
- // given length in the buffer. Not doing that means every single
- // check that calls this function to make sure the buffer has a
- // given length is Go) panicking; or C) accessing invalid memory.
- //return true
- }
-
- // Return if the buffer contains enough characters.
- if parser.unread >= length {
- return true
- }
-
- // Determine the input encoding if it is not known yet.
- if parser.encoding == yaml_ANY_ENCODING {
- if !yaml_parser_determine_encoding(parser) {
- return false
- }
- }
-
- // Move the unread characters to the beginning of the buffer.
- buffer_len := len(parser.buffer)
- if parser.buffer_pos > 0 && parser.buffer_pos < buffer_len {
- copy(parser.buffer, parser.buffer[parser.buffer_pos:])
- buffer_len -= parser.buffer_pos
- parser.buffer_pos = 0
- } else if parser.buffer_pos == buffer_len {
- buffer_len = 0
- parser.buffer_pos = 0
- }
-
- // Open the whole buffer for writing, and cut it before returning.
- parser.buffer = parser.buffer[:cap(parser.buffer)]
-
- // Fill the buffer until it has enough characters.
- first := true
- for parser.unread < length {
-
- // Fill the raw buffer if necessary.
- if !first || parser.raw_buffer_pos == len(parser.raw_buffer) {
- if !yaml_parser_update_raw_buffer(parser) {
- parser.buffer = parser.buffer[:buffer_len]
- return false
- }
- }
- first = false
-
- // Decode the raw buffer.
- inner:
- for parser.raw_buffer_pos != len(parser.raw_buffer) {
- var value rune
- var width int
-
- raw_unread := len(parser.raw_buffer) - parser.raw_buffer_pos
-
- // Decode the next character.
- switch parser.encoding {
- case yaml_UTF8_ENCODING:
- // Decode a UTF-8 character. Check RFC 3629
- // (http://www.ietf.org/rfc/rfc3629.txt) for more details.
- //
- // The following table (taken from the RFC) is used for
- // decoding.
- //
- // Char. number range | UTF-8 octet sequence
- // (hexadecimal) | (binary)
- // --------------------+------------------------------------
- // 0000 0000-0000 007F | 0xxxxxxx
- // 0000 0080-0000 07FF | 110xxxxx 10xxxxxx
- // 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
- // 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- //
- // Additionally, the characters in the range 0xD800-0xDFFF
- // are prohibited as they are reserved for use with UTF-16
- // surrogate pairs.
-
- // Determine the length of the UTF-8 sequence.
- octet := parser.raw_buffer[parser.raw_buffer_pos]
- switch {
- case octet&0x80 == 0x00:
- width = 1
- case octet&0xE0 == 0xC0:
- width = 2
- case octet&0xF0 == 0xE0:
- width = 3
- case octet&0xF8 == 0xF0:
- width = 4
- default:
- // The leading octet is invalid.
- return yaml_parser_set_reader_error(parser,
- "invalid leading UTF-8 octet",
- parser.offset, int(octet))
- }
-
- // Check if the raw buffer contains an incomplete character.
- if width > raw_unread {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-8 octet sequence",
- parser.offset, -1)
- }
- break inner
- }
-
- // Decode the leading octet.
- switch {
- case octet&0x80 == 0x00:
- value = rune(octet & 0x7F)
- case octet&0xE0 == 0xC0:
- value = rune(octet & 0x1F)
- case octet&0xF0 == 0xE0:
- value = rune(octet & 0x0F)
- case octet&0xF8 == 0xF0:
- value = rune(octet & 0x07)
- default:
- value = 0
- }
-
- // Check and decode the trailing octets.
- for k := 1; k < width; k++ {
- octet = parser.raw_buffer[parser.raw_buffer_pos+k]
-
- // Check if the octet is valid.
- if (octet & 0xC0) != 0x80 {
- return yaml_parser_set_reader_error(parser,
- "invalid trailing UTF-8 octet",
- parser.offset+k, int(octet))
- }
-
- // Decode the octet.
- value = (value << 6) + rune(octet&0x3F)
- }
-
- // Check the length of the sequence against the value.
- switch {
- case width == 1:
- case width == 2 && value >= 0x80:
- case width == 3 && value >= 0x800:
- case width == 4 && value >= 0x10000:
- default:
- return yaml_parser_set_reader_error(parser,
- "invalid length of a UTF-8 sequence",
- parser.offset, -1)
- }
-
- // Check the range of the value.
- if value >= 0xD800 && value <= 0xDFFF || value > 0x10FFFF {
- return yaml_parser_set_reader_error(parser,
- "invalid Unicode character",
- parser.offset, int(value))
- }
-
- case yaml_UTF16LE_ENCODING, yaml_UTF16BE_ENCODING:
- var low, high int
- if parser.encoding == yaml_UTF16LE_ENCODING {
- low, high = 0, 1
- } else {
- low, high = 1, 0
- }
-
- // The UTF-16 encoding is not as simple as one might
- // naively think. Check RFC 2781
- // (http://www.ietf.org/rfc/rfc2781.txt).
- //
- // Normally, two subsequent bytes describe a Unicode
- // character. However a special technique (called a
- // surrogate pair) is used for specifying character
- // values larger than 0xFFFF.
- //
- // A surrogate pair consists of two pseudo-characters:
- // high surrogate area (0xD800-0xDBFF)
- // low surrogate area (0xDC00-0xDFFF)
- //
- // The following formulas are used for decoding
- // and encoding characters using surrogate pairs:
- //
- // U = U' + 0x10000 (0x01 00 00 <= U <= 0x10 FF FF)
- // U' = yyyyyyyyyyxxxxxxxxxx (0 <= U' <= 0x0F FF FF)
- // W1 = 110110yyyyyyyyyy
- // W2 = 110111xxxxxxxxxx
- //
- // where U is the character value, W1 is the high surrogate
- // area, W2 is the low surrogate area.
-
- // Check for incomplete UTF-16 character.
- if raw_unread < 2 {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-16 character",
- parser.offset, -1)
- }
- break inner
- }
-
- // Get the character.
- value = rune(parser.raw_buffer[parser.raw_buffer_pos+low]) +
- (rune(parser.raw_buffer[parser.raw_buffer_pos+high]) << 8)
-
- // Check for unexpected low surrogate area.
- if value&0xFC00 == 0xDC00 {
- return yaml_parser_set_reader_error(parser,
- "unexpected low surrogate area",
- parser.offset, int(value))
- }
-
- // Check for a high surrogate area.
- if value&0xFC00 == 0xD800 {
- width = 4
-
- // Check for incomplete surrogate pair.
- if raw_unread < 4 {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-16 surrogate pair",
- parser.offset, -1)
- }
- break inner
- }
-
- // Get the next character.
- value2 := rune(parser.raw_buffer[parser.raw_buffer_pos+low+2]) +
- (rune(parser.raw_buffer[parser.raw_buffer_pos+high+2]) << 8)
-
- // Check for a low surrogate area.
- if value2&0xFC00 != 0xDC00 {
- return yaml_parser_set_reader_error(parser,
- "expected low surrogate area",
- parser.offset+2, int(value2))
- }
-
- // Generate the value of the surrogate pair.
- value = 0x10000 + ((value & 0x3FF) << 10) + (value2 & 0x3FF)
- } else {
- width = 2
- }
-
- default:
- panic("impossible")
- }
-
- // Check if the character is in the allowed range:
- // #x9 | #xA | #xD | [#x20-#x7E] (8 bit)
- // | #x85 | [#xA0-#xD7FF] | [#xE000-#xFFFD] (16 bit)
- // | [#x10000-#x10FFFF] (32 bit)
- switch {
- case value == 0x09:
- case value == 0x0A:
- case value == 0x0D:
- case value >= 0x20 && value <= 0x7E:
- case value == 0x85:
- case value >= 0xA0 && value <= 0xD7FF:
- case value >= 0xE000 && value <= 0xFFFD:
- case value >= 0x10000 && value <= 0x10FFFF:
- default:
- return yaml_parser_set_reader_error(parser,
- "control characters are not allowed",
- parser.offset, int(value))
- }
-
- // Move the raw pointers.
- parser.raw_buffer_pos += width
- parser.offset += width
-
- // Finally put the character into the buffer.
- if value <= 0x7F {
- // 0000 0000-0000 007F . 0xxxxxxx
- parser.buffer[buffer_len+0] = byte(value)
- buffer_len += 1
- } else if value <= 0x7FF {
- // 0000 0080-0000 07FF . 110xxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xC0 + (value >> 6))
- parser.buffer[buffer_len+1] = byte(0x80 + (value & 0x3F))
- buffer_len += 2
- } else if value <= 0xFFFF {
- // 0000 0800-0000 FFFF . 1110xxxx 10xxxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xE0 + (value >> 12))
- parser.buffer[buffer_len+1] = byte(0x80 + ((value >> 6) & 0x3F))
- parser.buffer[buffer_len+2] = byte(0x80 + (value & 0x3F))
- buffer_len += 3
- } else {
- // 0001 0000-0010 FFFF . 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xF0 + (value >> 18))
- parser.buffer[buffer_len+1] = byte(0x80 + ((value >> 12) & 0x3F))
- parser.buffer[buffer_len+2] = byte(0x80 + ((value >> 6) & 0x3F))
- parser.buffer[buffer_len+3] = byte(0x80 + (value & 0x3F))
- buffer_len += 4
- }
-
- parser.unread++
- }
-
- // On EOF, put NUL into the buffer and return.
- if parser.eof {
- parser.buffer[buffer_len] = 0
- buffer_len++
- parser.unread++
- break
- }
- }
- // [Go] Read the documentation of this function above. To return true,
- // we need to have the given length in the buffer. Not doing that means
- // every single check that calls this function to make sure the buffer
- // has a given length is Go) panicking; or C) accessing invalid memory.
- // This happens here due to the EOF above breaking early.
- for buffer_len < length {
- parser.buffer[buffer_len] = 0
- buffer_len++
- }
- parser.buffer = parser.buffer[:buffer_len]
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/resolve.go b/sesh/vendor/gopkg.in/yaml.v3/resolve.go
deleted file mode 100644
index 64ae888..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/resolve.go
+++ /dev/null
@@ -1,326 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding/base64"
- "math"
- "regexp"
- "strconv"
- "strings"
- "time"
-)
-
-type resolveMapItem struct {
- value interface{}
- tag string
-}
-
-var resolveTable = make([]byte, 256)
-var resolveMap = make(map[string]resolveMapItem)
-
-func init() {
- t := resolveTable
- t[int('+')] = 'S' // Sign
- t[int('-')] = 'S'
- for _, c := range "0123456789" {
- t[int(c)] = 'D' // Digit
- }
- for _, c := range "yYnNtTfFoO~" {
- t[int(c)] = 'M' // In map
- }
- t[int('.')] = '.' // Float (potentially in map)
-
- var resolveMapList = []struct {
- v interface{}
- tag string
- l []string
- }{
- {true, boolTag, []string{"true", "True", "TRUE"}},
- {false, boolTag, []string{"false", "False", "FALSE"}},
- {nil, nullTag, []string{"", "~", "null", "Null", "NULL"}},
- {math.NaN(), floatTag, []string{".nan", ".NaN", ".NAN"}},
- {math.Inf(+1), floatTag, []string{".inf", ".Inf", ".INF"}},
- {math.Inf(+1), floatTag, []string{"+.inf", "+.Inf", "+.INF"}},
- {math.Inf(-1), floatTag, []string{"-.inf", "-.Inf", "-.INF"}},
- {"<<", mergeTag, []string{"<<"}},
- }
-
- m := resolveMap
- for _, item := range resolveMapList {
- for _, s := range item.l {
- m[s] = resolveMapItem{item.v, item.tag}
- }
- }
-}
-
-const (
- nullTag = "!!null"
- boolTag = "!!bool"
- strTag = "!!str"
- intTag = "!!int"
- floatTag = "!!float"
- timestampTag = "!!timestamp"
- seqTag = "!!seq"
- mapTag = "!!map"
- binaryTag = "!!binary"
- mergeTag = "!!merge"
-)
-
-var longTags = make(map[string]string)
-var shortTags = make(map[string]string)
-
-func init() {
- for _, stag := range []string{nullTag, boolTag, strTag, intTag, floatTag, timestampTag, seqTag, mapTag, binaryTag, mergeTag} {
- ltag := longTag(stag)
- longTags[stag] = ltag
- shortTags[ltag] = stag
- }
-}
-
-const longTagPrefix = "tag:yaml.org,2002:"
-
-func shortTag(tag string) string {
- if strings.HasPrefix(tag, longTagPrefix) {
- if stag, ok := shortTags[tag]; ok {
- return stag
- }
- return "!!" + tag[len(longTagPrefix):]
- }
- return tag
-}
-
-func longTag(tag string) string {
- if strings.HasPrefix(tag, "!!") {
- if ltag, ok := longTags[tag]; ok {
- return ltag
- }
- return longTagPrefix + tag[2:]
- }
- return tag
-}
-
-func resolvableTag(tag string) bool {
- switch tag {
- case "", strTag, boolTag, intTag, floatTag, nullTag, timestampTag:
- return true
- }
- return false
-}
-
-var yamlStyleFloat = regexp.MustCompile(`^[-+]?(\.[0-9]+|[0-9]+(\.[0-9]*)?)([eE][-+]?[0-9]+)?$`)
-
-func resolve(tag string, in string) (rtag string, out interface{}) {
- tag = shortTag(tag)
- if !resolvableTag(tag) {
- return tag, in
- }
-
- defer func() {
- switch tag {
- case "", rtag, strTag, binaryTag:
- return
- case floatTag:
- if rtag == intTag {
- switch v := out.(type) {
- case int64:
- rtag = floatTag
- out = float64(v)
- return
- case int:
- rtag = floatTag
- out = float64(v)
- return
- }
- }
- }
- failf("cannot decode %s `%s` as a %s", shortTag(rtag), in, shortTag(tag))
- }()
-
- // Any data is accepted as a !!str or !!binary.
- // Otherwise, the prefix is enough of a hint about what it might be.
- hint := byte('N')
- if in != "" {
- hint = resolveTable[in[0]]
- }
- if hint != 0 && tag != strTag && tag != binaryTag {
- // Handle things we can lookup in a map.
- if item, ok := resolveMap[in]; ok {
- return item.tag, item.value
- }
-
- // Base 60 floats are a bad idea, were dropped in YAML 1.2, and
- // are purposefully unsupported here. They're still quoted on
- // the way out for compatibility with other parser, though.
-
- switch hint {
- case 'M':
- // We've already checked the map above.
-
- case '.':
- // Not in the map, so maybe a normal float.
- floatv, err := strconv.ParseFloat(in, 64)
- if err == nil {
- return floatTag, floatv
- }
-
- case 'D', 'S':
- // Int, float, or timestamp.
- // Only try values as a timestamp if the value is unquoted or there's an explicit
- // !!timestamp tag.
- if tag == "" || tag == timestampTag {
- t, ok := parseTimestamp(in)
- if ok {
- return timestampTag, t
- }
- }
-
- plain := strings.Replace(in, "_", "", -1)
- intv, err := strconv.ParseInt(plain, 0, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain, 0, 64)
- if err == nil {
- return intTag, uintv
- }
- if yamlStyleFloat.MatchString(plain) {
- floatv, err := strconv.ParseFloat(plain, 64)
- if err == nil {
- return floatTag, floatv
- }
- }
- if strings.HasPrefix(plain, "0b") {
- intv, err := strconv.ParseInt(plain[2:], 2, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain[2:], 2, 64)
- if err == nil {
- return intTag, uintv
- }
- } else if strings.HasPrefix(plain, "-0b") {
- intv, err := strconv.ParseInt("-"+plain[3:], 2, 64)
- if err == nil {
- if true || intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- }
- // Octals as introduced in version 1.2 of the spec.
- // Octals from the 1.1 spec, spelled as 0777, are still
- // decoded by default in v3 as well for compatibility.
- // May be dropped in v4 depending on how usage evolves.
- if strings.HasPrefix(plain, "0o") {
- intv, err := strconv.ParseInt(plain[2:], 8, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain[2:], 8, 64)
- if err == nil {
- return intTag, uintv
- }
- } else if strings.HasPrefix(plain, "-0o") {
- intv, err := strconv.ParseInt("-"+plain[3:], 8, 64)
- if err == nil {
- if true || intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- }
- default:
- panic("internal error: missing handler for resolver table: " + string(rune(hint)) + " (with " + in + ")")
- }
- }
- return strTag, in
-}
-
-// encodeBase64 encodes s as base64 that is broken up into multiple lines
-// as appropriate for the resulting length.
-func encodeBase64(s string) string {
- const lineLen = 70
- encLen := base64.StdEncoding.EncodedLen(len(s))
- lines := encLen/lineLen + 1
- buf := make([]byte, encLen*2+lines)
- in := buf[0:encLen]
- out := buf[encLen:]
- base64.StdEncoding.Encode(in, []byte(s))
- k := 0
- for i := 0; i < len(in); i += lineLen {
- j := i + lineLen
- if j > len(in) {
- j = len(in)
- }
- k += copy(out[k:], in[i:j])
- if lines > 1 {
- out[k] = '\n'
- k++
- }
- }
- return string(out[:k])
-}
-
-// This is a subset of the formats allowed by the regular expression
-// defined at http://yaml.org/type/timestamp.html.
-var allowedTimestampFormats = []string{
- "2006-1-2T15:4:5.999999999Z07:00", // RCF3339Nano with short date fields.
- "2006-1-2t15:4:5.999999999Z07:00", // RFC3339Nano with short date fields and lower-case "t".
- "2006-1-2 15:4:5.999999999", // space separated with no time zone
- "2006-1-2", // date only
- // Notable exception: time.Parse cannot handle: "2001-12-14 21:59:43.10 -5"
- // from the set of examples.
-}
-
-// parseTimestamp parses s as a timestamp string and
-// returns the timestamp and reports whether it succeeded.
-// Timestamp formats are defined at http://yaml.org/type/timestamp.html
-func parseTimestamp(s string) (time.Time, bool) {
- // TODO write code to check all the formats supported by
- // http://yaml.org/type/timestamp.html instead of using time.Parse.
-
- // Quick check: all date formats start with YYYY-.
- i := 0
- for ; i < len(s); i++ {
- if c := s[i]; c < '0' || c > '9' {
- break
- }
- }
- if i != 4 || i == len(s) || s[i] != '-' {
- return time.Time{}, false
- }
- for _, format := range allowedTimestampFormats {
- if t, err := time.Parse(format, s); err == nil {
- return t, true
- }
- }
- return time.Time{}, false
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/scannerc.go b/sesh/vendor/gopkg.in/yaml.v3/scannerc.go
deleted file mode 100644
index ca00701..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/scannerc.go
+++ /dev/null
@@ -1,3038 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
- "fmt"
-)
-
-// Introduction
-// ************
-//
-// The following notes assume that you are familiar with the YAML specification
-// (http://yaml.org/spec/1.2/spec.html). We mostly follow it, although in
-// some cases we are less restrictive that it requires.
-//
-// The process of transforming a YAML stream into a sequence of events is
-// divided on two steps: Scanning and Parsing.
-//
-// The Scanner transforms the input stream into a sequence of tokens, while the
-// parser transform the sequence of tokens produced by the Scanner into a
-// sequence of parsing events.
-//
-// The Scanner is rather clever and complicated. The Parser, on the contrary,
-// is a straightforward implementation of a recursive-descendant parser (or,
-// LL(1) parser, as it is usually called).
-//
-// Actually there are two issues of Scanning that might be called "clever", the
-// rest is quite straightforward. The issues are "block collection start" and
-// "simple keys". Both issues are explained below in details.
-//
-// Here the Scanning step is explained and implemented. We start with the list
-// of all the tokens produced by the Scanner together with short descriptions.
-//
-// Now, tokens:
-//
-// STREAM-START(encoding) # The stream start.
-// STREAM-END # The stream end.
-// VERSION-DIRECTIVE(major,minor) # The '%YAML' directive.
-// TAG-DIRECTIVE(handle,prefix) # The '%TAG' directive.
-// DOCUMENT-START # '---'
-// DOCUMENT-END # '...'
-// BLOCK-SEQUENCE-START # Indentation increase denoting a block
-// BLOCK-MAPPING-START # sequence or a block mapping.
-// BLOCK-END # Indentation decrease.
-// FLOW-SEQUENCE-START # '['
-// FLOW-SEQUENCE-END # ']'
-// BLOCK-SEQUENCE-START # '{'
-// BLOCK-SEQUENCE-END # '}'
-// BLOCK-ENTRY # '-'
-// FLOW-ENTRY # ','
-// KEY # '?' or nothing (simple keys).
-// VALUE # ':'
-// ALIAS(anchor) # '*anchor'
-// ANCHOR(anchor) # '&anchor'
-// TAG(handle,suffix) # '!handle!suffix'
-// SCALAR(value,style) # A scalar.
-//
-// The following two tokens are "virtual" tokens denoting the beginning and the
-// end of the stream:
-//
-// STREAM-START(encoding)
-// STREAM-END
-//
-// We pass the information about the input stream encoding with the
-// STREAM-START token.
-//
-// The next two tokens are responsible for tags:
-//
-// VERSION-DIRECTIVE(major,minor)
-// TAG-DIRECTIVE(handle,prefix)
-//
-// Example:
-//
-// %YAML 1.1
-// %TAG ! !foo
-// %TAG !yaml! tag:yaml.org,2002:
-// ---
-//
-// The correspoding sequence of tokens:
-//
-// STREAM-START(utf-8)
-// VERSION-DIRECTIVE(1,1)
-// TAG-DIRECTIVE("!","!foo")
-// TAG-DIRECTIVE("!yaml","tag:yaml.org,2002:")
-// DOCUMENT-START
-// STREAM-END
-//
-// Note that the VERSION-DIRECTIVE and TAG-DIRECTIVE tokens occupy a whole
-// line.
-//
-// The document start and end indicators are represented by:
-//
-// DOCUMENT-START
-// DOCUMENT-END
-//
-// Note that if a YAML stream contains an implicit document (without '---'
-// and '...' indicators), no DOCUMENT-START and DOCUMENT-END tokens will be
-// produced.
-//
-// In the following examples, we present whole documents together with the
-// produced tokens.
-//
-// 1. An implicit document:
-//
-// 'a scalar'
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// SCALAR("a scalar",single-quoted)
-// STREAM-END
-//
-// 2. An explicit document:
-//
-// ---
-// 'a scalar'
-// ...
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// DOCUMENT-START
-// SCALAR("a scalar",single-quoted)
-// DOCUMENT-END
-// STREAM-END
-//
-// 3. Several documents in a stream:
-//
-// 'a scalar'
-// ---
-// 'another scalar'
-// ---
-// 'yet another scalar'
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// SCALAR("a scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("another scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("yet another scalar",single-quoted)
-// STREAM-END
-//
-// We have already introduced the SCALAR token above. The following tokens are
-// used to describe aliases, anchors, tag, and scalars:
-//
-// ALIAS(anchor)
-// ANCHOR(anchor)
-// TAG(handle,suffix)
-// SCALAR(value,style)
-//
-// The following series of examples illustrate the usage of these tokens:
-//
-// 1. A recursive sequence:
-//
-// &A [ *A ]
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// ANCHOR("A")
-// FLOW-SEQUENCE-START
-// ALIAS("A")
-// FLOW-SEQUENCE-END
-// STREAM-END
-//
-// 2. A tagged scalar:
-//
-// !!float "3.14" # A good approximation.
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// TAG("!!","float")
-// SCALAR("3.14",double-quoted)
-// STREAM-END
-//
-// 3. Various scalar styles:
-//
-// --- # Implicit empty plain scalars do not produce tokens.
-// --- a plain scalar
-// --- 'a single-quoted scalar'
-// --- "a double-quoted scalar"
-// --- |-
-// a literal scalar
-// --- >-
-// a folded
-// scalar
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// DOCUMENT-START
-// DOCUMENT-START
-// SCALAR("a plain scalar",plain)
-// DOCUMENT-START
-// SCALAR("a single-quoted scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("a double-quoted scalar",double-quoted)
-// DOCUMENT-START
-// SCALAR("a literal scalar",literal)
-// DOCUMENT-START
-// SCALAR("a folded scalar",folded)
-// STREAM-END
-//
-// Now it's time to review collection-related tokens. We will start with
-// flow collections:
-//
-// FLOW-SEQUENCE-START
-// FLOW-SEQUENCE-END
-// FLOW-MAPPING-START
-// FLOW-MAPPING-END
-// FLOW-ENTRY
-// KEY
-// VALUE
-//
-// The tokens FLOW-SEQUENCE-START, FLOW-SEQUENCE-END, FLOW-MAPPING-START, and
-// FLOW-MAPPING-END represent the indicators '[', ']', '{', and '}'
-// correspondingly. FLOW-ENTRY represent the ',' indicator. Finally the
-// indicators '?' and ':', which are used for denoting mapping keys and values,
-// are represented by the KEY and VALUE tokens.
-//
-// The following examples show flow collections:
-//
-// 1. A flow sequence:
-//
-// [item 1, item 2, item 3]
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// FLOW-SEQUENCE-START
-// SCALAR("item 1",plain)
-// FLOW-ENTRY
-// SCALAR("item 2",plain)
-// FLOW-ENTRY
-// SCALAR("item 3",plain)
-// FLOW-SEQUENCE-END
-// STREAM-END
-//
-// 2. A flow mapping:
-//
-// {
-// a simple key: a value, # Note that the KEY token is produced.
-// ? a complex key: another value,
-// }
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// FLOW-MAPPING-START
-// KEY
-// SCALAR("a simple key",plain)
-// VALUE
-// SCALAR("a value",plain)
-// FLOW-ENTRY
-// KEY
-// SCALAR("a complex key",plain)
-// VALUE
-// SCALAR("another value",plain)
-// FLOW-ENTRY
-// FLOW-MAPPING-END
-// STREAM-END
-//
-// A simple key is a key which is not denoted by the '?' indicator. Note that
-// the Scanner still produce the KEY token whenever it encounters a simple key.
-//
-// For scanning block collections, the following tokens are used (note that we
-// repeat KEY and VALUE here):
-//
-// BLOCK-SEQUENCE-START
-// BLOCK-MAPPING-START
-// BLOCK-END
-// BLOCK-ENTRY
-// KEY
-// VALUE
-//
-// The tokens BLOCK-SEQUENCE-START and BLOCK-MAPPING-START denote indentation
-// increase that precedes a block collection (cf. the INDENT token in Python).
-// The token BLOCK-END denote indentation decrease that ends a block collection
-// (cf. the DEDENT token in Python). However YAML has some syntax pecularities
-// that makes detections of these tokens more complex.
-//
-// The tokens BLOCK-ENTRY, KEY, and VALUE are used to represent the indicators
-// '-', '?', and ':' correspondingly.
-//
-// The following examples show how the tokens BLOCK-SEQUENCE-START,
-// BLOCK-MAPPING-START, and BLOCK-END are emitted by the Scanner:
-//
-// 1. Block sequences:
-//
-// - item 1
-// - item 2
-// -
-// - item 3.1
-// - item 3.2
-// -
-// key 1: value 1
-// key 2: value 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-ENTRY
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 3.1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 3.2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// 2. Block mappings:
-//
-// a simple key: a value # The KEY token is produced here.
-// ? a complex key
-// : another value
-// a mapping:
-// key 1: value 1
-// key 2: value 2
-// a sequence:
-// - item 1
-// - item 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("a simple key",plain)
-// VALUE
-// SCALAR("a value",plain)
-// KEY
-// SCALAR("a complex key",plain)
-// VALUE
-// SCALAR("another value",plain)
-// KEY
-// SCALAR("a mapping",plain)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// KEY
-// SCALAR("a sequence",plain)
-// VALUE
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// YAML does not always require to start a new block collection from a new
-// line. If the current line contains only '-', '?', and ':' indicators, a new
-// block collection may start at the current line. The following examples
-// illustrate this case:
-//
-// 1. Collections in a sequence:
-//
-// - - item 1
-// - item 2
-// - key 1: value 1
-// key 2: value 2
-// - ? complex key
-// : complex value
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("complex key")
-// VALUE
-// SCALAR("complex value")
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// 2. Collections in a mapping:
-//
-// ? a sequence
-// : - item 1
-// - item 2
-// ? a mapping
-// : key 1: value 1
-// key 2: value 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("a sequence",plain)
-// VALUE
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// KEY
-// SCALAR("a mapping",plain)
-// VALUE
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// YAML also permits non-indented sequences if they are included into a block
-// mapping. In this case, the token BLOCK-SEQUENCE-START is not produced:
-//
-// key:
-// - item 1 # BLOCK-SEQUENCE-START is NOT produced here.
-// - item 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key",plain)
-// VALUE
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-//
-
-// Ensure that the buffer contains the required number of characters.
-// Return true on success, false on failure (reader error or memory error).
-func cache(parser *yaml_parser_t, length int) bool {
- // [Go] This was inlined: !cache(A, B) -> unread < B && !update(A, B)
- return parser.unread >= length || yaml_parser_update_buffer(parser, length)
-}
-
-// Advance the buffer pointer.
-func skip(parser *yaml_parser_t) {
- if !is_blank(parser.buffer, parser.buffer_pos) {
- parser.newlines = 0
- }
- parser.mark.index++
- parser.mark.column++
- parser.unread--
- parser.buffer_pos += width(parser.buffer[parser.buffer_pos])
-}
-
-func skip_line(parser *yaml_parser_t) {
- if is_crlf(parser.buffer, parser.buffer_pos) {
- parser.mark.index += 2
- parser.mark.column = 0
- parser.mark.line++
- parser.unread -= 2
- parser.buffer_pos += 2
- parser.newlines++
- } else if is_break(parser.buffer, parser.buffer_pos) {
- parser.mark.index++
- parser.mark.column = 0
- parser.mark.line++
- parser.unread--
- parser.buffer_pos += width(parser.buffer[parser.buffer_pos])
- parser.newlines++
- }
-}
-
-// Copy a character to a string buffer and advance pointers.
-func read(parser *yaml_parser_t, s []byte) []byte {
- if !is_blank(parser.buffer, parser.buffer_pos) {
- parser.newlines = 0
- }
- w := width(parser.buffer[parser.buffer_pos])
- if w == 0 {
- panic("invalid character sequence")
- }
- if len(s) == 0 {
- s = make([]byte, 0, 32)
- }
- if w == 1 && len(s)+w <= cap(s) {
- s = s[:len(s)+1]
- s[len(s)-1] = parser.buffer[parser.buffer_pos]
- parser.buffer_pos++
- } else {
- s = append(s, parser.buffer[parser.buffer_pos:parser.buffer_pos+w]...)
- parser.buffer_pos += w
- }
- parser.mark.index++
- parser.mark.column++
- parser.unread--
- return s
-}
-
-// Copy a line break character to a string buffer and advance pointers.
-func read_line(parser *yaml_parser_t, s []byte) []byte {
- buf := parser.buffer
- pos := parser.buffer_pos
- switch {
- case buf[pos] == '\r' && buf[pos+1] == '\n':
- // CR LF . LF
- s = append(s, '\n')
- parser.buffer_pos += 2
- parser.mark.index++
- parser.unread--
- case buf[pos] == '\r' || buf[pos] == '\n':
- // CR|LF . LF
- s = append(s, '\n')
- parser.buffer_pos += 1
- case buf[pos] == '\xC2' && buf[pos+1] == '\x85':
- // NEL . LF
- s = append(s, '\n')
- parser.buffer_pos += 2
- case buf[pos] == '\xE2' && buf[pos+1] == '\x80' && (buf[pos+2] == '\xA8' || buf[pos+2] == '\xA9'):
- // LS|PS . LS|PS
- s = append(s, buf[parser.buffer_pos:pos+3]...)
- parser.buffer_pos += 3
- default:
- return s
- }
- parser.mark.index++
- parser.mark.column = 0
- parser.mark.line++
- parser.unread--
- parser.newlines++
- return s
-}
-
-// Get the next token.
-func yaml_parser_scan(parser *yaml_parser_t, token *yaml_token_t) bool {
- // Erase the token object.
- *token = yaml_token_t{} // [Go] Is this necessary?
-
- // No tokens after STREAM-END or error.
- if parser.stream_end_produced || parser.error != yaml_NO_ERROR {
- return true
- }
-
- // Ensure that the tokens queue contains enough tokens.
- if !parser.token_available {
- if !yaml_parser_fetch_more_tokens(parser) {
- return false
- }
- }
-
- // Fetch the next token from the queue.
- *token = parser.tokens[parser.tokens_head]
- parser.tokens_head++
- parser.tokens_parsed++
- parser.token_available = false
-
- if token.typ == yaml_STREAM_END_TOKEN {
- parser.stream_end_produced = true
- }
- return true
-}
-
-// Set the scanner error and return false.
-func yaml_parser_set_scanner_error(parser *yaml_parser_t, context string, context_mark yaml_mark_t, problem string) bool {
- parser.error = yaml_SCANNER_ERROR
- parser.context = context
- parser.context_mark = context_mark
- parser.problem = problem
- parser.problem_mark = parser.mark
- return false
-}
-
-func yaml_parser_set_scanner_tag_error(parser *yaml_parser_t, directive bool, context_mark yaml_mark_t, problem string) bool {
- context := "while parsing a tag"
- if directive {
- context = "while parsing a %TAG directive"
- }
- return yaml_parser_set_scanner_error(parser, context, context_mark, problem)
-}
-
-func trace(args ...interface{}) func() {
- pargs := append([]interface{}{"+++"}, args...)
- fmt.Println(pargs...)
- pargs = append([]interface{}{"---"}, args...)
- return func() { fmt.Println(pargs...) }
-}
-
-// Ensure that the tokens queue contains at least one token which can be
-// returned to the Parser.
-func yaml_parser_fetch_more_tokens(parser *yaml_parser_t) bool {
- // While we need more tokens to fetch, do it.
- for {
- // [Go] The comment parsing logic requires a lookahead of two tokens
- // so that foot comments may be parsed in time of associating them
- // with the tokens that are parsed before them, and also for line
- // comments to be transformed into head comments in some edge cases.
- if parser.tokens_head < len(parser.tokens)-2 {
- // If a potential simple key is at the head position, we need to fetch
- // the next token to disambiguate it.
- head_tok_idx, ok := parser.simple_keys_by_tok[parser.tokens_parsed]
- if !ok {
- break
- } else if valid, ok := yaml_simple_key_is_valid(parser, &parser.simple_keys[head_tok_idx]); !ok {
- return false
- } else if !valid {
- break
- }
- }
- // Fetch the next token.
- if !yaml_parser_fetch_next_token(parser) {
- return false
- }
- }
-
- parser.token_available = true
- return true
-}
-
-// The dispatcher for token fetchers.
-func yaml_parser_fetch_next_token(parser *yaml_parser_t) (ok bool) {
- // Ensure that the buffer is initialized.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check if we just started scanning. Fetch STREAM-START then.
- if !parser.stream_start_produced {
- return yaml_parser_fetch_stream_start(parser)
- }
-
- scan_mark := parser.mark
-
- // Eat whitespaces and comments until we reach the next token.
- if !yaml_parser_scan_to_next_token(parser) {
- return false
- }
-
- // [Go] While unrolling indents, transform the head comments of prior
- // indentation levels observed after scan_start into foot comments at
- // the respective indexes.
-
- // Check the indentation level against the current column.
- if !yaml_parser_unroll_indent(parser, parser.mark.column, scan_mark) {
- return false
- }
-
- // Ensure that the buffer contains at least 4 characters. 4 is the length
- // of the longest indicators ('--- ' and '... ').
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
-
- // Is it the end of the stream?
- if is_z(parser.buffer, parser.buffer_pos) {
- return yaml_parser_fetch_stream_end(parser)
- }
-
- // Is it a directive?
- if parser.mark.column == 0 && parser.buffer[parser.buffer_pos] == '%' {
- return yaml_parser_fetch_directive(parser)
- }
-
- buf := parser.buffer
- pos := parser.buffer_pos
-
- // Is it the document start indicator?
- if parser.mark.column == 0 && buf[pos] == '-' && buf[pos+1] == '-' && buf[pos+2] == '-' && is_blankz(buf, pos+3) {
- return yaml_parser_fetch_document_indicator(parser, yaml_DOCUMENT_START_TOKEN)
- }
-
- // Is it the document end indicator?
- if parser.mark.column == 0 && buf[pos] == '.' && buf[pos+1] == '.' && buf[pos+2] == '.' && is_blankz(buf, pos+3) {
- return yaml_parser_fetch_document_indicator(parser, yaml_DOCUMENT_END_TOKEN)
- }
-
- comment_mark := parser.mark
- if len(parser.tokens) > 0 && (parser.flow_level == 0 && buf[pos] == ':' || parser.flow_level > 0 && buf[pos] == ',') {
- // Associate any following comments with the prior token.
- comment_mark = parser.tokens[len(parser.tokens)-1].start_mark
- }
- defer func() {
- if !ok {
- return
- }
- if len(parser.tokens) > 0 && parser.tokens[len(parser.tokens)-1].typ == yaml_BLOCK_ENTRY_TOKEN {
- // Sequence indicators alone have no line comments. It becomes
- // a head comment for whatever follows.
- return
- }
- if !yaml_parser_scan_line_comment(parser, comment_mark) {
- ok = false
- return
- }
- }()
-
- // Is it the flow sequence start indicator?
- if buf[pos] == '[' {
- return yaml_parser_fetch_flow_collection_start(parser, yaml_FLOW_SEQUENCE_START_TOKEN)
- }
-
- // Is it the flow mapping start indicator?
- if parser.buffer[parser.buffer_pos] == '{' {
- return yaml_parser_fetch_flow_collection_start(parser, yaml_FLOW_MAPPING_START_TOKEN)
- }
-
- // Is it the flow sequence end indicator?
- if parser.buffer[parser.buffer_pos] == ']' {
- return yaml_parser_fetch_flow_collection_end(parser,
- yaml_FLOW_SEQUENCE_END_TOKEN)
- }
-
- // Is it the flow mapping end indicator?
- if parser.buffer[parser.buffer_pos] == '}' {
- return yaml_parser_fetch_flow_collection_end(parser,
- yaml_FLOW_MAPPING_END_TOKEN)
- }
-
- // Is it the flow entry indicator?
- if parser.buffer[parser.buffer_pos] == ',' {
- return yaml_parser_fetch_flow_entry(parser)
- }
-
- // Is it the block entry indicator?
- if parser.buffer[parser.buffer_pos] == '-' && is_blankz(parser.buffer, parser.buffer_pos+1) {
- return yaml_parser_fetch_block_entry(parser)
- }
-
- // Is it the key indicator?
- if parser.buffer[parser.buffer_pos] == '?' && (parser.flow_level > 0 || is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_key(parser)
- }
-
- // Is it the value indicator?
- if parser.buffer[parser.buffer_pos] == ':' && (parser.flow_level > 0 || is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_value(parser)
- }
-
- // Is it an alias?
- if parser.buffer[parser.buffer_pos] == '*' {
- return yaml_parser_fetch_anchor(parser, yaml_ALIAS_TOKEN)
- }
-
- // Is it an anchor?
- if parser.buffer[parser.buffer_pos] == '&' {
- return yaml_parser_fetch_anchor(parser, yaml_ANCHOR_TOKEN)
- }
-
- // Is it a tag?
- if parser.buffer[parser.buffer_pos] == '!' {
- return yaml_parser_fetch_tag(parser)
- }
-
- // Is it a literal scalar?
- if parser.buffer[parser.buffer_pos] == '|' && parser.flow_level == 0 {
- return yaml_parser_fetch_block_scalar(parser, true)
- }
-
- // Is it a folded scalar?
- if parser.buffer[parser.buffer_pos] == '>' && parser.flow_level == 0 {
- return yaml_parser_fetch_block_scalar(parser, false)
- }
-
- // Is it a single-quoted scalar?
- if parser.buffer[parser.buffer_pos] == '\'' {
- return yaml_parser_fetch_flow_scalar(parser, true)
- }
-
- // Is it a double-quoted scalar?
- if parser.buffer[parser.buffer_pos] == '"' {
- return yaml_parser_fetch_flow_scalar(parser, false)
- }
-
- // Is it a plain scalar?
- //
- // A plain scalar may start with any non-blank characters except
- //
- // '-', '?', ':', ',', '[', ']', '{', '}',
- // '#', '&', '*', '!', '|', '>', '\'', '\"',
- // '%', '@', '`'.
- //
- // In the block context (and, for the '-' indicator, in the flow context
- // too), it may also start with the characters
- //
- // '-', '?', ':'
- //
- // if it is followed by a non-space character.
- //
- // The last rule is more restrictive than the specification requires.
- // [Go] TODO Make this logic more reasonable.
- //switch parser.buffer[parser.buffer_pos] {
- //case '-', '?', ':', ',', '?', '-', ',', ':', ']', '[', '}', '{', '&', '#', '!', '*', '>', '|', '"', '\'', '@', '%', '-', '`':
- //}
- if !(is_blankz(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == '-' ||
- parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == ':' ||
- parser.buffer[parser.buffer_pos] == ',' || parser.buffer[parser.buffer_pos] == '[' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '{' ||
- parser.buffer[parser.buffer_pos] == '}' || parser.buffer[parser.buffer_pos] == '#' ||
- parser.buffer[parser.buffer_pos] == '&' || parser.buffer[parser.buffer_pos] == '*' ||
- parser.buffer[parser.buffer_pos] == '!' || parser.buffer[parser.buffer_pos] == '|' ||
- parser.buffer[parser.buffer_pos] == '>' || parser.buffer[parser.buffer_pos] == '\'' ||
- parser.buffer[parser.buffer_pos] == '"' || parser.buffer[parser.buffer_pos] == '%' ||
- parser.buffer[parser.buffer_pos] == '@' || parser.buffer[parser.buffer_pos] == '`') ||
- (parser.buffer[parser.buffer_pos] == '-' && !is_blank(parser.buffer, parser.buffer_pos+1)) ||
- (parser.flow_level == 0 &&
- (parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == ':') &&
- !is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_plain_scalar(parser)
- }
-
- // If we don't determine the token type so far, it is an error.
- return yaml_parser_set_scanner_error(parser,
- "while scanning for the next token", parser.mark,
- "found character that cannot start any token")
-}
-
-func yaml_simple_key_is_valid(parser *yaml_parser_t, simple_key *yaml_simple_key_t) (valid, ok bool) {
- if !simple_key.possible {
- return false, true
- }
-
- // The 1.2 specification says:
- //
- // "If the ? indicator is omitted, parsing needs to see past the
- // implicit key to recognize it as such. To limit the amount of
- // lookahead required, the “:” indicator must appear at most 1024
- // Unicode characters beyond the start of the key. In addition, the key
- // is restricted to a single line."
- //
- if simple_key.mark.line < parser.mark.line || simple_key.mark.index+1024 < parser.mark.index {
- // Check if the potential simple key to be removed is required.
- if simple_key.required {
- return false, yaml_parser_set_scanner_error(parser,
- "while scanning a simple key", simple_key.mark,
- "could not find expected ':'")
- }
- simple_key.possible = false
- return false, true
- }
- return true, true
-}
-
-// Check if a simple key may start at the current position and add it if
-// needed.
-func yaml_parser_save_simple_key(parser *yaml_parser_t) bool {
- // A simple key is required at the current position if the scanner is in
- // the block context and the current column coincides with the indentation
- // level.
-
- required := parser.flow_level == 0 && parser.indent == parser.mark.column
-
- //
- // If the current position may start a simple key, save it.
- //
- if parser.simple_key_allowed {
- simple_key := yaml_simple_key_t{
- possible: true,
- required: required,
- token_number: parser.tokens_parsed + (len(parser.tokens) - parser.tokens_head),
- mark: parser.mark,
- }
-
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
- parser.simple_keys[len(parser.simple_keys)-1] = simple_key
- parser.simple_keys_by_tok[simple_key.token_number] = len(parser.simple_keys) - 1
- }
- return true
-}
-
-// Remove a potential simple key at the current flow level.
-func yaml_parser_remove_simple_key(parser *yaml_parser_t) bool {
- i := len(parser.simple_keys) - 1
- if parser.simple_keys[i].possible {
- // If the key is required, it is an error.
- if parser.simple_keys[i].required {
- return yaml_parser_set_scanner_error(parser,
- "while scanning a simple key", parser.simple_keys[i].mark,
- "could not find expected ':'")
- }
- // Remove the key from the stack.
- parser.simple_keys[i].possible = false
- delete(parser.simple_keys_by_tok, parser.simple_keys[i].token_number)
- }
- return true
-}
-
-// max_flow_level limits the flow_level
-const max_flow_level = 10000
-
-// Increase the flow level and resize the simple key list if needed.
-func yaml_parser_increase_flow_level(parser *yaml_parser_t) bool {
- // Reset the simple key on the next level.
- parser.simple_keys = append(parser.simple_keys, yaml_simple_key_t{
- possible: false,
- required: false,
- token_number: parser.tokens_parsed + (len(parser.tokens) - parser.tokens_head),
- mark: parser.mark,
- })
-
- // Increase the flow level.
- parser.flow_level++
- if parser.flow_level > max_flow_level {
- return yaml_parser_set_scanner_error(parser,
- "while increasing flow level", parser.simple_keys[len(parser.simple_keys)-1].mark,
- fmt.Sprintf("exceeded max depth of %d", max_flow_level))
- }
- return true
-}
-
-// Decrease the flow level.
-func yaml_parser_decrease_flow_level(parser *yaml_parser_t) bool {
- if parser.flow_level > 0 {
- parser.flow_level--
- last := len(parser.simple_keys) - 1
- delete(parser.simple_keys_by_tok, parser.simple_keys[last].token_number)
- parser.simple_keys = parser.simple_keys[:last]
- }
- return true
-}
-
-// max_indents limits the indents stack size
-const max_indents = 10000
-
-// Push the current indentation level to the stack and set the new level
-// the current column is greater than the indentation level. In this case,
-// append or insert the specified token into the token queue.
-func yaml_parser_roll_indent(parser *yaml_parser_t, column, number int, typ yaml_token_type_t, mark yaml_mark_t) bool {
- // In the flow context, do nothing.
- if parser.flow_level > 0 {
- return true
- }
-
- if parser.indent < column {
- // Push the current indentation level to the stack and set the new
- // indentation level.
- parser.indents = append(parser.indents, parser.indent)
- parser.indent = column
- if len(parser.indents) > max_indents {
- return yaml_parser_set_scanner_error(parser,
- "while increasing indent level", parser.simple_keys[len(parser.simple_keys)-1].mark,
- fmt.Sprintf("exceeded max depth of %d", max_indents))
- }
-
- // Create a token and insert it into the queue.
- token := yaml_token_t{
- typ: typ,
- start_mark: mark,
- end_mark: mark,
- }
- if number > -1 {
- number -= parser.tokens_parsed
- }
- yaml_insert_token(parser, number, &token)
- }
- return true
-}
-
-// Pop indentation levels from the indents stack until the current level
-// becomes less or equal to the column. For each indentation level, append
-// the BLOCK-END token.
-func yaml_parser_unroll_indent(parser *yaml_parser_t, column int, scan_mark yaml_mark_t) bool {
- // In the flow context, do nothing.
- if parser.flow_level > 0 {
- return true
- }
-
- block_mark := scan_mark
- block_mark.index--
-
- // Loop through the indentation levels in the stack.
- for parser.indent > column {
-
- // [Go] Reposition the end token before potential following
- // foot comments of parent blocks. For that, search
- // backwards for recent comments that were at the same
- // indent as the block that is ending now.
- stop_index := block_mark.index
- for i := len(parser.comments) - 1; i >= 0; i-- {
- comment := &parser.comments[i]
-
- if comment.end_mark.index < stop_index {
- // Don't go back beyond the start of the comment/whitespace scan, unless column < 0.
- // If requested indent column is < 0, then the document is over and everything else
- // is a foot anyway.
- break
- }
- if comment.start_mark.column == parser.indent+1 {
- // This is a good match. But maybe there's a former comment
- // at that same indent level, so keep searching.
- block_mark = comment.start_mark
- }
-
- // While the end of the former comment matches with
- // the start of the following one, we know there's
- // nothing in between and scanning is still safe.
- stop_index = comment.scan_mark.index
- }
-
- // Create a token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_BLOCK_END_TOKEN,
- start_mark: block_mark,
- end_mark: block_mark,
- }
- yaml_insert_token(parser, -1, &token)
-
- // Pop the indentation level.
- parser.indent = parser.indents[len(parser.indents)-1]
- parser.indents = parser.indents[:len(parser.indents)-1]
- }
- return true
-}
-
-// Initialize the scanner and produce the STREAM-START token.
-func yaml_parser_fetch_stream_start(parser *yaml_parser_t) bool {
-
- // Set the initial indentation.
- parser.indent = -1
-
- // Initialize the simple key stack.
- parser.simple_keys = append(parser.simple_keys, yaml_simple_key_t{})
-
- parser.simple_keys_by_tok = make(map[int]int)
-
- // A simple key is allowed at the beginning of the stream.
- parser.simple_key_allowed = true
-
- // We have started.
- parser.stream_start_produced = true
-
- // Create the STREAM-START token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_STREAM_START_TOKEN,
- start_mark: parser.mark,
- end_mark: parser.mark,
- encoding: parser.encoding,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the STREAM-END token and shut down the scanner.
-func yaml_parser_fetch_stream_end(parser *yaml_parser_t) bool {
-
- // Force new line.
- if parser.mark.column != 0 {
- parser.mark.column = 0
- parser.mark.line++
- }
-
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Create the STREAM-END token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_STREAM_END_TOKEN,
- start_mark: parser.mark,
- end_mark: parser.mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce a VERSION-DIRECTIVE or TAG-DIRECTIVE token.
-func yaml_parser_fetch_directive(parser *yaml_parser_t) bool {
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Create the YAML-DIRECTIVE or TAG-DIRECTIVE token.
- token := yaml_token_t{}
- if !yaml_parser_scan_directive(parser, &token) {
- return false
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the DOCUMENT-START or DOCUMENT-END token.
-func yaml_parser_fetch_document_indicator(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Consume the token.
- start_mark := parser.mark
-
- skip(parser)
- skip(parser)
- skip(parser)
-
- end_mark := parser.mark
-
- // Create the DOCUMENT-START or DOCUMENT-END token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-SEQUENCE-START or FLOW-MAPPING-START token.
-func yaml_parser_fetch_flow_collection_start(parser *yaml_parser_t, typ yaml_token_type_t) bool {
-
- // The indicators '[' and '{' may start a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // Increase the flow level.
- if !yaml_parser_increase_flow_level(parser) {
- return false
- }
-
- // A simple key may follow the indicators '[' and '{'.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-SEQUENCE-START of FLOW-MAPPING-START token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-SEQUENCE-END or FLOW-MAPPING-END token.
-func yaml_parser_fetch_flow_collection_end(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // Reset any potential simple key on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Decrease the flow level.
- if !yaml_parser_decrease_flow_level(parser) {
- return false
- }
-
- // No simple keys after the indicators ']' and '}'.
- parser.simple_key_allowed = false
-
- // Consume the token.
-
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-SEQUENCE-END of FLOW-MAPPING-END token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-ENTRY token.
-func yaml_parser_fetch_flow_entry(parser *yaml_parser_t) bool {
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after ','.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-ENTRY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_FLOW_ENTRY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the BLOCK-ENTRY token.
-func yaml_parser_fetch_block_entry(parser *yaml_parser_t) bool {
- // Check if the scanner is in the block context.
- if parser.flow_level == 0 {
- // Check if we are allowed to start a new entry.
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "block sequence entries are not allowed in this context")
- }
- // Add the BLOCK-SEQUENCE-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_SEQUENCE_START_TOKEN, parser.mark) {
- return false
- }
- } else {
- // It is an error for the '-' indicator to occur in the flow context,
- // but we let the Parser detect and report about it because the Parser
- // is able to point to the context.
- }
-
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after '-'.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the BLOCK-ENTRY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_BLOCK_ENTRY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the KEY token.
-func yaml_parser_fetch_key(parser *yaml_parser_t) bool {
-
- // In the block context, additional checks are required.
- if parser.flow_level == 0 {
- // Check if we are allowed to start a new key (not nessesary simple).
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "mapping keys are not allowed in this context")
- }
- // Add the BLOCK-MAPPING-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_MAPPING_START_TOKEN, parser.mark) {
- return false
- }
- }
-
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after '?' in the block context.
- parser.simple_key_allowed = parser.flow_level == 0
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the KEY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_KEY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the VALUE token.
-func yaml_parser_fetch_value(parser *yaml_parser_t) bool {
-
- simple_key := &parser.simple_keys[len(parser.simple_keys)-1]
-
- // Have we found a simple key?
- if valid, ok := yaml_simple_key_is_valid(parser, simple_key); !ok {
- return false
-
- } else if valid {
-
- // Create the KEY token and insert it into the queue.
- token := yaml_token_t{
- typ: yaml_KEY_TOKEN,
- start_mark: simple_key.mark,
- end_mark: simple_key.mark,
- }
- yaml_insert_token(parser, simple_key.token_number-parser.tokens_parsed, &token)
-
- // In the block context, we may need to add the BLOCK-MAPPING-START token.
- if !yaml_parser_roll_indent(parser, simple_key.mark.column,
- simple_key.token_number,
- yaml_BLOCK_MAPPING_START_TOKEN, simple_key.mark) {
- return false
- }
-
- // Remove the simple key.
- simple_key.possible = false
- delete(parser.simple_keys_by_tok, simple_key.token_number)
-
- // A simple key cannot follow another simple key.
- parser.simple_key_allowed = false
-
- } else {
- // The ':' indicator follows a complex key.
-
- // In the block context, extra checks are required.
- if parser.flow_level == 0 {
-
- // Check if we are allowed to start a complex value.
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "mapping values are not allowed in this context")
- }
-
- // Add the BLOCK-MAPPING-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_MAPPING_START_TOKEN, parser.mark) {
- return false
- }
- }
-
- // Simple keys after ':' are allowed in the block context.
- parser.simple_key_allowed = parser.flow_level == 0
- }
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the VALUE token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_VALUE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the ALIAS or ANCHOR token.
-func yaml_parser_fetch_anchor(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // An anchor or an alias could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow an anchor or an alias.
- parser.simple_key_allowed = false
-
- // Create the ALIAS or ANCHOR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_anchor(parser, &token, typ) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the TAG token.
-func yaml_parser_fetch_tag(parser *yaml_parser_t) bool {
- // A tag could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a tag.
- parser.simple_key_allowed = false
-
- // Create the TAG token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_tag(parser, &token) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,literal) or SCALAR(...,folded) tokens.
-func yaml_parser_fetch_block_scalar(parser *yaml_parser_t, literal bool) bool {
- // Remove any potential simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // A simple key may follow a block scalar.
- parser.simple_key_allowed = true
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_block_scalar(parser, &token, literal) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,single-quoted) or SCALAR(...,double-quoted) tokens.
-func yaml_parser_fetch_flow_scalar(parser *yaml_parser_t, single bool) bool {
- // A plain scalar could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a flow scalar.
- parser.simple_key_allowed = false
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_flow_scalar(parser, &token, single) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,plain) token.
-func yaml_parser_fetch_plain_scalar(parser *yaml_parser_t) bool {
- // A plain scalar could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a flow scalar.
- parser.simple_key_allowed = false
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_plain_scalar(parser, &token) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Eat whitespaces and comments until the next token is found.
-func yaml_parser_scan_to_next_token(parser *yaml_parser_t) bool {
-
- scan_mark := parser.mark
-
- // Until the next token is not found.
- for {
- // Allow the BOM mark to start a line.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.mark.column == 0 && is_bom(parser.buffer, parser.buffer_pos) {
- skip(parser)
- }
-
- // Eat whitespaces.
- // Tabs are allowed:
- // - in the flow context
- // - in the block context, but not at the beginning of the line or
- // after '-', '?', or ':' (complex value).
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for parser.buffer[parser.buffer_pos] == ' ' || ((parser.flow_level > 0 || !parser.simple_key_allowed) && parser.buffer[parser.buffer_pos] == '\t') {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if we just had a line comment under a sequence entry that
- // looks more like a header to the following content. Similar to this:
- //
- // - # The comment
- // - Some data
- //
- // If so, transform the line comment to a head comment and reposition.
- if len(parser.comments) > 0 && len(parser.tokens) > 1 {
- tokenA := parser.tokens[len(parser.tokens)-2]
- tokenB := parser.tokens[len(parser.tokens)-1]
- comment := &parser.comments[len(parser.comments)-1]
- if tokenA.typ == yaml_BLOCK_SEQUENCE_START_TOKEN && tokenB.typ == yaml_BLOCK_ENTRY_TOKEN && len(comment.line) > 0 && !is_break(parser.buffer, parser.buffer_pos) {
- // If it was in the prior line, reposition so it becomes a
- // header of the follow up token. Otherwise, keep it in place
- // so it becomes a header of the former.
- comment.head = comment.line
- comment.line = nil
- if comment.start_mark.line == parser.mark.line-1 {
- comment.token_mark = parser.mark
- }
- }
- }
-
- // Eat a comment until a line break.
- if parser.buffer[parser.buffer_pos] == '#' {
- if !yaml_parser_scan_comments(parser, scan_mark) {
- return false
- }
- }
-
- // If it is a line break, eat it.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
-
- // In the block context, a new line may start a simple key.
- if parser.flow_level == 0 {
- parser.simple_key_allowed = true
- }
- } else {
- break // We have found a token.
- }
- }
-
- return true
-}
-
-// Scan a YAML-DIRECTIVE or TAG-DIRECTIVE token.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-//
-func yaml_parser_scan_directive(parser *yaml_parser_t, token *yaml_token_t) bool {
- // Eat '%'.
- start_mark := parser.mark
- skip(parser)
-
- // Scan the directive name.
- var name []byte
- if !yaml_parser_scan_directive_name(parser, start_mark, &name) {
- return false
- }
-
- // Is it a YAML directive?
- if bytes.Equal(name, []byte("YAML")) {
- // Scan the VERSION directive value.
- var major, minor int8
- if !yaml_parser_scan_version_directive_value(parser, start_mark, &major, &minor) {
- return false
- }
- end_mark := parser.mark
-
- // Create a VERSION-DIRECTIVE token.
- *token = yaml_token_t{
- typ: yaml_VERSION_DIRECTIVE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- major: major,
- minor: minor,
- }
-
- // Is it a TAG directive?
- } else if bytes.Equal(name, []byte("TAG")) {
- // Scan the TAG directive value.
- var handle, prefix []byte
- if !yaml_parser_scan_tag_directive_value(parser, start_mark, &handle, &prefix) {
- return false
- }
- end_mark := parser.mark
-
- // Create a TAG-DIRECTIVE token.
- *token = yaml_token_t{
- typ: yaml_TAG_DIRECTIVE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: handle,
- prefix: prefix,
- }
-
- // Unknown directive.
- } else {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "found unknown directive name")
- return false
- }
-
- // Eat the rest of the line including any comments.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- if parser.buffer[parser.buffer_pos] == '#' {
- // [Go] Discard this inline comment for the time being.
- //if !yaml_parser_scan_line_comment(parser, start_mark) {
- // return false
- //}
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- }
-
- // Check if we are at the end of the line.
- if !is_breakz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "did not find expected comment or line break")
- return false
- }
-
- // Eat a line break.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- }
-
- return true
-}
-
-// Scan the directive name.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^
-//
-func yaml_parser_scan_directive_name(parser *yaml_parser_t, start_mark yaml_mark_t, name *[]byte) bool {
- // Consume the directive name.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- var s []byte
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the name is empty.
- if len(s) == 0 {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "could not find expected directive name")
- return false
- }
-
- // Check for an blank character after the name.
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "found unexpected non-alphabetical character")
- return false
- }
- *name = s
- return true
-}
-
-// Scan the value of VERSION-DIRECTIVE.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^^^
-func yaml_parser_scan_version_directive_value(parser *yaml_parser_t, start_mark yaml_mark_t, major, minor *int8) bool {
- // Eat whitespaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Consume the major version number.
- if !yaml_parser_scan_version_directive_number(parser, start_mark, major) {
- return false
- }
-
- // Eat '.'.
- if parser.buffer[parser.buffer_pos] != '.' {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "did not find expected digit or '.' character")
- }
-
- skip(parser)
-
- // Consume the minor version number.
- if !yaml_parser_scan_version_directive_number(parser, start_mark, minor) {
- return false
- }
- return true
-}
-
-const max_number_length = 2
-
-// Scan the version number of VERSION-DIRECTIVE.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^
-// %YAML 1.1 # a comment \n
-// ^
-func yaml_parser_scan_version_directive_number(parser *yaml_parser_t, start_mark yaml_mark_t, number *int8) bool {
-
- // Repeat while the next character is digit.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- var value, length int8
- for is_digit(parser.buffer, parser.buffer_pos) {
- // Check if the number is too long.
- length++
- if length > max_number_length {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "found extremely long version number")
- }
- value = value*10 + int8(as_digit(parser.buffer, parser.buffer_pos))
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the number was present.
- if length == 0 {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "did not find expected version number")
- }
- *number = value
- return true
-}
-
-// Scan the value of a TAG-DIRECTIVE token.
-//
-// Scope:
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-//
-func yaml_parser_scan_tag_directive_value(parser *yaml_parser_t, start_mark yaml_mark_t, handle, prefix *[]byte) bool {
- var handle_value, prefix_value []byte
-
- // Eat whitespaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Scan a handle.
- if !yaml_parser_scan_tag_handle(parser, true, start_mark, &handle_value) {
- return false
- }
-
- // Expect a whitespace.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blank(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a %TAG directive",
- start_mark, "did not find expected whitespace")
- return false
- }
-
- // Eat whitespaces.
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Scan a prefix.
- if !yaml_parser_scan_tag_uri(parser, true, nil, start_mark, &prefix_value) {
- return false
- }
-
- // Expect a whitespace or line break.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a %TAG directive",
- start_mark, "did not find expected whitespace or line break")
- return false
- }
-
- *handle = handle_value
- *prefix = prefix_value
- return true
-}
-
-func yaml_parser_scan_anchor(parser *yaml_parser_t, token *yaml_token_t, typ yaml_token_type_t) bool {
- var s []byte
-
- // Eat the indicator character.
- start_mark := parser.mark
- skip(parser)
-
- // Consume the value.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- end_mark := parser.mark
-
- /*
- * Check if length of the anchor is greater than 0 and it is followed by
- * a whitespace character or one of the indicators:
- *
- * '?', ':', ',', ']', '}', '%', '@', '`'.
- */
-
- if len(s) == 0 ||
- !(is_blankz(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == '?' ||
- parser.buffer[parser.buffer_pos] == ':' || parser.buffer[parser.buffer_pos] == ',' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '}' ||
- parser.buffer[parser.buffer_pos] == '%' || parser.buffer[parser.buffer_pos] == '@' ||
- parser.buffer[parser.buffer_pos] == '`') {
- context := "while scanning an alias"
- if typ == yaml_ANCHOR_TOKEN {
- context = "while scanning an anchor"
- }
- yaml_parser_set_scanner_error(parser, context, start_mark,
- "did not find expected alphabetic or numeric character")
- return false
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- }
-
- return true
-}
-
-/*
- * Scan a TAG token.
- */
-
-func yaml_parser_scan_tag(parser *yaml_parser_t, token *yaml_token_t) bool {
- var handle, suffix []byte
-
- start_mark := parser.mark
-
- // Check if the tag is in the canonical form.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- if parser.buffer[parser.buffer_pos+1] == '<' {
- // Keep the handle as ''
-
- // Eat '!<'
- skip(parser)
- skip(parser)
-
- // Consume the tag value.
- if !yaml_parser_scan_tag_uri(parser, false, nil, start_mark, &suffix) {
- return false
- }
-
- // Check for '>' and eat it.
- if parser.buffer[parser.buffer_pos] != '>' {
- yaml_parser_set_scanner_error(parser, "while scanning a tag",
- start_mark, "did not find the expected '>'")
- return false
- }
-
- skip(parser)
- } else {
- // The tag has either the '!suffix' or the '!handle!suffix' form.
-
- // First, try to scan a handle.
- if !yaml_parser_scan_tag_handle(parser, false, start_mark, &handle) {
- return false
- }
-
- // Check if it is, indeed, handle.
- if handle[0] == '!' && len(handle) > 1 && handle[len(handle)-1] == '!' {
- // Scan the suffix now.
- if !yaml_parser_scan_tag_uri(parser, false, nil, start_mark, &suffix) {
- return false
- }
- } else {
- // It wasn't a handle after all. Scan the rest of the tag.
- if !yaml_parser_scan_tag_uri(parser, false, handle, start_mark, &suffix) {
- return false
- }
-
- // Set the handle to '!'.
- handle = []byte{'!'}
-
- // A special case: the '!' tag. Set the handle to '' and the
- // suffix to '!'.
- if len(suffix) == 0 {
- handle, suffix = suffix, handle
- }
- }
- }
-
- // Check the character which ends the tag.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a tag",
- start_mark, "did not find expected whitespace or line break")
- return false
- }
-
- end_mark := parser.mark
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_TAG_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: handle,
- suffix: suffix,
- }
- return true
-}
-
-// Scan a tag handle.
-func yaml_parser_scan_tag_handle(parser *yaml_parser_t, directive bool, start_mark yaml_mark_t, handle *[]byte) bool {
- // Check the initial '!' character.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.buffer[parser.buffer_pos] != '!' {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected '!'")
- return false
- }
-
- var s []byte
-
- // Copy the '!' character.
- s = read(parser, s)
-
- // Copy all subsequent alphabetical and numerical characters.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the trailing character is '!' and copy it.
- if parser.buffer[parser.buffer_pos] == '!' {
- s = read(parser, s)
- } else {
- // It's either the '!' tag or not really a tag handle. If it's a %TAG
- // directive, it's an error. If it's a tag token, it must be a part of URI.
- if directive && string(s) != "!" {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected '!'")
- return false
- }
- }
-
- *handle = s
- return true
-}
-
-// Scan a tag.
-func yaml_parser_scan_tag_uri(parser *yaml_parser_t, directive bool, head []byte, start_mark yaml_mark_t, uri *[]byte) bool {
- //size_t length = head ? strlen((char *)head) : 0
- var s []byte
- hasTag := len(head) > 0
-
- // Copy the head if needed.
- //
- // Note that we don't copy the leading '!' character.
- if len(head) > 1 {
- s = append(s, head[1:]...)
- }
-
- // Scan the tag.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // The set of characters that may appear in URI is as follows:
- //
- // '0'-'9', 'A'-'Z', 'a'-'z', '_', '-', ';', '/', '?', ':', '@', '&',
- // '=', '+', '$', ',', '.', '!', '~', '*', '\'', '(', ')', '[', ']',
- // '%'.
- // [Go] TODO Convert this into more reasonable logic.
- for is_alpha(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == ';' ||
- parser.buffer[parser.buffer_pos] == '/' || parser.buffer[parser.buffer_pos] == '?' ||
- parser.buffer[parser.buffer_pos] == ':' || parser.buffer[parser.buffer_pos] == '@' ||
- parser.buffer[parser.buffer_pos] == '&' || parser.buffer[parser.buffer_pos] == '=' ||
- parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '$' ||
- parser.buffer[parser.buffer_pos] == ',' || parser.buffer[parser.buffer_pos] == '.' ||
- parser.buffer[parser.buffer_pos] == '!' || parser.buffer[parser.buffer_pos] == '~' ||
- parser.buffer[parser.buffer_pos] == '*' || parser.buffer[parser.buffer_pos] == '\'' ||
- parser.buffer[parser.buffer_pos] == '(' || parser.buffer[parser.buffer_pos] == ')' ||
- parser.buffer[parser.buffer_pos] == '[' || parser.buffer[parser.buffer_pos] == ']' ||
- parser.buffer[parser.buffer_pos] == '%' {
- // Check if it is a URI-escape sequence.
- if parser.buffer[parser.buffer_pos] == '%' {
- if !yaml_parser_scan_uri_escapes(parser, directive, start_mark, &s) {
- return false
- }
- } else {
- s = read(parser, s)
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- hasTag = true
- }
-
- if !hasTag {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected tag URI")
- return false
- }
- *uri = s
- return true
-}
-
-// Decode an URI-escape sequence corresponding to a single UTF-8 character.
-func yaml_parser_scan_uri_escapes(parser *yaml_parser_t, directive bool, start_mark yaml_mark_t, s *[]byte) bool {
-
- // Decode the required number of characters.
- w := 1024
- for w > 0 {
- // Check for a URI-escaped octet.
- if parser.unread < 3 && !yaml_parser_update_buffer(parser, 3) {
- return false
- }
-
- if !(parser.buffer[parser.buffer_pos] == '%' &&
- is_hex(parser.buffer, parser.buffer_pos+1) &&
- is_hex(parser.buffer, parser.buffer_pos+2)) {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find URI escaped octet")
- }
-
- // Get the octet.
- octet := byte((as_hex(parser.buffer, parser.buffer_pos+1) << 4) + as_hex(parser.buffer, parser.buffer_pos+2))
-
- // If it is the leading octet, determine the length of the UTF-8 sequence.
- if w == 1024 {
- w = width(octet)
- if w == 0 {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "found an incorrect leading UTF-8 octet")
- }
- } else {
- // Check if the trailing octet is correct.
- if octet&0xC0 != 0x80 {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "found an incorrect trailing UTF-8 octet")
- }
- }
-
- // Copy the octet and move the pointers.
- *s = append(*s, octet)
- skip(parser)
- skip(parser)
- skip(parser)
- w--
- }
- return true
-}
-
-// Scan a block scalar.
-func yaml_parser_scan_block_scalar(parser *yaml_parser_t, token *yaml_token_t, literal bool) bool {
- // Eat the indicator '|' or '>'.
- start_mark := parser.mark
- skip(parser)
-
- // Scan the additional block scalar indicators.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check for a chomping indicator.
- var chomping, increment int
- if parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '-' {
- // Set the chomping method and eat the indicator.
- if parser.buffer[parser.buffer_pos] == '+' {
- chomping = +1
- } else {
- chomping = -1
- }
- skip(parser)
-
- // Check for an indentation indicator.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_digit(parser.buffer, parser.buffer_pos) {
- // Check that the indentation is greater than 0.
- if parser.buffer[parser.buffer_pos] == '0' {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found an indentation indicator equal to 0")
- return false
- }
-
- // Get the indentation level and eat the indicator.
- increment = as_digit(parser.buffer, parser.buffer_pos)
- skip(parser)
- }
-
- } else if is_digit(parser.buffer, parser.buffer_pos) {
- // Do the same as above, but in the opposite order.
-
- if parser.buffer[parser.buffer_pos] == '0' {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found an indentation indicator equal to 0")
- return false
- }
- increment = as_digit(parser.buffer, parser.buffer_pos)
- skip(parser)
-
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '-' {
- if parser.buffer[parser.buffer_pos] == '+' {
- chomping = +1
- } else {
- chomping = -1
- }
- skip(parser)
- }
- }
-
- // Eat whitespaces and comments to the end of the line.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- if parser.buffer[parser.buffer_pos] == '#' {
- if !yaml_parser_scan_line_comment(parser, start_mark) {
- return false
- }
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- }
-
- // Check if we are at the end of the line.
- if !is_breakz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "did not find expected comment or line break")
- return false
- }
-
- // Eat a line break.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- }
-
- end_mark := parser.mark
-
- // Set the indentation level if it was specified.
- var indent int
- if increment > 0 {
- if parser.indent >= 0 {
- indent = parser.indent + increment
- } else {
- indent = increment
- }
- }
-
- // Scan the leading line breaks and determine the indentation level if needed.
- var s, leading_break, trailing_breaks []byte
- if !yaml_parser_scan_block_scalar_breaks(parser, &indent, &trailing_breaks, start_mark, &end_mark) {
- return false
- }
-
- // Scan the block scalar content.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- var leading_blank, trailing_blank bool
- for parser.mark.column == indent && !is_z(parser.buffer, parser.buffer_pos) {
- // We are at the beginning of a non-empty line.
-
- // Is it a trailing whitespace?
- trailing_blank = is_blank(parser.buffer, parser.buffer_pos)
-
- // Check if we need to fold the leading line break.
- if !literal && !leading_blank && !trailing_blank && len(leading_break) > 0 && leading_break[0] == '\n' {
- // Do we need to join the lines by space?
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- }
- } else {
- s = append(s, leading_break...)
- }
- leading_break = leading_break[:0]
-
- // Append the remaining line breaks.
- s = append(s, trailing_breaks...)
- trailing_breaks = trailing_breaks[:0]
-
- // Is it a leading whitespace?
- leading_blank = is_blank(parser.buffer, parser.buffer_pos)
-
- // Consume the current line.
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Consume the line break.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- leading_break = read_line(parser, leading_break)
-
- // Eat the following indentation spaces and line breaks.
- if !yaml_parser_scan_block_scalar_breaks(parser, &indent, &trailing_breaks, start_mark, &end_mark) {
- return false
- }
- }
-
- // Chomp the tail.
- if chomping != -1 {
- s = append(s, leading_break...)
- }
- if chomping == 1 {
- s = append(s, trailing_breaks...)
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_LITERAL_SCALAR_STYLE,
- }
- if !literal {
- token.style = yaml_FOLDED_SCALAR_STYLE
- }
- return true
-}
-
-// Scan indentation spaces and line breaks for a block scalar. Determine the
-// indentation level if needed.
-func yaml_parser_scan_block_scalar_breaks(parser *yaml_parser_t, indent *int, breaks *[]byte, start_mark yaml_mark_t, end_mark *yaml_mark_t) bool {
- *end_mark = parser.mark
-
- // Eat the indentation spaces and line breaks.
- max_indent := 0
- for {
- // Eat the indentation spaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for (*indent == 0 || parser.mark.column < *indent) && is_space(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- if parser.mark.column > max_indent {
- max_indent = parser.mark.column
- }
-
- // Check for a tab character messing the indentation.
- if (*indent == 0 || parser.mark.column < *indent) && is_tab(parser.buffer, parser.buffer_pos) {
- return yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found a tab character where an indentation space is expected")
- }
-
- // Have we found a non-empty line?
- if !is_break(parser.buffer, parser.buffer_pos) {
- break
- }
-
- // Consume the line break.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- // [Go] Should really be returning breaks instead.
- *breaks = read_line(parser, *breaks)
- *end_mark = parser.mark
- }
-
- // Determine the indentation level if needed.
- if *indent == 0 {
- *indent = max_indent
- if *indent < parser.indent+1 {
- *indent = parser.indent + 1
- }
- if *indent < 1 {
- *indent = 1
- }
- }
- return true
-}
-
-// Scan a quoted scalar.
-func yaml_parser_scan_flow_scalar(parser *yaml_parser_t, token *yaml_token_t, single bool) bool {
- // Eat the left quote.
- start_mark := parser.mark
- skip(parser)
-
- // Consume the content of the quoted scalar.
- var s, leading_break, trailing_breaks, whitespaces []byte
- for {
- // Check that there are no document indicators at the beginning of the line.
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
-
- if parser.mark.column == 0 &&
- ((parser.buffer[parser.buffer_pos+0] == '-' &&
- parser.buffer[parser.buffer_pos+1] == '-' &&
- parser.buffer[parser.buffer_pos+2] == '-') ||
- (parser.buffer[parser.buffer_pos+0] == '.' &&
- parser.buffer[parser.buffer_pos+1] == '.' &&
- parser.buffer[parser.buffer_pos+2] == '.')) &&
- is_blankz(parser.buffer, parser.buffer_pos+3) {
- yaml_parser_set_scanner_error(parser, "while scanning a quoted scalar",
- start_mark, "found unexpected document indicator")
- return false
- }
-
- // Check for EOF.
- if is_z(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a quoted scalar",
- start_mark, "found unexpected end of stream")
- return false
- }
-
- // Consume non-blank characters.
- leading_blanks := false
- for !is_blankz(parser.buffer, parser.buffer_pos) {
- if single && parser.buffer[parser.buffer_pos] == '\'' && parser.buffer[parser.buffer_pos+1] == '\'' {
- // Is is an escaped single quote.
- s = append(s, '\'')
- skip(parser)
- skip(parser)
-
- } else if single && parser.buffer[parser.buffer_pos] == '\'' {
- // It is a right single quote.
- break
- } else if !single && parser.buffer[parser.buffer_pos] == '"' {
- // It is a right double quote.
- break
-
- } else if !single && parser.buffer[parser.buffer_pos] == '\\' && is_break(parser.buffer, parser.buffer_pos+1) {
- // It is an escaped line break.
- if parser.unread < 3 && !yaml_parser_update_buffer(parser, 3) {
- return false
- }
- skip(parser)
- skip_line(parser)
- leading_blanks = true
- break
-
- } else if !single && parser.buffer[parser.buffer_pos] == '\\' {
- // It is an escape sequence.
- code_length := 0
-
- // Check the escape character.
- switch parser.buffer[parser.buffer_pos+1] {
- case '0':
- s = append(s, 0)
- case 'a':
- s = append(s, '\x07')
- case 'b':
- s = append(s, '\x08')
- case 't', '\t':
- s = append(s, '\x09')
- case 'n':
- s = append(s, '\x0A')
- case 'v':
- s = append(s, '\x0B')
- case 'f':
- s = append(s, '\x0C')
- case 'r':
- s = append(s, '\x0D')
- case 'e':
- s = append(s, '\x1B')
- case ' ':
- s = append(s, '\x20')
- case '"':
- s = append(s, '"')
- case '\'':
- s = append(s, '\'')
- case '\\':
- s = append(s, '\\')
- case 'N': // NEL (#x85)
- s = append(s, '\xC2')
- s = append(s, '\x85')
- case '_': // #xA0
- s = append(s, '\xC2')
- s = append(s, '\xA0')
- case 'L': // LS (#x2028)
- s = append(s, '\xE2')
- s = append(s, '\x80')
- s = append(s, '\xA8')
- case 'P': // PS (#x2029)
- s = append(s, '\xE2')
- s = append(s, '\x80')
- s = append(s, '\xA9')
- case 'x':
- code_length = 2
- case 'u':
- code_length = 4
- case 'U':
- code_length = 8
- default:
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "found unknown escape character")
- return false
- }
-
- skip(parser)
- skip(parser)
-
- // Consume an arbitrary escape code.
- if code_length > 0 {
- var value int
-
- // Scan the character value.
- if parser.unread < code_length && !yaml_parser_update_buffer(parser, code_length) {
- return false
- }
- for k := 0; k < code_length; k++ {
- if !is_hex(parser.buffer, parser.buffer_pos+k) {
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "did not find expected hexdecimal number")
- return false
- }
- value = (value << 4) + as_hex(parser.buffer, parser.buffer_pos+k)
- }
-
- // Check the value and write the character.
- if (value >= 0xD800 && value <= 0xDFFF) || value > 0x10FFFF {
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "found invalid Unicode character escape code")
- return false
- }
- if value <= 0x7F {
- s = append(s, byte(value))
- } else if value <= 0x7FF {
- s = append(s, byte(0xC0+(value>>6)))
- s = append(s, byte(0x80+(value&0x3F)))
- } else if value <= 0xFFFF {
- s = append(s, byte(0xE0+(value>>12)))
- s = append(s, byte(0x80+((value>>6)&0x3F)))
- s = append(s, byte(0x80+(value&0x3F)))
- } else {
- s = append(s, byte(0xF0+(value>>18)))
- s = append(s, byte(0x80+((value>>12)&0x3F)))
- s = append(s, byte(0x80+((value>>6)&0x3F)))
- s = append(s, byte(0x80+(value&0x3F)))
- }
-
- // Advance the pointer.
- for k := 0; k < code_length; k++ {
- skip(parser)
- }
- }
- } else {
- // It is a non-escaped non-blank character.
- s = read(parser, s)
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- }
-
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check if we are at the end of the scalar.
- if single {
- if parser.buffer[parser.buffer_pos] == '\'' {
- break
- }
- } else {
- if parser.buffer[parser.buffer_pos] == '"' {
- break
- }
- }
-
- // Consume blank characters.
- for is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos) {
- if is_blank(parser.buffer, parser.buffer_pos) {
- // Consume a space or a tab character.
- if !leading_blanks {
- whitespaces = read(parser, whitespaces)
- } else {
- skip(parser)
- }
- } else {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- // Check if it is a first line break.
- if !leading_blanks {
- whitespaces = whitespaces[:0]
- leading_break = read_line(parser, leading_break)
- leading_blanks = true
- } else {
- trailing_breaks = read_line(parser, trailing_breaks)
- }
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Join the whitespaces or fold line breaks.
- if leading_blanks {
- // Do we need to fold line breaks?
- if len(leading_break) > 0 && leading_break[0] == '\n' {
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- } else {
- s = append(s, trailing_breaks...)
- }
- } else {
- s = append(s, leading_break...)
- s = append(s, trailing_breaks...)
- }
- trailing_breaks = trailing_breaks[:0]
- leading_break = leading_break[:0]
- } else {
- s = append(s, whitespaces...)
- whitespaces = whitespaces[:0]
- }
- }
-
- // Eat the right quote.
- skip(parser)
- end_mark := parser.mark
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_SINGLE_QUOTED_SCALAR_STYLE,
- }
- if !single {
- token.style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- return true
-}
-
-// Scan a plain scalar.
-func yaml_parser_scan_plain_scalar(parser *yaml_parser_t, token *yaml_token_t) bool {
-
- var s, leading_break, trailing_breaks, whitespaces []byte
- var leading_blanks bool
- var indent = parser.indent + 1
-
- start_mark := parser.mark
- end_mark := parser.mark
-
- // Consume the content of the plain scalar.
- for {
- // Check for a document indicator.
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
- if parser.mark.column == 0 &&
- ((parser.buffer[parser.buffer_pos+0] == '-' &&
- parser.buffer[parser.buffer_pos+1] == '-' &&
- parser.buffer[parser.buffer_pos+2] == '-') ||
- (parser.buffer[parser.buffer_pos+0] == '.' &&
- parser.buffer[parser.buffer_pos+1] == '.' &&
- parser.buffer[parser.buffer_pos+2] == '.')) &&
- is_blankz(parser.buffer, parser.buffer_pos+3) {
- break
- }
-
- // Check for a comment.
- if parser.buffer[parser.buffer_pos] == '#' {
- break
- }
-
- // Consume non-blank characters.
- for !is_blankz(parser.buffer, parser.buffer_pos) {
-
- // Check for indicators that may end a plain scalar.
- if (parser.buffer[parser.buffer_pos] == ':' && is_blankz(parser.buffer, parser.buffer_pos+1)) ||
- (parser.flow_level > 0 &&
- (parser.buffer[parser.buffer_pos] == ',' ||
- parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == '[' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '{' ||
- parser.buffer[parser.buffer_pos] == '}')) {
- break
- }
-
- // Check if we need to join whitespaces and breaks.
- if leading_blanks || len(whitespaces) > 0 {
- if leading_blanks {
- // Do we need to fold line breaks?
- if leading_break[0] == '\n' {
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- } else {
- s = append(s, trailing_breaks...)
- }
- } else {
- s = append(s, leading_break...)
- s = append(s, trailing_breaks...)
- }
- trailing_breaks = trailing_breaks[:0]
- leading_break = leading_break[:0]
- leading_blanks = false
- } else {
- s = append(s, whitespaces...)
- whitespaces = whitespaces[:0]
- }
- }
-
- // Copy the character.
- s = read(parser, s)
-
- end_mark = parser.mark
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- }
-
- // Is it the end?
- if !(is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos)) {
- break
- }
-
- // Consume blank characters.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos) {
- if is_blank(parser.buffer, parser.buffer_pos) {
-
- // Check for tab characters that abuse indentation.
- if leading_blanks && parser.mark.column < indent && is_tab(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a plain scalar",
- start_mark, "found a tab character that violates indentation")
- return false
- }
-
- // Consume a space or a tab character.
- if !leading_blanks {
- whitespaces = read(parser, whitespaces)
- } else {
- skip(parser)
- }
- } else {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- // Check if it is a first line break.
- if !leading_blanks {
- whitespaces = whitespaces[:0]
- leading_break = read_line(parser, leading_break)
- leading_blanks = true
- } else {
- trailing_breaks = read_line(parser, trailing_breaks)
- }
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check indentation level.
- if parser.flow_level == 0 && parser.mark.column < indent {
- break
- }
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_PLAIN_SCALAR_STYLE,
- }
-
- // Note that we change the 'simple_key_allowed' flag.
- if leading_blanks {
- parser.simple_key_allowed = true
- }
- return true
-}
-
-func yaml_parser_scan_line_comment(parser *yaml_parser_t, token_mark yaml_mark_t) bool {
- if parser.newlines > 0 {
- return true
- }
-
- var start_mark yaml_mark_t
- var text []byte
-
- for peek := 0; peek < 512; peek++ {
- if parser.unread < peek+1 && !yaml_parser_update_buffer(parser, peek+1) {
- break
- }
- if is_blank(parser.buffer, parser.buffer_pos+peek) {
- continue
- }
- if parser.buffer[parser.buffer_pos+peek] == '#' {
- seen := parser.mark.index+peek
- for {
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_breakz(parser.buffer, parser.buffer_pos) {
- if parser.mark.index >= seen {
- break
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- } else if parser.mark.index >= seen {
- if len(text) == 0 {
- start_mark = parser.mark
- }
- text = read(parser, text)
- } else {
- skip(parser)
- }
- }
- }
- break
- }
- if len(text) > 0 {
- parser.comments = append(parser.comments, yaml_comment_t{
- token_mark: token_mark,
- start_mark: start_mark,
- line: text,
- })
- }
- return true
-}
-
-func yaml_parser_scan_comments(parser *yaml_parser_t, scan_mark yaml_mark_t) bool {
- token := parser.tokens[len(parser.tokens)-1]
-
- if token.typ == yaml_FLOW_ENTRY_TOKEN && len(parser.tokens) > 1 {
- token = parser.tokens[len(parser.tokens)-2]
- }
-
- var token_mark = token.start_mark
- var start_mark yaml_mark_t
- var next_indent = parser.indent
- if next_indent < 0 {
- next_indent = 0
- }
-
- var recent_empty = false
- var first_empty = parser.newlines <= 1
-
- var line = parser.mark.line
- var column = parser.mark.column
-
- var text []byte
-
- // The foot line is the place where a comment must start to
- // still be considered as a foot of the prior content.
- // If there's some content in the currently parsed line, then
- // the foot is the line below it.
- var foot_line = -1
- if scan_mark.line > 0 {
- foot_line = parser.mark.line-parser.newlines+1
- if parser.newlines == 0 && parser.mark.column > 1 {
- foot_line++
- }
- }
-
- var peek = 0
- for ; peek < 512; peek++ {
- if parser.unread < peek+1 && !yaml_parser_update_buffer(parser, peek+1) {
- break
- }
- column++
- if is_blank(parser.buffer, parser.buffer_pos+peek) {
- continue
- }
- c := parser.buffer[parser.buffer_pos+peek]
- var close_flow = parser.flow_level > 0 && (c == ']' || c == '}')
- if close_flow || is_breakz(parser.buffer, parser.buffer_pos+peek) {
- // Got line break or terminator.
- if close_flow || !recent_empty {
- if close_flow || first_empty && (start_mark.line == foot_line && token.typ != yaml_VALUE_TOKEN || start_mark.column-1 < next_indent) {
- // This is the first empty line and there were no empty lines before,
- // so this initial part of the comment is a foot of the prior token
- // instead of being a head for the following one. Split it up.
- // Alternatively, this might also be the last comment inside a flow
- // scope, so it must be a footer.
- if len(text) > 0 {
- if start_mark.column-1 < next_indent {
- // If dedented it's unrelated to the prior token.
- token_mark = start_mark
- }
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: token_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek, line, column},
- foot: text,
- })
- scan_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- token_mark = scan_mark
- text = nil
- }
- } else {
- if len(text) > 0 && parser.buffer[parser.buffer_pos+peek] != 0 {
- text = append(text, '\n')
- }
- }
- }
- if !is_break(parser.buffer, parser.buffer_pos+peek) {
- break
- }
- first_empty = false
- recent_empty = true
- column = 0
- line++
- continue
- }
-
- if len(text) > 0 && (close_flow || column-1 < next_indent && column != start_mark.column) {
- // The comment at the different indentation is a foot of the
- // preceding data rather than a head of the upcoming one.
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: token_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek, line, column},
- foot: text,
- })
- scan_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- token_mark = scan_mark
- text = nil
- }
-
- if parser.buffer[parser.buffer_pos+peek] != '#' {
- break
- }
-
- if len(text) == 0 {
- start_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- } else {
- text = append(text, '\n')
- }
-
- recent_empty = false
-
- // Consume until after the consumed comment line.
- seen := parser.mark.index+peek
- for {
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_breakz(parser.buffer, parser.buffer_pos) {
- if parser.mark.index >= seen {
- break
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- } else if parser.mark.index >= seen {
- text = read(parser, text)
- } else {
- skip(parser)
- }
- }
-
- peek = 0
- column = 0
- line = parser.mark.line
- next_indent = parser.indent
- if next_indent < 0 {
- next_indent = 0
- }
- }
-
- if len(text) > 0 {
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: start_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek - 1, line, column},
- head: text,
- })
- }
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/sorter.go b/sesh/vendor/gopkg.in/yaml.v3/sorter.go
deleted file mode 100644
index 9210ece..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/sorter.go
+++ /dev/null
@@ -1,134 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "reflect"
- "unicode"
-)
-
-type keyList []reflect.Value
-
-func (l keyList) Len() int { return len(l) }
-func (l keyList) Swap(i, j int) { l[i], l[j] = l[j], l[i] }
-func (l keyList) Less(i, j int) bool {
- a := l[i]
- b := l[j]
- ak := a.Kind()
- bk := b.Kind()
- for (ak == reflect.Interface || ak == reflect.Ptr) && !a.IsNil() {
- a = a.Elem()
- ak = a.Kind()
- }
- for (bk == reflect.Interface || bk == reflect.Ptr) && !b.IsNil() {
- b = b.Elem()
- bk = b.Kind()
- }
- af, aok := keyFloat(a)
- bf, bok := keyFloat(b)
- if aok && bok {
- if af != bf {
- return af < bf
- }
- if ak != bk {
- return ak < bk
- }
- return numLess(a, b)
- }
- if ak != reflect.String || bk != reflect.String {
- return ak < bk
- }
- ar, br := []rune(a.String()), []rune(b.String())
- digits := false
- for i := 0; i < len(ar) && i < len(br); i++ {
- if ar[i] == br[i] {
- digits = unicode.IsDigit(ar[i])
- continue
- }
- al := unicode.IsLetter(ar[i])
- bl := unicode.IsLetter(br[i])
- if al && bl {
- return ar[i] < br[i]
- }
- if al || bl {
- if digits {
- return al
- } else {
- return bl
- }
- }
- var ai, bi int
- var an, bn int64
- if ar[i] == '0' || br[i] == '0' {
- for j := i - 1; j >= 0 && unicode.IsDigit(ar[j]); j-- {
- if ar[j] != '0' {
- an = 1
- bn = 1
- break
- }
- }
- }
- for ai = i; ai < len(ar) && unicode.IsDigit(ar[ai]); ai++ {
- an = an*10 + int64(ar[ai]-'0')
- }
- for bi = i; bi < len(br) && unicode.IsDigit(br[bi]); bi++ {
- bn = bn*10 + int64(br[bi]-'0')
- }
- if an != bn {
- return an < bn
- }
- if ai != bi {
- return ai < bi
- }
- return ar[i] < br[i]
- }
- return len(ar) < len(br)
-}
-
-// keyFloat returns a float value for v if it is a number/bool
-// and whether it is a number/bool or not.
-func keyFloat(v reflect.Value) (f float64, ok bool) {
- switch v.Kind() {
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return float64(v.Int()), true
- case reflect.Float32, reflect.Float64:
- return v.Float(), true
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return float64(v.Uint()), true
- case reflect.Bool:
- if v.Bool() {
- return 1, true
- }
- return 0, true
- }
- return 0, false
-}
-
-// numLess returns whether a < b.
-// a and b must necessarily have the same kind.
-func numLess(a, b reflect.Value) bool {
- switch a.Kind() {
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return a.Int() < b.Int()
- case reflect.Float32, reflect.Float64:
- return a.Float() < b.Float()
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return a.Uint() < b.Uint()
- case reflect.Bool:
- return !a.Bool() && b.Bool()
- }
- panic("not a number")
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/writerc.go b/sesh/vendor/gopkg.in/yaml.v3/writerc.go
deleted file mode 100644
index b8a116b..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/writerc.go
+++ /dev/null
@@ -1,48 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-// Set the writer error and return false.
-func yaml_emitter_set_writer_error(emitter *yaml_emitter_t, problem string) bool {
- emitter.error = yaml_WRITER_ERROR
- emitter.problem = problem
- return false
-}
-
-// Flush the output buffer.
-func yaml_emitter_flush(emitter *yaml_emitter_t) bool {
- if emitter.write_handler == nil {
- panic("write handler not set")
- }
-
- // Check if the buffer is empty.
- if emitter.buffer_pos == 0 {
- return true
- }
-
- if err := emitter.write_handler(emitter, emitter.buffer[:emitter.buffer_pos]); err != nil {
- return yaml_emitter_set_writer_error(emitter, "write error: "+err.Error())
- }
- emitter.buffer_pos = 0
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yaml.go b/sesh/vendor/gopkg.in/yaml.v3/yaml.go
deleted file mode 100644
index 8cec6da..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yaml.go
+++ /dev/null
@@ -1,698 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-// Package yaml implements YAML support for the Go language.
-//
-// Source code and other details for the project are available at GitHub:
-//
-// https://github.com/go-yaml/yaml
-//
-package yaml
-
-import (
- "errors"
- "fmt"
- "io"
- "reflect"
- "strings"
- "sync"
- "unicode/utf8"
-)
-
-// The Unmarshaler interface may be implemented by types to customize their
-// behavior when being unmarshaled from a YAML document.
-type Unmarshaler interface {
- UnmarshalYAML(value *Node) error
-}
-
-type obsoleteUnmarshaler interface {
- UnmarshalYAML(unmarshal func(interface{}) error) error
-}
-
-// The Marshaler interface may be implemented by types to customize their
-// behavior when being marshaled into a YAML document. The returned value
-// is marshaled in place of the original value implementing Marshaler.
-//
-// If an error is returned by MarshalYAML, the marshaling procedure stops
-// and returns with the provided error.
-type Marshaler interface {
- MarshalYAML() (interface{}, error)
-}
-
-// Unmarshal decodes the first document found within the in byte slice
-// and assigns decoded values into the out value.
-//
-// Maps and pointers (to a struct, string, int, etc) are accepted as out
-// values. If an internal pointer within a struct is not initialized,
-// the yaml package will initialize it if necessary for unmarshalling
-// the provided data. The out parameter must not be nil.
-//
-// The type of the decoded values should be compatible with the respective
-// values in out. If one or more values cannot be decoded due to a type
-// mismatches, decoding continues partially until the end of the YAML
-// content, and a *yaml.TypeError is returned with details for all
-// missed values.
-//
-// Struct fields are only unmarshalled if they are exported (have an
-// upper case first letter), and are unmarshalled using the field name
-// lowercased as the default key. Custom keys may be defined via the
-// "yaml" name in the field tag: the content preceding the first comma
-// is used as the key, and the following comma-separated options are
-// used to tweak the marshalling process (see Marshal).
-// Conflicting names result in a runtime error.
-//
-// For example:
-//
-// type T struct {
-// F int `yaml:"a,omitempty"`
-// B int
-// }
-// var t T
-// yaml.Unmarshal([]byte("a: 1\nb: 2"), &t)
-//
-// See the documentation of Marshal for the format of tags and a list of
-// supported tag options.
-//
-func Unmarshal(in []byte, out interface{}) (err error) {
- return unmarshal(in, out, false)
-}
-
-// A Decoder reads and decodes YAML values from an input stream.
-type Decoder struct {
- parser *parser
- knownFields bool
-}
-
-// NewDecoder returns a new decoder that reads from r.
-//
-// The decoder introduces its own buffering and may read
-// data from r beyond the YAML values requested.
-func NewDecoder(r io.Reader) *Decoder {
- return &Decoder{
- parser: newParserFromReader(r),
- }
-}
-
-// KnownFields ensures that the keys in decoded mappings to
-// exist as fields in the struct being decoded into.
-func (dec *Decoder) KnownFields(enable bool) {
- dec.knownFields = enable
-}
-
-// Decode reads the next YAML-encoded value from its input
-// and stores it in the value pointed to by v.
-//
-// See the documentation for Unmarshal for details about the
-// conversion of YAML into a Go value.
-func (dec *Decoder) Decode(v interface{}) (err error) {
- d := newDecoder()
- d.knownFields = dec.knownFields
- defer handleErr(&err)
- node := dec.parser.parse()
- if node == nil {
- return io.EOF
- }
- out := reflect.ValueOf(v)
- if out.Kind() == reflect.Ptr && !out.IsNil() {
- out = out.Elem()
- }
- d.unmarshal(node, out)
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-// Decode decodes the node and stores its data into the value pointed to by v.
-//
-// See the documentation for Unmarshal for details about the
-// conversion of YAML into a Go value.
-func (n *Node) Decode(v interface{}) (err error) {
- d := newDecoder()
- defer handleErr(&err)
- out := reflect.ValueOf(v)
- if out.Kind() == reflect.Ptr && !out.IsNil() {
- out = out.Elem()
- }
- d.unmarshal(n, out)
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-func unmarshal(in []byte, out interface{}, strict bool) (err error) {
- defer handleErr(&err)
- d := newDecoder()
- p := newParser(in)
- defer p.destroy()
- node := p.parse()
- if node != nil {
- v := reflect.ValueOf(out)
- if v.Kind() == reflect.Ptr && !v.IsNil() {
- v = v.Elem()
- }
- d.unmarshal(node, v)
- }
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-// Marshal serializes the value provided into a YAML document. The structure
-// of the generated document will reflect the structure of the value itself.
-// Maps and pointers (to struct, string, int, etc) are accepted as the in value.
-//
-// Struct fields are only marshalled if they are exported (have an upper case
-// first letter), and are marshalled using the field name lowercased as the
-// default key. Custom keys may be defined via the "yaml" name in the field
-// tag: the content preceding the first comma is used as the key, and the
-// following comma-separated options are used to tweak the marshalling process.
-// Conflicting names result in a runtime error.
-//
-// The field tag format accepted is:
-//
-// `(...) yaml:"[][,[,]]" (...)`
-//
-// The following flags are currently supported:
-//
-// omitempty Only include the field if it's not set to the zero
-// value for the type or to empty slices or maps.
-// Zero valued structs will be omitted if all their public
-// fields are zero, unless they implement an IsZero
-// method (see the IsZeroer interface type), in which
-// case the field will be excluded if IsZero returns true.
-//
-// flow Marshal using a flow style (useful for structs,
-// sequences and maps).
-//
-// inline Inline the field, which must be a struct or a map,
-// causing all of its fields or keys to be processed as if
-// they were part of the outer struct. For maps, keys must
-// not conflict with the yaml keys of other struct fields.
-//
-// In addition, if the key is "-", the field is ignored.
-//
-// For example:
-//
-// type T struct {
-// F int `yaml:"a,omitempty"`
-// B int
-// }
-// yaml.Marshal(&T{B: 2}) // Returns "b: 2\n"
-// yaml.Marshal(&T{F: 1}} // Returns "a: 1\nb: 0\n"
-//
-func Marshal(in interface{}) (out []byte, err error) {
- defer handleErr(&err)
- e := newEncoder()
- defer e.destroy()
- e.marshalDoc("", reflect.ValueOf(in))
- e.finish()
- out = e.out
- return
-}
-
-// An Encoder writes YAML values to an output stream.
-type Encoder struct {
- encoder *encoder
-}
-
-// NewEncoder returns a new encoder that writes to w.
-// The Encoder should be closed after use to flush all data
-// to w.
-func NewEncoder(w io.Writer) *Encoder {
- return &Encoder{
- encoder: newEncoderWithWriter(w),
- }
-}
-
-// Encode writes the YAML encoding of v to the stream.
-// If multiple items are encoded to the stream, the
-// second and subsequent document will be preceded
-// with a "---" document separator, but the first will not.
-//
-// See the documentation for Marshal for details about the conversion of Go
-// values to YAML.
-func (e *Encoder) Encode(v interface{}) (err error) {
- defer handleErr(&err)
- e.encoder.marshalDoc("", reflect.ValueOf(v))
- return nil
-}
-
-// Encode encodes value v and stores its representation in n.
-//
-// See the documentation for Marshal for details about the
-// conversion of Go values into YAML.
-func (n *Node) Encode(v interface{}) (err error) {
- defer handleErr(&err)
- e := newEncoder()
- defer e.destroy()
- e.marshalDoc("", reflect.ValueOf(v))
- e.finish()
- p := newParser(e.out)
- p.textless = true
- defer p.destroy()
- doc := p.parse()
- *n = *doc.Content[0]
- return nil
-}
-
-// SetIndent changes the used indentation used when encoding.
-func (e *Encoder) SetIndent(spaces int) {
- if spaces < 0 {
- panic("yaml: cannot indent to a negative number of spaces")
- }
- e.encoder.indent = spaces
-}
-
-// Close closes the encoder by writing any remaining data.
-// It does not write a stream terminating string "...".
-func (e *Encoder) Close() (err error) {
- defer handleErr(&err)
- e.encoder.finish()
- return nil
-}
-
-func handleErr(err *error) {
- if v := recover(); v != nil {
- if e, ok := v.(yamlError); ok {
- *err = e.err
- } else {
- panic(v)
- }
- }
-}
-
-type yamlError struct {
- err error
-}
-
-func fail(err error) {
- panic(yamlError{err})
-}
-
-func failf(format string, args ...interface{}) {
- panic(yamlError{fmt.Errorf("yaml: "+format, args...)})
-}
-
-// A TypeError is returned by Unmarshal when one or more fields in
-// the YAML document cannot be properly decoded into the requested
-// types. When this error is returned, the value is still
-// unmarshaled partially.
-type TypeError struct {
- Errors []string
-}
-
-func (e *TypeError) Error() string {
- return fmt.Sprintf("yaml: unmarshal errors:\n %s", strings.Join(e.Errors, "\n "))
-}
-
-type Kind uint32
-
-const (
- DocumentNode Kind = 1 << iota
- SequenceNode
- MappingNode
- ScalarNode
- AliasNode
-)
-
-type Style uint32
-
-const (
- TaggedStyle Style = 1 << iota
- DoubleQuotedStyle
- SingleQuotedStyle
- LiteralStyle
- FoldedStyle
- FlowStyle
-)
-
-// Node represents an element in the YAML document hierarchy. While documents
-// are typically encoded and decoded into higher level types, such as structs
-// and maps, Node is an intermediate representation that allows detailed
-// control over the content being decoded or encoded.
-//
-// It's worth noting that although Node offers access into details such as
-// line numbers, colums, and comments, the content when re-encoded will not
-// have its original textual representation preserved. An effort is made to
-// render the data plesantly, and to preserve comments near the data they
-// describe, though.
-//
-// Values that make use of the Node type interact with the yaml package in the
-// same way any other type would do, by encoding and decoding yaml data
-// directly or indirectly into them.
-//
-// For example:
-//
-// var person struct {
-// Name string
-// Address yaml.Node
-// }
-// err := yaml.Unmarshal(data, &person)
-//
-// Or by itself:
-//
-// var person Node
-// err := yaml.Unmarshal(data, &person)
-//
-type Node struct {
- // Kind defines whether the node is a document, a mapping, a sequence,
- // a scalar value, or an alias to another node. The specific data type of
- // scalar nodes may be obtained via the ShortTag and LongTag methods.
- Kind Kind
-
- // Style allows customizing the apperance of the node in the tree.
- Style Style
-
- // Tag holds the YAML tag defining the data type for the value.
- // When decoding, this field will always be set to the resolved tag,
- // even when it wasn't explicitly provided in the YAML content.
- // When encoding, if this field is unset the value type will be
- // implied from the node properties, and if it is set, it will only
- // be serialized into the representation if TaggedStyle is used or
- // the implicit tag diverges from the provided one.
- Tag string
-
- // Value holds the unescaped and unquoted represenation of the value.
- Value string
-
- // Anchor holds the anchor name for this node, which allows aliases to point to it.
- Anchor string
-
- // Alias holds the node that this alias points to. Only valid when Kind is AliasNode.
- Alias *Node
-
- // Content holds contained nodes for documents, mappings, and sequences.
- Content []*Node
-
- // HeadComment holds any comments in the lines preceding the node and
- // not separated by an empty line.
- HeadComment string
-
- // LineComment holds any comments at the end of the line where the node is in.
- LineComment string
-
- // FootComment holds any comments following the node and before empty lines.
- FootComment string
-
- // Line and Column hold the node position in the decoded YAML text.
- // These fields are not respected when encoding the node.
- Line int
- Column int
-}
-
-// IsZero returns whether the node has all of its fields unset.
-func (n *Node) IsZero() bool {
- return n.Kind == 0 && n.Style == 0 && n.Tag == "" && n.Value == "" && n.Anchor == "" && n.Alias == nil && n.Content == nil &&
- n.HeadComment == "" && n.LineComment == "" && n.FootComment == "" && n.Line == 0 && n.Column == 0
-}
-
-
-// LongTag returns the long form of the tag that indicates the data type for
-// the node. If the Tag field isn't explicitly defined, one will be computed
-// based on the node properties.
-func (n *Node) LongTag() string {
- return longTag(n.ShortTag())
-}
-
-// ShortTag returns the short form of the YAML tag that indicates data type for
-// the node. If the Tag field isn't explicitly defined, one will be computed
-// based on the node properties.
-func (n *Node) ShortTag() string {
- if n.indicatedString() {
- return strTag
- }
- if n.Tag == "" || n.Tag == "!" {
- switch n.Kind {
- case MappingNode:
- return mapTag
- case SequenceNode:
- return seqTag
- case AliasNode:
- if n.Alias != nil {
- return n.Alias.ShortTag()
- }
- case ScalarNode:
- tag, _ := resolve("", n.Value)
- return tag
- case 0:
- // Special case to make the zero value convenient.
- if n.IsZero() {
- return nullTag
- }
- }
- return ""
- }
- return shortTag(n.Tag)
-}
-
-func (n *Node) indicatedString() bool {
- return n.Kind == ScalarNode &&
- (shortTag(n.Tag) == strTag ||
- (n.Tag == "" || n.Tag == "!") && n.Style&(SingleQuotedStyle|DoubleQuotedStyle|LiteralStyle|FoldedStyle) != 0)
-}
-
-// SetString is a convenience function that sets the node to a string value
-// and defines its style in a pleasant way depending on its content.
-func (n *Node) SetString(s string) {
- n.Kind = ScalarNode
- if utf8.ValidString(s) {
- n.Value = s
- n.Tag = strTag
- } else {
- n.Value = encodeBase64(s)
- n.Tag = binaryTag
- }
- if strings.Contains(n.Value, "\n") {
- n.Style = LiteralStyle
- }
-}
-
-// --------------------------------------------------------------------------
-// Maintain a mapping of keys to structure field indexes
-
-// The code in this section was copied from mgo/bson.
-
-// structInfo holds details for the serialization of fields of
-// a given struct.
-type structInfo struct {
- FieldsMap map[string]fieldInfo
- FieldsList []fieldInfo
-
- // InlineMap is the number of the field in the struct that
- // contains an ,inline map, or -1 if there's none.
- InlineMap int
-
- // InlineUnmarshalers holds indexes to inlined fields that
- // contain unmarshaler values.
- InlineUnmarshalers [][]int
-}
-
-type fieldInfo struct {
- Key string
- Num int
- OmitEmpty bool
- Flow bool
- // Id holds the unique field identifier, so we can cheaply
- // check for field duplicates without maintaining an extra map.
- Id int
-
- // Inline holds the field index if the field is part of an inlined struct.
- Inline []int
-}
-
-var structMap = make(map[reflect.Type]*structInfo)
-var fieldMapMutex sync.RWMutex
-var unmarshalerType reflect.Type
-
-func init() {
- var v Unmarshaler
- unmarshalerType = reflect.ValueOf(&v).Elem().Type()
-}
-
-func getStructInfo(st reflect.Type) (*structInfo, error) {
- fieldMapMutex.RLock()
- sinfo, found := structMap[st]
- fieldMapMutex.RUnlock()
- if found {
- return sinfo, nil
- }
-
- n := st.NumField()
- fieldsMap := make(map[string]fieldInfo)
- fieldsList := make([]fieldInfo, 0, n)
- inlineMap := -1
- inlineUnmarshalers := [][]int(nil)
- for i := 0; i != n; i++ {
- field := st.Field(i)
- if field.PkgPath != "" && !field.Anonymous {
- continue // Private field
- }
-
- info := fieldInfo{Num: i}
-
- tag := field.Tag.Get("yaml")
- if tag == "" && strings.Index(string(field.Tag), ":") < 0 {
- tag = string(field.Tag)
- }
- if tag == "-" {
- continue
- }
-
- inline := false
- fields := strings.Split(tag, ",")
- if len(fields) > 1 {
- for _, flag := range fields[1:] {
- switch flag {
- case "omitempty":
- info.OmitEmpty = true
- case "flow":
- info.Flow = true
- case "inline":
- inline = true
- default:
- return nil, errors.New(fmt.Sprintf("unsupported flag %q in tag %q of type %s", flag, tag, st))
- }
- }
- tag = fields[0]
- }
-
- if inline {
- switch field.Type.Kind() {
- case reflect.Map:
- if inlineMap >= 0 {
- return nil, errors.New("multiple ,inline maps in struct " + st.String())
- }
- if field.Type.Key() != reflect.TypeOf("") {
- return nil, errors.New("option ,inline needs a map with string keys in struct " + st.String())
- }
- inlineMap = info.Num
- case reflect.Struct, reflect.Ptr:
- ftype := field.Type
- for ftype.Kind() == reflect.Ptr {
- ftype = ftype.Elem()
- }
- if ftype.Kind() != reflect.Struct {
- return nil, errors.New("option ,inline may only be used on a struct or map field")
- }
- if reflect.PtrTo(ftype).Implements(unmarshalerType) {
- inlineUnmarshalers = append(inlineUnmarshalers, []int{i})
- } else {
- sinfo, err := getStructInfo(ftype)
- if err != nil {
- return nil, err
- }
- for _, index := range sinfo.InlineUnmarshalers {
- inlineUnmarshalers = append(inlineUnmarshalers, append([]int{i}, index...))
- }
- for _, finfo := range sinfo.FieldsList {
- if _, found := fieldsMap[finfo.Key]; found {
- msg := "duplicated key '" + finfo.Key + "' in struct " + st.String()
- return nil, errors.New(msg)
- }
- if finfo.Inline == nil {
- finfo.Inline = []int{i, finfo.Num}
- } else {
- finfo.Inline = append([]int{i}, finfo.Inline...)
- }
- finfo.Id = len(fieldsList)
- fieldsMap[finfo.Key] = finfo
- fieldsList = append(fieldsList, finfo)
- }
- }
- default:
- return nil, errors.New("option ,inline may only be used on a struct or map field")
- }
- continue
- }
-
- if tag != "" {
- info.Key = tag
- } else {
- info.Key = strings.ToLower(field.Name)
- }
-
- if _, found = fieldsMap[info.Key]; found {
- msg := "duplicated key '" + info.Key + "' in struct " + st.String()
- return nil, errors.New(msg)
- }
-
- info.Id = len(fieldsList)
- fieldsList = append(fieldsList, info)
- fieldsMap[info.Key] = info
- }
-
- sinfo = &structInfo{
- FieldsMap: fieldsMap,
- FieldsList: fieldsList,
- InlineMap: inlineMap,
- InlineUnmarshalers: inlineUnmarshalers,
- }
-
- fieldMapMutex.Lock()
- structMap[st] = sinfo
- fieldMapMutex.Unlock()
- return sinfo, nil
-}
-
-// IsZeroer is used to check whether an object is zero to
-// determine whether it should be omitted when marshaling
-// with the omitempty flag. One notable implementation
-// is time.Time.
-type IsZeroer interface {
- IsZero() bool
-}
-
-func isZero(v reflect.Value) bool {
- kind := v.Kind()
- if z, ok := v.Interface().(IsZeroer); ok {
- if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
- return true
- }
- return z.IsZero()
- }
- switch kind {
- case reflect.String:
- return len(v.String()) == 0
- case reflect.Interface, reflect.Ptr:
- return v.IsNil()
- case reflect.Slice:
- return v.Len() == 0
- case reflect.Map:
- return v.Len() == 0
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return v.Int() == 0
- case reflect.Float32, reflect.Float64:
- return v.Float() == 0
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return v.Uint() == 0
- case reflect.Bool:
- return !v.Bool()
- case reflect.Struct:
- vt := v.Type()
- for i := v.NumField() - 1; i >= 0; i-- {
- if vt.Field(i).PkgPath != "" {
- continue // Private field
- }
- if !isZero(v.Field(i)) {
- return false
- }
- }
- return true
- }
- return false
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yamlh.go b/sesh/vendor/gopkg.in/yaml.v3/yamlh.go
deleted file mode 100644
index 7c6d007..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yamlh.go
+++ /dev/null
@@ -1,807 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "fmt"
- "io"
-)
-
-// The version directive data.
-type yaml_version_directive_t struct {
- major int8 // The major version number.
- minor int8 // The minor version number.
-}
-
-// The tag directive data.
-type yaml_tag_directive_t struct {
- handle []byte // The tag handle.
- prefix []byte // The tag prefix.
-}
-
-type yaml_encoding_t int
-
-// The stream encoding.
-const (
- // Let the parser choose the encoding.
- yaml_ANY_ENCODING yaml_encoding_t = iota
-
- yaml_UTF8_ENCODING // The default UTF-8 encoding.
- yaml_UTF16LE_ENCODING // The UTF-16-LE encoding with BOM.
- yaml_UTF16BE_ENCODING // The UTF-16-BE encoding with BOM.
-)
-
-type yaml_break_t int
-
-// Line break types.
-const (
- // Let the parser choose the break type.
- yaml_ANY_BREAK yaml_break_t = iota
-
- yaml_CR_BREAK // Use CR for line breaks (Mac style).
- yaml_LN_BREAK // Use LN for line breaks (Unix style).
- yaml_CRLN_BREAK // Use CR LN for line breaks (DOS style).
-)
-
-type yaml_error_type_t int
-
-// Many bad things could happen with the parser and emitter.
-const (
- // No error is produced.
- yaml_NO_ERROR yaml_error_type_t = iota
-
- yaml_MEMORY_ERROR // Cannot allocate or reallocate a block of memory.
- yaml_READER_ERROR // Cannot read or decode the input stream.
- yaml_SCANNER_ERROR // Cannot scan the input stream.
- yaml_PARSER_ERROR // Cannot parse the input stream.
- yaml_COMPOSER_ERROR // Cannot compose a YAML document.
- yaml_WRITER_ERROR // Cannot write to the output stream.
- yaml_EMITTER_ERROR // Cannot emit a YAML stream.
-)
-
-// The pointer position.
-type yaml_mark_t struct {
- index int // The position index.
- line int // The position line.
- column int // The position column.
-}
-
-// Node Styles
-
-type yaml_style_t int8
-
-type yaml_scalar_style_t yaml_style_t
-
-// Scalar styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_SCALAR_STYLE yaml_scalar_style_t = 0
-
- yaml_PLAIN_SCALAR_STYLE yaml_scalar_style_t = 1 << iota // The plain scalar style.
- yaml_SINGLE_QUOTED_SCALAR_STYLE // The single-quoted scalar style.
- yaml_DOUBLE_QUOTED_SCALAR_STYLE // The double-quoted scalar style.
- yaml_LITERAL_SCALAR_STYLE // The literal scalar style.
- yaml_FOLDED_SCALAR_STYLE // The folded scalar style.
-)
-
-type yaml_sequence_style_t yaml_style_t
-
-// Sequence styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_SEQUENCE_STYLE yaml_sequence_style_t = iota
-
- yaml_BLOCK_SEQUENCE_STYLE // The block sequence style.
- yaml_FLOW_SEQUENCE_STYLE // The flow sequence style.
-)
-
-type yaml_mapping_style_t yaml_style_t
-
-// Mapping styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_MAPPING_STYLE yaml_mapping_style_t = iota
-
- yaml_BLOCK_MAPPING_STYLE // The block mapping style.
- yaml_FLOW_MAPPING_STYLE // The flow mapping style.
-)
-
-// Tokens
-
-type yaml_token_type_t int
-
-// Token types.
-const (
- // An empty token.
- yaml_NO_TOKEN yaml_token_type_t = iota
-
- yaml_STREAM_START_TOKEN // A STREAM-START token.
- yaml_STREAM_END_TOKEN // A STREAM-END token.
-
- yaml_VERSION_DIRECTIVE_TOKEN // A VERSION-DIRECTIVE token.
- yaml_TAG_DIRECTIVE_TOKEN // A TAG-DIRECTIVE token.
- yaml_DOCUMENT_START_TOKEN // A DOCUMENT-START token.
- yaml_DOCUMENT_END_TOKEN // A DOCUMENT-END token.
-
- yaml_BLOCK_SEQUENCE_START_TOKEN // A BLOCK-SEQUENCE-START token.
- yaml_BLOCK_MAPPING_START_TOKEN // A BLOCK-SEQUENCE-END token.
- yaml_BLOCK_END_TOKEN // A BLOCK-END token.
-
- yaml_FLOW_SEQUENCE_START_TOKEN // A FLOW-SEQUENCE-START token.
- yaml_FLOW_SEQUENCE_END_TOKEN // A FLOW-SEQUENCE-END token.
- yaml_FLOW_MAPPING_START_TOKEN // A FLOW-MAPPING-START token.
- yaml_FLOW_MAPPING_END_TOKEN // A FLOW-MAPPING-END token.
-
- yaml_BLOCK_ENTRY_TOKEN // A BLOCK-ENTRY token.
- yaml_FLOW_ENTRY_TOKEN // A FLOW-ENTRY token.
- yaml_KEY_TOKEN // A KEY token.
- yaml_VALUE_TOKEN // A VALUE token.
-
- yaml_ALIAS_TOKEN // An ALIAS token.
- yaml_ANCHOR_TOKEN // An ANCHOR token.
- yaml_TAG_TOKEN // A TAG token.
- yaml_SCALAR_TOKEN // A SCALAR token.
-)
-
-func (tt yaml_token_type_t) String() string {
- switch tt {
- case yaml_NO_TOKEN:
- return "yaml_NO_TOKEN"
- case yaml_STREAM_START_TOKEN:
- return "yaml_STREAM_START_TOKEN"
- case yaml_STREAM_END_TOKEN:
- return "yaml_STREAM_END_TOKEN"
- case yaml_VERSION_DIRECTIVE_TOKEN:
- return "yaml_VERSION_DIRECTIVE_TOKEN"
- case yaml_TAG_DIRECTIVE_TOKEN:
- return "yaml_TAG_DIRECTIVE_TOKEN"
- case yaml_DOCUMENT_START_TOKEN:
- return "yaml_DOCUMENT_START_TOKEN"
- case yaml_DOCUMENT_END_TOKEN:
- return "yaml_DOCUMENT_END_TOKEN"
- case yaml_BLOCK_SEQUENCE_START_TOKEN:
- return "yaml_BLOCK_SEQUENCE_START_TOKEN"
- case yaml_BLOCK_MAPPING_START_TOKEN:
- return "yaml_BLOCK_MAPPING_START_TOKEN"
- case yaml_BLOCK_END_TOKEN:
- return "yaml_BLOCK_END_TOKEN"
- case yaml_FLOW_SEQUENCE_START_TOKEN:
- return "yaml_FLOW_SEQUENCE_START_TOKEN"
- case yaml_FLOW_SEQUENCE_END_TOKEN:
- return "yaml_FLOW_SEQUENCE_END_TOKEN"
- case yaml_FLOW_MAPPING_START_TOKEN:
- return "yaml_FLOW_MAPPING_START_TOKEN"
- case yaml_FLOW_MAPPING_END_TOKEN:
- return "yaml_FLOW_MAPPING_END_TOKEN"
- case yaml_BLOCK_ENTRY_TOKEN:
- return "yaml_BLOCK_ENTRY_TOKEN"
- case yaml_FLOW_ENTRY_TOKEN:
- return "yaml_FLOW_ENTRY_TOKEN"
- case yaml_KEY_TOKEN:
- return "yaml_KEY_TOKEN"
- case yaml_VALUE_TOKEN:
- return "yaml_VALUE_TOKEN"
- case yaml_ALIAS_TOKEN:
- return "yaml_ALIAS_TOKEN"
- case yaml_ANCHOR_TOKEN:
- return "yaml_ANCHOR_TOKEN"
- case yaml_TAG_TOKEN:
- return "yaml_TAG_TOKEN"
- case yaml_SCALAR_TOKEN:
- return "yaml_SCALAR_TOKEN"
- }
- return ""
-}
-
-// The token structure.
-type yaml_token_t struct {
- // The token type.
- typ yaml_token_type_t
-
- // The start/end of the token.
- start_mark, end_mark yaml_mark_t
-
- // The stream encoding (for yaml_STREAM_START_TOKEN).
- encoding yaml_encoding_t
-
- // The alias/anchor/scalar value or tag/tag directive handle
- // (for yaml_ALIAS_TOKEN, yaml_ANCHOR_TOKEN, yaml_SCALAR_TOKEN, yaml_TAG_TOKEN, yaml_TAG_DIRECTIVE_TOKEN).
- value []byte
-
- // The tag suffix (for yaml_TAG_TOKEN).
- suffix []byte
-
- // The tag directive prefix (for yaml_TAG_DIRECTIVE_TOKEN).
- prefix []byte
-
- // The scalar style (for yaml_SCALAR_TOKEN).
- style yaml_scalar_style_t
-
- // The version directive major/minor (for yaml_VERSION_DIRECTIVE_TOKEN).
- major, minor int8
-}
-
-// Events
-
-type yaml_event_type_t int8
-
-// Event types.
-const (
- // An empty event.
- yaml_NO_EVENT yaml_event_type_t = iota
-
- yaml_STREAM_START_EVENT // A STREAM-START event.
- yaml_STREAM_END_EVENT // A STREAM-END event.
- yaml_DOCUMENT_START_EVENT // A DOCUMENT-START event.
- yaml_DOCUMENT_END_EVENT // A DOCUMENT-END event.
- yaml_ALIAS_EVENT // An ALIAS event.
- yaml_SCALAR_EVENT // A SCALAR event.
- yaml_SEQUENCE_START_EVENT // A SEQUENCE-START event.
- yaml_SEQUENCE_END_EVENT // A SEQUENCE-END event.
- yaml_MAPPING_START_EVENT // A MAPPING-START event.
- yaml_MAPPING_END_EVENT // A MAPPING-END event.
- yaml_TAIL_COMMENT_EVENT
-)
-
-var eventStrings = []string{
- yaml_NO_EVENT: "none",
- yaml_STREAM_START_EVENT: "stream start",
- yaml_STREAM_END_EVENT: "stream end",
- yaml_DOCUMENT_START_EVENT: "document start",
- yaml_DOCUMENT_END_EVENT: "document end",
- yaml_ALIAS_EVENT: "alias",
- yaml_SCALAR_EVENT: "scalar",
- yaml_SEQUENCE_START_EVENT: "sequence start",
- yaml_SEQUENCE_END_EVENT: "sequence end",
- yaml_MAPPING_START_EVENT: "mapping start",
- yaml_MAPPING_END_EVENT: "mapping end",
- yaml_TAIL_COMMENT_EVENT: "tail comment",
-}
-
-func (e yaml_event_type_t) String() string {
- if e < 0 || int(e) >= len(eventStrings) {
- return fmt.Sprintf("unknown event %d", e)
- }
- return eventStrings[e]
-}
-
-// The event structure.
-type yaml_event_t struct {
-
- // The event type.
- typ yaml_event_type_t
-
- // The start and end of the event.
- start_mark, end_mark yaml_mark_t
-
- // The document encoding (for yaml_STREAM_START_EVENT).
- encoding yaml_encoding_t
-
- // The version directive (for yaml_DOCUMENT_START_EVENT).
- version_directive *yaml_version_directive_t
-
- // The list of tag directives (for yaml_DOCUMENT_START_EVENT).
- tag_directives []yaml_tag_directive_t
-
- // The comments
- head_comment []byte
- line_comment []byte
- foot_comment []byte
- tail_comment []byte
-
- // The anchor (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT, yaml_ALIAS_EVENT).
- anchor []byte
-
- // The tag (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT).
- tag []byte
-
- // The scalar value (for yaml_SCALAR_EVENT).
- value []byte
-
- // Is the document start/end indicator implicit, or the tag optional?
- // (for yaml_DOCUMENT_START_EVENT, yaml_DOCUMENT_END_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT, yaml_SCALAR_EVENT).
- implicit bool
-
- // Is the tag optional for any non-plain style? (for yaml_SCALAR_EVENT).
- quoted_implicit bool
-
- // The style (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT).
- style yaml_style_t
-}
-
-func (e *yaml_event_t) scalar_style() yaml_scalar_style_t { return yaml_scalar_style_t(e.style) }
-func (e *yaml_event_t) sequence_style() yaml_sequence_style_t { return yaml_sequence_style_t(e.style) }
-func (e *yaml_event_t) mapping_style() yaml_mapping_style_t { return yaml_mapping_style_t(e.style) }
-
-// Nodes
-
-const (
- yaml_NULL_TAG = "tag:yaml.org,2002:null" // The tag !!null with the only possible value: null.
- yaml_BOOL_TAG = "tag:yaml.org,2002:bool" // The tag !!bool with the values: true and false.
- yaml_STR_TAG = "tag:yaml.org,2002:str" // The tag !!str for string values.
- yaml_INT_TAG = "tag:yaml.org,2002:int" // The tag !!int for integer values.
- yaml_FLOAT_TAG = "tag:yaml.org,2002:float" // The tag !!float for float values.
- yaml_TIMESTAMP_TAG = "tag:yaml.org,2002:timestamp" // The tag !!timestamp for date and time values.
-
- yaml_SEQ_TAG = "tag:yaml.org,2002:seq" // The tag !!seq is used to denote sequences.
- yaml_MAP_TAG = "tag:yaml.org,2002:map" // The tag !!map is used to denote mapping.
-
- // Not in original libyaml.
- yaml_BINARY_TAG = "tag:yaml.org,2002:binary"
- yaml_MERGE_TAG = "tag:yaml.org,2002:merge"
-
- yaml_DEFAULT_SCALAR_TAG = yaml_STR_TAG // The default scalar tag is !!str.
- yaml_DEFAULT_SEQUENCE_TAG = yaml_SEQ_TAG // The default sequence tag is !!seq.
- yaml_DEFAULT_MAPPING_TAG = yaml_MAP_TAG // The default mapping tag is !!map.
-)
-
-type yaml_node_type_t int
-
-// Node types.
-const (
- // An empty node.
- yaml_NO_NODE yaml_node_type_t = iota
-
- yaml_SCALAR_NODE // A scalar node.
- yaml_SEQUENCE_NODE // A sequence node.
- yaml_MAPPING_NODE // A mapping node.
-)
-
-// An element of a sequence node.
-type yaml_node_item_t int
-
-// An element of a mapping node.
-type yaml_node_pair_t struct {
- key int // The key of the element.
- value int // The value of the element.
-}
-
-// The node structure.
-type yaml_node_t struct {
- typ yaml_node_type_t // The node type.
- tag []byte // The node tag.
-
- // The node data.
-
- // The scalar parameters (for yaml_SCALAR_NODE).
- scalar struct {
- value []byte // The scalar value.
- length int // The length of the scalar value.
- style yaml_scalar_style_t // The scalar style.
- }
-
- // The sequence parameters (for YAML_SEQUENCE_NODE).
- sequence struct {
- items_data []yaml_node_item_t // The stack of sequence items.
- style yaml_sequence_style_t // The sequence style.
- }
-
- // The mapping parameters (for yaml_MAPPING_NODE).
- mapping struct {
- pairs_data []yaml_node_pair_t // The stack of mapping pairs (key, value).
- pairs_start *yaml_node_pair_t // The beginning of the stack.
- pairs_end *yaml_node_pair_t // The end of the stack.
- pairs_top *yaml_node_pair_t // The top of the stack.
- style yaml_mapping_style_t // The mapping style.
- }
-
- start_mark yaml_mark_t // The beginning of the node.
- end_mark yaml_mark_t // The end of the node.
-
-}
-
-// The document structure.
-type yaml_document_t struct {
-
- // The document nodes.
- nodes []yaml_node_t
-
- // The version directive.
- version_directive *yaml_version_directive_t
-
- // The list of tag directives.
- tag_directives_data []yaml_tag_directive_t
- tag_directives_start int // The beginning of the tag directives list.
- tag_directives_end int // The end of the tag directives list.
-
- start_implicit int // Is the document start indicator implicit?
- end_implicit int // Is the document end indicator implicit?
-
- // The start/end of the document.
- start_mark, end_mark yaml_mark_t
-}
-
-// The prototype of a read handler.
-//
-// The read handler is called when the parser needs to read more bytes from the
-// source. The handler should write not more than size bytes to the buffer.
-// The number of written bytes should be set to the size_read variable.
-//
-// [in,out] data A pointer to an application data specified by
-// yaml_parser_set_input().
-// [out] buffer The buffer to write the data from the source.
-// [in] size The size of the buffer.
-// [out] size_read The actual number of bytes read from the source.
-//
-// On success, the handler should return 1. If the handler failed,
-// the returned value should be 0. On EOF, the handler should set the
-// size_read to 0 and return 1.
-type yaml_read_handler_t func(parser *yaml_parser_t, buffer []byte) (n int, err error)
-
-// This structure holds information about a potential simple key.
-type yaml_simple_key_t struct {
- possible bool // Is a simple key possible?
- required bool // Is a simple key required?
- token_number int // The number of the token.
- mark yaml_mark_t // The position mark.
-}
-
-// The states of the parser.
-type yaml_parser_state_t int
-
-const (
- yaml_PARSE_STREAM_START_STATE yaml_parser_state_t = iota
-
- yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE // Expect the beginning of an implicit document.
- yaml_PARSE_DOCUMENT_START_STATE // Expect DOCUMENT-START.
- yaml_PARSE_DOCUMENT_CONTENT_STATE // Expect the content of a document.
- yaml_PARSE_DOCUMENT_END_STATE // Expect DOCUMENT-END.
- yaml_PARSE_BLOCK_NODE_STATE // Expect a block node.
- yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE // Expect a block node or indentless sequence.
- yaml_PARSE_FLOW_NODE_STATE // Expect a flow node.
- yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE // Expect the first entry of a block sequence.
- yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE // Expect an entry of a block sequence.
- yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE // Expect an entry of an indentless sequence.
- yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE // Expect the first key of a block mapping.
- yaml_PARSE_BLOCK_MAPPING_KEY_STATE // Expect a block mapping key.
- yaml_PARSE_BLOCK_MAPPING_VALUE_STATE // Expect a block mapping value.
- yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE // Expect the first entry of a flow sequence.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE // Expect an entry of a flow sequence.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE // Expect a key of an ordered mapping.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE // Expect a value of an ordered mapping.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE // Expect the and of an ordered mapping entry.
- yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE // Expect the first key of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_KEY_STATE // Expect a key of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_VALUE_STATE // Expect a value of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE // Expect an empty value of a flow mapping.
- yaml_PARSE_END_STATE // Expect nothing.
-)
-
-func (ps yaml_parser_state_t) String() string {
- switch ps {
- case yaml_PARSE_STREAM_START_STATE:
- return "yaml_PARSE_STREAM_START_STATE"
- case yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE:
- return "yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE"
- case yaml_PARSE_DOCUMENT_START_STATE:
- return "yaml_PARSE_DOCUMENT_START_STATE"
- case yaml_PARSE_DOCUMENT_CONTENT_STATE:
- return "yaml_PARSE_DOCUMENT_CONTENT_STATE"
- case yaml_PARSE_DOCUMENT_END_STATE:
- return "yaml_PARSE_DOCUMENT_END_STATE"
- case yaml_PARSE_BLOCK_NODE_STATE:
- return "yaml_PARSE_BLOCK_NODE_STATE"
- case yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE:
- return "yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE"
- case yaml_PARSE_FLOW_NODE_STATE:
- return "yaml_PARSE_FLOW_NODE_STATE"
- case yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE:
- return "yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE"
- case yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_KEY_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_KEY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_VALUE_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE"
- case yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE:
- return "yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE"
- case yaml_PARSE_FLOW_MAPPING_KEY_STATE:
- return "yaml_PARSE_FLOW_MAPPING_KEY_STATE"
- case yaml_PARSE_FLOW_MAPPING_VALUE_STATE:
- return "yaml_PARSE_FLOW_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE:
- return "yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE"
- case yaml_PARSE_END_STATE:
- return "yaml_PARSE_END_STATE"
- }
- return ""
-}
-
-// This structure holds aliases data.
-type yaml_alias_data_t struct {
- anchor []byte // The anchor.
- index int // The node id.
- mark yaml_mark_t // The anchor mark.
-}
-
-// The parser structure.
-//
-// All members are internal. Manage the structure using the
-// yaml_parser_ family of functions.
-type yaml_parser_t struct {
-
- // Error handling
-
- error yaml_error_type_t // Error type.
-
- problem string // Error description.
-
- // The byte about which the problem occurred.
- problem_offset int
- problem_value int
- problem_mark yaml_mark_t
-
- // The error context.
- context string
- context_mark yaml_mark_t
-
- // Reader stuff
-
- read_handler yaml_read_handler_t // Read handler.
-
- input_reader io.Reader // File input data.
- input []byte // String input data.
- input_pos int
-
- eof bool // EOF flag
-
- buffer []byte // The working buffer.
- buffer_pos int // The current position of the buffer.
-
- unread int // The number of unread characters in the buffer.
-
- newlines int // The number of line breaks since last non-break/non-blank character
-
- raw_buffer []byte // The raw buffer.
- raw_buffer_pos int // The current position of the buffer.
-
- encoding yaml_encoding_t // The input encoding.
-
- offset int // The offset of the current position (in bytes).
- mark yaml_mark_t // The mark of the current position.
-
- // Comments
-
- head_comment []byte // The current head comments
- line_comment []byte // The current line comments
- foot_comment []byte // The current foot comments
- tail_comment []byte // Foot comment that happens at the end of a block.
- stem_comment []byte // Comment in item preceding a nested structure (list inside list item, etc)
-
- comments []yaml_comment_t // The folded comments for all parsed tokens
- comments_head int
-
- // Scanner stuff
-
- stream_start_produced bool // Have we started to scan the input stream?
- stream_end_produced bool // Have we reached the end of the input stream?
-
- flow_level int // The number of unclosed '[' and '{' indicators.
-
- tokens []yaml_token_t // The tokens queue.
- tokens_head int // The head of the tokens queue.
- tokens_parsed int // The number of tokens fetched from the queue.
- token_available bool // Does the tokens queue contain a token ready for dequeueing.
-
- indent int // The current indentation level.
- indents []int // The indentation levels stack.
-
- simple_key_allowed bool // May a simple key occur at the current position?
- simple_keys []yaml_simple_key_t // The stack of simple keys.
- simple_keys_by_tok map[int]int // possible simple_key indexes indexed by token_number
-
- // Parser stuff
-
- state yaml_parser_state_t // The current parser state.
- states []yaml_parser_state_t // The parser states stack.
- marks []yaml_mark_t // The stack of marks.
- tag_directives []yaml_tag_directive_t // The list of TAG directives.
-
- // Dumper stuff
-
- aliases []yaml_alias_data_t // The alias data.
-
- document *yaml_document_t // The currently parsed document.
-}
-
-type yaml_comment_t struct {
-
- scan_mark yaml_mark_t // Position where scanning for comments started
- token_mark yaml_mark_t // Position after which tokens will be associated with this comment
- start_mark yaml_mark_t // Position of '#' comment mark
- end_mark yaml_mark_t // Position where comment terminated
-
- head []byte
- line []byte
- foot []byte
-}
-
-// Emitter Definitions
-
-// The prototype of a write handler.
-//
-// The write handler is called when the emitter needs to flush the accumulated
-// characters to the output. The handler should write @a size bytes of the
-// @a buffer to the output.
-//
-// @param[in,out] data A pointer to an application data specified by
-// yaml_emitter_set_output().
-// @param[in] buffer The buffer with bytes to be written.
-// @param[in] size The size of the buffer.
-//
-// @returns On success, the handler should return @c 1. If the handler failed,
-// the returned value should be @c 0.
-//
-type yaml_write_handler_t func(emitter *yaml_emitter_t, buffer []byte) error
-
-type yaml_emitter_state_t int
-
-// The emitter states.
-const (
- // Expect STREAM-START.
- yaml_EMIT_STREAM_START_STATE yaml_emitter_state_t = iota
-
- yaml_EMIT_FIRST_DOCUMENT_START_STATE // Expect the first DOCUMENT-START or STREAM-END.
- yaml_EMIT_DOCUMENT_START_STATE // Expect DOCUMENT-START or STREAM-END.
- yaml_EMIT_DOCUMENT_CONTENT_STATE // Expect the content of a document.
- yaml_EMIT_DOCUMENT_END_STATE // Expect DOCUMENT-END.
- yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE // Expect the first item of a flow sequence.
- yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE // Expect the next item of a flow sequence, with the comma already written out
- yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE // Expect an item of a flow sequence.
- yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE // Expect the first key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE // Expect the next key of a flow mapping, with the comma already written out
- yaml_EMIT_FLOW_MAPPING_KEY_STATE // Expect a key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE // Expect a value for a simple key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_VALUE_STATE // Expect a value of a flow mapping.
- yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE // Expect the first item of a block sequence.
- yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE // Expect an item of a block sequence.
- yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE // Expect the first key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_KEY_STATE // Expect the key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE // Expect a value for a simple key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_VALUE_STATE // Expect a value of a block mapping.
- yaml_EMIT_END_STATE // Expect nothing.
-)
-
-// The emitter structure.
-//
-// All members are internal. Manage the structure using the @c yaml_emitter_
-// family of functions.
-type yaml_emitter_t struct {
-
- // Error handling
-
- error yaml_error_type_t // Error type.
- problem string // Error description.
-
- // Writer stuff
-
- write_handler yaml_write_handler_t // Write handler.
-
- output_buffer *[]byte // String output data.
- output_writer io.Writer // File output data.
-
- buffer []byte // The working buffer.
- buffer_pos int // The current position of the buffer.
-
- raw_buffer []byte // The raw buffer.
- raw_buffer_pos int // The current position of the buffer.
-
- encoding yaml_encoding_t // The stream encoding.
-
- // Emitter stuff
-
- canonical bool // If the output is in the canonical style?
- best_indent int // The number of indentation spaces.
- best_width int // The preferred width of the output lines.
- unicode bool // Allow unescaped non-ASCII characters?
- line_break yaml_break_t // The preferred line break.
-
- state yaml_emitter_state_t // The current emitter state.
- states []yaml_emitter_state_t // The stack of states.
-
- events []yaml_event_t // The event queue.
- events_head int // The head of the event queue.
-
- indents []int // The stack of indentation levels.
-
- tag_directives []yaml_tag_directive_t // The list of tag directives.
-
- indent int // The current indentation level.
-
- flow_level int // The current flow level.
-
- root_context bool // Is it the document root context?
- sequence_context bool // Is it a sequence context?
- mapping_context bool // Is it a mapping context?
- simple_key_context bool // Is it a simple mapping key context?
-
- line int // The current line.
- column int // The current column.
- whitespace bool // If the last character was a whitespace?
- indention bool // If the last character was an indentation character (' ', '-', '?', ':')?
- open_ended bool // If an explicit document end is required?
-
- space_above bool // Is there's an empty line above?
- foot_indent int // The indent used to write the foot comment above, or -1 if none.
-
- // Anchor analysis.
- anchor_data struct {
- anchor []byte // The anchor value.
- alias bool // Is it an alias?
- }
-
- // Tag analysis.
- tag_data struct {
- handle []byte // The tag handle.
- suffix []byte // The tag suffix.
- }
-
- // Scalar analysis.
- scalar_data struct {
- value []byte // The scalar value.
- multiline bool // Does the scalar contain line breaks?
- flow_plain_allowed bool // Can the scalar be expessed in the flow plain style?
- block_plain_allowed bool // Can the scalar be expressed in the block plain style?
- single_quoted_allowed bool // Can the scalar be expressed in the single quoted style?
- block_allowed bool // Can the scalar be expressed in the literal or folded styles?
- style yaml_scalar_style_t // The output style.
- }
-
- // Comments
- head_comment []byte
- line_comment []byte
- foot_comment []byte
- tail_comment []byte
-
- key_line_comment []byte
-
- // Dumper stuff
-
- opened bool // If the stream was already opened?
- closed bool // If the stream was already closed?
-
- // The information associated with the document nodes.
- anchors *struct {
- references int // The number of references.
- anchor int // The anchor id.
- serialized bool // If the node has been emitted?
- }
-
- last_anchor_id int // The last assigned anchor id.
-
- document *yaml_document_t // The currently emitted document.
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go b/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go
deleted file mode 100644
index e88f9c5..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go
+++ /dev/null
@@ -1,198 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-const (
- // The size of the input raw buffer.
- input_raw_buffer_size = 512
-
- // The size of the input buffer.
- // It should be possible to decode the whole raw buffer.
- input_buffer_size = input_raw_buffer_size * 3
-
- // The size of the output buffer.
- output_buffer_size = 128
-
- // The size of the output raw buffer.
- // It should be possible to encode the whole output buffer.
- output_raw_buffer_size = (output_buffer_size*2 + 2)
-
- // The size of other stacks and queues.
- initial_stack_size = 16
- initial_queue_size = 16
- initial_string_size = 16
-)
-
-// Check if the character at the specified position is an alphabetical
-// character, a digit, '_', or '-'.
-func is_alpha(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9' || b[i] >= 'A' && b[i] <= 'Z' || b[i] >= 'a' && b[i] <= 'z' || b[i] == '_' || b[i] == '-'
-}
-
-// Check if the character at the specified position is a digit.
-func is_digit(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9'
-}
-
-// Get the value of a digit.
-func as_digit(b []byte, i int) int {
- return int(b[i]) - '0'
-}
-
-// Check if the character at the specified position is a hex-digit.
-func is_hex(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9' || b[i] >= 'A' && b[i] <= 'F' || b[i] >= 'a' && b[i] <= 'f'
-}
-
-// Get the value of a hex-digit.
-func as_hex(b []byte, i int) int {
- bi := b[i]
- if bi >= 'A' && bi <= 'F' {
- return int(bi) - 'A' + 10
- }
- if bi >= 'a' && bi <= 'f' {
- return int(bi) - 'a' + 10
- }
- return int(bi) - '0'
-}
-
-// Check if the character is ASCII.
-func is_ascii(b []byte, i int) bool {
- return b[i] <= 0x7F
-}
-
-// Check if the character at the start of the buffer can be printed unescaped.
-func is_printable(b []byte, i int) bool {
- return ((b[i] == 0x0A) || // . == #x0A
- (b[i] >= 0x20 && b[i] <= 0x7E) || // #x20 <= . <= #x7E
- (b[i] == 0xC2 && b[i+1] >= 0xA0) || // #0xA0 <= . <= #xD7FF
- (b[i] > 0xC2 && b[i] < 0xED) ||
- (b[i] == 0xED && b[i+1] < 0xA0) ||
- (b[i] == 0xEE) ||
- (b[i] == 0xEF && // #xE000 <= . <= #xFFFD
- !(b[i+1] == 0xBB && b[i+2] == 0xBF) && // && . != #xFEFF
- !(b[i+1] == 0xBF && (b[i+2] == 0xBE || b[i+2] == 0xBF))))
-}
-
-// Check if the character at the specified position is NUL.
-func is_z(b []byte, i int) bool {
- return b[i] == 0x00
-}
-
-// Check if the beginning of the buffer is a BOM.
-func is_bom(b []byte, i int) bool {
- return b[0] == 0xEF && b[1] == 0xBB && b[2] == 0xBF
-}
-
-// Check if the character at the specified position is space.
-func is_space(b []byte, i int) bool {
- return b[i] == ' '
-}
-
-// Check if the character at the specified position is tab.
-func is_tab(b []byte, i int) bool {
- return b[i] == '\t'
-}
-
-// Check if the character at the specified position is blank (space or tab).
-func is_blank(b []byte, i int) bool {
- //return is_space(b, i) || is_tab(b, i)
- return b[i] == ' ' || b[i] == '\t'
-}
-
-// Check if the character at the specified position is a line break.
-func is_break(b []byte, i int) bool {
- return (b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9) // PS (#x2029)
-}
-
-func is_crlf(b []byte, i int) bool {
- return b[i] == '\r' && b[i+1] == '\n'
-}
-
-// Check if the character is a line break or NUL.
-func is_breakz(b []byte, i int) bool {
- //return is_break(b, i) || is_z(b, i)
- return (
- // is_break:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- // is_z:
- b[i] == 0)
-}
-
-// Check if the character is a line break, space, or NUL.
-func is_spacez(b []byte, i int) bool {
- //return is_space(b, i) || is_breakz(b, i)
- return (
- // is_space:
- b[i] == ' ' ||
- // is_breakz:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- b[i] == 0)
-}
-
-// Check if the character is a line break, space, tab, or NUL.
-func is_blankz(b []byte, i int) bool {
- //return is_blank(b, i) || is_breakz(b, i)
- return (
- // is_blank:
- b[i] == ' ' || b[i] == '\t' ||
- // is_breakz:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- b[i] == 0)
-}
-
-// Determine the width of the character.
-func width(b byte) int {
- // Don't replace these by a switch without first
- // confirming that it is being inlined.
- if b&0x80 == 0x00 {
- return 1
- }
- if b&0xE0 == 0xC0 {
- return 2
- }
- if b&0xF0 == 0xE0 {
- return 3
- }
- if b&0xF8 == 0xF0 {
- return 4
- }
- return 0
-
-}
diff --git a/sesh/vendor/modules.txt b/sesh/vendor/modules.txt
index 750e523..4cae9ad 100644
--- a/sesh/vendor/modules.txt
+++ b/sesh/vendor/modules.txt
@@ -42,6 +42,17 @@ github.com/gdamore/tcell/v2/terminfo/x/xfce
github.com/gdamore/tcell/v2/terminfo/x/xterm
github.com/gdamore/tcell/v2/terminfo/x/xterm_kitty
github.com/gdamore/tcell/v2/terminfo/x/xterm_termite
+# github.com/goccy/go-yaml v1.19.2
+## explicit; go 1.21.0
+github.com/goccy/go-yaml
+github.com/goccy/go-yaml/ast
+github.com/goccy/go-yaml/internal/errors
+github.com/goccy/go-yaml/internal/format
+github.com/goccy/go-yaml/lexer
+github.com/goccy/go-yaml/parser
+github.com/goccy/go-yaml/printer
+github.com/goccy/go-yaml/scanner
+github.com/goccy/go-yaml/token
# github.com/ktr0731/go-ansisgr v0.1.0
## explicit; go 1.19
github.com/ktr0731/go-ansisgr
@@ -78,6 +89,3 @@ golang.org/x/term
golang.org/x/text/encoding
golang.org/x/text/encoding/internal/identifier
golang.org/x/text/transform
-# gopkg.in/yaml.v3 v3.0.1
-## explicit
-gopkg.in/yaml.v3
+
+### Installation
+
+```sh
+git clone https://github.com/goccy/go-yaml.git
+cd go-yaml/cmd/ycat && go install .
+```
+
+
+# For Developers
+
+> [!NOTE]
+> In this project, we manage such test code under the `testdata` directory to avoid adding dependencies on libraries that are only needed for testing to the top `go.mod` file. Therefore, if you want to add test cases that use 3rd party libraries, please add the test code to the `testdata` directory.
+
+# Looking for Sponsors
+
+I'm looking for sponsors this library. This library is being developed as a personal project in my spare time. If you want a quick response or problem resolution when using this library in your project, please register as a [sponsor](https://github.com/sponsors/goccy). I will cooperate as much as possible. Of course, this library is developed as an MIT license, so you can use it freely for free.
+
+# License
+
+MIT
diff --git a/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go b/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go
new file mode 100644
index 0000000..a8078a5
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/ast/ast.go
@@ -0,0 +1,2381 @@
+package ast
+
+import (
+ "errors"
+ "fmt"
+ "io"
+ "math"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+var (
+ ErrInvalidTokenType = errors.New("invalid token type")
+ ErrInvalidAnchorName = errors.New("invalid anchor name")
+ ErrInvalidAliasName = errors.New("invalid alias name")
+)
+
+// NodeType type identifier of node
+type NodeType int
+
+const (
+ // UnknownNodeType type identifier for default
+ UnknownNodeType NodeType = iota
+ // DocumentType type identifier for document node
+ DocumentType
+ // NullType type identifier for null node
+ NullType
+ // BoolType type identifier for boolean node
+ BoolType
+ // IntegerType type identifier for integer node
+ IntegerType
+ // FloatType type identifier for float node
+ FloatType
+ // InfinityType type identifier for infinity node
+ InfinityType
+ // NanType type identifier for nan node
+ NanType
+ // StringType type identifier for string node
+ StringType
+ // MergeKeyType type identifier for merge key node
+ MergeKeyType
+ // LiteralType type identifier for literal node
+ LiteralType
+ // MappingType type identifier for mapping node
+ MappingType
+ // MappingKeyType type identifier for mapping key node
+ MappingKeyType
+ // MappingValueType type identifier for mapping value node
+ MappingValueType
+ // SequenceType type identifier for sequence node
+ SequenceType
+ // SequenceEntryType type identifier for sequence entry node
+ SequenceEntryType
+ // AnchorType type identifier for anchor node
+ AnchorType
+ // AliasType type identifier for alias node
+ AliasType
+ // DirectiveType type identifier for directive node
+ DirectiveType
+ // TagType type identifier for tag node
+ TagType
+ // CommentType type identifier for comment node
+ CommentType
+ // CommentGroupType type identifier for comment group node
+ CommentGroupType
+)
+
+// String node type identifier to text
+func (t NodeType) String() string {
+ switch t {
+ case UnknownNodeType:
+ return "UnknownNode"
+ case DocumentType:
+ return "Document"
+ case NullType:
+ return "Null"
+ case BoolType:
+ return "Bool"
+ case IntegerType:
+ return "Integer"
+ case FloatType:
+ return "Float"
+ case InfinityType:
+ return "Infinity"
+ case NanType:
+ return "Nan"
+ case StringType:
+ return "String"
+ case MergeKeyType:
+ return "MergeKey"
+ case LiteralType:
+ return "Literal"
+ case MappingType:
+ return "Mapping"
+ case MappingKeyType:
+ return "MappingKey"
+ case MappingValueType:
+ return "MappingValue"
+ case SequenceType:
+ return "Sequence"
+ case SequenceEntryType:
+ return "SequenceEntry"
+ case AnchorType:
+ return "Anchor"
+ case AliasType:
+ return "Alias"
+ case DirectiveType:
+ return "Directive"
+ case TagType:
+ return "Tag"
+ case CommentType:
+ return "Comment"
+ case CommentGroupType:
+ return "CommentGroup"
+ }
+ return ""
+}
+
+// String node type identifier to YAML Structure name
+// based on https://yaml.org/spec/1.2/spec.html
+func (t NodeType) YAMLName() string {
+ switch t {
+ case UnknownNodeType:
+ return "unknown"
+ case DocumentType:
+ return "document"
+ case NullType:
+ return "null"
+ case BoolType:
+ return "boolean"
+ case IntegerType:
+ return "int"
+ case FloatType:
+ return "float"
+ case InfinityType:
+ return "inf"
+ case NanType:
+ return "nan"
+ case StringType:
+ return "string"
+ case MergeKeyType:
+ return "merge key"
+ case LiteralType:
+ return "scalar"
+ case MappingType:
+ return "mapping"
+ case MappingKeyType:
+ return "key"
+ case MappingValueType:
+ return "value"
+ case SequenceType:
+ return "sequence"
+ case SequenceEntryType:
+ return "value"
+ case AnchorType:
+ return "anchor"
+ case AliasType:
+ return "alias"
+ case DirectiveType:
+ return "directive"
+ case TagType:
+ return "tag"
+ case CommentType:
+ return "comment"
+ case CommentGroupType:
+ return "comment"
+ }
+ return ""
+}
+
+// Node type of node
+type Node interface {
+ io.Reader
+ // String node to text
+ String() string
+ // GetToken returns token instance
+ GetToken() *token.Token
+ // Type returns type of node
+ Type() NodeType
+ // AddColumn add column number to child nodes recursively
+ AddColumn(int)
+ // SetComment set comment token to node
+ SetComment(*CommentGroupNode) error
+ // Comment returns comment token instance
+ GetComment() *CommentGroupNode
+ // GetPath returns YAMLPath for the current node
+ GetPath() string
+ // SetPath set YAMLPath for the current node
+ SetPath(string)
+ // MarshalYAML
+ MarshalYAML() ([]byte, error)
+ // already read length
+ readLen() int
+ // append read length
+ addReadLen(int)
+ // clean read length
+ clearLen()
+}
+
+// MapKeyNode type for map key node
+type MapKeyNode interface {
+ Node
+ IsMergeKey() bool
+ // String node to text without comment
+ stringWithoutComment() string
+}
+
+// ScalarNode type for scalar node
+type ScalarNode interface {
+ MapKeyNode
+ GetValue() interface{}
+}
+
+type BaseNode struct {
+ Path string
+ Comment *CommentGroupNode
+ read int
+}
+
+func addCommentString(base string, node *CommentGroupNode) string {
+ return fmt.Sprintf("%s %s", base, node.String())
+}
+
+func (n *BaseNode) readLen() int {
+ return n.read
+}
+
+func (n *BaseNode) clearLen() {
+ n.read = 0
+}
+
+func (n *BaseNode) addReadLen(len int) {
+ n.read += len
+}
+
+// GetPath returns YAMLPath for the current node.
+func (n *BaseNode) GetPath() string {
+ if n == nil {
+ return ""
+ }
+ return n.Path
+}
+
+// SetPath set YAMLPath for the current node.
+func (n *BaseNode) SetPath(path string) {
+ if n == nil {
+ return
+ }
+ n.Path = path
+}
+
+// GetComment returns comment token instance
+func (n *BaseNode) GetComment() *CommentGroupNode {
+ return n.Comment
+}
+
+// SetComment set comment token
+func (n *BaseNode) SetComment(node *CommentGroupNode) error {
+ n.Comment = node
+ return nil
+}
+
+func min(a, b int) int {
+ if a < b {
+ return a
+ }
+ return b
+}
+
+func readNode(p []byte, node Node) (int, error) {
+ s := node.String()
+ readLen := node.readLen()
+ remain := len(s) - readLen
+ if remain == 0 {
+ node.clearLen()
+ return 0, io.EOF
+ }
+ size := min(remain, len(p))
+ for idx, b := range []byte(s[readLen : readLen+size]) {
+ p[idx] = byte(b)
+ }
+ node.addReadLen(size)
+ return size, nil
+}
+
+func checkLineBreak(t *token.Token) bool {
+ if t.Prev != nil {
+ lbc := "\n"
+ prev := t.Prev
+ var adjustment int
+ // if the previous type is sequence entry use the previous type for that
+ if prev.Type == token.SequenceEntryType {
+ // as well as switching to previous type count any new lines in origin to account for:
+ // -
+ // b: c
+ adjustment = strings.Count(strings.TrimRight(t.Origin, lbc), lbc)
+ if prev.Prev != nil {
+ prev = prev.Prev
+ }
+ }
+ lineDiff := t.Position.Line - prev.Position.Line - 1
+ if lineDiff > 0 {
+ if prev.Type == token.StringType {
+ // Remove any line breaks included in multiline string
+ adjustment += strings.Count(strings.TrimRight(strings.TrimSpace(prev.Origin), lbc), lbc)
+ }
+ // Due to the way that comment parsing works its assumed that when a null value does not have new line in origin
+ // it was squashed therefore difference is ignored.
+ // foo:
+ // bar:
+ // # comment
+ // baz: 1
+ // becomes
+ // foo:
+ // bar: null # comment
+ //
+ // baz: 1
+ if prev.Type == token.NullType || prev.Type == token.ImplicitNullType {
+ return strings.Count(prev.Origin, lbc) > 0
+ }
+ if lineDiff-adjustment > 0 {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+// Null create node for null value
+func Null(tk *token.Token) *NullNode {
+ return &NullNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// Bool create node for boolean value
+func Bool(tk *token.Token) *BoolNode {
+ b, _ := strconv.ParseBool(tk.Value)
+ return &BoolNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: b,
+ }
+}
+
+// Integer create node for integer value
+func Integer(tk *token.Token) *IntegerNode {
+ var v any
+ if num := token.ToNumber(tk.Value); num != nil {
+ v = num.Value
+ }
+ return &IntegerNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: v,
+ }
+}
+
+// Float create node for float value
+func Float(tk *token.Token) *FloatNode {
+ var v float64
+ if num := token.ToNumber(tk.Value); num != nil && num.Type == token.NumberTypeFloat {
+ value, ok := num.Value.(float64)
+ if ok {
+ v = value
+ }
+ }
+ return &FloatNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: v,
+ }
+}
+
+// Infinity create node for .inf or -.inf value
+func Infinity(tk *token.Token) *InfinityNode {
+ node := &InfinityNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+ switch tk.Value {
+ case ".inf", ".Inf", ".INF":
+ node.Value = math.Inf(0)
+ case "-.inf", "-.Inf", "-.INF":
+ node.Value = math.Inf(-1)
+ }
+ return node
+}
+
+// Nan create node for .nan value
+func Nan(tk *token.Token) *NanNode {
+ return &NanNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// String create node for string value
+func String(tk *token.Token) *StringNode {
+ return &StringNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ Value: tk.Value,
+ }
+}
+
+// Comment create node for comment
+func Comment(tk *token.Token) *CommentNode {
+ return &CommentNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+func CommentGroup(comments []*token.Token) *CommentGroupNode {
+ nodes := []*CommentNode{}
+ for _, comment := range comments {
+ nodes = append(nodes, Comment(comment))
+ }
+ return &CommentGroupNode{
+ BaseNode: &BaseNode{},
+ Comments: nodes,
+ }
+}
+
+// MergeKey create node for merge key ( << )
+func MergeKey(tk *token.Token) *MergeKeyNode {
+ return &MergeKeyNode{
+ BaseNode: &BaseNode{},
+ Token: tk,
+ }
+}
+
+// Mapping create node for map
+func Mapping(tk *token.Token, isFlowStyle bool, values ...*MappingValueNode) *MappingNode {
+ node := &MappingNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ IsFlowStyle: isFlowStyle,
+ Values: []*MappingValueNode{},
+ }
+ node.Values = append(node.Values, values...)
+ return node
+}
+
+// MappingValue create node for mapping value
+func MappingValue(tk *token.Token, key MapKeyNode, value Node) *MappingValueNode {
+ return &MappingValueNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ Key: key,
+ Value: value,
+ }
+}
+
+// MappingKey create node for map key ( '?' ).
+func MappingKey(tk *token.Token) *MappingKeyNode {
+ return &MappingKeyNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+// Sequence create node for sequence
+func Sequence(tk *token.Token, isFlowStyle bool) *SequenceNode {
+ return &SequenceNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ IsFlowStyle: isFlowStyle,
+ Values: []Node{},
+ }
+}
+
+func Anchor(tk *token.Token) *AnchorNode {
+ return &AnchorNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Alias(tk *token.Token) *AliasNode {
+ return &AliasNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Document(tk *token.Token, body Node) *DocumentNode {
+ return &DocumentNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ Body: body,
+ }
+}
+
+func Directive(tk *token.Token) *DirectiveNode {
+ return &DirectiveNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Literal(tk *token.Token) *LiteralNode {
+ return &LiteralNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+func Tag(tk *token.Token) *TagNode {
+ return &TagNode{
+ BaseNode: &BaseNode{},
+ Start: tk,
+ }
+}
+
+// File contains all documents in YAML file
+type File struct {
+ Name string
+ Docs []*DocumentNode
+}
+
+// Read implements (io.Reader).Read
+func (f *File) Read(p []byte) (int, error) {
+ for _, doc := range f.Docs {
+ n, err := doc.Read(p)
+ if err == io.EOF {
+ continue
+ }
+ return n, nil
+ }
+ return 0, io.EOF
+}
+
+// String all documents to text
+func (f *File) String() string {
+ docs := []string{}
+ for _, doc := range f.Docs {
+ docs = append(docs, doc.String())
+ }
+ if len(docs) > 0 {
+ return strings.Join(docs, "\n") + "\n"
+ } else {
+ return ""
+ }
+}
+
+// DocumentNode type of Document
+type DocumentNode struct {
+ *BaseNode
+ Start *token.Token // position of DocumentHeader ( `---` )
+ End *token.Token // position of DocumentEnd ( `...` )
+ Body Node
+}
+
+// Read implements (io.Reader).Read
+func (d *DocumentNode) Read(p []byte) (int, error) {
+ return readNode(p, d)
+}
+
+// Type returns DocumentNodeType
+func (d *DocumentNode) Type() NodeType { return DocumentType }
+
+// GetToken returns token instance
+func (d *DocumentNode) GetToken() *token.Token {
+ return d.Body.GetToken()
+}
+
+// AddColumn add column number to child nodes recursively
+func (d *DocumentNode) AddColumn(col int) {
+ if d.Body != nil {
+ d.Body.AddColumn(col)
+ }
+}
+
+// String document to text
+func (d *DocumentNode) String() string {
+ doc := []string{}
+ if d.Start != nil {
+ doc = append(doc, d.Start.Value)
+ }
+ if d.Body != nil {
+ doc = append(doc, d.Body.String())
+ }
+ if d.End != nil {
+ doc = append(doc, d.End.Value)
+ }
+ return strings.Join(doc, "\n")
+}
+
+// MarshalYAML encodes to a YAML text
+func (d *DocumentNode) MarshalYAML() ([]byte, error) {
+ return []byte(d.String()), nil
+}
+
+// NullNode type of null node
+type NullNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *NullNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns NullType
+func (n *NullNode) Type() NodeType { return NullType }
+
+// GetToken returns token instance
+func (n *NullNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *NullNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns nil value
+func (n *NullNode) GetValue() interface{} {
+ return nil
+}
+
+// String returns `null` text
+func (n *NullNode) String() string {
+ if n.Token.Type == token.ImplicitNullType {
+ if n.Comment != nil {
+ return n.Comment.String()
+ }
+ return ""
+ }
+ if n.Comment != nil {
+ return addCommentString("null", n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *NullNode) stringWithoutComment() string {
+ return "null"
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *NullNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *NullNode) IsMergeKey() bool {
+ return false
+}
+
+// IntegerNode type of integer node
+type IntegerNode struct {
+ *BaseNode
+ Token *token.Token
+ Value interface{} // int64 or uint64 value
+}
+
+// Read implements (io.Reader).Read
+func (n *IntegerNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns IntegerType
+func (n *IntegerNode) Type() NodeType { return IntegerType }
+
+// GetToken returns token instance
+func (n *IntegerNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *IntegerNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns int64 value
+func (n *IntegerNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String int64 to text
+func (n *IntegerNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *IntegerNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *IntegerNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *IntegerNode) IsMergeKey() bool {
+ return false
+}
+
+// FloatNode type of float node
+type FloatNode struct {
+ *BaseNode
+ Token *token.Token
+ Precision int
+ Value float64
+}
+
+// Read implements (io.Reader).Read
+func (n *FloatNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns FloatType
+func (n *FloatNode) Type() NodeType { return FloatType }
+
+// GetToken returns token instance
+func (n *FloatNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *FloatNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns float64 value
+func (n *FloatNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String float64 to text
+func (n *FloatNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *FloatNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *FloatNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *FloatNode) IsMergeKey() bool {
+ return false
+}
+
+// StringNode type of string node
+type StringNode struct {
+ *BaseNode
+ Token *token.Token
+ Value string
+}
+
+// Read implements (io.Reader).Read
+func (n *StringNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns StringType
+func (n *StringNode) Type() NodeType { return StringType }
+
+// GetToken returns token instance
+func (n *StringNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *StringNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns string value
+func (n *StringNode) GetValue() interface{} {
+ return n.Value
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *StringNode) IsMergeKey() bool {
+ return false
+}
+
+// escapeSingleQuote escapes s to a single quoted scalar.
+// https://yaml.org/spec/1.2.2/#732-single-quoted-style
+func escapeSingleQuote(s string) string {
+ var sb strings.Builder
+ growLen := len(s) + // s includes also one ' from the doubled pair
+ 2 + // opening and closing '
+ strings.Count(s, "'") // ' added by ReplaceAll
+ sb.Grow(growLen)
+ sb.WriteString("'")
+ sb.WriteString(strings.ReplaceAll(s, "'", "''"))
+ sb.WriteString("'")
+ return sb.String()
+}
+
+// String string value to text with quote or literal header if required
+func (n *StringNode) String() string {
+ switch n.Token.Type {
+ case token.SingleQuoteType:
+ quoted := escapeSingleQuote(n.Value)
+ if n.Comment != nil {
+ return addCommentString(quoted, n.Comment)
+ }
+ return quoted
+ case token.DoubleQuoteType:
+ quoted := strconv.Quote(n.Value)
+ if n.Comment != nil {
+ return addCommentString(quoted, n.Comment)
+ }
+ return quoted
+ }
+
+ lbc := token.DetectLineBreakCharacter(n.Value)
+ if strings.Contains(n.Value, lbc) {
+ // This block assumes that the line breaks in this inside scalar content and the Outside scalar content are the same.
+ // It works mostly, but inconsistencies occur if line break characters are mixed.
+ header := token.LiteralBlockHeader(n.Value)
+ space := strings.Repeat(" ", n.Token.Position.Column-1)
+ indent := strings.Repeat(" ", n.Token.Position.IndentNum)
+ values := []string{}
+ for _, v := range strings.Split(n.Value, lbc) {
+ values = append(values, fmt.Sprintf("%s%s%s", space, indent, v))
+ }
+ block := strings.TrimSuffix(strings.TrimSuffix(strings.Join(values, lbc), fmt.Sprintf("%s%s%s", lbc, indent, space)), fmt.Sprintf("%s%s", indent, space))
+ return fmt.Sprintf("%s%s%s", header, lbc, block)
+ } else if len(n.Value) > 0 && (n.Value[0] == '{' || n.Value[0] == '[') {
+ return fmt.Sprintf(`'%s'`, n.Value)
+ }
+ if n.Comment != nil {
+ return addCommentString(n.Value, n.Comment)
+ }
+ return n.Value
+}
+
+func (n *StringNode) stringWithoutComment() string {
+ switch n.Token.Type {
+ case token.SingleQuoteType:
+ quoted := fmt.Sprintf(`'%s'`, n.Value)
+ return quoted
+ case token.DoubleQuoteType:
+ quoted := strconv.Quote(n.Value)
+ return quoted
+ }
+
+ lbc := token.DetectLineBreakCharacter(n.Value)
+ if strings.Contains(n.Value, lbc) {
+ // This block assumes that the line breaks in this inside scalar content and the Outside scalar content are the same.
+ // It works mostly, but inconsistencies occur if line break characters are mixed.
+ header := token.LiteralBlockHeader(n.Value)
+ space := strings.Repeat(" ", n.Token.Position.Column-1)
+ indent := strings.Repeat(" ", n.Token.Position.IndentNum)
+ values := []string{}
+ for _, v := range strings.Split(n.Value, lbc) {
+ values = append(values, fmt.Sprintf("%s%s%s", space, indent, v))
+ }
+ block := strings.TrimSuffix(strings.TrimSuffix(strings.Join(values, lbc), fmt.Sprintf("%s%s%s", lbc, indent, space)), fmt.Sprintf(" %s", space))
+ return fmt.Sprintf("%s%s%s", header, lbc, block)
+ } else if len(n.Value) > 0 && (n.Value[0] == '{' || n.Value[0] == '[') {
+ return fmt.Sprintf(`'%s'`, n.Value)
+ }
+ return n.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *StringNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// LiteralNode type of literal node
+type LiteralNode struct {
+ *BaseNode
+ Start *token.Token
+ Value *StringNode
+}
+
+// Read implements (io.Reader).Read
+func (n *LiteralNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns LiteralType
+func (n *LiteralNode) Type() NodeType { return LiteralType }
+
+// GetToken returns token instance
+func (n *LiteralNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *LiteralNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// GetValue returns string value
+func (n *LiteralNode) GetValue() interface{} {
+ return n.String()
+}
+
+// String literal to text
+func (n *LiteralNode) String() string {
+ origin := n.Value.GetToken().Origin
+ lit := strings.TrimRight(strings.TrimRight(origin, " "), "\n")
+ if n.Comment != nil {
+ return fmt.Sprintf("%s %s\n%s", n.Start.Value, n.Comment.String(), lit)
+ }
+ return fmt.Sprintf("%s\n%s", n.Start.Value, lit)
+}
+
+func (n *LiteralNode) stringWithoutComment() string {
+ return n.String()
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *LiteralNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *LiteralNode) IsMergeKey() bool {
+ return false
+}
+
+// MergeKeyNode type of merge key node
+type MergeKeyNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *MergeKeyNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MergeKeyType
+func (n *MergeKeyNode) Type() NodeType { return MergeKeyType }
+
+// GetToken returns token instance
+func (n *MergeKeyNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// GetValue returns '<<' value
+func (n *MergeKeyNode) GetValue() interface{} {
+ return n.Token.Value
+}
+
+// String returns '<<' value
+func (n *MergeKeyNode) String() string {
+ return n.stringWithoutComment()
+}
+
+func (n *MergeKeyNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MergeKeyNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MergeKeyNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *MergeKeyNode) IsMergeKey() bool {
+ return true
+}
+
+// BoolNode type of boolean node
+type BoolNode struct {
+ *BaseNode
+ Token *token.Token
+ Value bool
+}
+
+// Read implements (io.Reader).Read
+func (n *BoolNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns BoolType
+func (n *BoolNode) Type() NodeType { return BoolType }
+
+// GetToken returns token instance
+func (n *BoolNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *BoolNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns boolean value
+func (n *BoolNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String boolean to text
+func (n *BoolNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *BoolNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *BoolNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *BoolNode) IsMergeKey() bool {
+ return false
+}
+
+// InfinityNode type of infinity node
+type InfinityNode struct {
+ *BaseNode
+ Token *token.Token
+ Value float64
+}
+
+// Read implements (io.Reader).Read
+func (n *InfinityNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns InfinityType
+func (n *InfinityNode) Type() NodeType { return InfinityType }
+
+// GetToken returns token instance
+func (n *InfinityNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *InfinityNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns math.Inf(0) or math.Inf(-1)
+func (n *InfinityNode) GetValue() interface{} {
+ return n.Value
+}
+
+// String infinity to text
+func (n *InfinityNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *InfinityNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *InfinityNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *InfinityNode) IsMergeKey() bool {
+ return false
+}
+
+// NanNode type of nan node
+type NanNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *NanNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns NanType
+func (n *NanNode) Type() NodeType { return NanType }
+
+// GetToken returns token instance
+func (n *NanNode) GetToken() *token.Token {
+ return n.Token
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *NanNode) AddColumn(col int) {
+ n.Token.AddColumn(col)
+}
+
+// GetValue returns math.NaN()
+func (n *NanNode) GetValue() interface{} {
+ return math.NaN()
+}
+
+// String returns .nan
+func (n *NanNode) String() string {
+ if n.Comment != nil {
+ return addCommentString(n.Token.Value, n.Comment)
+ }
+ return n.stringWithoutComment()
+}
+
+func (n *NanNode) stringWithoutComment() string {
+ return n.Token.Value
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *NanNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *NanNode) IsMergeKey() bool {
+ return false
+}
+
+// MapNode interface of MappingValueNode / MappingNode
+type MapNode interface {
+ MapRange() *MapNodeIter
+}
+
+// MapNodeIter is an iterator for ranging over a MapNode
+type MapNodeIter struct {
+ values []*MappingValueNode
+ idx int
+}
+
+const (
+ startRangeIndex = -1
+)
+
+// Next advances the map iterator and reports whether there is another entry.
+// It returns false when the iterator is exhausted.
+func (m *MapNodeIter) Next() bool {
+ m.idx++
+ next := m.idx < len(m.values)
+ return next
+}
+
+// Key returns the key of the iterator's current map node entry.
+func (m *MapNodeIter) Key() MapKeyNode {
+ return m.values[m.idx].Key
+}
+
+// Value returns the value of the iterator's current map node entry.
+func (m *MapNodeIter) Value() Node {
+ return m.values[m.idx].Value
+}
+
+// KeyValue returns the MappingValueNode of the iterator's current map node entry.
+func (m *MapNodeIter) KeyValue() *MappingValueNode {
+ return m.values[m.idx]
+}
+
+// MappingNode type of mapping node
+type MappingNode struct {
+ *BaseNode
+ Start *token.Token
+ End *token.Token
+ IsFlowStyle bool
+ Values []*MappingValueNode
+ FootComment *CommentGroupNode
+}
+
+func (n *MappingNode) startPos() *token.Position {
+ if len(n.Values) == 0 {
+ return n.Start.Position
+ }
+ return n.Values[0].Key.GetToken().Position
+}
+
+// Merge merge key/value of map.
+func (n *MappingNode) Merge(target *MappingNode) {
+ keyToMapValueMap := map[string]*MappingValueNode{}
+ for _, value := range n.Values {
+ key := value.Key.String()
+ keyToMapValueMap[key] = value
+ }
+ column := n.startPos().Column - target.startPos().Column
+ target.AddColumn(column)
+ for _, value := range target.Values {
+ mapValue, exists := keyToMapValueMap[value.Key.String()]
+ if exists {
+ mapValue.Value = value.Value
+ } else {
+ n.Values = append(n.Values, value)
+ }
+ }
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *MappingNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ for _, value := range n.Values {
+ value.SetIsFlowStyle(isFlow)
+ }
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingType
+func (n *MappingNode) Type() NodeType { return MappingType }
+
+// GetToken returns token instance
+func (n *MappingNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ n.End.AddColumn(col)
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+func (n *MappingNode) flowStyleString(commentMode bool) string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, strings.TrimLeft(value.String(), " "))
+ }
+ mapText := fmt.Sprintf("{%s}", strings.Join(values, ", "))
+ if commentMode && n.Comment != nil {
+ return addCommentString(mapText, n.Comment)
+ }
+ return mapText
+}
+
+func (n *MappingNode) blockStyleString(commentMode bool) string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, value.String())
+ }
+ mapText := strings.Join(values, "\n")
+ if commentMode && n.Comment != nil {
+ value := values[0]
+ var spaceNum int
+ for i := 0; i < len(value); i++ {
+ if value[i] != ' ' {
+ break
+ }
+ spaceNum++
+ }
+ comment := n.Comment.StringWithSpace(spaceNum)
+ return fmt.Sprintf("%s\n%s", comment, mapText)
+ }
+ return mapText
+}
+
+// String mapping values to text
+func (n *MappingNode) String() string {
+ if len(n.Values) == 0 {
+ if n.Comment != nil {
+ return addCommentString("{}", n.Comment)
+ }
+ return "{}"
+ }
+
+ commentMode := true
+ if n.IsFlowStyle || len(n.Values) == 0 {
+ return n.flowStyleString(commentMode)
+ }
+ return n.blockStyleString(commentMode)
+}
+
+// MapRange implements MapNode protocol
+func (n *MappingNode) MapRange() *MapNodeIter {
+ return &MapNodeIter{
+ idx: startRangeIndex,
+ values: n.Values,
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// MappingKeyNode type of tag node
+type MappingKeyNode struct {
+ *BaseNode
+ Start *token.Token
+ Value Node
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingKeyNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingKeyType
+func (n *MappingKeyNode) Type() NodeType { return MappingKeyType }
+
+// GetToken returns token instance
+func (n *MappingKeyNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingKeyNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String tag to text
+func (n *MappingKeyNode) String() string {
+ return n.stringWithoutComment()
+}
+
+func (n *MappingKeyNode) stringWithoutComment() string {
+ return fmt.Sprintf("%s %s", n.Start.Value, n.Value.String())
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingKeyNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *MappingKeyNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+// MappingValueNode type of mapping value
+type MappingValueNode struct {
+ *BaseNode
+ Start *token.Token // delimiter token ':'.
+ CollectEntry *token.Token // collect entry token ','.
+ Key MapKeyNode
+ Value Node
+ FootComment *CommentGroupNode
+ IsFlowStyle bool
+}
+
+// Replace replace value node.
+func (n *MappingValueNode) Replace(value Node) error {
+ column := n.Value.GetToken().Position.Column - value.GetToken().Position.Column
+ value.AddColumn(column)
+ n.Value = value
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *MappingValueNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns MappingValueType
+func (n *MappingValueNode) Type() NodeType { return MappingValueType }
+
+// GetToken returns token instance
+func (n *MappingValueNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *MappingValueNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Key != nil {
+ n.Key.AddColumn(col)
+ }
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *MappingValueNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ switch value := n.Value.(type) {
+ case *MappingNode:
+ value.SetIsFlowStyle(isFlow)
+ case *MappingValueNode:
+ value.SetIsFlowStyle(isFlow)
+ case *SequenceNode:
+ value.SetIsFlowStyle(isFlow)
+ }
+}
+
+// String mapping value to text
+func (n *MappingValueNode) String() string {
+ var text string
+ if n.Comment != nil {
+ text = fmt.Sprintf(
+ "%s\n%s",
+ n.Comment.StringWithSpace(n.Key.GetToken().Position.Column-1),
+ n.toString(),
+ )
+ } else {
+ text = n.toString()
+ }
+ if n.FootComment != nil {
+ text += fmt.Sprintf("\n%s", n.FootComment.StringWithSpace(n.Key.GetToken().Position.Column-1))
+ }
+ return text
+}
+
+func (n *MappingValueNode) toString() string {
+ space := strings.Repeat(" ", n.Key.GetToken().Position.Column-1)
+ if checkLineBreak(n.Key.GetToken()) {
+ space = fmt.Sprintf("%s%s", "\n", space)
+ }
+ keyIndentLevel := n.Key.GetToken().Position.IndentLevel
+ valueIndentLevel := n.Value.GetToken().Position.IndentLevel
+ keyComment := n.Key.GetComment()
+ if _, ok := n.Value.(ScalarNode); ok {
+ value := n.Value.String()
+ if value == "" {
+ // implicit null value.
+ return fmt.Sprintf("%s%s:", space, n.Key.String())
+ }
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), value)
+ } else if keyIndentLevel < valueIndentLevel && !n.IsFlowStyle {
+ valueStr := n.Value.String()
+ // For flow-style values indented on the next line, we need to add the proper indentation
+ if m, ok := n.Value.(*MappingNode); ok && m.IsFlowStyle {
+ valueIndent := strings.Repeat(" ", n.Value.GetToken().Position.Column-1)
+ valueStr = valueIndent + valueStr
+ } else if s, ok := n.Value.(*SequenceNode); ok && s.IsFlowStyle {
+ valueIndent := strings.Repeat(" ", n.Value.GetToken().Position.Column-1)
+ valueStr = valueIndent + valueStr
+ }
+ if keyComment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s\n%s",
+ space,
+ n.Key.stringWithoutComment(),
+ keyComment.String(),
+ valueStr,
+ )
+ }
+ return fmt.Sprintf("%s%s:\n%s", space, n.Key.String(), valueStr)
+ } else if m, ok := n.Value.(*MappingNode); ok && (m.IsFlowStyle || len(m.Values) == 0) {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if s, ok := n.Value.(*SequenceNode); ok && (s.IsFlowStyle || len(s.Values) == 0) {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*AnchorNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*AliasNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ } else if _, ok := n.Value.(*TagNode); ok {
+ return fmt.Sprintf("%s%s: %s", space, n.Key.String(), n.Value.String())
+ }
+
+ if keyComment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s\n%s",
+ space,
+ n.Key.stringWithoutComment(),
+ keyComment.String(),
+ n.Value.String(),
+ )
+ }
+ if m, ok := n.Value.(*MappingNode); ok && m.Comment != nil {
+ return fmt.Sprintf(
+ "%s%s: %s",
+ space,
+ n.Key.String(),
+ strings.TrimLeft(n.Value.String(), " "),
+ )
+ }
+ return fmt.Sprintf("%s%s:\n%s", space, n.Key.String(), n.Value.String())
+}
+
+// MapRange implements MapNode protocol
+func (n *MappingValueNode) MapRange() *MapNodeIter {
+ return &MapNodeIter{
+ idx: startRangeIndex,
+ values: []*MappingValueNode{n},
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *MappingValueNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// ArrayNode interface of SequenceNode
+type ArrayNode interface {
+ ArrayRange() *ArrayNodeIter
+}
+
+// ArrayNodeIter is an iterator for ranging over a ArrayNode
+type ArrayNodeIter struct {
+ values []Node
+ idx int
+}
+
+// Next advances the array iterator and reports whether there is another entry.
+// It returns false when the iterator is exhausted.
+func (m *ArrayNodeIter) Next() bool {
+ m.idx++
+ next := m.idx < len(m.values)
+ return next
+}
+
+// Value returns the value of the iterator's current array entry.
+func (m *ArrayNodeIter) Value() Node {
+ return m.values[m.idx]
+}
+
+// Len returns length of array
+func (m *ArrayNodeIter) Len() int {
+ return len(m.values)
+}
+
+// SequenceNode type of sequence node
+type SequenceNode struct {
+ *BaseNode
+ Start *token.Token
+ End *token.Token
+ IsFlowStyle bool
+ Values []Node
+ ValueHeadComments []*CommentGroupNode
+ Entries []*SequenceEntryNode
+ FootComment *CommentGroupNode
+}
+
+// Replace replace value node.
+func (n *SequenceNode) Replace(idx int, value Node) error {
+ if len(n.Values) <= idx {
+ return fmt.Errorf(
+ "invalid index for sequence: sequence length is %d, but specified %d index",
+ len(n.Values), idx,
+ )
+ }
+ column := n.Values[idx].GetToken().Position.Column - value.GetToken().Position.Column
+ value.AddColumn(column)
+ n.Values[idx] = value
+ return nil
+}
+
+// Merge merge sequence value.
+func (n *SequenceNode) Merge(target *SequenceNode) {
+ column := n.Start.Position.Column - target.Start.Position.Column
+ target.AddColumn(column)
+ n.Values = append(n.Values, target.Values...)
+ if len(target.ValueHeadComments) == 0 {
+ n.ValueHeadComments = append(n.ValueHeadComments, make([]*CommentGroupNode, len(target.Values))...)
+ return
+ }
+ n.ValueHeadComments = append(n.ValueHeadComments, target.ValueHeadComments...)
+}
+
+// SetIsFlowStyle set value to IsFlowStyle field recursively.
+func (n *SequenceNode) SetIsFlowStyle(isFlow bool) {
+ n.IsFlowStyle = isFlow
+ for _, value := range n.Values {
+ switch value := value.(type) {
+ case *MappingNode:
+ value.SetIsFlowStyle(isFlow)
+ case *MappingValueNode:
+ value.SetIsFlowStyle(isFlow)
+ case *SequenceNode:
+ value.SetIsFlowStyle(isFlow)
+ }
+ }
+}
+
+// Read implements (io.Reader).Read
+func (n *SequenceNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns SequenceType
+func (n *SequenceNode) Type() NodeType { return SequenceType }
+
+// GetToken returns token instance
+func (n *SequenceNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *SequenceNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ n.End.AddColumn(col)
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+func (n *SequenceNode) flowStyleString() string {
+ values := []string{}
+ for _, value := range n.Values {
+ values = append(values, value.String())
+ }
+ seqText := fmt.Sprintf("[%s]", strings.Join(values, ", "))
+ if n.Comment != nil {
+ return addCommentString(seqText, n.Comment)
+ }
+ return seqText
+}
+
+func (n *SequenceNode) blockStyleString() string {
+ space := strings.Repeat(" ", n.Start.Position.Column-1)
+ values := []string{}
+ if n.Comment != nil {
+ values = append(values, n.Comment.StringWithSpace(n.Start.Position.Column-1))
+ }
+
+ for idx, value := range n.Values {
+ if value == nil {
+ continue
+ }
+ valueStr := value.String()
+ newLinePrefix := ""
+ if strings.HasPrefix(valueStr, "\n") {
+ valueStr = valueStr[1:]
+ newLinePrefix = "\n"
+ }
+ splittedValues := strings.Split(valueStr, "\n")
+ trimmedFirstValue := strings.TrimLeft(splittedValues[0], " ")
+ diffLength := len(splittedValues[0]) - len(trimmedFirstValue)
+ if len(splittedValues) > 1 && value.Type() == StringType || value.Type() == LiteralType {
+ // If multi-line string, the space characters for indent have already been added, so delete them.
+ prefix := space + " "
+ for i := 1; i < len(splittedValues); i++ {
+ splittedValues[i] = strings.TrimPrefix(splittedValues[i], prefix)
+ }
+ }
+ newValues := []string{trimmedFirstValue}
+ for i := 1; i < len(splittedValues); i++ {
+ if len(splittedValues[i]) <= diffLength {
+ // this line is \n or white space only
+ newValues = append(newValues, "")
+ continue
+ }
+ trimmed := splittedValues[i][diffLength:]
+ newValues = append(newValues, fmt.Sprintf("%s %s", space, trimmed))
+ }
+ newValue := strings.Join(newValues, "\n")
+ if len(n.ValueHeadComments) == len(n.Values) && n.ValueHeadComments[idx] != nil {
+ values = append(values, fmt.Sprintf("%s%s", newLinePrefix, n.ValueHeadComments[idx].StringWithSpace(n.Start.Position.Column-1)))
+ newLinePrefix = ""
+ }
+ values = append(values, fmt.Sprintf("%s%s- %s", newLinePrefix, space, newValue))
+ }
+ if n.FootComment != nil {
+ values = append(values, n.FootComment.StringWithSpace(n.Start.Position.Column-1))
+ }
+ return strings.Join(values, "\n")
+}
+
+// String sequence to text
+func (n *SequenceNode) String() string {
+ if n.IsFlowStyle || len(n.Values) == 0 {
+ return n.flowStyleString()
+ }
+ return n.blockStyleString()
+}
+
+// ArrayRange implements ArrayNode protocol
+func (n *SequenceNode) ArrayRange() *ArrayNodeIter {
+ return &ArrayNodeIter{
+ idx: startRangeIndex,
+ values: n.Values,
+ }
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *SequenceNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// SequenceEntryNode is the sequence entry.
+type SequenceEntryNode struct {
+ *BaseNode
+ HeadComment *CommentGroupNode // head comment.
+ LineComment *CommentGroupNode // line comment e.g.) - # comment.
+ Start *token.Token // entry token.
+ Value Node // value node.
+}
+
+// String node to text
+func (n *SequenceEntryNode) String() string {
+ return "" // TODO
+}
+
+// GetToken returns token instance
+func (n *SequenceEntryNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// Type returns type of node
+func (n *SequenceEntryNode) Type() NodeType {
+ return SequenceEntryType
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *SequenceEntryNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+}
+
+// SetComment set line comment.
+func (n *SequenceEntryNode) SetComment(cm *CommentGroupNode) error {
+ n.LineComment = cm
+ return nil
+}
+
+// Comment returns comment token instance
+func (n *SequenceEntryNode) GetComment() *CommentGroupNode {
+ return n.LineComment
+}
+
+// MarshalYAML
+func (n *SequenceEntryNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+func (n *SequenceEntryNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// SequenceEntry creates SequenceEntryNode instance.
+func SequenceEntry(start *token.Token, value Node, headComment *CommentGroupNode) *SequenceEntryNode {
+ return &SequenceEntryNode{
+ BaseNode: &BaseNode{},
+ HeadComment: headComment,
+ Start: start,
+ Value: value,
+ }
+}
+
+// SequenceMergeValue creates SequenceMergeValueNode instance.
+func SequenceMergeValue(values ...MapNode) *SequenceMergeValueNode {
+ return &SequenceMergeValueNode{
+ values: values,
+ }
+}
+
+// SequenceMergeValueNode is used to convert the Sequence node specified for the merge key into a MapNode format.
+type SequenceMergeValueNode struct {
+ values []MapNode
+}
+
+// MapRange returns MapNodeIter instance.
+func (n *SequenceMergeValueNode) MapRange() *MapNodeIter {
+ ret := &MapNodeIter{idx: startRangeIndex}
+ for _, value := range n.values {
+ iter := value.MapRange()
+ ret.values = append(ret.values, iter.values...)
+ }
+ return ret
+}
+
+// AnchorNode type of anchor node
+type AnchorNode struct {
+ *BaseNode
+ Start *token.Token
+ Name Node
+ Value Node
+}
+
+func (n *AnchorNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+func (n *AnchorNode) SetName(name string) error {
+ if n.Name == nil {
+ return ErrInvalidAnchorName
+ }
+ s, ok := n.Name.(*StringNode)
+ if !ok {
+ return ErrInvalidAnchorName
+ }
+ s.Value = name
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *AnchorNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns AnchorType
+func (n *AnchorNode) Type() NodeType { return AnchorType }
+
+// GetToken returns token instance
+func (n *AnchorNode) GetToken() *token.Token {
+ return n.Start
+}
+
+func (n *AnchorNode) GetValue() any {
+ return n.Value.GetToken().Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *AnchorNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Name != nil {
+ n.Name.AddColumn(col)
+ }
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String anchor to text
+func (n *AnchorNode) String() string {
+ anchor := "&" + n.Name.String()
+ value := n.Value.String()
+ if s, ok := n.Value.(*SequenceNode); ok && !s.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", anchor, value)
+ } else if m, ok := n.Value.(*MappingNode); ok && !m.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", anchor, value)
+ }
+ if value == "" {
+ // implicit null value.
+ return anchor
+ }
+ return fmt.Sprintf("%s %s", anchor, value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *AnchorNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *AnchorNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+// AliasNode type of alias node
+type AliasNode struct {
+ *BaseNode
+ Start *token.Token
+ Value Node
+}
+
+func (n *AliasNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+func (n *AliasNode) SetName(name string) error {
+ if n.Value == nil {
+ return ErrInvalidAliasName
+ }
+ s, ok := n.Value.(*StringNode)
+ if !ok {
+ return ErrInvalidAliasName
+ }
+ s.Value = name
+ return nil
+}
+
+// Read implements (io.Reader).Read
+func (n *AliasNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns AliasType
+func (n *AliasNode) Type() NodeType { return AliasType }
+
+// GetToken returns token instance
+func (n *AliasNode) GetToken() *token.Token {
+ return n.Start
+}
+
+func (n *AliasNode) GetValue() any {
+ return n.Value.GetToken().Value
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *AliasNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String alias to text
+func (n *AliasNode) String() string {
+ return fmt.Sprintf("*%s", n.Value.String())
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *AliasNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *AliasNode) IsMergeKey() bool {
+ return false
+}
+
+// DirectiveNode type of directive node
+type DirectiveNode struct {
+ *BaseNode
+ // Start is '%' token.
+ Start *token.Token
+ // Name is directive name e.g.) "YAML" or "TAG".
+ Name Node
+ // Values is directive values e.g.) "1.2" or "!!" and "tag:clarkevans.com,2002:app/".
+ Values []Node
+}
+
+// Read implements (io.Reader).Read
+func (n *DirectiveNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns DirectiveType
+func (n *DirectiveNode) Type() NodeType { return DirectiveType }
+
+// GetToken returns token instance
+func (n *DirectiveNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *DirectiveNode) AddColumn(col int) {
+ if n.Name != nil {
+ n.Name.AddColumn(col)
+ }
+ for _, value := range n.Values {
+ value.AddColumn(col)
+ }
+}
+
+// String directive to text
+func (n *DirectiveNode) String() string {
+ values := make([]string, 0, len(n.Values))
+ for _, val := range n.Values {
+ values = append(values, val.String())
+ }
+ return strings.Join(append([]string{"%" + n.Name.String()}, values...), " ")
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *DirectiveNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// TagNode type of tag node
+type TagNode struct {
+ *BaseNode
+ Directive *DirectiveNode
+ Start *token.Token
+ Value Node
+}
+
+func (n *TagNode) GetValue() any {
+ scalar, ok := n.Value.(ScalarNode)
+ if !ok {
+ return nil
+ }
+ return scalar.GetValue()
+}
+
+func (n *TagNode) stringWithoutComment() string {
+ return n.Value.String()
+}
+
+// Read implements (io.Reader).Read
+func (n *TagNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *TagNode) Type() NodeType { return TagType }
+
+// GetToken returns token instance
+func (n *TagNode) GetToken() *token.Token {
+ return n.Start
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *TagNode) AddColumn(col int) {
+ n.Start.AddColumn(col)
+ if n.Value != nil {
+ n.Value.AddColumn(col)
+ }
+}
+
+// String tag to text
+func (n *TagNode) String() string {
+ value := n.Value.String()
+ if s, ok := n.Value.(*SequenceNode); ok && !s.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", n.Start.Value, value)
+ } else if m, ok := n.Value.(*MappingNode); ok && !m.IsFlowStyle {
+ return fmt.Sprintf("%s\n%s", n.Start.Value, value)
+ }
+
+ return fmt.Sprintf("%s %s", n.Start.Value, value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *TagNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// IsMergeKey returns whether it is a MergeKey node.
+func (n *TagNode) IsMergeKey() bool {
+ if n.Value == nil {
+ return false
+ }
+ key, ok := n.Value.(MapKeyNode)
+ if !ok {
+ return false
+ }
+ return key.IsMergeKey()
+}
+
+func (n *TagNode) ArrayRange() *ArrayNodeIter {
+ arr, ok := n.Value.(ArrayNode)
+ if !ok {
+ return nil
+ }
+ return arr.ArrayRange()
+}
+
+// CommentNode type of comment node
+type CommentNode struct {
+ *BaseNode
+ Token *token.Token
+}
+
+// Read implements (io.Reader).Read
+func (n *CommentNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *CommentNode) Type() NodeType { return CommentType }
+
+// GetToken returns token instance
+func (n *CommentNode) GetToken() *token.Token { return n.Token }
+
+// AddColumn add column number to child nodes recursively
+func (n *CommentNode) AddColumn(col int) {
+ if n.Token == nil {
+ return
+ }
+ n.Token.AddColumn(col)
+}
+
+// String comment to text
+func (n *CommentNode) String() string {
+ return fmt.Sprintf("#%s", n.Token.Value)
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *CommentNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// CommentGroupNode type of comment node
+type CommentGroupNode struct {
+ *BaseNode
+ Comments []*CommentNode
+}
+
+// Read implements (io.Reader).Read
+func (n *CommentGroupNode) Read(p []byte) (int, error) {
+ return readNode(p, n)
+}
+
+// Type returns TagType
+func (n *CommentGroupNode) Type() NodeType { return CommentType }
+
+// GetToken returns token instance
+func (n *CommentGroupNode) GetToken() *token.Token {
+ if len(n.Comments) > 0 {
+ return n.Comments[0].Token
+ }
+ return nil
+}
+
+// AddColumn add column number to child nodes recursively
+func (n *CommentGroupNode) AddColumn(col int) {
+ for _, comment := range n.Comments {
+ comment.AddColumn(col)
+ }
+}
+
+// String comment to text
+func (n *CommentGroupNode) String() string {
+ values := []string{}
+ for _, comment := range n.Comments {
+ values = append(values, comment.String())
+ }
+ return strings.Join(values, "\n")
+}
+
+func (n *CommentGroupNode) StringWithSpace(col int) string {
+ values := []string{}
+ space := strings.Repeat(" ", col)
+ for _, comment := range n.Comments {
+ space := space
+ if checkLineBreak(comment.Token) {
+ space = fmt.Sprintf("%s%s", "\n", space)
+ }
+ values = append(values, space+comment.String())
+ }
+ return strings.Join(values, "\n")
+}
+
+// MarshalYAML encodes to a YAML text
+func (n *CommentGroupNode) MarshalYAML() ([]byte, error) {
+ return []byte(n.String()), nil
+}
+
+// Visitor has Visit method that is invokded for each node encountered by Walk.
+// If the result visitor w is not nil, Walk visits each of the children of node with the visitor w,
+// followed by a call of w.Visit(nil).
+type Visitor interface {
+ Visit(Node) Visitor
+}
+
+// Walk traverses an AST in depth-first order: It starts by calling v.Visit(node); node must not be nil.
+// If the visitor w returned by v.Visit(node) is not nil,
+// Walk is invoked recursively with visitor w for each of the non-nil children of node,
+// followed by a call of w.Visit(nil).
+func Walk(v Visitor, node Node) {
+ if v = v.Visit(node); v == nil {
+ return
+ }
+
+ switch n := node.(type) {
+ case *CommentNode:
+ case *NullNode:
+ walkComment(v, n.BaseNode)
+ case *IntegerNode:
+ walkComment(v, n.BaseNode)
+ case *FloatNode:
+ walkComment(v, n.BaseNode)
+ case *StringNode:
+ walkComment(v, n.BaseNode)
+ case *MergeKeyNode:
+ walkComment(v, n.BaseNode)
+ case *BoolNode:
+ walkComment(v, n.BaseNode)
+ case *InfinityNode:
+ walkComment(v, n.BaseNode)
+ case *NanNode:
+ walkComment(v, n.BaseNode)
+ case *LiteralNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *DirectiveNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Name)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *TagNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *DocumentNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Body)
+ case *MappingNode:
+ walkComment(v, n.BaseNode)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *MappingKeyNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ case *MappingValueNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Key)
+ Walk(v, n.Value)
+ case *SequenceNode:
+ walkComment(v, n.BaseNode)
+ for _, value := range n.Values {
+ Walk(v, value)
+ }
+ case *AnchorNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Name)
+ Walk(v, n.Value)
+ case *AliasNode:
+ walkComment(v, n.BaseNode)
+ Walk(v, n.Value)
+ }
+}
+
+func walkComment(v Visitor, base *BaseNode) {
+ if base == nil {
+ return
+ }
+ if base.Comment == nil {
+ return
+ }
+ Walk(v, base.Comment)
+}
+
+type filterWalker struct {
+ typ NodeType
+ results []Node
+}
+
+func (v *filterWalker) Visit(n Node) Visitor {
+ if v.typ == n.Type() {
+ v.results = append(v.results, n)
+ }
+ return v
+}
+
+type parentFinder struct {
+ target Node
+}
+
+func (f *parentFinder) walk(parent, node Node) Node {
+ if f.target == node {
+ return parent
+ }
+ switch n := node.(type) {
+ case *CommentNode:
+ return nil
+ case *NullNode:
+ return nil
+ case *IntegerNode:
+ return nil
+ case *FloatNode:
+ return nil
+ case *StringNode:
+ return nil
+ case *MergeKeyNode:
+ return nil
+ case *BoolNode:
+ return nil
+ case *InfinityNode:
+ return nil
+ case *NanNode:
+ return nil
+ case *LiteralNode:
+ return f.walk(node, n.Value)
+ case *DirectiveNode:
+ if found := f.walk(node, n.Name); found != nil {
+ return found
+ }
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *TagNode:
+ return f.walk(node, n.Value)
+ case *DocumentNode:
+ return f.walk(node, n.Body)
+ case *MappingNode:
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *MappingKeyNode:
+ return f.walk(node, n.Value)
+ case *MappingValueNode:
+ if found := f.walk(node, n.Key); found != nil {
+ return found
+ }
+ return f.walk(node, n.Value)
+ case *SequenceNode:
+ for _, value := range n.Values {
+ if found := f.walk(node, value); found != nil {
+ return found
+ }
+ }
+ case *AnchorNode:
+ if found := f.walk(node, n.Name); found != nil {
+ return found
+ }
+ return f.walk(node, n.Value)
+ case *AliasNode:
+ return f.walk(node, n.Value)
+ }
+ return nil
+}
+
+// Parent get parent node from child node.
+func Parent(root, child Node) Node {
+ finder := &parentFinder{target: child}
+ return finder.walk(root, root)
+}
+
+// Filter returns a list of nodes that match the given type.
+func Filter(typ NodeType, node Node) []Node {
+ walker := &filterWalker{typ: typ}
+ Walk(walker, node)
+ return walker.results
+}
+
+// FilterFile returns a list of nodes that match the given type.
+func FilterFile(typ NodeType, file *File) []Node {
+ results := []Node{}
+ for _, doc := range file.Docs {
+ walker := &filterWalker{typ: typ}
+ Walk(walker, doc)
+ results = append(results, walker.results...)
+ }
+ return results
+}
+
+type ErrInvalidMergeType struct {
+ dst Node
+ src Node
+}
+
+func (e *ErrInvalidMergeType) Error() string {
+ return fmt.Sprintf("cannot merge %s into %s", e.src.Type(), e.dst.Type())
+}
+
+// Merge merge document, map, sequence node.
+func Merge(dst Node, src Node) error {
+ if doc, ok := src.(*DocumentNode); ok {
+ src = doc.Body
+ }
+ err := &ErrInvalidMergeType{dst: dst, src: src}
+ switch dst.Type() {
+ case DocumentType:
+ node, _ := dst.(*DocumentNode)
+ return Merge(node.Body, src)
+ case MappingType:
+ node, _ := dst.(*MappingNode)
+ target, ok := src.(*MappingNode)
+ if !ok {
+ return err
+ }
+ node.Merge(target)
+ return nil
+ case SequenceType:
+ node, _ := dst.(*SequenceNode)
+ target, ok := src.(*SequenceNode)
+ if !ok {
+ return err
+ }
+ node.Merge(target)
+ return nil
+ }
+ return err
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/context.go b/sesh/vendor/github.com/goccy/go-yaml/context.go
new file mode 100644
index 0000000..133f05e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/context.go
@@ -0,0 +1,37 @@
+package yaml
+
+import "context"
+
+type (
+ ctxMergeKey struct{}
+ ctxAnchorKey struct{}
+)
+
+func withMerge(ctx context.Context) context.Context {
+ return context.WithValue(ctx, ctxMergeKey{}, true)
+}
+
+func isMerge(ctx context.Context) bool {
+ v, ok := ctx.Value(ctxMergeKey{}).(bool)
+ if !ok {
+ return false
+ }
+ return v
+}
+
+func withAnchor(ctx context.Context, name string) context.Context {
+ anchorMap := getAnchorMap(ctx)
+ if anchorMap == nil {
+ anchorMap = make(map[string]struct{})
+ }
+ anchorMap[name] = struct{}{}
+ return context.WithValue(ctx, ctxAnchorKey{}, anchorMap)
+}
+
+func getAnchorMap(ctx context.Context) map[string]struct{} {
+ v, ok := ctx.Value(ctxAnchorKey{}).(map[string]struct{})
+ if !ok {
+ return nil
+ }
+ return v
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/decode.go b/sesh/vendor/github.com/goccy/go-yaml/decode.go
new file mode 100644
index 0000000..e9b3baa
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/decode.go
@@ -0,0 +1,2037 @@
+package yaml
+
+import (
+ "bytes"
+ "context"
+ "encoding"
+ "encoding/base64"
+ "fmt"
+ "io"
+ "maps"
+ "math"
+ "os"
+ "path/filepath"
+ "reflect"
+ "sort"
+ "strconv"
+ "strings"
+ "time"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/internal/format"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Decoder reads and decodes YAML values from an input stream.
+type Decoder struct {
+ reader io.Reader
+ referenceReaders []io.Reader
+ anchorNodeMap map[string]ast.Node
+ anchorValueMap map[string]reflect.Value
+ customUnmarshalerMap map[reflect.Type]func(context.Context, interface{}, []byte) error
+ commentMaps []CommentMap
+ toCommentMap CommentMap
+ opts []DecodeOption
+ referenceFiles []string
+ referenceDirs []string
+ isRecursiveDir bool
+ isResolvedReference bool
+ validator StructValidator
+ disallowUnknownField bool
+ allowedFieldPrefixes []string
+ allowDuplicateMapKey bool
+ useOrderedMap bool
+ useJSONUnmarshaler bool
+ parsedFile *ast.File
+ streamIndex int
+ decodeDepth int
+}
+
+// NewDecoder returns a new decoder that reads from r.
+func NewDecoder(r io.Reader, opts ...DecodeOption) *Decoder {
+ return &Decoder{
+ reader: r,
+ anchorNodeMap: map[string]ast.Node{},
+ anchorValueMap: map[string]reflect.Value{},
+ customUnmarshalerMap: map[reflect.Type]func(context.Context, interface{}, []byte) error{},
+ opts: opts,
+ referenceReaders: []io.Reader{},
+ referenceFiles: []string{},
+ referenceDirs: []string{},
+ isRecursiveDir: false,
+ isResolvedReference: false,
+ disallowUnknownField: false,
+ allowDuplicateMapKey: false,
+ useOrderedMap: false,
+ }
+}
+
+const maxDecodeDepth = 10000
+
+func (d *Decoder) stepIn() {
+ d.decodeDepth++
+}
+
+func (d *Decoder) stepOut() {
+ d.decodeDepth--
+}
+
+func (d *Decoder) isExceededMaxDepth() bool {
+ return d.decodeDepth > maxDecodeDepth
+}
+
+func (d *Decoder) castToFloat(v interface{}) interface{} {
+ switch vv := v.(type) {
+ case int:
+ return float64(vv)
+ case int8:
+ return float64(vv)
+ case int16:
+ return float64(vv)
+ case int32:
+ return float64(vv)
+ case int64:
+ return float64(vv)
+ case uint:
+ return float64(vv)
+ case uint8:
+ return float64(vv)
+ case uint16:
+ return float64(vv)
+ case uint32:
+ return float64(vv)
+ case uint64:
+ return float64(vv)
+ case float32:
+ return float64(vv)
+ case float64:
+ return vv
+ case string:
+ // if error occurred, return zero value
+ f, _ := strconv.ParseFloat(vv, 64)
+ return f
+ }
+ return 0
+}
+
+func (d *Decoder) mapKeyNodeToString(ctx context.Context, node ast.MapKeyNode) (string, error) {
+ key, err := d.nodeToValue(ctx, node)
+ if err != nil {
+ return "", err
+ }
+ if key == nil {
+ return "null", nil
+ }
+ if k, ok := key.(string); ok {
+ return k, nil
+ }
+ return fmt.Sprint(key), nil
+}
+
+func (d *Decoder) setToMapValue(ctx context.Context, node ast.Node, m map[string]interface{}) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return err
+ }
+ iter := value.MapRange()
+ for iter.Next() {
+ if err := d.setToMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return err
+ }
+ }
+ } else {
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return err
+ }
+ m[key] = v
+ }
+ case *ast.MappingNode:
+ for _, value := range n.Values {
+ if err := d.setToMapValue(ctx, value, m); err != nil {
+ return err
+ }
+ }
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+ d.anchorNodeMap[anchorName] = n.Value
+ }
+ return nil
+}
+
+func (d *Decoder) setToOrderedMapValue(ctx context.Context, node ast.Node, m *MapSlice) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return err
+ }
+ iter := value.MapRange()
+ for iter.Next() {
+ if err := d.setToOrderedMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return err
+ }
+ }
+ } else {
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return err
+ }
+ value, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return err
+ }
+ *m = append(*m, MapItem{Key: key, Value: value})
+ }
+ case *ast.MappingNode:
+ for _, value := range n.Values {
+ if err := d.setToOrderedMapValue(ctx, value, m); err != nil {
+ return err
+ }
+ }
+ }
+ return nil
+}
+
+func (d *Decoder) setPathToCommentMap(node ast.Node) {
+ if node == nil {
+ return
+ }
+ if d.toCommentMap == nil {
+ return
+ }
+ d.addHeadOrLineCommentToMap(node)
+ d.addFootCommentToMap(node)
+}
+
+func (d *Decoder) addHeadOrLineCommentToMap(node ast.Node) {
+ sequence, ok := node.(*ast.SequenceNode)
+ if ok {
+ d.addSequenceNodeCommentToMap(sequence)
+ return
+ }
+ commentGroup := node.GetComment()
+ if commentGroup == nil {
+ return
+ }
+ texts := []string{}
+ targetLine := node.GetToken().Position.Line
+ minCommentLine := math.MaxInt
+ for _, comment := range commentGroup.Comments {
+ if minCommentLine > comment.Token.Position.Line {
+ minCommentLine = comment.Token.Position.Line
+ }
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) == 0 {
+ return
+ }
+ commentPath := node.GetPath()
+ if minCommentLine < targetLine {
+ switch n := node.(type) {
+ case *ast.MappingNode:
+ if len(n.Values) != 0 {
+ commentPath = n.Values[0].Key.GetPath()
+ }
+ case *ast.MappingValueNode:
+ commentPath = n.Key.GetPath()
+ }
+ d.addCommentToMap(commentPath, HeadComment(texts...))
+ } else {
+ d.addCommentToMap(commentPath, LineComment(texts[0]))
+ }
+}
+
+func (d *Decoder) addSequenceNodeCommentToMap(node *ast.SequenceNode) {
+ if len(node.ValueHeadComments) != 0 {
+ for idx, headComment := range node.ValueHeadComments {
+ if headComment == nil {
+ continue
+ }
+ texts := make([]string, 0, len(headComment.Comments))
+ for _, comment := range headComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ d.addCommentToMap(node.Values[idx].GetPath(), HeadComment(texts...))
+ }
+ }
+ }
+ firstElemHeadComment := node.GetComment()
+ if firstElemHeadComment != nil {
+ texts := make([]string, 0, len(firstElemHeadComment.Comments))
+ for _, comment := range firstElemHeadComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ if len(node.Values) != 0 {
+ d.addCommentToMap(node.Values[0].GetPath(), HeadComment(texts...))
+ }
+ }
+ }
+}
+
+func (d *Decoder) addFootCommentToMap(node ast.Node) {
+ var (
+ footComment *ast.CommentGroupNode
+ footCommentPath = node.GetPath()
+ )
+ switch n := node.(type) {
+ case *ast.SequenceNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ case *ast.MappingNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ case *ast.MappingValueNode:
+ footComment = n.FootComment
+ if n.FootComment != nil {
+ footCommentPath = n.FootComment.GetPath()
+ }
+ }
+ if footComment == nil {
+ return
+ }
+ var texts []string
+ for _, comment := range footComment.Comments {
+ texts = append(texts, comment.Token.Value)
+ }
+ if len(texts) != 0 {
+ d.addCommentToMap(footCommentPath, FootComment(texts...))
+ }
+}
+
+func (d *Decoder) addCommentToMap(path string, comment *Comment) {
+ for _, c := range d.toCommentMap[path] {
+ if c.Position == comment.Position {
+ // already added same comment
+ return
+ }
+ }
+ d.toCommentMap[path] = append(d.toCommentMap[path], comment)
+ sort.Slice(d.toCommentMap[path], func(i, j int) bool {
+ return d.toCommentMap[path][i].Position < d.toCommentMap[path][j].Position
+ })
+}
+
+func (d *Decoder) nodeToValue(ctx context.Context, node ast.Node) (any, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ d.setPathToCommentMap(node)
+ switch n := node.(type) {
+ case *ast.NullNode:
+ return nil, nil
+ case *ast.StringNode:
+ return n.GetValue(), nil
+ case *ast.IntegerNode:
+ return n.GetValue(), nil
+ case *ast.FloatNode:
+ return n.GetValue(), nil
+ case *ast.BoolNode:
+ return n.GetValue(), nil
+ case *ast.InfinityNode:
+ return n.GetValue(), nil
+ case *ast.NanNode:
+ return n.GetValue(), nil
+ case *ast.TagNode:
+ if n.Directive != nil {
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ if v == nil {
+ return "", nil
+ }
+ return fmt.Sprint(v), nil
+ }
+ switch token.ReservedTagKeyword(n.Start.Value) {
+ case token.TimestampTag:
+ t, _ := d.castToTime(ctx, n.Value)
+ return t, nil
+ case token.IntegerTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ i, _ := strconv.Atoi(fmt.Sprint(v))
+ return i, nil
+ case token.FloatTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return d.castToFloat(v), nil
+ case token.NullTag:
+ return nil, nil
+ case token.BinaryTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ str, ok := v.(string)
+ if !ok {
+ return nil, errors.ErrSyntax(
+ fmt.Sprintf("cannot convert %q to string", fmt.Sprint(v)),
+ n.Value.GetToken(),
+ )
+ }
+ b, _ := base64.StdEncoding.DecodeString(str)
+ return b, nil
+ case token.BooleanTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ str := strings.ToLower(fmt.Sprint(v))
+ b, err := strconv.ParseBool(str)
+ if err == nil {
+ return b, nil
+ }
+ switch str {
+ case "yes":
+ return true, nil
+ case "no":
+ return false, nil
+ }
+ return nil, errors.ErrSyntax(fmt.Sprintf("cannot convert %q to boolean", fmt.Sprint(v)), n.Value.GetToken())
+ case token.StringTag:
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ if v == nil {
+ return "", nil
+ }
+ return fmt.Sprint(v), nil
+ case token.MappingTag:
+ return d.nodeToValue(ctx, n.Value)
+ default:
+ return d.nodeToValue(ctx, n.Value)
+ }
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+
+ // To handle the case where alias is processed recursively, the result of alias can be set to nil in advance.
+ d.anchorNodeMap[anchorName] = nil
+ anchorValue, err := d.nodeToValue(withAnchor(ctx, anchorName), n.Value)
+ if err != nil {
+ delete(d.anchorNodeMap, anchorName)
+ return nil, err
+ }
+ d.anchorNodeMap[anchorName] = n.Value
+ d.anchorValueMap[anchorName] = reflect.ValueOf(anchorValue)
+ return anchorValue, nil
+ case *ast.AliasNode:
+ text := n.Value.String()
+ if _, exists := getAnchorMap(ctx)[text]; exists {
+ // self recursion.
+ return nil, nil
+ }
+ if v, exists := d.anchorValueMap[text]; exists {
+ if !v.IsValid() {
+ return nil, nil
+ }
+ return v.Interface(), nil
+ }
+ if node, exists := d.anchorNodeMap[text]; exists {
+ return d.nodeToValue(ctx, node)
+ }
+ return nil, errors.ErrSyntax(fmt.Sprintf("could not find alias %q", text), n.Value.GetToken())
+ case *ast.LiteralNode:
+ return n.Value.GetValue(), nil
+ case *ast.MappingKeyNode:
+ return d.nodeToValue(ctx, n.Value)
+ case *ast.MappingValueNode:
+ if n.Key.IsMergeKey() {
+ value, err := d.getMapNode(n.Value, true)
+ if err != nil {
+ return nil, err
+ }
+ iter := value.MapRange()
+ if d.useOrderedMap {
+ m := MapSlice{}
+ for iter.Next() {
+ if err := d.setToOrderedMapValue(ctx, iter.KeyValue(), &m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ m := make(map[string]any)
+ for iter.Next() {
+ if err := d.setToMapValue(ctx, iter.KeyValue(), m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ key, err := d.mapKeyNodeToString(ctx, n.Key)
+ if err != nil {
+ return nil, err
+ }
+ if d.useOrderedMap {
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return MapSlice{{Key: key, Value: v}}, nil
+ }
+ v, err := d.nodeToValue(ctx, n.Value)
+ if err != nil {
+ return nil, err
+ }
+ return map[string]interface{}{key: v}, nil
+ case *ast.MappingNode:
+ if d.useOrderedMap {
+ m := make(MapSlice, 0, len(n.Values))
+ for _, value := range n.Values {
+ if err := d.setToOrderedMapValue(ctx, value, &m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ }
+ m := make(map[string]interface{}, len(n.Values))
+ for _, value := range n.Values {
+ if err := d.setToMapValue(ctx, value, m); err != nil {
+ return nil, err
+ }
+ }
+ return m, nil
+ case *ast.SequenceNode:
+ v := make([]interface{}, 0, len(n.Values))
+ for _, value := range n.Values {
+ vv, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return nil, err
+ }
+ v = append(v, vv)
+ }
+ return v, nil
+ }
+ return nil, nil
+}
+
+func (d *Decoder) getMapNode(node ast.Node, isMerge bool) (ast.MapNode, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ switch n := node.(type) {
+ case ast.MapNode:
+ return n, nil
+ case *ast.AnchorNode:
+ anchorName := n.Name.GetToken().Value
+ d.anchorNodeMap[anchorName] = n.Value
+ return d.getMapNode(n.Value, isMerge)
+ case *ast.AliasNode:
+ aliasName := n.Value.GetToken().Value
+ node := d.anchorNodeMap[aliasName]
+ if node == nil {
+ return nil, fmt.Errorf("cannot find anchor by alias name %s", aliasName)
+ }
+ return d.getMapNode(node, isMerge)
+ case *ast.SequenceNode:
+ if !isMerge {
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.MappingType, node.GetToken())
+ }
+ var mapNodes []ast.MapNode
+ for _, value := range n.Values {
+ mapNode, err := d.getMapNode(value, false)
+ if err != nil {
+ return nil, err
+ }
+ mapNodes = append(mapNodes, mapNode)
+ }
+ return ast.SequenceMergeValue(mapNodes...), nil
+ }
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.MappingType, node.GetToken())
+}
+
+func (d *Decoder) getArrayNode(node ast.Node) (ast.ArrayNode, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ if _, ok := node.(*ast.NullNode); ok {
+ return nil, nil
+ }
+ if anchor, ok := node.(*ast.AnchorNode); ok {
+ arrayNode, ok := anchor.Value.(ast.ArrayNode)
+ if ok {
+ return arrayNode, nil
+ }
+
+ return nil, errors.ErrUnexpectedNodeType(anchor.Value.Type(), ast.SequenceType, node.GetToken())
+ }
+ if alias, ok := node.(*ast.AliasNode); ok {
+ aliasName := alias.Value.GetToken().Value
+ node := d.anchorNodeMap[aliasName]
+ if node == nil {
+ return nil, fmt.Errorf("cannot find anchor by alias name %s", aliasName)
+ }
+ arrayNode, ok := node.(ast.ArrayNode)
+ if ok {
+ return arrayNode, nil
+ }
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.SequenceType, node.GetToken())
+ }
+ arrayNode, ok := node.(ast.ArrayNode)
+ if !ok {
+ return nil, errors.ErrUnexpectedNodeType(node.Type(), ast.SequenceType, node.GetToken())
+ }
+ return arrayNode, nil
+}
+
+func (d *Decoder) convertValue(v reflect.Value, typ reflect.Type, src ast.Node) (reflect.Value, error) {
+ if typ.Kind() != reflect.String {
+ if !v.Type().ConvertibleTo(typ) {
+
+ // Special case for "strings -> floats" aka scientific notation
+ // If the destination type is a float and the source type is a string, check if we can
+ // use strconv.ParseFloat to convert the string to a float.
+ if (typ.Kind() == reflect.Float32 || typ.Kind() == reflect.Float64) &&
+ v.Type().Kind() == reflect.String {
+ if f, err := strconv.ParseFloat(v.String(), 64); err == nil {
+ if typ.Kind() == reflect.Float32 {
+ return reflect.ValueOf(float32(f)), nil
+ } else if typ.Kind() == reflect.Float64 {
+ return reflect.ValueOf(f), nil
+ }
+ // else, fall through to the error below
+ }
+ }
+ return reflect.Zero(typ), errors.ErrTypeMismatch(typ, v.Type(), src.GetToken())
+ }
+ return v.Convert(typ), nil
+ }
+ // cast value to string
+ var strVal string
+ switch v.Type().Kind() {
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ strVal = strconv.FormatInt(v.Int(), 10)
+ case reflect.Float32, reflect.Float64:
+ strVal = fmt.Sprint(v.Float())
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ strVal = strconv.FormatUint(v.Uint(), 10)
+ case reflect.Bool:
+ strVal = strconv.FormatBool(v.Bool())
+ default:
+ if !v.Type().ConvertibleTo(typ) {
+ return reflect.Zero(typ), errors.ErrTypeMismatch(typ, v.Type(), src.GetToken())
+ }
+ return v.Convert(typ), nil
+ }
+
+ val := reflect.ValueOf(strVal)
+ if val.Type() != typ {
+ // Handle named types, e.g., `type MyString string`
+ val = val.Convert(typ)
+ }
+ return val, nil
+}
+
+func (d *Decoder) deleteStructKeys(structType reflect.Type, unknownFields map[string]ast.Node) error {
+ if structType.Kind() == reflect.Ptr {
+ structType = structType.Elem()
+ }
+ structFieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return err
+ }
+
+ for j := 0; j < structType.NumField(); j++ {
+ field := structType.Field(j)
+ if isIgnoredStructField(field) {
+ continue
+ }
+
+ structField, exists := structFieldMap[field.Name]
+ if !exists {
+ continue
+ }
+
+ if structField.IsInline {
+ _ = d.deleteStructKeys(field.Type, unknownFields)
+ } else {
+ delete(unknownFields, structField.RenderName)
+ }
+ }
+ return nil
+}
+
+func (d *Decoder) unmarshalableDocument(node ast.Node) ([]byte, error) {
+ doc := format.FormatNodeWithResolvedAlias(node, d.anchorNodeMap)
+ return []byte(doc), nil
+}
+
+func (d *Decoder) unmarshalableText(node ast.Node) ([]byte, bool) {
+ doc := format.FormatNodeWithResolvedAlias(node, d.anchorNodeMap)
+ var v string
+ if err := Unmarshal([]byte(doc), &v); err != nil {
+ return nil, false
+ }
+ return []byte(v), true
+}
+
+type jsonUnmarshaler interface {
+ UnmarshalJSON([]byte) error
+}
+
+func (d *Decoder) existsTypeInCustomUnmarshalerMap(t reflect.Type) bool {
+ if _, exists := d.customUnmarshalerMap[t]; exists {
+ return true
+ }
+
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+ if _, exists := globalCustomUnmarshalerMap[t]; exists {
+ return true
+ }
+ return false
+}
+
+func (d *Decoder) unmarshalerFromCustomUnmarshalerMap(t reflect.Type) (func(context.Context, interface{}, []byte) error, bool) {
+ if unmarshaler, exists := d.customUnmarshalerMap[t]; exists {
+ return unmarshaler, exists
+ }
+
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+ if unmarshaler, exists := globalCustomUnmarshalerMap[t]; exists {
+ return unmarshaler, exists
+ }
+ return nil, false
+}
+
+func (d *Decoder) canDecodeByUnmarshaler(dst reflect.Value) bool {
+ ptrValue := dst.Addr()
+ if d.existsTypeInCustomUnmarshalerMap(ptrValue.Type()) {
+ return true
+ }
+ iface := ptrValue.Interface()
+ switch iface.(type) {
+ case BytesUnmarshalerContext,
+ BytesUnmarshaler,
+ InterfaceUnmarshalerContext,
+ InterfaceUnmarshaler,
+ NodeUnmarshaler,
+ NodeUnmarshalerContext,
+ *time.Time,
+ *time.Duration,
+ encoding.TextUnmarshaler:
+ return true
+ case jsonUnmarshaler:
+ return d.useJSONUnmarshaler
+ }
+ return false
+}
+
+func (d *Decoder) decodeByUnmarshaler(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ ptrValue := dst.Addr()
+ if unmarshaler, exists := d.unmarshalerFromCustomUnmarshalerMap(ptrValue.Type()); exists {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler(ctx, ptrValue.Interface(), b); err != nil {
+ return err
+ }
+ return nil
+ }
+ iface := ptrValue.Interface()
+
+ if unmarshaler, ok := iface.(BytesUnmarshalerContext); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler.UnmarshalYAML(ctx, b); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(BytesUnmarshaler); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ if err := unmarshaler.UnmarshalYAML(b); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(InterfaceUnmarshalerContext); ok {
+ if err := unmarshaler.UnmarshalYAML(ctx, func(v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), src); err != nil {
+ return err
+ }
+ return nil
+ }); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(InterfaceUnmarshaler); ok {
+ if err := unmarshaler.UnmarshalYAML(func(v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), src); err != nil {
+ return err
+ }
+ return nil
+ }); err != nil {
+ return err
+ }
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(NodeUnmarshaler); ok {
+ if err := unmarshaler.UnmarshalYAML(src); err != nil {
+ return err
+ }
+
+ return nil
+ }
+
+ if unmarshaler, ok := iface.(NodeUnmarshalerContext); ok {
+ if err := unmarshaler.UnmarshalYAML(ctx, src); err != nil {
+ return err
+ }
+
+ return nil
+ }
+
+ if _, ok := iface.(*time.Time); ok {
+ return d.decodeTime(ctx, dst, src)
+ }
+
+ if _, ok := iface.(*time.Duration); ok {
+ return d.decodeDuration(ctx, dst, src)
+ }
+
+ if unmarshaler, isText := iface.(encoding.TextUnmarshaler); isText {
+ b, ok := d.unmarshalableText(src)
+ if ok {
+ if err := unmarshaler.UnmarshalText(b); err != nil {
+ return err
+ }
+ return nil
+ }
+ }
+
+ if d.useJSONUnmarshaler {
+ if unmarshaler, ok := iface.(jsonUnmarshaler); ok {
+ b, err := d.unmarshalableDocument(src)
+ if err != nil {
+ return err
+ }
+ jsonBytes, err := YAMLToJSON(b)
+ if err != nil {
+ return err
+ }
+ jsonBytes = bytes.TrimRight(jsonBytes, "\n")
+ if err := unmarshaler.UnmarshalJSON(jsonBytes); err != nil {
+ return err
+ }
+ return nil
+ }
+ }
+
+ return errors.New("does not implemented Unmarshaler")
+}
+
+var (
+ astNodeType = reflect.TypeOf((*ast.Node)(nil)).Elem()
+)
+
+func (d *Decoder) decodeValue(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+ if !dst.IsValid() {
+ return nil
+ }
+
+ if src.Type() == ast.AnchorType {
+ anchor, _ := src.(*ast.AnchorNode)
+ anchorName := anchor.Name.GetToken().Value
+ if err := d.decodeValue(withAnchor(ctx, anchorName), dst, anchor.Value); err != nil {
+ return err
+ }
+ d.anchorValueMap[anchorName] = dst
+ return nil
+ }
+ if d.canDecodeByUnmarshaler(dst) {
+ if err := d.decodeByUnmarshaler(ctx, dst, src); err != nil {
+ return err
+ }
+ return nil
+ }
+ valueType := dst.Type()
+ switch valueType.Kind() {
+ case reflect.Ptr:
+ if dst.IsNil() {
+ return nil
+ }
+ if src.Type() == ast.NullType {
+ // set nil value to pointer
+ dst.Set(reflect.Zero(valueType))
+ return nil
+ }
+ v := d.createDecodableValue(dst.Type())
+ if err := d.decodeValue(ctx, v, src); err != nil {
+ return err
+ }
+ castedValue, err := d.castToAssignableValue(v, dst.Type(), src)
+ if err != nil {
+ return err
+ }
+ dst.Set(castedValue)
+ case reflect.Interface:
+ if dst.Type() == astNodeType {
+ dst.Set(reflect.ValueOf(src))
+ return nil
+ }
+ srcVal, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ v := reflect.ValueOf(srcVal)
+ if v.IsValid() {
+ dst.Set(v)
+ } else {
+ dst.Set(reflect.Zero(valueType))
+ }
+ case reflect.Map:
+ return d.decodeMap(ctx, dst, src)
+ case reflect.Array:
+ return d.decodeArray(ctx, dst, src)
+ case reflect.Slice:
+ if mapSlice, ok := dst.Addr().Interface().(*MapSlice); ok {
+ return d.decodeMapSlice(ctx, mapSlice, src)
+ }
+ return d.decodeSlice(ctx, dst, src)
+ case reflect.Struct:
+ if mapItem, ok := dst.Addr().Interface().(*MapItem); ok {
+ return d.decodeMapItem(ctx, mapItem, src)
+ }
+ return d.decodeStruct(ctx, dst, src)
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ switch vv := v.(type) {
+ case int64:
+ if !dst.OverflowInt(vv) {
+ dst.SetInt(vv)
+ return nil
+ }
+ case uint64:
+ if vv <= math.MaxInt64 && !dst.OverflowInt(int64(vv)) {
+ dst.SetInt(int64(vv))
+ return nil
+ }
+ case float64:
+ if vv <= math.MaxInt64 && !dst.OverflowInt(int64(vv)) {
+ dst.SetInt(int64(vv))
+ return nil
+ }
+ case string: // handle scientific notation
+ if i, err := strconv.ParseFloat(vv, 64); err == nil {
+ if 0 <= i && i <= math.MaxUint64 && !dst.OverflowInt(int64(i)) {
+ dst.SetInt(int64(i))
+ return nil
+ }
+ } else { // couldn't be parsed as float
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ default:
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ return errors.ErrOverflow(valueType, fmt.Sprint(v), src.GetToken())
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64:
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ switch vv := v.(type) {
+ case int64:
+ if 0 <= vv && !dst.OverflowUint(uint64(vv)) {
+ dst.SetUint(uint64(vv))
+ return nil
+ }
+ case uint64:
+ if !dst.OverflowUint(vv) {
+ dst.SetUint(vv)
+ return nil
+ }
+ case float64:
+ if 0 <= vv && vv <= math.MaxUint64 && !dst.OverflowUint(uint64(vv)) {
+ dst.SetUint(uint64(vv))
+ return nil
+ }
+ case string: // handle scientific notation
+ if i, err := strconv.ParseFloat(vv, 64); err == nil {
+ if 0 <= i && i <= math.MaxUint64 && !dst.OverflowUint(uint64(i)) {
+ dst.SetUint(uint64(i))
+ return nil
+ }
+ } else { // couldn't be parsed as float
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+
+ default:
+ return errors.ErrTypeMismatch(valueType, reflect.TypeOf(v), src.GetToken())
+ }
+ return errors.ErrOverflow(valueType, fmt.Sprint(v), src.GetToken())
+ }
+ srcVal, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return err
+ }
+ v := reflect.ValueOf(srcVal)
+ if v.IsValid() {
+ convertedValue, err := d.convertValue(v, dst.Type(), src)
+ if err != nil {
+ return err
+ }
+ dst.Set(convertedValue)
+ }
+ return nil
+}
+
+func (d *Decoder) createDecodableValue(typ reflect.Type) reflect.Value {
+ for {
+ if typ.Kind() == reflect.Ptr {
+ typ = typ.Elem()
+ continue
+ }
+ break
+ }
+ return reflect.New(typ).Elem()
+}
+
+func (d *Decoder) castToAssignableValue(value reflect.Value, target reflect.Type, src ast.Node) (reflect.Value, error) {
+ if target.Kind() != reflect.Ptr {
+ if !value.Type().AssignableTo(target) {
+ return reflect.Value{}, errors.ErrTypeMismatch(target, value.Type(), src.GetToken())
+ }
+ return value, nil
+ }
+
+ const maxAddrCount = 5
+
+ for i := 0; i < maxAddrCount; i++ {
+ if value.Type().AssignableTo(target) {
+ break
+ }
+ if !value.CanAddr() {
+ break
+ }
+ value = value.Addr()
+ }
+ if !value.Type().AssignableTo(target) {
+ return reflect.Value{}, errors.ErrTypeMismatch(target, value.Type(), src.GetToken())
+ }
+ return value, nil
+}
+
+func (d *Decoder) createDecodedNewValue(
+ ctx context.Context, typ reflect.Type, defaultVal reflect.Value, node ast.Node,
+) (reflect.Value, error) {
+ if node.Type() == ast.AliasType {
+ aliasName := node.(*ast.AliasNode).Value.GetToken().Value
+ value := d.anchorValueMap[aliasName]
+ if value.IsValid() {
+ v, err := d.castToAssignableValue(value, typ, node)
+ if err == nil {
+ return v, nil
+ }
+ }
+ anchor, exists := d.anchorNodeMap[aliasName]
+ if exists {
+ node = anchor
+ }
+ }
+ var newValue reflect.Value
+ if node.Type() == ast.NullType {
+ newValue = reflect.New(typ).Elem()
+ } else {
+ newValue = d.createDecodableValue(typ)
+ }
+ for defaultVal.Kind() == reflect.Ptr {
+ defaultVal = defaultVal.Elem()
+ }
+ if defaultVal.IsValid() && defaultVal.Type().AssignableTo(newValue.Type()) {
+ newValue.Set(defaultVal)
+ }
+ if node.Type() != ast.NullType {
+ if err := d.decodeValue(ctx, newValue, node); err != nil {
+ return reflect.Value{}, err
+ }
+ }
+ return d.castToAssignableValue(newValue, typ, node)
+}
+
+func (d *Decoder) keyToNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool, getKeyOrValueNode func(*ast.MapNodeIter) ast.Node) (map[string]ast.Node, error) {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return nil, ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(node, false)
+ if err != nil {
+ return nil, err
+ }
+ keyMap := map[string]struct{}{}
+ keyToNodeMap := map[string]ast.Node{}
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ keyNode := mapIter.Key()
+ if keyNode.IsMergeKey() {
+ if ignoreMergeKey {
+ continue
+ }
+ mergeMap, err := d.keyToNodeMap(ctx, mapIter.Value(), ignoreMergeKey, getKeyOrValueNode)
+ if err != nil {
+ return nil, err
+ }
+ for k, v := range mergeMap {
+ if err := d.validateDuplicateKey(keyMap, k, v); err != nil {
+ return nil, err
+ }
+ keyToNodeMap[k] = v
+ }
+ } else {
+ keyVal, err := d.nodeToValue(ctx, keyNode)
+ if err != nil {
+ return nil, err
+ }
+ key, ok := keyVal.(string)
+ if !ok {
+ return nil, err
+ }
+ if err := d.validateDuplicateKey(keyMap, key, keyNode); err != nil {
+ return nil, err
+ }
+ keyToNodeMap[key] = getKeyOrValueNode(mapIter)
+ }
+ }
+ return keyToNodeMap, nil
+}
+
+func (d *Decoder) keyToKeyNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool) (map[string]ast.Node, error) {
+ m, err := d.keyToNodeMap(ctx, node, ignoreMergeKey, func(nodeMap *ast.MapNodeIter) ast.Node { return nodeMap.Key() })
+ if err != nil {
+ return nil, err
+ }
+ return m, nil
+}
+
+func (d *Decoder) keyToValueNodeMap(ctx context.Context, node ast.Node, ignoreMergeKey bool) (map[string]ast.Node, error) {
+ m, err := d.keyToNodeMap(ctx, node, ignoreMergeKey, func(nodeMap *ast.MapNodeIter) ast.Node { return nodeMap.Value() })
+ if err != nil {
+ return nil, err
+ }
+ return m, nil
+}
+
+func (d *Decoder) setDefaultValueIfConflicted(v reflect.Value, fieldMap StructFieldMap) error {
+ for v.Type().Kind() == reflect.Ptr {
+ v = v.Elem()
+ }
+ typ := v.Type()
+ if typ.Kind() != reflect.Struct {
+ return nil
+ }
+ embeddedStructFieldMap, err := structFieldMap(typ)
+ if err != nil {
+ return err
+ }
+ for i := 0; i < typ.NumField(); i++ {
+ field := typ.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ structField := embeddedStructFieldMap[field.Name]
+ if !fieldMap.isIncludedRenderName(structField.RenderName) {
+ continue
+ }
+ // if declared same key name, set default value
+ fieldValue := v.Field(i)
+ if fieldValue.CanSet() {
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ }
+ }
+ return nil
+}
+
+// This is a subset of the formats allowed by the regular expression
+// defined at http://yaml.org/type/timestamp.html.
+var allowedTimestampFormats = []string{
+ "2006-1-2T15:4:5.999999999Z07:00", // RCF3339Nano with short date fields.
+ "2006-1-2t15:4:5.999999999Z07:00", // RFC3339Nano with short date fields and lower-case "t".
+ "2006-1-2 15:4:5.999999999", // space separated with no time zone
+ "2006-1-2", // date only
+}
+
+func (d *Decoder) castToTime(ctx context.Context, src ast.Node) (time.Time, error) {
+ if src == nil {
+ return time.Time{}, nil
+ }
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return time.Time{}, err
+ }
+ if t, ok := v.(time.Time); ok {
+ return t, nil
+ }
+ s, ok := v.(string)
+ if !ok {
+ return time.Time{}, errors.ErrTypeMismatch(reflect.TypeOf(time.Time{}), reflect.TypeOf(v), src.GetToken())
+ }
+ for _, format := range allowedTimestampFormats {
+ t, err := time.Parse(format, s)
+ if err != nil {
+ // invalid format
+ continue
+ }
+ return t, nil
+ }
+ return time.Time{}, nil
+}
+
+func (d *Decoder) decodeTime(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ t, err := d.castToTime(ctx, src)
+ if err != nil {
+ return err
+ }
+ dst.Set(reflect.ValueOf(t))
+ return nil
+}
+
+func (d *Decoder) castToDuration(ctx context.Context, src ast.Node) (time.Duration, error) {
+ if src == nil {
+ return 0, nil
+ }
+ v, err := d.nodeToValue(ctx, src)
+ if err != nil {
+ return 0, err
+ }
+ if t, ok := v.(time.Duration); ok {
+ return t, nil
+ }
+ s, ok := v.(string)
+ if !ok {
+ return 0, errors.ErrTypeMismatch(reflect.TypeOf(time.Duration(0)), reflect.TypeOf(v), src.GetToken())
+ }
+ t, err := time.ParseDuration(s)
+ if err != nil {
+ return 0, err
+ }
+ return t, nil
+}
+
+func (d *Decoder) decodeDuration(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ t, err := d.castToDuration(ctx, src)
+ if err != nil {
+ return err
+ }
+ dst.Set(reflect.ValueOf(t))
+ return nil
+}
+
+// getMergeAliasName support single alias only
+func (d *Decoder) getMergeAliasName(src ast.Node) string {
+ mapNode, err := d.getMapNode(src, true)
+ if err != nil {
+ return ""
+ }
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() && value.Type() == ast.AliasType {
+ return value.(*ast.AliasNode).Value.GetToken().Value
+ }
+ }
+ return ""
+}
+
+func (d *Decoder) decodeStruct(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ if src == nil {
+ return nil
+ }
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ structType := dst.Type()
+ srcValue := reflect.ValueOf(src)
+ srcType := srcValue.Type()
+ if srcType.Kind() == reflect.Ptr {
+ srcType = srcType.Elem()
+ srcValue = srcValue.Elem()
+ }
+ if structType == srcType {
+ // dst value implements ast.Node
+ dst.Set(srcValue)
+ return nil
+ }
+ structFieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return err
+ }
+ ignoreMergeKey := structFieldMap.hasMergeProperty()
+ keyToNodeMap, err := d.keyToValueNodeMap(ctx, src, ignoreMergeKey)
+ if err != nil {
+ return err
+ }
+ var unknownFields map[string]ast.Node
+ if d.disallowUnknownField {
+ unknownFields, err = d.keyToKeyNodeMap(ctx, src, ignoreMergeKey)
+ if err != nil {
+ return err
+ }
+ }
+
+ aliasName := d.getMergeAliasName(src)
+ var foundErr error
+
+ for i := 0; i < structType.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ structField := structFieldMap[field.Name]
+ if structField.IsInline {
+ fieldValue := dst.FieldByName(field.Name)
+ if structField.IsAutoAlias {
+ if aliasName != "" {
+ newFieldValue := d.anchorValueMap[aliasName]
+ if newFieldValue.IsValid() {
+ value, err := d.castToAssignableValue(newFieldValue, fieldValue.Type(), d.anchorNodeMap[aliasName])
+ if err != nil {
+ return err
+ }
+ fieldValue.Set(value)
+ }
+ }
+ continue
+ }
+ if !fieldValue.CanSet() {
+ return fmt.Errorf("cannot set embedded type as unexported field %s.%s", field.PkgPath, field.Name)
+ }
+ if fieldValue.Type().Kind() == reflect.Ptr && src.Type() == ast.NullType {
+ // set nil value to pointer
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ continue
+ }
+ mapNode := ast.Mapping(nil, false)
+ for k, v := range keyToNodeMap {
+ key := &ast.StringNode{BaseNode: &ast.BaseNode{}, Value: k}
+ mapNode.Values = append(mapNode.Values, ast.MappingValue(nil, key, v))
+ }
+ newFieldValue, err := d.createDecodedNewValue(ctx, fieldValue.Type(), fieldValue, mapNode)
+ if d.disallowUnknownField {
+ if err := d.deleteStructKeys(fieldValue.Type(), unknownFields); err != nil {
+ return err
+ }
+ }
+
+ if err != nil {
+ if foundErr != nil {
+ continue
+ }
+ var te *errors.TypeError
+ if errors.As(err, &te) {
+ if te.StructFieldName != nil {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), *te.StructFieldName)
+ te.StructFieldName = &fieldName
+ } else {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), field.Name)
+ te.StructFieldName = &fieldName
+ }
+ foundErr = te
+ continue
+ } else {
+ foundErr = err
+ }
+ continue
+ }
+ _ = d.setDefaultValueIfConflicted(newFieldValue, structFieldMap)
+ fieldValue.Set(newFieldValue)
+ continue
+ }
+ v, exists := keyToNodeMap[structField.RenderName]
+ if !exists {
+ continue
+ }
+ delete(unknownFields, structField.RenderName)
+ fieldValue := dst.FieldByName(field.Name)
+ if fieldValue.Type().Kind() == reflect.Ptr && src.Type() == ast.NullType {
+ // set nil value to pointer
+ fieldValue.Set(reflect.Zero(fieldValue.Type()))
+ continue
+ }
+ newFieldValue, err := d.createDecodedNewValue(ctx, fieldValue.Type(), fieldValue, v)
+ if err != nil {
+ if foundErr != nil {
+ continue
+ }
+ var te *errors.TypeError
+ if errors.As(err, &te) {
+ fieldName := fmt.Sprintf("%s.%s", structType.Name(), field.Name)
+ te.StructFieldName = &fieldName
+ foundErr = te
+ } else {
+ foundErr = err
+ }
+ continue
+ }
+ fieldValue.Set(newFieldValue)
+ }
+ if foundErr != nil {
+ return foundErr
+ }
+
+ // Ignore unknown fields when parsing an inline struct (recognized by a nil token).
+ // Unknown fields are expected (they could be fields from the parent struct).
+ if len(unknownFields) != 0 && d.disallowUnknownField && src.GetToken() != nil {
+ for key, node := range unknownFields {
+ var ok bool
+ for _, prefix := range d.allowedFieldPrefixes {
+ if strings.HasPrefix(key, prefix) {
+ ok = true
+ break
+ }
+ }
+ if !ok {
+ return errors.ErrUnknownField(fmt.Sprintf(`unknown field "%s"`, key), node.GetToken())
+ }
+ }
+ }
+
+ if d.validator != nil {
+ if err := d.validator.Struct(dst.Interface()); err != nil {
+ ev := reflect.ValueOf(err)
+ if ev.Type().Kind() == reflect.Slice {
+ for i := 0; i < ev.Len(); i++ {
+ fieldErr, ok := ev.Index(i).Interface().(FieldError)
+ if !ok {
+ continue
+ }
+ fieldName := fieldErr.StructField()
+ structField, exists := structFieldMap[fieldName]
+ if !exists {
+ continue
+ }
+ node, exists := keyToNodeMap[structField.RenderName]
+ if exists {
+ // TODO: to make FieldError message cutomizable
+ return errors.ErrSyntax(
+ fmt.Sprintf("%s", err),
+ d.getParentMapTokenIfExistsForValidationError(node.Type(), node.GetToken()),
+ )
+ } else if t := src.GetToken(); t != nil && t.Prev != nil && t.Prev.Prev != nil {
+ // A missing required field will not be in the keyToNodeMap
+ // the error needs to be associated with the parent of the source node
+ return errors.ErrSyntax(fmt.Sprintf("%s", err), t.Prev.Prev)
+ }
+ }
+ }
+ return err
+ }
+ }
+ return nil
+}
+
+// getParentMapTokenIfExists if the NodeType is a container type such as MappingType or SequenceType,
+// it is necessary to return the parent MapNode's colon token to represent the entire container.
+func (d *Decoder) getParentMapTokenIfExistsForValidationError(typ ast.NodeType, tk *token.Token) *token.Token {
+ if tk == nil {
+ return nil
+ }
+ if typ == ast.MappingType {
+ // map:
+ // key: value
+ // ^ current token ( colon )
+ if tk.Prev == nil {
+ return tk
+ }
+ key := tk.Prev
+ if key.Prev == nil {
+ return tk
+ }
+ return key.Prev
+ }
+ if typ == ast.SequenceType {
+ // map:
+ // - value
+ // ^ current token ( sequence entry )
+ if tk.Prev == nil {
+ return tk
+ }
+ return tk.Prev
+ }
+ return tk
+}
+
+func (d *Decoder) decodeArray(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ arrayNode, err := d.getArrayNode(src)
+ if err != nil {
+ return err
+ }
+ if arrayNode == nil {
+ return nil
+ }
+ iter := arrayNode.ArrayRange()
+ arrayValue := reflect.New(dst.Type()).Elem()
+ arrayType := dst.Type()
+ elemType := arrayType.Elem()
+ idx := 0
+
+ var foundErr error
+ for iter.Next() {
+ v := iter.Value()
+ if elemType.Kind() == reflect.Ptr && v.Type() == ast.NullType {
+ // set nil value to pointer
+ arrayValue.Index(idx).Set(reflect.Zero(elemType))
+ } else {
+ dstValue, err := d.createDecodedNewValue(ctx, elemType, reflect.Value{}, v)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ continue
+ }
+ arrayValue.Index(idx).Set(dstValue)
+ }
+ idx++
+ }
+ dst.Set(arrayValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) decodeSlice(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ arrayNode, err := d.getArrayNode(src)
+ if err != nil {
+ return err
+ }
+ if arrayNode == nil {
+ return nil
+ }
+ iter := arrayNode.ArrayRange()
+ sliceType := dst.Type()
+ sliceValue := reflect.MakeSlice(sliceType, 0, iter.Len())
+ elemType := sliceType.Elem()
+
+ var foundErr error
+ for iter.Next() {
+ v := iter.Value()
+ if elemType.Kind() == reflect.Ptr && v.Type() == ast.NullType {
+ // set nil value to pointer
+ sliceValue = reflect.Append(sliceValue, reflect.Zero(elemType))
+ continue
+ }
+ dstValue, err := d.createDecodedNewValue(ctx, elemType, reflect.Value{}, v)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ continue
+ }
+ sliceValue = reflect.Append(sliceValue, dstValue)
+ }
+ dst.Set(sliceValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) decodeMapItem(ctx context.Context, dst *MapItem, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapIter := mapNode.MapRange()
+ if !mapIter.Next() {
+ return nil
+ }
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ if err := d.decodeMapItem(withMerge(ctx), dst, value); err != nil {
+ return err
+ }
+ return nil
+ }
+ k, err := d.nodeToValue(ctx, key)
+ if err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return err
+ }
+ *dst = MapItem{Key: k, Value: v}
+ return nil
+}
+
+func (d *Decoder) validateDuplicateKey(keyMap map[string]struct{}, key interface{}, keyNode ast.Node) error {
+ k, ok := key.(string)
+ if !ok {
+ return nil
+ }
+ if !d.allowDuplicateMapKey {
+ if _, exists := keyMap[k]; exists {
+ return errors.ErrDuplicateKey(fmt.Sprintf(`duplicate key "%s"`, k), keyNode.GetToken())
+ }
+ }
+ keyMap[k] = struct{}{}
+ return nil
+}
+
+func (d *Decoder) decodeMapSlice(ctx context.Context, dst *MapSlice, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapSlice := MapSlice{}
+ mapIter := mapNode.MapRange()
+ keyMap := map[string]struct{}{}
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ var m MapSlice
+ if err := d.decodeMapSlice(withMerge(ctx), &m, value); err != nil {
+ return err
+ }
+ for _, v := range m {
+ if err := d.validateDuplicateKey(keyMap, v.Key, value); err != nil {
+ return err
+ }
+ mapSlice = append(mapSlice, v)
+ }
+ continue
+ }
+ k, err := d.nodeToValue(ctx, key)
+ if err != nil {
+ return err
+ }
+ if err := d.validateDuplicateKey(keyMap, k, key); err != nil {
+ return err
+ }
+ v, err := d.nodeToValue(ctx, value)
+ if err != nil {
+ return err
+ }
+ mapSlice = append(mapSlice, MapItem{Key: k, Value: v})
+ }
+ *dst = mapSlice
+ return nil
+}
+
+func (d *Decoder) decodeMap(ctx context.Context, dst reflect.Value, src ast.Node) error {
+ d.stepIn()
+ defer d.stepOut()
+ if d.isExceededMaxDepth() {
+ return ErrExceededMaxDepth
+ }
+
+ mapNode, err := d.getMapNode(src, isMerge(ctx))
+ if err != nil {
+ return err
+ }
+ mapType := dst.Type()
+ mapValue := reflect.MakeMap(mapType)
+ keyType := mapValue.Type().Key()
+ valueType := mapValue.Type().Elem()
+ mapIter := mapNode.MapRange()
+ keyMap := map[string]struct{}{}
+ var foundErr error
+ for mapIter.Next() {
+ key := mapIter.Key()
+ value := mapIter.Value()
+ if key.IsMergeKey() {
+ if err := d.decodeMap(withMerge(ctx), dst, value); err != nil {
+ return err
+ }
+ iter := dst.MapRange()
+ for iter.Next() {
+ if err := d.validateDuplicateKey(keyMap, iter.Key(), value); err != nil {
+ return err
+ }
+ mapValue.SetMapIndex(iter.Key(), iter.Value())
+ }
+ continue
+ }
+
+ k := d.createDecodableValue(keyType)
+ if d.canDecodeByUnmarshaler(k) {
+ if err := d.decodeByUnmarshaler(ctx, k, key); err != nil {
+ return err
+ }
+ } else {
+ keyVal, err := d.createDecodedNewValue(ctx, keyType, reflect.Value{}, key)
+ if err != nil {
+ return err
+ }
+ k = keyVal
+ }
+
+ if k.IsValid() {
+ if err := d.validateDuplicateKey(keyMap, k.Interface(), key); err != nil {
+ return err
+ }
+ }
+ if valueType.Kind() == reflect.Ptr && value.Type() == ast.NullType {
+ // set nil value to pointer
+ mapValue.SetMapIndex(k, reflect.Zero(valueType))
+ continue
+ }
+ dstValue, err := d.createDecodedNewValue(ctx, valueType, reflect.Value{}, value)
+ if err != nil {
+ if foundErr == nil {
+ foundErr = err
+ }
+ }
+ if !k.IsValid() {
+ // expect nil key
+ mapValue.SetMapIndex(d.createDecodableValue(keyType), dstValue)
+ continue
+ }
+ if keyType.Kind() != k.Kind() {
+ return errors.ErrSyntax(
+ fmt.Sprintf("cannot convert %q type to %q type", k.Kind(), keyType.Kind()),
+ key.GetToken(),
+ )
+ }
+ mapValue.SetMapIndex(k, dstValue)
+ }
+ dst.Set(mapValue)
+ if foundErr != nil {
+ return foundErr
+ }
+ return nil
+}
+
+func (d *Decoder) fileToReader(file string) (io.Reader, error) {
+ reader, err := os.Open(file)
+ if err != nil {
+ return nil, err
+ }
+ return reader, nil
+}
+
+func (d *Decoder) isYAMLFile(file string) bool {
+ ext := filepath.Ext(file)
+ if ext == ".yml" {
+ return true
+ }
+ if ext == ".yaml" {
+ return true
+ }
+ return false
+}
+
+func (d *Decoder) readersUnderDir(dir string) ([]io.Reader, error) {
+ pattern := fmt.Sprintf("%s/*", dir)
+ matches, err := filepath.Glob(pattern)
+ if err != nil {
+ return nil, err
+ }
+ readers := []io.Reader{}
+ for _, match := range matches {
+ if !d.isYAMLFile(match) {
+ continue
+ }
+ reader, err := d.fileToReader(match)
+ if err != nil {
+ return nil, err
+ }
+ readers = append(readers, reader)
+ }
+ return readers, nil
+}
+
+func (d *Decoder) readersUnderDirRecursive(dir string) ([]io.Reader, error) {
+ readers := []io.Reader{}
+ if err := filepath.Walk(dir, func(path string, info os.FileInfo, _ error) error {
+ if !d.isYAMLFile(path) {
+ return nil
+ }
+ reader, readerErr := d.fileToReader(path)
+ if readerErr != nil {
+ return readerErr
+ }
+ readers = append(readers, reader)
+ return nil
+ }); err != nil {
+ return nil, err
+ }
+ return readers, nil
+}
+
+func (d *Decoder) resolveReference(ctx context.Context) error {
+ for _, opt := range d.opts {
+ if err := opt(d); err != nil {
+ return err
+ }
+ }
+ for _, file := range d.referenceFiles {
+ reader, err := d.fileToReader(file)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, reader)
+ }
+ for _, dir := range d.referenceDirs {
+ if !d.isRecursiveDir {
+ readers, err := d.readersUnderDir(dir)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ } else {
+ readers, err := d.readersUnderDirRecursive(dir)
+ if err != nil {
+ return err
+ }
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ }
+ }
+ for _, reader := range d.referenceReaders {
+ bytes, err := io.ReadAll(reader)
+ if err != nil {
+ return err
+ }
+
+ // assign new anchor definition to anchorMap
+ if _, err := d.parse(ctx, bytes); err != nil {
+ return err
+ }
+ }
+ d.isResolvedReference = true
+ return nil
+}
+
+func (d *Decoder) parse(ctx context.Context, bytes []byte) (*ast.File, error) {
+ var parseMode parser.Mode
+ if d.toCommentMap != nil {
+ parseMode = parser.ParseComments
+ }
+ var opts []parser.Option
+ if d.allowDuplicateMapKey {
+ opts = append(opts, parser.AllowDuplicateMapKey())
+ }
+ f, err := parser.ParseBytes(bytes, parseMode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ normalizedFile := &ast.File{}
+ for _, doc := range f.Docs {
+ // try to decode ast.Node to value and map anchor value to anchorMap
+ v, err := d.nodeToValue(ctx, doc.Body)
+ if err != nil {
+ return nil, err
+ }
+ if v != nil || (doc.Body != nil && doc.Body.Type() == ast.NullType) {
+ normalizedFile.Docs = append(normalizedFile.Docs, doc)
+ cm := CommentMap{}
+ maps.Copy(cm, d.toCommentMap)
+ d.commentMaps = append(d.commentMaps, cm)
+ }
+ for k := range d.toCommentMap {
+ delete(d.toCommentMap, k)
+ }
+ }
+ return normalizedFile, nil
+}
+
+func (d *Decoder) isInitialized() bool {
+ return d.parsedFile != nil
+}
+
+func (d *Decoder) decodeInit(ctx context.Context) error {
+ if !d.isResolvedReference {
+ if err := d.resolveReference(ctx); err != nil {
+ return err
+ }
+ }
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, d.reader); err != nil {
+ return err
+ }
+ file, err := d.parse(ctx, buf.Bytes())
+ if err != nil {
+ return err
+ }
+ d.parsedFile = file
+ return nil
+}
+
+func (d *Decoder) decode(ctx context.Context, v reflect.Value) error {
+ d.decodeDepth = 0
+ d.anchorValueMap = make(map[string]reflect.Value)
+ if len(d.parsedFile.Docs) == 0 {
+ // empty document.
+ dst := v.Elem()
+ if dst.IsValid() {
+ dst.Set(reflect.Zero(dst.Type()))
+ }
+ }
+ if len(d.parsedFile.Docs) <= d.streamIndex {
+ return io.EOF
+ }
+ body := d.parsedFile.Docs[d.streamIndex].Body
+ if body == nil {
+ return nil
+ }
+ if len(d.commentMaps) > d.streamIndex {
+ maps.Copy(d.toCommentMap, d.commentMaps[d.streamIndex])
+ }
+ if err := d.decodeValue(ctx, v.Elem(), body); err != nil {
+ return err
+ }
+ d.streamIndex++
+ return nil
+}
+
+// Decode reads the next YAML-encoded value from its input
+// and stores it in the value pointed to by v.
+//
+// See the documentation for Unmarshal for details about the
+// conversion of YAML into a Go value.
+func (d *Decoder) Decode(v interface{}) error {
+ return d.DecodeContext(context.Background(), v)
+}
+
+// DecodeContext reads the next YAML-encoded value from its input
+// and stores it in the value pointed to by v with context.Context.
+func (d *Decoder) DecodeContext(ctx context.Context, v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if !rv.IsValid() || rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if d.isInitialized() {
+ if err := d.decode(ctx, rv); err != nil {
+ return err
+ }
+ return nil
+ }
+ if err := d.decodeInit(ctx); err != nil {
+ return err
+ }
+ if err := d.decode(ctx, rv); err != nil {
+ return err
+ }
+ return nil
+}
+
+// DecodeFromNode decodes node into the value pointed to by v.
+func (d *Decoder) DecodeFromNode(node ast.Node, v interface{}) error {
+ return d.DecodeFromNodeContext(context.Background(), node, v)
+}
+
+// DecodeFromNodeContext decodes node into the value pointed to by v with context.Context.
+func (d *Decoder) DecodeFromNodeContext(ctx context.Context, node ast.Node, v interface{}) error {
+ rv := reflect.ValueOf(v)
+ if rv.Type().Kind() != reflect.Ptr {
+ return ErrDecodeRequiredPointerType
+ }
+ if !d.isInitialized() {
+ if err := d.decodeInit(ctx); err != nil {
+ return err
+ }
+ }
+ // resolve references to the anchor on the same file
+ if _, err := d.nodeToValue(ctx, node); err != nil {
+ return err
+ }
+ if err := d.decodeValue(ctx, rv.Elem(), node); err != nil {
+ return err
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/encode.go b/sesh/vendor/github.com/goccy/go-yaml/encode.go
new file mode 100644
index 0000000..e810608
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/encode.go
@@ -0,0 +1,1074 @@
+package yaml
+
+import (
+ "context"
+ "encoding"
+ "fmt"
+ "io"
+ "math"
+ "reflect"
+ "sort"
+ "strconv"
+ "strings"
+ "time"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/printer"
+ "github.com/goccy/go-yaml/token"
+)
+
+const (
+ // DefaultIndentSpaces default number of space for indent
+ DefaultIndentSpaces = 2
+)
+
+// Encoder writes YAML values to an output stream.
+type Encoder struct {
+ writer io.Writer
+ opts []EncodeOption
+ singleQuote bool
+ isFlowStyle bool
+ isJSONStyle bool
+ useJSONMarshaler bool
+ enableSmartAnchor bool
+ aliasRefToName map[uintptr]string
+ anchorRefToName map[uintptr]string
+ anchorNameMap map[string]struct{}
+ anchorCallback func(*ast.AnchorNode, interface{}) error
+ customMarshalerMap map[reflect.Type]func(context.Context, interface{}) ([]byte, error)
+ omitZero bool
+ omitEmpty bool
+ autoInt bool
+ useLiteralStyleIfMultiline bool
+ commentMap map[*Path][]*Comment
+ written bool
+
+ line int
+ column int
+ offset int
+ indentNum int
+ indentLevel int
+ indentSequence bool
+}
+
+// NewEncoder returns a new encoder that writes to w.
+// The Encoder should be closed after use to flush all data to w.
+func NewEncoder(w io.Writer, opts ...EncodeOption) *Encoder {
+ return &Encoder{
+ writer: w,
+ opts: opts,
+ customMarshalerMap: map[reflect.Type]func(context.Context, interface{}) ([]byte, error){},
+ line: 1,
+ column: 1,
+ offset: 0,
+ indentNum: DefaultIndentSpaces,
+ anchorRefToName: make(map[uintptr]string),
+ anchorNameMap: make(map[string]struct{}),
+ aliasRefToName: make(map[uintptr]string),
+ }
+}
+
+// Close closes the encoder by writing any remaining data.
+// It does not write a stream terminating string "...".
+func (e *Encoder) Close() error {
+ return nil
+}
+
+// Encode writes the YAML encoding of v to the stream.
+// If multiple items are encoded to the stream,
+// the second and subsequent document will be preceded with a "---" document separator,
+// but the first will not.
+//
+// See the documentation for Marshal for details about the conversion of Go values to YAML.
+func (e *Encoder) Encode(v interface{}) error {
+ return e.EncodeContext(context.Background(), v)
+}
+
+// EncodeContext writes the YAML encoding of v to the stream with context.Context.
+func (e *Encoder) EncodeContext(ctx context.Context, v interface{}) error {
+ node, err := e.EncodeToNodeContext(ctx, v)
+ if err != nil {
+ return err
+ }
+ if err := e.setCommentByCommentMap(node); err != nil {
+ return err
+ }
+ if !e.written {
+ e.written = true
+ } else {
+ // write document separator
+ _, _ = e.writer.Write([]byte("---\n"))
+ }
+ var p printer.Printer
+ _, _ = e.writer.Write(p.PrintNode(node))
+ return nil
+}
+
+// EncodeToNode convert v to ast.Node.
+func (e *Encoder) EncodeToNode(v interface{}) (ast.Node, error) {
+ return e.EncodeToNodeContext(context.Background(), v)
+}
+
+// EncodeToNodeContext convert v to ast.Node with context.Context.
+func (e *Encoder) EncodeToNodeContext(ctx context.Context, v interface{}) (ast.Node, error) {
+ for _, opt := range e.opts {
+ if err := opt(e); err != nil {
+ return nil, err
+ }
+ }
+ if e.enableSmartAnchor {
+ // during the first encoding, store all mappings between alias addresses and their names.
+ if _, err := e.encodeValue(ctx, reflect.ValueOf(v), 1); err != nil {
+ return nil, err
+ }
+ e.clearSmartAnchorRef()
+ }
+ node, err := e.encodeValue(ctx, reflect.ValueOf(v), 1)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func (e *Encoder) setCommentByCommentMap(node ast.Node) error {
+ if e.commentMap == nil {
+ return nil
+ }
+ for path, comments := range e.commentMap {
+ n, err := path.FilterNode(node)
+ if err != nil {
+ return err
+ }
+ if n == nil {
+ continue
+ }
+ for _, comment := range comments {
+ commentTokens := []*token.Token{}
+ for _, text := range comment.Texts {
+ commentTokens = append(commentTokens, token.New(text, text, nil))
+ }
+ commentGroup := ast.CommentGroup(commentTokens)
+ switch comment.Position {
+ case CommentHeadPosition:
+ if err := e.setHeadComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ case CommentLinePosition:
+ if err := e.setLineComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ case CommentFootPosition:
+ if err := e.setFootComment(node, n, commentGroup); err != nil {
+ return err
+ }
+ default:
+ return ErrUnknownCommentPositionType
+ }
+ }
+ }
+ return nil
+}
+
+func (e *Encoder) setHeadComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedHeadPositionType(node)
+ }
+ switch p := parent.(type) {
+ case *ast.MappingValueNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.MappingNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.SequenceNode:
+ if len(p.ValueHeadComments) == 0 {
+ p.ValueHeadComments = make([]*ast.CommentGroupNode, len(p.Values))
+ }
+ var foundIdx int
+ for idx, v := range p.Values {
+ if v == filtered {
+ foundIdx = idx
+ break
+ }
+ }
+ p.ValueHeadComments[foundIdx] = comment
+ default:
+ return ErrUnsupportedHeadPositionType(node)
+ }
+ return nil
+}
+
+func (e *Encoder) setLineComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ switch filtered.(type) {
+ case *ast.MappingValueNode, *ast.SequenceNode:
+ // Line comment cannot be set for mapping value node.
+ // It should probably be set for the parent map node
+ if err := e.setLineCommentToParentMapNode(node, filtered, comment); err != nil {
+ return err
+ }
+ default:
+ if err := filtered.SetComment(comment); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+func (e *Encoder) setLineCommentToParentMapNode(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedLinePositionType(node)
+ }
+ switch p := parent.(type) {
+ case *ast.MappingValueNode:
+ if err := p.Key.SetComment(comment); err != nil {
+ return err
+ }
+ case *ast.MappingNode:
+ if err := p.SetComment(comment); err != nil {
+ return err
+ }
+ default:
+ return ErrUnsupportedLinePositionType(parent)
+ }
+ return nil
+}
+
+func (e *Encoder) setFootComment(node ast.Node, filtered ast.Node, comment *ast.CommentGroupNode) error {
+ parent := ast.Parent(node, filtered)
+ if parent == nil {
+ return ErrUnsupportedFootPositionType(node)
+ }
+ switch n := parent.(type) {
+ case *ast.MappingValueNode:
+ n.FootComment = comment
+ case *ast.MappingNode:
+ n.FootComment = comment
+ case *ast.SequenceNode:
+ n.FootComment = comment
+ default:
+ return ErrUnsupportedFootPositionType(n)
+ }
+ return nil
+}
+
+func (e *Encoder) encodeDocument(doc []byte) (ast.Node, error) {
+ f, err := parser.ParseBytes(doc, 0)
+ if err != nil {
+ return nil, err
+ }
+ for _, docNode := range f.Docs {
+ if docNode.Body != nil {
+ return docNode.Body, nil
+ }
+ }
+ return nil, nil
+}
+
+func (e *Encoder) isInvalidValue(v reflect.Value) bool {
+ if !v.IsValid() {
+ return true
+ }
+ kind := v.Type().Kind()
+ if kind == reflect.Ptr && v.IsNil() {
+ return true
+ }
+ if kind == reflect.Interface && v.IsNil() {
+ return true
+ }
+ return false
+}
+
+type jsonMarshaler interface {
+ MarshalJSON() ([]byte, error)
+}
+
+func (e *Encoder) existsTypeInCustomMarshalerMap(t reflect.Type) bool {
+ if _, exists := e.customMarshalerMap[t]; exists {
+ return true
+ }
+
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+ if _, exists := globalCustomMarshalerMap[t]; exists {
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) marshalerFromCustomMarshalerMap(t reflect.Type) (func(context.Context, interface{}) ([]byte, error), bool) {
+ if marshaler, exists := e.customMarshalerMap[t]; exists {
+ return marshaler, exists
+ }
+
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+ if marshaler, exists := globalCustomMarshalerMap[t]; exists {
+ return marshaler, exists
+ }
+ return nil, false
+}
+
+func (e *Encoder) canEncodeByMarshaler(v reflect.Value) bool {
+ if !v.CanInterface() {
+ return false
+ }
+ if e.existsTypeInCustomMarshalerMap(v.Type()) {
+ return true
+ }
+ iface := v.Interface()
+ switch iface.(type) {
+ case BytesMarshalerContext:
+ return true
+ case BytesMarshaler:
+ return true
+ case InterfaceMarshalerContext:
+ return true
+ case InterfaceMarshaler:
+ return true
+ case time.Time, *time.Time:
+ return true
+ case time.Duration:
+ return true
+ case encoding.TextMarshaler:
+ return true
+ case jsonMarshaler:
+ return e.useJSONMarshaler
+ }
+ return false
+}
+
+func (e *Encoder) encodeByMarshaler(ctx context.Context, v reflect.Value, column int) (ast.Node, error) {
+ iface := v.Interface()
+
+ if marshaler, exists := e.marshalerFromCustomMarshalerMap(v.Type()); exists {
+ doc, err := marshaler(ctx, iface)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(BytesMarshalerContext); ok {
+ doc, err := marshaler.MarshalYAML(ctx)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(BytesMarshaler); ok {
+ doc, err := marshaler.MarshalYAML()
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+
+ if marshaler, ok := iface.(InterfaceMarshalerContext); ok {
+ marshalV, err := marshaler.MarshalYAML(ctx)
+ if err != nil {
+ return nil, err
+ }
+ return e.encodeValue(ctx, reflect.ValueOf(marshalV), column)
+ }
+
+ if marshaler, ok := iface.(InterfaceMarshaler); ok {
+ marshalV, err := marshaler.MarshalYAML()
+ if err != nil {
+ return nil, err
+ }
+ return e.encodeValue(ctx, reflect.ValueOf(marshalV), column)
+ }
+
+ if t, ok := iface.(time.Time); ok {
+ return e.encodeTime(t, column), nil
+ }
+ // Handle *time.Time explicitly since it implements TextMarshaler and shouldn't be treated as plain text
+ if t, ok := iface.(*time.Time); ok && t != nil {
+ return e.encodeTime(*t, column), nil
+ }
+
+ if t, ok := iface.(time.Duration); ok {
+ return e.encodeDuration(t, column), nil
+ }
+
+ if marshaler, ok := iface.(encoding.TextMarshaler); ok {
+ text, err := marshaler.MarshalText()
+ if err != nil {
+ return nil, err
+ }
+ node := e.encodeString(string(text), column)
+ return node, nil
+ }
+
+ if e.useJSONMarshaler {
+ if marshaler, ok := iface.(jsonMarshaler); ok {
+ jsonBytes, err := marshaler.MarshalJSON()
+ if err != nil {
+ return nil, err
+ }
+ doc, err := JSONToYAML(jsonBytes)
+ if err != nil {
+ return nil, err
+ }
+ node, err := e.encodeDocument(doc)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+ }
+
+ return nil, errors.New("does not implemented Marshaler")
+}
+
+func (e *Encoder) encodeValue(ctx context.Context, v reflect.Value, column int) (ast.Node, error) {
+ if e.isInvalidValue(v) {
+ return e.encodeNil(), nil
+ }
+ if e.canEncodeByMarshaler(v) {
+ node, err := e.encodeByMarshaler(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+ }
+ switch v.Type().Kind() {
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return e.encodeInt(v.Int()), nil
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64:
+ return e.encodeUint(v.Uint()), nil
+ case reflect.Float32:
+ return e.encodeFloat(v.Float(), 32), nil
+ case reflect.Float64:
+ return e.encodeFloat(v.Float(), 64), nil
+ case reflect.Ptr:
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeValue(ctx, v.Elem(), column)
+ case reflect.Interface:
+ return e.encodeValue(ctx, v.Elem(), column)
+ case reflect.String:
+ return e.encodeString(v.String(), column), nil
+ case reflect.Bool:
+ return e.encodeBool(v.Bool()), nil
+ case reflect.Slice:
+ if mapSlice, ok := v.Interface().(MapSlice); ok {
+ return e.encodeMapSlice(ctx, mapSlice, column)
+ }
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeSlice(ctx, v)
+ case reflect.Array:
+ return e.encodeArray(ctx, v)
+ case reflect.Struct:
+ if v.CanInterface() {
+ if mapItem, ok := v.Interface().(MapItem); ok {
+ return e.encodeMapItem(ctx, mapItem, column)
+ }
+ if t, ok := v.Interface().(time.Time); ok {
+ return e.encodeTime(t, column), nil
+ }
+ }
+ return e.encodeStruct(ctx, v, column)
+ case reflect.Map:
+ if value := e.encodePtrAnchor(v, column); value != nil {
+ return value, nil
+ }
+ return e.encodeMap(ctx, v, column)
+ default:
+ return nil, fmt.Errorf("unknown value type %s", v.Type().String())
+ }
+}
+
+func (e *Encoder) encodePtrAnchor(v reflect.Value, column int) ast.Node {
+ anchorName, exists := e.getAnchor(v.Pointer())
+ if !exists {
+ return nil
+ }
+ aliasName := anchorName
+ alias := ast.Alias(token.New("*", "*", e.pos(column)))
+ alias.Value = ast.String(token.New(aliasName, aliasName, e.pos(column)))
+ e.setSmartAlias(aliasName, v.Pointer())
+ return alias
+}
+
+func (e *Encoder) pos(column int) *token.Position {
+ return &token.Position{
+ Line: e.line,
+ Column: column,
+ Offset: e.offset,
+ IndentNum: e.indentNum,
+ IndentLevel: e.indentLevel,
+ }
+}
+
+func (e *Encoder) encodeNil() *ast.NullNode {
+ value := "null"
+ return ast.Null(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeInt(v int64) *ast.IntegerNode {
+ value := strconv.FormatInt(v, 10)
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeUint(v uint64) *ast.IntegerNode {
+ value := strconv.FormatUint(v, 10)
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeFloat(v float64, bitSize int) ast.Node {
+ if v == math.Inf(0) {
+ value := ".inf"
+ return ast.Infinity(token.New(value, value, e.pos(e.column)))
+ } else if v == math.Inf(-1) {
+ value := "-.inf"
+ return ast.Infinity(token.New(value, value, e.pos(e.column)))
+ } else if math.IsNaN(v) {
+ value := ".nan"
+ return ast.Nan(token.New(value, value, e.pos(e.column)))
+ }
+ value := strconv.FormatFloat(v, 'g', -1, bitSize)
+ if !strings.Contains(value, ".") && !strings.Contains(value, "e") {
+ if e.autoInt {
+ return ast.Integer(token.New(value, value, e.pos(e.column)))
+ }
+ // append x.0 suffix to keep float value context
+ value = fmt.Sprintf("%s.0", value)
+ }
+ return ast.Float(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) isNeedQuoted(v string) bool {
+ if e.isJSONStyle {
+ return true
+ }
+ if e.useLiteralStyleIfMultiline && strings.ContainsAny(v, "\n\r") {
+ return false
+ }
+ if e.isFlowStyle && strings.ContainsAny(v, `]},'"`) {
+ return true
+ }
+ if e.isFlowStyle {
+ for i := 0; i < len(v); i++ {
+ if v[i] != ':' {
+ continue
+ }
+ if i+1 < len(v) && v[i+1] == '/' {
+ continue
+ }
+ return true
+ }
+ }
+ if token.IsNeedQuoted(v) {
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) encodeString(v string, column int) *ast.StringNode {
+ if e.isNeedQuoted(v) {
+ if e.singleQuote {
+ v = quoteWith(v, '\'')
+ } else {
+ v = strconv.Quote(v)
+ }
+ }
+ return ast.String(token.New(v, v, e.pos(column)))
+}
+
+func (e *Encoder) encodeBool(v bool) *ast.BoolNode {
+ value := strconv.FormatBool(v)
+ return ast.Bool(token.New(value, value, e.pos(e.column)))
+}
+
+func (e *Encoder) encodeSlice(ctx context.Context, value reflect.Value) (*ast.SequenceNode, error) {
+ if e.indentSequence {
+ e.column += e.indentNum
+ defer func() { e.column -= e.indentNum }()
+ }
+ column := e.column
+ sequence := ast.Sequence(token.New("-", "-", e.pos(column)), e.isFlowStyle)
+ for i := 0; i < value.Len(); i++ {
+ node, err := e.encodeValue(ctx, value.Index(i), column)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, node)
+ }
+ return sequence, nil
+}
+
+func (e *Encoder) encodeArray(ctx context.Context, value reflect.Value) (*ast.SequenceNode, error) {
+ if e.indentSequence {
+ e.column += e.indentNum
+ defer func() { e.column -= e.indentNum }()
+ }
+ column := e.column
+ sequence := ast.Sequence(token.New("-", "-", e.pos(column)), e.isFlowStyle)
+ for i := 0; i < value.Len(); i++ {
+ node, err := e.encodeValue(ctx, value.Index(i), column)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, node)
+ }
+ return sequence, nil
+}
+
+func (e *Encoder) encodeMapItem(ctx context.Context, item MapItem, column int) (*ast.MappingValueNode, error) {
+ k := reflect.ValueOf(item.Key)
+ v := reflect.ValueOf(item.Value)
+ value, err := e.encodeValue(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(value) {
+ value.AddColumn(e.indentNum)
+ }
+ if e.isTagAndMapNode(value) {
+ value.AddColumn(e.indentNum)
+ }
+ return ast.MappingValue(
+ token.New("", "", e.pos(column)),
+ e.encodeString(k.Interface().(string), column),
+ value,
+ ), nil
+}
+
+func (e *Encoder) encodeMapSlice(ctx context.Context, value MapSlice, column int) (*ast.MappingNode, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ for _, item := range value {
+ encoded, err := e.encodeMapItem(ctx, item, column)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, encoded)
+ }
+ return node, nil
+}
+
+func (e *Encoder) isMapNode(node ast.Node) bool {
+ _, ok := node.(ast.MapNode)
+ return ok
+}
+
+func (e *Encoder) isTagAndMapNode(node ast.Node) bool {
+ tn, ok := node.(*ast.TagNode)
+ return ok && e.isMapNode(tn.Value)
+}
+
+func (e *Encoder) encodeMap(ctx context.Context, value reflect.Value, column int) (ast.Node, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ keys := make([]interface{}, len(value.MapKeys()))
+ for i, k := range value.MapKeys() {
+ keys[i] = k.Interface()
+ }
+ sort.Slice(keys, func(i, j int) bool {
+ return fmt.Sprint(keys[i]) < fmt.Sprint(keys[j])
+ })
+ for _, key := range keys {
+ k := reflect.ValueOf(key)
+ v := value.MapIndex(k)
+ encoded, err := e.encodeValue(ctx, v, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ if e.isTagAndMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ keyText := fmt.Sprint(key)
+ vRef := e.toPointer(v)
+
+ // during the second encoding, an anchor is assigned if it is found to be used by an alias.
+ if aliasName, exists := e.getSmartAlias(vRef); exists {
+ anchorName := aliasName
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = encoded
+ encoded = anchorNode
+ }
+
+ kn, err := e.encodeValue(ctx, reflect.ValueOf(key), column)
+ keyNode, ok := kn.(ast.MapKeyNode)
+ if !ok || err != nil {
+ keyNode = e.encodeString(fmt.Sprint(key), column)
+ }
+ node.Values = append(node.Values, ast.MappingValue(
+ nil,
+ keyNode,
+ encoded,
+ ))
+ e.setSmartAnchor(vRef, keyText)
+ }
+ return node, nil
+}
+
+// IsZeroer is used to check whether an object is zero to determine
+// whether it should be omitted when marshaling with the omitempty flag.
+// One notable implementation is time.Time.
+type IsZeroer interface {
+ IsZero() bool
+}
+
+func (e *Encoder) isOmittedByOmitZero(v reflect.Value) bool {
+ kind := v.Kind()
+ if z, ok := v.Interface().(IsZeroer); ok {
+ if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
+ return true
+ }
+ return z.IsZero()
+ }
+ switch kind {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr, reflect.Slice, reflect.Map:
+ return v.IsNil()
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Struct:
+ vt := v.Type()
+ for i := v.NumField() - 1; i >= 0; i-- {
+ if vt.Field(i).PkgPath != "" {
+ continue // private field
+ }
+ if !e.isOmittedByOmitZero(v.Field(i)) {
+ return false
+ }
+ }
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) isOmittedByOmitEmptyOption(v reflect.Value) bool {
+ switch v.Kind() {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr:
+ return v.IsNil()
+ case reflect.Slice, reflect.Map:
+ return v.Len() == 0
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ }
+ return false
+}
+
+// The current implementation of the omitempty tag combines the functionality of encoding/json's omitempty and omitzero tags.
+// This stems from a historical decision to respect the implementation of gopkg.in/yaml.v2, but it has caused confusion,
+// so we are working to integrate it into the functionality of encoding/json. (However, this will take some time.)
+// In the current implementation, in addition to the exclusion conditions of omitempty,
+// if a type implements IsZero, that implementation will be used.
+// Furthermore, for non-pointer structs, if all fields are eligible for exclusion,
+// the struct itself will also be excluded. These behaviors are originally the functionality of omitzero.
+func (e *Encoder) isOmittedByOmitEmptyTag(v reflect.Value) bool {
+ kind := v.Kind()
+ if z, ok := v.Interface().(IsZeroer); ok {
+ if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
+ return true
+ }
+ return z.IsZero()
+ }
+ switch kind {
+ case reflect.String:
+ return len(v.String()) == 0
+ case reflect.Interface, reflect.Ptr:
+ return v.IsNil()
+ case reflect.Slice, reflect.Map:
+ return v.Len() == 0
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Struct:
+ vt := v.Type()
+ for i := v.NumField() - 1; i >= 0; i-- {
+ if vt.Field(i).PkgPath != "" {
+ continue // private field
+ }
+ if !e.isOmittedByOmitEmptyTag(v.Field(i)) {
+ return false
+ }
+ }
+ return true
+ }
+ return false
+}
+
+func (e *Encoder) encodeTime(v time.Time, column int) *ast.StringNode {
+ value := v.Format(time.RFC3339Nano)
+ if e.isJSONStyle {
+ value = strconv.Quote(value)
+ }
+ return ast.String(token.New(value, value, e.pos(column)))
+}
+
+func (e *Encoder) encodeDuration(v time.Duration, column int) *ast.StringNode {
+ value := v.String()
+ if e.isJSONStyle {
+ value = strconv.Quote(value)
+ }
+ return ast.String(token.New(value, value, e.pos(column)))
+}
+
+func (e *Encoder) encodeAnchor(anchorName string, value ast.Node, fieldValue reflect.Value, column int) (*ast.AnchorNode, error) {
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = value
+ if e.anchorCallback != nil {
+ if err := e.anchorCallback(anchorNode, fieldValue.Interface()); err != nil {
+ return nil, err
+ }
+ if snode, ok := anchorNode.Name.(*ast.StringNode); ok {
+ anchorName = snode.Value
+ }
+ }
+ if fieldValue.Kind() == reflect.Ptr {
+ e.setAnchor(fieldValue.Pointer(), anchorName)
+ }
+ return anchorNode, nil
+}
+
+func (e *Encoder) encodeStruct(ctx context.Context, value reflect.Value, column int) (ast.Node, error) {
+ node := ast.Mapping(token.New("", "", e.pos(column)), e.isFlowStyle)
+ structType := value.Type()
+ fieldMap, err := structFieldMap(structType)
+ if err != nil {
+ return nil, err
+ }
+ hasInlineAnchorField := false
+ var inlineAnchorValue reflect.Value
+ for i := 0; i < value.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ fieldValue := value.FieldByName(field.Name)
+ sf := fieldMap[field.Name]
+ if (e.omitZero || sf.IsOmitZero) && e.isOmittedByOmitZero(fieldValue) {
+ // omit encoding by omitzero tag or OmitZero option.
+ continue
+ }
+ if e.omitEmpty && e.isOmittedByOmitEmptyOption(fieldValue) {
+ // omit encoding by OmitEmpty option.
+ continue
+ }
+ if sf.IsOmitEmpty && e.isOmittedByOmitEmptyTag(fieldValue) {
+ // omit encoding by omitempty tag.
+ continue
+ }
+ ve := e
+ if !e.isFlowStyle && sf.IsFlow {
+ ve = &Encoder{}
+ *ve = *e
+ ve.isFlowStyle = true
+ }
+ encoded, err := ve.encodeValue(ctx, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ if e.isMapNode(encoded) {
+ encoded.AddColumn(e.indentNum)
+ }
+ var key ast.MapKeyNode = e.encodeString(sf.RenderName, column)
+ switch {
+ case encoded.Type() == ast.AliasType:
+ if aliasName := sf.AliasName; aliasName != "" {
+ alias, ok := encoded.(*ast.AliasNode)
+ if !ok {
+ return nil, errors.ErrUnexpectedNodeType(encoded.Type(), ast.AliasType, encoded.GetToken())
+ }
+ got := alias.Value.String()
+ if aliasName != got {
+ return nil, fmt.Errorf("expected alias name is %q but got %q", aliasName, got)
+ }
+ }
+ if sf.IsInline {
+ // if both used alias and inline, output `<<: *alias`
+ key = ast.MergeKey(token.New("<<", "<<", e.pos(column)))
+ }
+ case sf.AnchorName != "":
+ anchorNode, err := e.encodeAnchor(sf.AnchorName, encoded, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ encoded = anchorNode
+ case sf.IsInline:
+ isAutoAnchor := sf.IsAutoAnchor
+ if !hasInlineAnchorField {
+ hasInlineAnchorField = isAutoAnchor
+ }
+ if isAutoAnchor {
+ inlineAnchorValue = fieldValue
+ }
+ mapNode, ok := encoded.(ast.MapNode)
+ if !ok {
+ // if an inline field is null, skip encoding it
+ if _, ok := encoded.(*ast.NullNode); ok {
+ continue
+ }
+ return nil, errors.New("inline value is must be map or struct type")
+ }
+ mapIter := mapNode.MapRange()
+ for mapIter.Next() {
+ mapKey := mapIter.Key()
+ mapValue := mapIter.Value()
+ keyName := mapKey.GetToken().Value
+ if fieldMap.isIncludedRenderName(keyName) {
+ // if declared the same key name, skip encoding this field
+ continue
+ }
+ mapKey.AddColumn(-e.indentNum)
+ mapValue.AddColumn(-e.indentNum)
+ node.Values = append(node.Values, ast.MappingValue(nil, mapKey, mapValue))
+ }
+ continue
+ case sf.IsAutoAnchor:
+ anchorNode, err := e.encodeAnchor(sf.RenderName, encoded, fieldValue, column)
+ if err != nil {
+ return nil, err
+ }
+ encoded = anchorNode
+ }
+ node.Values = append(node.Values, ast.MappingValue(nil, key, encoded))
+ }
+ if hasInlineAnchorField {
+ node.AddColumn(e.indentNum)
+ anchorName := "anchor"
+ anchorNode := ast.Anchor(token.New("&", "&", e.pos(column)))
+ anchorNode.Name = ast.String(token.New(anchorName, anchorName, e.pos(column)))
+ anchorNode.Value = node
+ if e.anchorCallback != nil {
+ if err := e.anchorCallback(anchorNode, value.Addr().Interface()); err != nil {
+ return nil, err
+ }
+ if snode, ok := anchorNode.Name.(*ast.StringNode); ok {
+ anchorName = snode.Value
+ }
+ }
+ if inlineAnchorValue.Kind() == reflect.Ptr {
+ e.setAnchor(inlineAnchorValue.Pointer(), anchorName)
+ }
+ return anchorNode, nil
+ }
+ return node, nil
+}
+
+func (e *Encoder) toPointer(v reflect.Value) uintptr {
+ if e.isInvalidValue(v) {
+ return 0
+ }
+
+ switch v.Type().Kind() {
+ case reflect.Ptr:
+ return v.Pointer()
+ case reflect.Interface:
+ return e.toPointer(v.Elem())
+ case reflect.Slice:
+ return v.Pointer()
+ case reflect.Map:
+ return v.Pointer()
+ }
+ return 0
+}
+
+func (e *Encoder) clearSmartAnchorRef() {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.anchorRefToName = make(map[uintptr]string)
+ e.anchorNameMap = make(map[string]struct{})
+}
+
+func (e *Encoder) setSmartAnchor(ptr uintptr, name string) {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.setAnchor(ptr, e.generateAnchorName(name))
+}
+
+func (e *Encoder) setAnchor(ptr uintptr, name string) {
+ if ptr == 0 {
+ return
+ }
+ if name == "" {
+ return
+ }
+ e.anchorRefToName[ptr] = name
+ e.anchorNameMap[name] = struct{}{}
+}
+
+func (e *Encoder) generateAnchorName(base string) string {
+ if _, exists := e.anchorNameMap[base]; !exists {
+ return base
+ }
+ for i := 1; i < 100; i++ {
+ name := base + strconv.Itoa(i)
+ if _, exists := e.anchorNameMap[name]; exists {
+ continue
+ }
+ return name
+ }
+ return ""
+}
+
+func (e *Encoder) getAnchor(ref uintptr) (string, bool) {
+ anchorName, exists := e.anchorRefToName[ref]
+ return anchorName, exists
+}
+
+func (e *Encoder) setSmartAlias(name string, ref uintptr) {
+ if !e.enableSmartAnchor {
+ return
+ }
+ e.aliasRefToName[ref] = name
+}
+
+func (e *Encoder) getSmartAlias(ref uintptr) (string, bool) {
+ if !e.enableSmartAnchor {
+ return "", false
+ }
+ aliasName, exists := e.aliasRefToName[ref]
+ return aliasName, exists
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/error.go b/sesh/vendor/github.com/goccy/go-yaml/error.go
new file mode 100644
index 0000000..52d3e7e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/error.go
@@ -0,0 +1,77 @@
+package yaml
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+)
+
+var (
+ ErrInvalidQuery = errors.New("invalid query")
+ ErrInvalidPath = errors.New("invalid path instance")
+ ErrInvalidPathString = errors.New("invalid path string")
+ ErrNotFoundNode = errors.New("node not found")
+ ErrUnknownCommentPositionType = errors.New("unknown comment position type")
+ ErrInvalidCommentMapValue = errors.New("invalid comment map value. it must be not nil value")
+ ErrDecodeRequiredPointerType = errors.New("required pointer type value")
+ ErrExceededMaxDepth = errors.New("exceeded max depth")
+ FormatErrorWithToken = errors.FormatError
+)
+
+type (
+ SyntaxError = errors.SyntaxError
+ TypeError = errors.TypeError
+ OverflowError = errors.OverflowError
+ DuplicateKeyError = errors.DuplicateKeyError
+ UnknownFieldError = errors.UnknownFieldError
+ UnexpectedNodeTypeError = errors.UnexpectedNodeTypeError
+ Error = errors.Error
+)
+
+func ErrUnsupportedHeadPositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment head position for %s", node.Type())
+}
+
+func ErrUnsupportedLinePositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment line position for %s", node.Type())
+}
+
+func ErrUnsupportedFootPositionType(node ast.Node) error {
+ return fmt.Errorf("unsupported comment foot position for %s", node.Type())
+}
+
+// IsInvalidQueryError whether err is ErrInvalidQuery or not.
+func IsInvalidQueryError(err error) bool {
+ return errors.Is(err, ErrInvalidQuery)
+}
+
+// IsInvalidPathError whether err is ErrInvalidPath or not.
+func IsInvalidPathError(err error) bool {
+ return errors.Is(err, ErrInvalidPath)
+}
+
+// IsInvalidPathStringError whether err is ErrInvalidPathString or not.
+func IsInvalidPathStringError(err error) bool {
+ return errors.Is(err, ErrInvalidPathString)
+}
+
+// IsNotFoundNodeError whether err is ErrNotFoundNode or not.
+func IsNotFoundNodeError(err error) bool {
+ return errors.Is(err, ErrNotFoundNode)
+}
+
+// IsInvalidTokenTypeError whether err is ast.ErrInvalidTokenType or not.
+func IsInvalidTokenTypeError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidTokenType)
+}
+
+// IsInvalidAnchorNameError whether err is ast.ErrInvalidAnchorName or not.
+func IsInvalidAnchorNameError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidAnchorName)
+}
+
+// IsInvalidAliasNameError whether err is ast.ErrInvalidAliasName or not.
+func IsInvalidAliasNameError(err error) bool {
+ return errors.Is(err, ast.ErrInvalidAliasName)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go b/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go
new file mode 100644
index 0000000..b08a3fc
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/internal/errors/error.go
@@ -0,0 +1,246 @@
+package errors
+
+import (
+ "errors"
+ "fmt"
+ "reflect"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/printer"
+ "github.com/goccy/go-yaml/token"
+)
+
+var (
+ As = errors.As
+ Is = errors.Is
+ New = errors.New
+)
+
+const (
+ defaultFormatColor = false
+ defaultIncludeSource = true
+)
+
+type Error interface {
+ error
+ GetToken() *token.Token
+ GetMessage() string
+ FormatError(bool, bool) string
+}
+
+var (
+ _ Error = new(SyntaxError)
+ _ Error = new(TypeError)
+ _ Error = new(OverflowError)
+ _ Error = new(DuplicateKeyError)
+ _ Error = new(UnknownFieldError)
+ _ Error = new(UnexpectedNodeTypeError)
+)
+
+type SyntaxError struct {
+ Message string
+ Token *token.Token
+}
+
+type TypeError struct {
+ DstType reflect.Type
+ SrcType reflect.Type
+ StructFieldName *string
+ Token *token.Token
+}
+
+type OverflowError struct {
+ DstType reflect.Type
+ SrcNum string
+ Token *token.Token
+}
+
+type DuplicateKeyError struct {
+ Message string
+ Token *token.Token
+}
+
+type UnknownFieldError struct {
+ Message string
+ Token *token.Token
+}
+
+type UnexpectedNodeTypeError struct {
+ Actual ast.NodeType
+ Expected ast.NodeType
+ Token *token.Token
+}
+
+// ErrSyntax create syntax error instance with message and token
+func ErrSyntax(msg string, tk *token.Token) *SyntaxError {
+ return &SyntaxError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+// ErrOverflow creates an overflow error instance with message and a token.
+func ErrOverflow(dstType reflect.Type, num string, tk *token.Token) *OverflowError {
+ return &OverflowError{
+ DstType: dstType,
+ SrcNum: num,
+ Token: tk,
+ }
+}
+
+// ErrTypeMismatch cerates an type mismatch error instance with token.
+func ErrTypeMismatch(dstType, srcType reflect.Type, token *token.Token) *TypeError {
+ return &TypeError{
+ DstType: dstType,
+ SrcType: srcType,
+ Token: token,
+ }
+}
+
+// ErrDuplicateKey creates an duplicate key error instance with token.
+func ErrDuplicateKey(msg string, tk *token.Token) *DuplicateKeyError {
+ return &DuplicateKeyError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+// ErrUnknownField creates an unknown field error instance with token.
+func ErrUnknownField(msg string, tk *token.Token) *UnknownFieldError {
+ return &UnknownFieldError{
+ Message: msg,
+ Token: tk,
+ }
+}
+
+func ErrUnexpectedNodeType(actual, expected ast.NodeType, tk *token.Token) *UnexpectedNodeTypeError {
+ return &UnexpectedNodeTypeError{
+ Actual: actual,
+ Expected: expected,
+ Token: tk,
+ }
+}
+
+func (e *SyntaxError) GetMessage() string {
+ return e.Message
+}
+
+func (e *SyntaxError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *SyntaxError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *SyntaxError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *OverflowError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *OverflowError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *OverflowError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *OverflowError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *OverflowError) msg() string {
+ return fmt.Sprintf("cannot unmarshal %s into Go value of type %s ( overflow )", e.SrcNum, e.DstType)
+}
+
+func (e *TypeError) msg() string {
+ if e.StructFieldName != nil {
+ return fmt.Sprintf("cannot unmarshal %s into Go struct field %s of type %s", e.SrcType, *e.StructFieldName, e.DstType)
+ }
+ return fmt.Sprintf("cannot unmarshal %s into Go value of type %s", e.SrcType, e.DstType)
+}
+
+func (e *TypeError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *TypeError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *TypeError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *TypeError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *DuplicateKeyError) GetMessage() string {
+ return e.Message
+}
+
+func (e *DuplicateKeyError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *DuplicateKeyError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *DuplicateKeyError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *UnknownFieldError) GetMessage() string {
+ return e.Message
+}
+
+func (e *UnknownFieldError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *UnknownFieldError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *UnknownFieldError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.Message, e.Token, colored, inclSource)
+}
+
+func (e *UnexpectedNodeTypeError) GetMessage() string {
+ return e.msg()
+}
+
+func (e *UnexpectedNodeTypeError) GetToken() *token.Token {
+ return e.Token
+}
+
+func (e *UnexpectedNodeTypeError) Error() string {
+ return e.FormatError(defaultFormatColor, defaultIncludeSource)
+}
+
+func (e *UnexpectedNodeTypeError) FormatError(colored, inclSource bool) string {
+ return FormatError(e.msg(), e.Token, colored, inclSource)
+}
+
+func (e *UnexpectedNodeTypeError) msg() string {
+ return fmt.Sprintf("%s was used where %s is expected", e.Actual.YAMLName(), e.Expected.YAMLName())
+}
+
+func FormatError(errMsg string, token *token.Token, colored, inclSource bool) string {
+ var pp printer.Printer
+ if token == nil {
+ return pp.PrintErrorMessage(errMsg, colored)
+ }
+ pos := fmt.Sprintf("[%d:%d] ", token.Position.Line, token.Position.Column)
+ msg := pp.PrintErrorMessage(fmt.Sprintf("%s%s", pos, errMsg), colored)
+ if inclSource {
+ msg += "\n" + pp.PrintErrorToken(token, colored)
+ }
+ return msg
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go b/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go
new file mode 100644
index 0000000..461dc36
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/internal/format/format.go
@@ -0,0 +1,541 @@
+package format
+
+import (
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/token"
+)
+
+func FormatNodeWithResolvedAlias(n ast.Node, anchorNodeMap map[string]ast.Node) string {
+ tk := getFirstToken(n)
+ if tk == nil {
+ return ""
+ }
+ formatter := newFormatter(tk, hasComment(n))
+ formatter.anchorNodeMap = anchorNodeMap
+ return formatter.format(n)
+}
+
+func FormatNode(n ast.Node) string {
+ tk := getFirstToken(n)
+ if tk == nil {
+ return ""
+ }
+ return newFormatter(tk, hasComment(n)).format(n)
+}
+
+func FormatFile(file *ast.File) string {
+ if len(file.Docs) == 0 {
+ return ""
+ }
+ tk := getFirstToken(file.Docs[0])
+ if tk == nil {
+ return ""
+ }
+ return newFormatter(tk, hasCommentFile(file)).formatFile(file)
+}
+
+func hasCommentFile(f *ast.File) bool {
+ for _, doc := range f.Docs {
+ if hasComment(doc.Body) {
+ return true
+ }
+ }
+ return false
+}
+
+func hasComment(n ast.Node) bool {
+ if n == nil {
+ return false
+ }
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ return hasComment(nn.Body)
+ case *ast.NullNode:
+ return nn.Comment != nil
+ case *ast.BoolNode:
+ return nn.Comment != nil
+ case *ast.IntegerNode:
+ return nn.Comment != nil
+ case *ast.FloatNode:
+ return nn.Comment != nil
+ case *ast.StringNode:
+ return nn.Comment != nil
+ case *ast.InfinityNode:
+ return nn.Comment != nil
+ case *ast.NanNode:
+ return nn.Comment != nil
+ case *ast.LiteralNode:
+ return nn.Comment != nil
+ case *ast.DirectiveNode:
+ if nn.Comment != nil {
+ return true
+ }
+ for _, value := range nn.Values {
+ if hasComment(value) {
+ return true
+ }
+ }
+ case *ast.TagNode:
+ if nn.Comment != nil {
+ return true
+ }
+ return hasComment(nn.Value)
+ case *ast.MappingNode:
+ if nn.Comment != nil || nn.FootComment != nil {
+ return true
+ }
+ for _, value := range nn.Values {
+ if value.Comment != nil || value.FootComment != nil {
+ return true
+ }
+ if hasComment(value.Key) {
+ return true
+ }
+ if hasComment(value.Value) {
+ return true
+ }
+ }
+ case *ast.MappingKeyNode:
+ return nn.Comment != nil
+ case *ast.MergeKeyNode:
+ return nn.Comment != nil
+ case *ast.SequenceNode:
+ if nn.Comment != nil || nn.FootComment != nil {
+ return true
+ }
+ for _, entry := range nn.Entries {
+ if entry.Comment != nil || entry.HeadComment != nil || entry.LineComment != nil {
+ return true
+ }
+ if hasComment(entry.Value) {
+ return true
+ }
+ }
+ case *ast.AnchorNode:
+ if nn.Comment != nil {
+ return true
+ }
+ if hasComment(nn.Name) || hasComment(nn.Value) {
+ return true
+ }
+ case *ast.AliasNode:
+ if nn.Comment != nil {
+ return true
+ }
+ if hasComment(nn.Value) {
+ return true
+ }
+ }
+ return false
+}
+
+func getFirstToken(n ast.Node) *token.Token {
+ if n == nil {
+ return nil
+ }
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ if nn.Start != nil {
+ return nn.Start
+ }
+ return getFirstToken(nn.Body)
+ case *ast.NullNode:
+ return nn.Token
+ case *ast.BoolNode:
+ return nn.Token
+ case *ast.IntegerNode:
+ return nn.Token
+ case *ast.FloatNode:
+ return nn.Token
+ case *ast.StringNode:
+ return nn.Token
+ case *ast.InfinityNode:
+ return nn.Token
+ case *ast.NanNode:
+ return nn.Token
+ case *ast.LiteralNode:
+ return nn.Start
+ case *ast.DirectiveNode:
+ return nn.Start
+ case *ast.TagNode:
+ return nn.Start
+ case *ast.MappingNode:
+ if nn.IsFlowStyle {
+ return nn.Start
+ }
+ if len(nn.Values) == 0 {
+ return nn.Start
+ }
+ return getFirstToken(nn.Values[0].Key)
+ case *ast.MappingKeyNode:
+ return nn.Start
+ case *ast.MergeKeyNode:
+ return nn.Token
+ case *ast.SequenceNode:
+ return nn.Start
+ case *ast.AnchorNode:
+ return nn.Start
+ case *ast.AliasNode:
+ return nn.Start
+ }
+ return nil
+}
+
+type Formatter struct {
+ existsComment bool
+ tokenToOriginMap map[*token.Token]string
+ anchorNodeMap map[string]ast.Node
+}
+
+func newFormatter(tk *token.Token, existsComment bool) *Formatter {
+ tokenToOriginMap := make(map[*token.Token]string)
+ for tk.Prev != nil {
+ tk = tk.Prev
+ }
+ tokenToOriginMap[tk] = tk.Origin
+
+ var origin string
+ for tk.Next != nil {
+ tk = tk.Next
+ if tk.Type == token.CommentType {
+ origin += strings.Repeat("\n", strings.Count(normalizeNewLineChars(tk.Origin), "\n"))
+ continue
+ }
+ origin += tk.Origin
+ tokenToOriginMap[tk] = origin
+ origin = ""
+ }
+ return &Formatter{
+ existsComment: existsComment,
+ tokenToOriginMap: tokenToOriginMap,
+ }
+}
+
+func getIndentNumByFirstLineToken(tk *token.Token) int {
+ defaultIndent := tk.Position.Column - 1
+
+ // key: value
+ // ^
+ // next
+ if tk.Type == token.SequenceEntryType {
+ // If the current token is the sequence entry.
+ // the indent is calculated from the column value of the current token.
+ return defaultIndent
+ }
+
+ // key: value
+ // ^
+ // next
+ if tk.Next != nil && tk.Next.Type == token.MappingValueType {
+ // If the current token is the key in the mapping-value,
+ // the indent is calculated from the column value of the current token.
+ return defaultIndent
+ }
+
+ if tk.Prev == nil {
+ return defaultIndent
+ }
+ prev := tk.Prev
+
+ // key: value
+ // ^
+ // prev
+ if prev.Type == token.MappingValueType {
+ // If the current token is the value in the mapping-value,
+ // the indent is calculated from the column value of the key two steps back.
+ if prev.Prev == nil {
+ return defaultIndent
+ }
+ return prev.Prev.Position.Column - 1
+ }
+
+ // - value
+ // ^
+ // prev
+ if prev.Type == token.SequenceEntryType {
+ // If the value is not a mapping-value and the previous token was a sequence entry,
+ // the indent is calculated using the column value of the sequence entry token.
+ return prev.Position.Column - 1
+ }
+
+ return defaultIndent
+}
+
+func (f *Formatter) format(n ast.Node) string {
+ return f.trimSpacePrefix(
+ f.trimIndentSpace(
+ getIndentNumByFirstLineToken(getFirstToken(n)),
+ f.trimNewLineCharPrefix(f.formatNode(n)),
+ ),
+ )
+}
+
+func (f *Formatter) formatFile(file *ast.File) string {
+ if len(file.Docs) == 0 {
+ return ""
+ }
+ var ret string
+ for _, doc := range file.Docs {
+ ret += f.formatDocument(doc)
+ }
+ return ret
+}
+
+func (f *Formatter) origin(tk *token.Token) string {
+ if tk == nil {
+ return ""
+ }
+ if f.existsComment {
+ return tk.Origin
+ }
+ return f.tokenToOriginMap[tk]
+}
+
+func (f *Formatter) formatDocument(n *ast.DocumentNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Body) + f.origin(n.End)
+}
+
+func (f *Formatter) formatNull(n *ast.NullNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatString(n *ast.StringNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatInteger(n *ast.IntegerNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatFloat(n *ast.FloatNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatBool(n *ast.BoolNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatInfinity(n *ast.InfinityNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatNan(n *ast.NanNode) string {
+ return f.origin(n.Token) + f.formatCommentGroup(n.Comment)
+}
+
+func (f *Formatter) formatLiteral(n *ast.LiteralNode) string {
+ return f.origin(n.Start) + f.formatCommentGroup(n.Comment) + f.origin(n.Value.Token)
+}
+
+func (f *Formatter) formatMergeKey(n *ast.MergeKeyNode) string {
+ return f.origin(n.Token)
+}
+
+func (f *Formatter) formatMappingValue(n *ast.MappingValueNode) string {
+ return f.formatCommentGroup(n.Comment) +
+ f.origin(n.Key.GetToken()) + ":" + f.formatCommentGroup(n.Key.GetComment()) + f.formatNode(n.Value) +
+ f.formatCommentGroup(n.FootComment)
+}
+
+func (f *Formatter) formatDirective(n *ast.DirectiveNode) string {
+ ret := f.origin(n.Start) + f.formatNode(n.Name)
+ for _, val := range n.Values {
+ ret += f.formatNode(val)
+ }
+ return ret
+}
+
+func (f *Formatter) formatMapping(n *ast.MappingNode) string {
+ var ret string
+ if n.IsFlowStyle {
+ ret = f.origin(n.Start)
+ } else {
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ for _, value := range n.Values {
+ if value.CollectEntry != nil {
+ ret += f.origin(value.CollectEntry)
+ }
+ ret += f.formatMappingValue(value)
+ }
+ if n.IsFlowStyle {
+ ret += f.origin(n.End)
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ return ret
+}
+
+func (f *Formatter) formatTag(n *ast.TagNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatMappingKey(n *ast.MappingKeyNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatSequence(n *ast.SequenceNode) string {
+ var ret string
+ if n.IsFlowStyle {
+ ret = f.origin(n.Start)
+ } else {
+ // add head comment.
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ for _, entry := range n.Entries {
+ ret += f.formatNode(entry)
+ }
+ if n.IsFlowStyle {
+ ret += f.origin(n.End)
+ ret += f.formatCommentGroup(n.Comment)
+ }
+ ret += f.formatCommentGroup(n.FootComment)
+ return ret
+}
+
+func (f *Formatter) formatSequenceEntry(n *ast.SequenceEntryNode) string {
+ return f.formatCommentGroup(n.HeadComment) + f.origin(n.Start) + f.formatCommentGroup(n.LineComment) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatAnchor(n *ast.AnchorNode) string {
+ return f.origin(n.Start) + f.formatNode(n.Name) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatAlias(n *ast.AliasNode) string {
+ if f.anchorNodeMap != nil {
+ anchorName := n.Value.GetToken().Value
+ node := f.anchorNodeMap[anchorName]
+ if node != nil {
+ formatted := f.formatNode(node)
+ // If formatted text contains newline characters, indentation needs to be considered.
+ if strings.Contains(formatted, "\n") {
+ // If the first character is not a newline, the first line should be output without indentation.
+ isIgnoredFirstLine := !strings.HasPrefix(formatted, "\n")
+ formatted = f.addIndentSpace(n.GetToken().Position.IndentNum, formatted, isIgnoredFirstLine)
+ }
+ return formatted
+ }
+ }
+ return f.origin(n.Start) + f.formatNode(n.Value)
+}
+
+func (f *Formatter) formatNode(n ast.Node) string {
+ switch nn := n.(type) {
+ case *ast.DocumentNode:
+ return f.formatDocument(nn)
+ case *ast.NullNode:
+ return f.formatNull(nn)
+ case *ast.BoolNode:
+ return f.formatBool(nn)
+ case *ast.IntegerNode:
+ return f.formatInteger(nn)
+ case *ast.FloatNode:
+ return f.formatFloat(nn)
+ case *ast.StringNode:
+ return f.formatString(nn)
+ case *ast.InfinityNode:
+ return f.formatInfinity(nn)
+ case *ast.NanNode:
+ return f.formatNan(nn)
+ case *ast.LiteralNode:
+ return f.formatLiteral(nn)
+ case *ast.DirectiveNode:
+ return f.formatDirective(nn)
+ case *ast.TagNode:
+ return f.formatTag(nn)
+ case *ast.MappingNode:
+ return f.formatMapping(nn)
+ case *ast.MappingKeyNode:
+ return f.formatMappingKey(nn)
+ case *ast.MappingValueNode:
+ return f.formatMappingValue(nn)
+ case *ast.MergeKeyNode:
+ return f.formatMergeKey(nn)
+ case *ast.SequenceNode:
+ return f.formatSequence(nn)
+ case *ast.SequenceEntryNode:
+ return f.formatSequenceEntry(nn)
+ case *ast.AnchorNode:
+ return f.formatAnchor(nn)
+ case *ast.AliasNode:
+ return f.formatAlias(nn)
+ }
+ return ""
+}
+
+func (f *Formatter) formatCommentGroup(g *ast.CommentGroupNode) string {
+ if g == nil {
+ return ""
+ }
+ var ret string
+ for _, cm := range g.Comments {
+ ret += f.formatComment(cm)
+ }
+ return ret
+}
+
+func (f *Formatter) formatComment(n *ast.CommentNode) string {
+ if n == nil {
+ return ""
+ }
+ return n.Token.Origin
+}
+
+// nolint: unused
+func (f *Formatter) formatIndent(col int) string {
+ if col <= 1 {
+ return ""
+ }
+ return strings.Repeat(" ", col-1)
+}
+
+func (f *Formatter) trimNewLineCharPrefix(v string) string {
+ return strings.TrimLeftFunc(v, func(r rune) bool {
+ return r == '\n' || r == '\r'
+ })
+}
+
+func (f *Formatter) trimSpacePrefix(v string) string {
+ return strings.TrimLeftFunc(v, func(r rune) bool {
+ return r == ' '
+ })
+}
+
+func (f *Formatter) trimIndentSpace(trimIndentNum int, v string) string {
+ if trimIndentNum == 0 {
+ return v
+ }
+ lines := strings.Split(normalizeNewLineChars(v), "\n")
+ out := make([]string, 0, len(lines))
+ for _, line := range lines {
+ var cnt int
+ out = append(out, strings.TrimLeftFunc(line, func(r rune) bool {
+ cnt++
+ return r == ' ' && cnt <= trimIndentNum
+ }))
+ }
+ return strings.Join(out, "\n")
+}
+
+func (f *Formatter) addIndentSpace(indentNum int, v string, isIgnoredFirstLine bool) string {
+ if indentNum == 0 {
+ return v
+ }
+ indent := strings.Repeat(" ", indentNum)
+ lines := strings.Split(normalizeNewLineChars(v), "\n")
+ out := make([]string, 0, len(lines))
+ for idx, line := range lines {
+ if line == "" || (isIgnoredFirstLine && idx == 0) {
+ out = append(out, line)
+ continue
+ }
+ out = append(out, indent+line)
+ }
+ return strings.Join(out, "\n")
+}
+
+// normalizeNewLineChars normalize CRLF and CR to LF.
+func normalizeNewLineChars(v string) string {
+ return strings.ReplaceAll(strings.ReplaceAll(v, "\r\n", "\n"), "\r", "\n")
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go b/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go
new file mode 100644
index 0000000..3207f4f
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/lexer/lexer.go
@@ -0,0 +1,23 @@
+package lexer
+
+import (
+ "io"
+
+ "github.com/goccy/go-yaml/scanner"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Tokenize split to token instances from string
+func Tokenize(src string) token.Tokens {
+ var s scanner.Scanner
+ s.Init(src)
+ var tokens token.Tokens
+ for {
+ subTokens, err := s.Scan()
+ if err == io.EOF {
+ break
+ }
+ tokens.Add(subTokens...)
+ }
+ return tokens
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/option.go b/sesh/vendor/github.com/goccy/go-yaml/option.go
new file mode 100644
index 0000000..12b8f27
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/option.go
@@ -0,0 +1,352 @@
+package yaml
+
+import (
+ "context"
+ "io"
+ "reflect"
+
+ "github.com/goccy/go-yaml/ast"
+)
+
+// DecodeOption functional option type for Decoder
+type DecodeOption func(d *Decoder) error
+
+// ReferenceReaders pass to Decoder that reference to anchor defined by passed readers
+func ReferenceReaders(readers ...io.Reader) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceReaders = append(d.referenceReaders, readers...)
+ return nil
+ }
+}
+
+// ReferenceFiles pass to Decoder that reference to anchor defined by passed files
+func ReferenceFiles(files ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceFiles = files
+ return nil
+ }
+}
+
+// ReferenceDirs pass to Decoder that reference to anchor defined by files under the passed dirs
+func ReferenceDirs(dirs ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.referenceDirs = dirs
+ return nil
+ }
+}
+
+// RecursiveDir search yaml file recursively from passed dirs by ReferenceDirs option
+func RecursiveDir(isRecursive bool) DecodeOption {
+ return func(d *Decoder) error {
+ d.isRecursiveDir = isRecursive
+ return nil
+ }
+}
+
+// Validator set StructValidator instance to Decoder
+func Validator(v StructValidator) DecodeOption {
+ return func(d *Decoder) error {
+ d.validator = v
+ return nil
+ }
+}
+
+// Strict enable DisallowUnknownField
+func Strict() DecodeOption {
+ return func(d *Decoder) error {
+ d.disallowUnknownField = true
+ return nil
+ }
+}
+
+// DisallowUnknownField causes the Decoder to return an error when the destination
+// is a struct and the input contains object keys which do not match any
+// non-ignored, exported fields in the destination.
+func DisallowUnknownField() DecodeOption {
+ return func(d *Decoder) error {
+ d.disallowUnknownField = true
+ return nil
+ }
+}
+
+// AllowFieldPrefixes, when paired with [DisallowUnknownField], allows fields
+// with the specified prefixes to bypass the unknown field check.
+func AllowFieldPrefixes(prefixes ...string) DecodeOption {
+ return func(d *Decoder) error {
+ d.allowedFieldPrefixes = append(d.allowedFieldPrefixes, prefixes...)
+ return nil
+ }
+}
+
+// AllowDuplicateMapKey ignore syntax error when mapping keys that are duplicates.
+func AllowDuplicateMapKey() DecodeOption {
+ return func(d *Decoder) error {
+ d.allowDuplicateMapKey = true
+ return nil
+ }
+}
+
+// UseOrderedMap can be interpreted as a map,
+// and uses MapSlice ( ordered map ) aggressively if there is no type specification
+func UseOrderedMap() DecodeOption {
+ return func(d *Decoder) error {
+ d.useOrderedMap = true
+ return nil
+ }
+}
+
+// UseJSONUnmarshaler if neither `BytesUnmarshaler` nor `InterfaceUnmarshaler` is implemented
+// and `UnmashalJSON([]byte)error` is implemented, convert the argument from `YAML` to `JSON` and then call it.
+func UseJSONUnmarshaler() DecodeOption {
+ return func(d *Decoder) error {
+ d.useJSONUnmarshaler = true
+ return nil
+ }
+}
+
+// CustomUnmarshaler overrides any decoding process for the type specified in generics.
+//
+// NOTE: If RegisterCustomUnmarshaler and CustomUnmarshaler of DecodeOption are specified for the same type,
+// the CustomUnmarshaler specified in DecodeOption takes precedence.
+func CustomUnmarshaler[T any](unmarshaler func(*T, []byte) error) DecodeOption {
+ return func(d *Decoder) error {
+ var typ *T
+ d.customUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(v.(*T), b)
+ }
+ return nil
+ }
+}
+
+// CustomUnmarshalerContext overrides any decoding process for the type specified in generics.
+// Similar to CustomUnmarshaler, but allows passing a context to the unmarshaler function.
+func CustomUnmarshalerContext[T any](unmarshaler func(context.Context, *T, []byte) error) DecodeOption {
+ return func(d *Decoder) error {
+ var typ *T
+ d.customUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(ctx, v.(*T), b)
+ }
+ return nil
+ }
+}
+
+// EncodeOption functional option type for Encoder
+type EncodeOption func(e *Encoder) error
+
+// Indent change indent number
+func Indent(spaces int) EncodeOption {
+ return func(e *Encoder) error {
+ e.indentNum = spaces
+ return nil
+ }
+}
+
+// IndentSequence causes sequence values to be indented the same value as Indent
+func IndentSequence(indent bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.indentSequence = indent
+ return nil
+ }
+}
+
+// UseSingleQuote determines if single or double quotes should be preferred for strings.
+func UseSingleQuote(sq bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.singleQuote = sq
+ return nil
+ }
+}
+
+// Flow encoding by flow style
+func Flow(isFlowStyle bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.isFlowStyle = isFlowStyle
+ return nil
+ }
+}
+
+// WithSmartAnchor when multiple map values share the same pointer,
+// an anchor is automatically assigned to the first occurrence, and aliases are used for subsequent elements.
+// The map key name is used as the anchor name by default.
+// If key names conflict, a suffix is automatically added to avoid collisions.
+// This is an experimental feature and cannot be used simultaneously with anchor tags.
+func WithSmartAnchor() EncodeOption {
+ return func(e *Encoder) error {
+ e.enableSmartAnchor = true
+ return nil
+ }
+}
+
+// UseLiteralStyleIfMultiline causes encoding multiline strings with a literal syntax,
+// no matter what characters they include
+func UseLiteralStyleIfMultiline(useLiteralStyleIfMultiline bool) EncodeOption {
+ return func(e *Encoder) error {
+ e.useLiteralStyleIfMultiline = useLiteralStyleIfMultiline
+ return nil
+ }
+}
+
+// JSON encode in JSON format
+func JSON() EncodeOption {
+ return func(e *Encoder) error {
+ e.isJSONStyle = true
+ e.isFlowStyle = true
+ return nil
+ }
+}
+
+// MarshalAnchor call back if encoder find an anchor during encoding
+func MarshalAnchor(callback func(*ast.AnchorNode, interface{}) error) EncodeOption {
+ return func(e *Encoder) error {
+ e.anchorCallback = callback
+ return nil
+ }
+}
+
+// UseJSONMarshaler if neither `BytesMarshaler` nor `InterfaceMarshaler`
+// nor `encoding.TextMarshaler` is implemented and `MarshalJSON()([]byte, error)` is implemented,
+// call `MarshalJSON` to convert the returned `JSON` to `YAML` for processing.
+func UseJSONMarshaler() EncodeOption {
+ return func(e *Encoder) error {
+ e.useJSONMarshaler = true
+ return nil
+ }
+}
+
+// CustomMarshaler overrides any encoding process for the type specified in generics.
+//
+// NOTE: If type T implements MarshalYAML for pointer receiver, the type specified in CustomMarshaler must be *T.
+// If RegisterCustomMarshaler and CustomMarshaler of EncodeOption are specified for the same type,
+// the CustomMarshaler specified in EncodeOption takes precedence.
+func CustomMarshaler[T any](marshaler func(T) ([]byte, error)) EncodeOption {
+ return func(e *Encoder) error {
+ var typ T
+ e.customMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(v.(T))
+ }
+ return nil
+ }
+}
+
+// CustomMarshalerContext overrides any encoding process for the type specified in generics.
+// Similar to CustomMarshaler, but allows passing a context to the marshaler function.
+func CustomMarshalerContext[T any](marshaler func(context.Context, T) ([]byte, error)) EncodeOption {
+ return func(e *Encoder) error {
+ var typ T
+ e.customMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(ctx, v.(T))
+ }
+ return nil
+ }
+}
+
+// AutoInt automatically converts floating-point numbers to integers when the fractional part is zero.
+// For example, a value of 1.0 will be encoded as 1.
+func AutoInt() EncodeOption {
+ return func(e *Encoder) error {
+ e.autoInt = true
+ return nil
+ }
+}
+
+// OmitEmpty behaves in the same way as the interpretation of the omitempty tag in the encoding/json library.
+// set on all the fields.
+// In the current implementation, the omitempty tag is not implemented in the same way as encoding/json,
+// so please specify this option if you expect the same behavior.
+func OmitEmpty() EncodeOption {
+ return func(e *Encoder) error {
+ e.omitEmpty = true
+ return nil
+ }
+}
+
+// OmitZero forces the encoder to assume an `omitzero` struct tag is
+// set on all the fields. See `Marshal` commentary for the `omitzero` tag logic.
+func OmitZero() EncodeOption {
+ return func(e *Encoder) error {
+ e.omitZero = true
+ return nil
+ }
+}
+
+// CommentPosition type of the position for comment.
+type CommentPosition int
+
+const (
+ CommentHeadPosition CommentPosition = CommentPosition(iota)
+ CommentLinePosition
+ CommentFootPosition
+)
+
+func (p CommentPosition) String() string {
+ switch p {
+ case CommentHeadPosition:
+ return "Head"
+ case CommentLinePosition:
+ return "Line"
+ case CommentFootPosition:
+ return "Foot"
+ default:
+ return ""
+ }
+}
+
+// LineComment create a one-line comment for CommentMap.
+func LineComment(text string) *Comment {
+ return &Comment{
+ Texts: []string{text},
+ Position: CommentLinePosition,
+ }
+}
+
+// HeadComment create a multiline comment for CommentMap.
+func HeadComment(texts ...string) *Comment {
+ return &Comment{
+ Texts: texts,
+ Position: CommentHeadPosition,
+ }
+}
+
+// FootComment create a multiline comment for CommentMap.
+func FootComment(texts ...string) *Comment {
+ return &Comment{
+ Texts: texts,
+ Position: CommentFootPosition,
+ }
+}
+
+// Comment raw data for comment.
+type Comment struct {
+ Texts []string
+ Position CommentPosition
+}
+
+// CommentMap map of the position of the comment and the comment information.
+type CommentMap map[string][]*Comment
+
+// WithComment add a comment using the location and text information given in the CommentMap.
+func WithComment(cm CommentMap) EncodeOption {
+ return func(e *Encoder) error {
+ commentMap := map[*Path][]*Comment{}
+ for k, v := range cm {
+ path, err := PathString(k)
+ if err != nil {
+ return err
+ }
+ commentMap[path] = v
+ }
+ e.commentMap = commentMap
+ return nil
+ }
+}
+
+// CommentToMap apply the position and content of comments in a YAML document to a CommentMap.
+func CommentToMap(cm CommentMap) DecodeOption {
+ return func(d *Decoder) error {
+ if cm == nil {
+ return ErrInvalidCommentMapValue
+ }
+ d.toCommentMap = cm
+ return nil
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/color.go b/sesh/vendor/github.com/goccy/go-yaml/parser/color.go
new file mode 100644
index 0000000..aeee0dc
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/color.go
@@ -0,0 +1,28 @@
+package parser
+
+import "fmt"
+
+const (
+ colorFgHiBlack int = iota + 90
+ colorFgHiRed
+ colorFgHiGreen
+ colorFgHiYellow
+ colorFgHiBlue
+ colorFgHiMagenta
+ colorFgHiCyan
+)
+
+var colorTable = []int{
+ colorFgHiRed,
+ colorFgHiGreen,
+ colorFgHiYellow,
+ colorFgHiBlue,
+ colorFgHiMagenta,
+ colorFgHiCyan,
+}
+
+func colorize(idx int, content string) string {
+ colorIdx := idx % len(colorTable)
+ color := colorTable[colorIdx]
+ return fmt.Sprintf("\x1b[1;%dm", color) + content + "\x1b[22;0m"
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/context.go b/sesh/vendor/github.com/goccy/go-yaml/parser/context.go
new file mode 100644
index 0000000..1584b3e
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/context.go
@@ -0,0 +1,187 @@
+package parser
+
+import (
+ "fmt"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// context context at parsing
+type context struct {
+ tokenRef *tokenRef
+ path string
+ isFlow bool
+}
+
+type tokenRef struct {
+ tokens []*Token
+ size int
+ idx int
+}
+
+var pathSpecialChars = []string{
+ "$", "*", ".", "[", "]",
+}
+
+func containsPathSpecialChar(path string) bool {
+ for _, char := range pathSpecialChars {
+ if strings.Contains(path, char) {
+ return true
+ }
+ }
+ return false
+}
+
+func normalizePath(path string) string {
+ if containsPathSpecialChar(path) {
+ return fmt.Sprintf("'%s'", path)
+ }
+ return path
+}
+
+func (c *context) currentToken() *Token {
+ if c.tokenRef.idx >= c.tokenRef.size {
+ return nil
+ }
+ return c.tokenRef.tokens[c.tokenRef.idx]
+}
+
+func (c *context) isComment() bool {
+ return c.currentToken().Type() == token.CommentType
+}
+
+func (c *context) nextToken() *Token {
+ if c.tokenRef.idx+1 >= c.tokenRef.size {
+ return nil
+ }
+ return c.tokenRef.tokens[c.tokenRef.idx+1]
+}
+
+func (c *context) nextNotCommentToken() *Token {
+ for i := c.tokenRef.idx + 1; i < c.tokenRef.size; i++ {
+ tk := c.tokenRef.tokens[i]
+ if tk.Type() == token.CommentType {
+ continue
+ }
+ return tk
+ }
+ return nil
+}
+
+func (c *context) isTokenNotFound() bool {
+ return c.currentToken() == nil
+}
+
+func (c *context) withGroup(g *TokenGroup) *context {
+ ctx := *c
+ ctx.tokenRef = &tokenRef{
+ tokens: g.Tokens,
+ size: len(g.Tokens),
+ }
+ return &ctx
+}
+
+func (c *context) withChild(path string) *context {
+ ctx := *c
+ ctx.path = c.path + "." + normalizePath(path)
+ return &ctx
+}
+
+func (c *context) withIndex(idx uint) *context {
+ ctx := *c
+ ctx.path = c.path + "[" + fmt.Sprint(idx) + "]"
+ return &ctx
+}
+
+func (c *context) withFlow(isFlow bool) *context {
+ ctx := *c
+ ctx.isFlow = isFlow
+ return &ctx
+}
+
+func newContext() *context {
+ return &context{
+ path: "$",
+ }
+}
+
+func (c *context) goNext() {
+ ref := c.tokenRef
+ if ref.size <= ref.idx+1 {
+ ref.idx = ref.size
+ } else {
+ ref.idx++
+ }
+}
+
+func (c *context) next() bool {
+ return c.tokenRef.idx < c.tokenRef.size
+}
+
+func (c *context) insertNullToken(tk *Token) *Token {
+ nullToken := c.createImplicitNullToken(tk)
+ c.insertToken(nullToken)
+ c.goNext()
+
+ return nullToken
+}
+
+func (c *context) addNullValueToken(tk *Token) *Token {
+ nullToken := c.createImplicitNullToken(tk)
+ rawTk := nullToken.RawToken()
+
+ // add space for map or sequence value.
+ rawTk.Position.Column++
+
+ c.addToken(nullToken)
+ c.goNext()
+
+ return nullToken
+}
+
+func (c *context) createImplicitNullToken(base *Token) *Token {
+ pos := *(base.RawToken().Position)
+ pos.Column++
+ tk := token.New("null", " null", &pos)
+ tk.Type = token.ImplicitNullType
+ return &Token{Token: tk}
+}
+
+func (c *context) insertToken(tk *Token) {
+ ref := c.tokenRef
+ idx := ref.idx
+ if ref.size < idx {
+ return
+ }
+ if ref.size == idx {
+ curToken := ref.tokens[ref.size-1]
+ tk.RawToken().Next = curToken.RawToken()
+ curToken.RawToken().Prev = tk.RawToken()
+
+ ref.tokens = append(ref.tokens, tk)
+ ref.size = len(ref.tokens)
+ return
+ }
+
+ curToken := ref.tokens[idx]
+ tk.RawToken().Next = curToken.RawToken()
+ curToken.RawToken().Prev = tk.RawToken()
+
+ ref.tokens = append(ref.tokens[:idx+1], ref.tokens[idx:]...)
+ ref.tokens[idx] = tk
+ ref.size = len(ref.tokens)
+}
+
+func (c *context) addToken(tk *Token) {
+ ref := c.tokenRef
+ lastTk := ref.tokens[ref.size-1]
+ if lastTk.Group != nil {
+ lastTk = lastTk.Group.Last()
+ }
+ lastTk.RawToken().Next = tk.RawToken()
+ tk.RawToken().Prev = lastTk.RawToken()
+
+ ref.tokens = append(ref.tokens, tk)
+ ref.size = len(ref.tokens)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/node.go b/sesh/vendor/github.com/goccy/go-yaml/parser/node.go
new file mode 100644
index 0000000..8d35554
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/node.go
@@ -0,0 +1,257 @@
+package parser
+
+import (
+ "fmt"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/token"
+)
+
+func newMappingNode(ctx *context, tk *Token, isFlow bool, values ...*ast.MappingValueNode) (*ast.MappingNode, error) {
+ node := ast.Mapping(tk.RawToken(), isFlow, values...)
+ node.SetPath(ctx.path)
+ return node, nil
+}
+
+func newMappingValueNode(ctx *context, colonTk, entryTk *Token, key ast.MapKeyNode, value ast.Node) (*ast.MappingValueNode, error) {
+ node := ast.MappingValue(colonTk.RawToken(), key, value)
+ node.SetPath(ctx.path)
+ node.CollectEntry = entryTk.RawToken()
+ if key.GetToken().Position.Line == value.GetToken().Position.Line {
+ // originally key was commented, but now that null value has been added, value must be commented.
+ if err := setLineComment(ctx, value, colonTk); err != nil {
+ return nil, err
+ }
+ // set line comment by colonTk or entryTk.
+ if err := setLineComment(ctx, value, entryTk); err != nil {
+ return nil, err
+ }
+ } else {
+ if err := setLineComment(ctx, key, colonTk); err != nil {
+ return nil, err
+ }
+ // set line comment by colonTk or entryTk.
+ if err := setLineComment(ctx, key, entryTk); err != nil {
+ return nil, err
+ }
+ }
+ return node, nil
+}
+
+func newMappingKeyNode(ctx *context, tk *Token) (*ast.MappingKeyNode, error) {
+ node := ast.MappingKey(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newAnchorNode(ctx *context, tk *Token) (*ast.AnchorNode, error) {
+ node := ast.Anchor(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newAliasNode(ctx *context, tk *Token) (*ast.AliasNode, error) {
+ node := ast.Alias(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newDirectiveNode(ctx *context, tk *Token) (*ast.DirectiveNode, error) {
+ node := ast.Directive(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newMergeKeyNode(ctx *context, tk *Token) (*ast.MergeKeyNode, error) {
+ node := ast.MergeKey(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newNullNode(ctx *context, tk *Token) (*ast.NullNode, error) {
+ node := ast.Null(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newBoolNode(ctx *context, tk *Token) (*ast.BoolNode, error) {
+ node := ast.Bool(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newIntegerNode(ctx *context, tk *Token) (*ast.IntegerNode, error) {
+ node := ast.Integer(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newFloatNode(ctx *context, tk *Token) (*ast.FloatNode, error) {
+ node := ast.Float(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newInfinityNode(ctx *context, tk *Token) (*ast.InfinityNode, error) {
+ node := ast.Infinity(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newNanNode(ctx *context, tk *Token) (*ast.NanNode, error) {
+ node := ast.Nan(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newStringNode(ctx *context, tk *Token) (*ast.StringNode, error) {
+ node := ast.String(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newLiteralNode(ctx *context, tk *Token) (*ast.LiteralNode, error) {
+ node := ast.Literal(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newTagNode(ctx *context, tk *Token) (*ast.TagNode, error) {
+ node := ast.Tag(tk.RawToken())
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newSequenceNode(ctx *context, tk *Token, isFlow bool) (*ast.SequenceNode, error) {
+ node := ast.Sequence(tk.RawToken(), isFlow)
+ node.SetPath(ctx.path)
+ if err := setLineComment(ctx, node, tk); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func newTagDefaultScalarValueNode(ctx *context, tag *token.Token) (ast.ScalarNode, error) {
+ pos := *(tag.Position)
+ pos.Column++
+
+ var (
+ tk *Token
+ node ast.ScalarNode
+ )
+ switch token.ReservedTagKeyword(tag.Value) {
+ case token.IntegerTag:
+ tk = &Token{Token: token.New("0", "0", &pos)}
+ n, err := newIntegerNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.FloatTag:
+ tk = &Token{Token: token.New("0", "0", &pos)}
+ n, err := newFloatNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.StringTag, token.BinaryTag, token.TimestampTag:
+ tk = &Token{Token: token.New("", "", &pos)}
+ n, err := newStringNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.BooleanTag:
+ tk = &Token{Token: token.New("false", "false", &pos)}
+ n, err := newBoolNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ case token.NullTag:
+ tk = &Token{Token: token.New("null", "null", &pos)}
+ n, err := newNullNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ node = n
+ default:
+ return nil, errors.ErrSyntax(fmt.Sprintf("cannot assign default value for %q tag", tag.Value), tag)
+ }
+ ctx.insertToken(tk)
+ ctx.goNext()
+ return node, nil
+}
+
+func setLineComment(ctx *context, node ast.Node, tk *Token) error {
+ if tk == nil || tk.LineComment == nil {
+ return nil
+ }
+ comment := ast.CommentGroup([]*token.Token{tk.LineComment})
+ comment.SetPath(ctx.path)
+ if err := node.SetComment(comment); err != nil {
+ return err
+ }
+ return nil
+}
+
+func setHeadComment(cm *ast.CommentGroupNode, value ast.Node) error {
+ if cm == nil {
+ return nil
+ }
+ switch n := value.(type) {
+ case *ast.MappingNode:
+ if len(n.Values) != 0 && value.GetComment() == nil {
+ cm.SetPath(n.Values[0].GetPath())
+ return n.Values[0].SetComment(cm)
+ }
+ case *ast.MappingValueNode:
+ cm.SetPath(n.GetPath())
+ return n.SetComment(cm)
+ }
+ cm.SetPath(value.GetPath())
+ return value.SetComment(cm)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/option.go b/sesh/vendor/github.com/goccy/go-yaml/parser/option.go
new file mode 100644
index 0000000..3121a64
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/option.go
@@ -0,0 +1,12 @@
+package parser
+
+// Option represents parser's option.
+type Option func(p *parser)
+
+// AllowDuplicateMapKey allow the use of keys with the same name in the same map,
+// but by default, this is not permitted.
+func AllowDuplicateMapKey() Option {
+ return func(p *parser) {
+ p.allowDuplicateMapKey = true
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go b/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go
new file mode 100644
index 0000000..f5bfd1a
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/parser.go
@@ -0,0 +1,1330 @@
+package parser
+
+import (
+ "fmt"
+ "os"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/lexer"
+ "github.com/goccy/go-yaml/token"
+)
+
+type Mode uint
+
+const (
+ ParseComments Mode = 1 << iota // parse comments and add them to AST
+)
+
+// ParseBytes parse from byte slice, and returns ast.File
+func ParseBytes(bytes []byte, mode Mode, opts ...Option) (*ast.File, error) {
+ tokens := lexer.Tokenize(string(bytes))
+ f, err := Parse(tokens, mode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ return f, nil
+}
+
+// Parse parse from token instances, and returns ast.File
+func Parse(tokens token.Tokens, mode Mode, opts ...Option) (*ast.File, error) {
+ if tk := tokens.InvalidToken(); tk != nil {
+ return nil, errors.ErrSyntax(tk.Error, tk)
+ }
+ p, err := newParser(tokens, mode, opts)
+ if err != nil {
+ return nil, err
+ }
+ f, err := p.parse(newContext())
+ if err != nil {
+ return nil, err
+ }
+ return f, nil
+}
+
+// Parse parse from filename, and returns ast.File
+func ParseFile(filename string, mode Mode, opts ...Option) (*ast.File, error) {
+ file, err := os.ReadFile(filename)
+ if err != nil {
+ return nil, err
+ }
+ f, err := ParseBytes(file, mode, opts...)
+ if err != nil {
+ return nil, err
+ }
+ f.Name = filename
+ return f, nil
+}
+
+type YAMLVersion string
+
+const (
+ YAML10 YAMLVersion = "1.0"
+ YAML11 YAMLVersion = "1.1"
+ YAML12 YAMLVersion = "1.2"
+ YAML13 YAMLVersion = "1.3"
+)
+
+var yamlVersionMap = map[string]YAMLVersion{
+ "1.0": YAML10,
+ "1.1": YAML11,
+ "1.2": YAML12,
+ "1.3": YAML13,
+}
+
+type parser struct {
+ tokens []*Token
+ pathMap map[string]ast.Node
+ yamlVersion YAMLVersion
+ allowDuplicateMapKey bool
+ secondaryTagDirective *ast.DirectiveNode
+}
+
+func newParser(tokens token.Tokens, mode Mode, opts []Option) (*parser, error) {
+ filteredTokens := []*token.Token{}
+ if mode&ParseComments != 0 {
+ filteredTokens = tokens
+ } else {
+ for _, tk := range tokens {
+ if tk.Type == token.CommentType {
+ continue
+ }
+ // keep prev/next reference between tokens containing comments
+ // https://github.com/goccy/go-yaml/issues/254
+ filteredTokens = append(filteredTokens, tk)
+ }
+ }
+ tks, err := CreateGroupedTokens(token.Tokens(filteredTokens))
+ if err != nil {
+ return nil, err
+ }
+ p := &parser{
+ tokens: tks,
+ pathMap: make(map[string]ast.Node),
+ }
+ for _, opt := range opts {
+ opt(p)
+ }
+ return p, nil
+}
+
+func (p *parser) parse(ctx *context) (*ast.File, error) {
+ file := &ast.File{Docs: []*ast.DocumentNode{}}
+ for _, token := range p.tokens {
+ doc, err := p.parseDocument(ctx, token.Group)
+ if err != nil {
+ return nil, err
+ }
+ file.Docs = append(file.Docs, doc)
+ }
+ return file, nil
+}
+
+func (p *parser) parseDocument(ctx *context, docGroup *TokenGroup) (*ast.DocumentNode, error) {
+ if len(docGroup.Tokens) == 0 {
+ return ast.Document(docGroup.RawToken(), nil), nil
+ }
+
+ p.pathMap = make(map[string]ast.Node)
+
+ var (
+ tokens = docGroup.Tokens
+ start *token.Token
+ end *token.Token
+ )
+ if docGroup.First().Type() == token.DocumentHeaderType {
+ start = docGroup.First().RawToken()
+ tokens = tokens[1:]
+ }
+ if docGroup.Last().Type() == token.DocumentEndType {
+ end = docGroup.Last().RawToken()
+ tokens = tokens[:len(tokens)-1]
+ defer func() {
+ // clear yaml version value if DocumentEnd token (...) is specified.
+ p.yamlVersion = ""
+ }()
+ }
+
+ if len(tokens) == 0 {
+ return ast.Document(docGroup.RawToken(), nil), nil
+ }
+
+ body, err := p.parseDocumentBody(ctx.withGroup(&TokenGroup{
+ Type: TokenGroupDocumentBody,
+ Tokens: tokens,
+ }))
+ if err != nil {
+ return nil, err
+ }
+ node := ast.Document(start, body)
+ node.End = end
+ return node, nil
+}
+
+func (p *parser) parseDocumentBody(ctx *context) (ast.Node, error) {
+ node, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if ctx.next() {
+ return nil, errors.ErrSyntax("value is not allowed in this context", ctx.currentToken().RawToken())
+ }
+ return node, nil
+}
+
+func (p *parser) parseToken(ctx *context, tk *Token) (ast.Node, error) {
+ switch tk.GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return p.parseMap(ctx)
+ case TokenGroupDirective:
+ node, err := p.parseDirective(ctx.withGroup(tk.Group), tk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupDirectiveName:
+ node, err := p.parseDirectiveName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupAnchor:
+ node, err := p.parseAnchor(ctx.withGroup(tk.Group), tk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupAnchorName:
+ anchor, err := p.parseAnchorName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", tk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+ case TokenGroupAlias:
+ node, err := p.parseAlias(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupLiteral, TokenGroupFolded:
+ node, err := p.parseLiteral(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ case TokenGroupScalarTag:
+ node, err := p.parseTag(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+ }
+ switch tk.Type() {
+ case token.CommentType:
+ return p.parseComment(ctx)
+ case token.TagType:
+ return p.parseTag(ctx)
+ case token.MappingStartType:
+ return p.parseFlowMap(ctx.withFlow(true))
+ case token.SequenceStartType:
+ return p.parseFlowSequence(ctx.withFlow(true))
+ case token.SequenceEntryType:
+ return p.parseSequence(ctx)
+ case token.SequenceEndType:
+ // SequenceEndType is always validated in parseFlowSequence.
+ // Therefore, if this is found in other cases, it is treated as a syntax error.
+ return nil, errors.ErrSyntax("could not find '[' character corresponding to ']'", tk.RawToken())
+ case token.MappingEndType:
+ // MappingEndType is always validated in parseFlowMap.
+ // Therefore, if this is found in other cases, it is treated as a syntax error.
+ return nil, errors.ErrSyntax("could not find '{' character corresponding to '}'", tk.RawToken())
+ case token.MappingValueType:
+ return nil, errors.ErrSyntax("found an invalid key for this map", tk.RawToken())
+ }
+ node, err := p.parseScalarValue(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return node, nil
+}
+
+func (p *parser) parseScalarValue(ctx *context, tk *Token) (ast.ScalarNode, error) {
+ if tk.Group != nil {
+ switch tk.GroupType() {
+ case TokenGroupAnchor:
+ return p.parseAnchor(ctx.withGroup(tk.Group), tk.Group)
+ case TokenGroupAnchorName:
+ anchor, err := p.parseAnchorName(ctx.withGroup(tk.Group))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", tk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+ case TokenGroupAlias:
+ return p.parseAlias(ctx.withGroup(tk.Group))
+ case TokenGroupLiteral, TokenGroupFolded:
+ return p.parseLiteral(ctx.withGroup(tk.Group))
+ case TokenGroupScalarTag:
+ return p.parseTag(ctx.withGroup(tk.Group))
+ default:
+ return nil, errors.ErrSyntax("unexpected scalar value", tk.RawToken())
+ }
+ }
+ switch tk.Type() {
+ case token.MergeKeyType:
+ return newMergeKeyNode(ctx, tk)
+ case token.NullType, token.ImplicitNullType:
+ return newNullNode(ctx, tk)
+ case token.BoolType:
+ return newBoolNode(ctx, tk)
+ case token.IntegerType, token.BinaryIntegerType, token.OctetIntegerType, token.HexIntegerType:
+ return newIntegerNode(ctx, tk)
+ case token.FloatType:
+ return newFloatNode(ctx, tk)
+ case token.InfinityType:
+ return newInfinityNode(ctx, tk)
+ case token.NanType:
+ return newNanNode(ctx, tk)
+ case token.StringType, token.SingleQuoteType, token.DoubleQuoteType:
+ return newStringNode(ctx, tk)
+ case token.TagType:
+ // this case applies when it is a scalar tag and its value does not exist.
+ // Examples of cases where the value does not exist include cases like `key: !!str,` or `!!str : value`.
+ return p.parseScalarTag(ctx)
+ }
+ return nil, errors.ErrSyntax("unexpected scalar value type", tk.RawToken())
+}
+
+func (p *parser) parseFlowMap(ctx *context) (*ast.MappingNode, error) {
+ node, err := newMappingNode(ctx, ctx.currentToken(), true)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip MappingStart token
+
+ isFirst := true
+ for ctx.next() {
+ tk := ctx.currentToken()
+ if tk.Type() == token.MappingEndType {
+ node.End = tk.RawToken()
+ break
+ }
+
+ var entryTk *Token
+ if tk.Type() == token.CollectEntryType {
+ entryTk = tk
+ ctx.goNext()
+ } else if !isFirst {
+ return nil, errors.ErrSyntax("',' or '}' must be specified", tk.RawToken())
+ }
+
+ if tk := ctx.currentToken(); tk.Type() == token.MappingEndType {
+ // this case is here: "{ elem, }".
+ // In this case, ignore the last element and break mapping parsing.
+ node.End = tk.RawToken()
+ break
+ }
+
+ mapKeyTk := ctx.currentToken()
+ switch mapKeyTk.GroupType() {
+ case TokenGroupMapKeyValue:
+ value, err := p.parseMapKeyValue(ctx.withGroup(mapKeyTk.Group), mapKeyTk.Group, entryTk)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, value)
+ ctx.goNext()
+ case TokenGroupMapKey:
+ key, err := p.parseMapKey(ctx.withGroup(mapKeyTk.Group), mapKeyTk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx := ctx.withChild(p.mapKeyText(key))
+ colonTk := mapKeyTk.Group.Last()
+ if p.isFlowMapDelim(ctx.nextToken()) {
+ value, err := newNullNode(ctx, ctx.insertNullToken(colonTk))
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, colonTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ ctx.goNext()
+ } else {
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find map value", colonTk.RawToken())
+ }
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, colonTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ }
+ default:
+ if !p.isFlowMapDelim(ctx.nextToken()) {
+ errTk := mapKeyTk
+ if errTk == nil {
+ errTk = tk
+ }
+ return nil, errors.ErrSyntax("could not find flow map content", errTk.RawToken())
+ }
+ key, err := p.parseScalarValue(ctx, mapKeyTk)
+ if err != nil {
+ return nil, err
+ }
+ value, err := newNullNode(ctx, ctx.insertNullToken(mapKeyTk))
+ if err != nil {
+ return nil, err
+ }
+ mapValue, err := newMappingValueNode(ctx, mapKeyTk, entryTk, key, value)
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, mapValue)
+ ctx.goNext()
+ }
+ isFirst = false
+ }
+ if node.End == nil {
+ return nil, errors.ErrSyntax("could not find flow mapping end token '}'", node.Start)
+ }
+
+ // set line comment if exists. e.g.) } # comment
+ if err := setLineComment(ctx, node, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip mapping end token.
+ return node, nil
+}
+
+func (p *parser) isFlowMapDelim(tk *Token) bool {
+ return tk.Type() == token.MappingEndType || tk.Type() == token.CollectEntryType
+}
+
+func (p *parser) parseMap(ctx *context) (*ast.MappingNode, error) {
+ keyTk := ctx.currentToken()
+ if keyTk.Group == nil {
+ return nil, errors.ErrSyntax("unexpected map key", keyTk.RawToken())
+ }
+ var keyValueNode *ast.MappingValueNode
+ if keyTk.GroupType() == TokenGroupMapKeyValue {
+ node, err := p.parseMapKeyValue(ctx.withGroup(keyTk.Group), keyTk.Group, nil)
+ if err != nil {
+ return nil, err
+ }
+ keyValueNode = node
+ ctx.goNext()
+ if err := p.validateMapKeyValueNextToken(ctx, keyTk, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ } else {
+ key, err := p.parseMapKey(ctx.withGroup(keyTk.Group), keyTk.Group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+
+ valueTk := ctx.currentToken()
+ if keyTk.Line() == valueTk.Line() && valueTk.Type() == token.SequenceEntryType {
+ return nil, errors.ErrSyntax("block sequence entries are not allowed in this context", valueTk.RawToken())
+ }
+ ctx := ctx.withChild(p.mapKeyText(key))
+ value, err := p.parseMapValue(ctx, key, keyTk.Group.Last())
+ if err != nil {
+ return nil, err
+ }
+ node, err := newMappingValueNode(ctx, keyTk.Group.Last(), nil, key, value)
+ if err != nil {
+ return nil, err
+ }
+ keyValueNode = node
+ }
+ mapNode, err := newMappingNode(ctx, &Token{Token: keyValueNode.GetToken()}, false, keyValueNode)
+ if err != nil {
+ return nil, err
+ }
+ var tk *Token
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ } else {
+ tk = ctx.currentToken()
+ }
+ for tk.Column() == keyTk.Column() {
+ typ := tk.Type()
+ if ctx.isFlow && typ == token.SequenceEndType {
+ // [
+ // key: value
+ // ] <=
+ break
+ }
+ if !p.isMapToken(tk) {
+ return nil, errors.ErrSyntax("non-map value is specified", tk.RawToken())
+ }
+ cm := p.parseHeadComment(ctx)
+ if typ == token.MappingEndType {
+ // a: {
+ // b: c
+ // } <=
+ ctx.goNext()
+ break
+ }
+ node, err := p.parseMap(ctx)
+ if err != nil {
+ return nil, err
+ }
+ if len(node.Values) != 0 {
+ if err := setHeadComment(cm, node.Values[0]); err != nil {
+ return nil, err
+ }
+ }
+ mapNode.Values = append(mapNode.Values, node.Values...)
+ if node.FootComment != nil {
+ mapNode.Values[len(mapNode.Values)-1].FootComment = node.FootComment
+ }
+ tk = ctx.currentToken()
+ }
+ if ctx.isComment() {
+ if keyTk.Column() <= ctx.currentToken().Column() {
+ // If the comment is in the same or deeper column as the last element column in map value,
+ // treat it as a footer comment for the last element.
+ if len(mapNode.Values) == 1 {
+ mapNode.Values[0].FootComment = p.parseFootComment(ctx, keyTk.Column())
+ mapNode.Values[0].FootComment.SetPath(mapNode.Values[0].Key.GetPath())
+ } else {
+ mapNode.FootComment = p.parseFootComment(ctx, keyTk.Column())
+ mapNode.FootComment.SetPath(mapNode.GetPath())
+ }
+ }
+ }
+ return mapNode, nil
+}
+
+func (p *parser) validateMapKeyValueNextToken(ctx *context, keyTk, tk *Token) error {
+ if tk == nil {
+ return nil
+ }
+ if tk.Column() <= keyTk.Column() {
+ return nil
+ }
+ if ctx.isComment() {
+ return nil
+ }
+ if ctx.isFlow && (tk.Type() == token.CollectEntryType || tk.Type() == token.SequenceEndType) {
+ return nil
+ }
+ // a: b
+ // c <= this token is invalid.
+ return errors.ErrSyntax("value is not allowed in this context. map key-value is pre-defined", tk.RawToken())
+}
+
+func (p *parser) isMapToken(tk *Token) bool {
+ if tk.Group == nil {
+ return tk.Type() == token.MappingStartType || tk.Type() == token.MappingEndType
+ }
+ g := tk.Group
+ return g.Type == TokenGroupMapKey || g.Type == TokenGroupMapKeyValue
+}
+
+func (p *parser) parseMapKeyValue(ctx *context, g *TokenGroup, entryTk *Token) (*ast.MappingValueNode, error) {
+ if g.Type != TokenGroupMapKeyValue {
+ return nil, errors.ErrSyntax("unexpected map key-value pair", g.RawToken())
+ }
+ if g.First().Group == nil {
+ return nil, errors.ErrSyntax("unexpected map key", g.RawToken())
+ }
+ keyGroup := g.First().Group
+ key, err := p.parseMapKey(ctx.withGroup(keyGroup), keyGroup)
+ if err != nil {
+ return nil, err
+ }
+
+ c := ctx.withChild(p.mapKeyText(key))
+ value, err := p.parseToken(c, g.Last())
+ if err != nil {
+ return nil, err
+ }
+ return newMappingValueNode(c, keyGroup.Last(), entryTk, key, value)
+}
+
+func (p *parser) parseMapKey(ctx *context, g *TokenGroup) (ast.MapKeyNode, error) {
+ if g.Type != TokenGroupMapKey {
+ return nil, errors.ErrSyntax("unexpected map key", g.RawToken())
+ }
+ if g.First().Type() == token.MappingKeyType {
+ mapKeyTk := g.First()
+ if mapKeyTk.Group != nil {
+ ctx = ctx.withGroup(mapKeyTk.Group)
+ }
+ key, err := newMappingKeyNode(ctx, mapKeyTk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip mapping key token
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find value for mapping key", mapKeyTk.RawToken())
+ }
+
+ scalar, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ key.Value = scalar
+ keyText := p.mapKeyText(scalar)
+ keyPath := ctx.withChild(keyText).path
+ key.SetPath(keyPath)
+ if err := p.validateMapKey(ctx, key.GetToken(), keyPath, g.Last()); err != nil {
+ return nil, err
+ }
+ p.pathMap[keyPath] = key
+ return key, nil
+ }
+ if g.Last().Type() != token.MappingValueType {
+ return nil, errors.ErrSyntax("expected map key-value delimiter ':'", g.Last().RawToken())
+ }
+
+ scalar, err := p.parseScalarValue(ctx, g.First())
+ if err != nil {
+ return nil, err
+ }
+ key, ok := scalar.(ast.MapKeyNode)
+ if !ok {
+ return nil, errors.ErrSyntax("cannot take map-key node", scalar.GetToken())
+ }
+ keyText := p.mapKeyText(key)
+ keyPath := ctx.withChild(keyText).path
+ key.SetPath(keyPath)
+ if err := p.validateMapKey(ctx, key.GetToken(), keyPath, g.Last()); err != nil {
+ return nil, err
+ }
+ p.pathMap[keyPath] = key
+ return key, nil
+}
+
+func (p *parser) validateMapKey(ctx *context, tk *token.Token, keyPath string, colonTk *Token) error {
+ if !p.allowDuplicateMapKey {
+ if n, exists := p.pathMap[keyPath]; exists {
+ pos := n.GetToken().Position
+ return errors.ErrSyntax(
+ fmt.Sprintf("mapping key %q already defined at [%d:%d]", tk.Value, pos.Line, pos.Column),
+ tk,
+ )
+ }
+ }
+ origin := p.removeLeftWhiteSpace(tk.Origin)
+ if ctx.isFlow {
+ if tk.Type == token.StringType {
+ origin = p.removeRightWhiteSpace(origin)
+ if tk.Position.Line+p.newLineCharacterNum(origin) != colonTk.Line() {
+ return errors.ErrSyntax("map key definition includes an implicit line break", tk)
+ }
+ }
+ return nil
+ }
+ if tk.Type != token.StringType && tk.Type != token.SingleQuoteType && tk.Type != token.DoubleQuoteType {
+ return nil
+ }
+ if p.existsNewLineCharacter(origin) {
+ return errors.ErrSyntax("unexpected key name", tk)
+ }
+ return nil
+}
+
+func (p *parser) removeLeftWhiteSpace(src string) string {
+ // CR or LF or CRLF
+ return strings.TrimLeftFunc(src, func(r rune) bool {
+ return r == ' ' || r == '\r' || r == '\n'
+ })
+}
+
+func (p *parser) removeRightWhiteSpace(src string) string {
+ // CR or LF or CRLF
+ return strings.TrimRightFunc(src, func(r rune) bool {
+ return r == ' ' || r == '\r' || r == '\n'
+ })
+}
+
+func (p *parser) existsNewLineCharacter(src string) bool {
+ return p.newLineCharacterNum(src) > 0
+}
+
+func (p *parser) newLineCharacterNum(src string) int {
+ var num int
+ for i := 0; i < len(src); i++ {
+ switch src[i] {
+ case '\r':
+ if len(src) > i+1 && src[i+1] == '\n' {
+ i++
+ }
+ num++
+ case '\n':
+ num++
+ }
+ }
+ return num
+}
+
+func (p *parser) mapKeyText(n ast.Node) string {
+ if n == nil {
+ return ""
+ }
+ switch nn := n.(type) {
+ case *ast.MappingKeyNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.TagNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.AnchorNode:
+ return p.mapKeyText(nn.Value)
+ case *ast.AliasNode:
+ return ""
+ }
+ return n.GetToken().Value
+}
+
+func (p *parser) parseMapValue(ctx *context, key ast.MapKeyNode, colonTk *Token) (ast.Node, error) {
+ tk := ctx.currentToken()
+ if tk == nil {
+ return newNullNode(ctx, ctx.addNullValueToken(colonTk))
+ }
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ }
+ keyCol := key.GetToken().Position.Column
+ keyLine := key.GetToken().Position.Line
+
+ if tk.Column() != keyCol && tk.Line() == keyLine && (tk.GroupType() == TokenGroupMapKey || tk.GroupType() == TokenGroupMapKeyValue) {
+ // a: b:
+ // ^
+ //
+ // a: b: c
+ // ^
+ return nil, errors.ErrSyntax("mapping value is not allowed in this context", tk.RawToken())
+ }
+
+ if tk.Column() == keyCol && p.isMapToken(tk) {
+ // in this case,
+ // ----
+ // key:
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(colonTk))
+ }
+
+ if tk.Line() == keyLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() == keyCol && p.isMapToken(ctx.nextToken()) {
+ // in this case,
+ // ----
+ // key: &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ if tk.Column() <= keyCol && tk.GroupType() == TokenGroupAnchorName {
+ // key:
+ // &anchor
+ return nil, errors.ErrSyntax("anchor is not allowed in this context", tk.RawToken())
+ }
+ if tk.Column() <= keyCol && tk.Type() == token.TagType {
+ // key:
+ // !!tag
+ return nil, errors.ErrSyntax("tag is not allowed in this context", tk.RawToken())
+ }
+
+ if tk.Column() < keyCol {
+ // in this case,
+ // ----
+ // key:
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(colonTk))
+ }
+
+ if tk.Line() == keyLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() < keyCol {
+ // in this case,
+ // ----
+ // key: &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := p.validateAnchorValueInMapOrSeq(value, keyCol); err != nil {
+ return nil, err
+ }
+ return value, nil
+}
+
+func (p *parser) validateAnchorValueInMapOrSeq(value ast.Node, col int) error {
+ anchor, ok := value.(*ast.AnchorNode)
+ if !ok {
+ return nil
+ }
+ tag, ok := anchor.Value.(*ast.TagNode)
+ if !ok {
+ return nil
+ }
+ anchorTk := anchor.GetToken()
+ tagTk := tag.GetToken()
+
+ if anchorTk.Position.Line == tagTk.Position.Line {
+ // key:
+ // &anchor !!tag
+ //
+ // - &anchor !!tag
+ return nil
+ }
+
+ if tagTk.Position.Column <= col {
+ // key: &anchor
+ // !!tag
+ //
+ // - &anchor
+ // !!tag
+ return errors.ErrSyntax("tag is not allowed in this context", tagTk)
+ }
+ return nil
+}
+
+func (p *parser) parseAnchor(ctx *context, g *TokenGroup) (*ast.AnchorNode, error) {
+ anchorNameGroup := g.First().Group
+ anchor, err := p.parseAnchorName(ctx.withGroup(anchorNameGroup))
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", anchor.GetToken())
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if _, ok := value.(*ast.AnchorNode); ok {
+ return nil, errors.ErrSyntax("anchors cannot be used consecutively", value.GetToken())
+ }
+ anchor.Value = value
+ return anchor, nil
+}
+
+func (p *parser) parseAnchorName(ctx *context) (*ast.AnchorNode, error) {
+ anchor, err := newAnchorNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find anchor value", anchor.GetToken())
+ }
+
+ anchorName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if anchorName == nil {
+ return nil, errors.ErrSyntax("unexpected anchor. anchor name is not scalar value", ctx.currentToken().RawToken())
+ }
+ anchor.Name = anchorName
+ return anchor, nil
+}
+
+func (p *parser) parseAlias(ctx *context) (*ast.AliasNode, error) {
+ alias, err := newAliasNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find alias value", alias.GetToken())
+ }
+
+ aliasName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if aliasName == nil {
+ return nil, errors.ErrSyntax("unexpected alias. alias name is not scalar value", ctx.currentToken().RawToken())
+ }
+ alias.Value = aliasName
+ return alias, nil
+}
+
+func (p *parser) parseLiteral(ctx *context) (*ast.LiteralNode, error) {
+ node, err := newLiteralNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip literal/folded token
+
+ tk := ctx.currentToken()
+ if tk == nil {
+ value, err := newStringNode(ctx, &Token{Token: token.New("", "", node.Start.Position)})
+ if err != nil {
+ return nil, err
+ }
+ node.Value = value
+ return node, nil
+ }
+ value, err := p.parseToken(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ str, ok := value.(*ast.StringNode)
+ if !ok {
+ return nil, errors.ErrSyntax("unexpected token. required string token", value.GetToken())
+ }
+ node.Value = str
+ return node, nil
+}
+
+func (p *parser) parseScalarTag(ctx *context) (*ast.TagNode, error) {
+ tag, err := p.parseTag(ctx)
+ if err != nil {
+ return nil, err
+ }
+ if tag.Value == nil {
+ return nil, errors.ErrSyntax("specified not scalar tag", tag.GetToken())
+ }
+ if _, ok := tag.Value.(ast.ScalarNode); !ok {
+ return nil, errors.ErrSyntax("specified not scalar tag", tag.GetToken())
+ }
+ return tag, nil
+}
+
+func (p *parser) parseTag(ctx *context) (*ast.TagNode, error) {
+ tagTk := ctx.currentToken()
+ tagRawTk := tagTk.RawToken()
+ node, err := newTagNode(ctx, tagTk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+
+ comment := p.parseHeadComment(ctx)
+
+ var tagValue ast.Node
+ if p.secondaryTagDirective != nil {
+ value, err := newStringNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ tagValue = value
+ node.Directive = p.secondaryTagDirective
+ } else {
+ value, err := p.parseTagValue(ctx, tagRawTk, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ tagValue = value
+ }
+ if err := setHeadComment(comment, tagValue); err != nil {
+ return nil, err
+ }
+ node.Value = tagValue
+ return node, nil
+}
+
+func (p *parser) parseTagValue(ctx *context, tagRawTk *token.Token, tk *Token) (ast.Node, error) {
+ if tk == nil {
+ return newNullNode(ctx, ctx.createImplicitNullToken(&Token{Token: tagRawTk}))
+ }
+ switch token.ReservedTagKeyword(tagRawTk.Value) {
+ case token.MappingTag, token.SetTag:
+ if !p.isMapToken(tk) {
+ return nil, errors.ErrSyntax("could not find map", tk.RawToken())
+ }
+ if tk.Type() == token.MappingStartType {
+ return p.parseFlowMap(ctx.withFlow(true))
+ }
+ return p.parseMap(ctx)
+ case token.IntegerTag, token.FloatTag, token.StringTag, token.BinaryTag, token.TimestampTag, token.BooleanTag, token.NullTag:
+ if tk.GroupType() == TokenGroupLiteral || tk.GroupType() == TokenGroupFolded {
+ return p.parseLiteral(ctx.withGroup(tk.Group))
+ } else if tk.Type() == token.CollectEntryType || tk.Type() == token.MappingValueType {
+ return newTagDefaultScalarValueNode(ctx, tagRawTk)
+ }
+ scalar, err := p.parseScalarValue(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return scalar, nil
+ case token.SequenceTag, token.OrderedMapTag:
+ if tk.Type() == token.SequenceStartType {
+ return p.parseFlowSequence(ctx.withFlow(true))
+ }
+ return p.parseSequence(ctx)
+ }
+ return p.parseToken(ctx, tk)
+}
+
+func (p *parser) parseFlowSequence(ctx *context) (*ast.SequenceNode, error) {
+ node, err := newSequenceNode(ctx, ctx.currentToken(), true)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip SequenceStart token
+
+ isFirst := true
+ for ctx.next() {
+ tk := ctx.currentToken()
+ if tk.Type() == token.SequenceEndType {
+ node.End = tk.RawToken()
+ break
+ }
+
+ var entryTk *Token
+ if tk.Type() == token.CollectEntryType {
+ if isFirst {
+ return nil, errors.ErrSyntax("expected sequence element, but found ','", tk.RawToken())
+ }
+ entryTk = tk
+ ctx.goNext()
+ } else if !isFirst {
+ return nil, errors.ErrSyntax("',' or ']' must be specified", tk.RawToken())
+ }
+
+ if tk := ctx.currentToken(); tk.Type() == token.SequenceEndType {
+ // this case is here: "[ elem, ]".
+ // In this case, ignore the last element and break sequence parsing.
+ node.End = tk.RawToken()
+ break
+ }
+
+ if ctx.isTokenNotFound() {
+ break
+ }
+
+ ctx := ctx.withIndex(uint(len(node.Values)))
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ node.Values = append(node.Values, value)
+ seqEntry := ast.SequenceEntry(entryTk.RawToken(), value, nil)
+ if err := setLineComment(ctx, seqEntry, entryTk); err != nil {
+ return nil, err
+ }
+ seqEntry.SetPath(ctx.path)
+ node.Entries = append(node.Entries, seqEntry)
+
+ isFirst = false
+ }
+ if node.End == nil {
+ return nil, errors.ErrSyntax("sequence end token ']' not found", node.Start)
+ }
+
+ // set line comment if exists. e.g.) ] # comment
+ if err := setLineComment(ctx, node, ctx.currentToken()); err != nil {
+ return nil, err
+ }
+ ctx.goNext() // skip sequence end token.
+ return node, nil
+}
+
+func (p *parser) parseSequence(ctx *context) (*ast.SequenceNode, error) {
+ seqTk := ctx.currentToken()
+ seqNode, err := newSequenceNode(ctx, seqTk, false)
+ if err != nil {
+ return nil, err
+ }
+
+ tk := seqTk
+ for tk.Type() == token.SequenceEntryType && tk.Column() == seqTk.Column() {
+ seqTk := tk
+ headComment := p.parseHeadComment(ctx)
+ ctx.goNext() // skip sequence entry token
+
+ ctx := ctx.withIndex(uint(len(seqNode.Values)))
+ value, err := p.parseSequenceValue(ctx, seqTk)
+ if err != nil {
+ return nil, err
+ }
+ seqEntry := ast.SequenceEntry(seqTk.RawToken(), value, headComment)
+ if err := setLineComment(ctx, seqEntry, seqTk); err != nil {
+ return nil, err
+ }
+ seqEntry.SetPath(ctx.path)
+ seqNode.ValueHeadComments = append(seqNode.ValueHeadComments, headComment)
+ seqNode.Values = append(seqNode.Values, value)
+ seqNode.Entries = append(seqNode.Entries, seqEntry)
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ } else {
+ tk = ctx.currentToken()
+ }
+ }
+ if ctx.isComment() {
+ if seqTk.Column() <= ctx.currentToken().Column() {
+ // If the comment is in the same or deeper column as the last element column in sequence value,
+ // treat it as a footer comment for the last element.
+ seqNode.FootComment = p.parseFootComment(ctx, seqTk.Column())
+ if len(seqNode.Values) != 0 {
+ seqNode.FootComment.SetPath(seqNode.Values[len(seqNode.Values)-1].GetPath())
+ }
+ }
+ }
+ return seqNode, nil
+}
+
+func (p *parser) parseSequenceValue(ctx *context, seqTk *Token) (ast.Node, error) {
+ tk := ctx.currentToken()
+ if tk == nil {
+ return newNullNode(ctx, ctx.addNullValueToken(seqTk))
+ }
+
+ if ctx.isComment() {
+ tk = ctx.nextNotCommentToken()
+ }
+ seqCol := seqTk.Column()
+ seqLine := seqTk.Line()
+
+ if tk.Column() == seqCol && tk.Type() == token.SequenceEntryType {
+ // in this case,
+ // ----
+ // -
+ // -
+ return newNullNode(ctx, ctx.insertNullToken(seqTk))
+ }
+
+ if tk.Line() == seqLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() == seqCol && ctx.nextToken().Type() == token.SequenceEntryType {
+ // in this case,
+ // ----
+ // - &anchor
+ // -
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ if tk.Column() <= seqCol && tk.GroupType() == TokenGroupAnchorName {
+ // -
+ // &anchor
+ return nil, errors.ErrSyntax("anchor is not allowed in this sequence context", tk.RawToken())
+ }
+ if tk.Column() <= seqCol && tk.Type() == token.TagType {
+ // -
+ // !!tag
+ return nil, errors.ErrSyntax("tag is not allowed in this sequence context", tk.RawToken())
+ }
+
+ if tk.Column() < seqCol {
+ // in this case,
+ // ----
+ // -
+ // next
+ return newNullNode(ctx, ctx.insertNullToken(seqTk))
+ }
+
+ if tk.Line() == seqLine && tk.GroupType() == TokenGroupAnchorName &&
+ ctx.nextToken().Column() < seqCol {
+ // in this case,
+ // ----
+ // - &anchor
+ // next
+ group := &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, ctx.createImplicitNullToken(tk)},
+ }
+ anchor, err := p.parseAnchor(ctx.withGroup(group), group)
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ return anchor, nil
+ }
+
+ value, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := p.validateAnchorValueInMapOrSeq(value, seqCol); err != nil {
+ return nil, err
+ }
+ return value, nil
+}
+
+func (p *parser) parseDirective(ctx *context, g *TokenGroup) (*ast.DirectiveNode, error) {
+ directiveNameGroup := g.First().Group
+ directive, err := p.parseDirectiveName(ctx.withGroup(directiveNameGroup))
+ if err != nil {
+ return nil, err
+ }
+
+ switch directive.Name.String() {
+ case "YAML":
+ if len(g.Tokens) != 2 {
+ return nil, errors.ErrSyntax("unexpected format YAML directive", g.First().RawToken())
+ }
+ valueTk := g.Tokens[1]
+ valueRawTk := valueTk.RawToken()
+ value := valueRawTk.Value
+ ver, exists := yamlVersionMap[value]
+ if !exists {
+ return nil, errors.ErrSyntax(fmt.Sprintf("unknown YAML version %q", value), valueRawTk)
+ }
+ if p.yamlVersion != "" {
+ return nil, errors.ErrSyntax("YAML version has already been specified", valueRawTk)
+ }
+ p.yamlVersion = ver
+ versionNode, err := newStringNode(ctx, valueTk)
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, versionNode)
+ case "TAG":
+ if len(g.Tokens) != 3 {
+ return nil, errors.ErrSyntax("unexpected format TAG directive", g.First().RawToken())
+ }
+ tagKey, err := newStringNode(ctx, g.Tokens[1])
+ if err != nil {
+ return nil, err
+ }
+ if tagKey.Value == "!!" {
+ p.secondaryTagDirective = directive
+ }
+ tagValue, err := newStringNode(ctx, g.Tokens[2])
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, tagKey, tagValue)
+ default:
+ if len(g.Tokens) > 1 {
+ for _, tk := range g.Tokens[1:] {
+ value, err := newStringNode(ctx, tk)
+ if err != nil {
+ return nil, err
+ }
+ directive.Values = append(directive.Values, value)
+ }
+ }
+ }
+ return directive, nil
+}
+
+func (p *parser) parseDirectiveName(ctx *context) (*ast.DirectiveNode, error) {
+ directive, err := newDirectiveNode(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ ctx.goNext()
+ if ctx.isTokenNotFound() {
+ return nil, errors.ErrSyntax("could not find directive value", directive.GetToken())
+ }
+
+ directiveName, err := p.parseScalarValue(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if directiveName == nil {
+ return nil, errors.ErrSyntax("unexpected directive. directive name is not scalar value", ctx.currentToken().RawToken())
+ }
+ directive.Name = directiveName
+ return directive, nil
+}
+
+func (p *parser) parseComment(ctx *context) (ast.Node, error) {
+ cm := p.parseHeadComment(ctx)
+ if ctx.isTokenNotFound() {
+ return cm, nil
+ }
+ node, err := p.parseToken(ctx, ctx.currentToken())
+ if err != nil {
+ return nil, err
+ }
+ if err := setHeadComment(cm, node); err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+func (p *parser) parseHeadComment(ctx *context) *ast.CommentGroupNode {
+ tks := []*token.Token{}
+ for ctx.isComment() {
+ tks = append(tks, ctx.currentToken().RawToken())
+ ctx.goNext()
+ }
+ if len(tks) == 0 {
+ return nil
+ }
+ return ast.CommentGroup(tks)
+}
+
+func (p *parser) parseFootComment(ctx *context, col int) *ast.CommentGroupNode {
+ tks := []*token.Token{}
+ for ctx.isComment() && col <= ctx.currentToken().Column() {
+ tks = append(tks, ctx.currentToken().RawToken())
+ ctx.goNext()
+ }
+ if len(tks) == 0 {
+ return nil
+ }
+ return ast.CommentGroup(tks)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/parser/token.go b/sesh/vendor/github.com/goccy/go-yaml/parser/token.go
new file mode 100644
index 0000000..b07c018
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/parser/token.go
@@ -0,0 +1,746 @@
+package parser
+
+import (
+ "fmt"
+ "os"
+ "strings"
+
+ "github.com/goccy/go-yaml/internal/errors"
+ "github.com/goccy/go-yaml/token"
+)
+
+type TokenGroupType int
+
+const (
+ TokenGroupNone TokenGroupType = iota
+ TokenGroupDirective
+ TokenGroupDirectiveName
+ TokenGroupDocument
+ TokenGroupDocumentBody
+ TokenGroupAnchor
+ TokenGroupAnchorName
+ TokenGroupAlias
+ TokenGroupLiteral
+ TokenGroupFolded
+ TokenGroupScalarTag
+ TokenGroupMapKey
+ TokenGroupMapKeyValue
+)
+
+func (t TokenGroupType) String() string {
+ switch t {
+ case TokenGroupNone:
+ return "none"
+ case TokenGroupDirective:
+ return "directive"
+ case TokenGroupDirectiveName:
+ return "directive_name"
+ case TokenGroupDocument:
+ return "document"
+ case TokenGroupDocumentBody:
+ return "document_body"
+ case TokenGroupAnchor:
+ return "anchor"
+ case TokenGroupAnchorName:
+ return "anchor_name"
+ case TokenGroupAlias:
+ return "alias"
+ case TokenGroupLiteral:
+ return "literal"
+ case TokenGroupFolded:
+ return "folded"
+ case TokenGroupScalarTag:
+ return "scalar_tag"
+ case TokenGroupMapKey:
+ return "map_key"
+ case TokenGroupMapKeyValue:
+ return "map_key_value"
+ }
+ return "none"
+}
+
+type Token struct {
+ Token *token.Token
+ Group *TokenGroup
+ LineComment *token.Token
+}
+
+func (t *Token) RawToken() *token.Token {
+ if t == nil {
+ return nil
+ }
+ if t.Token != nil {
+ return t.Token
+ }
+ return t.Group.RawToken()
+}
+
+func (t *Token) Type() token.Type {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Type
+ }
+ return t.Group.TokenType()
+}
+
+func (t *Token) GroupType() TokenGroupType {
+ if t == nil {
+ return TokenGroupNone
+ }
+ if t.Token != nil {
+ return TokenGroupNone
+ }
+ return t.Group.Type
+}
+
+func (t *Token) Line() int {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Position.Line
+ }
+ return t.Group.Line()
+}
+
+func (t *Token) Column() int {
+ if t == nil {
+ return 0
+ }
+ if t.Token != nil {
+ return t.Token.Position.Column
+ }
+ return t.Group.Column()
+}
+
+func (t *Token) SetGroupType(typ TokenGroupType) {
+ if t.Group == nil {
+ return
+ }
+ t.Group.Type = typ
+}
+
+func (t *Token) Dump() {
+ ctx := new(groupTokenRenderContext)
+ if t.Token != nil {
+ fmt.Fprint(os.Stdout, t.Token.Value)
+ return
+ }
+ t.Group.dump(ctx)
+ fmt.Fprintf(os.Stdout, "\n")
+}
+
+func (t *Token) dump(ctx *groupTokenRenderContext) {
+ if t.Token != nil {
+ fmt.Fprint(os.Stdout, t.Token.Value)
+ return
+ }
+ t.Group.dump(ctx)
+}
+
+type groupTokenRenderContext struct {
+ num int
+}
+
+type TokenGroup struct {
+ Type TokenGroupType
+ Tokens []*Token
+}
+
+func (g *TokenGroup) First() *Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[0]
+}
+
+func (g *TokenGroup) Last() *Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[len(g.Tokens)-1]
+}
+
+func (g *TokenGroup) dump(ctx *groupTokenRenderContext) {
+ num := ctx.num
+ fmt.Fprint(os.Stdout, colorize(num, "("))
+ ctx.num++
+ for _, tk := range g.Tokens {
+ tk.dump(ctx)
+ }
+ fmt.Fprint(os.Stdout, colorize(num, ")"))
+}
+
+func (g *TokenGroup) RawToken() *token.Token {
+ if len(g.Tokens) == 0 {
+ return nil
+ }
+ return g.Tokens[0].RawToken()
+}
+
+func (g *TokenGroup) Line() int {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Line()
+}
+
+func (g *TokenGroup) Column() int {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Column()
+}
+
+func (g *TokenGroup) TokenType() token.Type {
+ if len(g.Tokens) == 0 {
+ return 0
+ }
+ return g.Tokens[0].Type()
+}
+
+func CreateGroupedTokens(tokens token.Tokens) ([]*Token, error) {
+ var err error
+ tks := newTokens(tokens)
+ tks = createLineCommentTokenGroups(tks)
+ tks, err = createLiteralAndFoldedTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createAnchorAndAliasTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createScalarTagTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createAnchorWithScalarTagTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createMapKeyTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks = createMapKeyValueTokenGroups(tks)
+ tks, err = createDirectiveTokenGroups(tks)
+ if err != nil {
+ return nil, err
+ }
+ tks, err = createDocumentTokens(tks)
+ if err != nil {
+ return nil, err
+ }
+ return tks, nil
+}
+
+func newTokens(tks token.Tokens) []*Token {
+ ret := make([]*Token, 0, len(tks))
+ for _, tk := range tks {
+ ret = append(ret, &Token{Token: tk})
+ }
+ return ret
+}
+
+func createLineCommentTokenGroups(tokens []*Token) []*Token {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.CommentType:
+ if i > 0 && tokens[i-1].Line() == tk.Line() {
+ tokens[i-1].LineComment = tk.RawToken()
+ } else {
+ ret = append(ret, tk)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret
+}
+
+func createLiteralAndFoldedTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.LiteralType:
+ tks := []*Token{tk}
+ if i+1 < len(tokens) {
+ tks = append(tks, tokens[i+1])
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupLiteral,
+ Tokens: tks,
+ },
+ })
+ i++
+ case token.FoldedType:
+ tks := []*Token{tk}
+ if i+1 < len(tokens) {
+ tks = append(tks, tokens[i+1])
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupFolded,
+ Tokens: tks,
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createAnchorAndAliasTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.AnchorType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor name", tk.RawToken())
+ }
+ if i+2 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor value", tk.RawToken())
+ }
+ anchorName := &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchorName,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ }
+ valueTk := tokens[i+2]
+ if tk.Line() == valueTk.Line() && valueTk.Type() == token.SequenceEntryType {
+ return nil, errors.ErrSyntax("sequence entries are not allowed after anchor on the same line", valueTk.RawToken())
+ }
+ if tk.Line() == valueTk.Line() && isScalarType(valueTk) {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{anchorName, valueTk},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, anchorName)
+ }
+ i++
+ case token.AliasType:
+ if i+1 == len(tokens) {
+ return nil, errors.ErrSyntax("undefined alias name", tk.RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAlias,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createScalarTagTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ if tk.Type() != token.TagType {
+ ret = append(ret, tk)
+ continue
+ }
+ tag := tk.RawToken()
+ if strings.HasPrefix(tag.Value, "!!") {
+ // secondary tag.
+ switch token.ReservedTagKeyword(tag.Value) {
+ case token.IntegerTag, token.FloatTag, token.StringTag, token.BinaryTag, token.TimestampTag, token.BooleanTag, token.NullTag:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if isScalarType(tokens[i+1]) {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ }
+ case token.MergeTag:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].Type() != token.MergeKeyType {
+ return nil, errors.ErrSyntax("could not find merge key", tokens[i+1].RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ } else {
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ if tk.Line() != tokens[i+1].Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if tokens[i+1].GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if isFlowType(tokens[i+1]) {
+ ret = append(ret, tk)
+ continue
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupScalarTag,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ }
+ }
+ return ret, nil
+}
+
+func createAnchorWithScalarTagTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.GroupType() {
+ case TokenGroupAnchorName:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined anchor value", tk.RawToken())
+ }
+ valueTk := tokens[i+1]
+ if tk.Line() == valueTk.Line() && valueTk.GroupType() == TokenGroupScalarTag {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupAnchor,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyTokenGroups(tokens []*Token) ([]*Token, error) {
+ tks, err := createMapKeyByMappingKey(tokens)
+ if err != nil {
+ return nil, err
+ }
+ return createMapKeyByMappingValue(tks)
+}
+
+func createMapKeyByMappingKey(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.MappingKeyType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined map key", tk.RawToken())
+ }
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupMapKey,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ })
+ i++
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyByMappingValue(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.MappingValueType:
+ if i == 0 {
+ return nil, errors.ErrSyntax("unexpected key name", tk.RawToken())
+ }
+ mapKeyTk := tokens[i-1]
+ if isNotMapKeyType(mapKeyTk) {
+ return nil, errors.ErrSyntax("found an invalid key for this map", tokens[i].RawToken())
+ }
+ newTk := &Token{Token: mapKeyTk.Token, Group: mapKeyTk.Group}
+ mapKeyTk.Token = nil
+ mapKeyTk.Group = &TokenGroup{
+ Type: TokenGroupMapKey,
+ Tokens: []*Token{newTk, tk},
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createMapKeyValueTokenGroups(tokens []*Token) []*Token {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.GroupType() {
+ case TokenGroupMapKey:
+ if len(tokens) <= i+1 {
+ ret = append(ret, tk)
+ continue
+ }
+ valueTk := tokens[i+1]
+ if tk.Line() != valueTk.Line() {
+ ret = append(ret, tk)
+ continue
+ }
+ if valueTk.GroupType() == TokenGroupAnchorName {
+ ret = append(ret, tk)
+ continue
+ }
+ if valueTk.Type() == token.TagType && valueTk.GroupType() != TokenGroupScalarTag {
+ ret = append(ret, tk)
+ continue
+ }
+
+ if isScalarType(valueTk) || valueTk.Type() == token.TagType {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupMapKeyValue,
+ Tokens: []*Token{tk, valueTk},
+ },
+ })
+ i++
+ } else {
+ ret = append(ret, tk)
+ continue
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret
+}
+
+func createDirectiveTokenGroups(tokens []*Token) ([]*Token, error) {
+ ret := make([]*Token, 0, len(tokens))
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.DirectiveType:
+ if i+1 >= len(tokens) {
+ return nil, errors.ErrSyntax("undefined directive value", tk.RawToken())
+ }
+ directiveName := &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDirectiveName,
+ Tokens: []*Token{tk, tokens[i+1]},
+ },
+ }
+ i++
+ var valueTks []*Token
+ for j := i + 1; j < len(tokens); j++ {
+ if tokens[j].Line() != tk.Line() {
+ break
+ }
+ valueTks = append(valueTks, tokens[j])
+ i++
+ }
+ if i+1 >= len(tokens) || tokens[i+1].Type() != token.DocumentHeaderType {
+ return nil, errors.ErrSyntax("unexpected directive value. document not started", tk.RawToken())
+ }
+ if len(valueTks) != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDirective,
+ Tokens: append([]*Token{directiveName}, valueTks...),
+ },
+ })
+ } else {
+ ret = append(ret, directiveName)
+ }
+ default:
+ ret = append(ret, tk)
+ }
+ }
+ return ret, nil
+}
+
+func createDocumentTokens(tokens []*Token) ([]*Token, error) {
+ var ret []*Token
+ for i := 0; i < len(tokens); i++ {
+ tk := tokens[i]
+ switch tk.Type() {
+ case token.DocumentHeaderType:
+ if i != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{Tokens: tokens[:i]},
+ })
+ }
+ if i+1 == len(tokens) {
+ // if current token is last token, add DocumentHeader only tokens to ret.
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ }
+ if tokens[i+1].Type() == token.DocumentHeaderType {
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ }
+ if tokens[i].Line() == tokens[i+1].Line() {
+ switch tokens[i+1].GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return nil, errors.ErrSyntax("value cannot be placed after document separator", tokens[i+1].RawToken())
+ }
+ switch tokens[i+1].Type() {
+ case token.SequenceEntryType:
+ return nil, errors.ErrSyntax("value cannot be placed after document separator", tokens[i+1].RawToken())
+ }
+ }
+ tks, err := createDocumentTokens(tokens[i+1:])
+ if err != nil {
+ return nil, err
+ }
+ if len(tks) != 0 {
+ tks[0].SetGroupType(TokenGroupDocument)
+ tks[0].Group.Tokens = append([]*Token{tk}, tks[0].Group.Tokens...)
+ return append(ret, tks...), nil
+ }
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: []*Token{tk},
+ },
+ }), nil
+ case token.DocumentEndType:
+ if i != 0 {
+ ret = append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: tokens[0 : i+1],
+ },
+ })
+ }
+ if i+1 == len(tokens) {
+ return ret, nil
+ }
+ if isScalarType(tokens[i+1]) {
+ return nil, errors.ErrSyntax("unexpected end content", tokens[i+1].RawToken())
+ }
+
+ tks, err := createDocumentTokens(tokens[i+1:])
+ if err != nil {
+ return nil, err
+ }
+ return append(ret, tks...), nil
+ }
+ }
+ return append(ret, &Token{
+ Group: &TokenGroup{
+ Type: TokenGroupDocument,
+ Tokens: tokens,
+ },
+ }), nil
+}
+
+func isScalarType(tk *Token) bool {
+ switch tk.GroupType() {
+ case TokenGroupMapKey, TokenGroupMapKeyValue:
+ return false
+ }
+ typ := tk.Type()
+ return typ == token.AnchorType ||
+ typ == token.AliasType ||
+ typ == token.LiteralType ||
+ typ == token.FoldedType ||
+ typ == token.NullType ||
+ typ == token.ImplicitNullType ||
+ typ == token.BoolType ||
+ typ == token.IntegerType ||
+ typ == token.BinaryIntegerType ||
+ typ == token.OctetIntegerType ||
+ typ == token.HexIntegerType ||
+ typ == token.FloatType ||
+ typ == token.InfinityType ||
+ typ == token.NanType ||
+ typ == token.StringType ||
+ typ == token.SingleQuoteType ||
+ typ == token.DoubleQuoteType
+}
+
+func isNotMapKeyType(tk *Token) bool {
+ typ := tk.Type()
+ return typ == token.DirectiveType ||
+ typ == token.DocumentHeaderType ||
+ typ == token.DocumentEndType ||
+ typ == token.CollectEntryType ||
+ typ == token.MappingStartType ||
+ typ == token.MappingValueType ||
+ typ == token.MappingEndType ||
+ typ == token.SequenceStartType ||
+ typ == token.SequenceEntryType ||
+ typ == token.SequenceEndType
+}
+
+func isFlowType(tk *Token) bool {
+ typ := tk.Type()
+ return typ == token.MappingStartType ||
+ typ == token.MappingEndType ||
+ typ == token.SequenceStartType ||
+ typ == token.SequenceEntryType
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/path.go b/sesh/vendor/github.com/goccy/go-yaml/path.go
new file mode 100644
index 0000000..568c4b4
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/path.go
@@ -0,0 +1,835 @@
+package yaml
+
+import (
+ "bytes"
+ "fmt"
+ "io"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/parser"
+ "github.com/goccy/go-yaml/printer"
+)
+
+// PathString create Path from string
+//
+// YAMLPath rule
+// $ : the root object/element
+// . : child operator
+// .. : recursive descent
+// [num] : object/element of array by number
+// [*] : all objects/elements for array.
+//
+// If you want to use reserved characters such as `.` and `*` as a key name,
+// enclose them in single quotation as follows ( $.foo.'bar.baz-*'.hoge ).
+// If you want to use a single quote with reserved characters, escape it with `\` ( $.foo.'bar.baz\'s value'.hoge ).
+func PathString(s string) (*Path, error) {
+ buf := []rune(s)
+ length := len(buf)
+ cursor := 0
+ builder := &PathBuilder{}
+ for cursor < length {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ builder = builder.Root()
+ cursor++
+ case '.':
+ b, buf, c, err := parsePathDot(builder, buf, cursor)
+ if err != nil {
+ return nil, err
+ }
+ length = len(buf)
+ builder = b
+ cursor = c
+ case '[':
+ b, buf, c, err := parsePathIndex(builder, buf, cursor)
+ if err != nil {
+ return nil, err
+ }
+ length = len(buf)
+ builder = b
+ cursor = c
+ default:
+ return nil, fmt.Errorf("invalid path at %d: %w", cursor, ErrInvalidPathString)
+ }
+ }
+ return builder.Build(), nil
+}
+
+func parsePathRecursive(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ length := len(buf)
+ cursor += 2 // skip .. characters
+ start := cursor
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '..' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '..' character: %w", ErrInvalidPathString)
+ case '.', '[':
+ goto end
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '..' character: %w", ErrInvalidPathString)
+ }
+ }
+end:
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("not found recursive selector: %w", ErrInvalidPathString)
+ }
+ return b.Recursive(string(buf[start:cursor])), buf, cursor, nil
+}
+
+func parsePathDot(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+ length := len(buf)
+ if cursor+1 < length && buf[cursor+1] == '.' {
+ b, buf, c, err := parsePathRecursive(b, buf, cursor)
+ if err != nil {
+ return nil, nil, 0, err
+ }
+ return b, buf, c, nil
+ }
+ cursor++ // skip . character
+ start := cursor
+
+ // if started single quote, looking for end single quote char
+ if cursor < length && buf[cursor] == '\'' {
+ return parseQuotedKey(b, buf, cursor)
+ }
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '.' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '.' character: %w", ErrInvalidPathString)
+ case '.', '[':
+ goto end
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '.' character: %w", ErrInvalidPathString)
+ }
+ }
+end:
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("could not find by empty key: %w", ErrInvalidPathString)
+ }
+ return b.child(string(buf[start:cursor])), buf, cursor, nil
+}
+
+func parseQuotedKey(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+
+ cursor++ // skip single quote
+ start := cursor
+ length := len(buf)
+ var foundEndDelim bool
+ for ; cursor < length; cursor++ {
+ switch buf[cursor] {
+ case '\\':
+ buf = append(append([]rune{}, buf[:cursor]...), buf[cursor+1:]...)
+ length = len(buf)
+ case '\'':
+ foundEndDelim = true
+ goto end
+ }
+ }
+end:
+ if !foundEndDelim {
+ return nil, nil, 0, fmt.Errorf("could not find end delimiter for key: %w", ErrInvalidPathString)
+ }
+ if start == cursor {
+ return nil, nil, 0, fmt.Errorf("could not find by empty key: %w", ErrInvalidPathString)
+ }
+ selector := buf[start:cursor]
+ cursor++
+ if cursor < length {
+ switch buf[cursor] {
+ case '$':
+ return nil, nil, 0, fmt.Errorf("specified '$' after '.' character: %w", ErrInvalidPathString)
+ case '*':
+ return nil, nil, 0, fmt.Errorf("specified '*' after '.' character: %w", ErrInvalidPathString)
+ case ']':
+ return nil, nil, 0, fmt.Errorf("specified ']' after '.' character: %w", ErrInvalidPathString)
+ }
+ }
+ return b.child(string(selector)), buf, cursor, nil
+}
+
+func parsePathIndex(b *PathBuilder, buf []rune, cursor int) (*PathBuilder, []rune, int, error) {
+ if b.root == nil || b.node == nil {
+ return nil, nil, 0, fmt.Errorf("required '$' character at first: %w", ErrInvalidPathString)
+ }
+
+ length := len(buf)
+ cursor++ // skip '[' character
+ if length <= cursor {
+ return nil, nil, 0, fmt.Errorf("unexpected end of YAML Path: %w", ErrInvalidPathString)
+ }
+ c := buf[cursor]
+ switch c {
+ case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '*':
+ start := cursor
+ cursor++
+ for ; cursor < length; cursor++ {
+ c := buf[cursor]
+ switch c {
+ case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
+ continue
+ }
+ break
+ }
+ if buf[cursor] != ']' {
+ return nil, nil, 0, fmt.Errorf("invalid character %s at %d: %w", string(buf[cursor]), cursor, ErrInvalidPathString)
+ }
+ numOrAll := string(buf[start:cursor])
+ if numOrAll == "*" {
+ return b.IndexAll(), buf, cursor + 1, nil
+ }
+ num, err := strconv.ParseInt(numOrAll, 10, 64)
+ if err != nil {
+ return nil, nil, 0, err
+ }
+ return b.Index(uint(num)), buf, cursor + 1, nil
+ }
+ return nil, nil, 0, fmt.Errorf("invalid character %q at %d: %w", c, cursor, ErrInvalidPathString)
+}
+
+// Path represent YAMLPath ( like a JSONPath ).
+type Path struct {
+ node pathNode
+}
+
+// String path to text.
+func (p *Path) String() string {
+ return p.node.String()
+}
+
+// Read decode from r and set extracted value by YAMLPath to v.
+func (p *Path) Read(r io.Reader, v interface{}) error {
+ node, err := p.ReadNode(r)
+ if err != nil {
+ return err
+ }
+ if err := Unmarshal([]byte(node.String()), v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReadNode create AST from r and extract node by YAMLPath.
+func (p *Path) ReadNode(r io.Reader) (ast.Node, error) {
+ if p.node == nil {
+ return nil, ErrInvalidPath
+ }
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, r); err != nil {
+ return nil, err
+ }
+ f, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return nil, err
+ }
+ node, err := p.FilterFile(f)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+// Filter filter from target by YAMLPath and set it to v.
+func (p *Path) Filter(target, v interface{}) error {
+ b, err := Marshal(target)
+ if err != nil {
+ return err
+ }
+ if err := p.Read(bytes.NewBuffer(b), v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// FilterFile filter from ast.File by YAMLPath.
+func (p *Path) FilterFile(f *ast.File) (ast.Node, error) {
+ for _, doc := range f.Docs {
+ // For simplicity, directives cannot be the target of operations
+ if doc.Body != nil && doc.Body.Type() == ast.DirectiveType {
+ continue
+ }
+ node, err := p.FilterNode(doc.Body)
+ if err != nil {
+ return nil, err
+ }
+ if node != nil {
+ return node, nil
+ }
+ }
+ return nil, fmt.Errorf("failed to find path ( %s ): %w", p.node, ErrNotFoundNode)
+}
+
+// FilterNode filter from node by YAMLPath.
+func (p *Path) FilterNode(node ast.Node) (ast.Node, error) {
+ if node == nil {
+ return nil, nil
+ }
+ n, err := p.node.filter(node)
+ if err != nil {
+ return nil, err
+ }
+ return n, nil
+}
+
+// MergeFromReader merge YAML text into ast.File.
+func (p *Path) MergeFromReader(dst *ast.File, src io.Reader) error {
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, src); err != nil {
+ return err
+ }
+ file, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return err
+ }
+ if err := p.MergeFromFile(dst, file); err != nil {
+ return err
+ }
+ return nil
+}
+
+// MergeFromFile merge ast.File into ast.File.
+func (p *Path) MergeFromFile(dst *ast.File, src *ast.File) error {
+ base, err := p.FilterFile(dst)
+ if err != nil {
+ return err
+ }
+ for _, doc := range src.Docs {
+ if err := ast.Merge(base, doc); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// MergeFromNode merge ast.Node into ast.File.
+func (p *Path) MergeFromNode(dst *ast.File, src ast.Node) error {
+ base, err := p.FilterFile(dst)
+ if err != nil {
+ return err
+ }
+ if err := ast.Merge(base, src); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReplaceWithReader replace ast.File with io.Reader.
+func (p *Path) ReplaceWithReader(dst *ast.File, src io.Reader) error {
+ var buf bytes.Buffer
+ if _, err := io.Copy(&buf, src); err != nil {
+ return err
+ }
+ file, err := parser.ParseBytes(buf.Bytes(), 0)
+ if err != nil {
+ return err
+ }
+ if err := p.ReplaceWithFile(dst, file); err != nil {
+ return err
+ }
+ return nil
+}
+
+// ReplaceWithFile replace ast.File with ast.File.
+func (p *Path) ReplaceWithFile(dst *ast.File, src *ast.File) error {
+ for _, doc := range src.Docs {
+ if err := p.ReplaceWithNode(dst, doc); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// ReplaceNode replace ast.File with ast.Node.
+func (p *Path) ReplaceWithNode(dst *ast.File, node ast.Node) error {
+ for _, doc := range dst.Docs {
+ // For simplicity, directives cannot be the target of operations
+ if doc.Body != nil && doc.Body.Type() == ast.DirectiveType {
+ continue
+ }
+ if node.Type() == ast.DocumentType {
+ node = node.(*ast.DocumentNode).Body
+ }
+ if err := p.node.replace(doc.Body, node); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+// AnnotateSource add annotation to passed source ( see section 5.1 in README.md ).
+func (p *Path) AnnotateSource(source []byte, colored bool) ([]byte, error) {
+ file, err := parser.ParseBytes(source, 0)
+ if err != nil {
+ return nil, err
+ }
+ node, err := p.FilterFile(file)
+ if err != nil {
+ return nil, err
+ }
+ var pp printer.Printer
+ return []byte(pp.PrintErrorToken(node.GetToken(), colored)), nil
+}
+
+// PathBuilder represent builder for YAMLPath.
+type PathBuilder struct {
+ root *rootNode
+ node pathNode
+}
+
+// Root add '$' to current path.
+func (b *PathBuilder) Root() *PathBuilder {
+ root := newRootNode()
+ return &PathBuilder{root: root, node: root}
+}
+
+// IndexAll add '[*]' to current path.
+func (b *PathBuilder) IndexAll() *PathBuilder {
+ b.node = b.node.chain(newIndexAllNode())
+ return b
+}
+
+// Recursive add '..selector' to current path.
+func (b *PathBuilder) Recursive(selector string) *PathBuilder {
+ b.node = b.node.chain(newRecursiveNode(selector))
+ return b
+}
+
+func (b *PathBuilder) containsReservedPathCharacters(path string) bool {
+ if strings.Contains(path, ".") {
+ return true
+ }
+ if strings.Contains(path, "*") {
+ return true
+ }
+ return false
+}
+
+func (b *PathBuilder) enclosedSingleQuote(name string) bool {
+ return strings.HasPrefix(name, "'") && strings.HasSuffix(name, "'")
+}
+
+func (b *PathBuilder) normalizeSelectorName(name string) string {
+ if b.enclosedSingleQuote(name) {
+ // already escaped name
+ return name
+ }
+ if b.containsReservedPathCharacters(name) {
+ escapedName := strings.ReplaceAll(name, `'`, `\'`)
+ return "'" + escapedName + "'"
+ }
+ return name
+}
+
+func (b *PathBuilder) child(name string) *PathBuilder {
+ b.node = b.node.chain(newSelectorNode(name))
+ return b
+}
+
+// Child add '.name' to current path.
+func (b *PathBuilder) Child(name string) *PathBuilder {
+ return b.child(b.normalizeSelectorName(name))
+}
+
+// Index add '[idx]' to current path.
+func (b *PathBuilder) Index(idx uint) *PathBuilder {
+ b.node = b.node.chain(newIndexNode(idx))
+ return b
+}
+
+// Build build YAMLPath.
+func (b *PathBuilder) Build() *Path {
+ return &Path{node: b.root}
+}
+
+type pathNode interface {
+ fmt.Stringer
+ chain(pathNode) pathNode
+ filter(ast.Node) (ast.Node, error)
+ replace(ast.Node, ast.Node) error
+}
+
+type basePathNode struct {
+ child pathNode
+}
+
+func (n *basePathNode) chain(node pathNode) pathNode {
+ n.child = node
+ return node
+}
+
+type rootNode struct {
+ *basePathNode
+}
+
+func newRootNode() *rootNode {
+ return &rootNode{basePathNode: &basePathNode{}}
+}
+
+func (n *rootNode) String() string {
+ s := "$"
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *rootNode) filter(node ast.Node) (ast.Node, error) {
+ if n.child == nil {
+ return node, nil
+ }
+ filtered, err := n.child.filter(node)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+}
+
+func (n *rootNode) replace(node ast.Node, target ast.Node) error {
+ if n.child == nil {
+ return nil
+ }
+ if err := n.child.replace(node, target); err != nil {
+ return err
+ }
+ return nil
+}
+
+type selectorNode struct {
+ *basePathNode
+ selector string
+}
+
+func newSelectorNode(selector string) *selectorNode {
+ return &selectorNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *selectorNode) filter(node ast.Node) (ast.Node, error) {
+ selector := n.selector
+ if len(selector) > 1 && selector[0] == '\'' && selector[len(selector)-1] == '\'' {
+ selector = selector[1 : len(selector)-1]
+ }
+ switch node.Type() {
+ case ast.MappingType:
+ for _, value := range node.(*ast.MappingNode).Values {
+ key := value.Key.GetToken().Value
+ if len(key) > 0 {
+ switch key[0] {
+ case '"':
+ var err error
+ key, err = strconv.Unquote(key)
+ if err != nil {
+ return nil, err
+ }
+ case '\'':
+ if len(key) > 1 && key[len(key)-1] == '\'' {
+ key = key[1 : len(key)-1]
+ }
+ }
+ }
+ if key == selector {
+ if n.child == nil {
+ return value.Value, nil
+ }
+ filtered, err := n.child.filter(value.Value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+ }
+ }
+ case ast.MappingValueType:
+ value, _ := node.(*ast.MappingValueNode)
+ key := value.Key.GetToken().Value
+ if key == selector {
+ if n.child == nil {
+ return value.Value, nil
+ }
+ filtered, err := n.child.filter(value.Value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+ }
+ default:
+ return nil, fmt.Errorf("expected node type is map or map value. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ return nil, nil
+}
+
+func (n *selectorNode) replaceMapValue(value *ast.MappingValueNode, target ast.Node) error {
+ key := value.Key.GetToken().Value
+ if key != n.selector {
+ return nil
+ }
+ if n.child == nil {
+ if err := value.Replace(target); err != nil {
+ return err
+ }
+ } else {
+ if err := n.child.replace(value.Value, target); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+func (n *selectorNode) replace(node ast.Node, target ast.Node) error {
+ switch node.Type() {
+ case ast.MappingType:
+ for _, value := range node.(*ast.MappingNode).Values {
+ if err := n.replaceMapValue(value, target); err != nil {
+ return err
+ }
+ }
+ case ast.MappingValueType:
+ value, _ := node.(*ast.MappingValueNode)
+ if err := n.replaceMapValue(value, target); err != nil {
+ return err
+ }
+ default:
+ return fmt.Errorf("expected node type is map or map value. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ return nil
+}
+
+func (n *selectorNode) String() string {
+ var builder PathBuilder
+ selector := builder.normalizeSelectorName(n.selector)
+ s := fmt.Sprintf(".%s", selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+type indexNode struct {
+ *basePathNode
+ selector uint
+}
+
+func newIndexNode(selector uint) *indexNode {
+ return &indexNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *indexNode) filter(node ast.Node) (ast.Node, error) {
+ if node.Type() != ast.SequenceType {
+ return nil, fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.selector >= uint(len(sequence.Values)) {
+ return nil, fmt.Errorf("expected index is %d. but got sequences has %d items: %w", n.selector, len(sequence.Values), ErrInvalidQuery)
+ }
+ value := sequence.Values[n.selector]
+ if n.child == nil {
+ return value, nil
+ }
+ filtered, err := n.child.filter(value)
+ if err != nil {
+ return nil, err
+ }
+ return filtered, nil
+}
+
+func (n *indexNode) replace(node ast.Node, target ast.Node) error {
+ if node.Type() != ast.SequenceType {
+ return fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.selector >= uint(len(sequence.Values)) {
+ return fmt.Errorf("expected index is %d. but got sequences has %d items: %w", n.selector, len(sequence.Values), ErrInvalidQuery)
+ }
+ if n.child == nil {
+ if err := sequence.Replace(int(n.selector), target); err != nil {
+ return err
+ }
+ return nil
+ }
+ if err := n.child.replace(sequence.Values[n.selector], target); err != nil {
+ return err
+ }
+ return nil
+}
+
+func (n *indexNode) String() string {
+ s := fmt.Sprintf("[%d]", n.selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+type indexAllNode struct {
+ *basePathNode
+}
+
+func newIndexAllNode() *indexAllNode {
+ return &indexAllNode{
+ basePathNode: &basePathNode{},
+ }
+}
+
+func (n *indexAllNode) String() string {
+ s := "[*]"
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *indexAllNode) filter(node ast.Node) (ast.Node, error) {
+ if node.Type() != ast.SequenceType {
+ return nil, fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.child == nil {
+ return sequence, nil
+ }
+ out := *sequence
+ out.Values = []ast.Node{}
+ for _, value := range sequence.Values {
+ filtered, err := n.child.filter(value)
+ if err != nil {
+ return nil, err
+ }
+ out.Values = append(out.Values, filtered)
+ }
+ return &out, nil
+}
+
+func (n *indexAllNode) replace(node ast.Node, target ast.Node) error {
+ if node.Type() != ast.SequenceType {
+ return fmt.Errorf("expected sequence type node. but got %s: %w", node.Type(), ErrInvalidQuery)
+ }
+ sequence, _ := node.(*ast.SequenceNode)
+ if n.child == nil {
+ for idx := range sequence.Values {
+ if err := sequence.Replace(idx, target); err != nil {
+ return err
+ }
+ }
+ return nil
+ }
+ for _, value := range sequence.Values {
+ if err := n.child.replace(value, target); err != nil {
+ return err
+ }
+ }
+ return nil
+}
+
+type recursiveNode struct {
+ *basePathNode
+ selector string
+}
+
+func newRecursiveNode(selector string) *recursiveNode {
+ return &recursiveNode{
+ basePathNode: &basePathNode{},
+ selector: selector,
+ }
+}
+
+func (n *recursiveNode) String() string {
+ s := fmt.Sprintf("..%s", n.selector)
+ if n.child != nil {
+ s += n.child.String()
+ }
+ return s
+}
+
+func (n *recursiveNode) filterNode(node ast.Node) (*ast.SequenceNode, error) {
+ sequence := &ast.SequenceNode{BaseNode: &ast.BaseNode{}}
+ switch typedNode := node.(type) {
+ case *ast.MappingNode:
+ for _, value := range typedNode.Values {
+ seq, err := n.filterNode(value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ }
+ case *ast.MappingValueNode:
+ key := typedNode.Key.GetToken().Value
+ if n.selector == key {
+ sequence.Values = append(sequence.Values, typedNode.Value)
+ }
+ seq, err := n.filterNode(typedNode.Value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ case *ast.SequenceNode:
+ for _, value := range typedNode.Values {
+ seq, err := n.filterNode(value)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Values = append(sequence.Values, seq.Values...)
+ }
+ }
+ return sequence, nil
+}
+
+func (n *recursiveNode) filter(node ast.Node) (ast.Node, error) {
+ sequence, err := n.filterNode(node)
+ if err != nil {
+ return nil, err
+ }
+ sequence.Start = node.GetToken()
+ return sequence, nil
+}
+
+func (n *recursiveNode) replaceNode(node ast.Node, target ast.Node) error {
+ switch typedNode := node.(type) {
+ case *ast.MappingNode:
+ for _, value := range typedNode.Values {
+ if err := n.replaceNode(value, target); err != nil {
+ return err
+ }
+ }
+ case *ast.MappingValueNode:
+ key := typedNode.Key.GetToken().Value
+ if n.selector == key {
+ if err := typedNode.Replace(target); err != nil {
+ return err
+ }
+ }
+ if err := n.replaceNode(typedNode.Value, target); err != nil {
+ return err
+ }
+ case *ast.SequenceNode:
+ for _, value := range typedNode.Values {
+ if err := n.replaceNode(value, target); err != nil {
+ return err
+ }
+ }
+ }
+ return nil
+}
+
+func (n *recursiveNode) replace(node ast.Node, target ast.Node) error {
+ if err := n.replaceNode(node, target); err != nil {
+ return err
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/printer/color.go b/sesh/vendor/github.com/goccy/go-yaml/printer/color.go
new file mode 100644
index 0000000..79d7d7c
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/printer/color.go
@@ -0,0 +1,83 @@
+// This source inspired by https://github.com/fatih/color.
+package printer
+
+import (
+ "fmt"
+ "strings"
+)
+
+type ColorAttribute int
+
+const (
+ ColorReset ColorAttribute = iota
+ ColorBold
+ ColorFaint
+ ColorItalic
+ ColorUnderline
+ ColorBlinkSlow
+ ColorBlinkRapid
+ ColorReverseVideo
+ ColorConcealed
+ ColorCrossedOut
+)
+
+const (
+ ColorFgHiBlack ColorAttribute = iota + 90
+ ColorFgHiRed
+ ColorFgHiGreen
+ ColorFgHiYellow
+ ColorFgHiBlue
+ ColorFgHiMagenta
+ ColorFgHiCyan
+ ColorFgHiWhite
+)
+
+const (
+ ColorResetBold ColorAttribute = iota + 22
+ ColorResetItalic
+ ColorResetUnderline
+ ColorResetBlinking
+
+ ColorResetReversed
+ ColorResetConcealed
+ ColorResetCrossedOut
+)
+
+const escape = "\x1b"
+
+var colorResetMap = map[ColorAttribute]ColorAttribute{
+ ColorBold: ColorResetBold,
+ ColorFaint: ColorResetBold,
+ ColorItalic: ColorResetItalic,
+ ColorUnderline: ColorResetUnderline,
+ ColorBlinkSlow: ColorResetBlinking,
+ ColorBlinkRapid: ColorResetBlinking,
+ ColorReverseVideo: ColorResetReversed,
+ ColorConcealed: ColorResetConcealed,
+ ColorCrossedOut: ColorResetCrossedOut,
+}
+
+func format(attrs ...ColorAttribute) string {
+ format := make([]string, 0, len(attrs))
+ for _, attr := range attrs {
+ format = append(format, fmt.Sprint(attr))
+ }
+ return fmt.Sprintf("%s[%sm", escape, strings.Join(format, ";"))
+}
+
+func unformat(attrs ...ColorAttribute) string {
+ format := make([]string, len(attrs))
+ for _, attr := range attrs {
+ v := fmt.Sprint(ColorReset)
+ reset, exists := colorResetMap[attr]
+ if exists {
+ v = fmt.Sprint(reset)
+ }
+ format = append(format, v)
+ }
+ return fmt.Sprintf("%s[%sm", escape, strings.Join(format, ";"))
+}
+
+func colorize(msg string, attrs ...ColorAttribute) string {
+ return format(attrs...) + msg + unformat(attrs...)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go b/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go
new file mode 100644
index 0000000..9346983
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/printer/printer.go
@@ -0,0 +1,353 @@
+package printer
+
+import (
+ "fmt"
+ "math"
+ "strings"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/token"
+)
+
+// Property additional property set for each the token
+type Property struct {
+ Prefix string
+ Suffix string
+}
+
+// PrintFunc returns property instance
+type PrintFunc func() *Property
+
+// Printer create text from token collection or ast
+type Printer struct {
+ LineNumber bool
+ LineNumberFormat func(num int) string
+ MapKey PrintFunc
+ Anchor PrintFunc
+ Alias PrintFunc
+ Bool PrintFunc
+ String PrintFunc
+ Number PrintFunc
+ Comment PrintFunc
+}
+
+func defaultLineNumberFormat(num int) string {
+ return fmt.Sprintf("%2d | ", num)
+}
+
+func (p *Printer) property(tk *token.Token) *Property {
+ prop := &Property{}
+ switch tk.PreviousType() {
+ case token.AnchorType:
+ if p.Anchor != nil {
+ return p.Anchor()
+ }
+ return prop
+ case token.AliasType:
+ if p.Alias != nil {
+ return p.Alias()
+ }
+ return prop
+ }
+ switch tk.NextType() {
+ case token.MappingValueType:
+ if p.MapKey != nil {
+ return p.MapKey()
+ }
+ return prop
+ }
+ switch tk.Type {
+ case token.BoolType:
+ if p.Bool != nil {
+ return p.Bool()
+ }
+ return prop
+ case token.AnchorType:
+ if p.Anchor != nil {
+ return p.Anchor()
+ }
+ return prop
+ case token.AliasType:
+ if p.Anchor != nil {
+ return p.Alias()
+ }
+ return prop
+ case token.StringType, token.SingleQuoteType, token.DoubleQuoteType:
+ if p.String != nil {
+ return p.String()
+ }
+ return prop
+ case token.IntegerType, token.FloatType:
+ if p.Number != nil {
+ return p.Number()
+ }
+ return prop
+ case token.CommentType:
+ if p.Comment != nil {
+ return p.Comment()
+ }
+ return prop
+ default:
+ }
+ return prop
+}
+
+// PrintTokens create text from token collection
+func (p *Printer) PrintTokens(tokens token.Tokens) string {
+ if len(tokens) == 0 {
+ return ""
+ }
+ if p.LineNumber {
+ if p.LineNumberFormat == nil {
+ p.LineNumberFormat = defaultLineNumberFormat
+ }
+ }
+ texts := []string{}
+ lineNumber := tokens[0].Position.Line
+ for _, tk := range tokens {
+ lines := strings.Split(tk.Origin, "\n")
+ prop := p.property(tk)
+ header := ""
+ if p.LineNumber {
+ header = p.LineNumberFormat(lineNumber)
+ }
+ if len(lines) == 1 {
+ line := prop.Prefix + lines[0] + prop.Suffix
+ if len(texts) == 0 {
+ texts = append(texts, header+line)
+ lineNumber++
+ } else {
+ text := texts[len(texts)-1]
+ texts[len(texts)-1] = text + line
+ }
+ } else {
+ for idx, src := range lines {
+ if p.LineNumber {
+ header = p.LineNumberFormat(lineNumber)
+ }
+ line := prop.Prefix + src + prop.Suffix
+ if idx == 0 {
+ if len(texts) == 0 {
+ texts = append(texts, header+line)
+ lineNumber++
+ } else {
+ text := texts[len(texts)-1]
+ texts[len(texts)-1] = text + line
+ }
+ } else {
+ texts = append(texts, fmt.Sprintf("%s%s", header, line))
+ lineNumber++
+ }
+ }
+ }
+ }
+ return strings.Join(texts, "\n")
+}
+
+// PrintNode create text from ast.Node
+func (p *Printer) PrintNode(node ast.Node) []byte {
+ return []byte(fmt.Sprintf("%+v\n", node))
+}
+
+func (p *Printer) setDefaultColorSet() {
+ p.Bool = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiMagenta),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Number = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiMagenta),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.MapKey = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiCyan),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Anchor = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiYellow),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Alias = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiYellow),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.String = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiGreen),
+ Suffix: format(ColorReset),
+ }
+ }
+ p.Comment = func() *Property {
+ return &Property{
+ Prefix: format(ColorFgHiBlack),
+ Suffix: format(ColorReset),
+ }
+ }
+}
+
+func (p *Printer) PrintErrorMessage(msg string, isColored bool) string {
+ if isColored {
+ return fmt.Sprintf("%s%s%s",
+ format(ColorFgHiRed),
+ msg,
+ format(ColorReset),
+ )
+ }
+ return msg
+}
+
+func (p *Printer) removeLeftSideNewLineChar(src string) string {
+ return strings.TrimLeft(strings.TrimLeft(strings.TrimLeft(src, "\r"), "\n"), "\r\n")
+}
+
+func (p *Printer) removeRightSideNewLineChar(src string) string {
+ return strings.TrimRight(strings.TrimRight(strings.TrimRight(src, "\r"), "\n"), "\r\n")
+}
+
+func (p *Printer) removeRightSideWhiteSpaceChar(src string) string {
+ return p.removeRightSideNewLineChar(strings.TrimRight(src, " "))
+}
+
+func (p *Printer) newLineCount(s string) int {
+ src := []rune(s)
+ size := len(src)
+ cnt := 0
+ for i := 0; i < size; i++ {
+ c := src[i]
+ switch c {
+ case '\r':
+ if i+1 < size && src[i+1] == '\n' {
+ i++
+ }
+ cnt++
+ case '\n':
+ cnt++
+ }
+ }
+ return cnt
+}
+
+func (p *Printer) isNewLineLastChar(s string) bool {
+ for i := len(s) - 1; i > 0; i-- {
+ c := s[i]
+ switch c {
+ case ' ':
+ continue
+ case '\n', '\r':
+ return true
+ }
+ break
+ }
+ return false
+}
+
+func (p *Printer) printBeforeTokens(tk *token.Token, minLine, extLine int) token.Tokens {
+ for tk.Prev != nil {
+ if tk.Prev.Position.Line < minLine {
+ break
+ }
+ tk = tk.Prev
+ }
+ minTk := tk.Clone()
+ if minTk.Prev != nil {
+ // add white spaces to minTk by prev token
+ prev := minTk.Prev
+ whiteSpaceLen := len(prev.Origin) - len(strings.TrimRight(prev.Origin, " "))
+ minTk.Origin = strings.Repeat(" ", whiteSpaceLen) + minTk.Origin
+ }
+ minTk.Origin = p.removeLeftSideNewLineChar(minTk.Origin)
+ tokens := token.Tokens{minTk}
+ tk = minTk.Next
+ for tk != nil && tk.Position.Line <= extLine {
+ clonedTk := tk.Clone()
+ tokens.Add(clonedTk)
+ tk = clonedTk.Next
+ }
+ lastTk := tokens[len(tokens)-1]
+ trimmedOrigin := p.removeRightSideWhiteSpaceChar(lastTk.Origin)
+ suffix := lastTk.Origin[len(trimmedOrigin):]
+ lastTk.Origin = trimmedOrigin
+
+ if lastTk.Next != nil && len(suffix) > 1 {
+ next := lastTk.Next.Clone()
+ // add suffix to header of next token
+ if suffix[0] == '\n' || suffix[0] == '\r' {
+ suffix = suffix[1:]
+ }
+ next.Origin = suffix + next.Origin
+ lastTk.Next = next
+ }
+ return tokens
+}
+
+func (p *Printer) printAfterTokens(tk *token.Token, maxLine int) token.Tokens {
+ tokens := token.Tokens{}
+ if tk == nil {
+ return tokens
+ }
+ if tk.Position.Line > maxLine {
+ return tokens
+ }
+ minTk := tk.Clone()
+ minTk.Origin = p.removeLeftSideNewLineChar(minTk.Origin)
+ tokens.Add(minTk)
+ tk = minTk.Next
+ for tk != nil && tk.Position.Line <= maxLine {
+ clonedTk := tk.Clone()
+ tokens.Add(clonedTk)
+ tk = clonedTk.Next
+ }
+ return tokens
+}
+
+func (p *Printer) setupErrorTokenFormat(annotateLine int, isColored bool) {
+ prefix := func(annotateLine, num int) string {
+ if annotateLine == num {
+ return fmt.Sprintf("> %2d | ", num)
+ }
+ return fmt.Sprintf(" %2d | ", num)
+ }
+ p.LineNumber = true
+ p.LineNumberFormat = func(num int) string {
+ if isColored {
+ return colorize(prefix(annotateLine, num), ColorBold, ColorFgHiWhite)
+ }
+ return prefix(annotateLine, num)
+ }
+ if isColored {
+ p.setDefaultColorSet()
+ }
+}
+
+func (p *Printer) PrintErrorToken(tk *token.Token, isColored bool) string {
+ errToken := tk
+ curLine := tk.Position.Line
+ curExtLine := curLine + p.newLineCount(p.removeLeftSideNewLineChar(tk.Origin))
+ if p.isNewLineLastChar(tk.Origin) {
+ // if last character ( exclude white space ) is new line character, ignore it.
+ curExtLine--
+ }
+
+ minLine := int(math.Max(float64(curLine-3), 1))
+ maxLine := curExtLine + 3
+ p.setupErrorTokenFormat(curLine, isColored)
+
+ beforeTokens := p.printBeforeTokens(tk, minLine, curExtLine)
+ lastTk := beforeTokens[len(beforeTokens)-1]
+ afterTokens := p.printAfterTokens(lastTk.Next, maxLine)
+
+ beforeSource := p.PrintTokens(beforeTokens)
+ prefixSpaceNum := len(fmt.Sprintf(" %2d | ", curLine))
+ annotateLine := strings.Repeat(" ", prefixSpaceNum+errToken.Position.Column-1) + "^"
+ afterSource := p.PrintTokens(afterTokens)
+ return fmt.Sprintf("%s\n%s\n%s", beforeSource, annotateLine, afterSource)
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go
new file mode 100644
index 0000000..4f3250b
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/context.go
@@ -0,0 +1,452 @@
+package scanner
+
+import (
+ "errors"
+ "strconv"
+ "strings"
+ "sync"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// Context context at scanning
+type Context struct {
+ idx int
+ size int
+ notSpaceCharPos int
+ notSpaceOrgCharPos int
+ src []rune
+ buf []rune
+ obuf []rune
+ tokens token.Tokens
+ mstate *MultiLineState
+}
+
+type MultiLineState struct {
+ opt string
+ firstLineIndentColumn int
+ prevLineIndentColumn int
+ lineIndentColumn int
+ lastNotSpaceOnlyLineIndentColumn int
+ spaceOnlyIndentColumn int
+ foldedNewLine bool
+ isRawFolded bool
+ isLiteral bool
+ isFolded bool
+}
+
+var (
+ ctxPool = sync.Pool{
+ New: func() interface{} {
+ return createContext()
+ },
+ }
+)
+
+func createContext() *Context {
+ return &Context{
+ idx: 0,
+ tokens: token.Tokens{},
+ }
+}
+
+func newContext(src []rune) *Context {
+ ctx, _ := ctxPool.Get().(*Context)
+ ctx.reset(src)
+ return ctx
+}
+
+func (c *Context) release() {
+ ctxPool.Put(c)
+}
+
+func (c *Context) clear() {
+ c.resetBuffer()
+ c.mstate = nil
+}
+
+func (c *Context) reset(src []rune) {
+ c.idx = 0
+ c.size = len(src)
+ c.src = src
+ c.tokens = c.tokens[:0]
+ c.resetBuffer()
+ c.mstate = nil
+}
+
+func (c *Context) resetBuffer() {
+ c.buf = c.buf[:0]
+ c.obuf = c.obuf[:0]
+ c.notSpaceCharPos = 0
+ c.notSpaceOrgCharPos = 0
+}
+
+func (c *Context) breakMultiLine() {
+ c.mstate = nil
+}
+
+func (c *Context) getMultiLineState() *MultiLineState {
+ return c.mstate
+}
+
+func (c *Context) setLiteral(lastDelimColumn int, opt string) {
+ mstate := &MultiLineState{
+ isLiteral: true,
+ opt: opt,
+ }
+ indent := firstLineIndentColumnByOpt(opt)
+ if indent > 0 {
+ mstate.firstLineIndentColumn = lastDelimColumn + indent
+ }
+ c.mstate = mstate
+}
+
+func (c *Context) setFolded(lastDelimColumn int, opt string) {
+ mstate := &MultiLineState{
+ isFolded: true,
+ opt: opt,
+ }
+ indent := firstLineIndentColumnByOpt(opt)
+ if indent > 0 {
+ mstate.firstLineIndentColumn = lastDelimColumn + indent
+ }
+ c.mstate = mstate
+}
+
+func (c *Context) setRawFolded(column int) {
+ mstate := &MultiLineState{
+ isRawFolded: true,
+ }
+ mstate.updateIndentColumn(column)
+ c.mstate = mstate
+}
+
+func firstLineIndentColumnByOpt(opt string) int {
+ opt = strings.TrimPrefix(opt, "-")
+ opt = strings.TrimPrefix(opt, "+")
+ opt = strings.TrimSuffix(opt, "-")
+ opt = strings.TrimSuffix(opt, "+")
+ i, _ := strconv.ParseInt(opt, 10, 64)
+ return int(i)
+}
+
+func (s *MultiLineState) lastDelimColumn() int {
+ if s.firstLineIndentColumn == 0 {
+ return 0
+ }
+ return s.firstLineIndentColumn - 1
+}
+
+func (s *MultiLineState) updateIndentColumn(column int) {
+ if s.firstLineIndentColumn == 0 {
+ s.firstLineIndentColumn = column
+ }
+ if s.lineIndentColumn == 0 {
+ s.lineIndentColumn = column
+ }
+}
+
+func (s *MultiLineState) updateSpaceOnlyIndentColumn(column int) {
+ if s.firstLineIndentColumn != 0 {
+ return
+ }
+ s.spaceOnlyIndentColumn = column
+}
+
+func (s *MultiLineState) validateIndentAfterSpaceOnly(column int) error {
+ if s.firstLineIndentColumn != 0 {
+ return nil
+ }
+ if s.spaceOnlyIndentColumn > column {
+ return errors.New("invalid number of indent is specified after space only")
+ }
+ return nil
+}
+
+func (s *MultiLineState) validateIndentColumn() error {
+ if firstLineIndentColumnByOpt(s.opt) == 0 {
+ return nil
+ }
+ if s.firstLineIndentColumn > s.lineIndentColumn {
+ return errors.New("invalid number of indent is specified in the multi-line header")
+ }
+ return nil
+}
+
+func (s *MultiLineState) updateNewLineState() {
+ s.prevLineIndentColumn = s.lineIndentColumn
+ if s.lineIndentColumn != 0 {
+ s.lastNotSpaceOnlyLineIndentColumn = s.lineIndentColumn
+ }
+ s.foldedNewLine = true
+ s.lineIndentColumn = 0
+}
+
+func (s *MultiLineState) isIndentColumn(column int) bool {
+ if s.firstLineIndentColumn == 0 {
+ return column == 1
+ }
+ return s.firstLineIndentColumn > column
+}
+
+func (s *MultiLineState) addIndent(ctx *Context, column int) {
+ if s.firstLineIndentColumn == 0 {
+ return
+ }
+
+ // If the first line of the document has already been evaluated, the number is treated as the threshold, since the `firstLineIndentColumn` is a positive number.
+ if column < s.firstLineIndentColumn {
+ return
+ }
+
+ // `c.foldedNewLine` is a variable that is set to true for every newline.
+ if !s.isLiteral && s.foldedNewLine {
+ s.foldedNewLine = false
+ }
+ // Since addBuf ignore space character, add to the buffer directly.
+ ctx.buf = append(ctx.buf, ' ')
+ ctx.notSpaceCharPos = len(ctx.buf)
+}
+
+// updateNewLineInFolded if Folded or RawFolded context and the content on the current line starts at the same column as the previous line,
+// treat the new-line-char as a space.
+func (s *MultiLineState) updateNewLineInFolded(ctx *Context, column int) {
+ if s.isLiteral {
+ return
+ }
+
+ // Folded or RawFolded.
+
+ if !s.foldedNewLine {
+ return
+ }
+ var (
+ lastChar rune
+ prevLastChar rune
+ )
+ if len(ctx.buf) != 0 {
+ lastChar = ctx.buf[len(ctx.buf)-1]
+ }
+ if len(ctx.buf) > 1 {
+ prevLastChar = ctx.buf[len(ctx.buf)-2]
+ }
+ if s.lineIndentColumn == s.prevLineIndentColumn {
+ // ---
+ // >
+ // a
+ // b
+ if lastChar == '\n' {
+ ctx.buf[len(ctx.buf)-1] = ' '
+ }
+ } else if s.prevLineIndentColumn == 0 && s.lastNotSpaceOnlyLineIndentColumn == column {
+ // if previous line is indent-space and new-line-char only, prevLineIndentColumn is zero.
+ // In this case, last new-line-char is removed.
+ // ---
+ // >
+ // a
+ //
+ // b
+ if lastChar == '\n' && prevLastChar == '\n' {
+ ctx.buf = ctx.buf[:len(ctx.buf)-1]
+ ctx.notSpaceCharPos = len(ctx.buf)
+ }
+ }
+ s.foldedNewLine = false
+}
+
+func (s *MultiLineState) hasTrimAllEndNewlineOpt() bool {
+ return strings.HasPrefix(s.opt, "-") || strings.HasSuffix(s.opt, "-") || s.isRawFolded
+}
+
+func (s *MultiLineState) hasKeepAllEndNewlineOpt() bool {
+ return strings.HasPrefix(s.opt, "+") || strings.HasSuffix(s.opt, "+")
+}
+
+func (c *Context) addToken(tk *token.Token) {
+ if tk == nil {
+ return
+ }
+ c.tokens = append(c.tokens, tk)
+}
+
+func (c *Context) addBuf(r rune) {
+ if len(c.buf) == 0 && (r == ' ' || r == '\t') {
+ return
+ }
+ c.buf = append(c.buf, r)
+ if r != ' ' && r != '\t' {
+ c.notSpaceCharPos = len(c.buf)
+ }
+}
+
+func (c *Context) addBufWithTab(r rune) {
+ if len(c.buf) == 0 && r == ' ' {
+ return
+ }
+ c.buf = append(c.buf, r)
+ if r != ' ' {
+ c.notSpaceCharPos = len(c.buf)
+ }
+}
+
+func (c *Context) addOriginBuf(r rune) {
+ c.obuf = append(c.obuf, r)
+ if r != ' ' && r != '\t' {
+ c.notSpaceOrgCharPos = len(c.obuf)
+ }
+}
+
+func (c *Context) removeRightSpaceFromBuf() {
+ trimmedBuf := c.obuf[:c.notSpaceOrgCharPos]
+ buflen := len(trimmedBuf)
+ diff := len(c.obuf) - buflen
+ if diff > 0 {
+ c.obuf = c.obuf[:buflen]
+ c.buf = c.bufferedSrc()
+ }
+}
+
+func (c *Context) isEOS() bool {
+ return len(c.src)-1 <= c.idx
+}
+
+func (c *Context) isNextEOS() bool {
+ return len(c.src) <= c.idx+1
+}
+
+func (c *Context) next() bool {
+ return c.idx < c.size
+}
+
+func (c *Context) source(s, e int) string {
+ return string(c.src[s:e])
+}
+
+func (c *Context) previousChar() rune {
+ if c.idx > 0 {
+ return c.src[c.idx-1]
+ }
+ return rune(0)
+}
+
+func (c *Context) currentChar() rune {
+ if c.size > c.idx {
+ return c.src[c.idx]
+ }
+ return rune(0)
+}
+
+func (c *Context) nextChar() rune {
+ if c.size > c.idx+1 {
+ return c.src[c.idx+1]
+ }
+ return rune(0)
+}
+
+func (c *Context) repeatNum(r rune) int {
+ cnt := 0
+ for i := c.idx; i < c.size; i++ {
+ if c.src[i] == r {
+ cnt++
+ } else {
+ break
+ }
+ }
+ return cnt
+}
+
+func (c *Context) progress(num int) {
+ c.idx += num
+}
+
+func (c *Context) existsBuffer() bool {
+ return len(c.bufferedSrc()) != 0
+}
+
+func (c *Context) isMultiLine() bool {
+ return c.mstate != nil
+}
+
+func (c *Context) bufferedSrc() []rune {
+ src := c.buf[:c.notSpaceCharPos]
+ if c.isMultiLine() {
+ mstate := c.getMultiLineState()
+ // remove end '\n' character and trailing empty lines.
+ // https://yaml.org/spec/1.2.2/#8112-block-chomping-indicator
+ if mstate.hasTrimAllEndNewlineOpt() {
+ // If the '-' flag is specified, all trailing newline characters will be removed.
+ src = []rune(strings.TrimRight(string(src), "\n"))
+ } else if !mstate.hasKeepAllEndNewlineOpt() {
+ // Normally, all but one of the trailing newline characters are removed.
+ var newLineCharCount int
+ for i := len(src) - 1; i >= 0; i-- {
+ if src[i] == '\n' {
+ newLineCharCount++
+ continue
+ }
+ break
+ }
+ removedNewLineCharCount := newLineCharCount - 1
+ for removedNewLineCharCount > 0 {
+ src = []rune(strings.TrimSuffix(string(src), "\n"))
+ removedNewLineCharCount--
+ }
+ }
+
+ // If the text ends with a space character, remove all of them.
+ if mstate.hasTrimAllEndNewlineOpt() {
+ src = []rune(strings.TrimRight(string(src), " "))
+ }
+ if string(src) == "\n" {
+ // If the content consists only of a newline,
+ // it can be considered as the document ending without any specified value,
+ // so it is treated as an empty string.
+ src = []rune{}
+ }
+ if mstate.hasKeepAllEndNewlineOpt() && len(src) == 0 {
+ src = []rune{'\n'}
+ }
+ }
+ return src
+}
+
+func (c *Context) bufferedToken(pos *token.Position) *token.Token {
+ if c.idx == 0 {
+ return nil
+ }
+ source := c.bufferedSrc()
+ if len(source) == 0 {
+ c.buf = c.buf[:0] // clear value's buffer only.
+ return nil
+ }
+ var tk *token.Token
+ if c.isMultiLine() {
+ tk = token.String(string(source), string(c.obuf), pos)
+ } else {
+ tk = token.New(string(source), string(c.obuf), pos)
+ }
+ c.setTokenTypeByPrevTag(tk)
+ c.resetBuffer()
+ return tk
+}
+
+func (c *Context) setTokenTypeByPrevTag(tk *token.Token) {
+ lastTk := c.lastToken()
+ if lastTk == nil {
+ return
+ }
+ if lastTk.Type != token.TagType {
+ return
+ }
+ tag := token.ReservedTagKeyword(lastTk.Value)
+ if _, exists := token.ReservedTagKeywordMap[tag]; !exists {
+ tk.Type = token.StringType
+ }
+}
+
+func (c *Context) lastToken() *token.Token {
+ if len(c.tokens) != 0 {
+ return c.tokens[len(c.tokens)-1]
+ }
+ return nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go
new file mode 100644
index 0000000..3f5419a
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/error.go
@@ -0,0 +1,17 @@
+package scanner
+
+import "github.com/goccy/go-yaml/token"
+
+type InvalidTokenError struct {
+ Token *token.Token
+}
+
+func (e *InvalidTokenError) Error() string {
+ return e.Token.Error
+}
+
+func ErrInvalidToken(tk *token.Token) *InvalidTokenError {
+ return &InvalidTokenError{
+ Token: tk,
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go b/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go
new file mode 100644
index 0000000..799f469
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/scanner/scanner.go
@@ -0,0 +1,1536 @@
+package scanner
+
+import (
+ "errors"
+ "fmt"
+ "io"
+ "strconv"
+ "strings"
+
+ "github.com/goccy/go-yaml/token"
+)
+
+// IndentState state for indent
+type IndentState int
+
+const (
+ // IndentStateEqual equals previous indent
+ IndentStateEqual IndentState = iota
+ // IndentStateUp more indent than previous
+ IndentStateUp
+ // IndentStateDown less indent than previous
+ IndentStateDown
+ // IndentStateKeep uses not indent token
+ IndentStateKeep
+)
+
+// Scanner holds the scanner's internal state while processing a given text.
+// It can be allocated as part of another data structure but must be initialized via Init before use.
+type Scanner struct {
+ source []rune
+ sourcePos int
+ sourceSize int
+ // line number. This number starts from 1.
+ line int
+ // column number. This number starts from 1.
+ column int
+ // offset represents the offset from the beginning of the source.
+ offset int
+ // lastDelimColumn is the last column needed to compare indent is retained.
+ lastDelimColumn int
+ // indentNum indicates the number of spaces used for indentation.
+ indentNum int
+ // prevLineIndentNum indicates the number of spaces used for indentation at previous line.
+ prevLineIndentNum int
+ // indentLevel indicates the level of indent depth. This value does not match the column value.
+ indentLevel int
+ isFirstCharAtLine bool
+ isAnchor bool
+ isAlias bool
+ isDirective bool
+ startedFlowSequenceNum int
+ startedFlowMapNum int
+ indentState IndentState
+ savedPos *token.Position
+}
+
+func (s *Scanner) pos() *token.Position {
+ return &token.Position{
+ Line: s.line,
+ Column: s.column,
+ Offset: s.offset,
+ IndentNum: s.indentNum,
+ IndentLevel: s.indentLevel,
+ }
+}
+
+func (s *Scanner) bufferedToken(ctx *Context) *token.Token {
+ if s.savedPos != nil {
+ tk := ctx.bufferedToken(s.savedPos)
+ s.savedPos = nil
+ return tk
+ }
+ line := s.line
+ column := s.column - len(ctx.buf)
+ level := s.indentLevel
+ if ctx.isMultiLine() {
+ line -= s.newLineCount(ctx.buf)
+ column = strings.Index(string(ctx.obuf), string(ctx.buf)) + 1
+ // Since we are in a literal, folded or raw folded
+ // we can use the indent level from the last token.
+ last := ctx.lastToken()
+ if last != nil { // The last token should never be nil here.
+ level = last.Position.IndentLevel + 1
+ }
+ }
+ return ctx.bufferedToken(&token.Position{
+ Line: line,
+ Column: column,
+ Offset: s.offset - len(ctx.buf),
+ IndentNum: s.indentNum,
+ IndentLevel: level,
+ })
+}
+
+func (s *Scanner) progressColumn(ctx *Context, num int) {
+ s.column += num
+ s.offset += num
+ s.progress(ctx, num)
+}
+
+func (s *Scanner) progressOnly(ctx *Context, num int) {
+ s.offset += num
+ s.progress(ctx, num)
+}
+
+func (s *Scanner) progressLine(ctx *Context) {
+ s.prevLineIndentNum = s.indentNum
+ s.column = 1
+ s.line++
+ s.offset++
+ s.indentNum = 0
+ s.isFirstCharAtLine = true
+ s.isAnchor = false
+ s.isAlias = false
+ s.isDirective = false
+ s.progress(ctx, 1)
+}
+
+func (s *Scanner) progress(ctx *Context, num int) {
+ ctx.progress(num)
+ s.sourcePos += num
+}
+
+func (s *Scanner) isNewLineChar(c rune) bool {
+ if c == '\n' {
+ return true
+ }
+ if c == '\r' {
+ return true
+ }
+ return false
+}
+
+func (s *Scanner) newLineCount(src []rune) int {
+ size := len(src)
+ cnt := 0
+ for i := 0; i < size; i++ {
+ c := src[i]
+ switch c {
+ case '\r':
+ if i+1 < size && src[i+1] == '\n' {
+ i++
+ }
+ cnt++
+ case '\n':
+ cnt++
+ }
+ }
+ return cnt
+}
+
+func (s *Scanner) updateIndentLevel() {
+ if s.prevLineIndentNum < s.indentNum {
+ s.indentLevel++
+ } else if s.prevLineIndentNum > s.indentNum {
+ if s.indentLevel > 0 {
+ s.indentLevel--
+ }
+ }
+}
+
+func (s *Scanner) updateIndentState(ctx *Context) {
+ if s.lastDelimColumn == 0 {
+ return
+ }
+
+ if s.lastDelimColumn < s.column {
+ s.indentState = IndentStateUp
+ } else {
+ // If lastDelimColumn and s.column are the same,
+ // treat as Down state since it is the same column as delimiter.
+ s.indentState = IndentStateDown
+ }
+}
+
+func (s *Scanner) updateIndent(ctx *Context, c rune) {
+ if s.isFirstCharAtLine && s.isNewLineChar(c) {
+ return
+ }
+ if s.isFirstCharAtLine && c == ' ' {
+ s.indentNum++
+ return
+ }
+ if s.isFirstCharAtLine && c == '\t' {
+ // found tab indent.
+ // In this case, scanTab returns error.
+ return
+ }
+ if !s.isFirstCharAtLine {
+ s.indentState = IndentStateKeep
+ return
+ }
+ s.updateIndentLevel()
+ s.updateIndentState(ctx)
+ s.isFirstCharAtLine = false
+}
+
+func (s *Scanner) isChangedToIndentStateDown() bool {
+ return s.indentState == IndentStateDown
+}
+
+func (s *Scanner) isChangedToIndentStateUp() bool {
+ return s.indentState == IndentStateUp
+}
+
+func (s *Scanner) addBufferedTokenIfExists(ctx *Context) {
+ ctx.addToken(s.bufferedToken(ctx))
+}
+
+func (s *Scanner) breakMultiLine(ctx *Context) {
+ ctx.breakMultiLine()
+}
+
+func (s *Scanner) scanSingleQuote(ctx *Context) (*token.Token, error) {
+ ctx.addOriginBuf('\'')
+ srcpos := s.pos()
+ startIndex := ctx.idx + 1
+ src := ctx.src
+ size := len(src)
+ value := []rune{}
+ isFirstLineChar := false
+ isNewLine := false
+
+ for idx := startIndex; idx < size; idx++ {
+ if !isNewLine {
+ s.progressColumn(ctx, 1)
+ } else {
+ isNewLine = false
+ }
+ c := src[idx]
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ notSpaceIdx := -1
+ for i := len(value) - 1; i >= 0; i-- {
+ if value[i] == ' ' {
+ continue
+ }
+ notSpaceIdx = i
+ break
+ }
+ if len(value) > notSpaceIdx {
+ value = value[:notSpaceIdx+1]
+ }
+ if isFirstLineChar {
+ value = append(value, '\n')
+ } else {
+ value = append(value, ' ')
+ }
+ isFirstLineChar = true
+ isNewLine = true
+ s.progressLine(ctx)
+ if idx+1 < size {
+ if err := s.validateDocumentSeparatorMarker(ctx, src[idx+1:]); err != nil {
+ return nil, err
+ }
+ }
+ continue
+ } else if isFirstLineChar && c == ' ' {
+ continue
+ } else if isFirstLineChar && c == '\t' {
+ if s.lastDelimColumn >= s.column {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "tab character cannot be used for indentation in single-quoted text",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ continue
+ } else if c != '\'' {
+ value = append(value, c)
+ isFirstLineChar = false
+ continue
+ } else if idx+1 < len(ctx.src) && ctx.src[idx+1] == '\'' {
+ // '' handle as ' character
+ value = append(value, c)
+ ctx.addOriginBuf(c)
+ idx++
+ s.progressColumn(ctx, 1)
+ continue
+ }
+ s.progressColumn(ctx, 1)
+ return token.SingleQuote(string(value), string(ctx.obuf), srcpos), nil
+ }
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "could not find end character of single-quoted text",
+ string(ctx.obuf), srcpos,
+ ),
+ )
+}
+
+func hexToInt(b rune) int {
+ if b >= 'A' && b <= 'F' {
+ return int(b) - 'A' + 10
+ }
+ if b >= 'a' && b <= 'f' {
+ return int(b) - 'a' + 10
+ }
+ return int(b) - '0'
+}
+
+func hexRunesToInt(b []rune) int {
+ sum := 0
+ for i := 0; i < len(b); i++ {
+ sum += hexToInt(b[i]) << (uint(len(b)-i-1) * 4)
+ }
+ return sum
+}
+
+func (s *Scanner) scanDoubleQuote(ctx *Context) (*token.Token, error) {
+ ctx.addOriginBuf('"')
+ srcpos := s.pos()
+ startIndex := ctx.idx + 1
+ src := ctx.src
+ size := len(src)
+ value := []rune{}
+ isFirstLineChar := false
+ isNewLine := false
+
+ for idx := startIndex; idx < size; idx++ {
+ if !isNewLine {
+ s.progressColumn(ctx, 1)
+ } else {
+ isNewLine = false
+ }
+ c := src[idx]
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ notSpaceIdx := -1
+ for i := len(value) - 1; i >= 0; i-- {
+ if value[i] == ' ' {
+ continue
+ }
+ notSpaceIdx = i
+ break
+ }
+ if len(value) > notSpaceIdx {
+ value = value[:notSpaceIdx+1]
+ }
+ if isFirstLineChar {
+ value = append(value, '\n')
+ } else {
+ value = append(value, ' ')
+ }
+ isFirstLineChar = true
+ isNewLine = true
+ s.progressLine(ctx)
+ if idx+1 < size {
+ if err := s.validateDocumentSeparatorMarker(ctx, src[idx+1:]); err != nil {
+ return nil, err
+ }
+ }
+ continue
+ } else if isFirstLineChar && c == ' ' {
+ continue
+ } else if isFirstLineChar && c == '\t' {
+ if s.lastDelimColumn >= s.column {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "tab character cannot be used for indentation in double-quoted text",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ continue
+ } else if c == '\\' {
+ isFirstLineChar = false
+ if idx+1 >= size {
+ value = append(value, c)
+ continue
+ }
+ nextChar := src[idx+1]
+ progress := 0
+ switch nextChar {
+ case '0':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x00)
+ case 'a':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x07)
+ case 'b':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x08)
+ case 't':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x09)
+ case 'n':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0A)
+ case 'v':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0B)
+ case 'f':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0C)
+ case 'r':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x0D)
+ case 'e':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x1B)
+ case ' ':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x20)
+ case '"':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x22)
+ case '/':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2F)
+ case '\\':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x5C)
+ case 'N':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x85)
+ case '_':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0xA0)
+ case 'L':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2028)
+ case 'P':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, 0x2029)
+ case 'x':
+ if idx+3 >= size {
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, nextChar)
+ } else {
+ progress = 3
+ codeNum := hexRunesToInt(src[idx+2 : idx+progress+1])
+ value = append(value, rune(codeNum))
+ }
+ case 'u':
+ // \u0000 style must have 5 characters at least.
+ if idx+5 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-16 character",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ progress = 5
+ codeNum := hexRunesToInt(src[idx+2 : idx+6])
+
+ // handle surrogate pairs.
+ if codeNum >= 0xD800 && codeNum <= 0xDBFF {
+ high := codeNum
+
+ // \u0000\u0000 style must have 11 characters at least.
+ if idx+11 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-16 surrogate pair",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+
+ if src[idx+6] != '\\' || src[idx+7] != 'u' {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "found unexpected character after high surrogate for UTF-16 surrogate pair",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+
+ low := hexRunesToInt(src[idx+8 : idx+12])
+ if low < 0xDC00 || low > 0xDFFF {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "found unexpected low surrogate after high surrogate",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ codeNum = ((high - 0xD800) * 0x400) + (low - 0xDC00) + 0x10000
+ progress += 6
+ }
+ value = append(value, rune(codeNum))
+ case 'U':
+ // \U00000000 style must have 9 characters at least.
+ if idx+9 >= size {
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "not enough length for escaped UTF-32 character",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ progress = 9
+ codeNum := hexRunesToInt(src[idx+2 : idx+10])
+ value = append(value, rune(codeNum))
+ case '\n':
+ isFirstLineChar = true
+ isNewLine = true
+ ctx.addOriginBuf(nextChar)
+ s.progressColumn(ctx, 1)
+ s.progressLine(ctx)
+ idx++
+ continue
+ case '\r':
+ isFirstLineChar = true
+ isNewLine = true
+ ctx.addOriginBuf(nextChar)
+ s.progressLine(ctx)
+ progress = 1
+ // Skip \n after \r in CRLF sequences
+ if idx+2 < size && src[idx+2] == '\n' {
+ ctx.addOriginBuf('\n')
+ progress = 2
+ }
+ case '\t':
+ progress = 1
+ ctx.addOriginBuf(nextChar)
+ value = append(value, nextChar)
+ default:
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ fmt.Sprintf("found unknown escape character %q", nextChar),
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ idx += progress
+ s.progressColumn(ctx, progress)
+ continue
+ } else if c == '\t' {
+ var (
+ foundNotSpaceChar bool
+ progress int
+ )
+ for i := idx + 1; i < size; i++ {
+ if src[i] == ' ' || src[i] == '\t' {
+ progress++
+ continue
+ }
+ if s.isNewLineChar(src[i]) {
+ break
+ }
+ foundNotSpaceChar = true
+ }
+ if foundNotSpaceChar {
+ value = append(value, c)
+ if src[idx+1] != '"' {
+ s.progressColumn(ctx, 1)
+ }
+ } else {
+ idx += progress
+ s.progressColumn(ctx, progress)
+ }
+ continue
+ } else if c != '"' {
+ value = append(value, c)
+ isFirstLineChar = false
+ continue
+ }
+ s.progressColumn(ctx, 1)
+ return token.DoubleQuote(string(value), string(ctx.obuf), srcpos), nil
+ }
+ s.progressColumn(ctx, 1)
+ return nil, ErrInvalidToken(
+ token.Invalid(
+ "could not find end character of double-quoted text",
+ string(ctx.obuf), srcpos,
+ ),
+ )
+}
+
+func (s *Scanner) validateDocumentSeparatorMarker(ctx *Context, src []rune) error {
+ if s.foundDocumentSeparatorMarker(src) {
+ return ErrInvalidToken(
+ token.Invalid("found unexpected document separator", string(ctx.obuf), s.pos()),
+ )
+ }
+ return nil
+}
+
+func (s *Scanner) foundDocumentSeparatorMarker(src []rune) bool {
+ if len(src) < 3 {
+ return false
+ }
+ var marker string
+ if len(src) == 3 {
+ marker = string(src)
+ } else {
+ marker = strings.TrimRightFunc(string(src[:4]), func(r rune) bool {
+ return r == ' ' || r == '\t' || r == '\n' || r == '\r'
+ })
+ }
+ return marker == "---" || marker == "..."
+}
+
+func (s *Scanner) scanQuote(ctx *Context, ch rune) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+ if ch == '\'' {
+ tk, err := s.scanSingleQuote(ctx)
+ if err != nil {
+ return false, err
+ }
+ ctx.addToken(tk)
+ } else {
+ tk, err := s.scanDoubleQuote(ctx)
+ if err != nil {
+ return false, err
+ }
+ ctx.addToken(tk)
+ }
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanWhiteSpace(ctx *Context) bool {
+ if ctx.isMultiLine() {
+ return false
+ }
+ if !s.isAnchor && !s.isDirective && !s.isAlias && !s.isFirstCharAtLine {
+ return false
+ }
+
+ if s.isFirstCharAtLine {
+ s.progressColumn(ctx, 1)
+ ctx.addOriginBuf(' ')
+ return true
+ }
+ if s.isDirective {
+ s.addBufferedTokenIfExists(ctx)
+ s.progressColumn(ctx, 1)
+ ctx.addOriginBuf(' ')
+ return true
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ s.isAnchor = false
+ s.isAlias = false
+ return true
+}
+
+func (s *Scanner) isMergeKey(ctx *Context) bool {
+ if ctx.repeatNum('<') != 2 {
+ return false
+ }
+ src := ctx.src
+ size := len(src)
+ for idx := ctx.idx + 2; idx < size; idx++ {
+ c := src[idx]
+ if c == ' ' {
+ continue
+ }
+ if c != ':' {
+ return false
+ }
+ if idx+1 < size {
+ nc := src[idx+1]
+ if nc == ' ' || s.isNewLineChar(nc) {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+func (s *Scanner) scanTag(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() || s.isDirective {
+ return false, nil
+ }
+
+ ctx.addOriginBuf('!')
+ s.progress(ctx, 1) // skip '!' character
+
+ var progress int
+ for idx, c := range ctx.src[ctx.idx:] {
+ progress = idx + 1
+ switch c {
+ case ' ':
+ ctx.addOriginBuf(c)
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value)))
+ ctx.clear()
+ return true, nil
+ case ',':
+ if s.startedFlowSequenceNum > 0 || s.startedFlowMapNum > 0 {
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value))-1) // progress column before collect-entry for scanning it at scanFlowEntry function.
+ ctx.clear()
+ return true, nil
+ } else {
+ ctx.addOriginBuf(c)
+ }
+ case '\n', '\r':
+ ctx.addOriginBuf(c)
+ value := ctx.source(ctx.idx-1, ctx.idx+idx)
+ ctx.addToken(token.Tag(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, len([]rune(value))-1) // progress column before new-line-char for scanning new-line-char at scanNewLine function.
+ ctx.clear()
+ return true, nil
+ case '{', '}':
+ ctx.addOriginBuf(c)
+ s.progressColumn(ctx, progress)
+ invalidTk := token.Invalid(fmt.Sprintf("found invalid tag character %q", c), string(ctx.obuf), s.pos())
+ return false, ErrInvalidToken(invalidTk)
+ default:
+ ctx.addOriginBuf(c)
+ }
+ }
+ s.progressColumn(ctx, progress)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanComment(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ c := ctx.previousChar()
+ if c != ' ' && c != '\t' && !s.isNewLineChar(c) {
+ return false
+ }
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('#')
+ s.progress(ctx, 1) // skip '#' character
+
+ for idx, c := range ctx.src[ctx.idx:] {
+ ctx.addOriginBuf(c)
+ if !s.isNewLineChar(c) {
+ continue
+ }
+ if ctx.previousChar() == '\\' {
+ continue
+ }
+ value := ctx.source(ctx.idx, ctx.idx+idx)
+ progress := len([]rune(value))
+ ctx.addToken(token.Comment(value, string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, progress)
+ s.progressLine(ctx)
+ ctx.clear()
+ return true
+ }
+ // document ends with comment.
+ value := string(ctx.src[ctx.idx:])
+ ctx.addToken(token.Comment(value, string(ctx.obuf), s.pos()))
+ progress := len([]rune(value))
+ s.progressColumn(ctx, progress)
+ s.progressLine(ctx)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMultiLine(ctx *Context, c rune) error {
+ state := ctx.getMultiLineState()
+ ctx.addOriginBuf(c)
+ // normalize CR and CRLF to LF
+ if c == '\r' {
+ if ctx.nextChar() == '\n' {
+ ctx.addOriginBuf('\n')
+ s.progress(ctx, 1)
+ s.offset++
+ }
+ c = '\n'
+ }
+ if ctx.isEOS() {
+ if s.isFirstCharAtLine && c == ' ' {
+ state.addIndent(ctx, s.column)
+ } else {
+ ctx.addBuf(c)
+ }
+ state.updateIndentColumn(s.column)
+ if err := state.validateIndentColumn(); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ value := ctx.bufferedSrc()
+ ctx.addToken(token.String(string(value), string(ctx.obuf), s.pos()))
+ ctx.clear()
+ s.progressColumn(ctx, 1)
+ } else if s.isNewLineChar(c) {
+ ctx.addBuf(c)
+ state.updateSpaceOnlyIndentColumn(s.column - 1)
+ state.updateNewLineState()
+ s.progressLine(ctx)
+ if ctx.next() {
+ if s.foundDocumentSeparatorMarker(ctx.src[ctx.idx:]) {
+ value := ctx.bufferedSrc()
+ ctx.addToken(token.String(string(value), string(ctx.obuf), s.pos()))
+ ctx.clear()
+ s.breakMultiLine(ctx)
+ }
+ }
+ } else if s.isFirstCharAtLine && c == ' ' {
+ state.addIndent(ctx, s.column)
+ s.progressColumn(ctx, 1)
+ } else if s.isFirstCharAtLine && c == '\t' && state.isIndentColumn(s.column) {
+ err := ErrInvalidToken(
+ token.Invalid(
+ "found a tab character where an indentation space is expected",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ return err
+ } else if c == '\t' && !state.isIndentColumn(s.column) {
+ ctx.addBufWithTab(c)
+ s.progressColumn(ctx, 1)
+ } else {
+ if err := state.validateIndentAfterSpaceOnly(s.column); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ state.updateIndentColumn(s.column)
+ if err := state.validateIndentColumn(); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return ErrInvalidToken(invalidTk)
+ }
+ if col := state.lastDelimColumn(); col > 0 {
+ s.lastDelimColumn = col
+ }
+ state.updateNewLineInFolded(ctx, s.column)
+ ctx.addBufWithTab(c)
+ s.progressColumn(ctx, 1)
+ }
+ return nil
+}
+
+func (s *Scanner) scanNewLine(ctx *Context, c rune) {
+ if len(ctx.buf) > 0 && s.savedPos == nil {
+ bufLen := len(ctx.bufferedSrc())
+ s.savedPos = s.pos()
+ s.savedPos.Column -= bufLen
+ s.savedPos.Offset -= bufLen
+ }
+
+ // if the following case, origin buffer has unnecessary two spaces.
+ // So, `removeRightSpaceFromOriginBuf` remove them, also fix column number too.
+ // ---
+ // a:[space][space]
+ // b: c
+ ctx.removeRightSpaceFromBuf()
+
+ // There is no problem that we ignore CR which followed by LF and normalize it to LF, because of following YAML1.2 spec.
+ // > Line breaks inside scalar content must be normalized by the YAML processor. Each such line break must be parsed into a single line feed character.
+ // > Outside scalar content, YAML allows any line break to be used to terminate lines.
+ // > -- https://yaml.org/spec/1.2/spec.html
+ if c == '\r' && ctx.nextChar() == '\n' {
+ ctx.addOriginBuf('\r')
+ s.progress(ctx, 1)
+ s.offset++
+ c = '\n'
+ }
+
+ if ctx.isEOS() {
+ s.addBufferedTokenIfExists(ctx)
+ } else if s.isAnchor || s.isAlias || s.isDirective {
+ s.addBufferedTokenIfExists(ctx)
+ }
+ if ctx.existsBuffer() && s.isFirstCharAtLine {
+ if ctx.buf[len(ctx.buf)-1] == ' ' {
+ ctx.buf[len(ctx.buf)-1] = '\n'
+ } else {
+ ctx.buf = append(ctx.buf, '\n')
+ }
+ } else {
+ ctx.addBuf(' ')
+ }
+ ctx.addOriginBuf(c)
+ s.progressLine(ctx)
+}
+
+func (s *Scanner) isFlowMode() bool {
+ if s.startedFlowSequenceNum > 0 {
+ return true
+ }
+ if s.startedFlowMapNum > 0 {
+ return true
+ }
+ return false
+}
+
+func (s *Scanner) scanFlowMapStart(ctx *Context) bool {
+ if ctx.existsBuffer() && !s.isFlowMode() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('{')
+ ctx.addToken(token.MappingStart(string(ctx.obuf), s.pos()))
+ s.startedFlowMapNum++
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowMapEnd(ctx *Context) bool {
+ if s.startedFlowMapNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('}')
+ ctx.addToken(token.MappingEnd(string(ctx.obuf), s.pos()))
+ s.startedFlowMapNum--
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowArrayStart(ctx *Context) bool {
+ if ctx.existsBuffer() && !s.isFlowMode() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('[')
+ ctx.addToken(token.SequenceStart(string(ctx.obuf), s.pos()))
+ s.startedFlowSequenceNum++
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowArrayEnd(ctx *Context) bool {
+ if ctx.existsBuffer() && s.startedFlowSequenceNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf(']')
+ ctx.addToken(token.SequenceEnd(string(ctx.obuf), s.pos()))
+ s.startedFlowSequenceNum--
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanFlowEntry(ctx *Context, c rune) bool {
+ if s.startedFlowSequenceNum <= 0 && s.startedFlowMapNum <= 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf(c)
+ ctx.addToken(token.CollectEntry(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMapDelim(ctx *Context) (bool, error) {
+ nc := ctx.nextChar()
+ if s.isDirective || s.isAnchor || s.isAlias {
+ return false, nil
+ }
+ if s.startedFlowMapNum <= 0 && nc != ' ' && nc != '\t' && !s.isNewLineChar(nc) && !ctx.isNextEOS() {
+ return false, nil
+ }
+ if s.startedFlowMapNum > 0 && nc == '/' {
+ // like http://
+ return false, nil
+ }
+ if s.startedFlowMapNum > 0 {
+ tk := ctx.lastToken()
+ if tk != nil && tk.Type == token.MappingValueType {
+ return false, nil
+ }
+ }
+
+ if strings.HasPrefix(strings.TrimPrefix(string(ctx.obuf), " "), "\t") && !strings.HasPrefix(string(ctx.buf), "\t") {
+ invalidTk := token.Invalid("tab character cannot use as a map key directly", string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return false, ErrInvalidToken(invalidTk)
+ }
+
+ // mapping value
+ tk := s.bufferedToken(ctx)
+ if tk != nil {
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ } else if tk := ctx.lastToken(); tk != nil {
+ // If the map key is quote, the buffer does not exist because it has already been cut into tokens.
+ // Therefore, we need to check the last token.
+ if tk.Indicator == token.QuotedScalarIndicator {
+ s.lastDelimColumn = tk.Position.Column
+ }
+ }
+ ctx.addToken(token.MappingValue(s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanDocumentStart(ctx *Context) bool {
+ if s.indentNum != 0 {
+ return false
+ }
+ if s.column != 1 {
+ return false
+ }
+ if ctx.repeatNum('-') != 3 {
+ return false
+ }
+ if ctx.size > ctx.idx+3 {
+ c := ctx.src[ctx.idx+3]
+ if c != ' ' && c != '\t' && c != '\n' && c != '\r' {
+ return false
+ }
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addToken(token.DocumentHeader(string(ctx.obuf)+"---", s.pos()))
+ s.progressColumn(ctx, 3)
+ ctx.clear()
+ s.clearState()
+ return true
+}
+
+func (s *Scanner) scanDocumentEnd(ctx *Context) bool {
+ if s.indentNum != 0 {
+ return false
+ }
+ if s.column != 1 {
+ return false
+ }
+ if ctx.repeatNum('.') != 3 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addToken(token.DocumentEnd(string(ctx.obuf)+"...", s.pos()))
+ s.progressColumn(ctx, 3)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanMergeKey(ctx *Context) bool {
+ if !s.isMergeKey(ctx) {
+ return false
+ }
+
+ s.lastDelimColumn = s.column
+ ctx.addToken(token.MergeKey(string(ctx.obuf)+"<<", s.pos()))
+ s.progressColumn(ctx, 2)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanRawFoldedChar(ctx *Context) bool {
+ if !ctx.existsBuffer() {
+ return false
+ }
+ if !s.isChangedToIndentStateUp() {
+ return false
+ }
+
+ ctx.setRawFolded(s.column)
+ ctx.addBuf('-')
+ ctx.addOriginBuf('-')
+ s.progressColumn(ctx, 1)
+ return true
+}
+
+func (s *Scanner) scanSequence(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+
+ nc := ctx.nextChar()
+ if nc != 0 && nc != ' ' && nc != '\t' && !s.isNewLineChar(nc) {
+ return false, nil
+ }
+
+ if strings.HasPrefix(strings.TrimPrefix(string(ctx.obuf), " "), "\t") {
+ invalidTk := token.Invalid("tab character cannot use as a sequence delimiter", string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, 1)
+ return false, ErrInvalidToken(invalidTk)
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('-')
+ tk := token.SequenceEntry(string(ctx.obuf), s.pos())
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true, nil
+}
+
+func (s *Scanner) scanMultiLineHeader(ctx *Context) (bool, error) {
+ if ctx.existsBuffer() {
+ return false, nil
+ }
+
+ if err := s.scanMultiLineHeaderOption(ctx); err != nil {
+ return false, err
+ }
+ s.progressLine(ctx)
+ return true, nil
+}
+
+func (s *Scanner) validateMultiLineHeaderOption(opt string) error {
+ if len(opt) == 0 {
+ return nil
+ }
+ orgOpt := opt
+ opt = strings.TrimPrefix(opt, "-")
+ opt = strings.TrimPrefix(opt, "+")
+ opt = strings.TrimSuffix(opt, "-")
+ opt = strings.TrimSuffix(opt, "+")
+ if len(opt) == 0 {
+ return nil
+ }
+ if opt == "0" {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ i, err := strconv.ParseInt(opt, 10, 64)
+ if err != nil {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ if i > 9 {
+ return fmt.Errorf("invalid header option: %q", orgOpt)
+ }
+ return nil
+}
+
+func (s *Scanner) scanMultiLineHeaderOption(ctx *Context) error {
+ header := ctx.currentChar()
+ ctx.addOriginBuf(header)
+ s.progress(ctx, 1) // skip '|' or '>' character
+
+ var progress int
+ var crlf bool
+ for idx, c := range ctx.src[ctx.idx:] {
+ progress = idx
+ ctx.addOriginBuf(c)
+ if s.isNewLineChar(c) {
+ nextIdx := ctx.idx + idx + 1
+ if c == '\r' && nextIdx < len(ctx.src) && ctx.src[nextIdx] == '\n' {
+ crlf = true
+ continue // process \n in the next iteration
+ }
+ break
+ }
+ }
+ endPos := ctx.idx + progress
+ if crlf {
+ // Exclude \r
+ endPos = endPos - 1
+ }
+ value := strings.TrimRight(ctx.source(ctx.idx, endPos), " ")
+ commentValueIndex := strings.Index(value, "#")
+ opt := value
+ if commentValueIndex > 0 {
+ opt = value[:commentValueIndex]
+ }
+ opt = strings.TrimRightFunc(opt, func(r rune) bool {
+ return r == ' ' || r == '\t'
+ })
+ if len(opt) != 0 {
+ if err := s.validateMultiLineHeaderOption(opt); err != nil {
+ invalidTk := token.Invalid(err.Error(), string(ctx.obuf), s.pos())
+ s.progressColumn(ctx, progress)
+ return ErrInvalidToken(invalidTk)
+ }
+ }
+ if s.column == 1 {
+ s.lastDelimColumn = 1
+ }
+
+ commentIndex := strings.Index(string(ctx.obuf), "#")
+ headerBuf := string(ctx.obuf)
+ if commentIndex > 0 {
+ headerBuf = headerBuf[:commentIndex]
+ }
+ switch header {
+ case '|':
+ ctx.addToken(token.Literal("|"+opt, headerBuf, s.pos()))
+ ctx.setLiteral(s.lastDelimColumn, opt)
+ case '>':
+ ctx.addToken(token.Folded(">"+opt, headerBuf, s.pos()))
+ ctx.setFolded(s.lastDelimColumn, opt)
+ }
+ if commentIndex > 0 {
+ comment := value[commentValueIndex+1:]
+ s.offset += len(headerBuf)
+ s.column += len(headerBuf)
+ ctx.addToken(token.Comment(comment, string(ctx.obuf[len(headerBuf):]), s.pos()))
+ }
+ s.indentState = IndentStateKeep
+ ctx.resetBuffer()
+ s.progressColumn(ctx, progress)
+ return nil
+}
+
+func (s *Scanner) scanMapKey(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ nc := ctx.nextChar()
+ if nc != ' ' && nc != '\t' {
+ return false
+ }
+
+ tk := token.MappingKey(s.pos())
+ s.lastDelimColumn = tk.Position.Column
+ ctx.addToken(tk)
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanDirective(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+ if s.indentNum != 0 {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('%')
+ ctx.addToken(token.Directive(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ s.isDirective = true
+ return true
+}
+
+func (s *Scanner) scanAnchor(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('&')
+ ctx.addToken(token.Anchor(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ s.isAnchor = true
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanAlias(ctx *Context) bool {
+ if ctx.existsBuffer() {
+ return false
+ }
+
+ s.addBufferedTokenIfExists(ctx)
+ ctx.addOriginBuf('*')
+ ctx.addToken(token.Alias(string(ctx.obuf), s.pos()))
+ s.progressColumn(ctx, 1)
+ s.isAlias = true
+ ctx.clear()
+ return true
+}
+
+func (s *Scanner) scanReservedChar(ctx *Context, c rune) error {
+ if ctx.existsBuffer() {
+ return nil
+ }
+
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ err := ErrInvalidToken(
+ token.Invalid(
+ fmt.Sprintf("%q is a reserved character", c),
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return err
+}
+
+func (s *Scanner) scanTab(ctx *Context, c rune) error {
+ if s.startedFlowSequenceNum > 0 || s.startedFlowMapNum > 0 {
+ // tabs character is allowed in flow mode.
+ return nil
+ }
+
+ if !s.isFirstCharAtLine {
+ return nil
+ }
+
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ err := ErrInvalidToken(
+ token.Invalid("found character '\t' that cannot start any token",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ s.progressColumn(ctx, 1)
+ ctx.clear()
+ return err
+}
+
+func (s *Scanner) scan(ctx *Context) error {
+ for ctx.next() {
+ c := ctx.currentChar()
+ // First, change the IndentState.
+ // If the target character is the first character in a line, IndentState is Up/Down/Equal state.
+ // The second and subsequent letters are Keep.
+ s.updateIndent(ctx, c)
+
+ // If IndentState is down, tokens are split, so the buffer accumulated until that point needs to be cutted as a token.
+ if s.isChangedToIndentStateDown() {
+ s.addBufferedTokenIfExists(ctx)
+ }
+ if ctx.isMultiLine() {
+ if s.isChangedToIndentStateDown() {
+ if tk := ctx.lastToken(); tk != nil {
+ // If literal/folded content is empty, no string token is added.
+ // Therefore, add an empty string token.
+ // But if literal/folded token column is 1, it is invalid at down state.
+ if tk.Position.Column == 1 {
+ return ErrInvalidToken(
+ token.Invalid(
+ "could not find multi-line content",
+ string(ctx.obuf), s.pos(),
+ ),
+ )
+ }
+ if tk.Type != token.StringType {
+ ctx.addToken(token.String("", "", s.pos()))
+ }
+ }
+ s.breakMultiLine(ctx)
+ } else {
+ if err := s.scanMultiLine(ctx, c); err != nil {
+ return err
+ }
+ continue
+ }
+ }
+ switch c {
+ case '{':
+ if s.scanFlowMapStart(ctx) {
+ continue
+ }
+ case '}':
+ if s.scanFlowMapEnd(ctx) {
+ continue
+ }
+ case '.':
+ if s.scanDocumentEnd(ctx) {
+ continue
+ }
+ case '<':
+ if s.scanMergeKey(ctx) {
+ continue
+ }
+ case '-':
+ if s.scanDocumentStart(ctx) {
+ continue
+ }
+ if s.scanRawFoldedChar(ctx) {
+ continue
+ }
+ scanned, err := s.scanSequence(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '[':
+ if s.scanFlowArrayStart(ctx) {
+ continue
+ }
+ case ']':
+ if s.scanFlowArrayEnd(ctx) {
+ continue
+ }
+ case ',':
+ if s.scanFlowEntry(ctx, c) {
+ continue
+ }
+ case ':':
+ scanned, err := s.scanMapDelim(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '|', '>':
+ scanned, err := s.scanMultiLineHeader(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '!':
+ scanned, err := s.scanTag(ctx)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '%':
+ if s.scanDirective(ctx) {
+ continue
+ }
+ case '?':
+ if s.scanMapKey(ctx) {
+ continue
+ }
+ case '&':
+ if s.scanAnchor(ctx) {
+ continue
+ }
+ case '*':
+ if s.scanAlias(ctx) {
+ continue
+ }
+ case '#':
+ if s.scanComment(ctx) {
+ continue
+ }
+ case '\'', '"':
+ scanned, err := s.scanQuote(ctx, c)
+ if err != nil {
+ return err
+ }
+ if scanned {
+ continue
+ }
+ case '\r', '\n':
+ s.scanNewLine(ctx, c)
+ continue
+ case ' ':
+ if s.scanWhiteSpace(ctx) {
+ continue
+ }
+ case '@', '`':
+ if err := s.scanReservedChar(ctx, c); err != nil {
+ return err
+ }
+ case '\t':
+ if ctx.existsBuffer() && s.lastDelimColumn == 0 {
+ // tab indent for plain text (yaml-test-suite's spec-example-7-12-plain-lines).
+ s.indentNum++
+ ctx.addOriginBuf(c)
+ s.progressOnly(ctx, 1)
+ continue
+ }
+ if s.lastDelimColumn < s.column {
+ s.indentNum++
+ ctx.addOriginBuf(c)
+ s.progressOnly(ctx, 1)
+ continue
+ }
+ if err := s.scanTab(ctx, c); err != nil {
+ return err
+ }
+ }
+ ctx.addBuf(c)
+ ctx.addOriginBuf(c)
+ s.progressColumn(ctx, 1)
+ }
+ s.addBufferedTokenIfExists(ctx)
+ return nil
+}
+
+// Init prepares the scanner s to tokenize the text src by setting the scanner at the beginning of src.
+func (s *Scanner) Init(text string) {
+ src := []rune(text)
+ s.source = src
+ s.sourcePos = 0
+ s.sourceSize = len(src)
+ s.line = 1
+ s.column = 1
+ s.offset = 1
+ s.isFirstCharAtLine = true
+ s.clearState()
+}
+
+func (s *Scanner) clearState() {
+ s.prevLineIndentNum = 0
+ s.lastDelimColumn = 0
+ s.indentLevel = 0
+ s.indentNum = 0
+}
+
+// Scan scans the next token and returns the token collection. The source end is indicated by io.EOF.
+func (s *Scanner) Scan() (token.Tokens, error) {
+ if s.sourcePos >= s.sourceSize {
+ return nil, io.EOF
+ }
+ ctx := newContext(s.source[s.sourcePos:])
+ defer ctx.release()
+
+ var tokens token.Tokens
+ err := s.scan(ctx)
+ tokens = append(tokens, ctx.tokens...)
+
+ if err != nil {
+ var invalidTokenErr *InvalidTokenError
+ if errors.As(err, &invalidTokenErr) {
+ tokens = append(tokens, invalidTokenErr.Token)
+ }
+ return tokens, err
+ }
+ return tokens, nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go b/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go
new file mode 100644
index 0000000..120448d
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/stdlib_quote.go
@@ -0,0 +1,113 @@
+// Copied and trimmed down from https://github.com/golang/go/blob/e3769299cd3484e018e0e2a6e1b95c2b18ce4f41/src/strconv/quote.go
+// We want to use the standard library's private "quoteWith" function rather than write our own so that we get robust unicode support.
+// Every private function called by quoteWith was copied.
+// There are 2 modifications to simplify the code:
+// 1. The unicode.IsPrint function was substituted for the custom implementation of IsPrint
+// 2. All code paths reachable only when ASCIIonly or grphicOnly are set to true were removed.
+
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+package yaml
+
+import (
+ "unicode"
+ "unicode/utf8"
+)
+
+const (
+ lowerhex = "0123456789abcdef"
+)
+
+func quoteWith(s string, quote byte) string {
+ return string(appendQuotedWith(make([]byte, 0, 3*len(s)/2), s, quote))
+}
+
+func appendQuotedWith(buf []byte, s string, quote byte) []byte {
+ // Often called with big strings, so preallocate. If there's quoting,
+ // this is conservative but still helps a lot.
+ if cap(buf)-len(buf) < len(s) {
+ nBuf := make([]byte, len(buf), len(buf)+1+len(s)+1)
+ copy(nBuf, buf)
+ buf = nBuf
+ }
+ buf = append(buf, quote)
+ for width := 0; len(s) > 0; s = s[width:] {
+ r := rune(s[0])
+ width = 1
+ if r >= utf8.RuneSelf {
+ r, width = utf8.DecodeRuneInString(s)
+ }
+ if width == 1 && r == utf8.RuneError {
+ buf = append(buf, `\x`...)
+ buf = append(buf, lowerhex[s[0]>>4])
+ buf = append(buf, lowerhex[s[0]&0xF])
+ continue
+ }
+ buf = appendEscapedRune(buf, r, quote)
+ }
+ buf = append(buf, quote)
+ return buf
+}
+
+func appendEscapedRune(buf []byte, r rune, quote byte) []byte {
+ var runeTmp [utf8.UTFMax]byte
+ // goccy/go-yaml patch on top of the standard library's appendEscapedRune function.
+ //
+ // We use this to implement the YAML single-quoted string, where the only escape sequence is '', which represents a single quote.
+ // The below snippet from the standard library is for escaping e.g. \ with \\, which is not what we want for the single-quoted string.
+ //
+ // if r == rune(quote) || r == '\\' { // always backslashed
+ // buf = append(buf, '\\')
+ // buf = append(buf, byte(r))
+ // return buf
+ // }
+ if r == rune(quote) {
+ buf = append(buf, byte(r))
+ buf = append(buf, byte(r))
+ return buf
+ }
+ if unicode.IsPrint(r) {
+ n := utf8.EncodeRune(runeTmp[:], r)
+ buf = append(buf, runeTmp[:n]...)
+ return buf
+ }
+ switch r {
+ case '\a':
+ buf = append(buf, `\a`...)
+ case '\b':
+ buf = append(buf, `\b`...)
+ case '\f':
+ buf = append(buf, `\f`...)
+ case '\n':
+ buf = append(buf, `\n`...)
+ case '\r':
+ buf = append(buf, `\r`...)
+ case '\t':
+ buf = append(buf, `\t`...)
+ case '\v':
+ buf = append(buf, `\v`...)
+ default:
+ switch {
+ case r < ' ':
+ buf = append(buf, `\x`...)
+ buf = append(buf, lowerhex[byte(r)>>4])
+ buf = append(buf, lowerhex[byte(r)&0xF])
+ case r > utf8.MaxRune:
+ r = 0xFFFD
+ fallthrough
+ case r < 0x10000:
+ buf = append(buf, `\u`...)
+ for s := 12; s >= 0; s -= 4 {
+ buf = append(buf, lowerhex[r>>uint(s)&0xF])
+ }
+ default:
+ buf = append(buf, `\U`...)
+ for s := 28; s >= 0; s -= 4 {
+ buf = append(buf, lowerhex[r>>uint(s)&0xF])
+ }
+ }
+ }
+ return buf
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/struct.go b/sesh/vendor/github.com/goccy/go-yaml/struct.go
new file mode 100644
index 0000000..ece77f5
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/struct.go
@@ -0,0 +1,128 @@
+package yaml
+
+import (
+ "fmt"
+ "reflect"
+ "strings"
+)
+
+const (
+ // StructTagName tag keyword for Marshal/Unmarshal
+ StructTagName = "yaml"
+)
+
+// StructField information for each the field in structure
+type StructField struct {
+ FieldName string
+ RenderName string
+ AnchorName string
+ AliasName string
+ IsAutoAnchor bool
+ IsAutoAlias bool
+ IsOmitEmpty bool
+ IsOmitZero bool
+ IsFlow bool
+ IsInline bool
+}
+
+func getTag(field reflect.StructField) string {
+ // If struct tag `yaml` exist, use that. If no `yaml`
+ // exists, but `json` does, use that and try the best to
+ // adhere to its rules
+ tag := field.Tag.Get(StructTagName)
+ if tag == "" {
+ tag = field.Tag.Get(`json`)
+ }
+ return tag
+}
+
+func structField(field reflect.StructField) *StructField {
+ tag := getTag(field)
+ fieldName := strings.ToLower(field.Name)
+ options := strings.Split(tag, ",")
+ if len(options) > 0 {
+ if options[0] != "" {
+ fieldName = options[0]
+ }
+ }
+ sf := &StructField{
+ FieldName: field.Name,
+ RenderName: fieldName,
+ }
+ if len(options) > 1 {
+ for _, opt := range options[1:] {
+ switch {
+ case opt == "omitempty":
+ sf.IsOmitEmpty = true
+ case opt == "omitzero":
+ sf.IsOmitZero = true
+ case opt == "flow":
+ sf.IsFlow = true
+ case opt == "inline":
+ sf.IsInline = true
+ case strings.HasPrefix(opt, "anchor"):
+ anchor := strings.Split(opt, "=")
+ if len(anchor) > 1 {
+ sf.AnchorName = anchor[1]
+ } else {
+ sf.IsAutoAnchor = true
+ }
+ case strings.HasPrefix(opt, "alias"):
+ alias := strings.Split(opt, "=")
+ if len(alias) > 1 {
+ sf.AliasName = alias[1]
+ } else {
+ sf.IsAutoAlias = true
+ }
+ default:
+ }
+ }
+ }
+ return sf
+}
+
+func isIgnoredStructField(field reflect.StructField) bool {
+ if field.PkgPath != "" && !field.Anonymous {
+ // private field
+ return true
+ }
+ return getTag(field) == "-"
+}
+
+type StructFieldMap map[string]*StructField
+
+func (m StructFieldMap) isIncludedRenderName(name string) bool {
+ for _, v := range m {
+ if !v.IsInline && v.RenderName == name {
+ return true
+ }
+ }
+ return false
+}
+
+func (m StructFieldMap) hasMergeProperty() bool {
+ for _, v := range m {
+ if v.IsOmitEmpty && v.IsInline && v.IsAutoAlias {
+ return true
+ }
+ }
+ return false
+}
+
+func structFieldMap(structType reflect.Type) (StructFieldMap, error) {
+ fieldMap := StructFieldMap{}
+ renderNameMap := map[string]struct{}{}
+ for i := 0; i < structType.NumField(); i++ {
+ field := structType.Field(i)
+ if isIgnoredStructField(field) {
+ continue
+ }
+ sf := structField(field)
+ if _, exists := renderNameMap[sf.RenderName]; exists {
+ return nil, fmt.Errorf("duplicated struct field name %s", sf.RenderName)
+ }
+ fieldMap[sf.FieldName] = sf
+ renderNameMap[sf.RenderName] = struct{}{}
+ }
+ return fieldMap, nil
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/token/token.go b/sesh/vendor/github.com/goccy/go-yaml/token/token.go
new file mode 100644
index 0000000..e887356
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/token/token.go
@@ -0,0 +1,1177 @@
+package token
+
+import (
+ "errors"
+ "fmt"
+ "strconv"
+ "strings"
+ "time"
+)
+
+// Character type for character
+type Character byte
+
+const (
+ // SequenceEntryCharacter character for sequence entry
+ SequenceEntryCharacter Character = '-'
+ // MappingKeyCharacter character for mapping key
+ MappingKeyCharacter Character = '?'
+ // MappingValueCharacter character for mapping value
+ MappingValueCharacter Character = ':'
+ // CollectEntryCharacter character for collect entry
+ CollectEntryCharacter Character = ','
+ // SequenceStartCharacter character for sequence start
+ SequenceStartCharacter Character = '['
+ // SequenceEndCharacter character for sequence end
+ SequenceEndCharacter Character = ']'
+ // MappingStartCharacter character for mapping start
+ MappingStartCharacter Character = '{'
+ // MappingEndCharacter character for mapping end
+ MappingEndCharacter Character = '}'
+ // CommentCharacter character for comment
+ CommentCharacter Character = '#'
+ // AnchorCharacter character for anchor
+ AnchorCharacter Character = '&'
+ // AliasCharacter character for alias
+ AliasCharacter Character = '*'
+ // TagCharacter character for tag
+ TagCharacter Character = '!'
+ // LiteralCharacter character for literal
+ LiteralCharacter Character = '|'
+ // FoldedCharacter character for folded
+ FoldedCharacter Character = '>'
+ // SingleQuoteCharacter character for single quote
+ SingleQuoteCharacter Character = '\''
+ // DoubleQuoteCharacter character for double quote
+ DoubleQuoteCharacter Character = '"'
+ // DirectiveCharacter character for directive
+ DirectiveCharacter Character = '%'
+ // SpaceCharacter character for space
+ SpaceCharacter Character = ' '
+ // LineBreakCharacter character for line break
+ LineBreakCharacter Character = '\n'
+)
+
+// Type type identifier for token
+type Type int
+
+const (
+ // UnknownType reserve for invalid type
+ UnknownType Type = iota
+ // DocumentHeaderType type for DocumentHeader token
+ DocumentHeaderType
+ // DocumentEndType type for DocumentEnd token
+ DocumentEndType
+ // SequenceEntryType type for SequenceEntry token
+ SequenceEntryType
+ // MappingKeyType type for MappingKey token
+ MappingKeyType
+ // MappingValueType type for MappingValue token
+ MappingValueType
+ // MergeKeyType type for MergeKey token
+ MergeKeyType
+ // CollectEntryType type for CollectEntry token
+ CollectEntryType
+ // SequenceStartType type for SequenceStart token
+ SequenceStartType
+ // SequenceEndType type for SequenceEnd token
+ SequenceEndType
+ // MappingStartType type for MappingStart token
+ MappingStartType
+ // MappingEndType type for MappingEnd token
+ MappingEndType
+ // CommentType type for Comment token
+ CommentType
+ // AnchorType type for Anchor token
+ AnchorType
+ // AliasType type for Alias token
+ AliasType
+ // TagType type for Tag token
+ TagType
+ // LiteralType type for Literal token
+ LiteralType
+ // FoldedType type for Folded token
+ FoldedType
+ // SingleQuoteType type for SingleQuote token
+ SingleQuoteType
+ // DoubleQuoteType type for DoubleQuote token
+ DoubleQuoteType
+ // DirectiveType type for Directive token
+ DirectiveType
+ // SpaceType type for Space token
+ SpaceType
+ // NullType type for Null token
+ NullType
+ // ImplicitNullType type for implicit Null token.
+ // This is used when explicit keywords such as null or ~ are not specified.
+ // It is distinguished during encoding and output as an empty string.
+ ImplicitNullType
+ // InfinityType type for Infinity token
+ InfinityType
+ // NanType type for Nan token
+ NanType
+ // IntegerType type for Integer token
+ IntegerType
+ // BinaryIntegerType type for BinaryInteger token
+ BinaryIntegerType
+ // OctetIntegerType type for OctetInteger token
+ OctetIntegerType
+ // HexIntegerType type for HexInteger token
+ HexIntegerType
+ // FloatType type for Float token
+ FloatType
+ // StringType type for String token
+ StringType
+ // BoolType type for Bool token
+ BoolType
+ // InvalidType type for invalid token
+ InvalidType
+)
+
+// String type identifier to text
+func (t Type) String() string {
+ switch t {
+ case UnknownType:
+ return "Unknown"
+ case DocumentHeaderType:
+ return "DocumentHeader"
+ case DocumentEndType:
+ return "DocumentEnd"
+ case SequenceEntryType:
+ return "SequenceEntry"
+ case MappingKeyType:
+ return "MappingKey"
+ case MappingValueType:
+ return "MappingValue"
+ case MergeKeyType:
+ return "MergeKey"
+ case CollectEntryType:
+ return "CollectEntry"
+ case SequenceStartType:
+ return "SequenceStart"
+ case SequenceEndType:
+ return "SequenceEnd"
+ case MappingStartType:
+ return "MappingStart"
+ case MappingEndType:
+ return "MappingEnd"
+ case CommentType:
+ return "Comment"
+ case AnchorType:
+ return "Anchor"
+ case AliasType:
+ return "Alias"
+ case TagType:
+ return "Tag"
+ case LiteralType:
+ return "Literal"
+ case FoldedType:
+ return "Folded"
+ case SingleQuoteType:
+ return "SingleQuote"
+ case DoubleQuoteType:
+ return "DoubleQuote"
+ case DirectiveType:
+ return "Directive"
+ case SpaceType:
+ return "Space"
+ case StringType:
+ return "String"
+ case BoolType:
+ return "Bool"
+ case IntegerType:
+ return "Integer"
+ case BinaryIntegerType:
+ return "BinaryInteger"
+ case OctetIntegerType:
+ return "OctetInteger"
+ case HexIntegerType:
+ return "HexInteger"
+ case FloatType:
+ return "Float"
+ case NullType:
+ return "Null"
+ case ImplicitNullType:
+ return "ImplicitNull"
+ case InfinityType:
+ return "Infinity"
+ case NanType:
+ return "Nan"
+ case InvalidType:
+ return "Invalid"
+ }
+ return ""
+}
+
+// CharacterType type for character category
+type CharacterType int
+
+const (
+ // CharacterTypeIndicator type of indicator character
+ CharacterTypeIndicator CharacterType = iota
+ // CharacterTypeWhiteSpace type of white space character
+ CharacterTypeWhiteSpace
+ // CharacterTypeMiscellaneous type of miscellaneous character
+ CharacterTypeMiscellaneous
+ // CharacterTypeEscaped type of escaped character
+ CharacterTypeEscaped
+ // CharacterTypeInvalid type for a invalid token.
+ CharacterTypeInvalid
+)
+
+// String character type identifier to text
+func (c CharacterType) String() string {
+ switch c {
+ case CharacterTypeIndicator:
+ return "Indicator"
+ case CharacterTypeWhiteSpace:
+ return "WhiteSpace"
+ case CharacterTypeMiscellaneous:
+ return "Miscellaneous"
+ case CharacterTypeEscaped:
+ return "Escaped"
+ }
+ return ""
+}
+
+// Indicator type for indicator
+type Indicator int
+
+const (
+ // NotIndicator not indicator
+ NotIndicator Indicator = iota
+ // BlockStructureIndicator indicator for block structure ( '-', '?', ':' )
+ BlockStructureIndicator
+ // FlowCollectionIndicator indicator for flow collection ( '[', ']', '{', '}', ',' )
+ FlowCollectionIndicator
+ // CommentIndicator indicator for comment ( '#' )
+ CommentIndicator
+ // NodePropertyIndicator indicator for node property ( '!', '&', '*' )
+ NodePropertyIndicator
+ // BlockScalarIndicator indicator for block scalar ( '|', '>' )
+ BlockScalarIndicator
+ // QuotedScalarIndicator indicator for quoted scalar ( ''', '"' )
+ QuotedScalarIndicator
+ // DirectiveIndicator indicator for directive ( '%' )
+ DirectiveIndicator
+ // InvalidUseOfReservedIndicator indicator for invalid use of reserved keyword ( '@', '`' )
+ InvalidUseOfReservedIndicator
+)
+
+// String indicator to text
+func (i Indicator) String() string {
+ switch i {
+ case NotIndicator:
+ return "NotIndicator"
+ case BlockStructureIndicator:
+ return "BlockStructure"
+ case FlowCollectionIndicator:
+ return "FlowCollection"
+ case CommentIndicator:
+ return "Comment"
+ case NodePropertyIndicator:
+ return "NodeProperty"
+ case BlockScalarIndicator:
+ return "BlockScalar"
+ case QuotedScalarIndicator:
+ return "QuotedScalar"
+ case DirectiveIndicator:
+ return "Directive"
+ case InvalidUseOfReservedIndicator:
+ return "InvalidUseOfReserved"
+ }
+ return ""
+}
+
+var (
+ reservedNullKeywords = []string{
+ "null",
+ "Null",
+ "NULL",
+ "~",
+ }
+ reservedBoolKeywords = []string{
+ "true",
+ "True",
+ "TRUE",
+ "false",
+ "False",
+ "FALSE",
+ }
+ // For compatibility with other YAML 1.1 parsers
+ // Note that we use these solely for encoding the bool value with quotes.
+ // go-yaml should not treat these as reserved keywords at parsing time.
+ // as go-yaml is supposed to be compliant only with YAML 1.2.
+ reservedLegacyBoolKeywords = []string{
+ "y",
+ "Y",
+ "yes",
+ "Yes",
+ "YES",
+ "n",
+ "N",
+ "no",
+ "No",
+ "NO",
+ "on",
+ "On",
+ "ON",
+ "off",
+ "Off",
+ "OFF",
+ }
+ reservedInfKeywords = []string{
+ ".inf",
+ ".Inf",
+ ".INF",
+ "-.inf",
+ "-.Inf",
+ "-.INF",
+ }
+ reservedNanKeywords = []string{
+ ".nan",
+ ".NaN",
+ ".NAN",
+ }
+ reservedKeywordMap = map[string]func(string, string, *Position) *Token{}
+ // reservedEncKeywordMap contains is the keyword map used at encoding time.
+ // This is supposed to be a superset of reservedKeywordMap,
+ // and used to quote legacy keywords present in YAML 1.1 or lesser for compatibility reasons,
+ // even though this library is supposed to be YAML 1.2-compliant.
+ reservedEncKeywordMap = map[string]func(string, string, *Position) *Token{}
+)
+
+func reservedKeywordToken(typ Type, value, org string, pos *Position) *Token {
+ return &Token{
+ Type: typ,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+func init() {
+ for _, keyword := range reservedNullKeywords {
+ f := func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(NullType, value, org, pos)
+ }
+
+ reservedKeywordMap[keyword] = f
+ reservedEncKeywordMap[keyword] = f
+ }
+ for _, keyword := range reservedBoolKeywords {
+ f := func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(BoolType, value, org, pos)
+ }
+ reservedKeywordMap[keyword] = f
+ reservedEncKeywordMap[keyword] = f
+ }
+ for _, keyword := range reservedLegacyBoolKeywords {
+ reservedEncKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(BoolType, value, org, pos)
+ }
+ }
+ for _, keyword := range reservedInfKeywords {
+ reservedKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(InfinityType, value, org, pos)
+ }
+ }
+ for _, keyword := range reservedNanKeywords {
+ reservedKeywordMap[keyword] = func(value, org string, pos *Position) *Token {
+ return reservedKeywordToken(NanType, value, org, pos)
+ }
+ }
+}
+
+// ReservedTagKeyword type of reserved tag keyword
+type ReservedTagKeyword string
+
+const (
+ // IntegerTag `!!int` tag
+ IntegerTag ReservedTagKeyword = "!!int"
+ // FloatTag `!!float` tag
+ FloatTag ReservedTagKeyword = "!!float"
+ // NullTag `!!null` tag
+ NullTag ReservedTagKeyword = "!!null"
+ // SequenceTag `!!seq` tag
+ SequenceTag ReservedTagKeyword = "!!seq"
+ // MappingTag `!!map` tag
+ MappingTag ReservedTagKeyword = "!!map"
+ // StringTag `!!str` tag
+ StringTag ReservedTagKeyword = "!!str"
+ // BinaryTag `!!binary` tag
+ BinaryTag ReservedTagKeyword = "!!binary"
+ // OrderedMapTag `!!omap` tag
+ OrderedMapTag ReservedTagKeyword = "!!omap"
+ // SetTag `!!set` tag
+ SetTag ReservedTagKeyword = "!!set"
+ // TimestampTag `!!timestamp` tag
+ TimestampTag ReservedTagKeyword = "!!timestamp"
+ // BooleanTag `!!bool` tag
+ BooleanTag ReservedTagKeyword = "!!bool"
+ // MergeTag `!!merge` tag
+ MergeTag ReservedTagKeyword = "!!merge"
+)
+
+var (
+ // ReservedTagKeywordMap map for reserved tag keywords
+ ReservedTagKeywordMap = map[ReservedTagKeyword]func(string, string, *Position) *Token{
+ IntegerTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ FloatTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ NullTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ SequenceTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ MappingTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ StringTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ BinaryTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ OrderedMapTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ SetTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ TimestampTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ BooleanTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ MergeTag: func(value, org string, pos *Position) *Token {
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ },
+ }
+)
+
+type NumberType string
+
+const (
+ NumberTypeDecimal NumberType = "decimal"
+ NumberTypeBinary NumberType = "binary"
+ NumberTypeOctet NumberType = "octet"
+ NumberTypeHex NumberType = "hex"
+ NumberTypeFloat NumberType = "float"
+)
+
+type NumberValue struct {
+ Type NumberType
+ Value any
+ Text string
+}
+
+func ToNumber(value string) *NumberValue {
+ num, err := toNumber(value)
+ if err != nil {
+ return nil
+ }
+ return num
+}
+
+func isNumber(value string) bool {
+ num, err := toNumber(value)
+ if err != nil {
+ var numErr *strconv.NumError
+ if errors.As(err, &numErr) && errors.Is(numErr.Err, strconv.ErrRange) {
+ return true
+ }
+ return false
+ }
+ return num != nil
+}
+
+func toNumber(value string) (*NumberValue, error) {
+ if len(value) == 0 {
+ return nil, nil
+ }
+ if strings.HasPrefix(value, "_") {
+ return nil, nil
+ }
+ dotCount := strings.Count(value, ".")
+ if dotCount > 1 {
+ return nil, nil
+ }
+
+ isNegative := strings.HasPrefix(value, "-")
+ normalized := strings.ReplaceAll(strings.TrimPrefix(strings.TrimPrefix(value, "+"), "-"), "_", "")
+
+ var (
+ typ NumberType
+ base int
+ )
+ switch {
+ case strings.HasPrefix(normalized, "0x"):
+ normalized = strings.TrimPrefix(normalized, "0x")
+ base = 16
+ typ = NumberTypeHex
+ case strings.HasPrefix(normalized, "0o"):
+ normalized = strings.TrimPrefix(normalized, "0o")
+ base = 8
+ typ = NumberTypeOctet
+ case strings.HasPrefix(normalized, "0b"):
+ normalized = strings.TrimPrefix(normalized, "0b")
+ base = 2
+ typ = NumberTypeBinary
+ case strings.HasPrefix(normalized, "0") && len(normalized) > 1 && dotCount == 0:
+ base = 8
+ typ = NumberTypeOctet
+ case dotCount == 1:
+ typ = NumberTypeFloat
+ default:
+ typ = NumberTypeDecimal
+ base = 10
+ }
+
+ text := normalized
+ if isNegative {
+ text = "-" + text
+ }
+
+ var v any
+ if typ == NumberTypeFloat {
+ f, err := strconv.ParseFloat(text, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = f
+ } else if isNegative {
+ i, err := strconv.ParseInt(text, base, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = i
+ } else {
+ u, err := strconv.ParseUint(text, base, 64)
+ if err != nil {
+ return nil, err
+ }
+ v = u
+ }
+
+ return &NumberValue{
+ Type: typ,
+ Value: v,
+ Text: text,
+ }, nil
+}
+
+// This is a subset of the formats permitted by the regular expression
+// defined at http://yaml.org/type/timestamp.html. Note that time.Parse
+// cannot handle: "2001-12-14 21:59:43.10 -5" from the examples.
+var timestampFormats = []string{
+ time.RFC3339Nano,
+ "2006-01-02t15:04:05.999999999Z07:00", // RFC3339Nano with lower-case "t".
+ time.DateTime,
+ time.DateOnly,
+
+ // Not in examples, but to preserve backward compatibility by quoting time values.
+ "15:4",
+}
+
+func isTimestamp(value string) bool {
+ for _, format := range timestampFormats {
+ if _, err := time.Parse(format, value); err == nil {
+ return true
+ }
+ }
+ return false
+}
+
+// IsNeedQuoted checks whether the value needs quote for passed string or not
+func IsNeedQuoted(value string) bool {
+ if value == "" {
+ return true
+ }
+ if _, exists := reservedEncKeywordMap[value]; exists {
+ return true
+ }
+ if isNumber(value) {
+ return true
+ }
+ if value == "-" {
+ return true
+ }
+ first := value[0]
+ switch first {
+ case '*', '&', '[', '{', '}', ']', ',', '!', '|', '>', '%', '\'', '"', '@', ' ', '`':
+ return true
+ }
+ last := value[len(value)-1]
+ switch last {
+ case ':', ' ':
+ return true
+ }
+ if isTimestamp(value) {
+ return true
+ }
+ for i, c := range value {
+ switch c {
+ case '#', '\\':
+ return true
+ case ':', '-':
+ if i+1 < len(value) && value[i+1] == ' ' {
+ return true
+ }
+ }
+ }
+ return false
+}
+
+// LiteralBlockHeader detect literal block scalar header
+func LiteralBlockHeader(value string) string {
+ lbc := DetectLineBreakCharacter(value)
+
+ switch {
+ case !strings.Contains(value, lbc):
+ return ""
+ case strings.HasSuffix(value, fmt.Sprintf("%s%s", lbc, lbc)):
+ return "|+"
+ case strings.HasSuffix(value, lbc):
+ return "|"
+ default:
+ return "|-"
+ }
+}
+
+// New create reserved keyword token or number token and other string token.
+func New(value string, org string, pos *Position) *Token {
+ fn := reservedKeywordMap[value]
+ if fn != nil {
+ return fn(value, org, pos)
+ }
+ if num := ToNumber(value); num != nil {
+ tk := &Token{
+ Type: IntegerType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+ switch num.Type {
+ case NumberTypeFloat:
+ tk.Type = FloatType
+ case NumberTypeBinary:
+ tk.Type = BinaryIntegerType
+ case NumberTypeOctet:
+ tk.Type = OctetIntegerType
+ case NumberTypeHex:
+ tk.Type = HexIntegerType
+ }
+ return tk
+ }
+ return String(value, org, pos)
+}
+
+// Position type for position in YAML document
+type Position struct {
+ Line int
+ Column int
+ Offset int
+ IndentNum int
+ IndentLevel int
+}
+
+// String position to text
+func (p *Position) String() string {
+ return fmt.Sprintf("[level:%d,line:%d,column:%d,offset:%d]", p.IndentLevel, p.Line, p.Column, p.Offset)
+}
+
+// Token type for token
+type Token struct {
+ // Type is a token type.
+ Type Type
+ // CharacterType is a character type.
+ CharacterType CharacterType
+ // Indicator is a indicator type.
+ Indicator Indicator
+ // Value is a string extracted with only meaningful characters, with spaces and such removed.
+ Value string
+ // Origin is a string that stores the original text as-is.
+ Origin string
+ // Error keeps error message for InvalidToken.
+ Error string
+ // Position is a token position.
+ Position *Position
+ // Next is a next token reference.
+ Next *Token
+ // Prev is a previous token reference.
+ Prev *Token
+}
+
+// PreviousType previous token type
+func (t *Token) PreviousType() Type {
+ if t.Prev != nil {
+ return t.Prev.Type
+ }
+ return UnknownType
+}
+
+// NextType next token type
+func (t *Token) NextType() Type {
+ if t.Next != nil {
+ return t.Next.Type
+ }
+ return UnknownType
+}
+
+// AddColumn append column number to current position of column
+func (t *Token) AddColumn(col int) {
+ if t == nil {
+ return
+ }
+ t.Position.Column += col
+}
+
+// Clone copy token ( preserve Prev/Next reference )
+func (t *Token) Clone() *Token {
+ if t == nil {
+ return nil
+ }
+ copied := *t
+ if t.Position != nil {
+ pos := *(t.Position)
+ copied.Position = &pos
+ }
+ return &copied
+}
+
+// Dump outputs token information to stdout for debugging.
+func (t *Token) Dump() {
+ fmt.Printf(
+ "[TYPE]:%q [CHARTYPE]:%q [INDICATOR]:%q [VALUE]:%q [ORG]:%q [POS(line:column:level:offset)]: %d:%d:%d:%d\n",
+ t.Type, t.CharacterType, t.Indicator, t.Value, t.Origin, t.Position.Line, t.Position.Column, t.Position.IndentLevel, t.Position.Offset,
+ )
+}
+
+// Tokens type of token collection
+type Tokens []*Token
+
+func (t Tokens) InvalidToken() *Token {
+ for _, tt := range t {
+ if tt.Type == InvalidType {
+ return tt
+ }
+ }
+ return nil
+}
+
+func (t *Tokens) add(tk *Token) {
+ tokens := *t
+ if len(tokens) == 0 {
+ tokens = append(tokens, tk)
+ } else {
+ last := tokens[len(tokens)-1]
+ last.Next = tk
+ tk.Prev = last
+ tokens = append(tokens, tk)
+ }
+ *t = tokens
+}
+
+// Add append new some tokens
+func (t *Tokens) Add(tks ...*Token) {
+ for _, tk := range tks {
+ t.add(tk)
+ }
+}
+
+// Dump dump all token structures for debugging
+func (t Tokens) Dump() {
+ for _, tk := range t {
+ fmt.Print("- ")
+ tk.Dump()
+ }
+}
+
+// String create token for String
+func String(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: StringType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceEntry create token for SequenceEntry
+func SequenceEntry(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceEntryType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(SequenceEntryCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingKey create token for MappingKey
+func MappingKey(pos *Position) *Token {
+ return &Token{
+ Type: MappingKeyType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(MappingKeyCharacter),
+ Origin: string(MappingKeyCharacter),
+ Position: pos,
+ }
+}
+
+// MappingValue create token for MappingValue
+func MappingValue(pos *Position) *Token {
+ return &Token{
+ Type: MappingValueType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockStructureIndicator,
+ Value: string(MappingValueCharacter),
+ Origin: string(MappingValueCharacter),
+ Position: pos,
+ }
+}
+
+// CollectEntry create token for CollectEntry
+func CollectEntry(org string, pos *Position) *Token {
+ return &Token{
+ Type: CollectEntryType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(CollectEntryCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceStart create token for SequenceStart
+func SequenceStart(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceStartType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(SequenceStartCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SequenceEnd create token for SequenceEnd
+func SequenceEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: SequenceEndType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(SequenceEndCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingStart create token for MappingStart
+func MappingStart(org string, pos *Position) *Token {
+ return &Token{
+ Type: MappingStartType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(MappingStartCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// MappingEnd create token for MappingEnd
+func MappingEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: MappingEndType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: FlowCollectionIndicator,
+ Value: string(MappingEndCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Comment create token for Comment
+func Comment(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: CommentType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: CommentIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Anchor create token for Anchor
+func Anchor(org string, pos *Position) *Token {
+ return &Token{
+ Type: AnchorType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: string(AnchorCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Alias create token for Alias
+func Alias(org string, pos *Position) *Token {
+ return &Token{
+ Type: AliasType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: string(AliasCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Tag create token for Tag
+func Tag(value string, org string, pos *Position) *Token {
+ fn := ReservedTagKeywordMap[ReservedTagKeyword(value)]
+ if fn != nil {
+ return fn(value, org, pos)
+ }
+ return &Token{
+ Type: TagType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: NodePropertyIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Literal create token for Literal
+func Literal(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: LiteralType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Folded create token for Folded
+func Folded(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: FoldedType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: BlockScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// SingleQuote create token for SingleQuote
+func SingleQuote(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: SingleQuoteType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: QuotedScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DoubleQuote create token for DoubleQuote
+func DoubleQuote(value string, org string, pos *Position) *Token {
+ return &Token{
+ Type: DoubleQuoteType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: QuotedScalarIndicator,
+ Value: value,
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Directive create token for Directive
+func Directive(org string, pos *Position) *Token {
+ return &Token{
+ Type: DirectiveType,
+ CharacterType: CharacterTypeIndicator,
+ Indicator: DirectiveIndicator,
+ Value: string(DirectiveCharacter),
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// Space create token for Space
+func Space(pos *Position) *Token {
+ return &Token{
+ Type: SpaceType,
+ CharacterType: CharacterTypeWhiteSpace,
+ Indicator: NotIndicator,
+ Value: string(SpaceCharacter),
+ Origin: string(SpaceCharacter),
+ Position: pos,
+ }
+}
+
+// MergeKey create token for MergeKey
+func MergeKey(org string, pos *Position) *Token {
+ return &Token{
+ Type: MergeKeyType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "<<",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DocumentHeader create token for DocumentHeader
+func DocumentHeader(org string, pos *Position) *Token {
+ return &Token{
+ Type: DocumentHeaderType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "---",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+// DocumentEnd create token for DocumentEnd
+func DocumentEnd(org string, pos *Position) *Token {
+ return &Token{
+ Type: DocumentEndType,
+ CharacterType: CharacterTypeMiscellaneous,
+ Indicator: NotIndicator,
+ Value: "...",
+ Origin: org,
+ Position: pos,
+ }
+}
+
+func Invalid(err string, org string, pos *Position) *Token {
+ return &Token{
+ Type: InvalidType,
+ CharacterType: CharacterTypeInvalid,
+ Indicator: NotIndicator,
+ Value: org,
+ Origin: org,
+ Error: err,
+ Position: pos,
+ }
+}
+
+// DetectLineBreakCharacter detect line break character in only one inside scalar content scope.
+func DetectLineBreakCharacter(src string) string {
+ nc := strings.Count(src, "\n")
+ rc := strings.Count(src, "\r")
+ rnc := strings.Count(src, "\r\n")
+ switch {
+ case nc == rnc && rc == rnc:
+ return "\r\n"
+ case rc > nc:
+ return "\r"
+ default:
+ return "\n"
+ }
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/validate.go b/sesh/vendor/github.com/goccy/go-yaml/validate.go
new file mode 100644
index 0000000..20a2d6d
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/validate.go
@@ -0,0 +1,13 @@
+package yaml
+
+// StructValidator need to implement Struct method only
+// ( see https://pkg.go.dev/github.com/go-playground/validator/v10#Validate.Struct )
+type StructValidator interface {
+ Struct(interface{}) error
+}
+
+// FieldError need to implement StructField method only
+// ( see https://pkg.go.dev/github.com/go-playground/validator/v10#FieldError )
+type FieldError interface {
+ StructField() string
+}
diff --git a/sesh/vendor/github.com/goccy/go-yaml/yaml.go b/sesh/vendor/github.com/goccy/go-yaml/yaml.go
new file mode 100644
index 0000000..e1b5fbd
--- /dev/null
+++ b/sesh/vendor/github.com/goccy/go-yaml/yaml.go
@@ -0,0 +1,357 @@
+package yaml
+
+import (
+ "bytes"
+ "context"
+ "io"
+ "reflect"
+ "sync"
+
+ "github.com/goccy/go-yaml/ast"
+ "github.com/goccy/go-yaml/internal/errors"
+)
+
+// BytesMarshaler interface may be implemented by types to customize their
+// behavior when being marshaled into a YAML document. The returned value
+// is marshaled in place of the original value implementing Marshaler.
+//
+// If an error is returned by MarshalYAML, the marshaling procedure stops
+// and returns with the provided error.
+type BytesMarshaler interface {
+ MarshalYAML() ([]byte, error)
+}
+
+// BytesMarshalerContext interface use BytesMarshaler with context.Context.
+type BytesMarshalerContext interface {
+ MarshalYAML(context.Context) ([]byte, error)
+}
+
+// InterfaceMarshaler interface has MarshalYAML compatible with github.com/go-yaml/yaml package.
+type InterfaceMarshaler interface {
+ MarshalYAML() (interface{}, error)
+}
+
+// InterfaceMarshalerContext interface use InterfaceMarshaler with context.Context.
+type InterfaceMarshalerContext interface {
+ MarshalYAML(context.Context) (interface{}, error)
+}
+
+// BytesUnmarshaler interface may be implemented by types to customize their
+// behavior when being unmarshaled from a YAML document.
+type BytesUnmarshaler interface {
+ UnmarshalYAML([]byte) error
+}
+
+// BytesUnmarshalerContext interface use BytesUnmarshaler with context.Context.
+type BytesUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, []byte) error
+}
+
+// InterfaceUnmarshaler interface has UnmarshalYAML compatible with github.com/go-yaml/yaml package.
+type InterfaceUnmarshaler interface {
+ UnmarshalYAML(func(interface{}) error) error
+}
+
+// InterfaceUnmarshalerContext interface use InterfaceUnmarshaler with context.Context.
+type InterfaceUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, func(interface{}) error) error
+}
+
+// NodeUnmarshaler interface is similar to BytesUnmarshaler but provide related AST node instead of raw YAML source.
+type NodeUnmarshaler interface {
+ UnmarshalYAML(ast.Node) error
+}
+
+// NodeUnmarshalerContext interface is similar to BytesUnmarshaler but provide related AST node instead of raw YAML source.
+type NodeUnmarshalerContext interface {
+ UnmarshalYAML(context.Context, ast.Node) error
+}
+
+// MapItem is an item in a MapSlice.
+type MapItem struct {
+ Key, Value interface{}
+}
+
+// MapSlice encodes and decodes as a YAML map.
+// The order of keys is preserved when encoding and decoding.
+type MapSlice []MapItem
+
+// ToMap convert to map[interface{}]interface{}.
+func (s MapSlice) ToMap() map[interface{}]interface{} {
+ v := map[interface{}]interface{}{}
+ for _, item := range s {
+ v[item.Key] = item.Value
+ }
+ return v
+}
+
+// Marshal serializes the value provided into a YAML document. The structure
+// of the generated document will reflect the structure of the value itself.
+// Maps and pointers (to struct, string, int, etc) are accepted as the in value.
+//
+// Struct fields are only marshaled if they are exported (have an upper case
+// first letter), and are marshaled using the field name lowercased as the
+// default key. Custom keys may be defined via the "yaml" name in the field
+// tag: the content preceding the first comma is used as the key, and the
+// following comma-separated options are used to tweak the marshaling process.
+// Conflicting names result in a runtime error.
+//
+// The field tag format accepted is:
+//
+// `(...) yaml:"[][,[,]]" (...)`
+//
+// The following flags are currently supported:
+//
+// omitempty Only include the field if it's not set to the zero
+// value for the type or to empty slices or maps.
+// Zero valued structs will be omitted if all their public
+// fields are zero, unless they implement an IsZero
+// method (see the IsZeroer interface type), in which
+// case the field will be included if that method returns true.
+// Note that this definition is slightly different from the Go's
+// encoding/json 'omitempty' definition. It combines some elements
+// of 'omitempty' and 'omitzero'. See https://github.com/goccy/go-yaml/issues/695.
+//
+// omitzero The omitzero tag behaves in the same way as the interpretation of the omitzero tag in the encoding/json library.
+// 1) If the field type has an "IsZero() bool" method, that will be used to determine whether the value is zero.
+// 2) Otherwise, the value is zero if it is the zero value for its type.
+//
+// flow Marshal using a flow style (useful for structs,
+// sequences and maps).
+//
+// inline Inline the field, which must be a struct or a map,
+// causing all of its fields or keys to be processed as if
+// they were part of the outer struct. For maps, keys must
+// not conflict with the yaml keys of other struct fields.
+//
+// anchor Marshal with anchor. If want to define anchor name explicitly, use anchor=name style.
+// Otherwise, if used 'anchor' name only, used the field name lowercased as the anchor name
+//
+// alias Marshal with alias. If want to define alias name explicitly, use alias=name style.
+// Otherwise, If omitted alias name and the field type is pointer type,
+// assigned anchor name automatically from same pointer address.
+//
+// In addition, if the key is "-", the field is ignored.
+//
+// For example:
+//
+// type T struct {
+// F int `yaml:"a,omitempty"`
+// B int
+// }
+// yaml.Marshal(&T{B: 2}) // Returns "b: 2\n"
+// yaml.Marshal(&T{F: 1}) // Returns "a: 1\nb: 0\n"
+func Marshal(v interface{}) ([]byte, error) {
+ return MarshalWithOptions(v)
+}
+
+// MarshalWithOptions serializes the value provided into a YAML document with EncodeOptions.
+func MarshalWithOptions(v interface{}, opts ...EncodeOption) ([]byte, error) {
+ return MarshalContext(context.Background(), v, opts...)
+}
+
+// MarshalContext serializes the value provided into a YAML document with context.Context and EncodeOptions.
+func MarshalContext(ctx context.Context, v interface{}, opts ...EncodeOption) ([]byte, error) {
+ var buf bytes.Buffer
+ if err := NewEncoder(&buf, opts...).EncodeContext(ctx, v); err != nil {
+ return nil, err
+ }
+ return buf.Bytes(), nil
+}
+
+// ValueToNode convert from value to ast.Node.
+func ValueToNode(v interface{}, opts ...EncodeOption) (ast.Node, error) {
+ var buf bytes.Buffer
+ node, err := NewEncoder(&buf, opts...).EncodeToNode(v)
+ if err != nil {
+ return nil, err
+ }
+ return node, nil
+}
+
+// Unmarshal decodes the first document found within the in byte slice
+// and assigns decoded values into the out value.
+//
+// Struct fields are only unmarshalled if they are exported (have an
+// upper case first letter), and are unmarshalled using the field name
+// lowercased as the default key. Custom keys may be defined via the
+// "yaml" name in the field tag: the content preceding the first comma
+// is used as the key, and the following comma-separated options are
+// used to tweak the marshaling process (see Marshal).
+// Conflicting names result in a runtime error.
+//
+// For example:
+//
+// type T struct {
+// F int `yaml:"a,omitempty"`
+// B int
+// }
+// var t T
+// yaml.Unmarshal([]byte("a: 1\nb: 2"), &t)
+//
+// See the documentation of Marshal for the format of tags and a list of
+// supported tag options.
+func Unmarshal(data []byte, v interface{}) error {
+ return UnmarshalWithOptions(data, v)
+}
+
+// UnmarshalWithOptions decodes with DecodeOptions the first document found within the in byte slice
+// and assigns decoded values into the out value.
+func UnmarshalWithOptions(data []byte, v interface{}, opts ...DecodeOption) error {
+ return UnmarshalContext(context.Background(), data, v, opts...)
+}
+
+// UnmarshalContext decodes with context.Context and DecodeOptions.
+func UnmarshalContext(ctx context.Context, data []byte, v interface{}, opts ...DecodeOption) error {
+ dec := NewDecoder(bytes.NewBuffer(data), opts...)
+ if err := dec.DecodeContext(ctx, v); err != nil {
+ if err == io.EOF {
+ return nil
+ }
+ return err
+ }
+ return nil
+}
+
+// NodeToValue converts node to the value pointed to by v.
+func NodeToValue(node ast.Node, v interface{}, opts ...DecodeOption) error {
+ var buf bytes.Buffer
+ if err := NewDecoder(&buf, opts...).DecodeFromNode(node, v); err != nil {
+ return err
+ }
+ return nil
+}
+
+// FormatError is a utility function that takes advantage of the metadata
+// stored in the errors returned by this package's parser.
+//
+// If the second argument `colored` is true, the error message is colorized.
+// If the third argument `inclSource` is true, the error message will
+// contain snippets of the YAML source that was used.
+func FormatError(e error, colored, inclSource bool) string {
+ var yamlErr Error
+ if errors.As(e, &yamlErr) {
+ return yamlErr.FormatError(colored, inclSource)
+ }
+
+ return e.Error()
+}
+
+// YAMLToJSON convert YAML bytes to JSON.
+func YAMLToJSON(bytes []byte) ([]byte, error) {
+ var v interface{}
+ if err := UnmarshalWithOptions(bytes, &v, UseOrderedMap()); err != nil {
+ return nil, err
+ }
+ out, err := MarshalWithOptions(v, JSON())
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+// JSONToYAML convert JSON bytes to YAML.
+func JSONToYAML(bytes []byte) ([]byte, error) {
+ var v interface{}
+ if err := UnmarshalWithOptions(bytes, &v, UseOrderedMap()); err != nil {
+ return nil, err
+ }
+ out, err := Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ return out, nil
+}
+
+var (
+ globalCustomMarshalerMu sync.Mutex
+ globalCustomUnmarshalerMu sync.Mutex
+ globalCustomMarshalerMap = map[reflect.Type]func(context.Context, interface{}) ([]byte, error){}
+ globalCustomUnmarshalerMap = map[reflect.Type]func(context.Context, interface{}, []byte) error{}
+)
+
+// RegisterCustomMarshaler overrides any encoding process for the type specified in generics.
+// If you want to switch the behavior for each encoder, use `CustomMarshaler` defined as EncodeOption.
+//
+// NOTE: If type T implements MarshalYAML for pointer receiver, the type specified in RegisterCustomMarshaler must be *T.
+// If RegisterCustomMarshaler and CustomMarshaler of EncodeOption are specified for the same type,
+// the CustomMarshaler specified in EncodeOption takes precedence.
+func RegisterCustomMarshaler[T any](marshaler func(T) ([]byte, error)) {
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+
+ var typ T
+ globalCustomMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(v.(T))
+ }
+}
+
+// RegisterCustomMarshalerContext overrides any encoding process for the type specified in generics.
+// Similar to RegisterCustomMarshalerContext, but allows passing a context to the unmarshaler function.
+func RegisterCustomMarshalerContext[T any](marshaler func(context.Context, T) ([]byte, error)) {
+ globalCustomMarshalerMu.Lock()
+ defer globalCustomMarshalerMu.Unlock()
+
+ var typ T
+ globalCustomMarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}) ([]byte, error) {
+ return marshaler(ctx, v.(T))
+ }
+}
+
+// RegisterCustomUnmarshaler overrides any decoding process for the type specified in generics.
+// If you want to switch the behavior for each decoder, use `CustomUnmarshaler` defined as DecodeOption.
+//
+// NOTE: If RegisterCustomUnmarshaler and CustomUnmarshaler of DecodeOption are specified for the same type,
+// the CustomUnmarshaler specified in DecodeOption takes precedence.
+func RegisterCustomUnmarshaler[T any](unmarshaler func(*T, []byte) error) {
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+
+ var typ *T
+ globalCustomUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(v.(*T), b)
+ }
+}
+
+// RegisterCustomUnmarshalerContext overrides any decoding process for the type specified in generics.
+// Similar to RegisterCustomUnmarshalerContext, but allows passing a context to the unmarshaler function.
+func RegisterCustomUnmarshalerContext[T any](unmarshaler func(context.Context, *T, []byte) error) {
+ globalCustomUnmarshalerMu.Lock()
+ defer globalCustomUnmarshalerMu.Unlock()
+
+ var typ *T
+ globalCustomUnmarshalerMap[reflect.TypeOf(typ)] = func(ctx context.Context, v interface{}, b []byte) error {
+ return unmarshaler(ctx, v.(*T), b)
+ }
+}
+
+// RawMessage is a raw encoded YAML value. It implements [BytesMarshaler] and
+// [BytesUnmarshaler] and can be used to delay YAML decoding or precompute a YAML
+// encoding.
+// It also implements [json.Marshaler] and [json.Unmarshaler].
+//
+// This is similar to [json.RawMessage] in the stdlib.
+type RawMessage []byte
+
+func (m RawMessage) MarshalYAML() ([]byte, error) {
+ if m == nil {
+ return []byte("null"), nil
+ }
+ return m, nil
+}
+
+func (m *RawMessage) UnmarshalYAML(dt []byte) error {
+ if m == nil {
+ return errors.New("yaml.RawMessage: UnmarshalYAML on nil pointer")
+ }
+ *m = append((*m)[0:0], dt...)
+ return nil
+}
+
+func (m *RawMessage) UnmarshalJSON(b []byte) error {
+ return m.UnmarshalYAML(b)
+}
+
+func (m RawMessage) MarshalJSON() ([]byte, error) {
+ return YAMLToJSON(m)
+}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/LICENSE b/sesh/vendor/gopkg.in/yaml.v3/LICENSE
deleted file mode 100644
index 2683e4b..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/LICENSE
+++ /dev/null
@@ -1,50 +0,0 @@
-
-This project is covered by two different licenses: MIT and Apache.
-
-#### MIT License ####
-
-The following files were ported to Go from C files of libyaml, and thus
-are still covered by their original MIT license, with the additional
-copyright staring in 2011 when the project was ported over:
-
- apic.go emitterc.go parserc.go readerc.go scannerc.go
- writerc.go yamlh.go yamlprivateh.go
-
-Copyright (c) 2006-2010 Kirill Simonov
-Copyright (c) 2006-2011 Kirill Simonov
-
-Permission is hereby granted, free of charge, to any person obtaining a copy of
-this software and associated documentation files (the "Software"), to deal in
-the Software without restriction, including without limitation the rights to
-use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-of the Software, and to permit persons to whom the Software is furnished to do
-so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all
-copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
-
-### Apache License ###
-
-All the remaining project files are covered by the Apache license:
-
-Copyright (c) 2011-2019 Canonical Ltd
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
diff --git a/sesh/vendor/gopkg.in/yaml.v3/NOTICE b/sesh/vendor/gopkg.in/yaml.v3/NOTICE
deleted file mode 100644
index 866d74a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/NOTICE
+++ /dev/null
@@ -1,13 +0,0 @@
-Copyright 2011-2016 Canonical Ltd.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
diff --git a/sesh/vendor/gopkg.in/yaml.v3/README.md b/sesh/vendor/gopkg.in/yaml.v3/README.md
deleted file mode 100644
index 08eb1ba..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/README.md
+++ /dev/null
@@ -1,150 +0,0 @@
-# YAML support for the Go language
-
-Introduction
-------------
-
-The yaml package enables Go programs to comfortably encode and decode YAML
-values. It was developed within [Canonical](https://www.canonical.com) as
-part of the [juju](https://juju.ubuntu.com) project, and is based on a
-pure Go port of the well-known [libyaml](http://pyyaml.org/wiki/LibYAML)
-C library to parse and generate YAML data quickly and reliably.
-
-Compatibility
--------------
-
-The yaml package supports most of YAML 1.2, but preserves some behavior
-from 1.1 for backwards compatibility.
-
-Specifically, as of v3 of the yaml package:
-
- - YAML 1.1 bools (_yes/no, on/off_) are supported as long as they are being
- decoded into a typed bool value. Otherwise they behave as a string. Booleans
- in YAML 1.2 are _true/false_ only.
- - Octals encode and decode as _0777_ per YAML 1.1, rather than _0o777_
- as specified in YAML 1.2, because most parsers still use the old format.
- Octals in the _0o777_ format are supported though, so new files work.
- - Does not support base-60 floats. These are gone from YAML 1.2, and were
- actually never supported by this package as it's clearly a poor choice.
-
-and offers backwards
-compatibility with YAML 1.1 in some cases.
-1.2, including support for
-anchors, tags, map merging, etc. Multi-document unmarshalling is not yet
-implemented, and base-60 floats from YAML 1.1 are purposefully not
-supported since they're a poor design and are gone in YAML 1.2.
-
-Installation and usage
-----------------------
-
-The import path for the package is *gopkg.in/yaml.v3*.
-
-To install it, run:
-
- go get gopkg.in/yaml.v3
-
-API documentation
------------------
-
-If opened in a browser, the import path itself leads to the API documentation:
-
- - [https://gopkg.in/yaml.v3](https://gopkg.in/yaml.v3)
-
-API stability
--------------
-
-The package API for yaml v3 will remain stable as described in [gopkg.in](https://gopkg.in).
-
-
-License
--------
-
-The yaml package is licensed under the MIT and Apache License 2.0 licenses.
-Please see the LICENSE file for details.
-
-
-Example
--------
-
-```Go
-package main
-
-import (
- "fmt"
- "log"
-
- "gopkg.in/yaml.v3"
-)
-
-var data = `
-a: Easy!
-b:
- c: 2
- d: [3, 4]
-`
-
-// Note: struct fields must be public in order for unmarshal to
-// correctly populate the data.
-type T struct {
- A string
- B struct {
- RenamedC int `yaml:"c"`
- D []int `yaml:",flow"`
- }
-}
-
-func main() {
- t := T{}
-
- err := yaml.Unmarshal([]byte(data), &t)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- t:\n%v\n\n", t)
-
- d, err := yaml.Marshal(&t)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- t dump:\n%s\n\n", string(d))
-
- m := make(map[interface{}]interface{})
-
- err = yaml.Unmarshal([]byte(data), &m)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- m:\n%v\n\n", m)
-
- d, err = yaml.Marshal(&m)
- if err != nil {
- log.Fatalf("error: %v", err)
- }
- fmt.Printf("--- m dump:\n%s\n\n", string(d))
-}
-```
-
-This example will generate the following output:
-
-```
---- t:
-{Easy! {2 [3 4]}}
-
---- t dump:
-a: Easy!
-b:
- c: 2
- d: [3, 4]
-
-
---- m:
-map[a:Easy! b:map[c:2 d:[3 4]]]
-
---- m dump:
-a: Easy!
-b:
- c: 2
- d:
- - 3
- - 4
-```
-
diff --git a/sesh/vendor/gopkg.in/yaml.v3/apic.go b/sesh/vendor/gopkg.in/yaml.v3/apic.go
deleted file mode 100644
index ae7d049..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/apic.go
+++ /dev/null
@@ -1,747 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "io"
-)
-
-func yaml_insert_token(parser *yaml_parser_t, pos int, token *yaml_token_t) {
- //fmt.Println("yaml_insert_token", "pos:", pos, "typ:", token.typ, "head:", parser.tokens_head, "len:", len(parser.tokens))
-
- // Check if we can move the queue at the beginning of the buffer.
- if parser.tokens_head > 0 && len(parser.tokens) == cap(parser.tokens) {
- if parser.tokens_head != len(parser.tokens) {
- copy(parser.tokens, parser.tokens[parser.tokens_head:])
- }
- parser.tokens = parser.tokens[:len(parser.tokens)-parser.tokens_head]
- parser.tokens_head = 0
- }
- parser.tokens = append(parser.tokens, *token)
- if pos < 0 {
- return
- }
- copy(parser.tokens[parser.tokens_head+pos+1:], parser.tokens[parser.tokens_head+pos:])
- parser.tokens[parser.tokens_head+pos] = *token
-}
-
-// Create a new parser object.
-func yaml_parser_initialize(parser *yaml_parser_t) bool {
- *parser = yaml_parser_t{
- raw_buffer: make([]byte, 0, input_raw_buffer_size),
- buffer: make([]byte, 0, input_buffer_size),
- }
- return true
-}
-
-// Destroy a parser object.
-func yaml_parser_delete(parser *yaml_parser_t) {
- *parser = yaml_parser_t{}
-}
-
-// String read handler.
-func yaml_string_read_handler(parser *yaml_parser_t, buffer []byte) (n int, err error) {
- if parser.input_pos == len(parser.input) {
- return 0, io.EOF
- }
- n = copy(buffer, parser.input[parser.input_pos:])
- parser.input_pos += n
- return n, nil
-}
-
-// Reader read handler.
-func yaml_reader_read_handler(parser *yaml_parser_t, buffer []byte) (n int, err error) {
- return parser.input_reader.Read(buffer)
-}
-
-// Set a string input.
-func yaml_parser_set_input_string(parser *yaml_parser_t, input []byte) {
- if parser.read_handler != nil {
- panic("must set the input source only once")
- }
- parser.read_handler = yaml_string_read_handler
- parser.input = input
- parser.input_pos = 0
-}
-
-// Set a file input.
-func yaml_parser_set_input_reader(parser *yaml_parser_t, r io.Reader) {
- if parser.read_handler != nil {
- panic("must set the input source only once")
- }
- parser.read_handler = yaml_reader_read_handler
- parser.input_reader = r
-}
-
-// Set the source encoding.
-func yaml_parser_set_encoding(parser *yaml_parser_t, encoding yaml_encoding_t) {
- if parser.encoding != yaml_ANY_ENCODING {
- panic("must set the encoding only once")
- }
- parser.encoding = encoding
-}
-
-// Create a new emitter object.
-func yaml_emitter_initialize(emitter *yaml_emitter_t) {
- *emitter = yaml_emitter_t{
- buffer: make([]byte, output_buffer_size),
- raw_buffer: make([]byte, 0, output_raw_buffer_size),
- states: make([]yaml_emitter_state_t, 0, initial_stack_size),
- events: make([]yaml_event_t, 0, initial_queue_size),
- best_width: -1,
- }
-}
-
-// Destroy an emitter object.
-func yaml_emitter_delete(emitter *yaml_emitter_t) {
- *emitter = yaml_emitter_t{}
-}
-
-// String write handler.
-func yaml_string_write_handler(emitter *yaml_emitter_t, buffer []byte) error {
- *emitter.output_buffer = append(*emitter.output_buffer, buffer...)
- return nil
-}
-
-// yaml_writer_write_handler uses emitter.output_writer to write the
-// emitted text.
-func yaml_writer_write_handler(emitter *yaml_emitter_t, buffer []byte) error {
- _, err := emitter.output_writer.Write(buffer)
- return err
-}
-
-// Set a string output.
-func yaml_emitter_set_output_string(emitter *yaml_emitter_t, output_buffer *[]byte) {
- if emitter.write_handler != nil {
- panic("must set the output target only once")
- }
- emitter.write_handler = yaml_string_write_handler
- emitter.output_buffer = output_buffer
-}
-
-// Set a file output.
-func yaml_emitter_set_output_writer(emitter *yaml_emitter_t, w io.Writer) {
- if emitter.write_handler != nil {
- panic("must set the output target only once")
- }
- emitter.write_handler = yaml_writer_write_handler
- emitter.output_writer = w
-}
-
-// Set the output encoding.
-func yaml_emitter_set_encoding(emitter *yaml_emitter_t, encoding yaml_encoding_t) {
- if emitter.encoding != yaml_ANY_ENCODING {
- panic("must set the output encoding only once")
- }
- emitter.encoding = encoding
-}
-
-// Set the canonical output style.
-func yaml_emitter_set_canonical(emitter *yaml_emitter_t, canonical bool) {
- emitter.canonical = canonical
-}
-
-// Set the indentation increment.
-func yaml_emitter_set_indent(emitter *yaml_emitter_t, indent int) {
- if indent < 2 || indent > 9 {
- indent = 2
- }
- emitter.best_indent = indent
-}
-
-// Set the preferred line width.
-func yaml_emitter_set_width(emitter *yaml_emitter_t, width int) {
- if width < 0 {
- width = -1
- }
- emitter.best_width = width
-}
-
-// Set if unescaped non-ASCII characters are allowed.
-func yaml_emitter_set_unicode(emitter *yaml_emitter_t, unicode bool) {
- emitter.unicode = unicode
-}
-
-// Set the preferred line break character.
-func yaml_emitter_set_break(emitter *yaml_emitter_t, line_break yaml_break_t) {
- emitter.line_break = line_break
-}
-
-///*
-// * Destroy a token object.
-// */
-//
-//YAML_DECLARE(void)
-//yaml_token_delete(yaml_token_t *token)
-//{
-// assert(token); // Non-NULL token object expected.
-//
-// switch (token.type)
-// {
-// case YAML_TAG_DIRECTIVE_TOKEN:
-// yaml_free(token.data.tag_directive.handle);
-// yaml_free(token.data.tag_directive.prefix);
-// break;
-//
-// case YAML_ALIAS_TOKEN:
-// yaml_free(token.data.alias.value);
-// break;
-//
-// case YAML_ANCHOR_TOKEN:
-// yaml_free(token.data.anchor.value);
-// break;
-//
-// case YAML_TAG_TOKEN:
-// yaml_free(token.data.tag.handle);
-// yaml_free(token.data.tag.suffix);
-// break;
-//
-// case YAML_SCALAR_TOKEN:
-// yaml_free(token.data.scalar.value);
-// break;
-//
-// default:
-// break;
-// }
-//
-// memset(token, 0, sizeof(yaml_token_t));
-//}
-//
-///*
-// * Check if a string is a valid UTF-8 sequence.
-// *
-// * Check 'reader.c' for more details on UTF-8 encoding.
-// */
-//
-//static int
-//yaml_check_utf8(yaml_char_t *start, size_t length)
-//{
-// yaml_char_t *end = start+length;
-// yaml_char_t *pointer = start;
-//
-// while (pointer < end) {
-// unsigned char octet;
-// unsigned int width;
-// unsigned int value;
-// size_t k;
-//
-// octet = pointer[0];
-// width = (octet & 0x80) == 0x00 ? 1 :
-// (octet & 0xE0) == 0xC0 ? 2 :
-// (octet & 0xF0) == 0xE0 ? 3 :
-// (octet & 0xF8) == 0xF0 ? 4 : 0;
-// value = (octet & 0x80) == 0x00 ? octet & 0x7F :
-// (octet & 0xE0) == 0xC0 ? octet & 0x1F :
-// (octet & 0xF0) == 0xE0 ? octet & 0x0F :
-// (octet & 0xF8) == 0xF0 ? octet & 0x07 : 0;
-// if (!width) return 0;
-// if (pointer+width > end) return 0;
-// for (k = 1; k < width; k ++) {
-// octet = pointer[k];
-// if ((octet & 0xC0) != 0x80) return 0;
-// value = (value << 6) + (octet & 0x3F);
-// }
-// if (!((width == 1) ||
-// (width == 2 && value >= 0x80) ||
-// (width == 3 && value >= 0x800) ||
-// (width == 4 && value >= 0x10000))) return 0;
-//
-// pointer += width;
-// }
-//
-// return 1;
-//}
-//
-
-// Create STREAM-START.
-func yaml_stream_start_event_initialize(event *yaml_event_t, encoding yaml_encoding_t) {
- *event = yaml_event_t{
- typ: yaml_STREAM_START_EVENT,
- encoding: encoding,
- }
-}
-
-// Create STREAM-END.
-func yaml_stream_end_event_initialize(event *yaml_event_t) {
- *event = yaml_event_t{
- typ: yaml_STREAM_END_EVENT,
- }
-}
-
-// Create DOCUMENT-START.
-func yaml_document_start_event_initialize(
- event *yaml_event_t,
- version_directive *yaml_version_directive_t,
- tag_directives []yaml_tag_directive_t,
- implicit bool,
-) {
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- version_directive: version_directive,
- tag_directives: tag_directives,
- implicit: implicit,
- }
-}
-
-// Create DOCUMENT-END.
-func yaml_document_end_event_initialize(event *yaml_event_t, implicit bool) {
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_END_EVENT,
- implicit: implicit,
- }
-}
-
-// Create ALIAS.
-func yaml_alias_event_initialize(event *yaml_event_t, anchor []byte) bool {
- *event = yaml_event_t{
- typ: yaml_ALIAS_EVENT,
- anchor: anchor,
- }
- return true
-}
-
-// Create SCALAR.
-func yaml_scalar_event_initialize(event *yaml_event_t, anchor, tag, value []byte, plain_implicit, quoted_implicit bool, style yaml_scalar_style_t) bool {
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- anchor: anchor,
- tag: tag,
- value: value,
- implicit: plain_implicit,
- quoted_implicit: quoted_implicit,
- style: yaml_style_t(style),
- }
- return true
-}
-
-// Create SEQUENCE-START.
-func yaml_sequence_start_event_initialize(event *yaml_event_t, anchor, tag []byte, implicit bool, style yaml_sequence_style_t) bool {
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(style),
- }
- return true
-}
-
-// Create SEQUENCE-END.
-func yaml_sequence_end_event_initialize(event *yaml_event_t) bool {
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- }
- return true
-}
-
-// Create MAPPING-START.
-func yaml_mapping_start_event_initialize(event *yaml_event_t, anchor, tag []byte, implicit bool, style yaml_mapping_style_t) {
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(style),
- }
-}
-
-// Create MAPPING-END.
-func yaml_mapping_end_event_initialize(event *yaml_event_t) {
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- }
-}
-
-// Destroy an event object.
-func yaml_event_delete(event *yaml_event_t) {
- *event = yaml_event_t{}
-}
-
-///*
-// * Create a document object.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_initialize(document *yaml_document_t,
-// version_directive *yaml_version_directive_t,
-// tag_directives_start *yaml_tag_directive_t,
-// tag_directives_end *yaml_tag_directive_t,
-// start_implicit int, end_implicit int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// struct {
-// start *yaml_node_t
-// end *yaml_node_t
-// top *yaml_node_t
-// } nodes = { NULL, NULL, NULL }
-// version_directive_copy *yaml_version_directive_t = NULL
-// struct {
-// start *yaml_tag_directive_t
-// end *yaml_tag_directive_t
-// top *yaml_tag_directive_t
-// } tag_directives_copy = { NULL, NULL, NULL }
-// value yaml_tag_directive_t = { NULL, NULL }
-// mark yaml_mark_t = { 0, 0, 0 }
-//
-// assert(document) // Non-NULL document object is expected.
-// assert((tag_directives_start && tag_directives_end) ||
-// (tag_directives_start == tag_directives_end))
-// // Valid tag directives are expected.
-//
-// if (!STACK_INIT(&context, nodes, INITIAL_STACK_SIZE)) goto error
-//
-// if (version_directive) {
-// version_directive_copy = yaml_malloc(sizeof(yaml_version_directive_t))
-// if (!version_directive_copy) goto error
-// version_directive_copy.major = version_directive.major
-// version_directive_copy.minor = version_directive.minor
-// }
-//
-// if (tag_directives_start != tag_directives_end) {
-// tag_directive *yaml_tag_directive_t
-// if (!STACK_INIT(&context, tag_directives_copy, INITIAL_STACK_SIZE))
-// goto error
-// for (tag_directive = tag_directives_start
-// tag_directive != tag_directives_end; tag_directive ++) {
-// assert(tag_directive.handle)
-// assert(tag_directive.prefix)
-// if (!yaml_check_utf8(tag_directive.handle,
-// strlen((char *)tag_directive.handle)))
-// goto error
-// if (!yaml_check_utf8(tag_directive.prefix,
-// strlen((char *)tag_directive.prefix)))
-// goto error
-// value.handle = yaml_strdup(tag_directive.handle)
-// value.prefix = yaml_strdup(tag_directive.prefix)
-// if (!value.handle || !value.prefix) goto error
-// if (!PUSH(&context, tag_directives_copy, value))
-// goto error
-// value.handle = NULL
-// value.prefix = NULL
-// }
-// }
-//
-// DOCUMENT_INIT(*document, nodes.start, nodes.end, version_directive_copy,
-// tag_directives_copy.start, tag_directives_copy.top,
-// start_implicit, end_implicit, mark, mark)
-//
-// return 1
-//
-//error:
-// STACK_DEL(&context, nodes)
-// yaml_free(version_directive_copy)
-// while (!STACK_EMPTY(&context, tag_directives_copy)) {
-// value yaml_tag_directive_t = POP(&context, tag_directives_copy)
-// yaml_free(value.handle)
-// yaml_free(value.prefix)
-// }
-// STACK_DEL(&context, tag_directives_copy)
-// yaml_free(value.handle)
-// yaml_free(value.prefix)
-//
-// return 0
-//}
-//
-///*
-// * Destroy a document object.
-// */
-//
-//YAML_DECLARE(void)
-//yaml_document_delete(document *yaml_document_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// tag_directive *yaml_tag_directive_t
-//
-// context.error = YAML_NO_ERROR // Eliminate a compiler warning.
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// while (!STACK_EMPTY(&context, document.nodes)) {
-// node yaml_node_t = POP(&context, document.nodes)
-// yaml_free(node.tag)
-// switch (node.type) {
-// case YAML_SCALAR_NODE:
-// yaml_free(node.data.scalar.value)
-// break
-// case YAML_SEQUENCE_NODE:
-// STACK_DEL(&context, node.data.sequence.items)
-// break
-// case YAML_MAPPING_NODE:
-// STACK_DEL(&context, node.data.mapping.pairs)
-// break
-// default:
-// assert(0) // Should not happen.
-// }
-// }
-// STACK_DEL(&context, document.nodes)
-//
-// yaml_free(document.version_directive)
-// for (tag_directive = document.tag_directives.start
-// tag_directive != document.tag_directives.end
-// tag_directive++) {
-// yaml_free(tag_directive.handle)
-// yaml_free(tag_directive.prefix)
-// }
-// yaml_free(document.tag_directives.start)
-//
-// memset(document, 0, sizeof(yaml_document_t))
-//}
-//
-///**
-// * Get a document node.
-// */
-//
-//YAML_DECLARE(yaml_node_t *)
-//yaml_document_get_node(document *yaml_document_t, index int)
-//{
-// assert(document) // Non-NULL document object is expected.
-//
-// if (index > 0 && document.nodes.start + index <= document.nodes.top) {
-// return document.nodes.start + index - 1
-// }
-// return NULL
-//}
-//
-///**
-// * Get the root object.
-// */
-//
-//YAML_DECLARE(yaml_node_t *)
-//yaml_document_get_root_node(document *yaml_document_t)
-//{
-// assert(document) // Non-NULL document object is expected.
-//
-// if (document.nodes.top != document.nodes.start) {
-// return document.nodes.start
-// }
-// return NULL
-//}
-//
-///*
-// * Add a scalar node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_scalar(document *yaml_document_t,
-// tag *yaml_char_t, value *yaml_char_t, length int,
-// style yaml_scalar_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// value_copy *yaml_char_t = NULL
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-// assert(value) // Non-NULL value is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_SCALAR_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (length < 0) {
-// length = strlen((char *)value)
-// }
-//
-// if (!yaml_check_utf8(value, length)) goto error
-// value_copy = yaml_malloc(length+1)
-// if (!value_copy) goto error
-// memcpy(value_copy, value, length)
-// value_copy[length] = '\0'
-//
-// SCALAR_NODE_INIT(node, tag_copy, value_copy, length, style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// yaml_free(tag_copy)
-// yaml_free(value_copy)
-//
-// return 0
-//}
-//
-///*
-// * Add a sequence node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_sequence(document *yaml_document_t,
-// tag *yaml_char_t, style yaml_sequence_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// struct {
-// start *yaml_node_item_t
-// end *yaml_node_item_t
-// top *yaml_node_item_t
-// } items = { NULL, NULL, NULL }
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_SEQUENCE_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (!STACK_INIT(&context, items, INITIAL_STACK_SIZE)) goto error
-//
-// SEQUENCE_NODE_INIT(node, tag_copy, items.start, items.end,
-// style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// STACK_DEL(&context, items)
-// yaml_free(tag_copy)
-//
-// return 0
-//}
-//
-///*
-// * Add a mapping node to a document.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_add_mapping(document *yaml_document_t,
-// tag *yaml_char_t, style yaml_mapping_style_t)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-// mark yaml_mark_t = { 0, 0, 0 }
-// tag_copy *yaml_char_t = NULL
-// struct {
-// start *yaml_node_pair_t
-// end *yaml_node_pair_t
-// top *yaml_node_pair_t
-// } pairs = { NULL, NULL, NULL }
-// node yaml_node_t
-//
-// assert(document) // Non-NULL document object is expected.
-//
-// if (!tag) {
-// tag = (yaml_char_t *)YAML_DEFAULT_MAPPING_TAG
-// }
-//
-// if (!yaml_check_utf8(tag, strlen((char *)tag))) goto error
-// tag_copy = yaml_strdup(tag)
-// if (!tag_copy) goto error
-//
-// if (!STACK_INIT(&context, pairs, INITIAL_STACK_SIZE)) goto error
-//
-// MAPPING_NODE_INIT(node, tag_copy, pairs.start, pairs.end,
-// style, mark, mark)
-// if (!PUSH(&context, document.nodes, node)) goto error
-//
-// return document.nodes.top - document.nodes.start
-//
-//error:
-// STACK_DEL(&context, pairs)
-// yaml_free(tag_copy)
-//
-// return 0
-//}
-//
-///*
-// * Append an item to a sequence node.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_append_sequence_item(document *yaml_document_t,
-// sequence int, item int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-//
-// assert(document) // Non-NULL document is required.
-// assert(sequence > 0
-// && document.nodes.start + sequence <= document.nodes.top)
-// // Valid sequence id is required.
-// assert(document.nodes.start[sequence-1].type == YAML_SEQUENCE_NODE)
-// // A sequence node is required.
-// assert(item > 0 && document.nodes.start + item <= document.nodes.top)
-// // Valid item id is required.
-//
-// if (!PUSH(&context,
-// document.nodes.start[sequence-1].data.sequence.items, item))
-// return 0
-//
-// return 1
-//}
-//
-///*
-// * Append a pair of a key and a value to a mapping node.
-// */
-//
-//YAML_DECLARE(int)
-//yaml_document_append_mapping_pair(document *yaml_document_t,
-// mapping int, key int, value int)
-//{
-// struct {
-// error yaml_error_type_t
-// } context
-//
-// pair yaml_node_pair_t
-//
-// assert(document) // Non-NULL document is required.
-// assert(mapping > 0
-// && document.nodes.start + mapping <= document.nodes.top)
-// // Valid mapping id is required.
-// assert(document.nodes.start[mapping-1].type == YAML_MAPPING_NODE)
-// // A mapping node is required.
-// assert(key > 0 && document.nodes.start + key <= document.nodes.top)
-// // Valid key id is required.
-// assert(value > 0 && document.nodes.start + value <= document.nodes.top)
-// // Valid value id is required.
-//
-// pair.key = key
-// pair.value = value
-//
-// if (!PUSH(&context,
-// document.nodes.start[mapping-1].data.mapping.pairs, pair))
-// return 0
-//
-// return 1
-//}
-//
-//
diff --git a/sesh/vendor/gopkg.in/yaml.v3/decode.go b/sesh/vendor/gopkg.in/yaml.v3/decode.go
deleted file mode 100644
index 0173b69..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/decode.go
+++ /dev/null
@@ -1,1000 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding"
- "encoding/base64"
- "fmt"
- "io"
- "math"
- "reflect"
- "strconv"
- "time"
-)
-
-// ----------------------------------------------------------------------------
-// Parser, produces a node tree out of a libyaml event stream.
-
-type parser struct {
- parser yaml_parser_t
- event yaml_event_t
- doc *Node
- anchors map[string]*Node
- doneInit bool
- textless bool
-}
-
-func newParser(b []byte) *parser {
- p := parser{}
- if !yaml_parser_initialize(&p.parser) {
- panic("failed to initialize YAML emitter")
- }
- if len(b) == 0 {
- b = []byte{'\n'}
- }
- yaml_parser_set_input_string(&p.parser, b)
- return &p
-}
-
-func newParserFromReader(r io.Reader) *parser {
- p := parser{}
- if !yaml_parser_initialize(&p.parser) {
- panic("failed to initialize YAML emitter")
- }
- yaml_parser_set_input_reader(&p.parser, r)
- return &p
-}
-
-func (p *parser) init() {
- if p.doneInit {
- return
- }
- p.anchors = make(map[string]*Node)
- p.expect(yaml_STREAM_START_EVENT)
- p.doneInit = true
-}
-
-func (p *parser) destroy() {
- if p.event.typ != yaml_NO_EVENT {
- yaml_event_delete(&p.event)
- }
- yaml_parser_delete(&p.parser)
-}
-
-// expect consumes an event from the event stream and
-// checks that it's of the expected type.
-func (p *parser) expect(e yaml_event_type_t) {
- if p.event.typ == yaml_NO_EVENT {
- if !yaml_parser_parse(&p.parser, &p.event) {
- p.fail()
- }
- }
- if p.event.typ == yaml_STREAM_END_EVENT {
- failf("attempted to go past the end of stream; corrupted value?")
- }
- if p.event.typ != e {
- p.parser.problem = fmt.Sprintf("expected %s event but got %s", e, p.event.typ)
- p.fail()
- }
- yaml_event_delete(&p.event)
- p.event.typ = yaml_NO_EVENT
-}
-
-// peek peeks at the next event in the event stream,
-// puts the results into p.event and returns the event type.
-func (p *parser) peek() yaml_event_type_t {
- if p.event.typ != yaml_NO_EVENT {
- return p.event.typ
- }
- // It's curious choice from the underlying API to generally return a
- // positive result on success, but on this case return true in an error
- // scenario. This was the source of bugs in the past (issue #666).
- if !yaml_parser_parse(&p.parser, &p.event) || p.parser.error != yaml_NO_ERROR {
- p.fail()
- }
- return p.event.typ
-}
-
-func (p *parser) fail() {
- var where string
- var line int
- if p.parser.context_mark.line != 0 {
- line = p.parser.context_mark.line
- // Scanner errors don't iterate line before returning error
- if p.parser.error == yaml_SCANNER_ERROR {
- line++
- }
- } else if p.parser.problem_mark.line != 0 {
- line = p.parser.problem_mark.line
- // Scanner errors don't iterate line before returning error
- if p.parser.error == yaml_SCANNER_ERROR {
- line++
- }
- }
- if line != 0 {
- where = "line " + strconv.Itoa(line) + ": "
- }
- var msg string
- if len(p.parser.problem) > 0 {
- msg = p.parser.problem
- } else {
- msg = "unknown problem parsing YAML content"
- }
- failf("%s%s", where, msg)
-}
-
-func (p *parser) anchor(n *Node, anchor []byte) {
- if anchor != nil {
- n.Anchor = string(anchor)
- p.anchors[n.Anchor] = n
- }
-}
-
-func (p *parser) parse() *Node {
- p.init()
- switch p.peek() {
- case yaml_SCALAR_EVENT:
- return p.scalar()
- case yaml_ALIAS_EVENT:
- return p.alias()
- case yaml_MAPPING_START_EVENT:
- return p.mapping()
- case yaml_SEQUENCE_START_EVENT:
- return p.sequence()
- case yaml_DOCUMENT_START_EVENT:
- return p.document()
- case yaml_STREAM_END_EVENT:
- // Happens when attempting to decode an empty buffer.
- return nil
- case yaml_TAIL_COMMENT_EVENT:
- panic("internal error: unexpected tail comment event (please report)")
- default:
- panic("internal error: attempted to parse unknown event (please report): " + p.event.typ.String())
- }
-}
-
-func (p *parser) node(kind Kind, defaultTag, tag, value string) *Node {
- var style Style
- if tag != "" && tag != "!" {
- tag = shortTag(tag)
- style = TaggedStyle
- } else if defaultTag != "" {
- tag = defaultTag
- } else if kind == ScalarNode {
- tag, _ = resolve("", value)
- }
- n := &Node{
- Kind: kind,
- Tag: tag,
- Value: value,
- Style: style,
- }
- if !p.textless {
- n.Line = p.event.start_mark.line + 1
- n.Column = p.event.start_mark.column + 1
- n.HeadComment = string(p.event.head_comment)
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- }
- return n
-}
-
-func (p *parser) parseChild(parent *Node) *Node {
- child := p.parse()
- parent.Content = append(parent.Content, child)
- return child
-}
-
-func (p *parser) document() *Node {
- n := p.node(DocumentNode, "", "", "")
- p.doc = n
- p.expect(yaml_DOCUMENT_START_EVENT)
- p.parseChild(n)
- if p.peek() == yaml_DOCUMENT_END_EVENT {
- n.FootComment = string(p.event.foot_comment)
- }
- p.expect(yaml_DOCUMENT_END_EVENT)
- return n
-}
-
-func (p *parser) alias() *Node {
- n := p.node(AliasNode, "", "", string(p.event.anchor))
- n.Alias = p.anchors[n.Value]
- if n.Alias == nil {
- failf("unknown anchor '%s' referenced", n.Value)
- }
- p.expect(yaml_ALIAS_EVENT)
- return n
-}
-
-func (p *parser) scalar() *Node {
- var parsedStyle = p.event.scalar_style()
- var nodeStyle Style
- switch {
- case parsedStyle&yaml_DOUBLE_QUOTED_SCALAR_STYLE != 0:
- nodeStyle = DoubleQuotedStyle
- case parsedStyle&yaml_SINGLE_QUOTED_SCALAR_STYLE != 0:
- nodeStyle = SingleQuotedStyle
- case parsedStyle&yaml_LITERAL_SCALAR_STYLE != 0:
- nodeStyle = LiteralStyle
- case parsedStyle&yaml_FOLDED_SCALAR_STYLE != 0:
- nodeStyle = FoldedStyle
- }
- var nodeValue = string(p.event.value)
- var nodeTag = string(p.event.tag)
- var defaultTag string
- if nodeStyle == 0 {
- if nodeValue == "<<" {
- defaultTag = mergeTag
- }
- } else {
- defaultTag = strTag
- }
- n := p.node(ScalarNode, defaultTag, nodeTag, nodeValue)
- n.Style |= nodeStyle
- p.anchor(n, p.event.anchor)
- p.expect(yaml_SCALAR_EVENT)
- return n
-}
-
-func (p *parser) sequence() *Node {
- n := p.node(SequenceNode, seqTag, string(p.event.tag), "")
- if p.event.sequence_style()&yaml_FLOW_SEQUENCE_STYLE != 0 {
- n.Style |= FlowStyle
- }
- p.anchor(n, p.event.anchor)
- p.expect(yaml_SEQUENCE_START_EVENT)
- for p.peek() != yaml_SEQUENCE_END_EVENT {
- p.parseChild(n)
- }
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- p.expect(yaml_SEQUENCE_END_EVENT)
- return n
-}
-
-func (p *parser) mapping() *Node {
- n := p.node(MappingNode, mapTag, string(p.event.tag), "")
- block := true
- if p.event.mapping_style()&yaml_FLOW_MAPPING_STYLE != 0 {
- block = false
- n.Style |= FlowStyle
- }
- p.anchor(n, p.event.anchor)
- p.expect(yaml_MAPPING_START_EVENT)
- for p.peek() != yaml_MAPPING_END_EVENT {
- k := p.parseChild(n)
- if block && k.FootComment != "" {
- // Must be a foot comment for the prior value when being dedented.
- if len(n.Content) > 2 {
- n.Content[len(n.Content)-3].FootComment = k.FootComment
- k.FootComment = ""
- }
- }
- v := p.parseChild(n)
- if k.FootComment == "" && v.FootComment != "" {
- k.FootComment = v.FootComment
- v.FootComment = ""
- }
- if p.peek() == yaml_TAIL_COMMENT_EVENT {
- if k.FootComment == "" {
- k.FootComment = string(p.event.foot_comment)
- }
- p.expect(yaml_TAIL_COMMENT_EVENT)
- }
- }
- n.LineComment = string(p.event.line_comment)
- n.FootComment = string(p.event.foot_comment)
- if n.Style&FlowStyle == 0 && n.FootComment != "" && len(n.Content) > 1 {
- n.Content[len(n.Content)-2].FootComment = n.FootComment
- n.FootComment = ""
- }
- p.expect(yaml_MAPPING_END_EVENT)
- return n
-}
-
-// ----------------------------------------------------------------------------
-// Decoder, unmarshals a node into a provided value.
-
-type decoder struct {
- doc *Node
- aliases map[*Node]bool
- terrors []string
-
- stringMapType reflect.Type
- generalMapType reflect.Type
-
- knownFields bool
- uniqueKeys bool
- decodeCount int
- aliasCount int
- aliasDepth int
-
- mergedFields map[interface{}]bool
-}
-
-var (
- nodeType = reflect.TypeOf(Node{})
- durationType = reflect.TypeOf(time.Duration(0))
- stringMapType = reflect.TypeOf(map[string]interface{}{})
- generalMapType = reflect.TypeOf(map[interface{}]interface{}{})
- ifaceType = generalMapType.Elem()
- timeType = reflect.TypeOf(time.Time{})
- ptrTimeType = reflect.TypeOf(&time.Time{})
-)
-
-func newDecoder() *decoder {
- d := &decoder{
- stringMapType: stringMapType,
- generalMapType: generalMapType,
- uniqueKeys: true,
- }
- d.aliases = make(map[*Node]bool)
- return d
-}
-
-func (d *decoder) terror(n *Node, tag string, out reflect.Value) {
- if n.Tag != "" {
- tag = n.Tag
- }
- value := n.Value
- if tag != seqTag && tag != mapTag {
- if len(value) > 10 {
- value = " `" + value[:7] + "...`"
- } else {
- value = " `" + value + "`"
- }
- }
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: cannot unmarshal %s%s into %s", n.Line, shortTag(tag), value, out.Type()))
-}
-
-func (d *decoder) callUnmarshaler(n *Node, u Unmarshaler) (good bool) {
- err := u.UnmarshalYAML(n)
- if e, ok := err.(*TypeError); ok {
- d.terrors = append(d.terrors, e.Errors...)
- return false
- }
- if err != nil {
- fail(err)
- }
- return true
-}
-
-func (d *decoder) callObsoleteUnmarshaler(n *Node, u obsoleteUnmarshaler) (good bool) {
- terrlen := len(d.terrors)
- err := u.UnmarshalYAML(func(v interface{}) (err error) {
- defer handleErr(&err)
- d.unmarshal(n, reflect.ValueOf(v))
- if len(d.terrors) > terrlen {
- issues := d.terrors[terrlen:]
- d.terrors = d.terrors[:terrlen]
- return &TypeError{issues}
- }
- return nil
- })
- if e, ok := err.(*TypeError); ok {
- d.terrors = append(d.terrors, e.Errors...)
- return false
- }
- if err != nil {
- fail(err)
- }
- return true
-}
-
-// d.prepare initializes and dereferences pointers and calls UnmarshalYAML
-// if a value is found to implement it.
-// It returns the initialized and dereferenced out value, whether
-// unmarshalling was already done by UnmarshalYAML, and if so whether
-// its types unmarshalled appropriately.
-//
-// If n holds a null value, prepare returns before doing anything.
-func (d *decoder) prepare(n *Node, out reflect.Value) (newout reflect.Value, unmarshaled, good bool) {
- if n.ShortTag() == nullTag {
- return out, false, false
- }
- again := true
- for again {
- again = false
- if out.Kind() == reflect.Ptr {
- if out.IsNil() {
- out.Set(reflect.New(out.Type().Elem()))
- }
- out = out.Elem()
- again = true
- }
- if out.CanAddr() {
- outi := out.Addr().Interface()
- if u, ok := outi.(Unmarshaler); ok {
- good = d.callUnmarshaler(n, u)
- return out, true, good
- }
- if u, ok := outi.(obsoleteUnmarshaler); ok {
- good = d.callObsoleteUnmarshaler(n, u)
- return out, true, good
- }
- }
- }
- return out, false, false
-}
-
-func (d *decoder) fieldByIndex(n *Node, v reflect.Value, index []int) (field reflect.Value) {
- if n.ShortTag() == nullTag {
- return reflect.Value{}
- }
- for _, num := range index {
- for {
- if v.Kind() == reflect.Ptr {
- if v.IsNil() {
- v.Set(reflect.New(v.Type().Elem()))
- }
- v = v.Elem()
- continue
- }
- break
- }
- v = v.Field(num)
- }
- return v
-}
-
-const (
- // 400,000 decode operations is ~500kb of dense object declarations, or
- // ~5kb of dense object declarations with 10000% alias expansion
- alias_ratio_range_low = 400000
-
- // 4,000,000 decode operations is ~5MB of dense object declarations, or
- // ~4.5MB of dense object declarations with 10% alias expansion
- alias_ratio_range_high = 4000000
-
- // alias_ratio_range is the range over which we scale allowed alias ratios
- alias_ratio_range = float64(alias_ratio_range_high - alias_ratio_range_low)
-)
-
-func allowedAliasRatio(decodeCount int) float64 {
- switch {
- case decodeCount <= alias_ratio_range_low:
- // allow 99% to come from alias expansion for small-to-medium documents
- return 0.99
- case decodeCount >= alias_ratio_range_high:
- // allow 10% to come from alias expansion for very large documents
- return 0.10
- default:
- // scale smoothly from 99% down to 10% over the range.
- // this maps to 396,000 - 400,000 allowed alias-driven decodes over the range.
- // 400,000 decode operations is ~100MB of allocations in worst-case scenarios (single-item maps).
- return 0.99 - 0.89*(float64(decodeCount-alias_ratio_range_low)/alias_ratio_range)
- }
-}
-
-func (d *decoder) unmarshal(n *Node, out reflect.Value) (good bool) {
- d.decodeCount++
- if d.aliasDepth > 0 {
- d.aliasCount++
- }
- if d.aliasCount > 100 && d.decodeCount > 1000 && float64(d.aliasCount)/float64(d.decodeCount) > allowedAliasRatio(d.decodeCount) {
- failf("document contains excessive aliasing")
- }
- if out.Type() == nodeType {
- out.Set(reflect.ValueOf(n).Elem())
- return true
- }
- switch n.Kind {
- case DocumentNode:
- return d.document(n, out)
- case AliasNode:
- return d.alias(n, out)
- }
- out, unmarshaled, good := d.prepare(n, out)
- if unmarshaled {
- return good
- }
- switch n.Kind {
- case ScalarNode:
- good = d.scalar(n, out)
- case MappingNode:
- good = d.mapping(n, out)
- case SequenceNode:
- good = d.sequence(n, out)
- case 0:
- if n.IsZero() {
- return d.null(out)
- }
- fallthrough
- default:
- failf("cannot decode node with unknown kind %d", n.Kind)
- }
- return good
-}
-
-func (d *decoder) document(n *Node, out reflect.Value) (good bool) {
- if len(n.Content) == 1 {
- d.doc = n
- d.unmarshal(n.Content[0], out)
- return true
- }
- return false
-}
-
-func (d *decoder) alias(n *Node, out reflect.Value) (good bool) {
- if d.aliases[n] {
- // TODO this could actually be allowed in some circumstances.
- failf("anchor '%s' value contains itself", n.Value)
- }
- d.aliases[n] = true
- d.aliasDepth++
- good = d.unmarshal(n.Alias, out)
- d.aliasDepth--
- delete(d.aliases, n)
- return good
-}
-
-var zeroValue reflect.Value
-
-func resetMap(out reflect.Value) {
- for _, k := range out.MapKeys() {
- out.SetMapIndex(k, zeroValue)
- }
-}
-
-func (d *decoder) null(out reflect.Value) bool {
- if out.CanAddr() {
- switch out.Kind() {
- case reflect.Interface, reflect.Ptr, reflect.Map, reflect.Slice:
- out.Set(reflect.Zero(out.Type()))
- return true
- }
- }
- return false
-}
-
-func (d *decoder) scalar(n *Node, out reflect.Value) bool {
- var tag string
- var resolved interface{}
- if n.indicatedString() {
- tag = strTag
- resolved = n.Value
- } else {
- tag, resolved = resolve(n.Tag, n.Value)
- if tag == binaryTag {
- data, err := base64.StdEncoding.DecodeString(resolved.(string))
- if err != nil {
- failf("!!binary value contains invalid base64 data")
- }
- resolved = string(data)
- }
- }
- if resolved == nil {
- return d.null(out)
- }
- if resolvedv := reflect.ValueOf(resolved); out.Type() == resolvedv.Type() {
- // We've resolved to exactly the type we want, so use that.
- out.Set(resolvedv)
- return true
- }
- // Perhaps we can use the value as a TextUnmarshaler to
- // set its value.
- if out.CanAddr() {
- u, ok := out.Addr().Interface().(encoding.TextUnmarshaler)
- if ok {
- var text []byte
- if tag == binaryTag {
- text = []byte(resolved.(string))
- } else {
- // We let any value be unmarshaled into TextUnmarshaler.
- // That might be more lax than we'd like, but the
- // TextUnmarshaler itself should bowl out any dubious values.
- text = []byte(n.Value)
- }
- err := u.UnmarshalText(text)
- if err != nil {
- fail(err)
- }
- return true
- }
- }
- switch out.Kind() {
- case reflect.String:
- if tag == binaryTag {
- out.SetString(resolved.(string))
- return true
- }
- out.SetString(n.Value)
- return true
- case reflect.Interface:
- out.Set(reflect.ValueOf(resolved))
- return true
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- // This used to work in v2, but it's very unfriendly.
- isDuration := out.Type() == durationType
-
- switch resolved := resolved.(type) {
- case int:
- if !isDuration && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case int64:
- if !isDuration && !out.OverflowInt(resolved) {
- out.SetInt(resolved)
- return true
- }
- case uint64:
- if !isDuration && resolved <= math.MaxInt64 && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case float64:
- if !isDuration && resolved <= math.MaxInt64 && !out.OverflowInt(int64(resolved)) {
- out.SetInt(int64(resolved))
- return true
- }
- case string:
- if out.Type() == durationType {
- d, err := time.ParseDuration(resolved)
- if err == nil {
- out.SetInt(int64(d))
- return true
- }
- }
- }
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- switch resolved := resolved.(type) {
- case int:
- if resolved >= 0 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case int64:
- if resolved >= 0 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case uint64:
- if !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- case float64:
- if resolved <= math.MaxUint64 && !out.OverflowUint(uint64(resolved)) {
- out.SetUint(uint64(resolved))
- return true
- }
- }
- case reflect.Bool:
- switch resolved := resolved.(type) {
- case bool:
- out.SetBool(resolved)
- return true
- case string:
- // This offers some compatibility with the 1.1 spec (https://yaml.org/type/bool.html).
- // It only works if explicitly attempting to unmarshal into a typed bool value.
- switch resolved {
- case "y", "Y", "yes", "Yes", "YES", "on", "On", "ON":
- out.SetBool(true)
- return true
- case "n", "N", "no", "No", "NO", "off", "Off", "OFF":
- out.SetBool(false)
- return true
- }
- }
- case reflect.Float32, reflect.Float64:
- switch resolved := resolved.(type) {
- case int:
- out.SetFloat(float64(resolved))
- return true
- case int64:
- out.SetFloat(float64(resolved))
- return true
- case uint64:
- out.SetFloat(float64(resolved))
- return true
- case float64:
- out.SetFloat(resolved)
- return true
- }
- case reflect.Struct:
- if resolvedv := reflect.ValueOf(resolved); out.Type() == resolvedv.Type() {
- out.Set(resolvedv)
- return true
- }
- case reflect.Ptr:
- panic("yaml internal error: please report the issue")
- }
- d.terror(n, tag, out)
- return false
-}
-
-func settableValueOf(i interface{}) reflect.Value {
- v := reflect.ValueOf(i)
- sv := reflect.New(v.Type()).Elem()
- sv.Set(v)
- return sv
-}
-
-func (d *decoder) sequence(n *Node, out reflect.Value) (good bool) {
- l := len(n.Content)
-
- var iface reflect.Value
- switch out.Kind() {
- case reflect.Slice:
- out.Set(reflect.MakeSlice(out.Type(), l, l))
- case reflect.Array:
- if l != out.Len() {
- failf("invalid array: want %d elements but got %d", out.Len(), l)
- }
- case reflect.Interface:
- // No type hints. Will have to use a generic sequence.
- iface = out
- out = settableValueOf(make([]interface{}, l))
- default:
- d.terror(n, seqTag, out)
- return false
- }
- et := out.Type().Elem()
-
- j := 0
- for i := 0; i < l; i++ {
- e := reflect.New(et).Elem()
- if ok := d.unmarshal(n.Content[i], e); ok {
- out.Index(j).Set(e)
- j++
- }
- }
- if out.Kind() != reflect.Array {
- out.Set(out.Slice(0, j))
- }
- if iface.IsValid() {
- iface.Set(out)
- }
- return true
-}
-
-func (d *decoder) mapping(n *Node, out reflect.Value) (good bool) {
- l := len(n.Content)
- if d.uniqueKeys {
- nerrs := len(d.terrors)
- for i := 0; i < l; i += 2 {
- ni := n.Content[i]
- for j := i + 2; j < l; j += 2 {
- nj := n.Content[j]
- if ni.Kind == nj.Kind && ni.Value == nj.Value {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: mapping key %#v already defined at line %d", nj.Line, nj.Value, ni.Line))
- }
- }
- }
- if len(d.terrors) > nerrs {
- return false
- }
- }
- switch out.Kind() {
- case reflect.Struct:
- return d.mappingStruct(n, out)
- case reflect.Map:
- // okay
- case reflect.Interface:
- iface := out
- if isStringMap(n) {
- out = reflect.MakeMap(d.stringMapType)
- } else {
- out = reflect.MakeMap(d.generalMapType)
- }
- iface.Set(out)
- default:
- d.terror(n, mapTag, out)
- return false
- }
-
- outt := out.Type()
- kt := outt.Key()
- et := outt.Elem()
-
- stringMapType := d.stringMapType
- generalMapType := d.generalMapType
- if outt.Elem() == ifaceType {
- if outt.Key().Kind() == reflect.String {
- d.stringMapType = outt
- } else if outt.Key() == ifaceType {
- d.generalMapType = outt
- }
- }
-
- mergedFields := d.mergedFields
- d.mergedFields = nil
-
- var mergeNode *Node
-
- mapIsNew := false
- if out.IsNil() {
- out.Set(reflect.MakeMap(outt))
- mapIsNew = true
- }
- for i := 0; i < l; i += 2 {
- if isMerge(n.Content[i]) {
- mergeNode = n.Content[i+1]
- continue
- }
- k := reflect.New(kt).Elem()
- if d.unmarshal(n.Content[i], k) {
- if mergedFields != nil {
- ki := k.Interface()
- if mergedFields[ki] {
- continue
- }
- mergedFields[ki] = true
- }
- kkind := k.Kind()
- if kkind == reflect.Interface {
- kkind = k.Elem().Kind()
- }
- if kkind == reflect.Map || kkind == reflect.Slice {
- failf("invalid map key: %#v", k.Interface())
- }
- e := reflect.New(et).Elem()
- if d.unmarshal(n.Content[i+1], e) || n.Content[i+1].ShortTag() == nullTag && (mapIsNew || !out.MapIndex(k).IsValid()) {
- out.SetMapIndex(k, e)
- }
- }
- }
-
- d.mergedFields = mergedFields
- if mergeNode != nil {
- d.merge(n, mergeNode, out)
- }
-
- d.stringMapType = stringMapType
- d.generalMapType = generalMapType
- return true
-}
-
-func isStringMap(n *Node) bool {
- if n.Kind != MappingNode {
- return false
- }
- l := len(n.Content)
- for i := 0; i < l; i += 2 {
- shortTag := n.Content[i].ShortTag()
- if shortTag != strTag && shortTag != mergeTag {
- return false
- }
- }
- return true
-}
-
-func (d *decoder) mappingStruct(n *Node, out reflect.Value) (good bool) {
- sinfo, err := getStructInfo(out.Type())
- if err != nil {
- panic(err)
- }
-
- var inlineMap reflect.Value
- var elemType reflect.Type
- if sinfo.InlineMap != -1 {
- inlineMap = out.Field(sinfo.InlineMap)
- elemType = inlineMap.Type().Elem()
- }
-
- for _, index := range sinfo.InlineUnmarshalers {
- field := d.fieldByIndex(n, out, index)
- d.prepare(n, field)
- }
-
- mergedFields := d.mergedFields
- d.mergedFields = nil
- var mergeNode *Node
- var doneFields []bool
- if d.uniqueKeys {
- doneFields = make([]bool, len(sinfo.FieldsList))
- }
- name := settableValueOf("")
- l := len(n.Content)
- for i := 0; i < l; i += 2 {
- ni := n.Content[i]
- if isMerge(ni) {
- mergeNode = n.Content[i+1]
- continue
- }
- if !d.unmarshal(ni, name) {
- continue
- }
- sname := name.String()
- if mergedFields != nil {
- if mergedFields[sname] {
- continue
- }
- mergedFields[sname] = true
- }
- if info, ok := sinfo.FieldsMap[sname]; ok {
- if d.uniqueKeys {
- if doneFields[info.Id] {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: field %s already set in type %s", ni.Line, name.String(), out.Type()))
- continue
- }
- doneFields[info.Id] = true
- }
- var field reflect.Value
- if info.Inline == nil {
- field = out.Field(info.Num)
- } else {
- field = d.fieldByIndex(n, out, info.Inline)
- }
- d.unmarshal(n.Content[i+1], field)
- } else if sinfo.InlineMap != -1 {
- if inlineMap.IsNil() {
- inlineMap.Set(reflect.MakeMap(inlineMap.Type()))
- }
- value := reflect.New(elemType).Elem()
- d.unmarshal(n.Content[i+1], value)
- inlineMap.SetMapIndex(name, value)
- } else if d.knownFields {
- d.terrors = append(d.terrors, fmt.Sprintf("line %d: field %s not found in type %s", ni.Line, name.String(), out.Type()))
- }
- }
-
- d.mergedFields = mergedFields
- if mergeNode != nil {
- d.merge(n, mergeNode, out)
- }
- return true
-}
-
-func failWantMap() {
- failf("map merge requires map or sequence of maps as the value")
-}
-
-func (d *decoder) merge(parent *Node, merge *Node, out reflect.Value) {
- mergedFields := d.mergedFields
- if mergedFields == nil {
- d.mergedFields = make(map[interface{}]bool)
- for i := 0; i < len(parent.Content); i += 2 {
- k := reflect.New(ifaceType).Elem()
- if d.unmarshal(parent.Content[i], k) {
- d.mergedFields[k.Interface()] = true
- }
- }
- }
-
- switch merge.Kind {
- case MappingNode:
- d.unmarshal(merge, out)
- case AliasNode:
- if merge.Alias != nil && merge.Alias.Kind != MappingNode {
- failWantMap()
- }
- d.unmarshal(merge, out)
- case SequenceNode:
- for i := 0; i < len(merge.Content); i++ {
- ni := merge.Content[i]
- if ni.Kind == AliasNode {
- if ni.Alias != nil && ni.Alias.Kind != MappingNode {
- failWantMap()
- }
- } else if ni.Kind != MappingNode {
- failWantMap()
- }
- d.unmarshal(ni, out)
- }
- default:
- failWantMap()
- }
-
- d.mergedFields = mergedFields
-}
-
-func isMerge(n *Node) bool {
- return n.Kind == ScalarNode && n.Value == "<<" && (n.Tag == "" || n.Tag == "!" || shortTag(n.Tag) == mergeTag)
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/emitterc.go b/sesh/vendor/gopkg.in/yaml.v3/emitterc.go
deleted file mode 100644
index 0f47c9c..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/emitterc.go
+++ /dev/null
@@ -1,2020 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
- "fmt"
-)
-
-// Flush the buffer if needed.
-func flush(emitter *yaml_emitter_t) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) {
- return yaml_emitter_flush(emitter)
- }
- return true
-}
-
-// Put a character to the output buffer.
-func put(emitter *yaml_emitter_t, value byte) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.buffer[emitter.buffer_pos] = value
- emitter.buffer_pos++
- emitter.column++
- return true
-}
-
-// Put a line break to the output buffer.
-func put_break(emitter *yaml_emitter_t) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- switch emitter.line_break {
- case yaml_CR_BREAK:
- emitter.buffer[emitter.buffer_pos] = '\r'
- emitter.buffer_pos += 1
- case yaml_LN_BREAK:
- emitter.buffer[emitter.buffer_pos] = '\n'
- emitter.buffer_pos += 1
- case yaml_CRLN_BREAK:
- emitter.buffer[emitter.buffer_pos+0] = '\r'
- emitter.buffer[emitter.buffer_pos+1] = '\n'
- emitter.buffer_pos += 2
- default:
- panic("unknown line break setting")
- }
- if emitter.column == 0 {
- emitter.space_above = true
- }
- emitter.column = 0
- emitter.line++
- // [Go] Do this here and below and drop from everywhere else (see commented lines).
- emitter.indention = true
- return true
-}
-
-// Copy a character from a string into buffer.
-func write(emitter *yaml_emitter_t, s []byte, i *int) bool {
- if emitter.buffer_pos+5 >= len(emitter.buffer) && !yaml_emitter_flush(emitter) {
- return false
- }
- p := emitter.buffer_pos
- w := width(s[*i])
- switch w {
- case 4:
- emitter.buffer[p+3] = s[*i+3]
- fallthrough
- case 3:
- emitter.buffer[p+2] = s[*i+2]
- fallthrough
- case 2:
- emitter.buffer[p+1] = s[*i+1]
- fallthrough
- case 1:
- emitter.buffer[p+0] = s[*i+0]
- default:
- panic("unknown character width")
- }
- emitter.column++
- emitter.buffer_pos += w
- *i += w
- return true
-}
-
-// Write a whole string into buffer.
-func write_all(emitter *yaml_emitter_t, s []byte) bool {
- for i := 0; i < len(s); {
- if !write(emitter, s, &i) {
- return false
- }
- }
- return true
-}
-
-// Copy a line break character from a string into buffer.
-func write_break(emitter *yaml_emitter_t, s []byte, i *int) bool {
- if s[*i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- *i++
- } else {
- if !write(emitter, s, i) {
- return false
- }
- if emitter.column == 0 {
- emitter.space_above = true
- }
- emitter.column = 0
- emitter.line++
- // [Go] Do this here and above and drop from everywhere else (see commented lines).
- emitter.indention = true
- }
- return true
-}
-
-// Set an emitter error and return false.
-func yaml_emitter_set_emitter_error(emitter *yaml_emitter_t, problem string) bool {
- emitter.error = yaml_EMITTER_ERROR
- emitter.problem = problem
- return false
-}
-
-// Emit an event.
-func yaml_emitter_emit(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- emitter.events = append(emitter.events, *event)
- for !yaml_emitter_need_more_events(emitter) {
- event := &emitter.events[emitter.events_head]
- if !yaml_emitter_analyze_event(emitter, event) {
- return false
- }
- if !yaml_emitter_state_machine(emitter, event) {
- return false
- }
- yaml_event_delete(event)
- emitter.events_head++
- }
- return true
-}
-
-// Check if we need to accumulate more events before emitting.
-//
-// We accumulate extra
-// - 1 event for DOCUMENT-START
-// - 2 events for SEQUENCE-START
-// - 3 events for MAPPING-START
-//
-func yaml_emitter_need_more_events(emitter *yaml_emitter_t) bool {
- if emitter.events_head == len(emitter.events) {
- return true
- }
- var accumulate int
- switch emitter.events[emitter.events_head].typ {
- case yaml_DOCUMENT_START_EVENT:
- accumulate = 1
- break
- case yaml_SEQUENCE_START_EVENT:
- accumulate = 2
- break
- case yaml_MAPPING_START_EVENT:
- accumulate = 3
- break
- default:
- return false
- }
- if len(emitter.events)-emitter.events_head > accumulate {
- return false
- }
- var level int
- for i := emitter.events_head; i < len(emitter.events); i++ {
- switch emitter.events[i].typ {
- case yaml_STREAM_START_EVENT, yaml_DOCUMENT_START_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT:
- level++
- case yaml_STREAM_END_EVENT, yaml_DOCUMENT_END_EVENT, yaml_SEQUENCE_END_EVENT, yaml_MAPPING_END_EVENT:
- level--
- }
- if level == 0 {
- return false
- }
- }
- return true
-}
-
-// Append a directive to the directives stack.
-func yaml_emitter_append_tag_directive(emitter *yaml_emitter_t, value *yaml_tag_directive_t, allow_duplicates bool) bool {
- for i := 0; i < len(emitter.tag_directives); i++ {
- if bytes.Equal(value.handle, emitter.tag_directives[i].handle) {
- if allow_duplicates {
- return true
- }
- return yaml_emitter_set_emitter_error(emitter, "duplicate %TAG directive")
- }
- }
-
- // [Go] Do we actually need to copy this given garbage collection
- // and the lack of deallocating destructors?
- tag_copy := yaml_tag_directive_t{
- handle: make([]byte, len(value.handle)),
- prefix: make([]byte, len(value.prefix)),
- }
- copy(tag_copy.handle, value.handle)
- copy(tag_copy.prefix, value.prefix)
- emitter.tag_directives = append(emitter.tag_directives, tag_copy)
- return true
-}
-
-// Increase the indentation level.
-func yaml_emitter_increase_indent(emitter *yaml_emitter_t, flow, indentless bool) bool {
- emitter.indents = append(emitter.indents, emitter.indent)
- if emitter.indent < 0 {
- if flow {
- emitter.indent = emitter.best_indent
- } else {
- emitter.indent = 0
- }
- } else if !indentless {
- // [Go] This was changed so that indentations are more regular.
- if emitter.states[len(emitter.states)-1] == yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE {
- // The first indent inside a sequence will just skip the "- " indicator.
- emitter.indent += 2
- } else {
- // Everything else aligns to the chosen indentation.
- emitter.indent = emitter.best_indent*((emitter.indent+emitter.best_indent)/emitter.best_indent)
- }
- }
- return true
-}
-
-// State dispatcher.
-func yaml_emitter_state_machine(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- switch emitter.state {
- default:
- case yaml_EMIT_STREAM_START_STATE:
- return yaml_emitter_emit_stream_start(emitter, event)
-
- case yaml_EMIT_FIRST_DOCUMENT_START_STATE:
- return yaml_emitter_emit_document_start(emitter, event, true)
-
- case yaml_EMIT_DOCUMENT_START_STATE:
- return yaml_emitter_emit_document_start(emitter, event, false)
-
- case yaml_EMIT_DOCUMENT_CONTENT_STATE:
- return yaml_emitter_emit_document_content(emitter, event)
-
- case yaml_EMIT_DOCUMENT_END_STATE:
- return yaml_emitter_emit_document_end(emitter, event)
-
- case yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, true, false)
-
- case yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, false, true)
-
- case yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE:
- return yaml_emitter_emit_flow_sequence_item(emitter, event, false, false)
-
- case yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, true, false)
-
- case yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, false, true)
-
- case yaml_EMIT_FLOW_MAPPING_KEY_STATE:
- return yaml_emitter_emit_flow_mapping_key(emitter, event, false, false)
-
- case yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE:
- return yaml_emitter_emit_flow_mapping_value(emitter, event, true)
-
- case yaml_EMIT_FLOW_MAPPING_VALUE_STATE:
- return yaml_emitter_emit_flow_mapping_value(emitter, event, false)
-
- case yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE:
- return yaml_emitter_emit_block_sequence_item(emitter, event, true)
-
- case yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE:
- return yaml_emitter_emit_block_sequence_item(emitter, event, false)
-
- case yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE:
- return yaml_emitter_emit_block_mapping_key(emitter, event, true)
-
- case yaml_EMIT_BLOCK_MAPPING_KEY_STATE:
- return yaml_emitter_emit_block_mapping_key(emitter, event, false)
-
- case yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE:
- return yaml_emitter_emit_block_mapping_value(emitter, event, true)
-
- case yaml_EMIT_BLOCK_MAPPING_VALUE_STATE:
- return yaml_emitter_emit_block_mapping_value(emitter, event, false)
-
- case yaml_EMIT_END_STATE:
- return yaml_emitter_set_emitter_error(emitter, "expected nothing after STREAM-END")
- }
- panic("invalid emitter state")
-}
-
-// Expect STREAM-START.
-func yaml_emitter_emit_stream_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if event.typ != yaml_STREAM_START_EVENT {
- return yaml_emitter_set_emitter_error(emitter, "expected STREAM-START")
- }
- if emitter.encoding == yaml_ANY_ENCODING {
- emitter.encoding = event.encoding
- if emitter.encoding == yaml_ANY_ENCODING {
- emitter.encoding = yaml_UTF8_ENCODING
- }
- }
- if emitter.best_indent < 2 || emitter.best_indent > 9 {
- emitter.best_indent = 2
- }
- if emitter.best_width >= 0 && emitter.best_width <= emitter.best_indent*2 {
- emitter.best_width = 80
- }
- if emitter.best_width < 0 {
- emitter.best_width = 1<<31 - 1
- }
- if emitter.line_break == yaml_ANY_BREAK {
- emitter.line_break = yaml_LN_BREAK
- }
-
- emitter.indent = -1
- emitter.line = 0
- emitter.column = 0
- emitter.whitespace = true
- emitter.indention = true
- emitter.space_above = true
- emitter.foot_indent = -1
-
- if emitter.encoding != yaml_UTF8_ENCODING {
- if !yaml_emitter_write_bom(emitter) {
- return false
- }
- }
- emitter.state = yaml_EMIT_FIRST_DOCUMENT_START_STATE
- return true
-}
-
-// Expect DOCUMENT-START or STREAM-END.
-func yaml_emitter_emit_document_start(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
-
- if event.typ == yaml_DOCUMENT_START_EVENT {
-
- if event.version_directive != nil {
- if !yaml_emitter_analyze_version_directive(emitter, event.version_directive) {
- return false
- }
- }
-
- for i := 0; i < len(event.tag_directives); i++ {
- tag_directive := &event.tag_directives[i]
- if !yaml_emitter_analyze_tag_directive(emitter, tag_directive) {
- return false
- }
- if !yaml_emitter_append_tag_directive(emitter, tag_directive, false) {
- return false
- }
- }
-
- for i := 0; i < len(default_tag_directives); i++ {
- tag_directive := &default_tag_directives[i]
- if !yaml_emitter_append_tag_directive(emitter, tag_directive, true) {
- return false
- }
- }
-
- implicit := event.implicit
- if !first || emitter.canonical {
- implicit = false
- }
-
- if emitter.open_ended && (event.version_directive != nil || len(event.tag_directives) > 0) {
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if event.version_directive != nil {
- implicit = false
- if !yaml_emitter_write_indicator(emitter, []byte("%YAML"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte("1.1"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if len(event.tag_directives) > 0 {
- implicit = false
- for i := 0; i < len(event.tag_directives); i++ {
- tag_directive := &event.tag_directives[i]
- if !yaml_emitter_write_indicator(emitter, []byte("%TAG"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_tag_handle(emitter, tag_directive.handle) {
- return false
- }
- if !yaml_emitter_write_tag_content(emitter, tag_directive.prefix, true) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- }
-
- if yaml_emitter_check_empty_document(emitter) {
- implicit = false
- }
- if !implicit {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte("---"), true, false, false) {
- return false
- }
- if emitter.canonical || true {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- }
-
- if len(emitter.head_comment) > 0 {
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !put_break(emitter) {
- return false
- }
- }
-
- emitter.state = yaml_EMIT_DOCUMENT_CONTENT_STATE
- return true
- }
-
- if event.typ == yaml_STREAM_END_EVENT {
- if emitter.open_ended {
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.state = yaml_EMIT_END_STATE
- return true
- }
-
- return yaml_emitter_set_emitter_error(emitter, "expected DOCUMENT-START or STREAM-END")
-}
-
-// Expect the root node.
-func yaml_emitter_emit_document_content(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- emitter.states = append(emitter.states, yaml_EMIT_DOCUMENT_END_STATE)
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !yaml_emitter_emit_node(emitter, event, true, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect DOCUMENT-END.
-func yaml_emitter_emit_document_end(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if event.typ != yaml_DOCUMENT_END_EVENT {
- return yaml_emitter_set_emitter_error(emitter, "expected DOCUMENT-END")
- }
- // [Go] Force document foot separation.
- emitter.foot_indent = 0
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.foot_indent = -1
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !event.implicit {
- // [Go] Allocate the slice elsewhere.
- if !yaml_emitter_write_indicator(emitter, []byte("..."), true, false, false) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_flush(emitter) {
- return false
- }
- emitter.state = yaml_EMIT_DOCUMENT_START_STATE
- emitter.tag_directives = emitter.tag_directives[:0]
- return true
-}
-
-// Expect a flow item node.
-func yaml_emitter_emit_flow_sequence_item(emitter *yaml_emitter_t, event *yaml_event_t, first, trail bool) bool {
- if first {
- if !yaml_emitter_write_indicator(emitter, []byte{'['}, true, true, false) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- emitter.flow_level++
- }
-
- if event.typ == yaml_SEQUENCE_END_EVENT {
- if emitter.canonical && !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- emitter.flow_level--
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- if emitter.column == 0 || emitter.canonical && !first {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{']'}, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
-
- return true
- }
-
- if !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if emitter.column == 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE)
- } else {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE)
- }
- if !yaml_emitter_emit_node(emitter, event, false, true, false, false) {
- return false
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a flow key node.
-func yaml_emitter_emit_flow_mapping_key(emitter *yaml_emitter_t, event *yaml_event_t, first, trail bool) bool {
- if first {
- if !yaml_emitter_write_indicator(emitter, []byte{'{'}, true, true, false) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- emitter.flow_level++
- }
-
- if event.typ == yaml_MAPPING_END_EVENT {
- if (emitter.canonical || len(emitter.head_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0) && !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- emitter.flow_level--
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- if emitter.canonical && !first {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'}'}, false, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
-
- if !first && !trail {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
-
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
-
- if emitter.column == 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
-
- if !emitter.canonical && yaml_emitter_check_simple_key(emitter) {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, true)
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'?'}, true, false, false) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, false)
-}
-
-// Expect a flow value node.
-func yaml_emitter_emit_flow_mapping_value(emitter *yaml_emitter_t, event *yaml_event_t, simple bool) bool {
- if simple {
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, false, false, false) {
- return false
- }
- } else {
- if emitter.canonical || emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, true, false, false) {
- return false
- }
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE)
- } else {
- emitter.states = append(emitter.states, yaml_EMIT_FLOW_MAPPING_KEY_STATE)
- }
- if !yaml_emitter_emit_node(emitter, event, false, false, true, false) {
- return false
- }
- if len(emitter.line_comment)+len(emitter.foot_comment)+len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indicator(emitter, []byte{','}, false, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a block item node.
-func yaml_emitter_emit_block_sequence_item(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
- if first {
- if !yaml_emitter_increase_indent(emitter, false, false) {
- return false
- }
- }
- if event.typ == yaml_SEQUENCE_END_EVENT {
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'-'}, true, false, true) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE)
- if !yaml_emitter_emit_node(emitter, event, false, true, false, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-// Expect a block key node.
-func yaml_emitter_emit_block_mapping_key(emitter *yaml_emitter_t, event *yaml_event_t, first bool) bool {
- if first {
- if !yaml_emitter_increase_indent(emitter, false, false) {
- return false
- }
- }
- if !yaml_emitter_process_head_comment(emitter) {
- return false
- }
- if event.typ == yaml_MAPPING_END_EVENT {
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if len(emitter.line_comment) > 0 {
- // [Go] A line comment was provided for the key. That's unusual as the
- // scanner associates line comments with the value. Either way,
- // save the line comment and render it appropriately later.
- emitter.key_line_comment = emitter.line_comment
- emitter.line_comment = nil
- }
- if yaml_emitter_check_simple_key(emitter) {
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, true)
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'?'}, true, false, true) {
- return false
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_VALUE_STATE)
- return yaml_emitter_emit_node(emitter, event, false, false, true, false)
-}
-
-// Expect a block value node.
-func yaml_emitter_emit_block_mapping_value(emitter *yaml_emitter_t, event *yaml_event_t, simple bool) bool {
- if simple {
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, false, false, false) {
- return false
- }
- } else {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{':'}, true, false, true) {
- return false
- }
- }
- if len(emitter.key_line_comment) > 0 {
- // [Go] Line comments are generally associated with the value, but when there's
- // no value on the same line as a mapping key they end up attached to the
- // key itself.
- if event.typ == yaml_SCALAR_EVENT {
- if len(emitter.line_comment) == 0 {
- // A scalar is coming and it has no line comments by itself yet,
- // so just let it handle the line comment as usual. If it has a
- // line comment, we can't have both so the one from the key is lost.
- emitter.line_comment = emitter.key_line_comment
- emitter.key_line_comment = nil
- }
- } else if event.sequence_style() != yaml_FLOW_SEQUENCE_STYLE && (event.typ == yaml_MAPPING_START_EVENT || event.typ == yaml_SEQUENCE_START_EVENT) {
- // An indented block follows, so write the comment right now.
- emitter.line_comment, emitter.key_line_comment = emitter.key_line_comment, emitter.line_comment
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- emitter.line_comment, emitter.key_line_comment = emitter.key_line_comment, emitter.line_comment
- }
- }
- emitter.states = append(emitter.states, yaml_EMIT_BLOCK_MAPPING_KEY_STATE)
- if !yaml_emitter_emit_node(emitter, event, false, false, true, false) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- if !yaml_emitter_process_foot_comment(emitter) {
- return false
- }
- return true
-}
-
-func yaml_emitter_silent_nil_event(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- return event.typ == yaml_SCALAR_EVENT && event.implicit && !emitter.canonical && len(emitter.scalar_data.value) == 0
-}
-
-// Expect a node.
-func yaml_emitter_emit_node(emitter *yaml_emitter_t, event *yaml_event_t,
- root bool, sequence bool, mapping bool, simple_key bool) bool {
-
- emitter.root_context = root
- emitter.sequence_context = sequence
- emitter.mapping_context = mapping
- emitter.simple_key_context = simple_key
-
- switch event.typ {
- case yaml_ALIAS_EVENT:
- return yaml_emitter_emit_alias(emitter, event)
- case yaml_SCALAR_EVENT:
- return yaml_emitter_emit_scalar(emitter, event)
- case yaml_SEQUENCE_START_EVENT:
- return yaml_emitter_emit_sequence_start(emitter, event)
- case yaml_MAPPING_START_EVENT:
- return yaml_emitter_emit_mapping_start(emitter, event)
- default:
- return yaml_emitter_set_emitter_error(emitter,
- fmt.Sprintf("expected SCALAR, SEQUENCE-START, MAPPING-START, or ALIAS, but got %v", event.typ))
- }
-}
-
-// Expect ALIAS.
-func yaml_emitter_emit_alias(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
-}
-
-// Expect SCALAR.
-func yaml_emitter_emit_scalar(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_select_scalar_style(emitter, event) {
- return false
- }
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if !yaml_emitter_increase_indent(emitter, true, false) {
- return false
- }
- if !yaml_emitter_process_scalar(emitter) {
- return false
- }
- emitter.indent = emitter.indents[len(emitter.indents)-1]
- emitter.indents = emitter.indents[:len(emitter.indents)-1]
- emitter.state = emitter.states[len(emitter.states)-1]
- emitter.states = emitter.states[:len(emitter.states)-1]
- return true
-}
-
-// Expect SEQUENCE-START.
-func yaml_emitter_emit_sequence_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if emitter.flow_level > 0 || emitter.canonical || event.sequence_style() == yaml_FLOW_SEQUENCE_STYLE ||
- yaml_emitter_check_empty_sequence(emitter) {
- emitter.state = yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE
- } else {
- emitter.state = yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE
- }
- return true
-}
-
-// Expect MAPPING-START.
-func yaml_emitter_emit_mapping_start(emitter *yaml_emitter_t, event *yaml_event_t) bool {
- if !yaml_emitter_process_anchor(emitter) {
- return false
- }
- if !yaml_emitter_process_tag(emitter) {
- return false
- }
- if emitter.flow_level > 0 || emitter.canonical || event.mapping_style() == yaml_FLOW_MAPPING_STYLE ||
- yaml_emitter_check_empty_mapping(emitter) {
- emitter.state = yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE
- } else {
- emitter.state = yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE
- }
- return true
-}
-
-// Check if the document content is an empty scalar.
-func yaml_emitter_check_empty_document(emitter *yaml_emitter_t) bool {
- return false // [Go] Huh?
-}
-
-// Check if the next events represent an empty sequence.
-func yaml_emitter_check_empty_sequence(emitter *yaml_emitter_t) bool {
- if len(emitter.events)-emitter.events_head < 2 {
- return false
- }
- return emitter.events[emitter.events_head].typ == yaml_SEQUENCE_START_EVENT &&
- emitter.events[emitter.events_head+1].typ == yaml_SEQUENCE_END_EVENT
-}
-
-// Check if the next events represent an empty mapping.
-func yaml_emitter_check_empty_mapping(emitter *yaml_emitter_t) bool {
- if len(emitter.events)-emitter.events_head < 2 {
- return false
- }
- return emitter.events[emitter.events_head].typ == yaml_MAPPING_START_EVENT &&
- emitter.events[emitter.events_head+1].typ == yaml_MAPPING_END_EVENT
-}
-
-// Check if the next node can be expressed as a simple key.
-func yaml_emitter_check_simple_key(emitter *yaml_emitter_t) bool {
- length := 0
- switch emitter.events[emitter.events_head].typ {
- case yaml_ALIAS_EVENT:
- length += len(emitter.anchor_data.anchor)
- case yaml_SCALAR_EVENT:
- if emitter.scalar_data.multiline {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix) +
- len(emitter.scalar_data.value)
- case yaml_SEQUENCE_START_EVENT:
- if !yaml_emitter_check_empty_sequence(emitter) {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix)
- case yaml_MAPPING_START_EVENT:
- if !yaml_emitter_check_empty_mapping(emitter) {
- return false
- }
- length += len(emitter.anchor_data.anchor) +
- len(emitter.tag_data.handle) +
- len(emitter.tag_data.suffix)
- default:
- return false
- }
- return length <= 128
-}
-
-// Determine an acceptable scalar style.
-func yaml_emitter_select_scalar_style(emitter *yaml_emitter_t, event *yaml_event_t) bool {
-
- no_tag := len(emitter.tag_data.handle) == 0 && len(emitter.tag_data.suffix) == 0
- if no_tag && !event.implicit && !event.quoted_implicit {
- return yaml_emitter_set_emitter_error(emitter, "neither tag nor implicit flags are specified")
- }
-
- style := event.scalar_style()
- if style == yaml_ANY_SCALAR_STYLE {
- style = yaml_PLAIN_SCALAR_STYLE
- }
- if emitter.canonical {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- if emitter.simple_key_context && emitter.scalar_data.multiline {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
-
- if style == yaml_PLAIN_SCALAR_STYLE {
- if emitter.flow_level > 0 && !emitter.scalar_data.flow_plain_allowed ||
- emitter.flow_level == 0 && !emitter.scalar_data.block_plain_allowed {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- if len(emitter.scalar_data.value) == 0 && (emitter.flow_level > 0 || emitter.simple_key_context) {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- if no_tag && !event.implicit {
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- }
- }
- if style == yaml_SINGLE_QUOTED_SCALAR_STYLE {
- if !emitter.scalar_data.single_quoted_allowed {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- }
- if style == yaml_LITERAL_SCALAR_STYLE || style == yaml_FOLDED_SCALAR_STYLE {
- if !emitter.scalar_data.block_allowed || emitter.flow_level > 0 || emitter.simple_key_context {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- }
-
- if no_tag && !event.quoted_implicit && style != yaml_PLAIN_SCALAR_STYLE {
- emitter.tag_data.handle = []byte{'!'}
- }
- emitter.scalar_data.style = style
- return true
-}
-
-// Write an anchor.
-func yaml_emitter_process_anchor(emitter *yaml_emitter_t) bool {
- if emitter.anchor_data.anchor == nil {
- return true
- }
- c := []byte{'&'}
- if emitter.anchor_data.alias {
- c[0] = '*'
- }
- if !yaml_emitter_write_indicator(emitter, c, true, false, false) {
- return false
- }
- return yaml_emitter_write_anchor(emitter, emitter.anchor_data.anchor)
-}
-
-// Write a tag.
-func yaml_emitter_process_tag(emitter *yaml_emitter_t) bool {
- if len(emitter.tag_data.handle) == 0 && len(emitter.tag_data.suffix) == 0 {
- return true
- }
- if len(emitter.tag_data.handle) > 0 {
- if !yaml_emitter_write_tag_handle(emitter, emitter.tag_data.handle) {
- return false
- }
- if len(emitter.tag_data.suffix) > 0 {
- if !yaml_emitter_write_tag_content(emitter, emitter.tag_data.suffix, false) {
- return false
- }
- }
- } else {
- // [Go] Allocate these slices elsewhere.
- if !yaml_emitter_write_indicator(emitter, []byte("!<"), true, false, false) {
- return false
- }
- if !yaml_emitter_write_tag_content(emitter, emitter.tag_data.suffix, false) {
- return false
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'>'}, false, false, false) {
- return false
- }
- }
- return true
-}
-
-// Write a scalar.
-func yaml_emitter_process_scalar(emitter *yaml_emitter_t) bool {
- switch emitter.scalar_data.style {
- case yaml_PLAIN_SCALAR_STYLE:
- return yaml_emitter_write_plain_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_SINGLE_QUOTED_SCALAR_STYLE:
- return yaml_emitter_write_single_quoted_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_DOUBLE_QUOTED_SCALAR_STYLE:
- return yaml_emitter_write_double_quoted_scalar(emitter, emitter.scalar_data.value, !emitter.simple_key_context)
-
- case yaml_LITERAL_SCALAR_STYLE:
- return yaml_emitter_write_literal_scalar(emitter, emitter.scalar_data.value)
-
- case yaml_FOLDED_SCALAR_STYLE:
- return yaml_emitter_write_folded_scalar(emitter, emitter.scalar_data.value)
- }
- panic("unknown scalar style")
-}
-
-// Write a head comment.
-func yaml_emitter_process_head_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.tail_comment) > 0 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.tail_comment) {
- return false
- }
- emitter.tail_comment = emitter.tail_comment[:0]
- emitter.foot_indent = emitter.indent
- if emitter.foot_indent < 0 {
- emitter.foot_indent = 0
- }
- }
-
- if len(emitter.head_comment) == 0 {
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.head_comment) {
- return false
- }
- emitter.head_comment = emitter.head_comment[:0]
- return true
-}
-
-// Write an line comment.
-func yaml_emitter_process_line_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.line_comment) == 0 {
- return true
- }
- if !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !yaml_emitter_write_comment(emitter, emitter.line_comment) {
- return false
- }
- emitter.line_comment = emitter.line_comment[:0]
- return true
-}
-
-// Write a foot comment.
-func yaml_emitter_process_foot_comment(emitter *yaml_emitter_t) bool {
- if len(emitter.foot_comment) == 0 {
- return true
- }
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !yaml_emitter_write_comment(emitter, emitter.foot_comment) {
- return false
- }
- emitter.foot_comment = emitter.foot_comment[:0]
- emitter.foot_indent = emitter.indent
- if emitter.foot_indent < 0 {
- emitter.foot_indent = 0
- }
- return true
-}
-
-// Check if a %YAML directive is valid.
-func yaml_emitter_analyze_version_directive(emitter *yaml_emitter_t, version_directive *yaml_version_directive_t) bool {
- if version_directive.major != 1 || version_directive.minor != 1 {
- return yaml_emitter_set_emitter_error(emitter, "incompatible %YAML directive")
- }
- return true
-}
-
-// Check if a %TAG directive is valid.
-func yaml_emitter_analyze_tag_directive(emitter *yaml_emitter_t, tag_directive *yaml_tag_directive_t) bool {
- handle := tag_directive.handle
- prefix := tag_directive.prefix
- if len(handle) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must not be empty")
- }
- if handle[0] != '!' {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must start with '!'")
- }
- if handle[len(handle)-1] != '!' {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must end with '!'")
- }
- for i := 1; i < len(handle)-1; i += width(handle[i]) {
- if !is_alpha(handle, i) {
- return yaml_emitter_set_emitter_error(emitter, "tag handle must contain alphanumerical characters only")
- }
- }
- if len(prefix) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag prefix must not be empty")
- }
- return true
-}
-
-// Check if an anchor is valid.
-func yaml_emitter_analyze_anchor(emitter *yaml_emitter_t, anchor []byte, alias bool) bool {
- if len(anchor) == 0 {
- problem := "anchor value must not be empty"
- if alias {
- problem = "alias value must not be empty"
- }
- return yaml_emitter_set_emitter_error(emitter, problem)
- }
- for i := 0; i < len(anchor); i += width(anchor[i]) {
- if !is_alpha(anchor, i) {
- problem := "anchor value must contain alphanumerical characters only"
- if alias {
- problem = "alias value must contain alphanumerical characters only"
- }
- return yaml_emitter_set_emitter_error(emitter, problem)
- }
- }
- emitter.anchor_data.anchor = anchor
- emitter.anchor_data.alias = alias
- return true
-}
-
-// Check if a tag is valid.
-func yaml_emitter_analyze_tag(emitter *yaml_emitter_t, tag []byte) bool {
- if len(tag) == 0 {
- return yaml_emitter_set_emitter_error(emitter, "tag value must not be empty")
- }
- for i := 0; i < len(emitter.tag_directives); i++ {
- tag_directive := &emitter.tag_directives[i]
- if bytes.HasPrefix(tag, tag_directive.prefix) {
- emitter.tag_data.handle = tag_directive.handle
- emitter.tag_data.suffix = tag[len(tag_directive.prefix):]
- return true
- }
- }
- emitter.tag_data.suffix = tag
- return true
-}
-
-// Check if a scalar is valid.
-func yaml_emitter_analyze_scalar(emitter *yaml_emitter_t, value []byte) bool {
- var (
- block_indicators = false
- flow_indicators = false
- line_breaks = false
- special_characters = false
- tab_characters = false
-
- leading_space = false
- leading_break = false
- trailing_space = false
- trailing_break = false
- break_space = false
- space_break = false
-
- preceded_by_whitespace = false
- followed_by_whitespace = false
- previous_space = false
- previous_break = false
- )
-
- emitter.scalar_data.value = value
-
- if len(value) == 0 {
- emitter.scalar_data.multiline = false
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = true
- emitter.scalar_data.single_quoted_allowed = true
- emitter.scalar_data.block_allowed = false
- return true
- }
-
- if len(value) >= 3 && ((value[0] == '-' && value[1] == '-' && value[2] == '-') || (value[0] == '.' && value[1] == '.' && value[2] == '.')) {
- block_indicators = true
- flow_indicators = true
- }
-
- preceded_by_whitespace = true
- for i, w := 0, 0; i < len(value); i += w {
- w = width(value[i])
- followed_by_whitespace = i+w >= len(value) || is_blank(value, i+w)
-
- if i == 0 {
- switch value[i] {
- case '#', ',', '[', ']', '{', '}', '&', '*', '!', '|', '>', '\'', '"', '%', '@', '`':
- flow_indicators = true
- block_indicators = true
- case '?', ':':
- flow_indicators = true
- if followed_by_whitespace {
- block_indicators = true
- }
- case '-':
- if followed_by_whitespace {
- flow_indicators = true
- block_indicators = true
- }
- }
- } else {
- switch value[i] {
- case ',', '?', '[', ']', '{', '}':
- flow_indicators = true
- case ':':
- flow_indicators = true
- if followed_by_whitespace {
- block_indicators = true
- }
- case '#':
- if preceded_by_whitespace {
- flow_indicators = true
- block_indicators = true
- }
- }
- }
-
- if value[i] == '\t' {
- tab_characters = true
- } else if !is_printable(value, i) || !is_ascii(value, i) && !emitter.unicode {
- special_characters = true
- }
- if is_space(value, i) {
- if i == 0 {
- leading_space = true
- }
- if i+width(value[i]) == len(value) {
- trailing_space = true
- }
- if previous_break {
- break_space = true
- }
- previous_space = true
- previous_break = false
- } else if is_break(value, i) {
- line_breaks = true
- if i == 0 {
- leading_break = true
- }
- if i+width(value[i]) == len(value) {
- trailing_break = true
- }
- if previous_space {
- space_break = true
- }
- previous_space = false
- previous_break = true
- } else {
- previous_space = false
- previous_break = false
- }
-
- // [Go]: Why 'z'? Couldn't be the end of the string as that's the loop condition.
- preceded_by_whitespace = is_blankz(value, i)
- }
-
- emitter.scalar_data.multiline = line_breaks
- emitter.scalar_data.flow_plain_allowed = true
- emitter.scalar_data.block_plain_allowed = true
- emitter.scalar_data.single_quoted_allowed = true
- emitter.scalar_data.block_allowed = true
-
- if leading_space || leading_break || trailing_space || trailing_break {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- }
- if trailing_space {
- emitter.scalar_data.block_allowed = false
- }
- if break_space {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- emitter.scalar_data.single_quoted_allowed = false
- }
- if space_break || tab_characters || special_characters {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- emitter.scalar_data.single_quoted_allowed = false
- }
- if space_break || special_characters {
- emitter.scalar_data.block_allowed = false
- }
- if line_breaks {
- emitter.scalar_data.flow_plain_allowed = false
- emitter.scalar_data.block_plain_allowed = false
- }
- if flow_indicators {
- emitter.scalar_data.flow_plain_allowed = false
- }
- if block_indicators {
- emitter.scalar_data.block_plain_allowed = false
- }
- return true
-}
-
-// Check if the event data is valid.
-func yaml_emitter_analyze_event(emitter *yaml_emitter_t, event *yaml_event_t) bool {
-
- emitter.anchor_data.anchor = nil
- emitter.tag_data.handle = nil
- emitter.tag_data.suffix = nil
- emitter.scalar_data.value = nil
-
- if len(event.head_comment) > 0 {
- emitter.head_comment = event.head_comment
- }
- if len(event.line_comment) > 0 {
- emitter.line_comment = event.line_comment
- }
- if len(event.foot_comment) > 0 {
- emitter.foot_comment = event.foot_comment
- }
- if len(event.tail_comment) > 0 {
- emitter.tail_comment = event.tail_comment
- }
-
- switch event.typ {
- case yaml_ALIAS_EVENT:
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, true) {
- return false
- }
-
- case yaml_SCALAR_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || (!event.implicit && !event.quoted_implicit)) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
- if !yaml_emitter_analyze_scalar(emitter, event.value) {
- return false
- }
-
- case yaml_SEQUENCE_START_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || !event.implicit) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
-
- case yaml_MAPPING_START_EVENT:
- if len(event.anchor) > 0 {
- if !yaml_emitter_analyze_anchor(emitter, event.anchor, false) {
- return false
- }
- }
- if len(event.tag) > 0 && (emitter.canonical || !event.implicit) {
- if !yaml_emitter_analyze_tag(emitter, event.tag) {
- return false
- }
- }
- }
- return true
-}
-
-// Write the BOM character.
-func yaml_emitter_write_bom(emitter *yaml_emitter_t) bool {
- if !flush(emitter) {
- return false
- }
- pos := emitter.buffer_pos
- emitter.buffer[pos+0] = '\xEF'
- emitter.buffer[pos+1] = '\xBB'
- emitter.buffer[pos+2] = '\xBF'
- emitter.buffer_pos += 3
- return true
-}
-
-func yaml_emitter_write_indent(emitter *yaml_emitter_t) bool {
- indent := emitter.indent
- if indent < 0 {
- indent = 0
- }
- if !emitter.indention || emitter.column > indent || (emitter.column == indent && !emitter.whitespace) {
- if !put_break(emitter) {
- return false
- }
- }
- if emitter.foot_indent == indent {
- if !put_break(emitter) {
- return false
- }
- }
- for emitter.column < indent {
- if !put(emitter, ' ') {
- return false
- }
- }
- emitter.whitespace = true
- //emitter.indention = true
- emitter.space_above = false
- emitter.foot_indent = -1
- return true
-}
-
-func yaml_emitter_write_indicator(emitter *yaml_emitter_t, indicator []byte, need_whitespace, is_whitespace, is_indention bool) bool {
- if need_whitespace && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !write_all(emitter, indicator) {
- return false
- }
- emitter.whitespace = is_whitespace
- emitter.indention = (emitter.indention && is_indention)
- emitter.open_ended = false
- return true
-}
-
-func yaml_emitter_write_anchor(emitter *yaml_emitter_t, value []byte) bool {
- if !write_all(emitter, value) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_tag_handle(emitter *yaml_emitter_t, value []byte) bool {
- if !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- if !write_all(emitter, value) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_tag_content(emitter *yaml_emitter_t, value []byte, need_whitespace bool) bool {
- if need_whitespace && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
- for i := 0; i < len(value); {
- var must_write bool
- switch value[i] {
- case ';', '/', '?', ':', '@', '&', '=', '+', '$', ',', '_', '.', '~', '*', '\'', '(', ')', '[', ']':
- must_write = true
- default:
- must_write = is_alpha(value, i)
- }
- if must_write {
- if !write(emitter, value, &i) {
- return false
- }
- } else {
- w := width(value[i])
- for k := 0; k < w; k++ {
- octet := value[i]
- i++
- if !put(emitter, '%') {
- return false
- }
-
- c := octet >> 4
- if c < 10 {
- c += '0'
- } else {
- c += 'A' - 10
- }
- if !put(emitter, c) {
- return false
- }
-
- c = octet & 0x0f
- if c < 10 {
- c += '0'
- } else {
- c += 'A' - 10
- }
- if !put(emitter, c) {
- return false
- }
- }
- }
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_plain_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
- if len(value) > 0 && !emitter.whitespace {
- if !put(emitter, ' ') {
- return false
- }
- }
-
- spaces := false
- breaks := false
- for i := 0; i < len(value); {
- if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && !is_space(value, i+1) {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- spaces = true
- } else if is_break(value, i) {
- if !breaks && value[i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- spaces = false
- breaks = false
- }
- }
-
- if len(value) > 0 {
- emitter.whitespace = false
- }
- emitter.indention = false
- if emitter.root_context {
- emitter.open_ended = true
- }
-
- return true
-}
-
-func yaml_emitter_write_single_quoted_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
-
- if !yaml_emitter_write_indicator(emitter, []byte{'\''}, true, false, false) {
- return false
- }
-
- spaces := false
- breaks := false
- for i := 0; i < len(value); {
- if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && i > 0 && i < len(value)-1 && !is_space(value, i+1) {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- spaces = true
- } else if is_break(value, i) {
- if !breaks && value[i] == '\n' {
- if !put_break(emitter) {
- return false
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if value[i] == '\'' {
- if !put(emitter, '\'') {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- spaces = false
- breaks = false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'\''}, false, false, false) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_double_quoted_scalar(emitter *yaml_emitter_t, value []byte, allow_breaks bool) bool {
- spaces := false
- if !yaml_emitter_write_indicator(emitter, []byte{'"'}, true, false, false) {
- return false
- }
-
- for i := 0; i < len(value); {
- if !is_printable(value, i) || (!emitter.unicode && !is_ascii(value, i)) ||
- is_bom(value, i) || is_break(value, i) ||
- value[i] == '"' || value[i] == '\\' {
-
- octet := value[i]
-
- var w int
- var v rune
- switch {
- case octet&0x80 == 0x00:
- w, v = 1, rune(octet&0x7F)
- case octet&0xE0 == 0xC0:
- w, v = 2, rune(octet&0x1F)
- case octet&0xF0 == 0xE0:
- w, v = 3, rune(octet&0x0F)
- case octet&0xF8 == 0xF0:
- w, v = 4, rune(octet&0x07)
- }
- for k := 1; k < w; k++ {
- octet = value[i+k]
- v = (v << 6) + (rune(octet) & 0x3F)
- }
- i += w
-
- if !put(emitter, '\\') {
- return false
- }
-
- var ok bool
- switch v {
- case 0x00:
- ok = put(emitter, '0')
- case 0x07:
- ok = put(emitter, 'a')
- case 0x08:
- ok = put(emitter, 'b')
- case 0x09:
- ok = put(emitter, 't')
- case 0x0A:
- ok = put(emitter, 'n')
- case 0x0b:
- ok = put(emitter, 'v')
- case 0x0c:
- ok = put(emitter, 'f')
- case 0x0d:
- ok = put(emitter, 'r')
- case 0x1b:
- ok = put(emitter, 'e')
- case 0x22:
- ok = put(emitter, '"')
- case 0x5c:
- ok = put(emitter, '\\')
- case 0x85:
- ok = put(emitter, 'N')
- case 0xA0:
- ok = put(emitter, '_')
- case 0x2028:
- ok = put(emitter, 'L')
- case 0x2029:
- ok = put(emitter, 'P')
- default:
- if v <= 0xFF {
- ok = put(emitter, 'x')
- w = 2
- } else if v <= 0xFFFF {
- ok = put(emitter, 'u')
- w = 4
- } else {
- ok = put(emitter, 'U')
- w = 8
- }
- for k := (w - 1) * 4; ok && k >= 0; k -= 4 {
- digit := byte((v >> uint(k)) & 0x0F)
- if digit < 10 {
- ok = put(emitter, digit+'0')
- } else {
- ok = put(emitter, digit+'A'-10)
- }
- }
- }
- if !ok {
- return false
- }
- spaces = false
- } else if is_space(value, i) {
- if allow_breaks && !spaces && emitter.column > emitter.best_width && i > 0 && i < len(value)-1 {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- if is_space(value, i+1) {
- if !put(emitter, '\\') {
- return false
- }
- }
- i += width(value[i])
- } else if !write(emitter, value, &i) {
- return false
- }
- spaces = true
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- spaces = false
- }
- }
- if !yaml_emitter_write_indicator(emitter, []byte{'"'}, false, false, false) {
- return false
- }
- emitter.whitespace = false
- emitter.indention = false
- return true
-}
-
-func yaml_emitter_write_block_scalar_hints(emitter *yaml_emitter_t, value []byte) bool {
- if is_space(value, 0) || is_break(value, 0) {
- indent_hint := []byte{'0' + byte(emitter.best_indent)}
- if !yaml_emitter_write_indicator(emitter, indent_hint, false, false, false) {
- return false
- }
- }
-
- emitter.open_ended = false
-
- var chomp_hint [1]byte
- if len(value) == 0 {
- chomp_hint[0] = '-'
- } else {
- i := len(value) - 1
- for value[i]&0xC0 == 0x80 {
- i--
- }
- if !is_break(value, i) {
- chomp_hint[0] = '-'
- } else if i == 0 {
- chomp_hint[0] = '+'
- emitter.open_ended = true
- } else {
- i--
- for value[i]&0xC0 == 0x80 {
- i--
- }
- if is_break(value, i) {
- chomp_hint[0] = '+'
- emitter.open_ended = true
- }
- }
- }
- if chomp_hint[0] != 0 {
- if !yaml_emitter_write_indicator(emitter, chomp_hint[:], false, false, false) {
- return false
- }
- }
- return true
-}
-
-func yaml_emitter_write_literal_scalar(emitter *yaml_emitter_t, value []byte) bool {
- if !yaml_emitter_write_indicator(emitter, []byte{'|'}, true, false, false) {
- return false
- }
- if !yaml_emitter_write_block_scalar_hints(emitter, value) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
- //emitter.indention = true
- emitter.whitespace = true
- breaks := true
- for i := 0; i < len(value); {
- if is_break(value, i) {
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- }
- if !write(emitter, value, &i) {
- return false
- }
- emitter.indention = false
- breaks = false
- }
- }
-
- return true
-}
-
-func yaml_emitter_write_folded_scalar(emitter *yaml_emitter_t, value []byte) bool {
- if !yaml_emitter_write_indicator(emitter, []byte{'>'}, true, false, false) {
- return false
- }
- if !yaml_emitter_write_block_scalar_hints(emitter, value) {
- return false
- }
- if !yaml_emitter_process_line_comment(emitter) {
- return false
- }
-
- //emitter.indention = true
- emitter.whitespace = true
-
- breaks := true
- leading_spaces := true
- for i := 0; i < len(value); {
- if is_break(value, i) {
- if !breaks && !leading_spaces && value[i] == '\n' {
- k := 0
- for is_break(value, k) {
- k += width(value[k])
- }
- if !is_blankz(value, k) {
- if !put_break(emitter) {
- return false
- }
- }
- }
- if !write_break(emitter, value, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- } else {
- if breaks {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- leading_spaces = is_blank(value, i)
- }
- if !breaks && is_space(value, i) && !is_space(value, i+1) && emitter.column > emitter.best_width {
- if !yaml_emitter_write_indent(emitter) {
- return false
- }
- i += width(value[i])
- } else {
- if !write(emitter, value, &i) {
- return false
- }
- }
- emitter.indention = false
- breaks = false
- }
- }
- return true
-}
-
-func yaml_emitter_write_comment(emitter *yaml_emitter_t, comment []byte) bool {
- breaks := false
- pound := false
- for i := 0; i < len(comment); {
- if is_break(comment, i) {
- if !write_break(emitter, comment, &i) {
- return false
- }
- //emitter.indention = true
- breaks = true
- pound = false
- } else {
- if breaks && !yaml_emitter_write_indent(emitter) {
- return false
- }
- if !pound {
- if comment[i] != '#' && (!put(emitter, '#') || !put(emitter, ' ')) {
- return false
- }
- pound = true
- }
- if !write(emitter, comment, &i) {
- return false
- }
- emitter.indention = false
- breaks = false
- }
- }
- if !breaks && !put_break(emitter) {
- return false
- }
-
- emitter.whitespace = true
- //emitter.indention = true
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/encode.go b/sesh/vendor/gopkg.in/yaml.v3/encode.go
deleted file mode 100644
index de9e72a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/encode.go
+++ /dev/null
@@ -1,577 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding"
- "fmt"
- "io"
- "reflect"
- "regexp"
- "sort"
- "strconv"
- "strings"
- "time"
- "unicode/utf8"
-)
-
-type encoder struct {
- emitter yaml_emitter_t
- event yaml_event_t
- out []byte
- flow bool
- indent int
- doneInit bool
-}
-
-func newEncoder() *encoder {
- e := &encoder{}
- yaml_emitter_initialize(&e.emitter)
- yaml_emitter_set_output_string(&e.emitter, &e.out)
- yaml_emitter_set_unicode(&e.emitter, true)
- return e
-}
-
-func newEncoderWithWriter(w io.Writer) *encoder {
- e := &encoder{}
- yaml_emitter_initialize(&e.emitter)
- yaml_emitter_set_output_writer(&e.emitter, w)
- yaml_emitter_set_unicode(&e.emitter, true)
- return e
-}
-
-func (e *encoder) init() {
- if e.doneInit {
- return
- }
- if e.indent == 0 {
- e.indent = 4
- }
- e.emitter.best_indent = e.indent
- yaml_stream_start_event_initialize(&e.event, yaml_UTF8_ENCODING)
- e.emit()
- e.doneInit = true
-}
-
-func (e *encoder) finish() {
- e.emitter.open_ended = false
- yaml_stream_end_event_initialize(&e.event)
- e.emit()
-}
-
-func (e *encoder) destroy() {
- yaml_emitter_delete(&e.emitter)
-}
-
-func (e *encoder) emit() {
- // This will internally delete the e.event value.
- e.must(yaml_emitter_emit(&e.emitter, &e.event))
-}
-
-func (e *encoder) must(ok bool) {
- if !ok {
- msg := e.emitter.problem
- if msg == "" {
- msg = "unknown problem generating YAML content"
- }
- failf("%s", msg)
- }
-}
-
-func (e *encoder) marshalDoc(tag string, in reflect.Value) {
- e.init()
- var node *Node
- if in.IsValid() {
- node, _ = in.Interface().(*Node)
- }
- if node != nil && node.Kind == DocumentNode {
- e.nodev(in)
- } else {
- yaml_document_start_event_initialize(&e.event, nil, nil, true)
- e.emit()
- e.marshal(tag, in)
- yaml_document_end_event_initialize(&e.event, true)
- e.emit()
- }
-}
-
-func (e *encoder) marshal(tag string, in reflect.Value) {
- tag = shortTag(tag)
- if !in.IsValid() || in.Kind() == reflect.Ptr && in.IsNil() {
- e.nilv()
- return
- }
- iface := in.Interface()
- switch value := iface.(type) {
- case *Node:
- e.nodev(in)
- return
- case Node:
- if !in.CanAddr() {
- var n = reflect.New(in.Type()).Elem()
- n.Set(in)
- in = n
- }
- e.nodev(in.Addr())
- return
- case time.Time:
- e.timev(tag, in)
- return
- case *time.Time:
- e.timev(tag, in.Elem())
- return
- case time.Duration:
- e.stringv(tag, reflect.ValueOf(value.String()))
- return
- case Marshaler:
- v, err := value.MarshalYAML()
- if err != nil {
- fail(err)
- }
- if v == nil {
- e.nilv()
- return
- }
- e.marshal(tag, reflect.ValueOf(v))
- return
- case encoding.TextMarshaler:
- text, err := value.MarshalText()
- if err != nil {
- fail(err)
- }
- in = reflect.ValueOf(string(text))
- case nil:
- e.nilv()
- return
- }
- switch in.Kind() {
- case reflect.Interface:
- e.marshal(tag, in.Elem())
- case reflect.Map:
- e.mapv(tag, in)
- case reflect.Ptr:
- e.marshal(tag, in.Elem())
- case reflect.Struct:
- e.structv(tag, in)
- case reflect.Slice, reflect.Array:
- e.slicev(tag, in)
- case reflect.String:
- e.stringv(tag, in)
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- e.intv(tag, in)
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- e.uintv(tag, in)
- case reflect.Float32, reflect.Float64:
- e.floatv(tag, in)
- case reflect.Bool:
- e.boolv(tag, in)
- default:
- panic("cannot marshal type: " + in.Type().String())
- }
-}
-
-func (e *encoder) mapv(tag string, in reflect.Value) {
- e.mappingv(tag, func() {
- keys := keyList(in.MapKeys())
- sort.Sort(keys)
- for _, k := range keys {
- e.marshal("", k)
- e.marshal("", in.MapIndex(k))
- }
- })
-}
-
-func (e *encoder) fieldByIndex(v reflect.Value, index []int) (field reflect.Value) {
- for _, num := range index {
- for {
- if v.Kind() == reflect.Ptr {
- if v.IsNil() {
- return reflect.Value{}
- }
- v = v.Elem()
- continue
- }
- break
- }
- v = v.Field(num)
- }
- return v
-}
-
-func (e *encoder) structv(tag string, in reflect.Value) {
- sinfo, err := getStructInfo(in.Type())
- if err != nil {
- panic(err)
- }
- e.mappingv(tag, func() {
- for _, info := range sinfo.FieldsList {
- var value reflect.Value
- if info.Inline == nil {
- value = in.Field(info.Num)
- } else {
- value = e.fieldByIndex(in, info.Inline)
- if !value.IsValid() {
- continue
- }
- }
- if info.OmitEmpty && isZero(value) {
- continue
- }
- e.marshal("", reflect.ValueOf(info.Key))
- e.flow = info.Flow
- e.marshal("", value)
- }
- if sinfo.InlineMap >= 0 {
- m := in.Field(sinfo.InlineMap)
- if m.Len() > 0 {
- e.flow = false
- keys := keyList(m.MapKeys())
- sort.Sort(keys)
- for _, k := range keys {
- if _, found := sinfo.FieldsMap[k.String()]; found {
- panic(fmt.Sprintf("cannot have key %q in inlined map: conflicts with struct field", k.String()))
- }
- e.marshal("", k)
- e.flow = false
- e.marshal("", m.MapIndex(k))
- }
- }
- }
- })
-}
-
-func (e *encoder) mappingv(tag string, f func()) {
- implicit := tag == ""
- style := yaml_BLOCK_MAPPING_STYLE
- if e.flow {
- e.flow = false
- style = yaml_FLOW_MAPPING_STYLE
- }
- yaml_mapping_start_event_initialize(&e.event, nil, []byte(tag), implicit, style)
- e.emit()
- f()
- yaml_mapping_end_event_initialize(&e.event)
- e.emit()
-}
-
-func (e *encoder) slicev(tag string, in reflect.Value) {
- implicit := tag == ""
- style := yaml_BLOCK_SEQUENCE_STYLE
- if e.flow {
- e.flow = false
- style = yaml_FLOW_SEQUENCE_STYLE
- }
- e.must(yaml_sequence_start_event_initialize(&e.event, nil, []byte(tag), implicit, style))
- e.emit()
- n := in.Len()
- for i := 0; i < n; i++ {
- e.marshal("", in.Index(i))
- }
- e.must(yaml_sequence_end_event_initialize(&e.event))
- e.emit()
-}
-
-// isBase60 returns whether s is in base 60 notation as defined in YAML 1.1.
-//
-// The base 60 float notation in YAML 1.1 is a terrible idea and is unsupported
-// in YAML 1.2 and by this package, but these should be marshalled quoted for
-// the time being for compatibility with other parsers.
-func isBase60Float(s string) (result bool) {
- // Fast path.
- if s == "" {
- return false
- }
- c := s[0]
- if !(c == '+' || c == '-' || c >= '0' && c <= '9') || strings.IndexByte(s, ':') < 0 {
- return false
- }
- // Do the full match.
- return base60float.MatchString(s)
-}
-
-// From http://yaml.org/type/float.html, except the regular expression there
-// is bogus. In practice parsers do not enforce the "\.[0-9_]*" suffix.
-var base60float = regexp.MustCompile(`^[-+]?[0-9][0-9_]*(?::[0-5]?[0-9])+(?:\.[0-9_]*)?$`)
-
-// isOldBool returns whether s is bool notation as defined in YAML 1.1.
-//
-// We continue to force strings that YAML 1.1 would interpret as booleans to be
-// rendered as quotes strings so that the marshalled output valid for YAML 1.1
-// parsing.
-func isOldBool(s string) (result bool) {
- switch s {
- case "y", "Y", "yes", "Yes", "YES", "on", "On", "ON",
- "n", "N", "no", "No", "NO", "off", "Off", "OFF":
- return true
- default:
- return false
- }
-}
-
-func (e *encoder) stringv(tag string, in reflect.Value) {
- var style yaml_scalar_style_t
- s := in.String()
- canUsePlain := true
- switch {
- case !utf8.ValidString(s):
- if tag == binaryTag {
- failf("explicitly tagged !!binary data must be base64-encoded")
- }
- if tag != "" {
- failf("cannot marshal invalid UTF-8 data as %s", shortTag(tag))
- }
- // It can't be encoded directly as YAML so use a binary tag
- // and encode it as base64.
- tag = binaryTag
- s = encodeBase64(s)
- case tag == "":
- // Check to see if it would resolve to a specific
- // tag when encoded unquoted. If it doesn't,
- // there's no need to quote it.
- rtag, _ := resolve("", s)
- canUsePlain = rtag == strTag && !(isBase60Float(s) || isOldBool(s))
- }
- // Note: it's possible for user code to emit invalid YAML
- // if they explicitly specify a tag and a string containing
- // text that's incompatible with that tag.
- switch {
- case strings.Contains(s, "\n"):
- if e.flow {
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- } else {
- style = yaml_LITERAL_SCALAR_STYLE
- }
- case canUsePlain:
- style = yaml_PLAIN_SCALAR_STYLE
- default:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- e.emitScalar(s, "", tag, style, nil, nil, nil, nil)
-}
-
-func (e *encoder) boolv(tag string, in reflect.Value) {
- var s string
- if in.Bool() {
- s = "true"
- } else {
- s = "false"
- }
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) intv(tag string, in reflect.Value) {
- s := strconv.FormatInt(in.Int(), 10)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) uintv(tag string, in reflect.Value) {
- s := strconv.FormatUint(in.Uint(), 10)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) timev(tag string, in reflect.Value) {
- t := in.Interface().(time.Time)
- s := t.Format(time.RFC3339Nano)
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) floatv(tag string, in reflect.Value) {
- // Issue #352: When formatting, use the precision of the underlying value
- precision := 64
- if in.Kind() == reflect.Float32 {
- precision = 32
- }
-
- s := strconv.FormatFloat(in.Float(), 'g', -1, precision)
- switch s {
- case "+Inf":
- s = ".inf"
- case "-Inf":
- s = "-.inf"
- case "NaN":
- s = ".nan"
- }
- e.emitScalar(s, "", tag, yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) nilv() {
- e.emitScalar("null", "", "", yaml_PLAIN_SCALAR_STYLE, nil, nil, nil, nil)
-}
-
-func (e *encoder) emitScalar(value, anchor, tag string, style yaml_scalar_style_t, head, line, foot, tail []byte) {
- // TODO Kill this function. Replace all initialize calls by their underlining Go literals.
- implicit := tag == ""
- if !implicit {
- tag = longTag(tag)
- }
- e.must(yaml_scalar_event_initialize(&e.event, []byte(anchor), []byte(tag), []byte(value), implicit, implicit, style))
- e.event.head_comment = head
- e.event.line_comment = line
- e.event.foot_comment = foot
- e.event.tail_comment = tail
- e.emit()
-}
-
-func (e *encoder) nodev(in reflect.Value) {
- e.node(in.Interface().(*Node), "")
-}
-
-func (e *encoder) node(node *Node, tail string) {
- // Zero nodes behave as nil.
- if node.Kind == 0 && node.IsZero() {
- e.nilv()
- return
- }
-
- // If the tag was not explicitly requested, and dropping it won't change the
- // implicit tag of the value, don't include it in the presentation.
- var tag = node.Tag
- var stag = shortTag(tag)
- var forceQuoting bool
- if tag != "" && node.Style&TaggedStyle == 0 {
- if node.Kind == ScalarNode {
- if stag == strTag && node.Style&(SingleQuotedStyle|DoubleQuotedStyle|LiteralStyle|FoldedStyle) != 0 {
- tag = ""
- } else {
- rtag, _ := resolve("", node.Value)
- if rtag == stag {
- tag = ""
- } else if stag == strTag {
- tag = ""
- forceQuoting = true
- }
- }
- } else {
- var rtag string
- switch node.Kind {
- case MappingNode:
- rtag = mapTag
- case SequenceNode:
- rtag = seqTag
- }
- if rtag == stag {
- tag = ""
- }
- }
- }
-
- switch node.Kind {
- case DocumentNode:
- yaml_document_start_event_initialize(&e.event, nil, nil, true)
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
- for _, node := range node.Content {
- e.node(node, "")
- }
- yaml_document_end_event_initialize(&e.event, true)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case SequenceNode:
- style := yaml_BLOCK_SEQUENCE_STYLE
- if node.Style&FlowStyle != 0 {
- style = yaml_FLOW_SEQUENCE_STYLE
- }
- e.must(yaml_sequence_start_event_initialize(&e.event, []byte(node.Anchor), []byte(longTag(tag)), tag == "", style))
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
- for _, node := range node.Content {
- e.node(node, "")
- }
- e.must(yaml_sequence_end_event_initialize(&e.event))
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case MappingNode:
- style := yaml_BLOCK_MAPPING_STYLE
- if node.Style&FlowStyle != 0 {
- style = yaml_FLOW_MAPPING_STYLE
- }
- yaml_mapping_start_event_initialize(&e.event, []byte(node.Anchor), []byte(longTag(tag)), tag == "", style)
- e.event.tail_comment = []byte(tail)
- e.event.head_comment = []byte(node.HeadComment)
- e.emit()
-
- // The tail logic below moves the foot comment of prior keys to the following key,
- // since the value for each key may be a nested structure and the foot needs to be
- // processed only the entirety of the value is streamed. The last tail is processed
- // with the mapping end event.
- var tail string
- for i := 0; i+1 < len(node.Content); i += 2 {
- k := node.Content[i]
- foot := k.FootComment
- if foot != "" {
- kopy := *k
- kopy.FootComment = ""
- k = &kopy
- }
- e.node(k, tail)
- tail = foot
-
- v := node.Content[i+1]
- e.node(v, "")
- }
-
- yaml_mapping_end_event_initialize(&e.event)
- e.event.tail_comment = []byte(tail)
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case AliasNode:
- yaml_alias_event_initialize(&e.event, []byte(node.Value))
- e.event.head_comment = []byte(node.HeadComment)
- e.event.line_comment = []byte(node.LineComment)
- e.event.foot_comment = []byte(node.FootComment)
- e.emit()
-
- case ScalarNode:
- value := node.Value
- if !utf8.ValidString(value) {
- if stag == binaryTag {
- failf("explicitly tagged !!binary data must be base64-encoded")
- }
- if stag != "" {
- failf("cannot marshal invalid UTF-8 data as %s", stag)
- }
- // It can't be encoded directly as YAML so use a binary tag
- // and encode it as base64.
- tag = binaryTag
- value = encodeBase64(value)
- }
-
- style := yaml_PLAIN_SCALAR_STYLE
- switch {
- case node.Style&DoubleQuotedStyle != 0:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- case node.Style&SingleQuotedStyle != 0:
- style = yaml_SINGLE_QUOTED_SCALAR_STYLE
- case node.Style&LiteralStyle != 0:
- style = yaml_LITERAL_SCALAR_STYLE
- case node.Style&FoldedStyle != 0:
- style = yaml_FOLDED_SCALAR_STYLE
- case strings.Contains(value, "\n"):
- style = yaml_LITERAL_SCALAR_STYLE
- case forceQuoting:
- style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
-
- e.emitScalar(value, node.Anchor, tag, style, []byte(node.HeadComment), []byte(node.LineComment), []byte(node.FootComment), []byte(tail))
- default:
- failf("cannot encode node with unknown kind %d", node.Kind)
- }
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/parserc.go b/sesh/vendor/gopkg.in/yaml.v3/parserc.go
deleted file mode 100644
index 268558a..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/parserc.go
+++ /dev/null
@@ -1,1258 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
-)
-
-// The parser implements the following grammar:
-//
-// stream ::= STREAM-START implicit_document? explicit_document* STREAM-END
-// implicit_document ::= block_node DOCUMENT-END*
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// block_node_or_indentless_sequence ::=
-// ALIAS
-// | properties (block_content | indentless_block_sequence)?
-// | block_content
-// | indentless_block_sequence
-// block_node ::= ALIAS
-// | properties block_content?
-// | block_content
-// flow_node ::= ALIAS
-// | properties flow_content?
-// | flow_content
-// properties ::= TAG ANCHOR? | ANCHOR TAG?
-// block_content ::= block_collection | flow_collection | SCALAR
-// flow_content ::= flow_collection | SCALAR
-// block_collection ::= block_sequence | block_mapping
-// flow_collection ::= flow_sequence | flow_mapping
-// block_sequence ::= BLOCK-SEQUENCE-START (BLOCK-ENTRY block_node?)* BLOCK-END
-// indentless_sequence ::= (BLOCK-ENTRY block_node?)+
-// block_mapping ::= BLOCK-MAPPING_START
-// ((KEY block_node_or_indentless_sequence?)?
-// (VALUE block_node_or_indentless_sequence?)?)*
-// BLOCK-END
-// flow_sequence ::= FLOW-SEQUENCE-START
-// (flow_sequence_entry FLOW-ENTRY)*
-// flow_sequence_entry?
-// FLOW-SEQUENCE-END
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// flow_mapping ::= FLOW-MAPPING-START
-// (flow_mapping_entry FLOW-ENTRY)*
-// flow_mapping_entry?
-// FLOW-MAPPING-END
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-
-// Peek the next token in the token queue.
-func peek_token(parser *yaml_parser_t) *yaml_token_t {
- if parser.token_available || yaml_parser_fetch_more_tokens(parser) {
- token := &parser.tokens[parser.tokens_head]
- yaml_parser_unfold_comments(parser, token)
- return token
- }
- return nil
-}
-
-// yaml_parser_unfold_comments walks through the comments queue and joins all
-// comments behind the position of the provided token into the respective
-// top-level comment slices in the parser.
-func yaml_parser_unfold_comments(parser *yaml_parser_t, token *yaml_token_t) {
- for parser.comments_head < len(parser.comments) && token.start_mark.index >= parser.comments[parser.comments_head].token_mark.index {
- comment := &parser.comments[parser.comments_head]
- if len(comment.head) > 0 {
- if token.typ == yaml_BLOCK_END_TOKEN {
- // No heads on ends, so keep comment.head for a follow up token.
- break
- }
- if len(parser.head_comment) > 0 {
- parser.head_comment = append(parser.head_comment, '\n')
- }
- parser.head_comment = append(parser.head_comment, comment.head...)
- }
- if len(comment.foot) > 0 {
- if len(parser.foot_comment) > 0 {
- parser.foot_comment = append(parser.foot_comment, '\n')
- }
- parser.foot_comment = append(parser.foot_comment, comment.foot...)
- }
- if len(comment.line) > 0 {
- if len(parser.line_comment) > 0 {
- parser.line_comment = append(parser.line_comment, '\n')
- }
- parser.line_comment = append(parser.line_comment, comment.line...)
- }
- *comment = yaml_comment_t{}
- parser.comments_head++
- }
-}
-
-// Remove the next token from the queue (must be called after peek_token).
-func skip_token(parser *yaml_parser_t) {
- parser.token_available = false
- parser.tokens_parsed++
- parser.stream_end_produced = parser.tokens[parser.tokens_head].typ == yaml_STREAM_END_TOKEN
- parser.tokens_head++
-}
-
-// Get the next event.
-func yaml_parser_parse(parser *yaml_parser_t, event *yaml_event_t) bool {
- // Erase the event object.
- *event = yaml_event_t{}
-
- // No events after the end of the stream or error.
- if parser.stream_end_produced || parser.error != yaml_NO_ERROR || parser.state == yaml_PARSE_END_STATE {
- return true
- }
-
- // Generate the next event.
- return yaml_parser_state_machine(parser, event)
-}
-
-// Set parser error.
-func yaml_parser_set_parser_error(parser *yaml_parser_t, problem string, problem_mark yaml_mark_t) bool {
- parser.error = yaml_PARSER_ERROR
- parser.problem = problem
- parser.problem_mark = problem_mark
- return false
-}
-
-func yaml_parser_set_parser_error_context(parser *yaml_parser_t, context string, context_mark yaml_mark_t, problem string, problem_mark yaml_mark_t) bool {
- parser.error = yaml_PARSER_ERROR
- parser.context = context
- parser.context_mark = context_mark
- parser.problem = problem
- parser.problem_mark = problem_mark
- return false
-}
-
-// State dispatcher.
-func yaml_parser_state_machine(parser *yaml_parser_t, event *yaml_event_t) bool {
- //trace("yaml_parser_state_machine", "state:", parser.state.String())
-
- switch parser.state {
- case yaml_PARSE_STREAM_START_STATE:
- return yaml_parser_parse_stream_start(parser, event)
-
- case yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE:
- return yaml_parser_parse_document_start(parser, event, true)
-
- case yaml_PARSE_DOCUMENT_START_STATE:
- return yaml_parser_parse_document_start(parser, event, false)
-
- case yaml_PARSE_DOCUMENT_CONTENT_STATE:
- return yaml_parser_parse_document_content(parser, event)
-
- case yaml_PARSE_DOCUMENT_END_STATE:
- return yaml_parser_parse_document_end(parser, event)
-
- case yaml_PARSE_BLOCK_NODE_STATE:
- return yaml_parser_parse_node(parser, event, true, false)
-
- case yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE:
- return yaml_parser_parse_node(parser, event, true, true)
-
- case yaml_PARSE_FLOW_NODE_STATE:
- return yaml_parser_parse_node(parser, event, false, false)
-
- case yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE:
- return yaml_parser_parse_block_sequence_entry(parser, event, true)
-
- case yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_block_sequence_entry(parser, event, false)
-
- case yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_indentless_sequence_entry(parser, event)
-
- case yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE:
- return yaml_parser_parse_block_mapping_key(parser, event, true)
-
- case yaml_PARSE_BLOCK_MAPPING_KEY_STATE:
- return yaml_parser_parse_block_mapping_key(parser, event, false)
-
- case yaml_PARSE_BLOCK_MAPPING_VALUE_STATE:
- return yaml_parser_parse_block_mapping_value(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE:
- return yaml_parser_parse_flow_sequence_entry(parser, event, true)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE:
- return yaml_parser_parse_flow_sequence_entry(parser, event, false)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_key(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_value(parser, event)
-
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE:
- return yaml_parser_parse_flow_sequence_entry_mapping_end(parser, event)
-
- case yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE:
- return yaml_parser_parse_flow_mapping_key(parser, event, true)
-
- case yaml_PARSE_FLOW_MAPPING_KEY_STATE:
- return yaml_parser_parse_flow_mapping_key(parser, event, false)
-
- case yaml_PARSE_FLOW_MAPPING_VALUE_STATE:
- return yaml_parser_parse_flow_mapping_value(parser, event, false)
-
- case yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE:
- return yaml_parser_parse_flow_mapping_value(parser, event, true)
-
- default:
- panic("invalid parser state")
- }
-}
-
-// Parse the production:
-// stream ::= STREAM-START implicit_document? explicit_document* STREAM-END
-// ************
-func yaml_parser_parse_stream_start(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_STREAM_START_TOKEN {
- return yaml_parser_set_parser_error(parser, "did not find expected ", token.start_mark)
- }
- parser.state = yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE
- *event = yaml_event_t{
- typ: yaml_STREAM_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- encoding: token.encoding,
- }
- skip_token(parser)
- return true
-}
-
-// Parse the productions:
-// implicit_document ::= block_node DOCUMENT-END*
-// *
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// *************************
-func yaml_parser_parse_document_start(parser *yaml_parser_t, event *yaml_event_t, implicit bool) bool {
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- // Parse extra document end indicators.
- if !implicit {
- for token.typ == yaml_DOCUMENT_END_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- }
-
- if implicit && token.typ != yaml_VERSION_DIRECTIVE_TOKEN &&
- token.typ != yaml_TAG_DIRECTIVE_TOKEN &&
- token.typ != yaml_DOCUMENT_START_TOKEN &&
- token.typ != yaml_STREAM_END_TOKEN {
- // Parse an implicit document.
- if !yaml_parser_process_directives(parser, nil, nil) {
- return false
- }
- parser.states = append(parser.states, yaml_PARSE_DOCUMENT_END_STATE)
- parser.state = yaml_PARSE_BLOCK_NODE_STATE
-
- var head_comment []byte
- if len(parser.head_comment) > 0 {
- // [Go] Scan the header comment backwards, and if an empty line is found, break
- // the header so the part before the last empty line goes into the
- // document header, while the bottom of it goes into a follow up event.
- for i := len(parser.head_comment) - 1; i > 0; i-- {
- if parser.head_comment[i] == '\n' {
- if i == len(parser.head_comment)-1 {
- head_comment = parser.head_comment[:i]
- parser.head_comment = parser.head_comment[i+1:]
- break
- } else if parser.head_comment[i-1] == '\n' {
- head_comment = parser.head_comment[:i-1]
- parser.head_comment = parser.head_comment[i+1:]
- break
- }
- }
- }
- }
-
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
-
- head_comment: head_comment,
- }
-
- } else if token.typ != yaml_STREAM_END_TOKEN {
- // Parse an explicit document.
- var version_directive *yaml_version_directive_t
- var tag_directives []yaml_tag_directive_t
- start_mark := token.start_mark
- if !yaml_parser_process_directives(parser, &version_directive, &tag_directives) {
- return false
- }
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_DOCUMENT_START_TOKEN {
- yaml_parser_set_parser_error(parser,
- "did not find expected ", token.start_mark)
- return false
- }
- parser.states = append(parser.states, yaml_PARSE_DOCUMENT_END_STATE)
- parser.state = yaml_PARSE_DOCUMENT_CONTENT_STATE
- end_mark := token.end_mark
-
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- version_directive: version_directive,
- tag_directives: tag_directives,
- implicit: false,
- }
- skip_token(parser)
-
- } else {
- // Parse the stream end.
- parser.state = yaml_PARSE_END_STATE
- *event = yaml_event_t{
- typ: yaml_STREAM_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- skip_token(parser)
- }
-
- return true
-}
-
-// Parse the productions:
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-// ***********
-//
-func yaml_parser_parse_document_content(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_VERSION_DIRECTIVE_TOKEN ||
- token.typ == yaml_TAG_DIRECTIVE_TOKEN ||
- token.typ == yaml_DOCUMENT_START_TOKEN ||
- token.typ == yaml_DOCUMENT_END_TOKEN ||
- token.typ == yaml_STREAM_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- return yaml_parser_process_empty_scalar(parser, event,
- token.start_mark)
- }
- return yaml_parser_parse_node(parser, event, true, false)
-}
-
-// Parse the productions:
-// implicit_document ::= block_node DOCUMENT-END*
-// *************
-// explicit_document ::= DIRECTIVE* DOCUMENT-START block_node? DOCUMENT-END*
-//
-func yaml_parser_parse_document_end(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- start_mark := token.start_mark
- end_mark := token.start_mark
-
- implicit := true
- if token.typ == yaml_DOCUMENT_END_TOKEN {
- end_mark = token.end_mark
- skip_token(parser)
- implicit = false
- }
-
- parser.tag_directives = parser.tag_directives[:0]
-
- parser.state = yaml_PARSE_DOCUMENT_START_STATE
- *event = yaml_event_t{
- typ: yaml_DOCUMENT_END_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- implicit: implicit,
- }
- yaml_parser_set_event_comments(parser, event)
- if len(event.head_comment) > 0 && len(event.foot_comment) == 0 {
- event.foot_comment = event.head_comment
- event.head_comment = nil
- }
- return true
-}
-
-func yaml_parser_set_event_comments(parser *yaml_parser_t, event *yaml_event_t) {
- event.head_comment = parser.head_comment
- event.line_comment = parser.line_comment
- event.foot_comment = parser.foot_comment
- parser.head_comment = nil
- parser.line_comment = nil
- parser.foot_comment = nil
- parser.tail_comment = nil
- parser.stem_comment = nil
-}
-
-// Parse the productions:
-// block_node_or_indentless_sequence ::=
-// ALIAS
-// *****
-// | properties (block_content | indentless_block_sequence)?
-// ********** *
-// | block_content | indentless_block_sequence
-// *
-// block_node ::= ALIAS
-// *****
-// | properties block_content?
-// ********** *
-// | block_content
-// *
-// flow_node ::= ALIAS
-// *****
-// | properties flow_content?
-// ********** *
-// | flow_content
-// *
-// properties ::= TAG ANCHOR? | ANCHOR TAG?
-// *************************
-// block_content ::= block_collection | flow_collection | SCALAR
-// ******
-// flow_content ::= flow_collection | SCALAR
-// ******
-func yaml_parser_parse_node(parser *yaml_parser_t, event *yaml_event_t, block, indentless_sequence bool) bool {
- //defer trace("yaml_parser_parse_node", "block:", block, "indentless_sequence:", indentless_sequence)()
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_ALIAS_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- *event = yaml_event_t{
- typ: yaml_ALIAS_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- anchor: token.value,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
-
- start_mark := token.start_mark
- end_mark := token.start_mark
-
- var tag_token bool
- var tag_handle, tag_suffix, anchor []byte
- var tag_mark yaml_mark_t
- if token.typ == yaml_ANCHOR_TOKEN {
- anchor = token.value
- start_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_TAG_TOKEN {
- tag_token = true
- tag_handle = token.value
- tag_suffix = token.suffix
- tag_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- } else if token.typ == yaml_TAG_TOKEN {
- tag_token = true
- tag_handle = token.value
- tag_suffix = token.suffix
- start_mark = token.start_mark
- tag_mark = token.start_mark
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_ANCHOR_TOKEN {
- anchor = token.value
- end_mark = token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
- }
-
- var tag []byte
- if tag_token {
- if len(tag_handle) == 0 {
- tag = tag_suffix
- tag_suffix = nil
- } else {
- for i := range parser.tag_directives {
- if bytes.Equal(parser.tag_directives[i].handle, tag_handle) {
- tag = append([]byte(nil), parser.tag_directives[i].prefix...)
- tag = append(tag, tag_suffix...)
- break
- }
- }
- if len(tag) == 0 {
- yaml_parser_set_parser_error_context(parser,
- "while parsing a node", start_mark,
- "found undefined tag handle", tag_mark)
- return false
- }
- }
- }
-
- implicit := len(tag) == 0
- if indentless_sequence && token.typ == yaml_BLOCK_ENTRY_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_SEQUENCE_STYLE),
- }
- return true
- }
- if token.typ == yaml_SCALAR_TOKEN {
- var plain_implicit, quoted_implicit bool
- end_mark = token.end_mark
- if (len(tag) == 0 && token.style == yaml_PLAIN_SCALAR_STYLE) || (len(tag) == 1 && tag[0] == '!') {
- plain_implicit = true
- } else if len(tag) == 0 {
- quoted_implicit = true
- }
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- value: token.value,
- implicit: plain_implicit,
- quoted_implicit: quoted_implicit,
- style: yaml_style_t(token.style),
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
- if token.typ == yaml_FLOW_SEQUENCE_START_TOKEN {
- // [Go] Some of the events below can be merged as they differ only on style.
- end_mark = token.end_mark
- parser.state = yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_FLOW_SEQUENCE_STYLE),
- }
- yaml_parser_set_event_comments(parser, event)
- return true
- }
- if token.typ == yaml_FLOW_MAPPING_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_FLOW_MAPPING_STYLE),
- }
- yaml_parser_set_event_comments(parser, event)
- return true
- }
- if block && token.typ == yaml_BLOCK_SEQUENCE_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_SEQUENCE_STYLE),
- }
- if parser.stem_comment != nil {
- event.head_comment = parser.stem_comment
- parser.stem_comment = nil
- }
- return true
- }
- if block && token.typ == yaml_BLOCK_MAPPING_START_TOKEN {
- end_mark = token.end_mark
- parser.state = yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- style: yaml_style_t(yaml_BLOCK_MAPPING_STYLE),
- }
- if parser.stem_comment != nil {
- event.head_comment = parser.stem_comment
- parser.stem_comment = nil
- }
- return true
- }
- if len(anchor) > 0 || len(tag) > 0 {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: start_mark,
- end_mark: end_mark,
- anchor: anchor,
- tag: tag,
- implicit: implicit,
- quoted_implicit: false,
- style: yaml_style_t(yaml_PLAIN_SCALAR_STYLE),
- }
- return true
- }
-
- context := "while parsing a flow node"
- if block {
- context = "while parsing a block node"
- }
- yaml_parser_set_parser_error_context(parser, context, start_mark,
- "did not find expected node content", token.start_mark)
- return false
-}
-
-// Parse the productions:
-// block_sequence ::= BLOCK-SEQUENCE-START (BLOCK-ENTRY block_node?)* BLOCK-END
-// ******************** *********** * *********
-//
-func yaml_parser_parse_block_sequence_entry(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_BLOCK_ENTRY_TOKEN {
- mark := token.end_mark
- prior_head_len := len(parser.head_comment)
- skip_token(parser)
- yaml_parser_split_stem_comment(parser, prior_head_len)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_BLOCK_ENTRY_TOKEN && token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, true, false)
- } else {
- parser.state = yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- }
- if token.typ == yaml_BLOCK_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
-
- skip_token(parser)
- return true
- }
-
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a block collection", context_mark,
- "did not find expected '-' indicator", token.start_mark)
-}
-
-// Parse the productions:
-// indentless_sequence ::= (BLOCK-ENTRY block_node?)+
-// *********** *
-func yaml_parser_parse_indentless_sequence_entry(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ == yaml_BLOCK_ENTRY_TOKEN {
- mark := token.end_mark
- prior_head_len := len(parser.head_comment)
- skip_token(parser)
- yaml_parser_split_stem_comment(parser, prior_head_len)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_BLOCK_ENTRY_TOKEN &&
- token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, true, false)
- }
- parser.state = yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.start_mark, // [Go] Shouldn't this be token.end_mark?
- }
- return true
-}
-
-// Split stem comment from head comment.
-//
-// When a sequence or map is found under a sequence entry, the former head comment
-// is assigned to the underlying sequence or map as a whole, not the individual
-// sequence or map entry as would be expected otherwise. To handle this case the
-// previous head comment is moved aside as the stem comment.
-func yaml_parser_split_stem_comment(parser *yaml_parser_t, stem_len int) {
- if stem_len == 0 {
- return
- }
-
- token := peek_token(parser)
- if token == nil || token.typ != yaml_BLOCK_SEQUENCE_START_TOKEN && token.typ != yaml_BLOCK_MAPPING_START_TOKEN {
- return
- }
-
- parser.stem_comment = parser.head_comment[:stem_len]
- if len(parser.head_comment) == stem_len {
- parser.head_comment = nil
- } else {
- // Copy suffix to prevent very strange bugs if someone ever appends
- // further bytes to the prefix in the stem_comment slice above.
- parser.head_comment = append([]byte(nil), parser.head_comment[stem_len+1:]...)
- }
-}
-
-// Parse the productions:
-// block_mapping ::= BLOCK-MAPPING_START
-// *******************
-// ((KEY block_node_or_indentless_sequence?)?
-// *** *
-// (VALUE block_node_or_indentless_sequence?)?)*
-//
-// BLOCK-END
-// *********
-//
-func yaml_parser_parse_block_mapping_key(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- // [Go] A tail comment was left from the prior mapping value processed. Emit an event
- // as it needs to be processed with that value and not the following key.
- if len(parser.tail_comment) > 0 {
- *event = yaml_event_t{
- typ: yaml_TAIL_COMMENT_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- foot_comment: parser.tail_comment,
- }
- parser.tail_comment = nil
- return true
- }
-
- if token.typ == yaml_KEY_TOKEN {
- mark := token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, true, true)
- } else {
- parser.state = yaml_PARSE_BLOCK_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- } else if token.typ == yaml_BLOCK_END_TOKEN {
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
- }
-
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a block mapping", context_mark,
- "did not find expected key", token.start_mark)
-}
-
-// Parse the productions:
-// block_mapping ::= BLOCK-MAPPING_START
-//
-// ((KEY block_node_or_indentless_sequence?)?
-//
-// (VALUE block_node_or_indentless_sequence?)?)*
-// ***** *
-// BLOCK-END
-//
-//
-func yaml_parser_parse_block_mapping_value(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_VALUE_TOKEN {
- mark := token.end_mark
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_KEY_TOKEN &&
- token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_BLOCK_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_BLOCK_MAPPING_KEY_STATE)
- return yaml_parser_parse_node(parser, event, true, true)
- }
- parser.state = yaml_PARSE_BLOCK_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
- }
- parser.state = yaml_PARSE_BLOCK_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Parse the productions:
-// flow_sequence ::= FLOW-SEQUENCE-START
-// *******************
-// (flow_sequence_entry FLOW-ENTRY)*
-// * **********
-// flow_sequence_entry?
-// *
-// FLOW-SEQUENCE-END
-// *****************
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *
-//
-func yaml_parser_parse_flow_sequence_entry(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- if !first {
- if token.typ == yaml_FLOW_ENTRY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- } else {
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a flow sequence", context_mark,
- "did not find expected ',' or ']'", token.start_mark)
- }
- }
-
- if token.typ == yaml_KEY_TOKEN {
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_START_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- implicit: true,
- style: yaml_style_t(yaml_FLOW_MAPPING_STYLE),
- }
- skip_token(parser)
- return true
- } else if token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
-
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
-
- *event = yaml_event_t{
- typ: yaml_SEQUENCE_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
-
- skip_token(parser)
- return true
-}
-
-//
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *** *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_key(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_FLOW_ENTRY_TOKEN &&
- token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- mark := token.end_mark
- skip_token(parser)
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, mark)
-}
-
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// ***** *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_value(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ == yaml_VALUE_TOKEN {
- skip_token(parser)
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_ENTRY_TOKEN && token.typ != yaml_FLOW_SEQUENCE_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Parse the productions:
-// flow_sequence_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// *
-//
-func yaml_parser_parse_flow_sequence_entry_mapping_end(parser *yaml_parser_t, event *yaml_event_t) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- parser.state = yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.start_mark, // [Go] Shouldn't this be end_mark?
- }
- return true
-}
-
-// Parse the productions:
-// flow_mapping ::= FLOW-MAPPING-START
-// ******************
-// (flow_mapping_entry FLOW-ENTRY)*
-// * **********
-// flow_mapping_entry?
-// ******************
-// FLOW-MAPPING-END
-// ****************
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// * *** *
-//
-func yaml_parser_parse_flow_mapping_key(parser *yaml_parser_t, event *yaml_event_t, first bool) bool {
- if first {
- token := peek_token(parser)
- parser.marks = append(parser.marks, token.start_mark)
- skip_token(parser)
- }
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- if token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- if !first {
- if token.typ == yaml_FLOW_ENTRY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- } else {
- context_mark := parser.marks[len(parser.marks)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- return yaml_parser_set_parser_error_context(parser,
- "while parsing a flow mapping", context_mark,
- "did not find expected ',' or '}'", token.start_mark)
- }
- }
-
- if token.typ == yaml_KEY_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_VALUE_TOKEN &&
- token.typ != yaml_FLOW_ENTRY_TOKEN &&
- token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- } else {
- parser.state = yaml_PARSE_FLOW_MAPPING_VALUE_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
- }
- } else if token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
-
- parser.state = parser.states[len(parser.states)-1]
- parser.states = parser.states[:len(parser.states)-1]
- parser.marks = parser.marks[:len(parser.marks)-1]
- *event = yaml_event_t{
- typ: yaml_MAPPING_END_EVENT,
- start_mark: token.start_mark,
- end_mark: token.end_mark,
- }
- yaml_parser_set_event_comments(parser, event)
- skip_token(parser)
- return true
-}
-
-// Parse the productions:
-// flow_mapping_entry ::= flow_node | KEY flow_node? (VALUE flow_node?)?
-// * ***** *
-//
-func yaml_parser_parse_flow_mapping_value(parser *yaml_parser_t, event *yaml_event_t, empty bool) bool {
- token := peek_token(parser)
- if token == nil {
- return false
- }
- if empty {
- parser.state = yaml_PARSE_FLOW_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
- }
- if token.typ == yaml_VALUE_TOKEN {
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- if token.typ != yaml_FLOW_ENTRY_TOKEN && token.typ != yaml_FLOW_MAPPING_END_TOKEN {
- parser.states = append(parser.states, yaml_PARSE_FLOW_MAPPING_KEY_STATE)
- return yaml_parser_parse_node(parser, event, false, false)
- }
- }
- parser.state = yaml_PARSE_FLOW_MAPPING_KEY_STATE
- return yaml_parser_process_empty_scalar(parser, event, token.start_mark)
-}
-
-// Generate an empty scalar event.
-func yaml_parser_process_empty_scalar(parser *yaml_parser_t, event *yaml_event_t, mark yaml_mark_t) bool {
- *event = yaml_event_t{
- typ: yaml_SCALAR_EVENT,
- start_mark: mark,
- end_mark: mark,
- value: nil, // Empty
- implicit: true,
- style: yaml_style_t(yaml_PLAIN_SCALAR_STYLE),
- }
- return true
-}
-
-var default_tag_directives = []yaml_tag_directive_t{
- {[]byte("!"), []byte("!")},
- {[]byte("!!"), []byte("tag:yaml.org,2002:")},
-}
-
-// Parse directives.
-func yaml_parser_process_directives(parser *yaml_parser_t,
- version_directive_ref **yaml_version_directive_t,
- tag_directives_ref *[]yaml_tag_directive_t) bool {
-
- var version_directive *yaml_version_directive_t
- var tag_directives []yaml_tag_directive_t
-
- token := peek_token(parser)
- if token == nil {
- return false
- }
-
- for token.typ == yaml_VERSION_DIRECTIVE_TOKEN || token.typ == yaml_TAG_DIRECTIVE_TOKEN {
- if token.typ == yaml_VERSION_DIRECTIVE_TOKEN {
- if version_directive != nil {
- yaml_parser_set_parser_error(parser,
- "found duplicate %YAML directive", token.start_mark)
- return false
- }
- if token.major != 1 || token.minor != 1 {
- yaml_parser_set_parser_error(parser,
- "found incompatible YAML document", token.start_mark)
- return false
- }
- version_directive = &yaml_version_directive_t{
- major: token.major,
- minor: token.minor,
- }
- } else if token.typ == yaml_TAG_DIRECTIVE_TOKEN {
- value := yaml_tag_directive_t{
- handle: token.value,
- prefix: token.prefix,
- }
- if !yaml_parser_append_tag_directive(parser, value, false, token.start_mark) {
- return false
- }
- tag_directives = append(tag_directives, value)
- }
-
- skip_token(parser)
- token = peek_token(parser)
- if token == nil {
- return false
- }
- }
-
- for i := range default_tag_directives {
- if !yaml_parser_append_tag_directive(parser, default_tag_directives[i], true, token.start_mark) {
- return false
- }
- }
-
- if version_directive_ref != nil {
- *version_directive_ref = version_directive
- }
- if tag_directives_ref != nil {
- *tag_directives_ref = tag_directives
- }
- return true
-}
-
-// Append a tag directive to the directives stack.
-func yaml_parser_append_tag_directive(parser *yaml_parser_t, value yaml_tag_directive_t, allow_duplicates bool, mark yaml_mark_t) bool {
- for i := range parser.tag_directives {
- if bytes.Equal(value.handle, parser.tag_directives[i].handle) {
- if allow_duplicates {
- return true
- }
- return yaml_parser_set_parser_error(parser, "found duplicate %TAG directive", mark)
- }
- }
-
- // [Go] I suspect the copy is unnecessary. This was likely done
- // because there was no way to track ownership of the data.
- value_copy := yaml_tag_directive_t{
- handle: make([]byte, len(value.handle)),
- prefix: make([]byte, len(value.prefix)),
- }
- copy(value_copy.handle, value.handle)
- copy(value_copy.prefix, value.prefix)
- parser.tag_directives = append(parser.tag_directives, value_copy)
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/readerc.go b/sesh/vendor/gopkg.in/yaml.v3/readerc.go
deleted file mode 100644
index b7de0a8..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/readerc.go
+++ /dev/null
@@ -1,434 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "io"
-)
-
-// Set the reader error and return 0.
-func yaml_parser_set_reader_error(parser *yaml_parser_t, problem string, offset int, value int) bool {
- parser.error = yaml_READER_ERROR
- parser.problem = problem
- parser.problem_offset = offset
- parser.problem_value = value
- return false
-}
-
-// Byte order marks.
-const (
- bom_UTF8 = "\xef\xbb\xbf"
- bom_UTF16LE = "\xff\xfe"
- bom_UTF16BE = "\xfe\xff"
-)
-
-// Determine the input stream encoding by checking the BOM symbol. If no BOM is
-// found, the UTF-8 encoding is assumed. Return 1 on success, 0 on failure.
-func yaml_parser_determine_encoding(parser *yaml_parser_t) bool {
- // Ensure that we had enough bytes in the raw buffer.
- for !parser.eof && len(parser.raw_buffer)-parser.raw_buffer_pos < 3 {
- if !yaml_parser_update_raw_buffer(parser) {
- return false
- }
- }
-
- // Determine the encoding.
- buf := parser.raw_buffer
- pos := parser.raw_buffer_pos
- avail := len(buf) - pos
- if avail >= 2 && buf[pos] == bom_UTF16LE[0] && buf[pos+1] == bom_UTF16LE[1] {
- parser.encoding = yaml_UTF16LE_ENCODING
- parser.raw_buffer_pos += 2
- parser.offset += 2
- } else if avail >= 2 && buf[pos] == bom_UTF16BE[0] && buf[pos+1] == bom_UTF16BE[1] {
- parser.encoding = yaml_UTF16BE_ENCODING
- parser.raw_buffer_pos += 2
- parser.offset += 2
- } else if avail >= 3 && buf[pos] == bom_UTF8[0] && buf[pos+1] == bom_UTF8[1] && buf[pos+2] == bom_UTF8[2] {
- parser.encoding = yaml_UTF8_ENCODING
- parser.raw_buffer_pos += 3
- parser.offset += 3
- } else {
- parser.encoding = yaml_UTF8_ENCODING
- }
- return true
-}
-
-// Update the raw buffer.
-func yaml_parser_update_raw_buffer(parser *yaml_parser_t) bool {
- size_read := 0
-
- // Return if the raw buffer is full.
- if parser.raw_buffer_pos == 0 && len(parser.raw_buffer) == cap(parser.raw_buffer) {
- return true
- }
-
- // Return on EOF.
- if parser.eof {
- return true
- }
-
- // Move the remaining bytes in the raw buffer to the beginning.
- if parser.raw_buffer_pos > 0 && parser.raw_buffer_pos < len(parser.raw_buffer) {
- copy(parser.raw_buffer, parser.raw_buffer[parser.raw_buffer_pos:])
- }
- parser.raw_buffer = parser.raw_buffer[:len(parser.raw_buffer)-parser.raw_buffer_pos]
- parser.raw_buffer_pos = 0
-
- // Call the read handler to fill the buffer.
- size_read, err := parser.read_handler(parser, parser.raw_buffer[len(parser.raw_buffer):cap(parser.raw_buffer)])
- parser.raw_buffer = parser.raw_buffer[:len(parser.raw_buffer)+size_read]
- if err == io.EOF {
- parser.eof = true
- } else if err != nil {
- return yaml_parser_set_reader_error(parser, "input error: "+err.Error(), parser.offset, -1)
- }
- return true
-}
-
-// Ensure that the buffer contains at least `length` characters.
-// Return true on success, false on failure.
-//
-// The length is supposed to be significantly less that the buffer size.
-func yaml_parser_update_buffer(parser *yaml_parser_t, length int) bool {
- if parser.read_handler == nil {
- panic("read handler must be set")
- }
-
- // [Go] This function was changed to guarantee the requested length size at EOF.
- // The fact we need to do this is pretty awful, but the description above implies
- // for that to be the case, and there are tests
-
- // If the EOF flag is set and the raw buffer is empty, do nothing.
- if parser.eof && parser.raw_buffer_pos == len(parser.raw_buffer) {
- // [Go] ACTUALLY! Read the documentation of this function above.
- // This is just broken. To return true, we need to have the
- // given length in the buffer. Not doing that means every single
- // check that calls this function to make sure the buffer has a
- // given length is Go) panicking; or C) accessing invalid memory.
- //return true
- }
-
- // Return if the buffer contains enough characters.
- if parser.unread >= length {
- return true
- }
-
- // Determine the input encoding if it is not known yet.
- if parser.encoding == yaml_ANY_ENCODING {
- if !yaml_parser_determine_encoding(parser) {
- return false
- }
- }
-
- // Move the unread characters to the beginning of the buffer.
- buffer_len := len(parser.buffer)
- if parser.buffer_pos > 0 && parser.buffer_pos < buffer_len {
- copy(parser.buffer, parser.buffer[parser.buffer_pos:])
- buffer_len -= parser.buffer_pos
- parser.buffer_pos = 0
- } else if parser.buffer_pos == buffer_len {
- buffer_len = 0
- parser.buffer_pos = 0
- }
-
- // Open the whole buffer for writing, and cut it before returning.
- parser.buffer = parser.buffer[:cap(parser.buffer)]
-
- // Fill the buffer until it has enough characters.
- first := true
- for parser.unread < length {
-
- // Fill the raw buffer if necessary.
- if !first || parser.raw_buffer_pos == len(parser.raw_buffer) {
- if !yaml_parser_update_raw_buffer(parser) {
- parser.buffer = parser.buffer[:buffer_len]
- return false
- }
- }
- first = false
-
- // Decode the raw buffer.
- inner:
- for parser.raw_buffer_pos != len(parser.raw_buffer) {
- var value rune
- var width int
-
- raw_unread := len(parser.raw_buffer) - parser.raw_buffer_pos
-
- // Decode the next character.
- switch parser.encoding {
- case yaml_UTF8_ENCODING:
- // Decode a UTF-8 character. Check RFC 3629
- // (http://www.ietf.org/rfc/rfc3629.txt) for more details.
- //
- // The following table (taken from the RFC) is used for
- // decoding.
- //
- // Char. number range | UTF-8 octet sequence
- // (hexadecimal) | (binary)
- // --------------------+------------------------------------
- // 0000 0000-0000 007F | 0xxxxxxx
- // 0000 0080-0000 07FF | 110xxxxx 10xxxxxx
- // 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
- // 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- //
- // Additionally, the characters in the range 0xD800-0xDFFF
- // are prohibited as they are reserved for use with UTF-16
- // surrogate pairs.
-
- // Determine the length of the UTF-8 sequence.
- octet := parser.raw_buffer[parser.raw_buffer_pos]
- switch {
- case octet&0x80 == 0x00:
- width = 1
- case octet&0xE0 == 0xC0:
- width = 2
- case octet&0xF0 == 0xE0:
- width = 3
- case octet&0xF8 == 0xF0:
- width = 4
- default:
- // The leading octet is invalid.
- return yaml_parser_set_reader_error(parser,
- "invalid leading UTF-8 octet",
- parser.offset, int(octet))
- }
-
- // Check if the raw buffer contains an incomplete character.
- if width > raw_unread {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-8 octet sequence",
- parser.offset, -1)
- }
- break inner
- }
-
- // Decode the leading octet.
- switch {
- case octet&0x80 == 0x00:
- value = rune(octet & 0x7F)
- case octet&0xE0 == 0xC0:
- value = rune(octet & 0x1F)
- case octet&0xF0 == 0xE0:
- value = rune(octet & 0x0F)
- case octet&0xF8 == 0xF0:
- value = rune(octet & 0x07)
- default:
- value = 0
- }
-
- // Check and decode the trailing octets.
- for k := 1; k < width; k++ {
- octet = parser.raw_buffer[parser.raw_buffer_pos+k]
-
- // Check if the octet is valid.
- if (octet & 0xC0) != 0x80 {
- return yaml_parser_set_reader_error(parser,
- "invalid trailing UTF-8 octet",
- parser.offset+k, int(octet))
- }
-
- // Decode the octet.
- value = (value << 6) + rune(octet&0x3F)
- }
-
- // Check the length of the sequence against the value.
- switch {
- case width == 1:
- case width == 2 && value >= 0x80:
- case width == 3 && value >= 0x800:
- case width == 4 && value >= 0x10000:
- default:
- return yaml_parser_set_reader_error(parser,
- "invalid length of a UTF-8 sequence",
- parser.offset, -1)
- }
-
- // Check the range of the value.
- if value >= 0xD800 && value <= 0xDFFF || value > 0x10FFFF {
- return yaml_parser_set_reader_error(parser,
- "invalid Unicode character",
- parser.offset, int(value))
- }
-
- case yaml_UTF16LE_ENCODING, yaml_UTF16BE_ENCODING:
- var low, high int
- if parser.encoding == yaml_UTF16LE_ENCODING {
- low, high = 0, 1
- } else {
- low, high = 1, 0
- }
-
- // The UTF-16 encoding is not as simple as one might
- // naively think. Check RFC 2781
- // (http://www.ietf.org/rfc/rfc2781.txt).
- //
- // Normally, two subsequent bytes describe a Unicode
- // character. However a special technique (called a
- // surrogate pair) is used for specifying character
- // values larger than 0xFFFF.
- //
- // A surrogate pair consists of two pseudo-characters:
- // high surrogate area (0xD800-0xDBFF)
- // low surrogate area (0xDC00-0xDFFF)
- //
- // The following formulas are used for decoding
- // and encoding characters using surrogate pairs:
- //
- // U = U' + 0x10000 (0x01 00 00 <= U <= 0x10 FF FF)
- // U' = yyyyyyyyyyxxxxxxxxxx (0 <= U' <= 0x0F FF FF)
- // W1 = 110110yyyyyyyyyy
- // W2 = 110111xxxxxxxxxx
- //
- // where U is the character value, W1 is the high surrogate
- // area, W2 is the low surrogate area.
-
- // Check for incomplete UTF-16 character.
- if raw_unread < 2 {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-16 character",
- parser.offset, -1)
- }
- break inner
- }
-
- // Get the character.
- value = rune(parser.raw_buffer[parser.raw_buffer_pos+low]) +
- (rune(parser.raw_buffer[parser.raw_buffer_pos+high]) << 8)
-
- // Check for unexpected low surrogate area.
- if value&0xFC00 == 0xDC00 {
- return yaml_parser_set_reader_error(parser,
- "unexpected low surrogate area",
- parser.offset, int(value))
- }
-
- // Check for a high surrogate area.
- if value&0xFC00 == 0xD800 {
- width = 4
-
- // Check for incomplete surrogate pair.
- if raw_unread < 4 {
- if parser.eof {
- return yaml_parser_set_reader_error(parser,
- "incomplete UTF-16 surrogate pair",
- parser.offset, -1)
- }
- break inner
- }
-
- // Get the next character.
- value2 := rune(parser.raw_buffer[parser.raw_buffer_pos+low+2]) +
- (rune(parser.raw_buffer[parser.raw_buffer_pos+high+2]) << 8)
-
- // Check for a low surrogate area.
- if value2&0xFC00 != 0xDC00 {
- return yaml_parser_set_reader_error(parser,
- "expected low surrogate area",
- parser.offset+2, int(value2))
- }
-
- // Generate the value of the surrogate pair.
- value = 0x10000 + ((value & 0x3FF) << 10) + (value2 & 0x3FF)
- } else {
- width = 2
- }
-
- default:
- panic("impossible")
- }
-
- // Check if the character is in the allowed range:
- // #x9 | #xA | #xD | [#x20-#x7E] (8 bit)
- // | #x85 | [#xA0-#xD7FF] | [#xE000-#xFFFD] (16 bit)
- // | [#x10000-#x10FFFF] (32 bit)
- switch {
- case value == 0x09:
- case value == 0x0A:
- case value == 0x0D:
- case value >= 0x20 && value <= 0x7E:
- case value == 0x85:
- case value >= 0xA0 && value <= 0xD7FF:
- case value >= 0xE000 && value <= 0xFFFD:
- case value >= 0x10000 && value <= 0x10FFFF:
- default:
- return yaml_parser_set_reader_error(parser,
- "control characters are not allowed",
- parser.offset, int(value))
- }
-
- // Move the raw pointers.
- parser.raw_buffer_pos += width
- parser.offset += width
-
- // Finally put the character into the buffer.
- if value <= 0x7F {
- // 0000 0000-0000 007F . 0xxxxxxx
- parser.buffer[buffer_len+0] = byte(value)
- buffer_len += 1
- } else if value <= 0x7FF {
- // 0000 0080-0000 07FF . 110xxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xC0 + (value >> 6))
- parser.buffer[buffer_len+1] = byte(0x80 + (value & 0x3F))
- buffer_len += 2
- } else if value <= 0xFFFF {
- // 0000 0800-0000 FFFF . 1110xxxx 10xxxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xE0 + (value >> 12))
- parser.buffer[buffer_len+1] = byte(0x80 + ((value >> 6) & 0x3F))
- parser.buffer[buffer_len+2] = byte(0x80 + (value & 0x3F))
- buffer_len += 3
- } else {
- // 0001 0000-0010 FFFF . 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- parser.buffer[buffer_len+0] = byte(0xF0 + (value >> 18))
- parser.buffer[buffer_len+1] = byte(0x80 + ((value >> 12) & 0x3F))
- parser.buffer[buffer_len+2] = byte(0x80 + ((value >> 6) & 0x3F))
- parser.buffer[buffer_len+3] = byte(0x80 + (value & 0x3F))
- buffer_len += 4
- }
-
- parser.unread++
- }
-
- // On EOF, put NUL into the buffer and return.
- if parser.eof {
- parser.buffer[buffer_len] = 0
- buffer_len++
- parser.unread++
- break
- }
- }
- // [Go] Read the documentation of this function above. To return true,
- // we need to have the given length in the buffer. Not doing that means
- // every single check that calls this function to make sure the buffer
- // has a given length is Go) panicking; or C) accessing invalid memory.
- // This happens here due to the EOF above breaking early.
- for buffer_len < length {
- parser.buffer[buffer_len] = 0
- buffer_len++
- }
- parser.buffer = parser.buffer[:buffer_len]
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/resolve.go b/sesh/vendor/gopkg.in/yaml.v3/resolve.go
deleted file mode 100644
index 64ae888..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/resolve.go
+++ /dev/null
@@ -1,326 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "encoding/base64"
- "math"
- "regexp"
- "strconv"
- "strings"
- "time"
-)
-
-type resolveMapItem struct {
- value interface{}
- tag string
-}
-
-var resolveTable = make([]byte, 256)
-var resolveMap = make(map[string]resolveMapItem)
-
-func init() {
- t := resolveTable
- t[int('+')] = 'S' // Sign
- t[int('-')] = 'S'
- for _, c := range "0123456789" {
- t[int(c)] = 'D' // Digit
- }
- for _, c := range "yYnNtTfFoO~" {
- t[int(c)] = 'M' // In map
- }
- t[int('.')] = '.' // Float (potentially in map)
-
- var resolveMapList = []struct {
- v interface{}
- tag string
- l []string
- }{
- {true, boolTag, []string{"true", "True", "TRUE"}},
- {false, boolTag, []string{"false", "False", "FALSE"}},
- {nil, nullTag, []string{"", "~", "null", "Null", "NULL"}},
- {math.NaN(), floatTag, []string{".nan", ".NaN", ".NAN"}},
- {math.Inf(+1), floatTag, []string{".inf", ".Inf", ".INF"}},
- {math.Inf(+1), floatTag, []string{"+.inf", "+.Inf", "+.INF"}},
- {math.Inf(-1), floatTag, []string{"-.inf", "-.Inf", "-.INF"}},
- {"<<", mergeTag, []string{"<<"}},
- }
-
- m := resolveMap
- for _, item := range resolveMapList {
- for _, s := range item.l {
- m[s] = resolveMapItem{item.v, item.tag}
- }
- }
-}
-
-const (
- nullTag = "!!null"
- boolTag = "!!bool"
- strTag = "!!str"
- intTag = "!!int"
- floatTag = "!!float"
- timestampTag = "!!timestamp"
- seqTag = "!!seq"
- mapTag = "!!map"
- binaryTag = "!!binary"
- mergeTag = "!!merge"
-)
-
-var longTags = make(map[string]string)
-var shortTags = make(map[string]string)
-
-func init() {
- for _, stag := range []string{nullTag, boolTag, strTag, intTag, floatTag, timestampTag, seqTag, mapTag, binaryTag, mergeTag} {
- ltag := longTag(stag)
- longTags[stag] = ltag
- shortTags[ltag] = stag
- }
-}
-
-const longTagPrefix = "tag:yaml.org,2002:"
-
-func shortTag(tag string) string {
- if strings.HasPrefix(tag, longTagPrefix) {
- if stag, ok := shortTags[tag]; ok {
- return stag
- }
- return "!!" + tag[len(longTagPrefix):]
- }
- return tag
-}
-
-func longTag(tag string) string {
- if strings.HasPrefix(tag, "!!") {
- if ltag, ok := longTags[tag]; ok {
- return ltag
- }
- return longTagPrefix + tag[2:]
- }
- return tag
-}
-
-func resolvableTag(tag string) bool {
- switch tag {
- case "", strTag, boolTag, intTag, floatTag, nullTag, timestampTag:
- return true
- }
- return false
-}
-
-var yamlStyleFloat = regexp.MustCompile(`^[-+]?(\.[0-9]+|[0-9]+(\.[0-9]*)?)([eE][-+]?[0-9]+)?$`)
-
-func resolve(tag string, in string) (rtag string, out interface{}) {
- tag = shortTag(tag)
- if !resolvableTag(tag) {
- return tag, in
- }
-
- defer func() {
- switch tag {
- case "", rtag, strTag, binaryTag:
- return
- case floatTag:
- if rtag == intTag {
- switch v := out.(type) {
- case int64:
- rtag = floatTag
- out = float64(v)
- return
- case int:
- rtag = floatTag
- out = float64(v)
- return
- }
- }
- }
- failf("cannot decode %s `%s` as a %s", shortTag(rtag), in, shortTag(tag))
- }()
-
- // Any data is accepted as a !!str or !!binary.
- // Otherwise, the prefix is enough of a hint about what it might be.
- hint := byte('N')
- if in != "" {
- hint = resolveTable[in[0]]
- }
- if hint != 0 && tag != strTag && tag != binaryTag {
- // Handle things we can lookup in a map.
- if item, ok := resolveMap[in]; ok {
- return item.tag, item.value
- }
-
- // Base 60 floats are a bad idea, were dropped in YAML 1.2, and
- // are purposefully unsupported here. They're still quoted on
- // the way out for compatibility with other parser, though.
-
- switch hint {
- case 'M':
- // We've already checked the map above.
-
- case '.':
- // Not in the map, so maybe a normal float.
- floatv, err := strconv.ParseFloat(in, 64)
- if err == nil {
- return floatTag, floatv
- }
-
- case 'D', 'S':
- // Int, float, or timestamp.
- // Only try values as a timestamp if the value is unquoted or there's an explicit
- // !!timestamp tag.
- if tag == "" || tag == timestampTag {
- t, ok := parseTimestamp(in)
- if ok {
- return timestampTag, t
- }
- }
-
- plain := strings.Replace(in, "_", "", -1)
- intv, err := strconv.ParseInt(plain, 0, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain, 0, 64)
- if err == nil {
- return intTag, uintv
- }
- if yamlStyleFloat.MatchString(plain) {
- floatv, err := strconv.ParseFloat(plain, 64)
- if err == nil {
- return floatTag, floatv
- }
- }
- if strings.HasPrefix(plain, "0b") {
- intv, err := strconv.ParseInt(plain[2:], 2, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain[2:], 2, 64)
- if err == nil {
- return intTag, uintv
- }
- } else if strings.HasPrefix(plain, "-0b") {
- intv, err := strconv.ParseInt("-"+plain[3:], 2, 64)
- if err == nil {
- if true || intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- }
- // Octals as introduced in version 1.2 of the spec.
- // Octals from the 1.1 spec, spelled as 0777, are still
- // decoded by default in v3 as well for compatibility.
- // May be dropped in v4 depending on how usage evolves.
- if strings.HasPrefix(plain, "0o") {
- intv, err := strconv.ParseInt(plain[2:], 8, 64)
- if err == nil {
- if intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- uintv, err := strconv.ParseUint(plain[2:], 8, 64)
- if err == nil {
- return intTag, uintv
- }
- } else if strings.HasPrefix(plain, "-0o") {
- intv, err := strconv.ParseInt("-"+plain[3:], 8, 64)
- if err == nil {
- if true || intv == int64(int(intv)) {
- return intTag, int(intv)
- } else {
- return intTag, intv
- }
- }
- }
- default:
- panic("internal error: missing handler for resolver table: " + string(rune(hint)) + " (with " + in + ")")
- }
- }
- return strTag, in
-}
-
-// encodeBase64 encodes s as base64 that is broken up into multiple lines
-// as appropriate for the resulting length.
-func encodeBase64(s string) string {
- const lineLen = 70
- encLen := base64.StdEncoding.EncodedLen(len(s))
- lines := encLen/lineLen + 1
- buf := make([]byte, encLen*2+lines)
- in := buf[0:encLen]
- out := buf[encLen:]
- base64.StdEncoding.Encode(in, []byte(s))
- k := 0
- for i := 0; i < len(in); i += lineLen {
- j := i + lineLen
- if j > len(in) {
- j = len(in)
- }
- k += copy(out[k:], in[i:j])
- if lines > 1 {
- out[k] = '\n'
- k++
- }
- }
- return string(out[:k])
-}
-
-// This is a subset of the formats allowed by the regular expression
-// defined at http://yaml.org/type/timestamp.html.
-var allowedTimestampFormats = []string{
- "2006-1-2T15:4:5.999999999Z07:00", // RCF3339Nano with short date fields.
- "2006-1-2t15:4:5.999999999Z07:00", // RFC3339Nano with short date fields and lower-case "t".
- "2006-1-2 15:4:5.999999999", // space separated with no time zone
- "2006-1-2", // date only
- // Notable exception: time.Parse cannot handle: "2001-12-14 21:59:43.10 -5"
- // from the set of examples.
-}
-
-// parseTimestamp parses s as a timestamp string and
-// returns the timestamp and reports whether it succeeded.
-// Timestamp formats are defined at http://yaml.org/type/timestamp.html
-func parseTimestamp(s string) (time.Time, bool) {
- // TODO write code to check all the formats supported by
- // http://yaml.org/type/timestamp.html instead of using time.Parse.
-
- // Quick check: all date formats start with YYYY-.
- i := 0
- for ; i < len(s); i++ {
- if c := s[i]; c < '0' || c > '9' {
- break
- }
- }
- if i != 4 || i == len(s) || s[i] != '-' {
- return time.Time{}, false
- }
- for _, format := range allowedTimestampFormats {
- if t, err := time.Parse(format, s); err == nil {
- return t, true
- }
- }
- return time.Time{}, false
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/scannerc.go b/sesh/vendor/gopkg.in/yaml.v3/scannerc.go
deleted file mode 100644
index ca00701..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/scannerc.go
+++ /dev/null
@@ -1,3038 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "bytes"
- "fmt"
-)
-
-// Introduction
-// ************
-//
-// The following notes assume that you are familiar with the YAML specification
-// (http://yaml.org/spec/1.2/spec.html). We mostly follow it, although in
-// some cases we are less restrictive that it requires.
-//
-// The process of transforming a YAML stream into a sequence of events is
-// divided on two steps: Scanning and Parsing.
-//
-// The Scanner transforms the input stream into a sequence of tokens, while the
-// parser transform the sequence of tokens produced by the Scanner into a
-// sequence of parsing events.
-//
-// The Scanner is rather clever and complicated. The Parser, on the contrary,
-// is a straightforward implementation of a recursive-descendant parser (or,
-// LL(1) parser, as it is usually called).
-//
-// Actually there are two issues of Scanning that might be called "clever", the
-// rest is quite straightforward. The issues are "block collection start" and
-// "simple keys". Both issues are explained below in details.
-//
-// Here the Scanning step is explained and implemented. We start with the list
-// of all the tokens produced by the Scanner together with short descriptions.
-//
-// Now, tokens:
-//
-// STREAM-START(encoding) # The stream start.
-// STREAM-END # The stream end.
-// VERSION-DIRECTIVE(major,minor) # The '%YAML' directive.
-// TAG-DIRECTIVE(handle,prefix) # The '%TAG' directive.
-// DOCUMENT-START # '---'
-// DOCUMENT-END # '...'
-// BLOCK-SEQUENCE-START # Indentation increase denoting a block
-// BLOCK-MAPPING-START # sequence or a block mapping.
-// BLOCK-END # Indentation decrease.
-// FLOW-SEQUENCE-START # '['
-// FLOW-SEQUENCE-END # ']'
-// BLOCK-SEQUENCE-START # '{'
-// BLOCK-SEQUENCE-END # '}'
-// BLOCK-ENTRY # '-'
-// FLOW-ENTRY # ','
-// KEY # '?' or nothing (simple keys).
-// VALUE # ':'
-// ALIAS(anchor) # '*anchor'
-// ANCHOR(anchor) # '&anchor'
-// TAG(handle,suffix) # '!handle!suffix'
-// SCALAR(value,style) # A scalar.
-//
-// The following two tokens are "virtual" tokens denoting the beginning and the
-// end of the stream:
-//
-// STREAM-START(encoding)
-// STREAM-END
-//
-// We pass the information about the input stream encoding with the
-// STREAM-START token.
-//
-// The next two tokens are responsible for tags:
-//
-// VERSION-DIRECTIVE(major,minor)
-// TAG-DIRECTIVE(handle,prefix)
-//
-// Example:
-//
-// %YAML 1.1
-// %TAG ! !foo
-// %TAG !yaml! tag:yaml.org,2002:
-// ---
-//
-// The correspoding sequence of tokens:
-//
-// STREAM-START(utf-8)
-// VERSION-DIRECTIVE(1,1)
-// TAG-DIRECTIVE("!","!foo")
-// TAG-DIRECTIVE("!yaml","tag:yaml.org,2002:")
-// DOCUMENT-START
-// STREAM-END
-//
-// Note that the VERSION-DIRECTIVE and TAG-DIRECTIVE tokens occupy a whole
-// line.
-//
-// The document start and end indicators are represented by:
-//
-// DOCUMENT-START
-// DOCUMENT-END
-//
-// Note that if a YAML stream contains an implicit document (without '---'
-// and '...' indicators), no DOCUMENT-START and DOCUMENT-END tokens will be
-// produced.
-//
-// In the following examples, we present whole documents together with the
-// produced tokens.
-//
-// 1. An implicit document:
-//
-// 'a scalar'
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// SCALAR("a scalar",single-quoted)
-// STREAM-END
-//
-// 2. An explicit document:
-//
-// ---
-// 'a scalar'
-// ...
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// DOCUMENT-START
-// SCALAR("a scalar",single-quoted)
-// DOCUMENT-END
-// STREAM-END
-//
-// 3. Several documents in a stream:
-//
-// 'a scalar'
-// ---
-// 'another scalar'
-// ---
-// 'yet another scalar'
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// SCALAR("a scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("another scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("yet another scalar",single-quoted)
-// STREAM-END
-//
-// We have already introduced the SCALAR token above. The following tokens are
-// used to describe aliases, anchors, tag, and scalars:
-//
-// ALIAS(anchor)
-// ANCHOR(anchor)
-// TAG(handle,suffix)
-// SCALAR(value,style)
-//
-// The following series of examples illustrate the usage of these tokens:
-//
-// 1. A recursive sequence:
-//
-// &A [ *A ]
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// ANCHOR("A")
-// FLOW-SEQUENCE-START
-// ALIAS("A")
-// FLOW-SEQUENCE-END
-// STREAM-END
-//
-// 2. A tagged scalar:
-//
-// !!float "3.14" # A good approximation.
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// TAG("!!","float")
-// SCALAR("3.14",double-quoted)
-// STREAM-END
-//
-// 3. Various scalar styles:
-//
-// --- # Implicit empty plain scalars do not produce tokens.
-// --- a plain scalar
-// --- 'a single-quoted scalar'
-// --- "a double-quoted scalar"
-// --- |-
-// a literal scalar
-// --- >-
-// a folded
-// scalar
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// DOCUMENT-START
-// DOCUMENT-START
-// SCALAR("a plain scalar",plain)
-// DOCUMENT-START
-// SCALAR("a single-quoted scalar",single-quoted)
-// DOCUMENT-START
-// SCALAR("a double-quoted scalar",double-quoted)
-// DOCUMENT-START
-// SCALAR("a literal scalar",literal)
-// DOCUMENT-START
-// SCALAR("a folded scalar",folded)
-// STREAM-END
-//
-// Now it's time to review collection-related tokens. We will start with
-// flow collections:
-//
-// FLOW-SEQUENCE-START
-// FLOW-SEQUENCE-END
-// FLOW-MAPPING-START
-// FLOW-MAPPING-END
-// FLOW-ENTRY
-// KEY
-// VALUE
-//
-// The tokens FLOW-SEQUENCE-START, FLOW-SEQUENCE-END, FLOW-MAPPING-START, and
-// FLOW-MAPPING-END represent the indicators '[', ']', '{', and '}'
-// correspondingly. FLOW-ENTRY represent the ',' indicator. Finally the
-// indicators '?' and ':', which are used for denoting mapping keys and values,
-// are represented by the KEY and VALUE tokens.
-//
-// The following examples show flow collections:
-//
-// 1. A flow sequence:
-//
-// [item 1, item 2, item 3]
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// FLOW-SEQUENCE-START
-// SCALAR("item 1",plain)
-// FLOW-ENTRY
-// SCALAR("item 2",plain)
-// FLOW-ENTRY
-// SCALAR("item 3",plain)
-// FLOW-SEQUENCE-END
-// STREAM-END
-//
-// 2. A flow mapping:
-//
-// {
-// a simple key: a value, # Note that the KEY token is produced.
-// ? a complex key: another value,
-// }
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// FLOW-MAPPING-START
-// KEY
-// SCALAR("a simple key",plain)
-// VALUE
-// SCALAR("a value",plain)
-// FLOW-ENTRY
-// KEY
-// SCALAR("a complex key",plain)
-// VALUE
-// SCALAR("another value",plain)
-// FLOW-ENTRY
-// FLOW-MAPPING-END
-// STREAM-END
-//
-// A simple key is a key which is not denoted by the '?' indicator. Note that
-// the Scanner still produce the KEY token whenever it encounters a simple key.
-//
-// For scanning block collections, the following tokens are used (note that we
-// repeat KEY and VALUE here):
-//
-// BLOCK-SEQUENCE-START
-// BLOCK-MAPPING-START
-// BLOCK-END
-// BLOCK-ENTRY
-// KEY
-// VALUE
-//
-// The tokens BLOCK-SEQUENCE-START and BLOCK-MAPPING-START denote indentation
-// increase that precedes a block collection (cf. the INDENT token in Python).
-// The token BLOCK-END denote indentation decrease that ends a block collection
-// (cf. the DEDENT token in Python). However YAML has some syntax pecularities
-// that makes detections of these tokens more complex.
-//
-// The tokens BLOCK-ENTRY, KEY, and VALUE are used to represent the indicators
-// '-', '?', and ':' correspondingly.
-//
-// The following examples show how the tokens BLOCK-SEQUENCE-START,
-// BLOCK-MAPPING-START, and BLOCK-END are emitted by the Scanner:
-//
-// 1. Block sequences:
-//
-// - item 1
-// - item 2
-// -
-// - item 3.1
-// - item 3.2
-// -
-// key 1: value 1
-// key 2: value 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-ENTRY
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 3.1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 3.2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// 2. Block mappings:
-//
-// a simple key: a value # The KEY token is produced here.
-// ? a complex key
-// : another value
-// a mapping:
-// key 1: value 1
-// key 2: value 2
-// a sequence:
-// - item 1
-// - item 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("a simple key",plain)
-// VALUE
-// SCALAR("a value",plain)
-// KEY
-// SCALAR("a complex key",plain)
-// VALUE
-// SCALAR("another value",plain)
-// KEY
-// SCALAR("a mapping",plain)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// KEY
-// SCALAR("a sequence",plain)
-// VALUE
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// YAML does not always require to start a new block collection from a new
-// line. If the current line contains only '-', '?', and ':' indicators, a new
-// block collection may start at the current line. The following examples
-// illustrate this case:
-//
-// 1. Collections in a sequence:
-//
-// - - item 1
-// - item 2
-// - key 1: value 1
-// key 2: value 2
-// - ? complex key
-// : complex value
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-ENTRY
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("complex key")
-// VALUE
-// SCALAR("complex value")
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// 2. Collections in a mapping:
-//
-// ? a sequence
-// : - item 1
-// - item 2
-// ? a mapping
-// : key 1: value 1
-// key 2: value 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("a sequence",plain)
-// VALUE
-// BLOCK-SEQUENCE-START
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-// KEY
-// SCALAR("a mapping",plain)
-// VALUE
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key 1",plain)
-// VALUE
-// SCALAR("value 1",plain)
-// KEY
-// SCALAR("key 2",plain)
-// VALUE
-// SCALAR("value 2",plain)
-// BLOCK-END
-// BLOCK-END
-// STREAM-END
-//
-// YAML also permits non-indented sequences if they are included into a block
-// mapping. In this case, the token BLOCK-SEQUENCE-START is not produced:
-//
-// key:
-// - item 1 # BLOCK-SEQUENCE-START is NOT produced here.
-// - item 2
-//
-// Tokens:
-//
-// STREAM-START(utf-8)
-// BLOCK-MAPPING-START
-// KEY
-// SCALAR("key",plain)
-// VALUE
-// BLOCK-ENTRY
-// SCALAR("item 1",plain)
-// BLOCK-ENTRY
-// SCALAR("item 2",plain)
-// BLOCK-END
-//
-
-// Ensure that the buffer contains the required number of characters.
-// Return true on success, false on failure (reader error or memory error).
-func cache(parser *yaml_parser_t, length int) bool {
- // [Go] This was inlined: !cache(A, B) -> unread < B && !update(A, B)
- return parser.unread >= length || yaml_parser_update_buffer(parser, length)
-}
-
-// Advance the buffer pointer.
-func skip(parser *yaml_parser_t) {
- if !is_blank(parser.buffer, parser.buffer_pos) {
- parser.newlines = 0
- }
- parser.mark.index++
- parser.mark.column++
- parser.unread--
- parser.buffer_pos += width(parser.buffer[parser.buffer_pos])
-}
-
-func skip_line(parser *yaml_parser_t) {
- if is_crlf(parser.buffer, parser.buffer_pos) {
- parser.mark.index += 2
- parser.mark.column = 0
- parser.mark.line++
- parser.unread -= 2
- parser.buffer_pos += 2
- parser.newlines++
- } else if is_break(parser.buffer, parser.buffer_pos) {
- parser.mark.index++
- parser.mark.column = 0
- parser.mark.line++
- parser.unread--
- parser.buffer_pos += width(parser.buffer[parser.buffer_pos])
- parser.newlines++
- }
-}
-
-// Copy a character to a string buffer and advance pointers.
-func read(parser *yaml_parser_t, s []byte) []byte {
- if !is_blank(parser.buffer, parser.buffer_pos) {
- parser.newlines = 0
- }
- w := width(parser.buffer[parser.buffer_pos])
- if w == 0 {
- panic("invalid character sequence")
- }
- if len(s) == 0 {
- s = make([]byte, 0, 32)
- }
- if w == 1 && len(s)+w <= cap(s) {
- s = s[:len(s)+1]
- s[len(s)-1] = parser.buffer[parser.buffer_pos]
- parser.buffer_pos++
- } else {
- s = append(s, parser.buffer[parser.buffer_pos:parser.buffer_pos+w]...)
- parser.buffer_pos += w
- }
- parser.mark.index++
- parser.mark.column++
- parser.unread--
- return s
-}
-
-// Copy a line break character to a string buffer and advance pointers.
-func read_line(parser *yaml_parser_t, s []byte) []byte {
- buf := parser.buffer
- pos := parser.buffer_pos
- switch {
- case buf[pos] == '\r' && buf[pos+1] == '\n':
- // CR LF . LF
- s = append(s, '\n')
- parser.buffer_pos += 2
- parser.mark.index++
- parser.unread--
- case buf[pos] == '\r' || buf[pos] == '\n':
- // CR|LF . LF
- s = append(s, '\n')
- parser.buffer_pos += 1
- case buf[pos] == '\xC2' && buf[pos+1] == '\x85':
- // NEL . LF
- s = append(s, '\n')
- parser.buffer_pos += 2
- case buf[pos] == '\xE2' && buf[pos+1] == '\x80' && (buf[pos+2] == '\xA8' || buf[pos+2] == '\xA9'):
- // LS|PS . LS|PS
- s = append(s, buf[parser.buffer_pos:pos+3]...)
- parser.buffer_pos += 3
- default:
- return s
- }
- parser.mark.index++
- parser.mark.column = 0
- parser.mark.line++
- parser.unread--
- parser.newlines++
- return s
-}
-
-// Get the next token.
-func yaml_parser_scan(parser *yaml_parser_t, token *yaml_token_t) bool {
- // Erase the token object.
- *token = yaml_token_t{} // [Go] Is this necessary?
-
- // No tokens after STREAM-END or error.
- if parser.stream_end_produced || parser.error != yaml_NO_ERROR {
- return true
- }
-
- // Ensure that the tokens queue contains enough tokens.
- if !parser.token_available {
- if !yaml_parser_fetch_more_tokens(parser) {
- return false
- }
- }
-
- // Fetch the next token from the queue.
- *token = parser.tokens[parser.tokens_head]
- parser.tokens_head++
- parser.tokens_parsed++
- parser.token_available = false
-
- if token.typ == yaml_STREAM_END_TOKEN {
- parser.stream_end_produced = true
- }
- return true
-}
-
-// Set the scanner error and return false.
-func yaml_parser_set_scanner_error(parser *yaml_parser_t, context string, context_mark yaml_mark_t, problem string) bool {
- parser.error = yaml_SCANNER_ERROR
- parser.context = context
- parser.context_mark = context_mark
- parser.problem = problem
- parser.problem_mark = parser.mark
- return false
-}
-
-func yaml_parser_set_scanner_tag_error(parser *yaml_parser_t, directive bool, context_mark yaml_mark_t, problem string) bool {
- context := "while parsing a tag"
- if directive {
- context = "while parsing a %TAG directive"
- }
- return yaml_parser_set_scanner_error(parser, context, context_mark, problem)
-}
-
-func trace(args ...interface{}) func() {
- pargs := append([]interface{}{"+++"}, args...)
- fmt.Println(pargs...)
- pargs = append([]interface{}{"---"}, args...)
- return func() { fmt.Println(pargs...) }
-}
-
-// Ensure that the tokens queue contains at least one token which can be
-// returned to the Parser.
-func yaml_parser_fetch_more_tokens(parser *yaml_parser_t) bool {
- // While we need more tokens to fetch, do it.
- for {
- // [Go] The comment parsing logic requires a lookahead of two tokens
- // so that foot comments may be parsed in time of associating them
- // with the tokens that are parsed before them, and also for line
- // comments to be transformed into head comments in some edge cases.
- if parser.tokens_head < len(parser.tokens)-2 {
- // If a potential simple key is at the head position, we need to fetch
- // the next token to disambiguate it.
- head_tok_idx, ok := parser.simple_keys_by_tok[parser.tokens_parsed]
- if !ok {
- break
- } else if valid, ok := yaml_simple_key_is_valid(parser, &parser.simple_keys[head_tok_idx]); !ok {
- return false
- } else if !valid {
- break
- }
- }
- // Fetch the next token.
- if !yaml_parser_fetch_next_token(parser) {
- return false
- }
- }
-
- parser.token_available = true
- return true
-}
-
-// The dispatcher for token fetchers.
-func yaml_parser_fetch_next_token(parser *yaml_parser_t) (ok bool) {
- // Ensure that the buffer is initialized.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check if we just started scanning. Fetch STREAM-START then.
- if !parser.stream_start_produced {
- return yaml_parser_fetch_stream_start(parser)
- }
-
- scan_mark := parser.mark
-
- // Eat whitespaces and comments until we reach the next token.
- if !yaml_parser_scan_to_next_token(parser) {
- return false
- }
-
- // [Go] While unrolling indents, transform the head comments of prior
- // indentation levels observed after scan_start into foot comments at
- // the respective indexes.
-
- // Check the indentation level against the current column.
- if !yaml_parser_unroll_indent(parser, parser.mark.column, scan_mark) {
- return false
- }
-
- // Ensure that the buffer contains at least 4 characters. 4 is the length
- // of the longest indicators ('--- ' and '... ').
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
-
- // Is it the end of the stream?
- if is_z(parser.buffer, parser.buffer_pos) {
- return yaml_parser_fetch_stream_end(parser)
- }
-
- // Is it a directive?
- if parser.mark.column == 0 && parser.buffer[parser.buffer_pos] == '%' {
- return yaml_parser_fetch_directive(parser)
- }
-
- buf := parser.buffer
- pos := parser.buffer_pos
-
- // Is it the document start indicator?
- if parser.mark.column == 0 && buf[pos] == '-' && buf[pos+1] == '-' && buf[pos+2] == '-' && is_blankz(buf, pos+3) {
- return yaml_parser_fetch_document_indicator(parser, yaml_DOCUMENT_START_TOKEN)
- }
-
- // Is it the document end indicator?
- if parser.mark.column == 0 && buf[pos] == '.' && buf[pos+1] == '.' && buf[pos+2] == '.' && is_blankz(buf, pos+3) {
- return yaml_parser_fetch_document_indicator(parser, yaml_DOCUMENT_END_TOKEN)
- }
-
- comment_mark := parser.mark
- if len(parser.tokens) > 0 && (parser.flow_level == 0 && buf[pos] == ':' || parser.flow_level > 0 && buf[pos] == ',') {
- // Associate any following comments with the prior token.
- comment_mark = parser.tokens[len(parser.tokens)-1].start_mark
- }
- defer func() {
- if !ok {
- return
- }
- if len(parser.tokens) > 0 && parser.tokens[len(parser.tokens)-1].typ == yaml_BLOCK_ENTRY_TOKEN {
- // Sequence indicators alone have no line comments. It becomes
- // a head comment for whatever follows.
- return
- }
- if !yaml_parser_scan_line_comment(parser, comment_mark) {
- ok = false
- return
- }
- }()
-
- // Is it the flow sequence start indicator?
- if buf[pos] == '[' {
- return yaml_parser_fetch_flow_collection_start(parser, yaml_FLOW_SEQUENCE_START_TOKEN)
- }
-
- // Is it the flow mapping start indicator?
- if parser.buffer[parser.buffer_pos] == '{' {
- return yaml_parser_fetch_flow_collection_start(parser, yaml_FLOW_MAPPING_START_TOKEN)
- }
-
- // Is it the flow sequence end indicator?
- if parser.buffer[parser.buffer_pos] == ']' {
- return yaml_parser_fetch_flow_collection_end(parser,
- yaml_FLOW_SEQUENCE_END_TOKEN)
- }
-
- // Is it the flow mapping end indicator?
- if parser.buffer[parser.buffer_pos] == '}' {
- return yaml_parser_fetch_flow_collection_end(parser,
- yaml_FLOW_MAPPING_END_TOKEN)
- }
-
- // Is it the flow entry indicator?
- if parser.buffer[parser.buffer_pos] == ',' {
- return yaml_parser_fetch_flow_entry(parser)
- }
-
- // Is it the block entry indicator?
- if parser.buffer[parser.buffer_pos] == '-' && is_blankz(parser.buffer, parser.buffer_pos+1) {
- return yaml_parser_fetch_block_entry(parser)
- }
-
- // Is it the key indicator?
- if parser.buffer[parser.buffer_pos] == '?' && (parser.flow_level > 0 || is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_key(parser)
- }
-
- // Is it the value indicator?
- if parser.buffer[parser.buffer_pos] == ':' && (parser.flow_level > 0 || is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_value(parser)
- }
-
- // Is it an alias?
- if parser.buffer[parser.buffer_pos] == '*' {
- return yaml_parser_fetch_anchor(parser, yaml_ALIAS_TOKEN)
- }
-
- // Is it an anchor?
- if parser.buffer[parser.buffer_pos] == '&' {
- return yaml_parser_fetch_anchor(parser, yaml_ANCHOR_TOKEN)
- }
-
- // Is it a tag?
- if parser.buffer[parser.buffer_pos] == '!' {
- return yaml_parser_fetch_tag(parser)
- }
-
- // Is it a literal scalar?
- if parser.buffer[parser.buffer_pos] == '|' && parser.flow_level == 0 {
- return yaml_parser_fetch_block_scalar(parser, true)
- }
-
- // Is it a folded scalar?
- if parser.buffer[parser.buffer_pos] == '>' && parser.flow_level == 0 {
- return yaml_parser_fetch_block_scalar(parser, false)
- }
-
- // Is it a single-quoted scalar?
- if parser.buffer[parser.buffer_pos] == '\'' {
- return yaml_parser_fetch_flow_scalar(parser, true)
- }
-
- // Is it a double-quoted scalar?
- if parser.buffer[parser.buffer_pos] == '"' {
- return yaml_parser_fetch_flow_scalar(parser, false)
- }
-
- // Is it a plain scalar?
- //
- // A plain scalar may start with any non-blank characters except
- //
- // '-', '?', ':', ',', '[', ']', '{', '}',
- // '#', '&', '*', '!', '|', '>', '\'', '\"',
- // '%', '@', '`'.
- //
- // In the block context (and, for the '-' indicator, in the flow context
- // too), it may also start with the characters
- //
- // '-', '?', ':'
- //
- // if it is followed by a non-space character.
- //
- // The last rule is more restrictive than the specification requires.
- // [Go] TODO Make this logic more reasonable.
- //switch parser.buffer[parser.buffer_pos] {
- //case '-', '?', ':', ',', '?', '-', ',', ':', ']', '[', '}', '{', '&', '#', '!', '*', '>', '|', '"', '\'', '@', '%', '-', '`':
- //}
- if !(is_blankz(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == '-' ||
- parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == ':' ||
- parser.buffer[parser.buffer_pos] == ',' || parser.buffer[parser.buffer_pos] == '[' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '{' ||
- parser.buffer[parser.buffer_pos] == '}' || parser.buffer[parser.buffer_pos] == '#' ||
- parser.buffer[parser.buffer_pos] == '&' || parser.buffer[parser.buffer_pos] == '*' ||
- parser.buffer[parser.buffer_pos] == '!' || parser.buffer[parser.buffer_pos] == '|' ||
- parser.buffer[parser.buffer_pos] == '>' || parser.buffer[parser.buffer_pos] == '\'' ||
- parser.buffer[parser.buffer_pos] == '"' || parser.buffer[parser.buffer_pos] == '%' ||
- parser.buffer[parser.buffer_pos] == '@' || parser.buffer[parser.buffer_pos] == '`') ||
- (parser.buffer[parser.buffer_pos] == '-' && !is_blank(parser.buffer, parser.buffer_pos+1)) ||
- (parser.flow_level == 0 &&
- (parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == ':') &&
- !is_blankz(parser.buffer, parser.buffer_pos+1)) {
- return yaml_parser_fetch_plain_scalar(parser)
- }
-
- // If we don't determine the token type so far, it is an error.
- return yaml_parser_set_scanner_error(parser,
- "while scanning for the next token", parser.mark,
- "found character that cannot start any token")
-}
-
-func yaml_simple_key_is_valid(parser *yaml_parser_t, simple_key *yaml_simple_key_t) (valid, ok bool) {
- if !simple_key.possible {
- return false, true
- }
-
- // The 1.2 specification says:
- //
- // "If the ? indicator is omitted, parsing needs to see past the
- // implicit key to recognize it as such. To limit the amount of
- // lookahead required, the “:” indicator must appear at most 1024
- // Unicode characters beyond the start of the key. In addition, the key
- // is restricted to a single line."
- //
- if simple_key.mark.line < parser.mark.line || simple_key.mark.index+1024 < parser.mark.index {
- // Check if the potential simple key to be removed is required.
- if simple_key.required {
- return false, yaml_parser_set_scanner_error(parser,
- "while scanning a simple key", simple_key.mark,
- "could not find expected ':'")
- }
- simple_key.possible = false
- return false, true
- }
- return true, true
-}
-
-// Check if a simple key may start at the current position and add it if
-// needed.
-func yaml_parser_save_simple_key(parser *yaml_parser_t) bool {
- // A simple key is required at the current position if the scanner is in
- // the block context and the current column coincides with the indentation
- // level.
-
- required := parser.flow_level == 0 && parser.indent == parser.mark.column
-
- //
- // If the current position may start a simple key, save it.
- //
- if parser.simple_key_allowed {
- simple_key := yaml_simple_key_t{
- possible: true,
- required: required,
- token_number: parser.tokens_parsed + (len(parser.tokens) - parser.tokens_head),
- mark: parser.mark,
- }
-
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
- parser.simple_keys[len(parser.simple_keys)-1] = simple_key
- parser.simple_keys_by_tok[simple_key.token_number] = len(parser.simple_keys) - 1
- }
- return true
-}
-
-// Remove a potential simple key at the current flow level.
-func yaml_parser_remove_simple_key(parser *yaml_parser_t) bool {
- i := len(parser.simple_keys) - 1
- if parser.simple_keys[i].possible {
- // If the key is required, it is an error.
- if parser.simple_keys[i].required {
- return yaml_parser_set_scanner_error(parser,
- "while scanning a simple key", parser.simple_keys[i].mark,
- "could not find expected ':'")
- }
- // Remove the key from the stack.
- parser.simple_keys[i].possible = false
- delete(parser.simple_keys_by_tok, parser.simple_keys[i].token_number)
- }
- return true
-}
-
-// max_flow_level limits the flow_level
-const max_flow_level = 10000
-
-// Increase the flow level and resize the simple key list if needed.
-func yaml_parser_increase_flow_level(parser *yaml_parser_t) bool {
- // Reset the simple key on the next level.
- parser.simple_keys = append(parser.simple_keys, yaml_simple_key_t{
- possible: false,
- required: false,
- token_number: parser.tokens_parsed + (len(parser.tokens) - parser.tokens_head),
- mark: parser.mark,
- })
-
- // Increase the flow level.
- parser.flow_level++
- if parser.flow_level > max_flow_level {
- return yaml_parser_set_scanner_error(parser,
- "while increasing flow level", parser.simple_keys[len(parser.simple_keys)-1].mark,
- fmt.Sprintf("exceeded max depth of %d", max_flow_level))
- }
- return true
-}
-
-// Decrease the flow level.
-func yaml_parser_decrease_flow_level(parser *yaml_parser_t) bool {
- if parser.flow_level > 0 {
- parser.flow_level--
- last := len(parser.simple_keys) - 1
- delete(parser.simple_keys_by_tok, parser.simple_keys[last].token_number)
- parser.simple_keys = parser.simple_keys[:last]
- }
- return true
-}
-
-// max_indents limits the indents stack size
-const max_indents = 10000
-
-// Push the current indentation level to the stack and set the new level
-// the current column is greater than the indentation level. In this case,
-// append or insert the specified token into the token queue.
-func yaml_parser_roll_indent(parser *yaml_parser_t, column, number int, typ yaml_token_type_t, mark yaml_mark_t) bool {
- // In the flow context, do nothing.
- if parser.flow_level > 0 {
- return true
- }
-
- if parser.indent < column {
- // Push the current indentation level to the stack and set the new
- // indentation level.
- parser.indents = append(parser.indents, parser.indent)
- parser.indent = column
- if len(parser.indents) > max_indents {
- return yaml_parser_set_scanner_error(parser,
- "while increasing indent level", parser.simple_keys[len(parser.simple_keys)-1].mark,
- fmt.Sprintf("exceeded max depth of %d", max_indents))
- }
-
- // Create a token and insert it into the queue.
- token := yaml_token_t{
- typ: typ,
- start_mark: mark,
- end_mark: mark,
- }
- if number > -1 {
- number -= parser.tokens_parsed
- }
- yaml_insert_token(parser, number, &token)
- }
- return true
-}
-
-// Pop indentation levels from the indents stack until the current level
-// becomes less or equal to the column. For each indentation level, append
-// the BLOCK-END token.
-func yaml_parser_unroll_indent(parser *yaml_parser_t, column int, scan_mark yaml_mark_t) bool {
- // In the flow context, do nothing.
- if parser.flow_level > 0 {
- return true
- }
-
- block_mark := scan_mark
- block_mark.index--
-
- // Loop through the indentation levels in the stack.
- for parser.indent > column {
-
- // [Go] Reposition the end token before potential following
- // foot comments of parent blocks. For that, search
- // backwards for recent comments that were at the same
- // indent as the block that is ending now.
- stop_index := block_mark.index
- for i := len(parser.comments) - 1; i >= 0; i-- {
- comment := &parser.comments[i]
-
- if comment.end_mark.index < stop_index {
- // Don't go back beyond the start of the comment/whitespace scan, unless column < 0.
- // If requested indent column is < 0, then the document is over and everything else
- // is a foot anyway.
- break
- }
- if comment.start_mark.column == parser.indent+1 {
- // This is a good match. But maybe there's a former comment
- // at that same indent level, so keep searching.
- block_mark = comment.start_mark
- }
-
- // While the end of the former comment matches with
- // the start of the following one, we know there's
- // nothing in between and scanning is still safe.
- stop_index = comment.scan_mark.index
- }
-
- // Create a token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_BLOCK_END_TOKEN,
- start_mark: block_mark,
- end_mark: block_mark,
- }
- yaml_insert_token(parser, -1, &token)
-
- // Pop the indentation level.
- parser.indent = parser.indents[len(parser.indents)-1]
- parser.indents = parser.indents[:len(parser.indents)-1]
- }
- return true
-}
-
-// Initialize the scanner and produce the STREAM-START token.
-func yaml_parser_fetch_stream_start(parser *yaml_parser_t) bool {
-
- // Set the initial indentation.
- parser.indent = -1
-
- // Initialize the simple key stack.
- parser.simple_keys = append(parser.simple_keys, yaml_simple_key_t{})
-
- parser.simple_keys_by_tok = make(map[int]int)
-
- // A simple key is allowed at the beginning of the stream.
- parser.simple_key_allowed = true
-
- // We have started.
- parser.stream_start_produced = true
-
- // Create the STREAM-START token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_STREAM_START_TOKEN,
- start_mark: parser.mark,
- end_mark: parser.mark,
- encoding: parser.encoding,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the STREAM-END token and shut down the scanner.
-func yaml_parser_fetch_stream_end(parser *yaml_parser_t) bool {
-
- // Force new line.
- if parser.mark.column != 0 {
- parser.mark.column = 0
- parser.mark.line++
- }
-
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Create the STREAM-END token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_STREAM_END_TOKEN,
- start_mark: parser.mark,
- end_mark: parser.mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce a VERSION-DIRECTIVE or TAG-DIRECTIVE token.
-func yaml_parser_fetch_directive(parser *yaml_parser_t) bool {
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Create the YAML-DIRECTIVE or TAG-DIRECTIVE token.
- token := yaml_token_t{}
- if !yaml_parser_scan_directive(parser, &token) {
- return false
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the DOCUMENT-START or DOCUMENT-END token.
-func yaml_parser_fetch_document_indicator(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // Reset the indentation level.
- if !yaml_parser_unroll_indent(parser, -1, parser.mark) {
- return false
- }
-
- // Reset simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- parser.simple_key_allowed = false
-
- // Consume the token.
- start_mark := parser.mark
-
- skip(parser)
- skip(parser)
- skip(parser)
-
- end_mark := parser.mark
-
- // Create the DOCUMENT-START or DOCUMENT-END token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-SEQUENCE-START or FLOW-MAPPING-START token.
-func yaml_parser_fetch_flow_collection_start(parser *yaml_parser_t, typ yaml_token_type_t) bool {
-
- // The indicators '[' and '{' may start a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // Increase the flow level.
- if !yaml_parser_increase_flow_level(parser) {
- return false
- }
-
- // A simple key may follow the indicators '[' and '{'.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-SEQUENCE-START of FLOW-MAPPING-START token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-SEQUENCE-END or FLOW-MAPPING-END token.
-func yaml_parser_fetch_flow_collection_end(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // Reset any potential simple key on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Decrease the flow level.
- if !yaml_parser_decrease_flow_level(parser) {
- return false
- }
-
- // No simple keys after the indicators ']' and '}'.
- parser.simple_key_allowed = false
-
- // Consume the token.
-
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-SEQUENCE-END of FLOW-MAPPING-END token.
- token := yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- // Append the token to the queue.
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the FLOW-ENTRY token.
-func yaml_parser_fetch_flow_entry(parser *yaml_parser_t) bool {
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after ','.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the FLOW-ENTRY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_FLOW_ENTRY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the BLOCK-ENTRY token.
-func yaml_parser_fetch_block_entry(parser *yaml_parser_t) bool {
- // Check if the scanner is in the block context.
- if parser.flow_level == 0 {
- // Check if we are allowed to start a new entry.
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "block sequence entries are not allowed in this context")
- }
- // Add the BLOCK-SEQUENCE-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_SEQUENCE_START_TOKEN, parser.mark) {
- return false
- }
- } else {
- // It is an error for the '-' indicator to occur in the flow context,
- // but we let the Parser detect and report about it because the Parser
- // is able to point to the context.
- }
-
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after '-'.
- parser.simple_key_allowed = true
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the BLOCK-ENTRY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_BLOCK_ENTRY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the KEY token.
-func yaml_parser_fetch_key(parser *yaml_parser_t) bool {
-
- // In the block context, additional checks are required.
- if parser.flow_level == 0 {
- // Check if we are allowed to start a new key (not nessesary simple).
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "mapping keys are not allowed in this context")
- }
- // Add the BLOCK-MAPPING-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_MAPPING_START_TOKEN, parser.mark) {
- return false
- }
- }
-
- // Reset any potential simple keys on the current flow level.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // Simple keys are allowed after '?' in the block context.
- parser.simple_key_allowed = parser.flow_level == 0
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the KEY token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_KEY_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the VALUE token.
-func yaml_parser_fetch_value(parser *yaml_parser_t) bool {
-
- simple_key := &parser.simple_keys[len(parser.simple_keys)-1]
-
- // Have we found a simple key?
- if valid, ok := yaml_simple_key_is_valid(parser, simple_key); !ok {
- return false
-
- } else if valid {
-
- // Create the KEY token and insert it into the queue.
- token := yaml_token_t{
- typ: yaml_KEY_TOKEN,
- start_mark: simple_key.mark,
- end_mark: simple_key.mark,
- }
- yaml_insert_token(parser, simple_key.token_number-parser.tokens_parsed, &token)
-
- // In the block context, we may need to add the BLOCK-MAPPING-START token.
- if !yaml_parser_roll_indent(parser, simple_key.mark.column,
- simple_key.token_number,
- yaml_BLOCK_MAPPING_START_TOKEN, simple_key.mark) {
- return false
- }
-
- // Remove the simple key.
- simple_key.possible = false
- delete(parser.simple_keys_by_tok, simple_key.token_number)
-
- // A simple key cannot follow another simple key.
- parser.simple_key_allowed = false
-
- } else {
- // The ':' indicator follows a complex key.
-
- // In the block context, extra checks are required.
- if parser.flow_level == 0 {
-
- // Check if we are allowed to start a complex value.
- if !parser.simple_key_allowed {
- return yaml_parser_set_scanner_error(parser, "", parser.mark,
- "mapping values are not allowed in this context")
- }
-
- // Add the BLOCK-MAPPING-START token if needed.
- if !yaml_parser_roll_indent(parser, parser.mark.column, -1, yaml_BLOCK_MAPPING_START_TOKEN, parser.mark) {
- return false
- }
- }
-
- // Simple keys after ':' are allowed in the block context.
- parser.simple_key_allowed = parser.flow_level == 0
- }
-
- // Consume the token.
- start_mark := parser.mark
- skip(parser)
- end_mark := parser.mark
-
- // Create the VALUE token and append it to the queue.
- token := yaml_token_t{
- typ: yaml_VALUE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the ALIAS or ANCHOR token.
-func yaml_parser_fetch_anchor(parser *yaml_parser_t, typ yaml_token_type_t) bool {
- // An anchor or an alias could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow an anchor or an alias.
- parser.simple_key_allowed = false
-
- // Create the ALIAS or ANCHOR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_anchor(parser, &token, typ) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the TAG token.
-func yaml_parser_fetch_tag(parser *yaml_parser_t) bool {
- // A tag could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a tag.
- parser.simple_key_allowed = false
-
- // Create the TAG token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_tag(parser, &token) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,literal) or SCALAR(...,folded) tokens.
-func yaml_parser_fetch_block_scalar(parser *yaml_parser_t, literal bool) bool {
- // Remove any potential simple keys.
- if !yaml_parser_remove_simple_key(parser) {
- return false
- }
-
- // A simple key may follow a block scalar.
- parser.simple_key_allowed = true
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_block_scalar(parser, &token, literal) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,single-quoted) or SCALAR(...,double-quoted) tokens.
-func yaml_parser_fetch_flow_scalar(parser *yaml_parser_t, single bool) bool {
- // A plain scalar could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a flow scalar.
- parser.simple_key_allowed = false
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_flow_scalar(parser, &token, single) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Produce the SCALAR(...,plain) token.
-func yaml_parser_fetch_plain_scalar(parser *yaml_parser_t) bool {
- // A plain scalar could be a simple key.
- if !yaml_parser_save_simple_key(parser) {
- return false
- }
-
- // A simple key cannot follow a flow scalar.
- parser.simple_key_allowed = false
-
- // Create the SCALAR token and append it to the queue.
- var token yaml_token_t
- if !yaml_parser_scan_plain_scalar(parser, &token) {
- return false
- }
- yaml_insert_token(parser, -1, &token)
- return true
-}
-
-// Eat whitespaces and comments until the next token is found.
-func yaml_parser_scan_to_next_token(parser *yaml_parser_t) bool {
-
- scan_mark := parser.mark
-
- // Until the next token is not found.
- for {
- // Allow the BOM mark to start a line.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.mark.column == 0 && is_bom(parser.buffer, parser.buffer_pos) {
- skip(parser)
- }
-
- // Eat whitespaces.
- // Tabs are allowed:
- // - in the flow context
- // - in the block context, but not at the beginning of the line or
- // after '-', '?', or ':' (complex value).
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for parser.buffer[parser.buffer_pos] == ' ' || ((parser.flow_level > 0 || !parser.simple_key_allowed) && parser.buffer[parser.buffer_pos] == '\t') {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if we just had a line comment under a sequence entry that
- // looks more like a header to the following content. Similar to this:
- //
- // - # The comment
- // - Some data
- //
- // If so, transform the line comment to a head comment and reposition.
- if len(parser.comments) > 0 && len(parser.tokens) > 1 {
- tokenA := parser.tokens[len(parser.tokens)-2]
- tokenB := parser.tokens[len(parser.tokens)-1]
- comment := &parser.comments[len(parser.comments)-1]
- if tokenA.typ == yaml_BLOCK_SEQUENCE_START_TOKEN && tokenB.typ == yaml_BLOCK_ENTRY_TOKEN && len(comment.line) > 0 && !is_break(parser.buffer, parser.buffer_pos) {
- // If it was in the prior line, reposition so it becomes a
- // header of the follow up token. Otherwise, keep it in place
- // so it becomes a header of the former.
- comment.head = comment.line
- comment.line = nil
- if comment.start_mark.line == parser.mark.line-1 {
- comment.token_mark = parser.mark
- }
- }
- }
-
- // Eat a comment until a line break.
- if parser.buffer[parser.buffer_pos] == '#' {
- if !yaml_parser_scan_comments(parser, scan_mark) {
- return false
- }
- }
-
- // If it is a line break, eat it.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
-
- // In the block context, a new line may start a simple key.
- if parser.flow_level == 0 {
- parser.simple_key_allowed = true
- }
- } else {
- break // We have found a token.
- }
- }
-
- return true
-}
-
-// Scan a YAML-DIRECTIVE or TAG-DIRECTIVE token.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-//
-func yaml_parser_scan_directive(parser *yaml_parser_t, token *yaml_token_t) bool {
- // Eat '%'.
- start_mark := parser.mark
- skip(parser)
-
- // Scan the directive name.
- var name []byte
- if !yaml_parser_scan_directive_name(parser, start_mark, &name) {
- return false
- }
-
- // Is it a YAML directive?
- if bytes.Equal(name, []byte("YAML")) {
- // Scan the VERSION directive value.
- var major, minor int8
- if !yaml_parser_scan_version_directive_value(parser, start_mark, &major, &minor) {
- return false
- }
- end_mark := parser.mark
-
- // Create a VERSION-DIRECTIVE token.
- *token = yaml_token_t{
- typ: yaml_VERSION_DIRECTIVE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- major: major,
- minor: minor,
- }
-
- // Is it a TAG directive?
- } else if bytes.Equal(name, []byte("TAG")) {
- // Scan the TAG directive value.
- var handle, prefix []byte
- if !yaml_parser_scan_tag_directive_value(parser, start_mark, &handle, &prefix) {
- return false
- }
- end_mark := parser.mark
-
- // Create a TAG-DIRECTIVE token.
- *token = yaml_token_t{
- typ: yaml_TAG_DIRECTIVE_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: handle,
- prefix: prefix,
- }
-
- // Unknown directive.
- } else {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "found unknown directive name")
- return false
- }
-
- // Eat the rest of the line including any comments.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- if parser.buffer[parser.buffer_pos] == '#' {
- // [Go] Discard this inline comment for the time being.
- //if !yaml_parser_scan_line_comment(parser, start_mark) {
- // return false
- //}
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- }
-
- // Check if we are at the end of the line.
- if !is_breakz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "did not find expected comment or line break")
- return false
- }
-
- // Eat a line break.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- }
-
- return true
-}
-
-// Scan the directive name.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^
-//
-func yaml_parser_scan_directive_name(parser *yaml_parser_t, start_mark yaml_mark_t, name *[]byte) bool {
- // Consume the directive name.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- var s []byte
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the name is empty.
- if len(s) == 0 {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "could not find expected directive name")
- return false
- }
-
- // Check for an blank character after the name.
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a directive",
- start_mark, "found unexpected non-alphabetical character")
- return false
- }
- *name = s
- return true
-}
-
-// Scan the value of VERSION-DIRECTIVE.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^^^^^^
-func yaml_parser_scan_version_directive_value(parser *yaml_parser_t, start_mark yaml_mark_t, major, minor *int8) bool {
- // Eat whitespaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Consume the major version number.
- if !yaml_parser_scan_version_directive_number(parser, start_mark, major) {
- return false
- }
-
- // Eat '.'.
- if parser.buffer[parser.buffer_pos] != '.' {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "did not find expected digit or '.' character")
- }
-
- skip(parser)
-
- // Consume the minor version number.
- if !yaml_parser_scan_version_directive_number(parser, start_mark, minor) {
- return false
- }
- return true
-}
-
-const max_number_length = 2
-
-// Scan the version number of VERSION-DIRECTIVE.
-//
-// Scope:
-// %YAML 1.1 # a comment \n
-// ^
-// %YAML 1.1 # a comment \n
-// ^
-func yaml_parser_scan_version_directive_number(parser *yaml_parser_t, start_mark yaml_mark_t, number *int8) bool {
-
- // Repeat while the next character is digit.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- var value, length int8
- for is_digit(parser.buffer, parser.buffer_pos) {
- // Check if the number is too long.
- length++
- if length > max_number_length {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "found extremely long version number")
- }
- value = value*10 + int8(as_digit(parser.buffer, parser.buffer_pos))
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the number was present.
- if length == 0 {
- return yaml_parser_set_scanner_error(parser, "while scanning a %YAML directive",
- start_mark, "did not find expected version number")
- }
- *number = value
- return true
-}
-
-// Scan the value of a TAG-DIRECTIVE token.
-//
-// Scope:
-// %TAG !yaml! tag:yaml.org,2002: \n
-// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-//
-func yaml_parser_scan_tag_directive_value(parser *yaml_parser_t, start_mark yaml_mark_t, handle, prefix *[]byte) bool {
- var handle_value, prefix_value []byte
-
- // Eat whitespaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Scan a handle.
- if !yaml_parser_scan_tag_handle(parser, true, start_mark, &handle_value) {
- return false
- }
-
- // Expect a whitespace.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blank(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a %TAG directive",
- start_mark, "did not find expected whitespace")
- return false
- }
-
- // Eat whitespaces.
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Scan a prefix.
- if !yaml_parser_scan_tag_uri(parser, true, nil, start_mark, &prefix_value) {
- return false
- }
-
- // Expect a whitespace or line break.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a %TAG directive",
- start_mark, "did not find expected whitespace or line break")
- return false
- }
-
- *handle = handle_value
- *prefix = prefix_value
- return true
-}
-
-func yaml_parser_scan_anchor(parser *yaml_parser_t, token *yaml_token_t, typ yaml_token_type_t) bool {
- var s []byte
-
- // Eat the indicator character.
- start_mark := parser.mark
- skip(parser)
-
- // Consume the value.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- end_mark := parser.mark
-
- /*
- * Check if length of the anchor is greater than 0 and it is followed by
- * a whitespace character or one of the indicators:
- *
- * '?', ':', ',', ']', '}', '%', '@', '`'.
- */
-
- if len(s) == 0 ||
- !(is_blankz(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == '?' ||
- parser.buffer[parser.buffer_pos] == ':' || parser.buffer[parser.buffer_pos] == ',' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '}' ||
- parser.buffer[parser.buffer_pos] == '%' || parser.buffer[parser.buffer_pos] == '@' ||
- parser.buffer[parser.buffer_pos] == '`') {
- context := "while scanning an alias"
- if typ == yaml_ANCHOR_TOKEN {
- context = "while scanning an anchor"
- }
- yaml_parser_set_scanner_error(parser, context, start_mark,
- "did not find expected alphabetic or numeric character")
- return false
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: typ,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- }
-
- return true
-}
-
-/*
- * Scan a TAG token.
- */
-
-func yaml_parser_scan_tag(parser *yaml_parser_t, token *yaml_token_t) bool {
- var handle, suffix []byte
-
- start_mark := parser.mark
-
- // Check if the tag is in the canonical form.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- if parser.buffer[parser.buffer_pos+1] == '<' {
- // Keep the handle as ''
-
- // Eat '!<'
- skip(parser)
- skip(parser)
-
- // Consume the tag value.
- if !yaml_parser_scan_tag_uri(parser, false, nil, start_mark, &suffix) {
- return false
- }
-
- // Check for '>' and eat it.
- if parser.buffer[parser.buffer_pos] != '>' {
- yaml_parser_set_scanner_error(parser, "while scanning a tag",
- start_mark, "did not find the expected '>'")
- return false
- }
-
- skip(parser)
- } else {
- // The tag has either the '!suffix' or the '!handle!suffix' form.
-
- // First, try to scan a handle.
- if !yaml_parser_scan_tag_handle(parser, false, start_mark, &handle) {
- return false
- }
-
- // Check if it is, indeed, handle.
- if handle[0] == '!' && len(handle) > 1 && handle[len(handle)-1] == '!' {
- // Scan the suffix now.
- if !yaml_parser_scan_tag_uri(parser, false, nil, start_mark, &suffix) {
- return false
- }
- } else {
- // It wasn't a handle after all. Scan the rest of the tag.
- if !yaml_parser_scan_tag_uri(parser, false, handle, start_mark, &suffix) {
- return false
- }
-
- // Set the handle to '!'.
- handle = []byte{'!'}
-
- // A special case: the '!' tag. Set the handle to '' and the
- // suffix to '!'.
- if len(suffix) == 0 {
- handle, suffix = suffix, handle
- }
- }
- }
-
- // Check the character which ends the tag.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if !is_blankz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a tag",
- start_mark, "did not find expected whitespace or line break")
- return false
- }
-
- end_mark := parser.mark
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_TAG_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: handle,
- suffix: suffix,
- }
- return true
-}
-
-// Scan a tag handle.
-func yaml_parser_scan_tag_handle(parser *yaml_parser_t, directive bool, start_mark yaml_mark_t, handle *[]byte) bool {
- // Check the initial '!' character.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.buffer[parser.buffer_pos] != '!' {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected '!'")
- return false
- }
-
- var s []byte
-
- // Copy the '!' character.
- s = read(parser, s)
-
- // Copy all subsequent alphabetical and numerical characters.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_alpha(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check if the trailing character is '!' and copy it.
- if parser.buffer[parser.buffer_pos] == '!' {
- s = read(parser, s)
- } else {
- // It's either the '!' tag or not really a tag handle. If it's a %TAG
- // directive, it's an error. If it's a tag token, it must be a part of URI.
- if directive && string(s) != "!" {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected '!'")
- return false
- }
- }
-
- *handle = s
- return true
-}
-
-// Scan a tag.
-func yaml_parser_scan_tag_uri(parser *yaml_parser_t, directive bool, head []byte, start_mark yaml_mark_t, uri *[]byte) bool {
- //size_t length = head ? strlen((char *)head) : 0
- var s []byte
- hasTag := len(head) > 0
-
- // Copy the head if needed.
- //
- // Note that we don't copy the leading '!' character.
- if len(head) > 1 {
- s = append(s, head[1:]...)
- }
-
- // Scan the tag.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // The set of characters that may appear in URI is as follows:
- //
- // '0'-'9', 'A'-'Z', 'a'-'z', '_', '-', ';', '/', '?', ':', '@', '&',
- // '=', '+', '$', ',', '.', '!', '~', '*', '\'', '(', ')', '[', ']',
- // '%'.
- // [Go] TODO Convert this into more reasonable logic.
- for is_alpha(parser.buffer, parser.buffer_pos) || parser.buffer[parser.buffer_pos] == ';' ||
- parser.buffer[parser.buffer_pos] == '/' || parser.buffer[parser.buffer_pos] == '?' ||
- parser.buffer[parser.buffer_pos] == ':' || parser.buffer[parser.buffer_pos] == '@' ||
- parser.buffer[parser.buffer_pos] == '&' || parser.buffer[parser.buffer_pos] == '=' ||
- parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '$' ||
- parser.buffer[parser.buffer_pos] == ',' || parser.buffer[parser.buffer_pos] == '.' ||
- parser.buffer[parser.buffer_pos] == '!' || parser.buffer[parser.buffer_pos] == '~' ||
- parser.buffer[parser.buffer_pos] == '*' || parser.buffer[parser.buffer_pos] == '\'' ||
- parser.buffer[parser.buffer_pos] == '(' || parser.buffer[parser.buffer_pos] == ')' ||
- parser.buffer[parser.buffer_pos] == '[' || parser.buffer[parser.buffer_pos] == ']' ||
- parser.buffer[parser.buffer_pos] == '%' {
- // Check if it is a URI-escape sequence.
- if parser.buffer[parser.buffer_pos] == '%' {
- if !yaml_parser_scan_uri_escapes(parser, directive, start_mark, &s) {
- return false
- }
- } else {
- s = read(parser, s)
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- hasTag = true
- }
-
- if !hasTag {
- yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find expected tag URI")
- return false
- }
- *uri = s
- return true
-}
-
-// Decode an URI-escape sequence corresponding to a single UTF-8 character.
-func yaml_parser_scan_uri_escapes(parser *yaml_parser_t, directive bool, start_mark yaml_mark_t, s *[]byte) bool {
-
- // Decode the required number of characters.
- w := 1024
- for w > 0 {
- // Check for a URI-escaped octet.
- if parser.unread < 3 && !yaml_parser_update_buffer(parser, 3) {
- return false
- }
-
- if !(parser.buffer[parser.buffer_pos] == '%' &&
- is_hex(parser.buffer, parser.buffer_pos+1) &&
- is_hex(parser.buffer, parser.buffer_pos+2)) {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "did not find URI escaped octet")
- }
-
- // Get the octet.
- octet := byte((as_hex(parser.buffer, parser.buffer_pos+1) << 4) + as_hex(parser.buffer, parser.buffer_pos+2))
-
- // If it is the leading octet, determine the length of the UTF-8 sequence.
- if w == 1024 {
- w = width(octet)
- if w == 0 {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "found an incorrect leading UTF-8 octet")
- }
- } else {
- // Check if the trailing octet is correct.
- if octet&0xC0 != 0x80 {
- return yaml_parser_set_scanner_tag_error(parser, directive,
- start_mark, "found an incorrect trailing UTF-8 octet")
- }
- }
-
- // Copy the octet and move the pointers.
- *s = append(*s, octet)
- skip(parser)
- skip(parser)
- skip(parser)
- w--
- }
- return true
-}
-
-// Scan a block scalar.
-func yaml_parser_scan_block_scalar(parser *yaml_parser_t, token *yaml_token_t, literal bool) bool {
- // Eat the indicator '|' or '>'.
- start_mark := parser.mark
- skip(parser)
-
- // Scan the additional block scalar indicators.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check for a chomping indicator.
- var chomping, increment int
- if parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '-' {
- // Set the chomping method and eat the indicator.
- if parser.buffer[parser.buffer_pos] == '+' {
- chomping = +1
- } else {
- chomping = -1
- }
- skip(parser)
-
- // Check for an indentation indicator.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_digit(parser.buffer, parser.buffer_pos) {
- // Check that the indentation is greater than 0.
- if parser.buffer[parser.buffer_pos] == '0' {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found an indentation indicator equal to 0")
- return false
- }
-
- // Get the indentation level and eat the indicator.
- increment = as_digit(parser.buffer, parser.buffer_pos)
- skip(parser)
- }
-
- } else if is_digit(parser.buffer, parser.buffer_pos) {
- // Do the same as above, but in the opposite order.
-
- if parser.buffer[parser.buffer_pos] == '0' {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found an indentation indicator equal to 0")
- return false
- }
- increment = as_digit(parser.buffer, parser.buffer_pos)
- skip(parser)
-
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if parser.buffer[parser.buffer_pos] == '+' || parser.buffer[parser.buffer_pos] == '-' {
- if parser.buffer[parser.buffer_pos] == '+' {
- chomping = +1
- } else {
- chomping = -1
- }
- skip(parser)
- }
- }
-
- // Eat whitespaces and comments to the end of the line.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for is_blank(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- if parser.buffer[parser.buffer_pos] == '#' {
- if !yaml_parser_scan_line_comment(parser, start_mark) {
- return false
- }
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- }
-
- // Check if we are at the end of the line.
- if !is_breakz(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "did not find expected comment or line break")
- return false
- }
-
- // Eat a line break.
- if is_break(parser.buffer, parser.buffer_pos) {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- }
-
- end_mark := parser.mark
-
- // Set the indentation level if it was specified.
- var indent int
- if increment > 0 {
- if parser.indent >= 0 {
- indent = parser.indent + increment
- } else {
- indent = increment
- }
- }
-
- // Scan the leading line breaks and determine the indentation level if needed.
- var s, leading_break, trailing_breaks []byte
- if !yaml_parser_scan_block_scalar_breaks(parser, &indent, &trailing_breaks, start_mark, &end_mark) {
- return false
- }
-
- // Scan the block scalar content.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- var leading_blank, trailing_blank bool
- for parser.mark.column == indent && !is_z(parser.buffer, parser.buffer_pos) {
- // We are at the beginning of a non-empty line.
-
- // Is it a trailing whitespace?
- trailing_blank = is_blank(parser.buffer, parser.buffer_pos)
-
- // Check if we need to fold the leading line break.
- if !literal && !leading_blank && !trailing_blank && len(leading_break) > 0 && leading_break[0] == '\n' {
- // Do we need to join the lines by space?
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- }
- } else {
- s = append(s, leading_break...)
- }
- leading_break = leading_break[:0]
-
- // Append the remaining line breaks.
- s = append(s, trailing_breaks...)
- trailing_breaks = trailing_breaks[:0]
-
- // Is it a leading whitespace?
- leading_blank = is_blank(parser.buffer, parser.buffer_pos)
-
- // Consume the current line.
- for !is_breakz(parser.buffer, parser.buffer_pos) {
- s = read(parser, s)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Consume the line break.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- leading_break = read_line(parser, leading_break)
-
- // Eat the following indentation spaces and line breaks.
- if !yaml_parser_scan_block_scalar_breaks(parser, &indent, &trailing_breaks, start_mark, &end_mark) {
- return false
- }
- }
-
- // Chomp the tail.
- if chomping != -1 {
- s = append(s, leading_break...)
- }
- if chomping == 1 {
- s = append(s, trailing_breaks...)
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_LITERAL_SCALAR_STYLE,
- }
- if !literal {
- token.style = yaml_FOLDED_SCALAR_STYLE
- }
- return true
-}
-
-// Scan indentation spaces and line breaks for a block scalar. Determine the
-// indentation level if needed.
-func yaml_parser_scan_block_scalar_breaks(parser *yaml_parser_t, indent *int, breaks *[]byte, start_mark yaml_mark_t, end_mark *yaml_mark_t) bool {
- *end_mark = parser.mark
-
- // Eat the indentation spaces and line breaks.
- max_indent := 0
- for {
- // Eat the indentation spaces.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- for (*indent == 0 || parser.mark.column < *indent) && is_space(parser.buffer, parser.buffer_pos) {
- skip(parser)
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
- if parser.mark.column > max_indent {
- max_indent = parser.mark.column
- }
-
- // Check for a tab character messing the indentation.
- if (*indent == 0 || parser.mark.column < *indent) && is_tab(parser.buffer, parser.buffer_pos) {
- return yaml_parser_set_scanner_error(parser, "while scanning a block scalar",
- start_mark, "found a tab character where an indentation space is expected")
- }
-
- // Have we found a non-empty line?
- if !is_break(parser.buffer, parser.buffer_pos) {
- break
- }
-
- // Consume the line break.
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- // [Go] Should really be returning breaks instead.
- *breaks = read_line(parser, *breaks)
- *end_mark = parser.mark
- }
-
- // Determine the indentation level if needed.
- if *indent == 0 {
- *indent = max_indent
- if *indent < parser.indent+1 {
- *indent = parser.indent + 1
- }
- if *indent < 1 {
- *indent = 1
- }
- }
- return true
-}
-
-// Scan a quoted scalar.
-func yaml_parser_scan_flow_scalar(parser *yaml_parser_t, token *yaml_token_t, single bool) bool {
- // Eat the left quote.
- start_mark := parser.mark
- skip(parser)
-
- // Consume the content of the quoted scalar.
- var s, leading_break, trailing_breaks, whitespaces []byte
- for {
- // Check that there are no document indicators at the beginning of the line.
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
-
- if parser.mark.column == 0 &&
- ((parser.buffer[parser.buffer_pos+0] == '-' &&
- parser.buffer[parser.buffer_pos+1] == '-' &&
- parser.buffer[parser.buffer_pos+2] == '-') ||
- (parser.buffer[parser.buffer_pos+0] == '.' &&
- parser.buffer[parser.buffer_pos+1] == '.' &&
- parser.buffer[parser.buffer_pos+2] == '.')) &&
- is_blankz(parser.buffer, parser.buffer_pos+3) {
- yaml_parser_set_scanner_error(parser, "while scanning a quoted scalar",
- start_mark, "found unexpected document indicator")
- return false
- }
-
- // Check for EOF.
- if is_z(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a quoted scalar",
- start_mark, "found unexpected end of stream")
- return false
- }
-
- // Consume non-blank characters.
- leading_blanks := false
- for !is_blankz(parser.buffer, parser.buffer_pos) {
- if single && parser.buffer[parser.buffer_pos] == '\'' && parser.buffer[parser.buffer_pos+1] == '\'' {
- // Is is an escaped single quote.
- s = append(s, '\'')
- skip(parser)
- skip(parser)
-
- } else if single && parser.buffer[parser.buffer_pos] == '\'' {
- // It is a right single quote.
- break
- } else if !single && parser.buffer[parser.buffer_pos] == '"' {
- // It is a right double quote.
- break
-
- } else if !single && parser.buffer[parser.buffer_pos] == '\\' && is_break(parser.buffer, parser.buffer_pos+1) {
- // It is an escaped line break.
- if parser.unread < 3 && !yaml_parser_update_buffer(parser, 3) {
- return false
- }
- skip(parser)
- skip_line(parser)
- leading_blanks = true
- break
-
- } else if !single && parser.buffer[parser.buffer_pos] == '\\' {
- // It is an escape sequence.
- code_length := 0
-
- // Check the escape character.
- switch parser.buffer[parser.buffer_pos+1] {
- case '0':
- s = append(s, 0)
- case 'a':
- s = append(s, '\x07')
- case 'b':
- s = append(s, '\x08')
- case 't', '\t':
- s = append(s, '\x09')
- case 'n':
- s = append(s, '\x0A')
- case 'v':
- s = append(s, '\x0B')
- case 'f':
- s = append(s, '\x0C')
- case 'r':
- s = append(s, '\x0D')
- case 'e':
- s = append(s, '\x1B')
- case ' ':
- s = append(s, '\x20')
- case '"':
- s = append(s, '"')
- case '\'':
- s = append(s, '\'')
- case '\\':
- s = append(s, '\\')
- case 'N': // NEL (#x85)
- s = append(s, '\xC2')
- s = append(s, '\x85')
- case '_': // #xA0
- s = append(s, '\xC2')
- s = append(s, '\xA0')
- case 'L': // LS (#x2028)
- s = append(s, '\xE2')
- s = append(s, '\x80')
- s = append(s, '\xA8')
- case 'P': // PS (#x2029)
- s = append(s, '\xE2')
- s = append(s, '\x80')
- s = append(s, '\xA9')
- case 'x':
- code_length = 2
- case 'u':
- code_length = 4
- case 'U':
- code_length = 8
- default:
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "found unknown escape character")
- return false
- }
-
- skip(parser)
- skip(parser)
-
- // Consume an arbitrary escape code.
- if code_length > 0 {
- var value int
-
- // Scan the character value.
- if parser.unread < code_length && !yaml_parser_update_buffer(parser, code_length) {
- return false
- }
- for k := 0; k < code_length; k++ {
- if !is_hex(parser.buffer, parser.buffer_pos+k) {
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "did not find expected hexdecimal number")
- return false
- }
- value = (value << 4) + as_hex(parser.buffer, parser.buffer_pos+k)
- }
-
- // Check the value and write the character.
- if (value >= 0xD800 && value <= 0xDFFF) || value > 0x10FFFF {
- yaml_parser_set_scanner_error(parser, "while parsing a quoted scalar",
- start_mark, "found invalid Unicode character escape code")
- return false
- }
- if value <= 0x7F {
- s = append(s, byte(value))
- } else if value <= 0x7FF {
- s = append(s, byte(0xC0+(value>>6)))
- s = append(s, byte(0x80+(value&0x3F)))
- } else if value <= 0xFFFF {
- s = append(s, byte(0xE0+(value>>12)))
- s = append(s, byte(0x80+((value>>6)&0x3F)))
- s = append(s, byte(0x80+(value&0x3F)))
- } else {
- s = append(s, byte(0xF0+(value>>18)))
- s = append(s, byte(0x80+((value>>12)&0x3F)))
- s = append(s, byte(0x80+((value>>6)&0x3F)))
- s = append(s, byte(0x80+(value&0x3F)))
- }
-
- // Advance the pointer.
- for k := 0; k < code_length; k++ {
- skip(parser)
- }
- }
- } else {
- // It is a non-escaped non-blank character.
- s = read(parser, s)
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- }
-
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- // Check if we are at the end of the scalar.
- if single {
- if parser.buffer[parser.buffer_pos] == '\'' {
- break
- }
- } else {
- if parser.buffer[parser.buffer_pos] == '"' {
- break
- }
- }
-
- // Consume blank characters.
- for is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos) {
- if is_blank(parser.buffer, parser.buffer_pos) {
- // Consume a space or a tab character.
- if !leading_blanks {
- whitespaces = read(parser, whitespaces)
- } else {
- skip(parser)
- }
- } else {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- // Check if it is a first line break.
- if !leading_blanks {
- whitespaces = whitespaces[:0]
- leading_break = read_line(parser, leading_break)
- leading_blanks = true
- } else {
- trailing_breaks = read_line(parser, trailing_breaks)
- }
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Join the whitespaces or fold line breaks.
- if leading_blanks {
- // Do we need to fold line breaks?
- if len(leading_break) > 0 && leading_break[0] == '\n' {
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- } else {
- s = append(s, trailing_breaks...)
- }
- } else {
- s = append(s, leading_break...)
- s = append(s, trailing_breaks...)
- }
- trailing_breaks = trailing_breaks[:0]
- leading_break = leading_break[:0]
- } else {
- s = append(s, whitespaces...)
- whitespaces = whitespaces[:0]
- }
- }
-
- // Eat the right quote.
- skip(parser)
- end_mark := parser.mark
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_SINGLE_QUOTED_SCALAR_STYLE,
- }
- if !single {
- token.style = yaml_DOUBLE_QUOTED_SCALAR_STYLE
- }
- return true
-}
-
-// Scan a plain scalar.
-func yaml_parser_scan_plain_scalar(parser *yaml_parser_t, token *yaml_token_t) bool {
-
- var s, leading_break, trailing_breaks, whitespaces []byte
- var leading_blanks bool
- var indent = parser.indent + 1
-
- start_mark := parser.mark
- end_mark := parser.mark
-
- // Consume the content of the plain scalar.
- for {
- // Check for a document indicator.
- if parser.unread < 4 && !yaml_parser_update_buffer(parser, 4) {
- return false
- }
- if parser.mark.column == 0 &&
- ((parser.buffer[parser.buffer_pos+0] == '-' &&
- parser.buffer[parser.buffer_pos+1] == '-' &&
- parser.buffer[parser.buffer_pos+2] == '-') ||
- (parser.buffer[parser.buffer_pos+0] == '.' &&
- parser.buffer[parser.buffer_pos+1] == '.' &&
- parser.buffer[parser.buffer_pos+2] == '.')) &&
- is_blankz(parser.buffer, parser.buffer_pos+3) {
- break
- }
-
- // Check for a comment.
- if parser.buffer[parser.buffer_pos] == '#' {
- break
- }
-
- // Consume non-blank characters.
- for !is_blankz(parser.buffer, parser.buffer_pos) {
-
- // Check for indicators that may end a plain scalar.
- if (parser.buffer[parser.buffer_pos] == ':' && is_blankz(parser.buffer, parser.buffer_pos+1)) ||
- (parser.flow_level > 0 &&
- (parser.buffer[parser.buffer_pos] == ',' ||
- parser.buffer[parser.buffer_pos] == '?' || parser.buffer[parser.buffer_pos] == '[' ||
- parser.buffer[parser.buffer_pos] == ']' || parser.buffer[parser.buffer_pos] == '{' ||
- parser.buffer[parser.buffer_pos] == '}')) {
- break
- }
-
- // Check if we need to join whitespaces and breaks.
- if leading_blanks || len(whitespaces) > 0 {
- if leading_blanks {
- // Do we need to fold line breaks?
- if leading_break[0] == '\n' {
- if len(trailing_breaks) == 0 {
- s = append(s, ' ')
- } else {
- s = append(s, trailing_breaks...)
- }
- } else {
- s = append(s, leading_break...)
- s = append(s, trailing_breaks...)
- }
- trailing_breaks = trailing_breaks[:0]
- leading_break = leading_break[:0]
- leading_blanks = false
- } else {
- s = append(s, whitespaces...)
- whitespaces = whitespaces[:0]
- }
- }
-
- // Copy the character.
- s = read(parser, s)
-
- end_mark = parser.mark
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- }
-
- // Is it the end?
- if !(is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos)) {
- break
- }
-
- // Consume blank characters.
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
-
- for is_blank(parser.buffer, parser.buffer_pos) || is_break(parser.buffer, parser.buffer_pos) {
- if is_blank(parser.buffer, parser.buffer_pos) {
-
- // Check for tab characters that abuse indentation.
- if leading_blanks && parser.mark.column < indent && is_tab(parser.buffer, parser.buffer_pos) {
- yaml_parser_set_scanner_error(parser, "while scanning a plain scalar",
- start_mark, "found a tab character that violates indentation")
- return false
- }
-
- // Consume a space or a tab character.
- if !leading_blanks {
- whitespaces = read(parser, whitespaces)
- } else {
- skip(parser)
- }
- } else {
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
-
- // Check if it is a first line break.
- if !leading_blanks {
- whitespaces = whitespaces[:0]
- leading_break = read_line(parser, leading_break)
- leading_blanks = true
- } else {
- trailing_breaks = read_line(parser, trailing_breaks)
- }
- }
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- }
-
- // Check indentation level.
- if parser.flow_level == 0 && parser.mark.column < indent {
- break
- }
- }
-
- // Create a token.
- *token = yaml_token_t{
- typ: yaml_SCALAR_TOKEN,
- start_mark: start_mark,
- end_mark: end_mark,
- value: s,
- style: yaml_PLAIN_SCALAR_STYLE,
- }
-
- // Note that we change the 'simple_key_allowed' flag.
- if leading_blanks {
- parser.simple_key_allowed = true
- }
- return true
-}
-
-func yaml_parser_scan_line_comment(parser *yaml_parser_t, token_mark yaml_mark_t) bool {
- if parser.newlines > 0 {
- return true
- }
-
- var start_mark yaml_mark_t
- var text []byte
-
- for peek := 0; peek < 512; peek++ {
- if parser.unread < peek+1 && !yaml_parser_update_buffer(parser, peek+1) {
- break
- }
- if is_blank(parser.buffer, parser.buffer_pos+peek) {
- continue
- }
- if parser.buffer[parser.buffer_pos+peek] == '#' {
- seen := parser.mark.index+peek
- for {
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_breakz(parser.buffer, parser.buffer_pos) {
- if parser.mark.index >= seen {
- break
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- } else if parser.mark.index >= seen {
- if len(text) == 0 {
- start_mark = parser.mark
- }
- text = read(parser, text)
- } else {
- skip(parser)
- }
- }
- }
- break
- }
- if len(text) > 0 {
- parser.comments = append(parser.comments, yaml_comment_t{
- token_mark: token_mark,
- start_mark: start_mark,
- line: text,
- })
- }
- return true
-}
-
-func yaml_parser_scan_comments(parser *yaml_parser_t, scan_mark yaml_mark_t) bool {
- token := parser.tokens[len(parser.tokens)-1]
-
- if token.typ == yaml_FLOW_ENTRY_TOKEN && len(parser.tokens) > 1 {
- token = parser.tokens[len(parser.tokens)-2]
- }
-
- var token_mark = token.start_mark
- var start_mark yaml_mark_t
- var next_indent = parser.indent
- if next_indent < 0 {
- next_indent = 0
- }
-
- var recent_empty = false
- var first_empty = parser.newlines <= 1
-
- var line = parser.mark.line
- var column = parser.mark.column
-
- var text []byte
-
- // The foot line is the place where a comment must start to
- // still be considered as a foot of the prior content.
- // If there's some content in the currently parsed line, then
- // the foot is the line below it.
- var foot_line = -1
- if scan_mark.line > 0 {
- foot_line = parser.mark.line-parser.newlines+1
- if parser.newlines == 0 && parser.mark.column > 1 {
- foot_line++
- }
- }
-
- var peek = 0
- for ; peek < 512; peek++ {
- if parser.unread < peek+1 && !yaml_parser_update_buffer(parser, peek+1) {
- break
- }
- column++
- if is_blank(parser.buffer, parser.buffer_pos+peek) {
- continue
- }
- c := parser.buffer[parser.buffer_pos+peek]
- var close_flow = parser.flow_level > 0 && (c == ']' || c == '}')
- if close_flow || is_breakz(parser.buffer, parser.buffer_pos+peek) {
- // Got line break or terminator.
- if close_flow || !recent_empty {
- if close_flow || first_empty && (start_mark.line == foot_line && token.typ != yaml_VALUE_TOKEN || start_mark.column-1 < next_indent) {
- // This is the first empty line and there were no empty lines before,
- // so this initial part of the comment is a foot of the prior token
- // instead of being a head for the following one. Split it up.
- // Alternatively, this might also be the last comment inside a flow
- // scope, so it must be a footer.
- if len(text) > 0 {
- if start_mark.column-1 < next_indent {
- // If dedented it's unrelated to the prior token.
- token_mark = start_mark
- }
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: token_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek, line, column},
- foot: text,
- })
- scan_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- token_mark = scan_mark
- text = nil
- }
- } else {
- if len(text) > 0 && parser.buffer[parser.buffer_pos+peek] != 0 {
- text = append(text, '\n')
- }
- }
- }
- if !is_break(parser.buffer, parser.buffer_pos+peek) {
- break
- }
- first_empty = false
- recent_empty = true
- column = 0
- line++
- continue
- }
-
- if len(text) > 0 && (close_flow || column-1 < next_indent && column != start_mark.column) {
- // The comment at the different indentation is a foot of the
- // preceding data rather than a head of the upcoming one.
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: token_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek, line, column},
- foot: text,
- })
- scan_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- token_mark = scan_mark
- text = nil
- }
-
- if parser.buffer[parser.buffer_pos+peek] != '#' {
- break
- }
-
- if len(text) == 0 {
- start_mark = yaml_mark_t{parser.mark.index + peek, line, column}
- } else {
- text = append(text, '\n')
- }
-
- recent_empty = false
-
- // Consume until after the consumed comment line.
- seen := parser.mark.index+peek
- for {
- if parser.unread < 1 && !yaml_parser_update_buffer(parser, 1) {
- return false
- }
- if is_breakz(parser.buffer, parser.buffer_pos) {
- if parser.mark.index >= seen {
- break
- }
- if parser.unread < 2 && !yaml_parser_update_buffer(parser, 2) {
- return false
- }
- skip_line(parser)
- } else if parser.mark.index >= seen {
- text = read(parser, text)
- } else {
- skip(parser)
- }
- }
-
- peek = 0
- column = 0
- line = parser.mark.line
- next_indent = parser.indent
- if next_indent < 0 {
- next_indent = 0
- }
- }
-
- if len(text) > 0 {
- parser.comments = append(parser.comments, yaml_comment_t{
- scan_mark: scan_mark,
- token_mark: start_mark,
- start_mark: start_mark,
- end_mark: yaml_mark_t{parser.mark.index + peek - 1, line, column},
- head: text,
- })
- }
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/sorter.go b/sesh/vendor/gopkg.in/yaml.v3/sorter.go
deleted file mode 100644
index 9210ece..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/sorter.go
+++ /dev/null
@@ -1,134 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-package yaml
-
-import (
- "reflect"
- "unicode"
-)
-
-type keyList []reflect.Value
-
-func (l keyList) Len() int { return len(l) }
-func (l keyList) Swap(i, j int) { l[i], l[j] = l[j], l[i] }
-func (l keyList) Less(i, j int) bool {
- a := l[i]
- b := l[j]
- ak := a.Kind()
- bk := b.Kind()
- for (ak == reflect.Interface || ak == reflect.Ptr) && !a.IsNil() {
- a = a.Elem()
- ak = a.Kind()
- }
- for (bk == reflect.Interface || bk == reflect.Ptr) && !b.IsNil() {
- b = b.Elem()
- bk = b.Kind()
- }
- af, aok := keyFloat(a)
- bf, bok := keyFloat(b)
- if aok && bok {
- if af != bf {
- return af < bf
- }
- if ak != bk {
- return ak < bk
- }
- return numLess(a, b)
- }
- if ak != reflect.String || bk != reflect.String {
- return ak < bk
- }
- ar, br := []rune(a.String()), []rune(b.String())
- digits := false
- for i := 0; i < len(ar) && i < len(br); i++ {
- if ar[i] == br[i] {
- digits = unicode.IsDigit(ar[i])
- continue
- }
- al := unicode.IsLetter(ar[i])
- bl := unicode.IsLetter(br[i])
- if al && bl {
- return ar[i] < br[i]
- }
- if al || bl {
- if digits {
- return al
- } else {
- return bl
- }
- }
- var ai, bi int
- var an, bn int64
- if ar[i] == '0' || br[i] == '0' {
- for j := i - 1; j >= 0 && unicode.IsDigit(ar[j]); j-- {
- if ar[j] != '0' {
- an = 1
- bn = 1
- break
- }
- }
- }
- for ai = i; ai < len(ar) && unicode.IsDigit(ar[ai]); ai++ {
- an = an*10 + int64(ar[ai]-'0')
- }
- for bi = i; bi < len(br) && unicode.IsDigit(br[bi]); bi++ {
- bn = bn*10 + int64(br[bi]-'0')
- }
- if an != bn {
- return an < bn
- }
- if ai != bi {
- return ai < bi
- }
- return ar[i] < br[i]
- }
- return len(ar) < len(br)
-}
-
-// keyFloat returns a float value for v if it is a number/bool
-// and whether it is a number/bool or not.
-func keyFloat(v reflect.Value) (f float64, ok bool) {
- switch v.Kind() {
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return float64(v.Int()), true
- case reflect.Float32, reflect.Float64:
- return v.Float(), true
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return float64(v.Uint()), true
- case reflect.Bool:
- if v.Bool() {
- return 1, true
- }
- return 0, true
- }
- return 0, false
-}
-
-// numLess returns whether a < b.
-// a and b must necessarily have the same kind.
-func numLess(a, b reflect.Value) bool {
- switch a.Kind() {
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return a.Int() < b.Int()
- case reflect.Float32, reflect.Float64:
- return a.Float() < b.Float()
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return a.Uint() < b.Uint()
- case reflect.Bool:
- return !a.Bool() && b.Bool()
- }
- panic("not a number")
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/writerc.go b/sesh/vendor/gopkg.in/yaml.v3/writerc.go
deleted file mode 100644
index b8a116b..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/writerc.go
+++ /dev/null
@@ -1,48 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-// Set the writer error and return false.
-func yaml_emitter_set_writer_error(emitter *yaml_emitter_t, problem string) bool {
- emitter.error = yaml_WRITER_ERROR
- emitter.problem = problem
- return false
-}
-
-// Flush the output buffer.
-func yaml_emitter_flush(emitter *yaml_emitter_t) bool {
- if emitter.write_handler == nil {
- panic("write handler not set")
- }
-
- // Check if the buffer is empty.
- if emitter.buffer_pos == 0 {
- return true
- }
-
- if err := emitter.write_handler(emitter, emitter.buffer[:emitter.buffer_pos]); err != nil {
- return yaml_emitter_set_writer_error(emitter, "write error: "+err.Error())
- }
- emitter.buffer_pos = 0
- return true
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yaml.go b/sesh/vendor/gopkg.in/yaml.v3/yaml.go
deleted file mode 100644
index 8cec6da..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yaml.go
+++ /dev/null
@@ -1,698 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-// Package yaml implements YAML support for the Go language.
-//
-// Source code and other details for the project are available at GitHub:
-//
-// https://github.com/go-yaml/yaml
-//
-package yaml
-
-import (
- "errors"
- "fmt"
- "io"
- "reflect"
- "strings"
- "sync"
- "unicode/utf8"
-)
-
-// The Unmarshaler interface may be implemented by types to customize their
-// behavior when being unmarshaled from a YAML document.
-type Unmarshaler interface {
- UnmarshalYAML(value *Node) error
-}
-
-type obsoleteUnmarshaler interface {
- UnmarshalYAML(unmarshal func(interface{}) error) error
-}
-
-// The Marshaler interface may be implemented by types to customize their
-// behavior when being marshaled into a YAML document. The returned value
-// is marshaled in place of the original value implementing Marshaler.
-//
-// If an error is returned by MarshalYAML, the marshaling procedure stops
-// and returns with the provided error.
-type Marshaler interface {
- MarshalYAML() (interface{}, error)
-}
-
-// Unmarshal decodes the first document found within the in byte slice
-// and assigns decoded values into the out value.
-//
-// Maps and pointers (to a struct, string, int, etc) are accepted as out
-// values. If an internal pointer within a struct is not initialized,
-// the yaml package will initialize it if necessary for unmarshalling
-// the provided data. The out parameter must not be nil.
-//
-// The type of the decoded values should be compatible with the respective
-// values in out. If one or more values cannot be decoded due to a type
-// mismatches, decoding continues partially until the end of the YAML
-// content, and a *yaml.TypeError is returned with details for all
-// missed values.
-//
-// Struct fields are only unmarshalled if they are exported (have an
-// upper case first letter), and are unmarshalled using the field name
-// lowercased as the default key. Custom keys may be defined via the
-// "yaml" name in the field tag: the content preceding the first comma
-// is used as the key, and the following comma-separated options are
-// used to tweak the marshalling process (see Marshal).
-// Conflicting names result in a runtime error.
-//
-// For example:
-//
-// type T struct {
-// F int `yaml:"a,omitempty"`
-// B int
-// }
-// var t T
-// yaml.Unmarshal([]byte("a: 1\nb: 2"), &t)
-//
-// See the documentation of Marshal for the format of tags and a list of
-// supported tag options.
-//
-func Unmarshal(in []byte, out interface{}) (err error) {
- return unmarshal(in, out, false)
-}
-
-// A Decoder reads and decodes YAML values from an input stream.
-type Decoder struct {
- parser *parser
- knownFields bool
-}
-
-// NewDecoder returns a new decoder that reads from r.
-//
-// The decoder introduces its own buffering and may read
-// data from r beyond the YAML values requested.
-func NewDecoder(r io.Reader) *Decoder {
- return &Decoder{
- parser: newParserFromReader(r),
- }
-}
-
-// KnownFields ensures that the keys in decoded mappings to
-// exist as fields in the struct being decoded into.
-func (dec *Decoder) KnownFields(enable bool) {
- dec.knownFields = enable
-}
-
-// Decode reads the next YAML-encoded value from its input
-// and stores it in the value pointed to by v.
-//
-// See the documentation for Unmarshal for details about the
-// conversion of YAML into a Go value.
-func (dec *Decoder) Decode(v interface{}) (err error) {
- d := newDecoder()
- d.knownFields = dec.knownFields
- defer handleErr(&err)
- node := dec.parser.parse()
- if node == nil {
- return io.EOF
- }
- out := reflect.ValueOf(v)
- if out.Kind() == reflect.Ptr && !out.IsNil() {
- out = out.Elem()
- }
- d.unmarshal(node, out)
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-// Decode decodes the node and stores its data into the value pointed to by v.
-//
-// See the documentation for Unmarshal for details about the
-// conversion of YAML into a Go value.
-func (n *Node) Decode(v interface{}) (err error) {
- d := newDecoder()
- defer handleErr(&err)
- out := reflect.ValueOf(v)
- if out.Kind() == reflect.Ptr && !out.IsNil() {
- out = out.Elem()
- }
- d.unmarshal(n, out)
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-func unmarshal(in []byte, out interface{}, strict bool) (err error) {
- defer handleErr(&err)
- d := newDecoder()
- p := newParser(in)
- defer p.destroy()
- node := p.parse()
- if node != nil {
- v := reflect.ValueOf(out)
- if v.Kind() == reflect.Ptr && !v.IsNil() {
- v = v.Elem()
- }
- d.unmarshal(node, v)
- }
- if len(d.terrors) > 0 {
- return &TypeError{d.terrors}
- }
- return nil
-}
-
-// Marshal serializes the value provided into a YAML document. The structure
-// of the generated document will reflect the structure of the value itself.
-// Maps and pointers (to struct, string, int, etc) are accepted as the in value.
-//
-// Struct fields are only marshalled if they are exported (have an upper case
-// first letter), and are marshalled using the field name lowercased as the
-// default key. Custom keys may be defined via the "yaml" name in the field
-// tag: the content preceding the first comma is used as the key, and the
-// following comma-separated options are used to tweak the marshalling process.
-// Conflicting names result in a runtime error.
-//
-// The field tag format accepted is:
-//
-// `(...) yaml:"[][,[,]]" (...)`
-//
-// The following flags are currently supported:
-//
-// omitempty Only include the field if it's not set to the zero
-// value for the type or to empty slices or maps.
-// Zero valued structs will be omitted if all their public
-// fields are zero, unless they implement an IsZero
-// method (see the IsZeroer interface type), in which
-// case the field will be excluded if IsZero returns true.
-//
-// flow Marshal using a flow style (useful for structs,
-// sequences and maps).
-//
-// inline Inline the field, which must be a struct or a map,
-// causing all of its fields or keys to be processed as if
-// they were part of the outer struct. For maps, keys must
-// not conflict with the yaml keys of other struct fields.
-//
-// In addition, if the key is "-", the field is ignored.
-//
-// For example:
-//
-// type T struct {
-// F int `yaml:"a,omitempty"`
-// B int
-// }
-// yaml.Marshal(&T{B: 2}) // Returns "b: 2\n"
-// yaml.Marshal(&T{F: 1}} // Returns "a: 1\nb: 0\n"
-//
-func Marshal(in interface{}) (out []byte, err error) {
- defer handleErr(&err)
- e := newEncoder()
- defer e.destroy()
- e.marshalDoc("", reflect.ValueOf(in))
- e.finish()
- out = e.out
- return
-}
-
-// An Encoder writes YAML values to an output stream.
-type Encoder struct {
- encoder *encoder
-}
-
-// NewEncoder returns a new encoder that writes to w.
-// The Encoder should be closed after use to flush all data
-// to w.
-func NewEncoder(w io.Writer) *Encoder {
- return &Encoder{
- encoder: newEncoderWithWriter(w),
- }
-}
-
-// Encode writes the YAML encoding of v to the stream.
-// If multiple items are encoded to the stream, the
-// second and subsequent document will be preceded
-// with a "---" document separator, but the first will not.
-//
-// See the documentation for Marshal for details about the conversion of Go
-// values to YAML.
-func (e *Encoder) Encode(v interface{}) (err error) {
- defer handleErr(&err)
- e.encoder.marshalDoc("", reflect.ValueOf(v))
- return nil
-}
-
-// Encode encodes value v and stores its representation in n.
-//
-// See the documentation for Marshal for details about the
-// conversion of Go values into YAML.
-func (n *Node) Encode(v interface{}) (err error) {
- defer handleErr(&err)
- e := newEncoder()
- defer e.destroy()
- e.marshalDoc("", reflect.ValueOf(v))
- e.finish()
- p := newParser(e.out)
- p.textless = true
- defer p.destroy()
- doc := p.parse()
- *n = *doc.Content[0]
- return nil
-}
-
-// SetIndent changes the used indentation used when encoding.
-func (e *Encoder) SetIndent(spaces int) {
- if spaces < 0 {
- panic("yaml: cannot indent to a negative number of spaces")
- }
- e.encoder.indent = spaces
-}
-
-// Close closes the encoder by writing any remaining data.
-// It does not write a stream terminating string "...".
-func (e *Encoder) Close() (err error) {
- defer handleErr(&err)
- e.encoder.finish()
- return nil
-}
-
-func handleErr(err *error) {
- if v := recover(); v != nil {
- if e, ok := v.(yamlError); ok {
- *err = e.err
- } else {
- panic(v)
- }
- }
-}
-
-type yamlError struct {
- err error
-}
-
-func fail(err error) {
- panic(yamlError{err})
-}
-
-func failf(format string, args ...interface{}) {
- panic(yamlError{fmt.Errorf("yaml: "+format, args...)})
-}
-
-// A TypeError is returned by Unmarshal when one or more fields in
-// the YAML document cannot be properly decoded into the requested
-// types. When this error is returned, the value is still
-// unmarshaled partially.
-type TypeError struct {
- Errors []string
-}
-
-func (e *TypeError) Error() string {
- return fmt.Sprintf("yaml: unmarshal errors:\n %s", strings.Join(e.Errors, "\n "))
-}
-
-type Kind uint32
-
-const (
- DocumentNode Kind = 1 << iota
- SequenceNode
- MappingNode
- ScalarNode
- AliasNode
-)
-
-type Style uint32
-
-const (
- TaggedStyle Style = 1 << iota
- DoubleQuotedStyle
- SingleQuotedStyle
- LiteralStyle
- FoldedStyle
- FlowStyle
-)
-
-// Node represents an element in the YAML document hierarchy. While documents
-// are typically encoded and decoded into higher level types, such as structs
-// and maps, Node is an intermediate representation that allows detailed
-// control over the content being decoded or encoded.
-//
-// It's worth noting that although Node offers access into details such as
-// line numbers, colums, and comments, the content when re-encoded will not
-// have its original textual representation preserved. An effort is made to
-// render the data plesantly, and to preserve comments near the data they
-// describe, though.
-//
-// Values that make use of the Node type interact with the yaml package in the
-// same way any other type would do, by encoding and decoding yaml data
-// directly or indirectly into them.
-//
-// For example:
-//
-// var person struct {
-// Name string
-// Address yaml.Node
-// }
-// err := yaml.Unmarshal(data, &person)
-//
-// Or by itself:
-//
-// var person Node
-// err := yaml.Unmarshal(data, &person)
-//
-type Node struct {
- // Kind defines whether the node is a document, a mapping, a sequence,
- // a scalar value, or an alias to another node. The specific data type of
- // scalar nodes may be obtained via the ShortTag and LongTag methods.
- Kind Kind
-
- // Style allows customizing the apperance of the node in the tree.
- Style Style
-
- // Tag holds the YAML tag defining the data type for the value.
- // When decoding, this field will always be set to the resolved tag,
- // even when it wasn't explicitly provided in the YAML content.
- // When encoding, if this field is unset the value type will be
- // implied from the node properties, and if it is set, it will only
- // be serialized into the representation if TaggedStyle is used or
- // the implicit tag diverges from the provided one.
- Tag string
-
- // Value holds the unescaped and unquoted represenation of the value.
- Value string
-
- // Anchor holds the anchor name for this node, which allows aliases to point to it.
- Anchor string
-
- // Alias holds the node that this alias points to. Only valid when Kind is AliasNode.
- Alias *Node
-
- // Content holds contained nodes for documents, mappings, and sequences.
- Content []*Node
-
- // HeadComment holds any comments in the lines preceding the node and
- // not separated by an empty line.
- HeadComment string
-
- // LineComment holds any comments at the end of the line where the node is in.
- LineComment string
-
- // FootComment holds any comments following the node and before empty lines.
- FootComment string
-
- // Line and Column hold the node position in the decoded YAML text.
- // These fields are not respected when encoding the node.
- Line int
- Column int
-}
-
-// IsZero returns whether the node has all of its fields unset.
-func (n *Node) IsZero() bool {
- return n.Kind == 0 && n.Style == 0 && n.Tag == "" && n.Value == "" && n.Anchor == "" && n.Alias == nil && n.Content == nil &&
- n.HeadComment == "" && n.LineComment == "" && n.FootComment == "" && n.Line == 0 && n.Column == 0
-}
-
-
-// LongTag returns the long form of the tag that indicates the data type for
-// the node. If the Tag field isn't explicitly defined, one will be computed
-// based on the node properties.
-func (n *Node) LongTag() string {
- return longTag(n.ShortTag())
-}
-
-// ShortTag returns the short form of the YAML tag that indicates data type for
-// the node. If the Tag field isn't explicitly defined, one will be computed
-// based on the node properties.
-func (n *Node) ShortTag() string {
- if n.indicatedString() {
- return strTag
- }
- if n.Tag == "" || n.Tag == "!" {
- switch n.Kind {
- case MappingNode:
- return mapTag
- case SequenceNode:
- return seqTag
- case AliasNode:
- if n.Alias != nil {
- return n.Alias.ShortTag()
- }
- case ScalarNode:
- tag, _ := resolve("", n.Value)
- return tag
- case 0:
- // Special case to make the zero value convenient.
- if n.IsZero() {
- return nullTag
- }
- }
- return ""
- }
- return shortTag(n.Tag)
-}
-
-func (n *Node) indicatedString() bool {
- return n.Kind == ScalarNode &&
- (shortTag(n.Tag) == strTag ||
- (n.Tag == "" || n.Tag == "!") && n.Style&(SingleQuotedStyle|DoubleQuotedStyle|LiteralStyle|FoldedStyle) != 0)
-}
-
-// SetString is a convenience function that sets the node to a string value
-// and defines its style in a pleasant way depending on its content.
-func (n *Node) SetString(s string) {
- n.Kind = ScalarNode
- if utf8.ValidString(s) {
- n.Value = s
- n.Tag = strTag
- } else {
- n.Value = encodeBase64(s)
- n.Tag = binaryTag
- }
- if strings.Contains(n.Value, "\n") {
- n.Style = LiteralStyle
- }
-}
-
-// --------------------------------------------------------------------------
-// Maintain a mapping of keys to structure field indexes
-
-// The code in this section was copied from mgo/bson.
-
-// structInfo holds details for the serialization of fields of
-// a given struct.
-type structInfo struct {
- FieldsMap map[string]fieldInfo
- FieldsList []fieldInfo
-
- // InlineMap is the number of the field in the struct that
- // contains an ,inline map, or -1 if there's none.
- InlineMap int
-
- // InlineUnmarshalers holds indexes to inlined fields that
- // contain unmarshaler values.
- InlineUnmarshalers [][]int
-}
-
-type fieldInfo struct {
- Key string
- Num int
- OmitEmpty bool
- Flow bool
- // Id holds the unique field identifier, so we can cheaply
- // check for field duplicates without maintaining an extra map.
- Id int
-
- // Inline holds the field index if the field is part of an inlined struct.
- Inline []int
-}
-
-var structMap = make(map[reflect.Type]*structInfo)
-var fieldMapMutex sync.RWMutex
-var unmarshalerType reflect.Type
-
-func init() {
- var v Unmarshaler
- unmarshalerType = reflect.ValueOf(&v).Elem().Type()
-}
-
-func getStructInfo(st reflect.Type) (*structInfo, error) {
- fieldMapMutex.RLock()
- sinfo, found := structMap[st]
- fieldMapMutex.RUnlock()
- if found {
- return sinfo, nil
- }
-
- n := st.NumField()
- fieldsMap := make(map[string]fieldInfo)
- fieldsList := make([]fieldInfo, 0, n)
- inlineMap := -1
- inlineUnmarshalers := [][]int(nil)
- for i := 0; i != n; i++ {
- field := st.Field(i)
- if field.PkgPath != "" && !field.Anonymous {
- continue // Private field
- }
-
- info := fieldInfo{Num: i}
-
- tag := field.Tag.Get("yaml")
- if tag == "" && strings.Index(string(field.Tag), ":") < 0 {
- tag = string(field.Tag)
- }
- if tag == "-" {
- continue
- }
-
- inline := false
- fields := strings.Split(tag, ",")
- if len(fields) > 1 {
- for _, flag := range fields[1:] {
- switch flag {
- case "omitempty":
- info.OmitEmpty = true
- case "flow":
- info.Flow = true
- case "inline":
- inline = true
- default:
- return nil, errors.New(fmt.Sprintf("unsupported flag %q in tag %q of type %s", flag, tag, st))
- }
- }
- tag = fields[0]
- }
-
- if inline {
- switch field.Type.Kind() {
- case reflect.Map:
- if inlineMap >= 0 {
- return nil, errors.New("multiple ,inline maps in struct " + st.String())
- }
- if field.Type.Key() != reflect.TypeOf("") {
- return nil, errors.New("option ,inline needs a map with string keys in struct " + st.String())
- }
- inlineMap = info.Num
- case reflect.Struct, reflect.Ptr:
- ftype := field.Type
- for ftype.Kind() == reflect.Ptr {
- ftype = ftype.Elem()
- }
- if ftype.Kind() != reflect.Struct {
- return nil, errors.New("option ,inline may only be used on a struct or map field")
- }
- if reflect.PtrTo(ftype).Implements(unmarshalerType) {
- inlineUnmarshalers = append(inlineUnmarshalers, []int{i})
- } else {
- sinfo, err := getStructInfo(ftype)
- if err != nil {
- return nil, err
- }
- for _, index := range sinfo.InlineUnmarshalers {
- inlineUnmarshalers = append(inlineUnmarshalers, append([]int{i}, index...))
- }
- for _, finfo := range sinfo.FieldsList {
- if _, found := fieldsMap[finfo.Key]; found {
- msg := "duplicated key '" + finfo.Key + "' in struct " + st.String()
- return nil, errors.New(msg)
- }
- if finfo.Inline == nil {
- finfo.Inline = []int{i, finfo.Num}
- } else {
- finfo.Inline = append([]int{i}, finfo.Inline...)
- }
- finfo.Id = len(fieldsList)
- fieldsMap[finfo.Key] = finfo
- fieldsList = append(fieldsList, finfo)
- }
- }
- default:
- return nil, errors.New("option ,inline may only be used on a struct or map field")
- }
- continue
- }
-
- if tag != "" {
- info.Key = tag
- } else {
- info.Key = strings.ToLower(field.Name)
- }
-
- if _, found = fieldsMap[info.Key]; found {
- msg := "duplicated key '" + info.Key + "' in struct " + st.String()
- return nil, errors.New(msg)
- }
-
- info.Id = len(fieldsList)
- fieldsList = append(fieldsList, info)
- fieldsMap[info.Key] = info
- }
-
- sinfo = &structInfo{
- FieldsMap: fieldsMap,
- FieldsList: fieldsList,
- InlineMap: inlineMap,
- InlineUnmarshalers: inlineUnmarshalers,
- }
-
- fieldMapMutex.Lock()
- structMap[st] = sinfo
- fieldMapMutex.Unlock()
- return sinfo, nil
-}
-
-// IsZeroer is used to check whether an object is zero to
-// determine whether it should be omitted when marshaling
-// with the omitempty flag. One notable implementation
-// is time.Time.
-type IsZeroer interface {
- IsZero() bool
-}
-
-func isZero(v reflect.Value) bool {
- kind := v.Kind()
- if z, ok := v.Interface().(IsZeroer); ok {
- if (kind == reflect.Ptr || kind == reflect.Interface) && v.IsNil() {
- return true
- }
- return z.IsZero()
- }
- switch kind {
- case reflect.String:
- return len(v.String()) == 0
- case reflect.Interface, reflect.Ptr:
- return v.IsNil()
- case reflect.Slice:
- return v.Len() == 0
- case reflect.Map:
- return v.Len() == 0
- case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
- return v.Int() == 0
- case reflect.Float32, reflect.Float64:
- return v.Float() == 0
- case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
- return v.Uint() == 0
- case reflect.Bool:
- return !v.Bool()
- case reflect.Struct:
- vt := v.Type()
- for i := v.NumField() - 1; i >= 0; i-- {
- if vt.Field(i).PkgPath != "" {
- continue // Private field
- }
- if !isZero(v.Field(i)) {
- return false
- }
- }
- return true
- }
- return false
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yamlh.go b/sesh/vendor/gopkg.in/yaml.v3/yamlh.go
deleted file mode 100644
index 7c6d007..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yamlh.go
+++ /dev/null
@@ -1,807 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-import (
- "fmt"
- "io"
-)
-
-// The version directive data.
-type yaml_version_directive_t struct {
- major int8 // The major version number.
- minor int8 // The minor version number.
-}
-
-// The tag directive data.
-type yaml_tag_directive_t struct {
- handle []byte // The tag handle.
- prefix []byte // The tag prefix.
-}
-
-type yaml_encoding_t int
-
-// The stream encoding.
-const (
- // Let the parser choose the encoding.
- yaml_ANY_ENCODING yaml_encoding_t = iota
-
- yaml_UTF8_ENCODING // The default UTF-8 encoding.
- yaml_UTF16LE_ENCODING // The UTF-16-LE encoding with BOM.
- yaml_UTF16BE_ENCODING // The UTF-16-BE encoding with BOM.
-)
-
-type yaml_break_t int
-
-// Line break types.
-const (
- // Let the parser choose the break type.
- yaml_ANY_BREAK yaml_break_t = iota
-
- yaml_CR_BREAK // Use CR for line breaks (Mac style).
- yaml_LN_BREAK // Use LN for line breaks (Unix style).
- yaml_CRLN_BREAK // Use CR LN for line breaks (DOS style).
-)
-
-type yaml_error_type_t int
-
-// Many bad things could happen with the parser and emitter.
-const (
- // No error is produced.
- yaml_NO_ERROR yaml_error_type_t = iota
-
- yaml_MEMORY_ERROR // Cannot allocate or reallocate a block of memory.
- yaml_READER_ERROR // Cannot read or decode the input stream.
- yaml_SCANNER_ERROR // Cannot scan the input stream.
- yaml_PARSER_ERROR // Cannot parse the input stream.
- yaml_COMPOSER_ERROR // Cannot compose a YAML document.
- yaml_WRITER_ERROR // Cannot write to the output stream.
- yaml_EMITTER_ERROR // Cannot emit a YAML stream.
-)
-
-// The pointer position.
-type yaml_mark_t struct {
- index int // The position index.
- line int // The position line.
- column int // The position column.
-}
-
-// Node Styles
-
-type yaml_style_t int8
-
-type yaml_scalar_style_t yaml_style_t
-
-// Scalar styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_SCALAR_STYLE yaml_scalar_style_t = 0
-
- yaml_PLAIN_SCALAR_STYLE yaml_scalar_style_t = 1 << iota // The plain scalar style.
- yaml_SINGLE_QUOTED_SCALAR_STYLE // The single-quoted scalar style.
- yaml_DOUBLE_QUOTED_SCALAR_STYLE // The double-quoted scalar style.
- yaml_LITERAL_SCALAR_STYLE // The literal scalar style.
- yaml_FOLDED_SCALAR_STYLE // The folded scalar style.
-)
-
-type yaml_sequence_style_t yaml_style_t
-
-// Sequence styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_SEQUENCE_STYLE yaml_sequence_style_t = iota
-
- yaml_BLOCK_SEQUENCE_STYLE // The block sequence style.
- yaml_FLOW_SEQUENCE_STYLE // The flow sequence style.
-)
-
-type yaml_mapping_style_t yaml_style_t
-
-// Mapping styles.
-const (
- // Let the emitter choose the style.
- yaml_ANY_MAPPING_STYLE yaml_mapping_style_t = iota
-
- yaml_BLOCK_MAPPING_STYLE // The block mapping style.
- yaml_FLOW_MAPPING_STYLE // The flow mapping style.
-)
-
-// Tokens
-
-type yaml_token_type_t int
-
-// Token types.
-const (
- // An empty token.
- yaml_NO_TOKEN yaml_token_type_t = iota
-
- yaml_STREAM_START_TOKEN // A STREAM-START token.
- yaml_STREAM_END_TOKEN // A STREAM-END token.
-
- yaml_VERSION_DIRECTIVE_TOKEN // A VERSION-DIRECTIVE token.
- yaml_TAG_DIRECTIVE_TOKEN // A TAG-DIRECTIVE token.
- yaml_DOCUMENT_START_TOKEN // A DOCUMENT-START token.
- yaml_DOCUMENT_END_TOKEN // A DOCUMENT-END token.
-
- yaml_BLOCK_SEQUENCE_START_TOKEN // A BLOCK-SEQUENCE-START token.
- yaml_BLOCK_MAPPING_START_TOKEN // A BLOCK-SEQUENCE-END token.
- yaml_BLOCK_END_TOKEN // A BLOCK-END token.
-
- yaml_FLOW_SEQUENCE_START_TOKEN // A FLOW-SEQUENCE-START token.
- yaml_FLOW_SEQUENCE_END_TOKEN // A FLOW-SEQUENCE-END token.
- yaml_FLOW_MAPPING_START_TOKEN // A FLOW-MAPPING-START token.
- yaml_FLOW_MAPPING_END_TOKEN // A FLOW-MAPPING-END token.
-
- yaml_BLOCK_ENTRY_TOKEN // A BLOCK-ENTRY token.
- yaml_FLOW_ENTRY_TOKEN // A FLOW-ENTRY token.
- yaml_KEY_TOKEN // A KEY token.
- yaml_VALUE_TOKEN // A VALUE token.
-
- yaml_ALIAS_TOKEN // An ALIAS token.
- yaml_ANCHOR_TOKEN // An ANCHOR token.
- yaml_TAG_TOKEN // A TAG token.
- yaml_SCALAR_TOKEN // A SCALAR token.
-)
-
-func (tt yaml_token_type_t) String() string {
- switch tt {
- case yaml_NO_TOKEN:
- return "yaml_NO_TOKEN"
- case yaml_STREAM_START_TOKEN:
- return "yaml_STREAM_START_TOKEN"
- case yaml_STREAM_END_TOKEN:
- return "yaml_STREAM_END_TOKEN"
- case yaml_VERSION_DIRECTIVE_TOKEN:
- return "yaml_VERSION_DIRECTIVE_TOKEN"
- case yaml_TAG_DIRECTIVE_TOKEN:
- return "yaml_TAG_DIRECTIVE_TOKEN"
- case yaml_DOCUMENT_START_TOKEN:
- return "yaml_DOCUMENT_START_TOKEN"
- case yaml_DOCUMENT_END_TOKEN:
- return "yaml_DOCUMENT_END_TOKEN"
- case yaml_BLOCK_SEQUENCE_START_TOKEN:
- return "yaml_BLOCK_SEQUENCE_START_TOKEN"
- case yaml_BLOCK_MAPPING_START_TOKEN:
- return "yaml_BLOCK_MAPPING_START_TOKEN"
- case yaml_BLOCK_END_TOKEN:
- return "yaml_BLOCK_END_TOKEN"
- case yaml_FLOW_SEQUENCE_START_TOKEN:
- return "yaml_FLOW_SEQUENCE_START_TOKEN"
- case yaml_FLOW_SEQUENCE_END_TOKEN:
- return "yaml_FLOW_SEQUENCE_END_TOKEN"
- case yaml_FLOW_MAPPING_START_TOKEN:
- return "yaml_FLOW_MAPPING_START_TOKEN"
- case yaml_FLOW_MAPPING_END_TOKEN:
- return "yaml_FLOW_MAPPING_END_TOKEN"
- case yaml_BLOCK_ENTRY_TOKEN:
- return "yaml_BLOCK_ENTRY_TOKEN"
- case yaml_FLOW_ENTRY_TOKEN:
- return "yaml_FLOW_ENTRY_TOKEN"
- case yaml_KEY_TOKEN:
- return "yaml_KEY_TOKEN"
- case yaml_VALUE_TOKEN:
- return "yaml_VALUE_TOKEN"
- case yaml_ALIAS_TOKEN:
- return "yaml_ALIAS_TOKEN"
- case yaml_ANCHOR_TOKEN:
- return "yaml_ANCHOR_TOKEN"
- case yaml_TAG_TOKEN:
- return "yaml_TAG_TOKEN"
- case yaml_SCALAR_TOKEN:
- return "yaml_SCALAR_TOKEN"
- }
- return ""
-}
-
-// The token structure.
-type yaml_token_t struct {
- // The token type.
- typ yaml_token_type_t
-
- // The start/end of the token.
- start_mark, end_mark yaml_mark_t
-
- // The stream encoding (for yaml_STREAM_START_TOKEN).
- encoding yaml_encoding_t
-
- // The alias/anchor/scalar value or tag/tag directive handle
- // (for yaml_ALIAS_TOKEN, yaml_ANCHOR_TOKEN, yaml_SCALAR_TOKEN, yaml_TAG_TOKEN, yaml_TAG_DIRECTIVE_TOKEN).
- value []byte
-
- // The tag suffix (for yaml_TAG_TOKEN).
- suffix []byte
-
- // The tag directive prefix (for yaml_TAG_DIRECTIVE_TOKEN).
- prefix []byte
-
- // The scalar style (for yaml_SCALAR_TOKEN).
- style yaml_scalar_style_t
-
- // The version directive major/minor (for yaml_VERSION_DIRECTIVE_TOKEN).
- major, minor int8
-}
-
-// Events
-
-type yaml_event_type_t int8
-
-// Event types.
-const (
- // An empty event.
- yaml_NO_EVENT yaml_event_type_t = iota
-
- yaml_STREAM_START_EVENT // A STREAM-START event.
- yaml_STREAM_END_EVENT // A STREAM-END event.
- yaml_DOCUMENT_START_EVENT // A DOCUMENT-START event.
- yaml_DOCUMENT_END_EVENT // A DOCUMENT-END event.
- yaml_ALIAS_EVENT // An ALIAS event.
- yaml_SCALAR_EVENT // A SCALAR event.
- yaml_SEQUENCE_START_EVENT // A SEQUENCE-START event.
- yaml_SEQUENCE_END_EVENT // A SEQUENCE-END event.
- yaml_MAPPING_START_EVENT // A MAPPING-START event.
- yaml_MAPPING_END_EVENT // A MAPPING-END event.
- yaml_TAIL_COMMENT_EVENT
-)
-
-var eventStrings = []string{
- yaml_NO_EVENT: "none",
- yaml_STREAM_START_EVENT: "stream start",
- yaml_STREAM_END_EVENT: "stream end",
- yaml_DOCUMENT_START_EVENT: "document start",
- yaml_DOCUMENT_END_EVENT: "document end",
- yaml_ALIAS_EVENT: "alias",
- yaml_SCALAR_EVENT: "scalar",
- yaml_SEQUENCE_START_EVENT: "sequence start",
- yaml_SEQUENCE_END_EVENT: "sequence end",
- yaml_MAPPING_START_EVENT: "mapping start",
- yaml_MAPPING_END_EVENT: "mapping end",
- yaml_TAIL_COMMENT_EVENT: "tail comment",
-}
-
-func (e yaml_event_type_t) String() string {
- if e < 0 || int(e) >= len(eventStrings) {
- return fmt.Sprintf("unknown event %d", e)
- }
- return eventStrings[e]
-}
-
-// The event structure.
-type yaml_event_t struct {
-
- // The event type.
- typ yaml_event_type_t
-
- // The start and end of the event.
- start_mark, end_mark yaml_mark_t
-
- // The document encoding (for yaml_STREAM_START_EVENT).
- encoding yaml_encoding_t
-
- // The version directive (for yaml_DOCUMENT_START_EVENT).
- version_directive *yaml_version_directive_t
-
- // The list of tag directives (for yaml_DOCUMENT_START_EVENT).
- tag_directives []yaml_tag_directive_t
-
- // The comments
- head_comment []byte
- line_comment []byte
- foot_comment []byte
- tail_comment []byte
-
- // The anchor (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT, yaml_ALIAS_EVENT).
- anchor []byte
-
- // The tag (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT).
- tag []byte
-
- // The scalar value (for yaml_SCALAR_EVENT).
- value []byte
-
- // Is the document start/end indicator implicit, or the tag optional?
- // (for yaml_DOCUMENT_START_EVENT, yaml_DOCUMENT_END_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT, yaml_SCALAR_EVENT).
- implicit bool
-
- // Is the tag optional for any non-plain style? (for yaml_SCALAR_EVENT).
- quoted_implicit bool
-
- // The style (for yaml_SCALAR_EVENT, yaml_SEQUENCE_START_EVENT, yaml_MAPPING_START_EVENT).
- style yaml_style_t
-}
-
-func (e *yaml_event_t) scalar_style() yaml_scalar_style_t { return yaml_scalar_style_t(e.style) }
-func (e *yaml_event_t) sequence_style() yaml_sequence_style_t { return yaml_sequence_style_t(e.style) }
-func (e *yaml_event_t) mapping_style() yaml_mapping_style_t { return yaml_mapping_style_t(e.style) }
-
-// Nodes
-
-const (
- yaml_NULL_TAG = "tag:yaml.org,2002:null" // The tag !!null with the only possible value: null.
- yaml_BOOL_TAG = "tag:yaml.org,2002:bool" // The tag !!bool with the values: true and false.
- yaml_STR_TAG = "tag:yaml.org,2002:str" // The tag !!str for string values.
- yaml_INT_TAG = "tag:yaml.org,2002:int" // The tag !!int for integer values.
- yaml_FLOAT_TAG = "tag:yaml.org,2002:float" // The tag !!float for float values.
- yaml_TIMESTAMP_TAG = "tag:yaml.org,2002:timestamp" // The tag !!timestamp for date and time values.
-
- yaml_SEQ_TAG = "tag:yaml.org,2002:seq" // The tag !!seq is used to denote sequences.
- yaml_MAP_TAG = "tag:yaml.org,2002:map" // The tag !!map is used to denote mapping.
-
- // Not in original libyaml.
- yaml_BINARY_TAG = "tag:yaml.org,2002:binary"
- yaml_MERGE_TAG = "tag:yaml.org,2002:merge"
-
- yaml_DEFAULT_SCALAR_TAG = yaml_STR_TAG // The default scalar tag is !!str.
- yaml_DEFAULT_SEQUENCE_TAG = yaml_SEQ_TAG // The default sequence tag is !!seq.
- yaml_DEFAULT_MAPPING_TAG = yaml_MAP_TAG // The default mapping tag is !!map.
-)
-
-type yaml_node_type_t int
-
-// Node types.
-const (
- // An empty node.
- yaml_NO_NODE yaml_node_type_t = iota
-
- yaml_SCALAR_NODE // A scalar node.
- yaml_SEQUENCE_NODE // A sequence node.
- yaml_MAPPING_NODE // A mapping node.
-)
-
-// An element of a sequence node.
-type yaml_node_item_t int
-
-// An element of a mapping node.
-type yaml_node_pair_t struct {
- key int // The key of the element.
- value int // The value of the element.
-}
-
-// The node structure.
-type yaml_node_t struct {
- typ yaml_node_type_t // The node type.
- tag []byte // The node tag.
-
- // The node data.
-
- // The scalar parameters (for yaml_SCALAR_NODE).
- scalar struct {
- value []byte // The scalar value.
- length int // The length of the scalar value.
- style yaml_scalar_style_t // The scalar style.
- }
-
- // The sequence parameters (for YAML_SEQUENCE_NODE).
- sequence struct {
- items_data []yaml_node_item_t // The stack of sequence items.
- style yaml_sequence_style_t // The sequence style.
- }
-
- // The mapping parameters (for yaml_MAPPING_NODE).
- mapping struct {
- pairs_data []yaml_node_pair_t // The stack of mapping pairs (key, value).
- pairs_start *yaml_node_pair_t // The beginning of the stack.
- pairs_end *yaml_node_pair_t // The end of the stack.
- pairs_top *yaml_node_pair_t // The top of the stack.
- style yaml_mapping_style_t // The mapping style.
- }
-
- start_mark yaml_mark_t // The beginning of the node.
- end_mark yaml_mark_t // The end of the node.
-
-}
-
-// The document structure.
-type yaml_document_t struct {
-
- // The document nodes.
- nodes []yaml_node_t
-
- // The version directive.
- version_directive *yaml_version_directive_t
-
- // The list of tag directives.
- tag_directives_data []yaml_tag_directive_t
- tag_directives_start int // The beginning of the tag directives list.
- tag_directives_end int // The end of the tag directives list.
-
- start_implicit int // Is the document start indicator implicit?
- end_implicit int // Is the document end indicator implicit?
-
- // The start/end of the document.
- start_mark, end_mark yaml_mark_t
-}
-
-// The prototype of a read handler.
-//
-// The read handler is called when the parser needs to read more bytes from the
-// source. The handler should write not more than size bytes to the buffer.
-// The number of written bytes should be set to the size_read variable.
-//
-// [in,out] data A pointer to an application data specified by
-// yaml_parser_set_input().
-// [out] buffer The buffer to write the data from the source.
-// [in] size The size of the buffer.
-// [out] size_read The actual number of bytes read from the source.
-//
-// On success, the handler should return 1. If the handler failed,
-// the returned value should be 0. On EOF, the handler should set the
-// size_read to 0 and return 1.
-type yaml_read_handler_t func(parser *yaml_parser_t, buffer []byte) (n int, err error)
-
-// This structure holds information about a potential simple key.
-type yaml_simple_key_t struct {
- possible bool // Is a simple key possible?
- required bool // Is a simple key required?
- token_number int // The number of the token.
- mark yaml_mark_t // The position mark.
-}
-
-// The states of the parser.
-type yaml_parser_state_t int
-
-const (
- yaml_PARSE_STREAM_START_STATE yaml_parser_state_t = iota
-
- yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE // Expect the beginning of an implicit document.
- yaml_PARSE_DOCUMENT_START_STATE // Expect DOCUMENT-START.
- yaml_PARSE_DOCUMENT_CONTENT_STATE // Expect the content of a document.
- yaml_PARSE_DOCUMENT_END_STATE // Expect DOCUMENT-END.
- yaml_PARSE_BLOCK_NODE_STATE // Expect a block node.
- yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE // Expect a block node or indentless sequence.
- yaml_PARSE_FLOW_NODE_STATE // Expect a flow node.
- yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE // Expect the first entry of a block sequence.
- yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE // Expect an entry of a block sequence.
- yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE // Expect an entry of an indentless sequence.
- yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE // Expect the first key of a block mapping.
- yaml_PARSE_BLOCK_MAPPING_KEY_STATE // Expect a block mapping key.
- yaml_PARSE_BLOCK_MAPPING_VALUE_STATE // Expect a block mapping value.
- yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE // Expect the first entry of a flow sequence.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE // Expect an entry of a flow sequence.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE // Expect a key of an ordered mapping.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE // Expect a value of an ordered mapping.
- yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE // Expect the and of an ordered mapping entry.
- yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE // Expect the first key of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_KEY_STATE // Expect a key of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_VALUE_STATE // Expect a value of a flow mapping.
- yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE // Expect an empty value of a flow mapping.
- yaml_PARSE_END_STATE // Expect nothing.
-)
-
-func (ps yaml_parser_state_t) String() string {
- switch ps {
- case yaml_PARSE_STREAM_START_STATE:
- return "yaml_PARSE_STREAM_START_STATE"
- case yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE:
- return "yaml_PARSE_IMPLICIT_DOCUMENT_START_STATE"
- case yaml_PARSE_DOCUMENT_START_STATE:
- return "yaml_PARSE_DOCUMENT_START_STATE"
- case yaml_PARSE_DOCUMENT_CONTENT_STATE:
- return "yaml_PARSE_DOCUMENT_CONTENT_STATE"
- case yaml_PARSE_DOCUMENT_END_STATE:
- return "yaml_PARSE_DOCUMENT_END_STATE"
- case yaml_PARSE_BLOCK_NODE_STATE:
- return "yaml_PARSE_BLOCK_NODE_STATE"
- case yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE:
- return "yaml_PARSE_BLOCK_NODE_OR_INDENTLESS_SEQUENCE_STATE"
- case yaml_PARSE_FLOW_NODE_STATE:
- return "yaml_PARSE_FLOW_NODE_STATE"
- case yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE:
- return "yaml_PARSE_BLOCK_SEQUENCE_FIRST_ENTRY_STATE"
- case yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_BLOCK_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_INDENTLESS_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_FIRST_KEY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_KEY_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_KEY_STATE"
- case yaml_PARSE_BLOCK_MAPPING_VALUE_STATE:
- return "yaml_PARSE_BLOCK_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_FIRST_ENTRY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_KEY_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE:
- return "yaml_PARSE_FLOW_SEQUENCE_ENTRY_MAPPING_END_STATE"
- case yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE:
- return "yaml_PARSE_FLOW_MAPPING_FIRST_KEY_STATE"
- case yaml_PARSE_FLOW_MAPPING_KEY_STATE:
- return "yaml_PARSE_FLOW_MAPPING_KEY_STATE"
- case yaml_PARSE_FLOW_MAPPING_VALUE_STATE:
- return "yaml_PARSE_FLOW_MAPPING_VALUE_STATE"
- case yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE:
- return "yaml_PARSE_FLOW_MAPPING_EMPTY_VALUE_STATE"
- case yaml_PARSE_END_STATE:
- return "yaml_PARSE_END_STATE"
- }
- return ""
-}
-
-// This structure holds aliases data.
-type yaml_alias_data_t struct {
- anchor []byte // The anchor.
- index int // The node id.
- mark yaml_mark_t // The anchor mark.
-}
-
-// The parser structure.
-//
-// All members are internal. Manage the structure using the
-// yaml_parser_ family of functions.
-type yaml_parser_t struct {
-
- // Error handling
-
- error yaml_error_type_t // Error type.
-
- problem string // Error description.
-
- // The byte about which the problem occurred.
- problem_offset int
- problem_value int
- problem_mark yaml_mark_t
-
- // The error context.
- context string
- context_mark yaml_mark_t
-
- // Reader stuff
-
- read_handler yaml_read_handler_t // Read handler.
-
- input_reader io.Reader // File input data.
- input []byte // String input data.
- input_pos int
-
- eof bool // EOF flag
-
- buffer []byte // The working buffer.
- buffer_pos int // The current position of the buffer.
-
- unread int // The number of unread characters in the buffer.
-
- newlines int // The number of line breaks since last non-break/non-blank character
-
- raw_buffer []byte // The raw buffer.
- raw_buffer_pos int // The current position of the buffer.
-
- encoding yaml_encoding_t // The input encoding.
-
- offset int // The offset of the current position (in bytes).
- mark yaml_mark_t // The mark of the current position.
-
- // Comments
-
- head_comment []byte // The current head comments
- line_comment []byte // The current line comments
- foot_comment []byte // The current foot comments
- tail_comment []byte // Foot comment that happens at the end of a block.
- stem_comment []byte // Comment in item preceding a nested structure (list inside list item, etc)
-
- comments []yaml_comment_t // The folded comments for all parsed tokens
- comments_head int
-
- // Scanner stuff
-
- stream_start_produced bool // Have we started to scan the input stream?
- stream_end_produced bool // Have we reached the end of the input stream?
-
- flow_level int // The number of unclosed '[' and '{' indicators.
-
- tokens []yaml_token_t // The tokens queue.
- tokens_head int // The head of the tokens queue.
- tokens_parsed int // The number of tokens fetched from the queue.
- token_available bool // Does the tokens queue contain a token ready for dequeueing.
-
- indent int // The current indentation level.
- indents []int // The indentation levels stack.
-
- simple_key_allowed bool // May a simple key occur at the current position?
- simple_keys []yaml_simple_key_t // The stack of simple keys.
- simple_keys_by_tok map[int]int // possible simple_key indexes indexed by token_number
-
- // Parser stuff
-
- state yaml_parser_state_t // The current parser state.
- states []yaml_parser_state_t // The parser states stack.
- marks []yaml_mark_t // The stack of marks.
- tag_directives []yaml_tag_directive_t // The list of TAG directives.
-
- // Dumper stuff
-
- aliases []yaml_alias_data_t // The alias data.
-
- document *yaml_document_t // The currently parsed document.
-}
-
-type yaml_comment_t struct {
-
- scan_mark yaml_mark_t // Position where scanning for comments started
- token_mark yaml_mark_t // Position after which tokens will be associated with this comment
- start_mark yaml_mark_t // Position of '#' comment mark
- end_mark yaml_mark_t // Position where comment terminated
-
- head []byte
- line []byte
- foot []byte
-}
-
-// Emitter Definitions
-
-// The prototype of a write handler.
-//
-// The write handler is called when the emitter needs to flush the accumulated
-// characters to the output. The handler should write @a size bytes of the
-// @a buffer to the output.
-//
-// @param[in,out] data A pointer to an application data specified by
-// yaml_emitter_set_output().
-// @param[in] buffer The buffer with bytes to be written.
-// @param[in] size The size of the buffer.
-//
-// @returns On success, the handler should return @c 1. If the handler failed,
-// the returned value should be @c 0.
-//
-type yaml_write_handler_t func(emitter *yaml_emitter_t, buffer []byte) error
-
-type yaml_emitter_state_t int
-
-// The emitter states.
-const (
- // Expect STREAM-START.
- yaml_EMIT_STREAM_START_STATE yaml_emitter_state_t = iota
-
- yaml_EMIT_FIRST_DOCUMENT_START_STATE // Expect the first DOCUMENT-START or STREAM-END.
- yaml_EMIT_DOCUMENT_START_STATE // Expect DOCUMENT-START or STREAM-END.
- yaml_EMIT_DOCUMENT_CONTENT_STATE // Expect the content of a document.
- yaml_EMIT_DOCUMENT_END_STATE // Expect DOCUMENT-END.
- yaml_EMIT_FLOW_SEQUENCE_FIRST_ITEM_STATE // Expect the first item of a flow sequence.
- yaml_EMIT_FLOW_SEQUENCE_TRAIL_ITEM_STATE // Expect the next item of a flow sequence, with the comma already written out
- yaml_EMIT_FLOW_SEQUENCE_ITEM_STATE // Expect an item of a flow sequence.
- yaml_EMIT_FLOW_MAPPING_FIRST_KEY_STATE // Expect the first key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_TRAIL_KEY_STATE // Expect the next key of a flow mapping, with the comma already written out
- yaml_EMIT_FLOW_MAPPING_KEY_STATE // Expect a key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_SIMPLE_VALUE_STATE // Expect a value for a simple key of a flow mapping.
- yaml_EMIT_FLOW_MAPPING_VALUE_STATE // Expect a value of a flow mapping.
- yaml_EMIT_BLOCK_SEQUENCE_FIRST_ITEM_STATE // Expect the first item of a block sequence.
- yaml_EMIT_BLOCK_SEQUENCE_ITEM_STATE // Expect an item of a block sequence.
- yaml_EMIT_BLOCK_MAPPING_FIRST_KEY_STATE // Expect the first key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_KEY_STATE // Expect the key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_SIMPLE_VALUE_STATE // Expect a value for a simple key of a block mapping.
- yaml_EMIT_BLOCK_MAPPING_VALUE_STATE // Expect a value of a block mapping.
- yaml_EMIT_END_STATE // Expect nothing.
-)
-
-// The emitter structure.
-//
-// All members are internal. Manage the structure using the @c yaml_emitter_
-// family of functions.
-type yaml_emitter_t struct {
-
- // Error handling
-
- error yaml_error_type_t // Error type.
- problem string // Error description.
-
- // Writer stuff
-
- write_handler yaml_write_handler_t // Write handler.
-
- output_buffer *[]byte // String output data.
- output_writer io.Writer // File output data.
-
- buffer []byte // The working buffer.
- buffer_pos int // The current position of the buffer.
-
- raw_buffer []byte // The raw buffer.
- raw_buffer_pos int // The current position of the buffer.
-
- encoding yaml_encoding_t // The stream encoding.
-
- // Emitter stuff
-
- canonical bool // If the output is in the canonical style?
- best_indent int // The number of indentation spaces.
- best_width int // The preferred width of the output lines.
- unicode bool // Allow unescaped non-ASCII characters?
- line_break yaml_break_t // The preferred line break.
-
- state yaml_emitter_state_t // The current emitter state.
- states []yaml_emitter_state_t // The stack of states.
-
- events []yaml_event_t // The event queue.
- events_head int // The head of the event queue.
-
- indents []int // The stack of indentation levels.
-
- tag_directives []yaml_tag_directive_t // The list of tag directives.
-
- indent int // The current indentation level.
-
- flow_level int // The current flow level.
-
- root_context bool // Is it the document root context?
- sequence_context bool // Is it a sequence context?
- mapping_context bool // Is it a mapping context?
- simple_key_context bool // Is it a simple mapping key context?
-
- line int // The current line.
- column int // The current column.
- whitespace bool // If the last character was a whitespace?
- indention bool // If the last character was an indentation character (' ', '-', '?', ':')?
- open_ended bool // If an explicit document end is required?
-
- space_above bool // Is there's an empty line above?
- foot_indent int // The indent used to write the foot comment above, or -1 if none.
-
- // Anchor analysis.
- anchor_data struct {
- anchor []byte // The anchor value.
- alias bool // Is it an alias?
- }
-
- // Tag analysis.
- tag_data struct {
- handle []byte // The tag handle.
- suffix []byte // The tag suffix.
- }
-
- // Scalar analysis.
- scalar_data struct {
- value []byte // The scalar value.
- multiline bool // Does the scalar contain line breaks?
- flow_plain_allowed bool // Can the scalar be expessed in the flow plain style?
- block_plain_allowed bool // Can the scalar be expressed in the block plain style?
- single_quoted_allowed bool // Can the scalar be expressed in the single quoted style?
- block_allowed bool // Can the scalar be expressed in the literal or folded styles?
- style yaml_scalar_style_t // The output style.
- }
-
- // Comments
- head_comment []byte
- line_comment []byte
- foot_comment []byte
- tail_comment []byte
-
- key_line_comment []byte
-
- // Dumper stuff
-
- opened bool // If the stream was already opened?
- closed bool // If the stream was already closed?
-
- // The information associated with the document nodes.
- anchors *struct {
- references int // The number of references.
- anchor int // The anchor id.
- serialized bool // If the node has been emitted?
- }
-
- last_anchor_id int // The last assigned anchor id.
-
- document *yaml_document_t // The currently emitted document.
-}
diff --git a/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go b/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go
deleted file mode 100644
index e88f9c5..0000000
--- a/sesh/vendor/gopkg.in/yaml.v3/yamlprivateh.go
+++ /dev/null
@@ -1,198 +0,0 @@
-//
-// Copyright (c) 2011-2019 Canonical Ltd
-// Copyright (c) 2006-2010 Kirill Simonov
-//
-// Permission is hereby granted, free of charge, to any person obtaining a copy of
-// this software and associated documentation files (the "Software"), to deal in
-// the Software without restriction, including without limitation the rights to
-// use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
-// of the Software, and to permit persons to whom the Software is furnished to do
-// so, subject to the following conditions:
-//
-// The above copyright notice and this permission notice shall be included in all
-// copies or substantial portions of the Software.
-//
-// THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-// IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-// FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-// AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-// LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-// OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-// SOFTWARE.
-
-package yaml
-
-const (
- // The size of the input raw buffer.
- input_raw_buffer_size = 512
-
- // The size of the input buffer.
- // It should be possible to decode the whole raw buffer.
- input_buffer_size = input_raw_buffer_size * 3
-
- // The size of the output buffer.
- output_buffer_size = 128
-
- // The size of the output raw buffer.
- // It should be possible to encode the whole output buffer.
- output_raw_buffer_size = (output_buffer_size*2 + 2)
-
- // The size of other stacks and queues.
- initial_stack_size = 16
- initial_queue_size = 16
- initial_string_size = 16
-)
-
-// Check if the character at the specified position is an alphabetical
-// character, a digit, '_', or '-'.
-func is_alpha(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9' || b[i] >= 'A' && b[i] <= 'Z' || b[i] >= 'a' && b[i] <= 'z' || b[i] == '_' || b[i] == '-'
-}
-
-// Check if the character at the specified position is a digit.
-func is_digit(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9'
-}
-
-// Get the value of a digit.
-func as_digit(b []byte, i int) int {
- return int(b[i]) - '0'
-}
-
-// Check if the character at the specified position is a hex-digit.
-func is_hex(b []byte, i int) bool {
- return b[i] >= '0' && b[i] <= '9' || b[i] >= 'A' && b[i] <= 'F' || b[i] >= 'a' && b[i] <= 'f'
-}
-
-// Get the value of a hex-digit.
-func as_hex(b []byte, i int) int {
- bi := b[i]
- if bi >= 'A' && bi <= 'F' {
- return int(bi) - 'A' + 10
- }
- if bi >= 'a' && bi <= 'f' {
- return int(bi) - 'a' + 10
- }
- return int(bi) - '0'
-}
-
-// Check if the character is ASCII.
-func is_ascii(b []byte, i int) bool {
- return b[i] <= 0x7F
-}
-
-// Check if the character at the start of the buffer can be printed unescaped.
-func is_printable(b []byte, i int) bool {
- return ((b[i] == 0x0A) || // . == #x0A
- (b[i] >= 0x20 && b[i] <= 0x7E) || // #x20 <= . <= #x7E
- (b[i] == 0xC2 && b[i+1] >= 0xA0) || // #0xA0 <= . <= #xD7FF
- (b[i] > 0xC2 && b[i] < 0xED) ||
- (b[i] == 0xED && b[i+1] < 0xA0) ||
- (b[i] == 0xEE) ||
- (b[i] == 0xEF && // #xE000 <= . <= #xFFFD
- !(b[i+1] == 0xBB && b[i+2] == 0xBF) && // && . != #xFEFF
- !(b[i+1] == 0xBF && (b[i+2] == 0xBE || b[i+2] == 0xBF))))
-}
-
-// Check if the character at the specified position is NUL.
-func is_z(b []byte, i int) bool {
- return b[i] == 0x00
-}
-
-// Check if the beginning of the buffer is a BOM.
-func is_bom(b []byte, i int) bool {
- return b[0] == 0xEF && b[1] == 0xBB && b[2] == 0xBF
-}
-
-// Check if the character at the specified position is space.
-func is_space(b []byte, i int) bool {
- return b[i] == ' '
-}
-
-// Check if the character at the specified position is tab.
-func is_tab(b []byte, i int) bool {
- return b[i] == '\t'
-}
-
-// Check if the character at the specified position is blank (space or tab).
-func is_blank(b []byte, i int) bool {
- //return is_space(b, i) || is_tab(b, i)
- return b[i] == ' ' || b[i] == '\t'
-}
-
-// Check if the character at the specified position is a line break.
-func is_break(b []byte, i int) bool {
- return (b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9) // PS (#x2029)
-}
-
-func is_crlf(b []byte, i int) bool {
- return b[i] == '\r' && b[i+1] == '\n'
-}
-
-// Check if the character is a line break or NUL.
-func is_breakz(b []byte, i int) bool {
- //return is_break(b, i) || is_z(b, i)
- return (
- // is_break:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- // is_z:
- b[i] == 0)
-}
-
-// Check if the character is a line break, space, or NUL.
-func is_spacez(b []byte, i int) bool {
- //return is_space(b, i) || is_breakz(b, i)
- return (
- // is_space:
- b[i] == ' ' ||
- // is_breakz:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- b[i] == 0)
-}
-
-// Check if the character is a line break, space, tab, or NUL.
-func is_blankz(b []byte, i int) bool {
- //return is_blank(b, i) || is_breakz(b, i)
- return (
- // is_blank:
- b[i] == ' ' || b[i] == '\t' ||
- // is_breakz:
- b[i] == '\r' || // CR (#xD)
- b[i] == '\n' || // LF (#xA)
- b[i] == 0xC2 && b[i+1] == 0x85 || // NEL (#x85)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA8 || // LS (#x2028)
- b[i] == 0xE2 && b[i+1] == 0x80 && b[i+2] == 0xA9 || // PS (#x2029)
- b[i] == 0)
-}
-
-// Determine the width of the character.
-func width(b byte) int {
- // Don't replace these by a switch without first
- // confirming that it is being inlined.
- if b&0x80 == 0x00 {
- return 1
- }
- if b&0xE0 == 0xC0 {
- return 2
- }
- if b&0xF0 == 0xE0 {
- return 3
- }
- if b&0xF8 == 0xF0 {
- return 4
- }
- return 0
-
-}
diff --git a/sesh/vendor/modules.txt b/sesh/vendor/modules.txt
index 750e523..4cae9ad 100644
--- a/sesh/vendor/modules.txt
+++ b/sesh/vendor/modules.txt
@@ -42,6 +42,17 @@ github.com/gdamore/tcell/v2/terminfo/x/xfce
github.com/gdamore/tcell/v2/terminfo/x/xterm
github.com/gdamore/tcell/v2/terminfo/x/xterm_kitty
github.com/gdamore/tcell/v2/terminfo/x/xterm_termite
+# github.com/goccy/go-yaml v1.19.2
+## explicit; go 1.21.0
+github.com/goccy/go-yaml
+github.com/goccy/go-yaml/ast
+github.com/goccy/go-yaml/internal/errors
+github.com/goccy/go-yaml/internal/format
+github.com/goccy/go-yaml/lexer
+github.com/goccy/go-yaml/parser
+github.com/goccy/go-yaml/printer
+github.com/goccy/go-yaml/scanner
+github.com/goccy/go-yaml/token
# github.com/ktr0731/go-ansisgr v0.1.0
## explicit; go 1.19
github.com/ktr0731/go-ansisgr
@@ -78,6 +89,3 @@ golang.org/x/term
golang.org/x/text/encoding
golang.org/x/text/encoding/internal/identifier
golang.org/x/text/transform
-# gopkg.in/yaml.v3 v3.0.1
-## explicit
-gopkg.in/yaml.v3